 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusionCom: Structure-Aware Multimodal Diffusion Model for Multimodal Knowledge Graph Completion
Apr 09, 2025Most current MKGC approaches are predominantly based on discriminative models that maximize conditional likelihood. These approaches struggle to efficiently capture the complex connections in real-world knowledge graphs, thereby limiting their overall performance. To address this issue, we propose a structure-aware multimodal Diffusion model for multimodal knowledge graph Completion (DiffusionCom). DiffusionCom innovatively approaches the problem from the perspective of generative models, modeling the association between the $(head, relation)$ pair and candidate tail entities as their joint probability distribution $p((head, relation), (tail))$, and framing the MKGC task as a process of gradually generating the joint probability distribution from noise. Furthermore, to fully leverage the structural information in MKGs, we propose Structure-MKGformer, an adaptive and structure-aware multimodal knowledge representation learning method, as the encoder for DiffusionCom. Structure-MKGformer captures rich structural information through a multimodal graph attention network (MGAT) and adaptively fuses it with entity representations, thereby enhancing the structural awareness of these representations. This design effectively addresses the limitations of existing MKGC methods, particularly those based on multimodal pre-trained models, in utilizing structural information. DiffusionCom is trained using both generative and discriminative losses for the generator, while the feature extractor is optimized exclusively with discriminative loss. This dual approach allows DiffusionCom to harness the strengths of both generative and discriminative models. Extensive experiments on the FB15k-237-IMG and WN18-IMG datasets demonstrate that DiffusionCom outperforms state-of-the-art models.
Addressing Heterogeneity and Heterophily in Graphs: A Heterogeneous Heterophilic Spectral Graph Neural Network
Oct 17, 2024Graph Neural Networks (GNNs) have garnered significant scholarly attention for their powerful capabilities in modeling graph structures. Despite this, two primary challenges persist: heterogeneity and heterophily. Existing studies often address heterogeneous and heterophilic graphs separately, leaving a research gap in the understanding of heterogeneous heterophilic graphs-those that feature diverse node or relation types with dissimilar connected nodes. To address this gap, we investigate the application of spectral graph filters within heterogeneous graphs. Specifically, we propose a Heterogeneous Heterophilic Spectral Graph Neural Network (H2SGNN), which employs a dual-module approach: local independent filtering and global hybrid filtering. The local independent filtering module applies polynomial filters to each subgraph independently to adapt to different homophily, while the global hybrid filtering module captures interactions across different subgraphs. Extensive empirical evaluations on four real-world datasets demonstrate the superiority of H2SGNN compared to state-of-the-art methods.
Dynamic Self-adaptive Multiscale Distillation from Pre-trained Multimodal Large Model for Efficient Cross-modal Representation Learning
Apr 16, 2024



In recent years, pre-trained multimodal large models have attracted widespread attention due to their outstanding performance in various multimodal applications. Nonetheless, the extensive computational resources and vast datasets required for their training present significant hurdles for deployment in environments with limited computational resources. To address this challenge, we propose a novel dynamic self-adaptive multiscale distillation from pre-trained multimodal large model for efficient cross-modal representation learning for the first time. Unlike existing distillation methods, our strategy employs a multiscale perspective, enabling the extraction structural knowledge across from the pre-trained multimodal large model. Ensuring that the student model inherits a comprehensive and nuanced understanding of the teacher knowledge. To optimize each distillation loss in a balanced and efficient manner, we propose a dynamic self-adaptive distillation loss balancer, a novel component eliminating the need for manual loss weight adjustments and dynamically balances each loss item during the distillation process. Our methodology streamlines pre-trained multimodal large models using only their output features and original image-level information, requiring minimal computational resources. This efficient approach is suited for various applications and allows the deployment of advanced multimodal technologies even in resource-limited settings. Extensive experiments has demonstrated that our method maintains high performance while significantly reducing model complexity and training costs. Moreover, our distilled student model utilizes only image-level information to achieve state-of-the-art performance on cross-modal retrieval tasks, surpassing previous methods that relied on region-level information.
Improving Expressive Power of Spectral Graph Neural Networks with Eigenvalue Correction
Jan 28, 2024In recent years, spectral graph neural networks, characterized by polynomial filters, have garnered increasing attention and have achieved remarkable performance in tasks such as node classification. These models typically assume that eigenvalues for the normalized Laplacian matrix are distinct from each other, thus expecting a polynomial filter to have a high fitting ability. However, this paper empirically observes that normalized Laplacian matrices frequently possess repeated eigenvalues. Moreover, we theoretically establish that the number of distinguishable eigenvalues plays a pivotal role in determining the expressive power of spectral graph neural networks. In light of this observation, we propose an eigenvalue correction strategy that can free polynomial filters from the constraints of repeated eigenvalue inputs. Concretely, the proposed eigenvalue correction strategy enhances the uniform distribution of eigenvalues, thus mitigating repeated eigenvalues, and improving the fitting capacity and expressive power of polynomial filters. Extensive experimental results on both synthetic and real-world datasets demonstrate the superiority of our method.
Topic model based on co-occurrence word networks for unbalanced short text datasets
Nov 05, 2023



We propose a straightforward solution for detecting scarce topics in unbalanced short-text datasets. Our approach, named CWUTM (Topic model based on co-occurrence word networks for unbalanced short text datasets), Our approach addresses the challenge of sparse and unbalanced short text topics by mitigating the effects of incidental word co-occurrence. This allows our model to prioritize the identification of scarce topics (Low-frequency topics). Unlike previous methods, CWUTM leverages co-occurrence word networks to capture the topic distribution of each word, and we enhanced the sensitivity in identifying scarce topics by redefining the calculation of node activity and normalizing the representation of both scarce and abundant topics to some extent. Moreover, CWUTM adopts Gibbs sampling, similar to LDA, making it easily adaptable to various application scenarios. Our extensive experimental validation on unbalanced short-text datasets demonstrates the superiority of CWUTM compared to baseline approaches in discovering scarce topics. According to the experimental results the proposed model is effective in early and accurate detection of emerging topics or unexpected events on social platforms.
Semantic Representation Learning of Scientific Literature based on Adaptive Feature and Graph Neural Network
Nov 01, 2023



Because most of the scientific literature data is unmarked, it makes semantic representation learning based on unsupervised graph become crucial. At the same time, in order to enrich the features of scientific literature, a learning method of semantic representation of scientific literature based on adaptive features and graph neural network is proposed. By introducing the adaptive feature method, the features of scientific literature are considered globally and locally. The graph attention mechanism is used to sum the features of scientific literature with citation relationship, and give each scientific literature different feature weights, so as to better express the correlation between the features of different scientific literature. In addition, an unsupervised graph neural network semantic representation learning method is proposed. By comparing the mutual information between the positive and negative local semantic representation of scientific literature and the global graph semantic representation in the potential space, the graph neural network can capture the local and global information, thus improving the learning ability of the semantic representation of scientific literature. The experimental results show that the proposed learning method of semantic representation of scientific literature based on adaptive feature and graph neural network is competitive on the basis of scientific literature classification, and has achieved good results.
Federated Topic Model and Model Pruning Based on Variational Autoencoder
Nov 01, 2023Topic modeling has emerged as a valuable tool for discovering patterns and topics within large collections of documents. However, when cross-analysis involves multiple parties, data privacy becomes a critical concern. Federated topic modeling has been developed to address this issue, allowing multiple parties to jointly train models while protecting pri-vacy. However, there are communication and performance challenges in the federated sce-nario. In order to solve the above problems, this paper proposes a method to establish a federated topic model while ensuring the privacy of each node, and use neural network model pruning to accelerate the model, where the client periodically sends the model neu-ron cumulative gradients and model weights to the server, and the server prunes the model. To address different requirements, two different methods are proposed to determine the model pruning rate. The first method involves slow pruning throughout the entire model training process, which has limited acceleration effect on the model training process, but can ensure that the pruned model achieves higher accuracy. This can significantly reduce the model inference time during the inference process. The second strategy is to quickly reach the target pruning rate in the early stage of model training in order to accelerate the model training speed, and then continue to train the model with a smaller model size after reaching the target pruning rate. This approach may lose more useful information but can complete the model training faster. Experimental results show that the federated topic model pruning based on the variational autoencoder proposed in this paper can greatly accelerate the model training speed while ensuring the model's performance.
* 8 pages
Cross-modal Search Method of Technology Video based on Adversarial Learning and Feature Fusion
Oct 11, 2022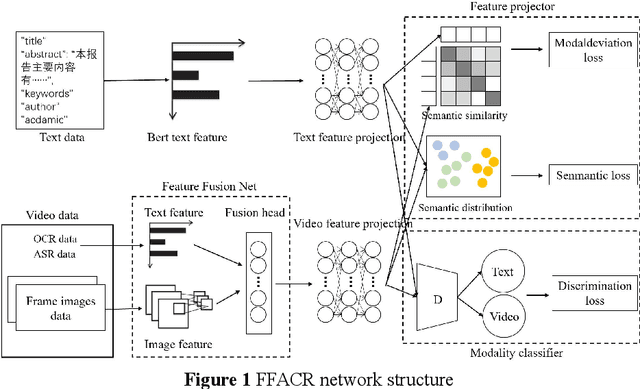
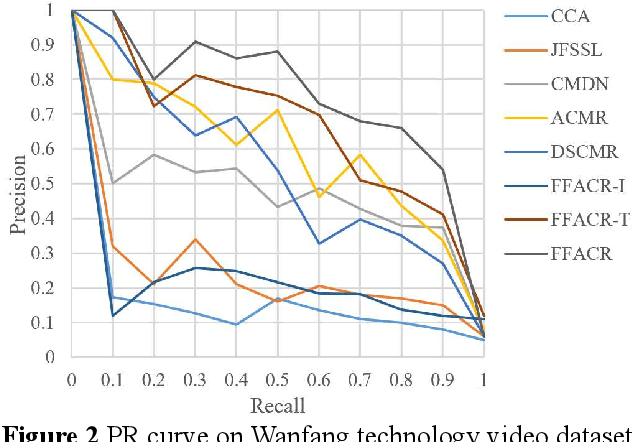
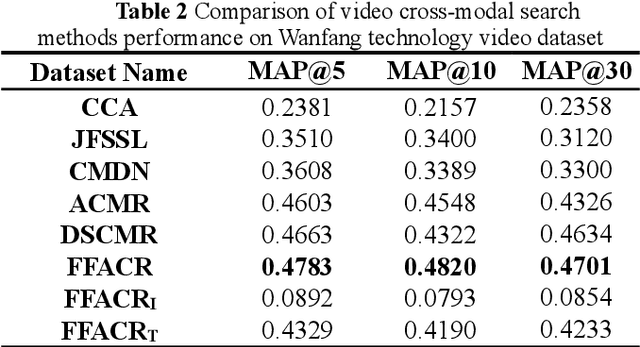
Technology videos contain rich multi-modal information. In cross-modal information search, the data features of different modalities cannot be compared directly, so the semantic gap between different modalities is a key problem that needs to be solved. To address the above problems, this paper proposes a novel Feature Fusion based Adversarial Cross-modal Retrieval method (FFACR) to achieve text-to-video matching, ranking and searching. The proposed method uses the framework of adversarial learning to construct a video multimodal feature fusion network and a feature mapping network as generator, a modality discrimination network as discriminator. Multi-modal features of videos are obtained by the feature fusion network. The feature mapping network projects multi-modal features into the same semantic space based on semantics and similarity. The modality discrimination network is responsible for determining the original modality of features. Generator and discriminator are trained alternately based on adversarial learning, so that the data obtained by the feature mapping network is semantically consistent with the original data and the modal features are eliminated, and finally the similarity is used to rank and obtain the search results in the semantic space. Experimental results demonstrate that the proposed method performs better in text-to-video search than other existing methods, and validate the effectiveness of the method on the self-built datasets of technology videos.
Unsupervised Semantic Representation Learning of Scientific Literature Based on Graph Attention Mechanism and Maximum Mutual Information
Oct 07, 2022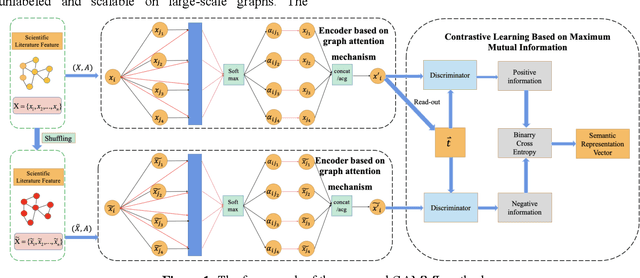

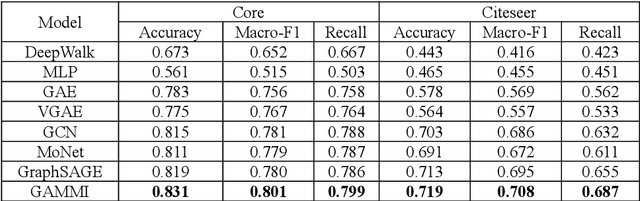
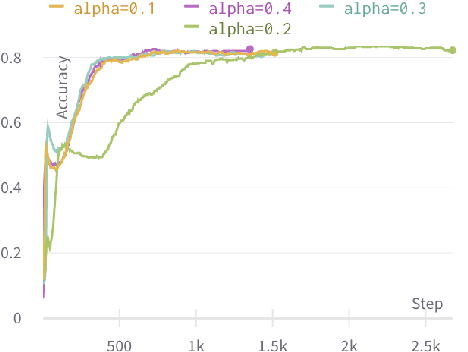
Since most scientific literature data are unlabeled, this makes unsupervised graph-based semantic representation learning crucial. Therefore, an unsupervised semantic representation learning method of scientific literature based on graph attention mechanism and maximum mutual information (GAMMI) is proposed. By introducing a graph attention mechanism, the weighted summation of nearby node features make the weights of adjacent node features entirely depend on the node features. Depending on the features of the nearby nodes, different weights can be applied to each node in the graph. Therefore, the correlations between vertex features can be better integrated into the model. In addition, an unsupervised graph contrastive learning strategy is proposed to solve the problem of being unlabeled and scalable on large-scale graphs. By comparing the mutual information between the positive and negative local node representations on the latent space and the global graph representation, the graph neural network can capture both local and global information. Experimental results demonstrate competitive performance on various node classification benchmarks, achieving good results and sometimes even surpassing the performance of supervised learning.
Embedding Representation of Academic Heterogeneous Information Networks Based on Federated Learning
Oct 07, 2022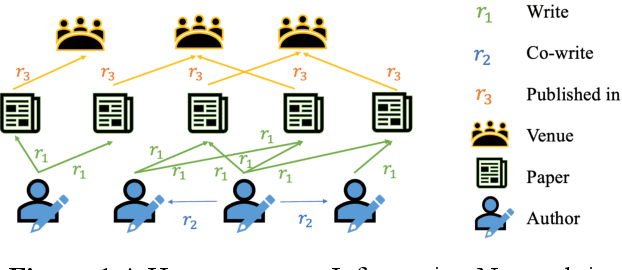
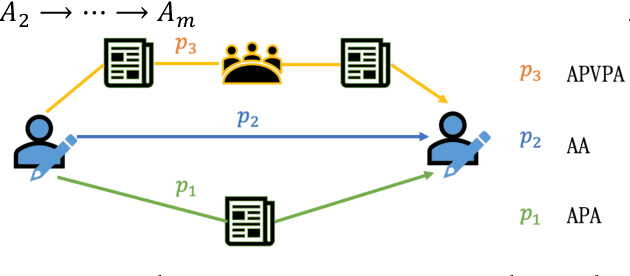
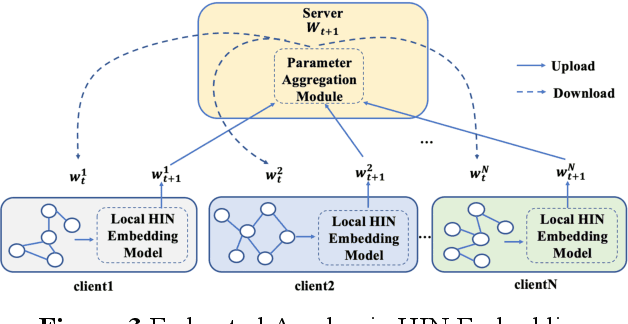
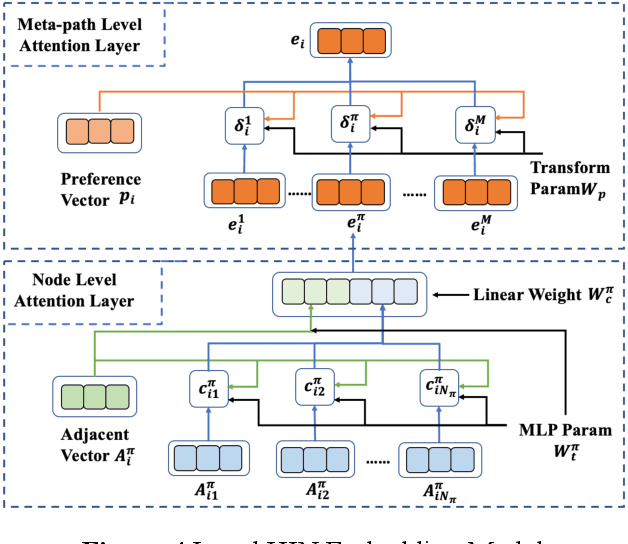
Academic networks in the real world can usually be portrayed as heterogeneous information networks (HINs) with multi-type, universally connected nodes and multi-relationships. Some existing studies for the representation learning of homogeneous information networks cannot be applicable to heterogeneous information networks because of the lack of ability to issue heterogeneity. At the same time, data has become a factor of production, playing an increasingly important role. Due to the closeness and blocking of businesses among different enterprises, there is a serious phenomenon of data islands. To solve the above challenges, aiming at the data information of scientific research teams closely related to science and technology, we proposed an academic heterogeneous information network embedding representation learning method based on federated learning (FedAHE), which utilizes node attention and meta path attention mechanism to learn low-dimensional, dense and real-valued vector representations while preserving the rich topological information and meta-path-based semantic information of nodes in network. Moreover, we combined federated learning with the representation learning of HINs composed of scientific research teams and put forward a federal training mechanism based on dynamic weighted aggregation of parameters (FedDWA) to optimize the node embeddings of HINs. Through sufficient experiments, the efficiency, accuracy and feasibility of our proposed framework are demonstrated.