 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CLEAR: Improving Vision-Language Navigation with Cross-Lingual, Environment-Agnostic Representations
Jul 05, 2022
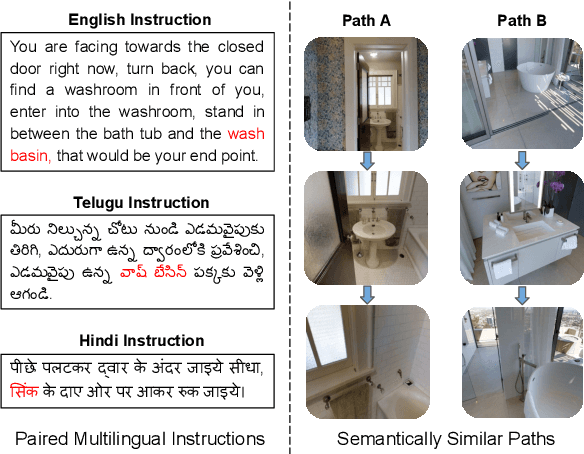
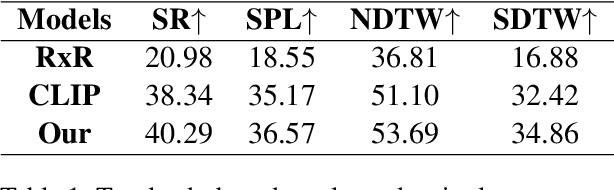
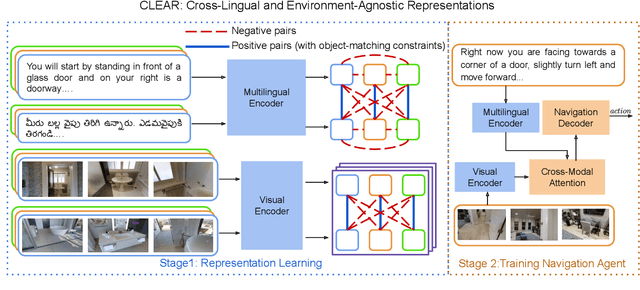
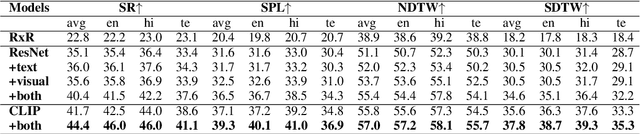
Vision-and-Language Navigation (VLN) tasks require an agent to navigate through the environment based on language instructions. In this paper, we aim to solve two key challenges in this task: utilizing multilingual instructions for improved instruction-path grounding and navigating through new environments that are unseen during training. To address these challenges, we propose CLEAR: Cross-Lingual and Environment-Agnostic Representations. First, our agent learns a shared and visually-aligned cross-lingual language representation for the three languages (English, Hindi and Telugu) in the Room-Across-Room dataset. Our language representation learning is guided by text pairs that are aligned by visual information. Second, our agent learns an environment-agnostic visual representation by maximizing the similarity between semantically-aligned image pairs (with constraints on object-matching) from different environments. Our environment agnostic visual representation can mitigate the environment bias induced by low-level visual information. Empirically, on the Room-Across-Room dataset, we show that our multilingual agent gets large improvements in all metrics over the strong baseline model when generalizing to unseen environments with the cross-lingual language representation and the environment-agnostic visual representation. Furthermore, we show that our learned language and visual representations can be successfully transferred to the Room-to-Room and Cooperative Vision-and-Dialogue Navigation task, and present detailed qualitative and quantitative generalization and grounding analysis. Our code is available at https://github.com/jialuli-luka/CLEAR
Hand-Assisted Expression Recognition Method from Synthetic Images at the Fourth ABAW Challenge
Jul 20, 2022
Learning from synthetic images plays an important role in facial expression recognition task due to the difficulties of labeling the real images, and it is challenging because of the gap between the synthetic images and real images. The fourth Affective Behavior Analysis in-the-wild Competition raises the challenge and provides the synthetic images generated from Aff-Wild2 dataset. In this paper, we propose a hand-assisted expression recognition method to reduce the gap between the synthetic data and real data. Our method consists of two parts: expression recognition module and hand prediction module. Expression recognition module extracts expression information and hand prediction module predicts whether the image contains hands. Decision mode is used to combine the results of two modules, and post-pruning is used to improve the result. F1 score is used to verify the effectiveness of our method.
Equivariant Representation Learning via Class-Pose Decomposition
Jul 11, 2022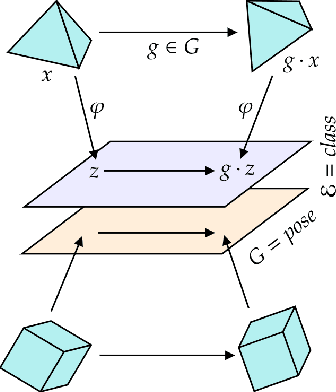
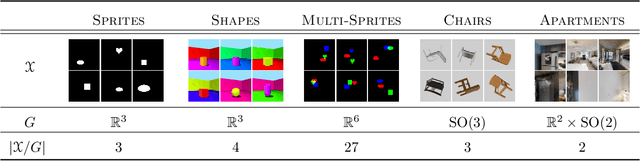
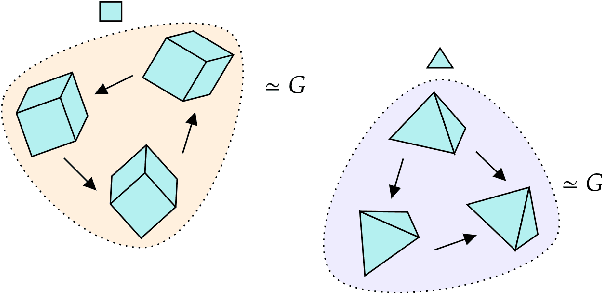
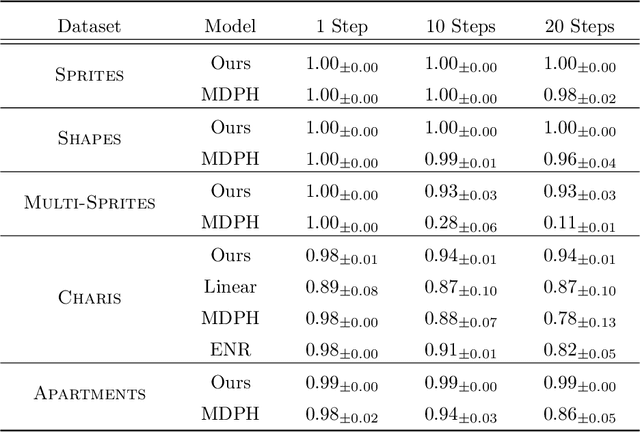
We introduce a general method for learning representations that are equivariant to symmetries of data. Our central idea is to decompose the latent space in an invariant factor and the symmetry group itself. The components semantically correspond to intrinsic data classes and poses respectively. The learner is self-supervised and infers these semantics based on relative symmetry information. The approach is motivated by theoretical results from group theory and guarantees representations that are lossless, interpretable and disentangled. We provide an empirical investigation via experiments involving datasets with a variety of symmetries. Results show that our representations capture the geometry of data and outperform other equivariant representation learning frameworks.
Exploring Map-based Features for Efficient Attention-based Vehicle Motion Prediction
May 25, 2022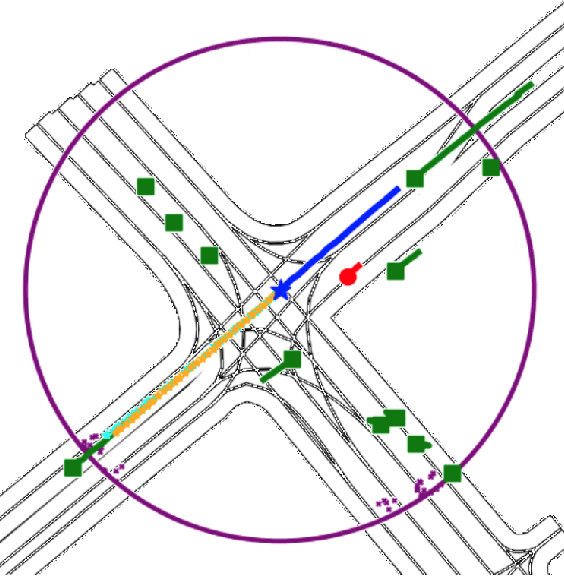
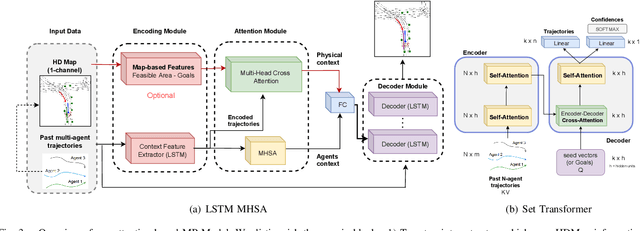
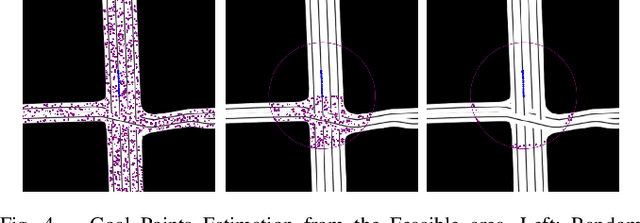
Motion prediction (MP) of multiple agents is a crucial task in arbitrarily complex environments, from social robots to self-driving cars. Current approaches tackle this problem using end-to-end networks, where the input data is usually a rendered top-view of the scene and the past trajectories of all the agents; leveraging this information is a must to obtain optimal performance. In that sense, a reliable Autonomous Driving (AD) system must produce reasonable predictions on time, however, despite many of these approaches use simple ConvNets and LSTMs, models might not be efficient enough for real-time applications when using both sources of information (map and trajectory history). Moreover, the performance of these models highly depends on the amount of training data, which can be expensive (particularly the annotated HD maps). In this work, we explore how to achieve competitive performance on the Argoverse 1.0 Benchmark using efficient attention-based models, which take as input the past trajectories and map-based features from minimal map information to ensure efficient and reliable MP. These features represent interpretable information as the driveable area and plausible goal points, in opposition to black-box CNN-based methods for map processing.
Explored An Effective Methodology for Fine-Grained Snake Recognition
Jul 24, 2022

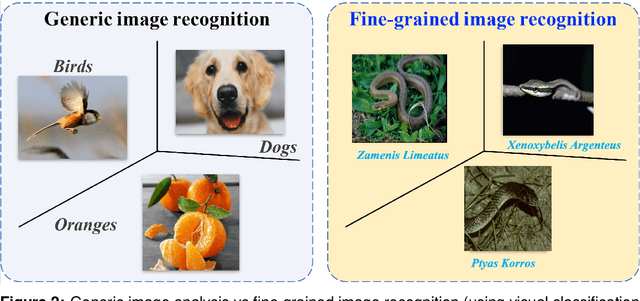

Fine-Grained Visual Classification (FGVC) is a longstanding and fundamental problem in computer vision and pattern recognition, and underpins a diverse set of real-world applications. This paper describes our contribution at SnakeCLEF2022 with FGVC. Firstly, we design a strong multimodal backbone to utilize various meta-information to assist in fine-grained identification. Secondly, we provide new loss functions to solve the long tail distribution with dataset. Then, in order to take full advantage of unlabeled datasets, we use self-supervised learning and supervised learning joint training to provide pre-trained model. Moreover, some effective data process tricks also are considered in our experiments. Last but not least, fine-tuned in downstream task with hard mining, ensambled kinds of model performance. Extensive experiments demonstrate that our method can effectively improve the performance of fine-grained recognition. Our method can achieve a macro f1 score 92.7% and 89.4% on private and public dataset, respectively, which is the 1st place among the participators on private leaderboard.
Delving into Effective Gradient Matching for Dataset Condensation
Jul 30, 2022
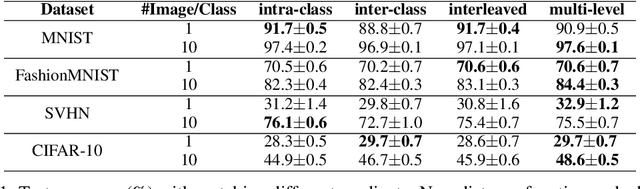
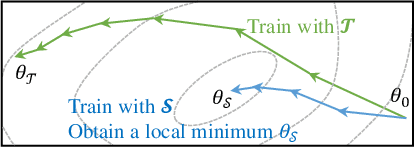

As deep learning models and datasets rapidly scale up, network training is extremely time-consuming and resource-costly. Instead of training on the entire dataset, learning with a small synthetic dataset becomes an efficient solution. Extensive research has been explored in the direction of dataset condensation, among which gradient matching achieves state-of-the-art performance. The gradient matching method directly targets the training dynamics by matching the gradient when training on the original and synthetic datasets. However, there are limited deep investigations into the principle and effectiveness of this method. In this work, we delve into the gradient matching method from a comprehensive perspective and answer the critical questions of what, how, and where to match. We propose to match the multi-level gradients to involve both intra-class and inter-class gradient information. We demonstrate that the distance function should focus on the angle, considering the magnitude simultaneously to delay the overfitting. An overfitting-aware adaptive learning step strategy is also proposed to trim unnecessary optimization steps for algorithmic efficiency improvement. Ablation and comparison experiments demonstrate that our proposed methodology shows superior accuracy, efficiency, and generalization compared to prior work.
Tackling the Score Shift in Cross-Lingual Speaker Verification by Exploiting Language Information
Oct 18, 2021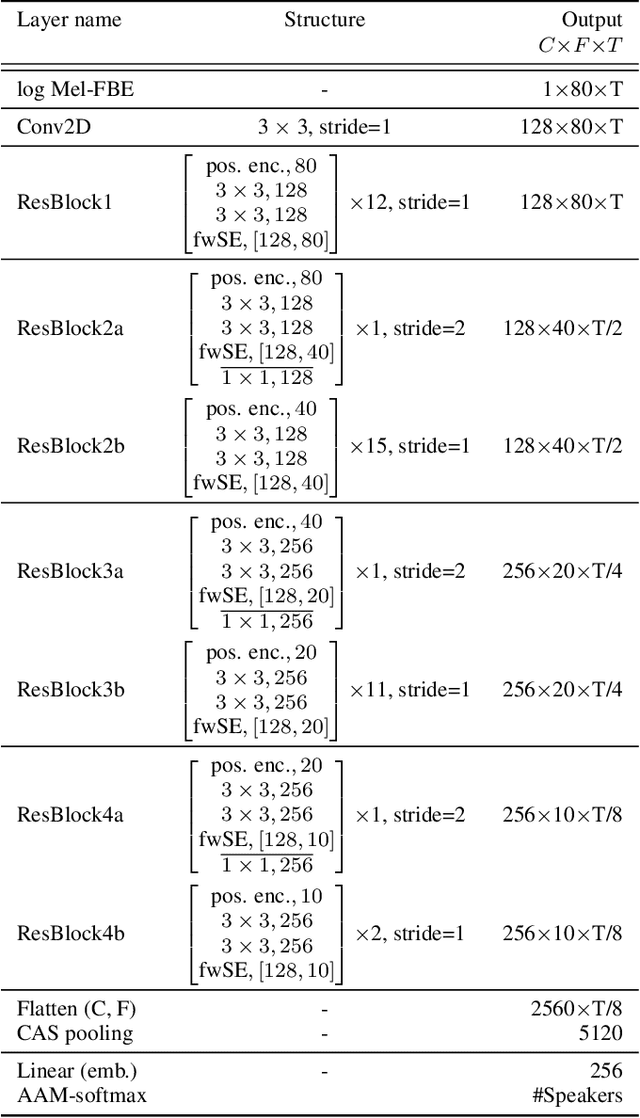
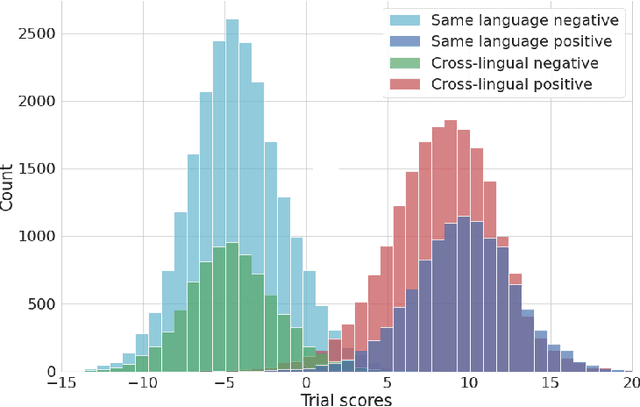
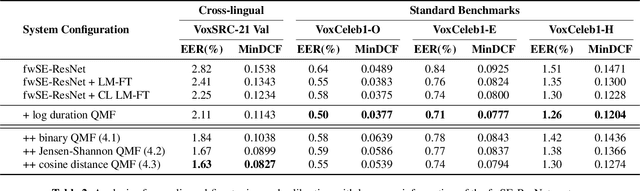
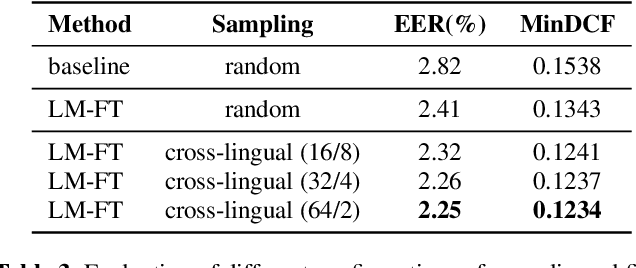
This paper contains a post-challenge performance analysis on cross-lingual speaker verification of the IDLab submission to the VoxCeleb Speaker Recognition Challenge 2021 (VoxSRC-21). We show that current speaker embedding extractors consistently underestimate speaker similarity in within-speaker cross-lingual trials. Consequently, the typical training and scoring protocols do not put enough emphasis on the compensation of intra-speaker language variability. We propose two techniques to increase cross-lingual speaker verification robustness. First, we enhance our previously proposed Large-Margin Fine-Tuning (LM-FT) training stage with a mini-batch sampling strategy which increases the amount of intra-speaker cross-lingual samples within the mini-batch. Second, we incorporate language information in the logistic regression calibration stage. We integrate quality metrics based on soft and hard decisions of a VoxLingua107 language identification model. The proposed techniques result in a 11.7% relative improvement over the baseline model on the VoxSRC-21 test set and contributed to our third place finish in the corresponding challenge.
GMML is All you Need
May 30, 2022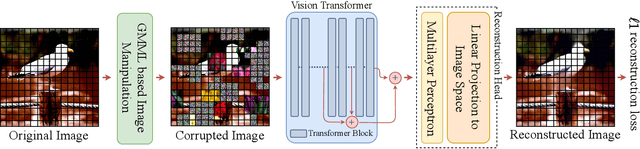
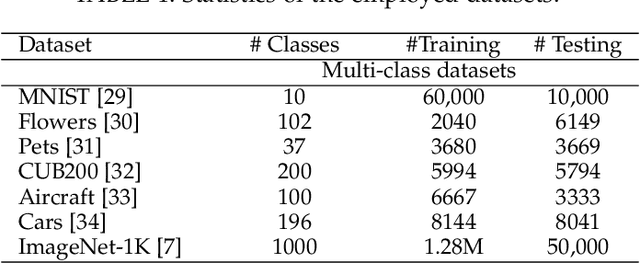
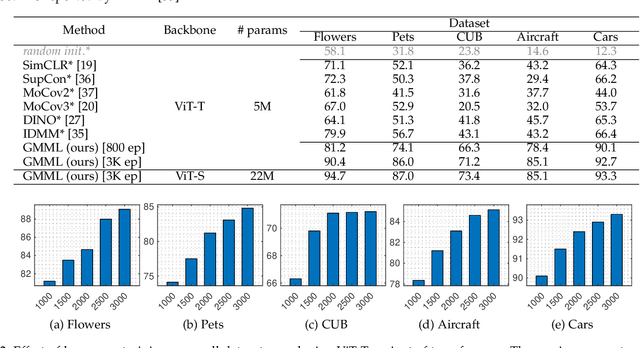
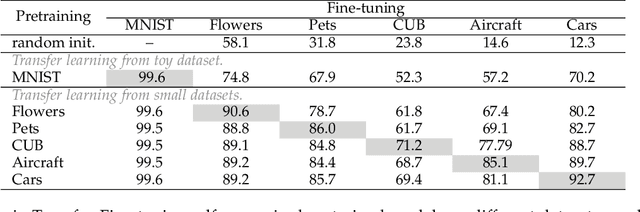
Vision transformers have generated significant interest in the computer vision community because of their flexibility in exploiting contextual information, whether it is sharply confined local, or long range global. However, they are known to be data hungry. This has motivated the research in self-supervised transformer pretraining, which does not need to decode the semantic information conveyed by labels to link it to the image properties, but rather focuses directly on extracting a concise representation of the image data that reflects the notion of similarity, and is invariant to nuisance factors. The key vehicle for the self-learning process used by the majority of self-learning methods is the generation of multiple views of the training data and the creation of pretext tasks which use these views to define the notion of image similarity, and data integrity. However, this approach lacks the natural propensity to extract contextual information. We propose group masked model learning (GMML), a self-supervised learning (SSL) mechanism for pretraining vision transformers with the ability to extract the contextual information present in all the concepts in an image. GMML achieves this by manipulating randomly groups of connected tokens, ensuingly covering a meaningful part of a semantic concept, and then recovering the hidden semantic information from the visible part of the concept. GMML implicitly introduces a novel data augmentation process. Unlike most of the existing SSL approaches, GMML does not require momentum encoder, nor rely on careful implementation details such as large batches and gradient stopping, which are all artefacts of most of the current self-supervised learning techniques. The source code is publicly available for the community to train on bigger corpora: https://github.com/Sara-Ahmed/GMML.
Speech Emotion: Investigating Model Representations, Multi-Task Learning and Knowledge Distillation
Jul 02, 2022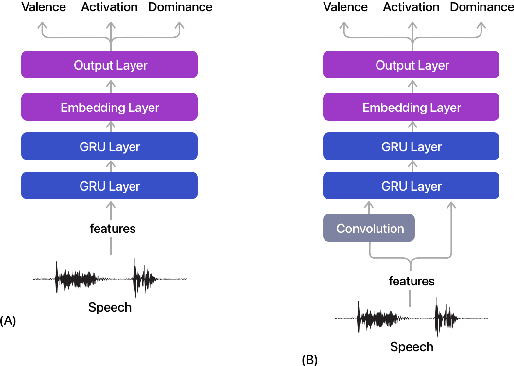
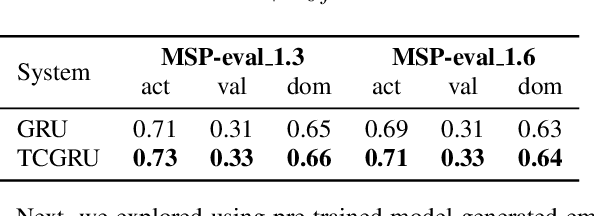
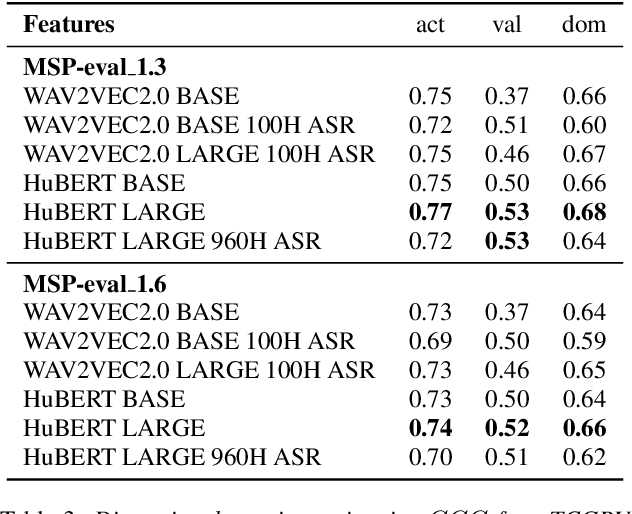
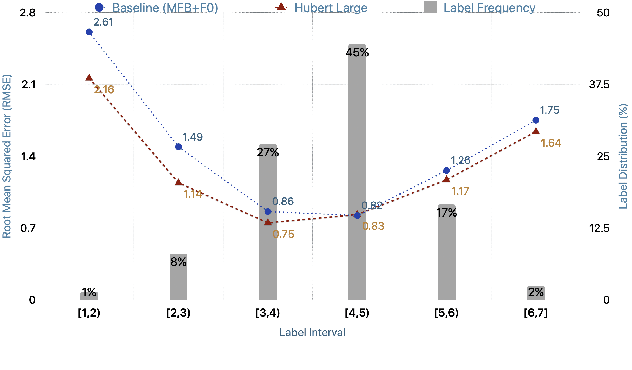
Estimating dimensional emotions, such as activation, valence and dominance, from acoustic speech signals has been widely explored over the past few years. While accurate estimation of activation and dominance from speech seem to be possible, the same for valence remains challenging. Previous research has shown that the use of lexical information can improve valence estimation performance. Lexical information can be obtained from pre-trained acoustic models, where the learned representations can improve valence estimation from speech. We investigate the use of pre-trained model representations to improve valence estimation from acoustic speech signal. We also explore fusion of representations to improve emotion estimation across all three emotion dimensions: activation, valence and dominance. Additionally, we investigate if representations from pre-trained models can be distilled into models trained with low-level features, resulting in models with a less number of parameters. We show that fusion of pre-trained model embeddings result in a 79% relative improvement in concordance correlation coefficient CCC on valence estimation compared to standard acoustic feature baseline (mel-filterbank energies), while distillation from pre-trained model embeddings to lower-dimensional representations yielded a relative 12% improvement. Such performance gains were observed over two evaluation sets, indicating that our proposed architecture generalizes across those evaluation sets. We report new state-of-the-art "text-free" acoustic-only dimensional emotion estimation $CCC$ values on two MSP-Podcast evaluation sets.
Time to augment contrastive learning
Jul 27, 2022
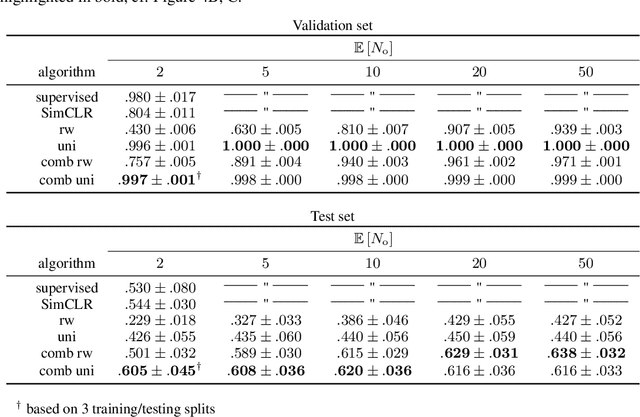

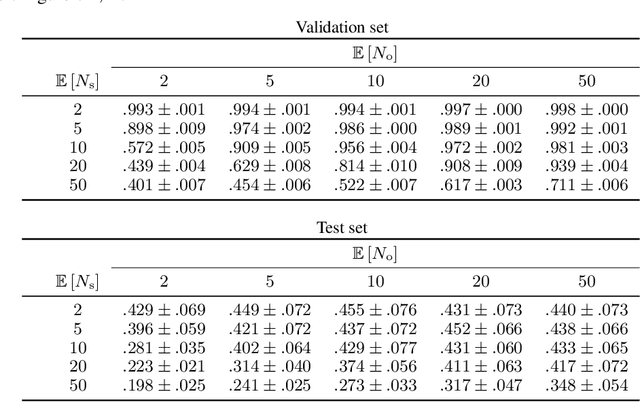
Biological vision systems are unparalleled in their ability to learn visual representations without supervision. In machine learning, contrastive learning (CL) has led to major advances in forming object representations in an unsupervised fashion. These systems learn representations invariant to augmentation operations over images, like cropping or flipping. In contrast, biological vision systems exploit the temporal structure of the visual experience. This gives access to augmentations not commonly used in CL, like watching the same object from multiple viewpoints or against different backgrounds. Here, we systematically investigate and compare the potential benefits of such time-based augmentations for learning object categories. Our results show that time-based augmentations achieve large performance gains over state-of-the-art image augmentations. Specifically, our analyses reveal that: 1) 3-D object rotations drastically improve the learning of object categories; 2) viewing objects against changing backgrounds is vital for learning to discard background-related information. Overall, we conclude that time-based augmentations can greatly improve contrastive learning, narrowing the gap between artificial and biological vision systems.