 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
D2HNet: Joint Denoising and Deblurring with Hierarchical Network for Robust Night Image Restoration
Jul 14, 2022

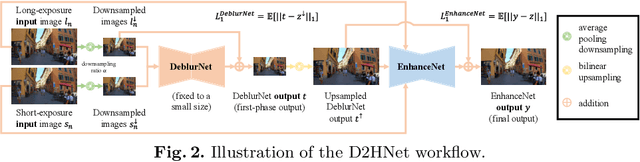
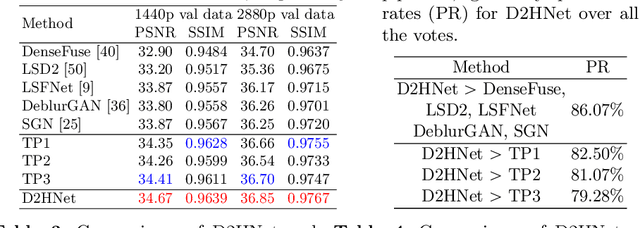
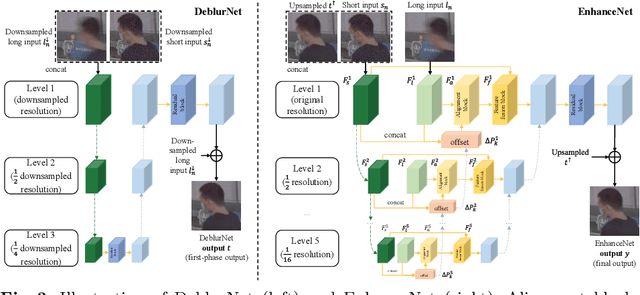
Night imaging with modern smartphone cameras is troublesome due to low photon count and unavoidable noise in the imaging system. Directly adjusting exposure time and ISO ratings cannot obtain sharp and noise-free images at the same time in low-light conditions. Though many methods have been proposed to enhance noisy or blurry night images, their performances on real-world night photos are still unsatisfactory due to two main reasons: 1) Limited information in a single image and 2) Domain gap between synthetic training images and real-world photos (e.g., differences in blur area and resolution). To exploit the information from successive long- and short-exposure images, we propose a learning-based pipeline to fuse them. A D2HNet framework is developed to recover a high-quality image by deblurring and enhancing a long-exposure image under the guidance of a short-exposure image. To shrink the domain gap, we leverage a two-phase DeblurNet-EnhanceNet architecture, which performs accurate blur removal on a fixed low resolution so that it is able to handle large ranges of blur in different resolution inputs. In addition, we synthesize a D2-Dataset from HD videos and experiment on it. The results on the validation set and real photos demonstrate our methods achieve better visual quality and state-of-the-art quantitative scores. The D2HNet codes and D2-Dataset can be found at https://github.com/zhaoyuzhi/D2HNet.
QTI Submission to DCASE 2021: residual normalization for device-imbalanced acoustic scene classification with efficient design
Jun 28, 2022
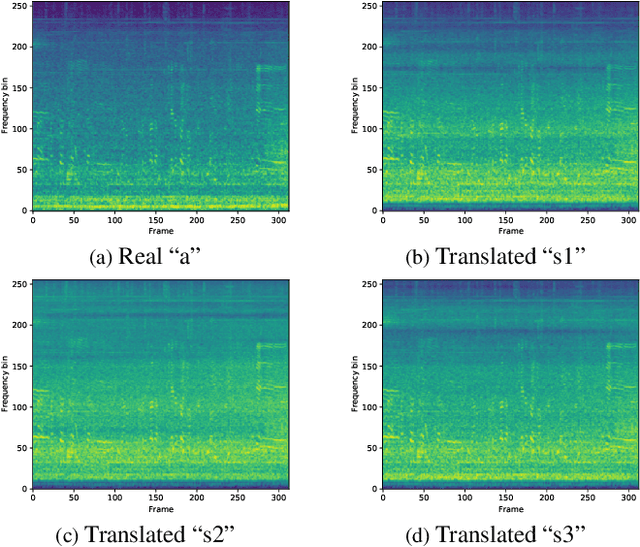
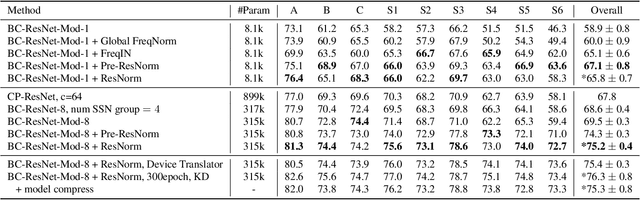
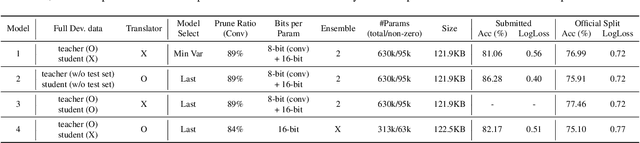
This technical report describes the details of our TASK1A submission of the DCASE2021 challenge. The goal of the task is to design an audio scene classification system for device-imbalanced datasets under the constraints of model complexity. This report introduces four methods to achieve the goal. First, we propose Residual Normalization, a novel feature normalization method that uses instance normalization with a shortcut path to discard unnecessary device-specific information without losing useful information for classification. Second, we design an efficient architecture, BC-ResNet-Mod, a modified version of the baseline architecture with a limited receptive field. Third, we exploit spectrogram-to-spectrogram translation from one to multiple devices to augment training data. Finally, we utilize three model compression schemes: pruning, quantization, and knowledge distillation to reduce model complexity. The proposed system achieves an average test accuracy of 76.3% in TAU Urban Acoustic Scenes 2020 Mobile, development dataset with 315k parameters, and average test accuracy of 75.3% after compression to 61.0KB of non-zero parameters.
Bayesian Experimental Design for Computed Tomography with the Linearised Deep Image Prior
Jul 11, 2022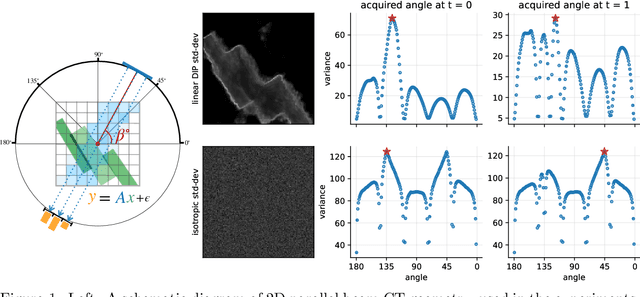

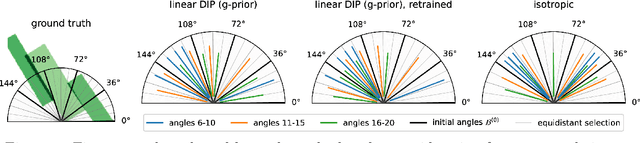

We investigate adaptive design based on a single sparse pilot scan for generating effective scanning strategies for computed tomography reconstruction. We propose a novel approach using the linearised deep image prior. It allows incorporating information from the pilot measurements into the angle selection criteria, while maintaining the tractability of a conjugate Gaussian-linear model. On a synthetically generated dataset with preferential directions, linearised DIP design allows reducing the number of scans by up to 30% relative to an equidistant angle baseline.
Neuro-symbolic computing with spiking neural networks
Aug 04, 2022
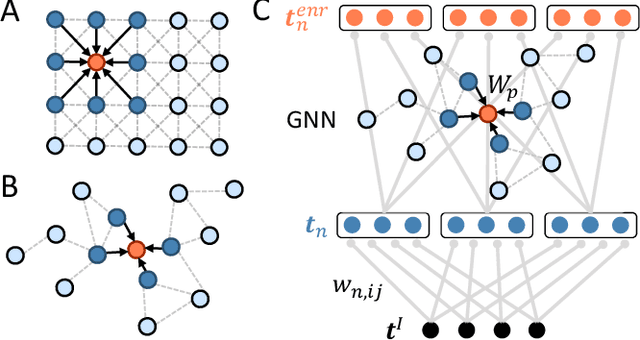
Knowledge graphs are an expressive and widely used data structure due to their ability to integrate data from different domains in a sensible and machine-readable way. Thus, they can be used to model a variety of systems such as molecules and social networks. However, it still remains an open question how symbolic reasoning could be realized in spiking systems and, therefore, how spiking neural networks could be applied to such graph data. Here, we extend previous work on spike-based graph algorithms by demonstrating how symbolic and multi-relational information can be encoded using spiking neurons, allowing reasoning over symbolic structures like knowledge graphs with spiking neural networks. The introduced framework is enabled by combining the graph embedding paradigm and the recent progress in training spiking neural networks using error backpropagation. The presented methods are applicable to a variety of spiking neuron models and can be trained end-to-end in combination with other differentiable network architectures, which we demonstrate by implementing a spiking relational graph neural network.
TractoFormer: A Novel Fiber-level Whole Brain Tractography Analysis Framework Using Spectral Embedding and Vision Transformers
Jul 11, 2022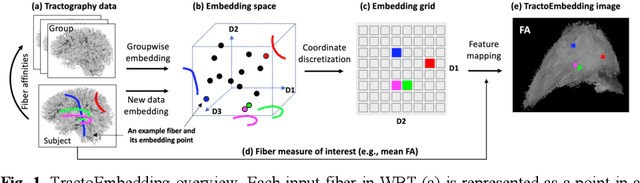
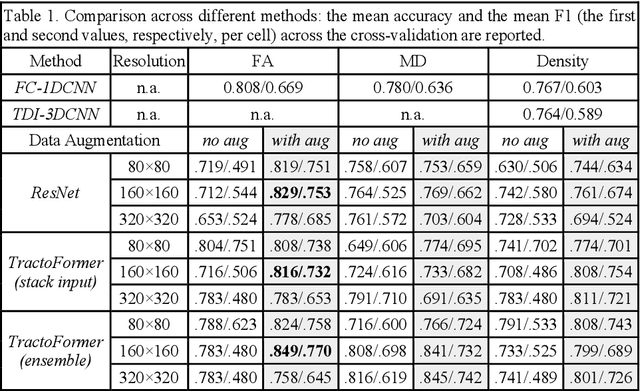
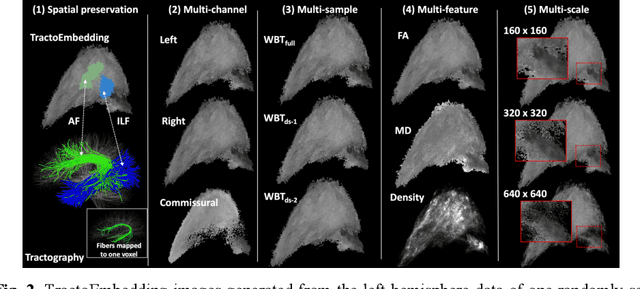
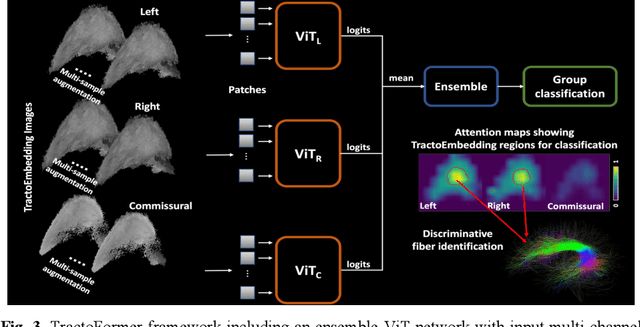
Diffusion MRI tractography is an advanced imaging technique for quantitative mapping of the brain's structural connectivity. Whole brain tractography (WBT) data contains over hundreds of thousands of individual fiber streamlines (estimated brain connections), and this data is usually parcellated to create compact representations for data analysis applications such as disease classification. In this paper, we propose a novel parcellation-free WBT analysis framework, TractoFormer, that leverages tractography information at the level of individual fiber streamlines and provides a natural mechanism for interpretation of results using the attention mechanism of transformers. TractoFormer includes two main contributions. First, we propose a novel and simple 2D image representation of WBT, TractoEmbedding, to encode 3D fiber spatial relationships and any feature of interest that can be computed from individual fibers (such as FA or MD). Second, we design a network based on vision transformers (ViTs) that includes: 1) data augmentation to overcome model overfitting on small datasets, 2) identification of discriminative fibers for interpretation of results, and 3) ensemble learning to leverage fiber information from different brain regions. In a synthetic data experiment, TractoFormer successfully identifies discriminative fibers with simulated group differences. In a disease classification experiment comparing several methods, TractoFormer achieves the highest accuracy in classifying schizophrenia vs control. Discriminative fibers are identified in left hemispheric frontal and parietal superficial white matter regions, which have previously been shown to be affected in schizophrenia patients.
A Domain Generalization Approach for Out-Of-Distribution 12-lead ECG Classification with Convolutional Neural Networks
Aug 20, 2022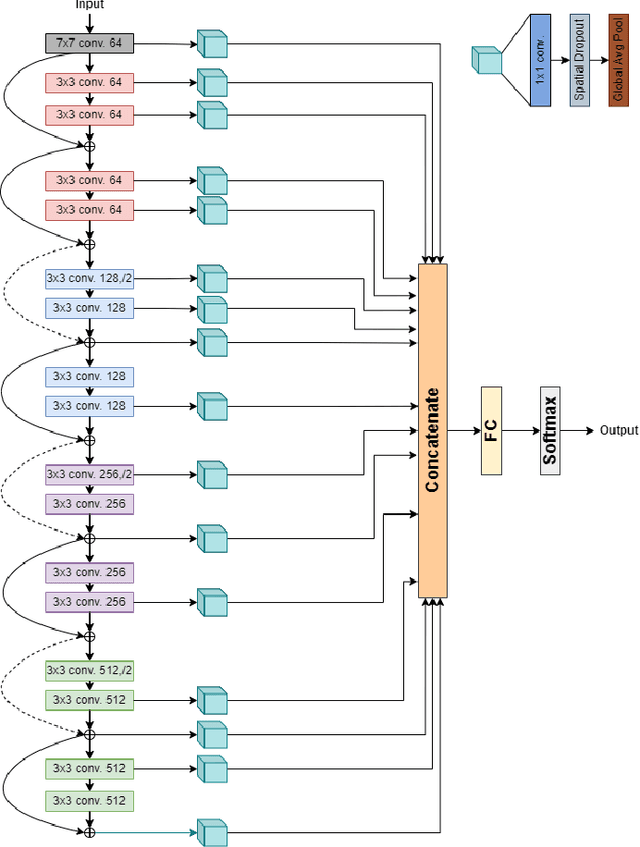
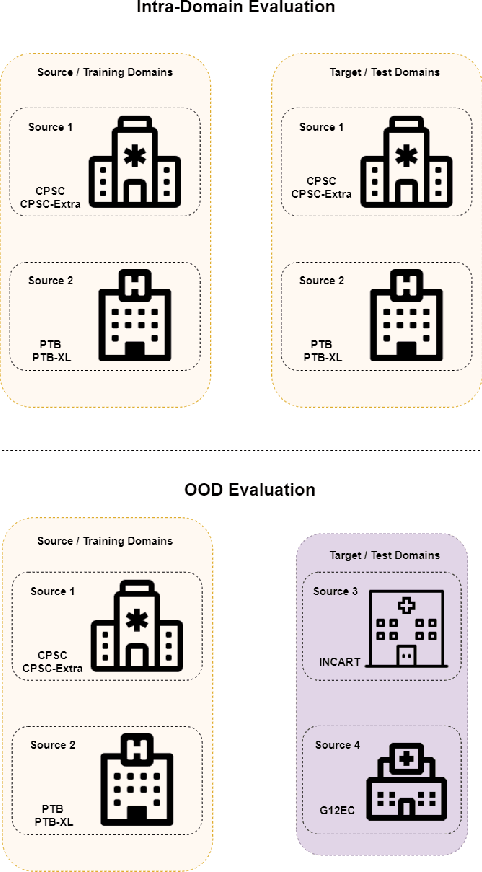
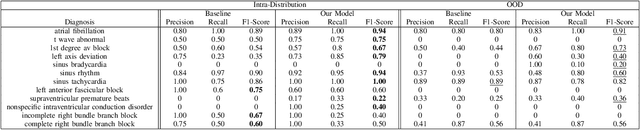
Deep Learning systems have achieved great success in the past few years, even surpassing human intelligence in several cases. As of late, they have also established themselves in the biomedical and healthcare domains, where they have shown a lot of promise, but have not yet achieved widespread adoption. This is in part due to the fact that most methods fail to maintain their performance when they are called to make decisions on data that originate from a different distribution than the one they were trained on, namely Out-Of-Distribution (OOD) data. For example, in the case of biosignal classification, models often fail to generalize well on datasets from different hospitals, due to the distribution discrepancy amongst different sources of data. Our goal is to demonstrate the Domain Generalization problem present between distinct hospital databases and propose a method that classifies abnormalities on 12-lead Electrocardiograms (ECGs), by leveraging information extracted across the architecture of a Deep Neural Network, and capturing the underlying structure of the signal. To this end, we adopt a ResNet-18 as the backbone model and extract features from several intermediate convolutional layers of the network. To evaluate our method, we adopt publicly available ECG datasets from four sources and handle them as separate domains. To simulate the distributional shift present in real-world settings, we train our model on a subset of the domains and leave-out the remaining ones. We then evaluate our model both on the data present at training time (intra-distribution) and the held-out data (out-of-distribution), achieving promising results and surpassing the baseline of a vanilla Residual Network in most of the cases.
Is neural language acquisition similar to natural? A chronological probing study
Jul 01, 2022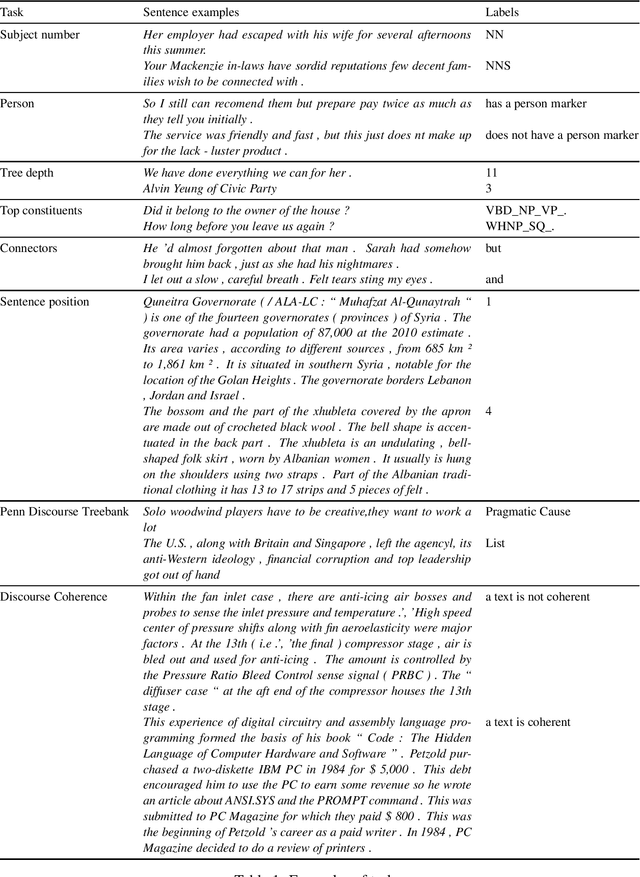
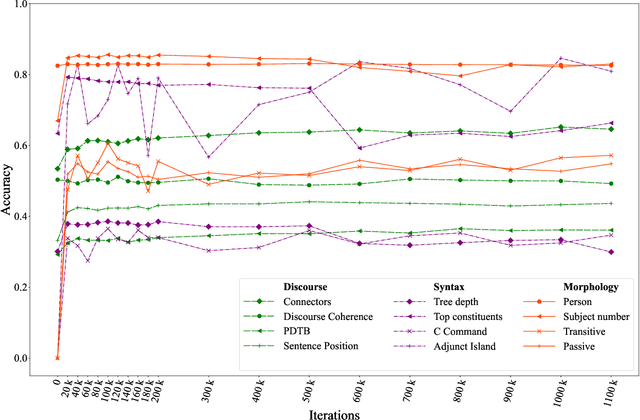

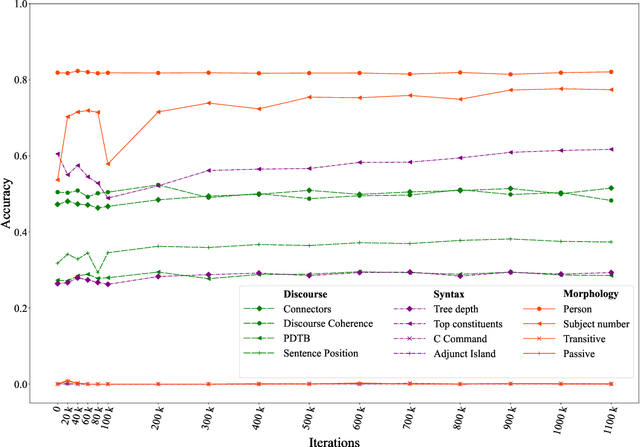
The probing methodology allows one to obtain a partial representation of linguistic phenomena stored in the inner layers of the neural network, using external classifiers and statistical analysis. Pre-trained transformer-based language models are widely used both for natural language understanding (NLU) and natural language generation (NLG) tasks making them most commonly used for downstream applications. However, little analysis was carried out, whether the models were pre-trained enough or contained knowledge correlated with linguistic theory. We are presenting the chronological probing study of transformer English models such as MultiBERT and T5. We sequentially compare the information about the language learned by the models in the process of training on corpora. The results show that 1) linguistic information is acquired in the early stages of training 2) both language models demonstrate capabilities to capture various features from various levels of language, including morphology, syntax, and even discourse, while they also can inconsistently fail on tasks that are perceived as easy. We also introduce the open-source framework for chronological probing research, compatible with other transformer-based models. https://github.com/EkaterinaVoloshina/chronological_probing
Fine-Grained Semantically Aligned Vision-Language Pre-Training
Aug 04, 2022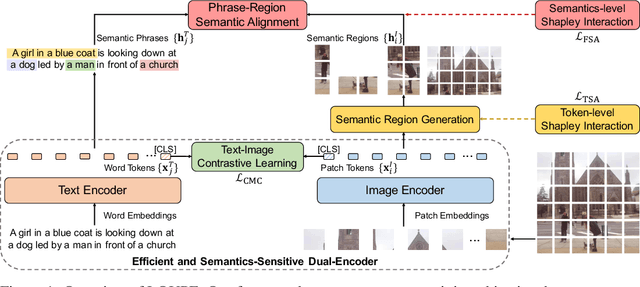
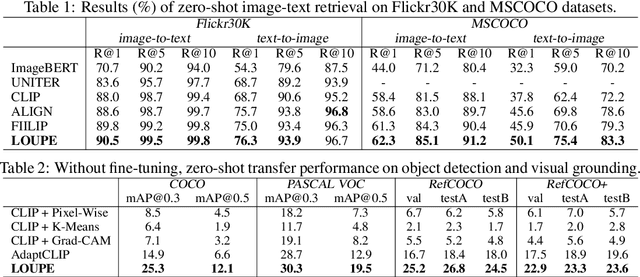
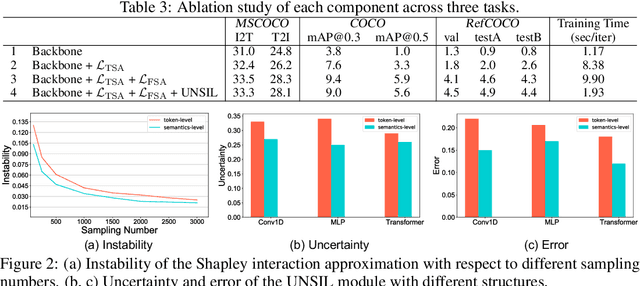

Large-scale vision-language pre-training has shown impressive advances in a wide range of downstream tasks. Existing methods mainly model the cross-modal alignment by the similarity of the global representations of images and texts, or advanced cross-modal attention upon image and text features. However, they fail to explicitly learn the fine-grained semantic alignment between visual regions and textual phrases, as only global image-text alignment information is available. In this paper, we introduce LOUPE, a fine-grained semantically aLigned visiOn-langUage PrE-training framework, which learns fine-grained semantic alignment from the novel perspective of game-theoretic interactions. To efficiently compute the game-theoretic interactions, we further propose an uncertainty-aware neural Shapley interaction learning module. Experiments show that LOUPE achieves state-of-the-art on image-text retrieval benchmarks. Without any object-level human annotations and fine-tuning, LOUPE achieves competitive performance on object detection and visual grounding. More importantly, LOUPE opens a new promising direction of learning fine-grained semantics from large-scale raw image-text pairs.
Optimal Tracking in Prediction with Expert Advice
Aug 07, 2022We study the prediction with expert advice setting, where the aim is to produce a decision by combining the decisions generated by a set of experts, e.g., independently running algorithms. We achieve the min-max optimal dynamic regret under the prediction with expert advice setting, i.e., we can compete against time-varying (not necessarily fixed) combinations of expert decisions in an optimal manner. Our end-algorithm is truly online with no prior information, such as the time horizon or loss ranges, which are commonly used by different algorithms in the literature. Both our regret guarantees and the min-max lower bounds are derived with the general consideration that the expert losses can have time-varying properties and are possibly unbounded. Our algorithm can be adapted for restrictive scenarios regarding both loss feedback and decision making. Our guarantees are universal, i.e., our end-algorithm can provide regret guarantee against any competitor sequence in a min-max optimal manner with logarithmic complexity. Note that, to our knowledge, for the prediction with expert advice problem, our algorithms are the first to produce such universally optimal, adaptive and truly online guarantees with no prior knowledge.
AutoSpeed: A Linked Autoencoder Approach for Pulse-Echo Speed-of-Sound Imaging for Medical Ultrasound
Jul 04, 2022
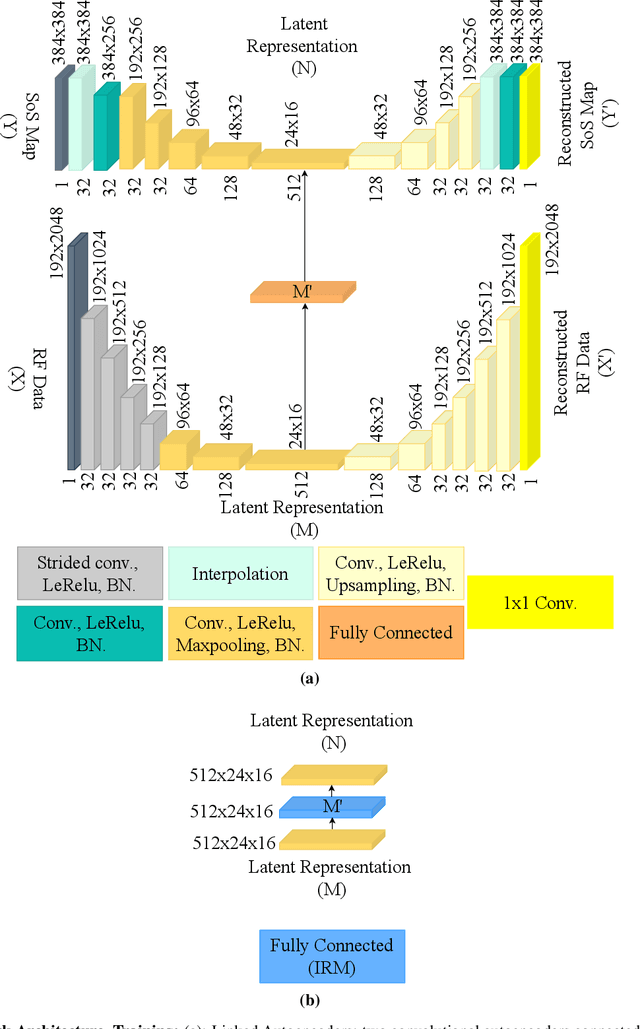
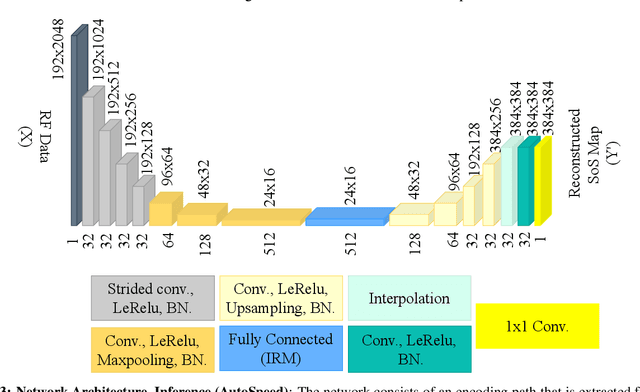
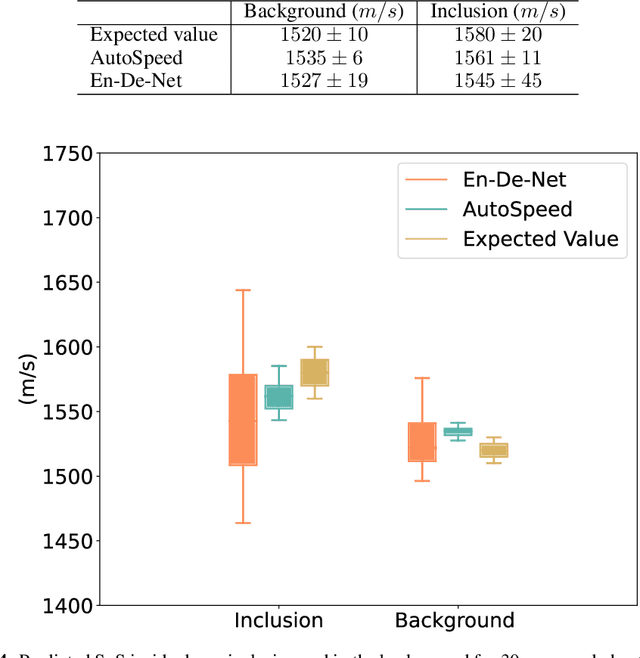
Quantitative ultrasound, e.g., speed-of-sound (SoS) in tissues, provides information about tissue properties that have diagnostic value. Recent studies showed the possibility of extracting SoS information from pulse-echo ultrasound raw data (a.k.a. RF data) using deep neural networks that are fully trained on simulated data. These methods take sensor domain data, i.e., RF data, as input and train a network in an end-to-end fashion to learn the implicit mapping between the RF data domain and SoS domain. However, such networks are prone to overfitting to simulated data which results in poor performance and instability when tested on measured data. We propose a novel method for SoS mapping employing learned representations from two linked autoencoders. We test our approach on simulated and measured data acquired from human breast mimicking phantoms. We show that SoS mapping is possible using linked autoencoders. The proposed method has a Mean Absolute Percentage Error (MAPE) of 2.39% on the simulated data. On the measured data, the predictions of the proposed method are close to the expected values with MAPE of 1.1%. Compared to an end-to-end trained network, the proposed method shows higher stability and reproducibility.