 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Blocked and Hierarchical Disentangled Representation From Information Theory Perspective
Jan 21, 2021
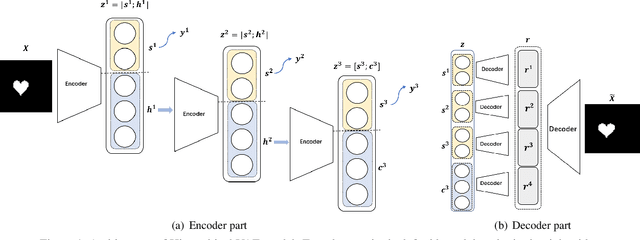

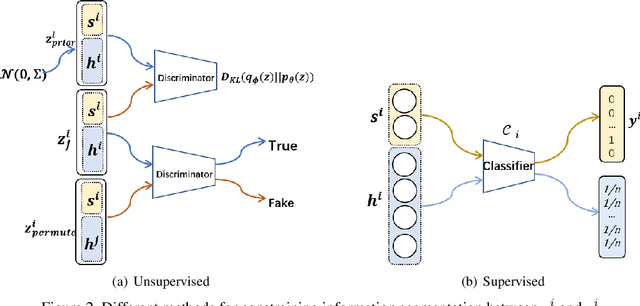
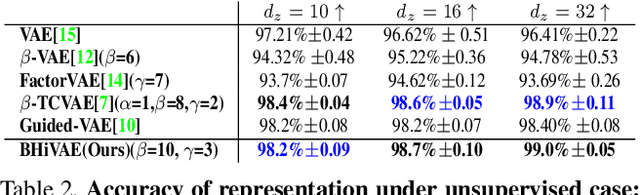
We propose a novel and theoretical model, blocked and hierarchical variational autoencoder (BHiVAE), to get better-disentangled representation. It is well known that information theory has an excellent explanatory meaning for the network, so we start to solve the disentanglement problem from the perspective of information theory. BHiVAE mainly comes from the information bottleneck theory and information maximization principle. Our main idea is that (1) Neurons block not only one neuron node is used to represent attribute, which can contain enough information; (2) Create a hierarchical structure with different attributes on different layers, so that we can segment the information within each layer to ensure that the final representation is disentangled. Furthermore, we present supervised and unsupervised BHiVAE, respectively, where the difference is mainly reflected in the separation of information between different blocks. In supervised BHiVAE, we utilize the label information as the standard to separate blocks. In unsupervised BHiVAE, without extra information, we use the Total Correlation (TC) measure to achieve independence, and we design a new prior distribution of the latent space to guide the representation learning. It also exhibits excellent disentanglement results in experiments and superior classification accuracy in representation learning.
Representation Gap in Deep Reinforcement Learning
May 29, 2022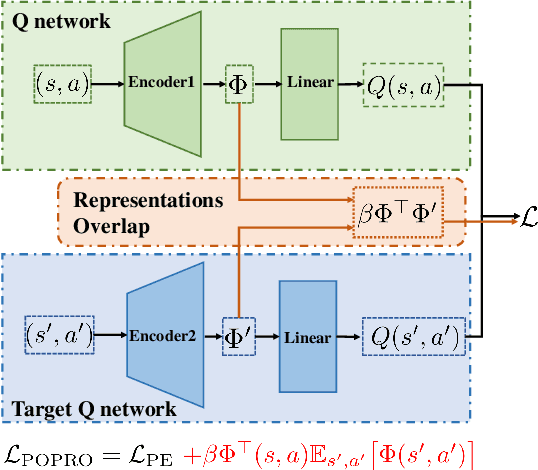
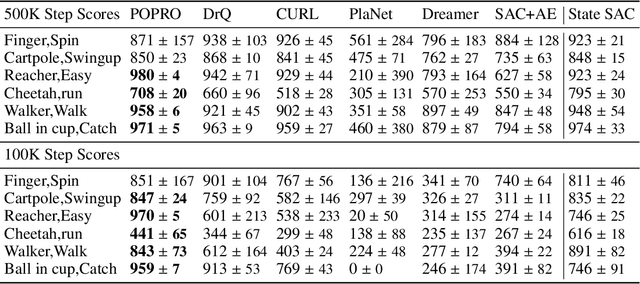
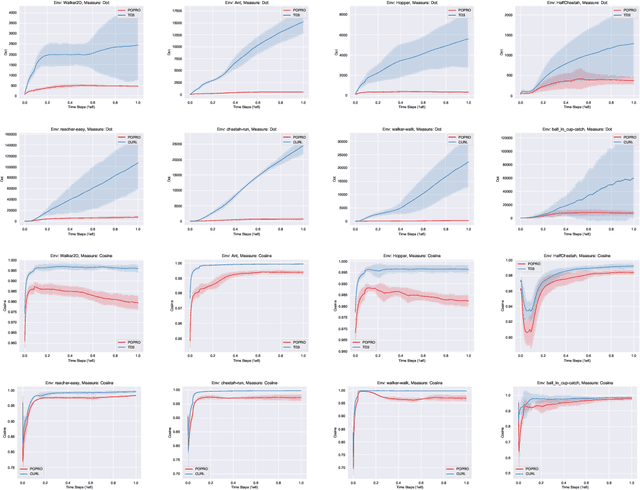
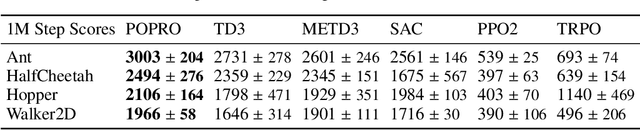
Deep reinforcement learning gives the promise that an agent learns good policy from high-dimensional information. Whereas representation learning removes irrelevant and redundant information and retains pertinent information. We consider the representation capacity of action value function and theoretically reveal its inherent property, \textit{representation gap} with its target action value function. This representation gap is favorable. However, through illustrative experiments, we show that the representation of action value function grows similarly compared with its target value function, i.e. the undesirable inactivity of the representation gap (\textit{representation overlap}). Representation overlap results in a loss of representation capacity, which further leads to sub-optimal learning performance. To activate the representation gap, we propose a simple but effective framework \underline{P}olicy \underline{O}ptimization from \underline{P}reventing \underline{R}epresentation \underline{O}verlaps (POPRO), which regularizes the policy evaluation phase through differing the representation of action value function from its target. We also provide the convergence rate guarantee of POPRO. We evaluate POPRO on gym continuous control suites. The empirical results show that POPRO using pixel inputs outperforms or parallels the sample-efficiency of methods that use state-based features.
Outcome-Guided Counterfactuals for Reinforcement Learning Agents from a Jointly Trained Generative Latent Space
Jul 15, 2022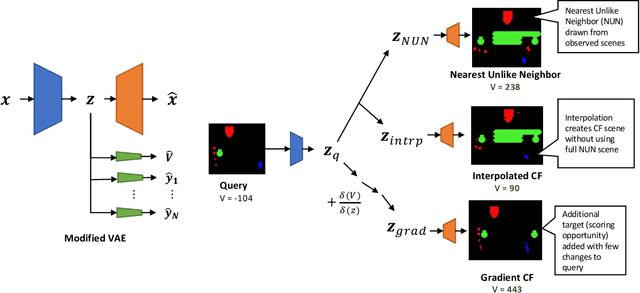
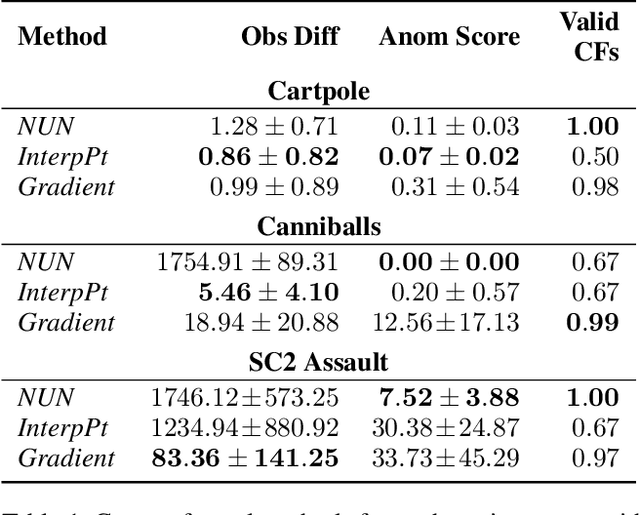
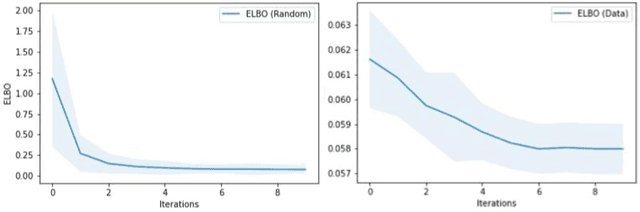
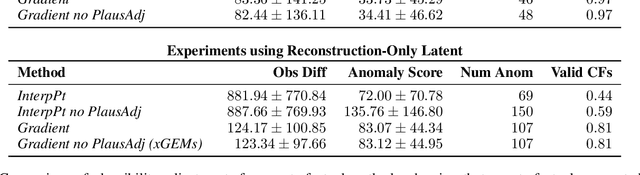
We present a novel generative method for producing unseen and plausible counterfactual examples for reinforcement learning (RL) agents based upon outcome variables that characterize agent behavior. Our approach uses a variational autoencoder to train a latent space that jointly encodes information about the observations and outcome variables pertaining to an agent's behavior. Counterfactuals are generated using traversals in this latent space, via gradient-driven updates as well as latent interpolations against cases drawn from a pool of examples. These include updates to raise the likelihood of generated examples, which improves the plausibility of generated counterfactuals. From experiments in three RL environments, we show that these methods produce counterfactuals that are more plausible and proximal to their queries compared to purely outcome-driven or case-based baselines. Finally, we show that a latent jointly trained to reconstruct both the input observations and behavioral outcome variables produces higher-quality counterfactuals over latents trained solely to reconstruct the observation inputs.
Algorithms to estimate Shapley value feature attributions
Jul 15, 2022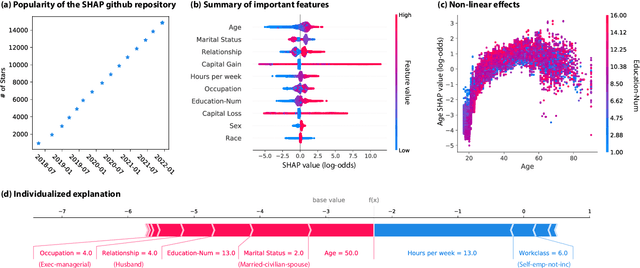
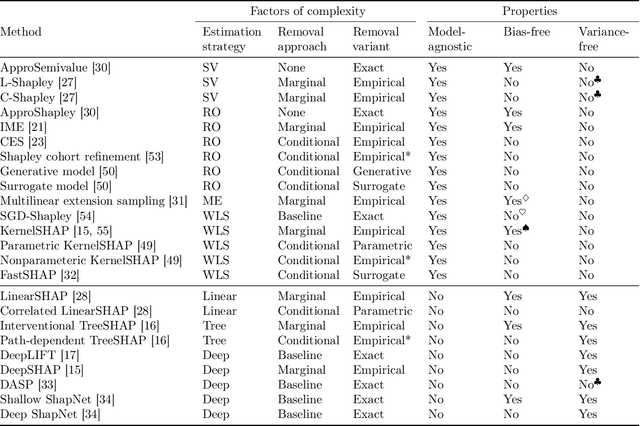
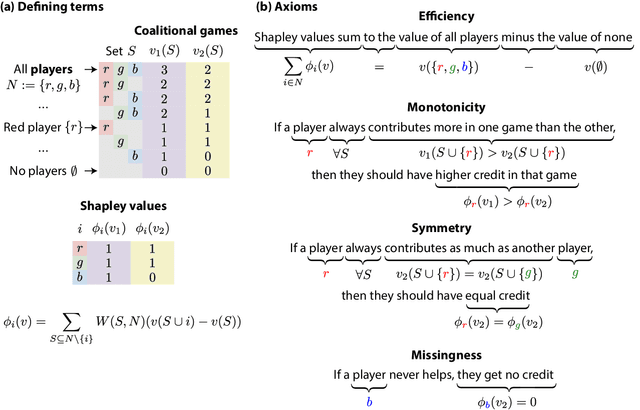
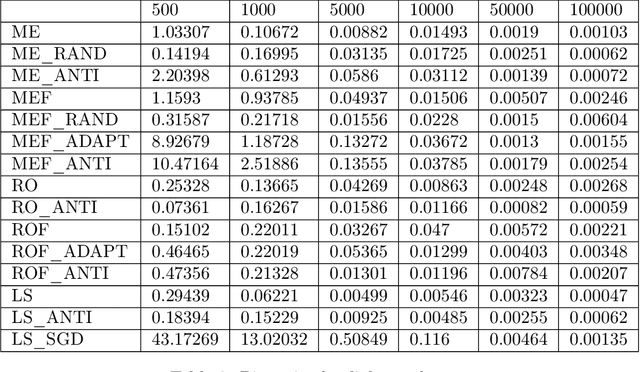
Feature attributions based on the Shapley value are popular for explaining machine learning models; however, their estimation is complex from both a theoretical and computational standpoint. We disentangle this complexity into two factors: (1)~the approach to removing feature information, and (2)~the tractable estimation strategy. These two factors provide a natural lens through which we can better understand and compare 24 distinct algorithms. Based on the various feature removal approaches, we describe the multiple types of Shapley value feature attributions and methods to calculate each one. Then, based on the tractable estimation strategies, we characterize two distinct families of approaches: model-agnostic and model-specific approximations. For the model-agnostic approximations, we benchmark a wide class of estimation approaches and tie them to alternative yet equivalent characterizations of the Shapley value. For the model-specific approximations, we clarify the assumptions crucial to each method's tractability for linear, tree, and deep models. Finally, we identify gaps in the literature and promising future research directions.
Dynamic 3D Scene Analysis by Point Cloud Accumulation
Jul 25, 2022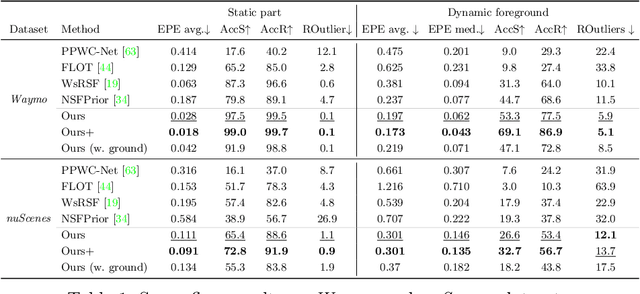
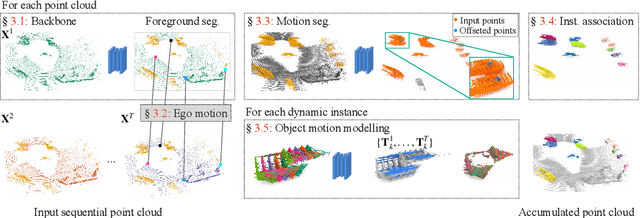
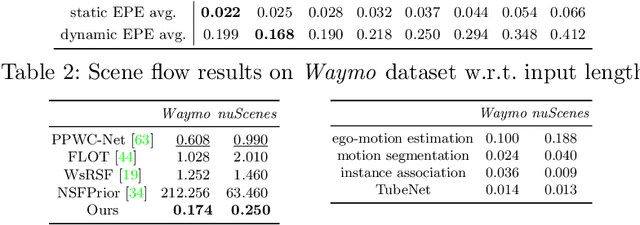
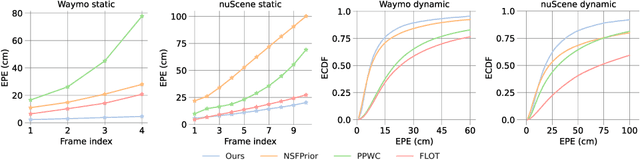
Multi-beam LiDAR sensors, as used on autonomous vehicles and mobile robots, acquire sequences of 3D range scans ("frames"). Each frame covers the scene sparsely, due to limited angular scanning resolution and occlusion. The sparsity restricts the performance of downstream processes like semantic segmentation or surface reconstruction. Luckily, when the sensor moves, frames are captured from a sequence of different viewpoints. This provides complementary information and, when accumulated in a common scene coordinate frame, yields a denser sampling and a more complete coverage of the underlying 3D scene. However, often the scanned scenes contain moving objects. Points on those objects are not correctly aligned by just undoing the scanner's ego-motion. In the present paper, we explore multi-frame point cloud accumulation as a mid-level representation of 3D scan sequences, and develop a method that exploits inductive biases of outdoor street scenes, including their geometric layout and object-level rigidity. Compared to state-of-the-art scene flow estimators, our proposed approach aims to align all 3D points in a common reference frame correctly accumulating the points on the individual objects. Our approach greatly reduces the alignment errors on several benchmark datasets. Moreover, the accumulated point clouds benefit high-level tasks like surface reconstruction.
Cross-media Scientific Research Achievements Query based on Ranking Learning
Apr 26, 2022With the advent of the information age, the scale of data on the Internet is getting larger and larger, and it is full of text, images, videos, and other information. Different from social media data and news data, scientific research achievements information has the characteristics of many proper nouns and strong ambiguity. The traditional single-mode query method based on keywords can no longer meet the needs of scientific researchers and managers of the Ministry of Science and Technology. Scientific research project information and scientific research scholar information contain a large amount of valuable scientific research achievement information. Evaluating the output capability of scientific research projects and scientific research teams can effectively assist managers in decision-making. In view of the above background, this paper expounds on the research status from four aspects: characteristic learning of scientific research results, cross-media research results query, ranking learning of scientific research results, and cross-media scientific research achievement query system.
CQE in OWL 2 QL: A "Longest Honeymoon" Approach (extended version)
Jul 22, 2022Controlled Query Evaluation (CQE) has been recently studied in the context of Semantic Web ontologies. The goal of CQE is concealing some query answers so as to prevent external users from inferring confidential information. In general, there exist multiple, mutually incomparable ways of concealing answers, and previous CQE approaches choose in advance which answers are visible and which are not. In this paper, instead, we study a dynamic CQE method, namely, we propose to alter the answer to the current query based on the evaluation of previous ones. We aim at a system that, besides being able to protect confidential data, is maximally cooperative, which intuitively means that it answers affirmatively to as many queries as possible; it achieves this goal by delaying answer modifications as much as possible. We also show that the behavior we get cannot be intensionally simulated through a static approach, independent of query history. Interestingly, for OWL 2 QL ontologies and policy expressed through denials, query evaluation under our semantics is first-order rewritable, and thus in AC0 in data complexity. This paves the way for the development of practical algorithms, which we also preliminarily discuss in the paper.
An Information-theoretic Approach to Distribution Shifts
Jun 07, 2021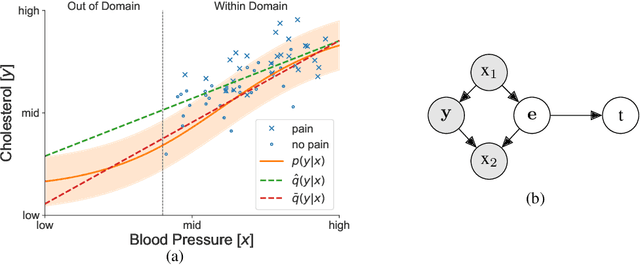
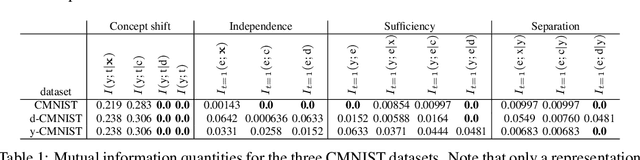
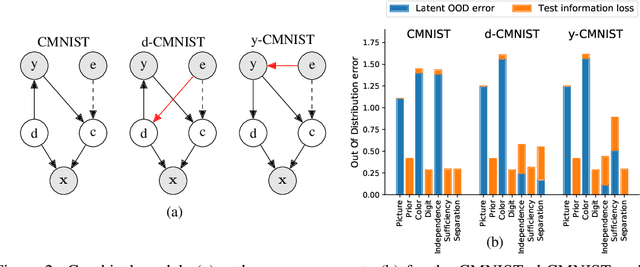
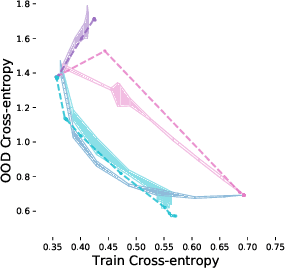
Safely deploying machine learning models to the real world is often a challenging process. Models trained with data obtained from a specific geographic location tend to fail when queried with data obtained elsewhere, agents trained in a simulation can struggle to adapt when deployed in the real world or novel environments, and neural networks that are fit to a subset of the population might carry some selection bias into their decision process. In this work, we describe the problem of data shift from a novel information-theoretic perspective by (i) identifying and describing the different sources of error, (ii) comparing some of the most promising objectives explored in the recent domain generalization, and fair classification literature. From our theoretical analysis and empirical evaluation, we conclude that the model selection procedure needs to be guided by careful considerations regarding the observed data, the factors used for correction, and the structure of the data-generating process.
WiVelo: Fine-grained Walking Velocity Estimation for Wi-Fi Passive Tracking
Jul 28, 2022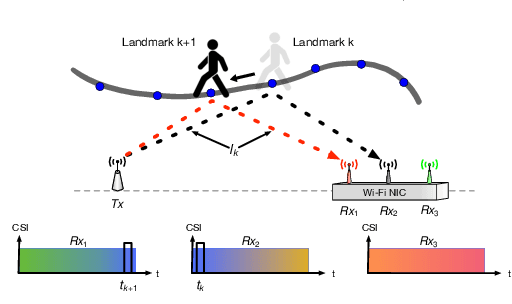
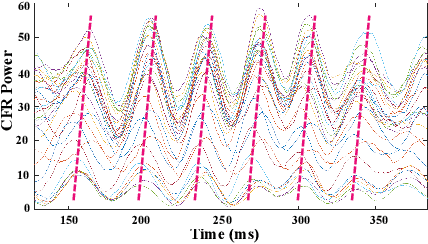
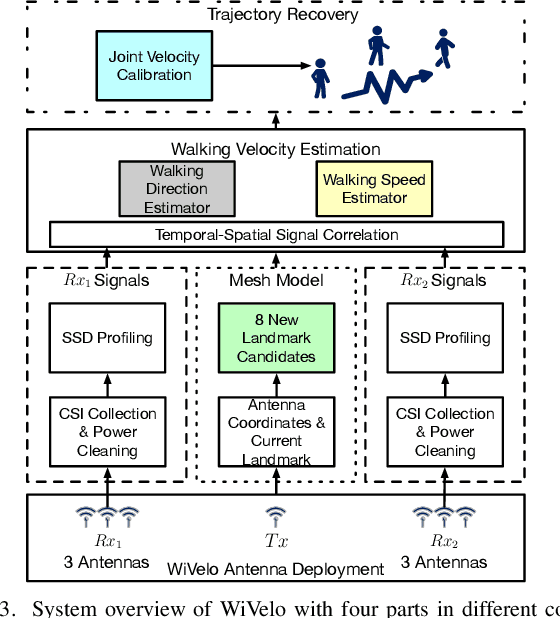
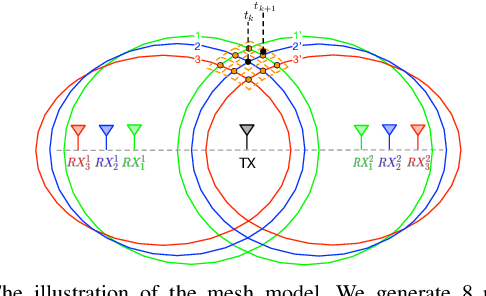
Passive human tracking via Wi-Fi has been researched broadly in the past decade. Besides straight-forward anchor point localization, velocity is another vital sign adopted by the existing approaches to infer user trajectory. However, state-of-the-art Wi-Fi velocity estimation relies on Doppler-Frequency-Shift (DFS) which suffers from the inevitable signal noise incurring unbounded velocity errors, further degrading the tracking accuracy. In this paper, we present WiVelo\footnote{Code\&datasets are available at \textit{https://github.com/liecn/WiVelo\_SECON22}} that explores new spatial-temporal signal correlation features observed from different antennas to achieve accurate velocity estimation. First, we use subcarrier shift distribution (SSD) extracted from channel state information (CSI) to define two correlation features for direction and speed estimation, separately. Then, we design a mesh model calculated by the antennas' locations to enable a fine-grained velocity estimation with bounded direction error. Finally, with the continuously estimated velocity, we develop an end-to-end trajectory recovery algorithm to mitigate velocity outliers with the property of walking velocity continuity. We implement WiVelo on commodity Wi-Fi hardware and extensively evaluate its tracking accuracy in various environments. The experimental results show our median and 90\% tracking errors are 0.47~m and 1.06~m, which are half and a quarter of state-of-the-arts.
ACM -- Attribute Conditioning for Abstractive Multi Document Summarization
May 09, 2022
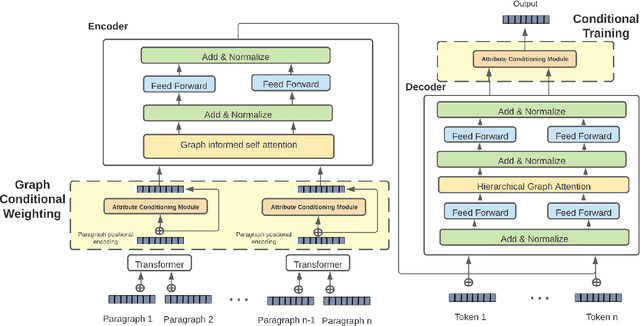


Abstractive multi document summarization has evolved as a task through the basic sequence to sequence approaches to transformer and graph based techniques. Each of these approaches has primarily focused on the issues of multi document information synthesis and attention based approaches to extract salient information. A challenge that arises with multi document summarization which is not prevalent in single document summarization is the need to effectively summarize multiple documents that might have conflicting polarity, sentiment or subjective information about a given topic. In this paper we propose ACM, attribute conditioned multi document summarization,a model that incorporates attribute conditioning modules in order to decouple conflicting information by conditioning for a certain attribute in the output summary. This approach shows strong gains in ROUGE score over baseline multi document summarization approaches and shows gains in fluency, informativeness and reduction in repetitiveness as shown through a human annotation analysis study.