 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Weight Set Decomposition for Weighted Rank Aggregation: An interpretable and visual decision support tool
May 31, 2022
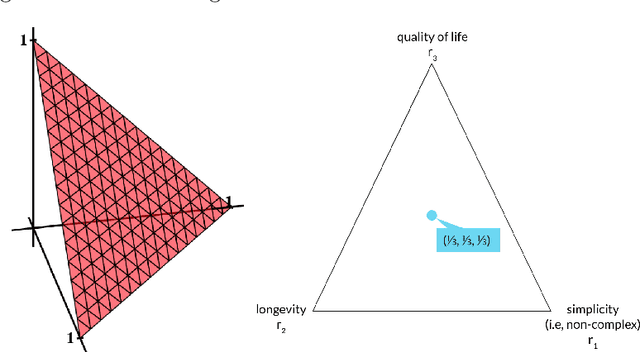
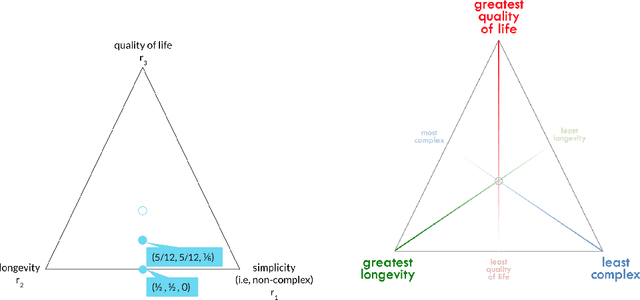
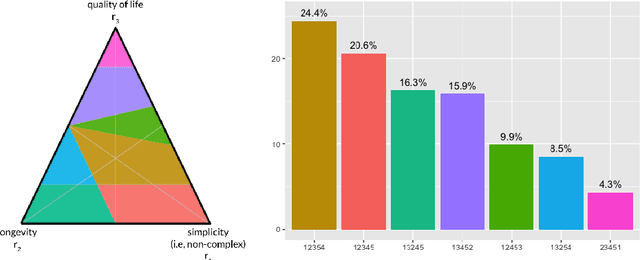
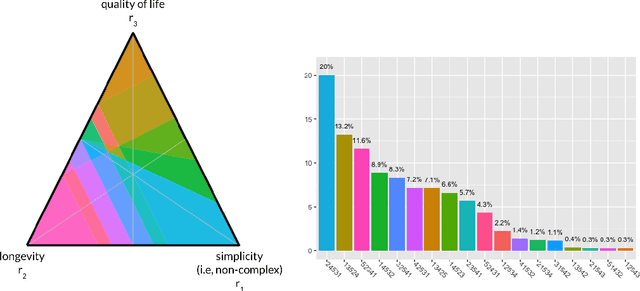
The problem of interpreting or aggregating multiple rankings is common to many real-world applications. Perhaps the simplest and most common approach is a weighted rank aggregation, wherein a (convex) weight is applied to each input ranking and then ordered. This paper describes a new tool for visualizing and displaying ranking information for the weighted rank aggregation method. Traditionally, the aim of rank aggregation is to summarize the information from the input rankings and provide one final ranking that hopefully represents a more accurate or truthful result than any one input ranking. While such an aggregated ranking is, and clearly has been, useful to many applications, it also obscures information. In this paper, we show the wealth of information that is available for the weighted rank aggregation problem due to its structure. We apply weight set decomposition to the set of convex multipliers, study the properties useful for understanding this decomposition, and visualize the indifference regions. This methodology reveals information--that is otherwise collapsed by the aggregated ranking--into a useful, interpretable, and intuitive decision support tool. Included are multiple illustrative examples, along with heuristic and exact algorithms for computing the weight set decomposition.
EICO: Energy-Harvesting Long-Range Environmental Sensor Nodes with Energy-Information Dynamic Co-Optimization
Jul 15, 2021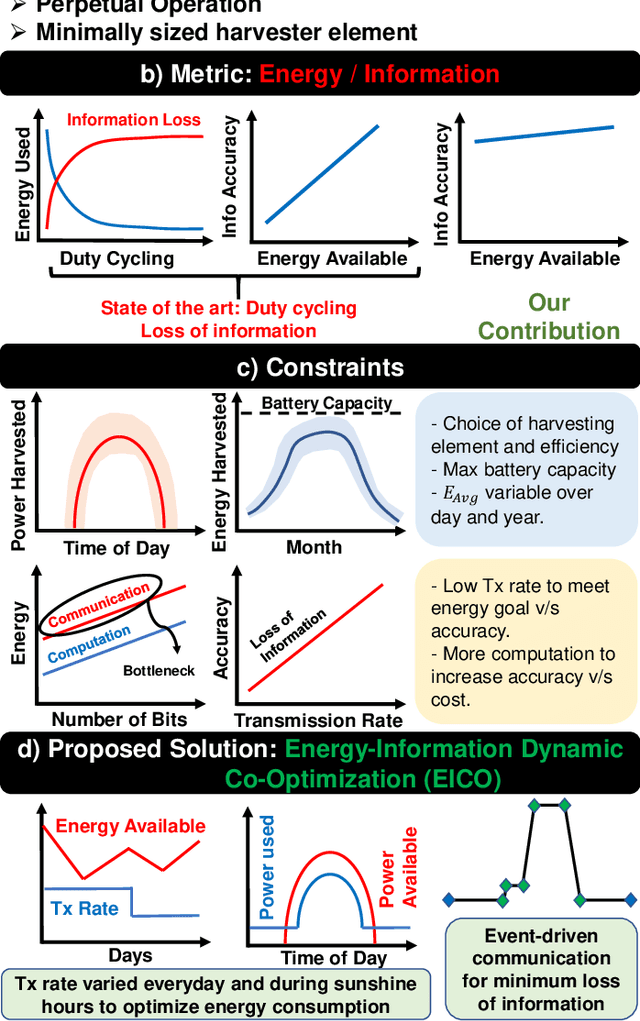
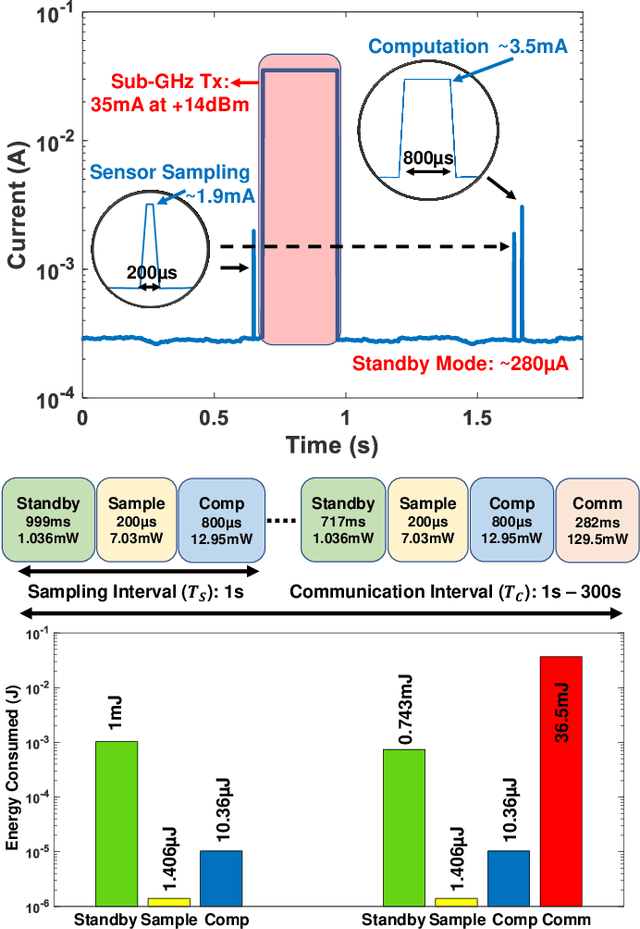
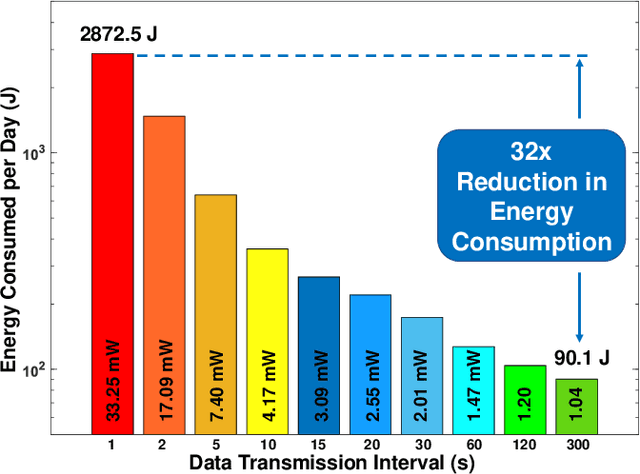
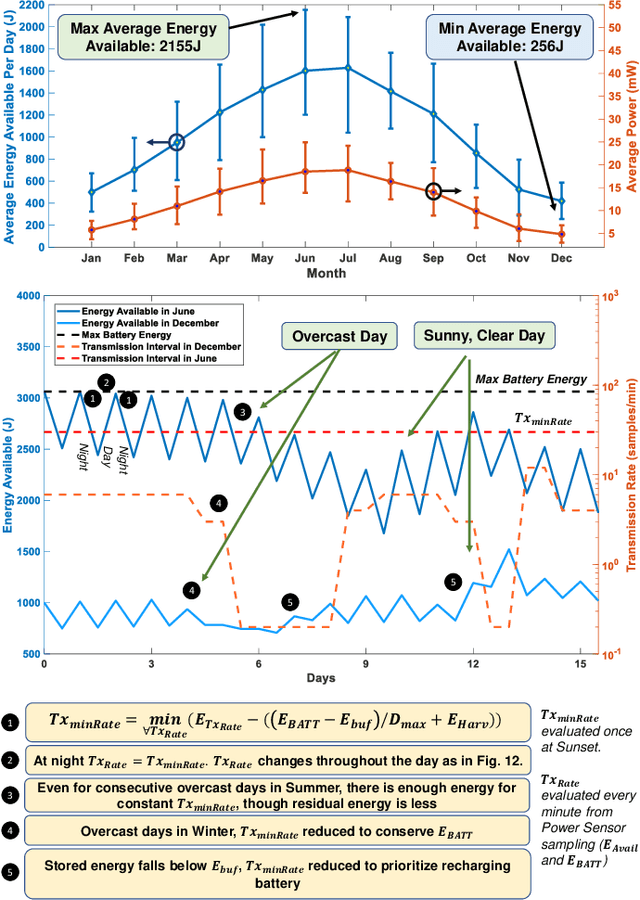
Intensive research on energy harvested sensor nodes with traditional battery powered devices has been driven by the challenges in achieving the stringent design goals of battery lifetime, information accuracy, transmission distance, and cost. This challenge is further amplified by the inherent power intensive nature of long-range communication when sensor networks are required to span vast areas such as agricultural fields and remote terrain. Solar power is a common energy source is wireless sensor nodes, however, it is not reliable due to fluctuations in power stemming from the changing seasons and weather conditions. This paper tackles these issues by presenting a perpetually-powered, energy-harvesting sensor node which utilizes a minimally sized solar cell and is capable of long range communication by dynamically co-optimizing energy consumption and information transfer, termed as Energy-Information Dynamic Co-Optimization (EICO). This energy-information intelligence is achieved by adaptive duty cycling of information transfer based on the total amount of energy available from the harvester and charge storage element to optimize the energy consumption of the sensor node, while employing in-sensor analytics (ISA) to minimize loss of information. This is the first reported sensor node < 35cm2 in dimension, which is capable of long-range communication over > 1Km at continuous information transfer rates of upto 1 packet/second which is enabled by EICO and ISA.
Statistical Properties of the log-cosh Loss Function Used in Machine Learning
Aug 12, 2022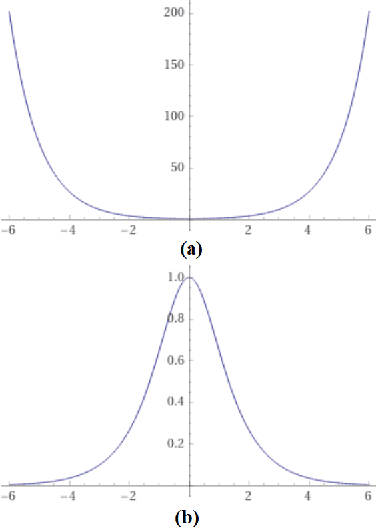
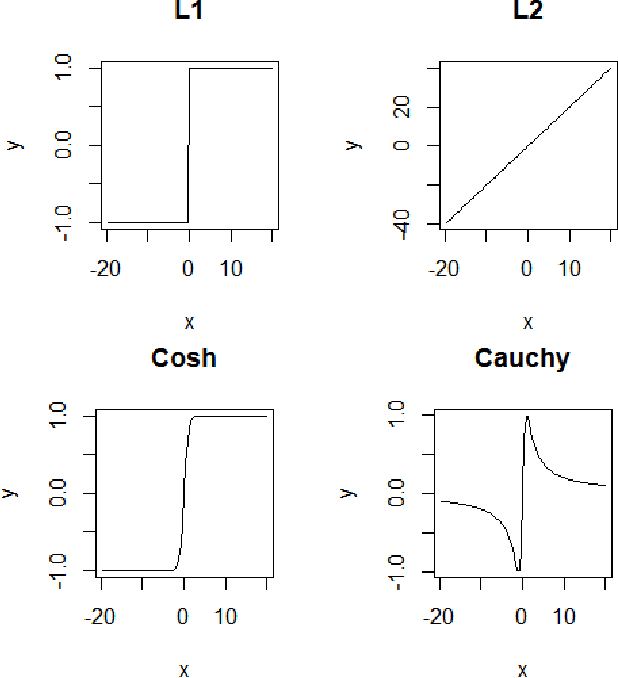
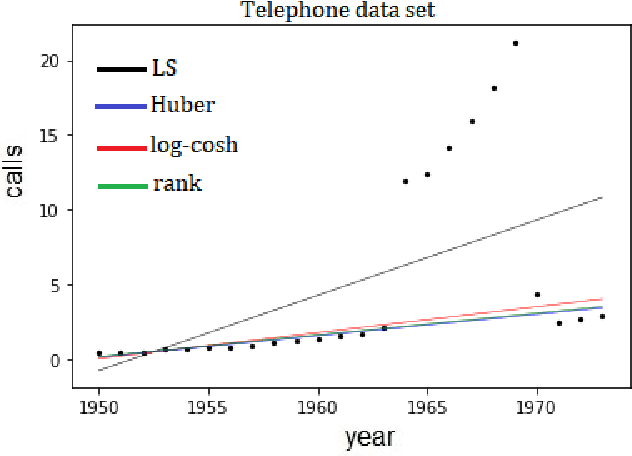
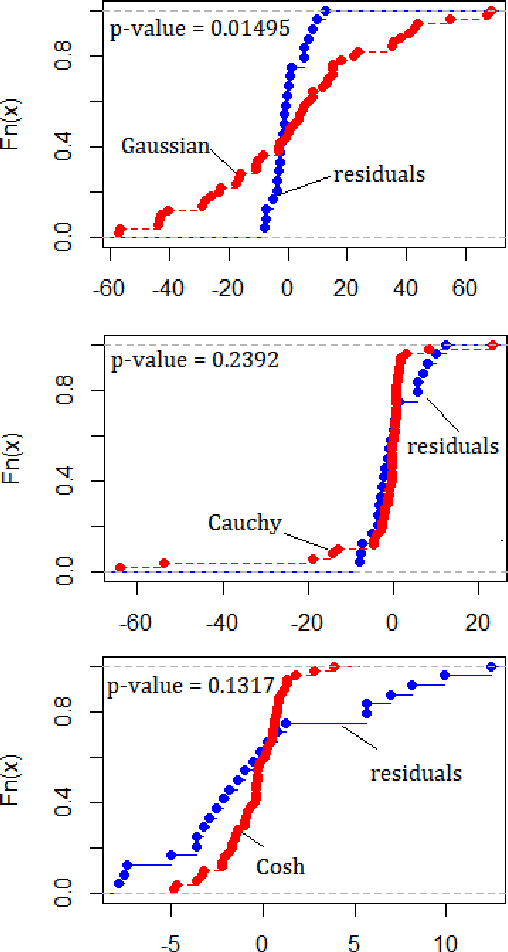
This paper analyzes a popular loss function used in machine learning called the log-cosh loss function. A number of papers have been published using this loss function but, to date, no statistical analysis has been presented in the literature. In this paper, we present the distribution function from which the log-cosh loss arises. We compare it to a similar distribution, called the Cauchy distribution, and carry out various statistical procedures that characterize its properties. In particular, we examine its associated pdf, cdf, likelihood function and Fisher information. Side-by-side we consider the Cauchy and Cosh distributions as well as the MLE of the location parameter with asymptotic bias, asymptotic variance, and confidence intervals. We also provide a comparison of robust estimators from several other loss functions, including the Huber loss function and the rank dispersion function. Further, we examine the use of the log-cosh function for quantile regression. In particular, we identify a quantile distribution function from which a maximum likelihood estimator for quantile regression can be derived. Finally, we compare a quantile M-estimator based on log-cosh with robust monotonicity against another approach to quantile regression based on convolutional smoothing.
ARIEL: Adversarial Graph Contrastive Learning
Aug 15, 2022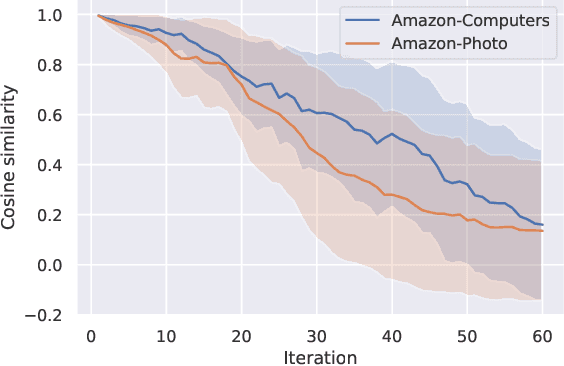
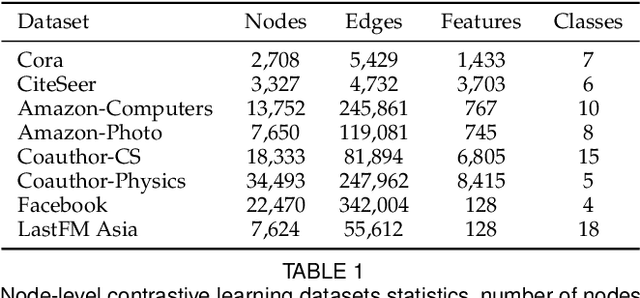
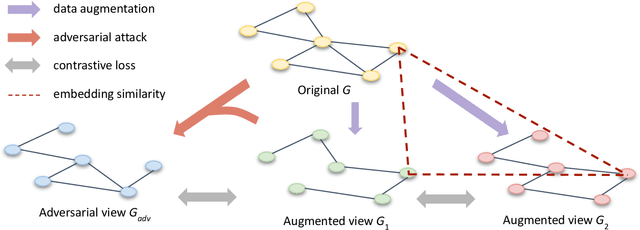
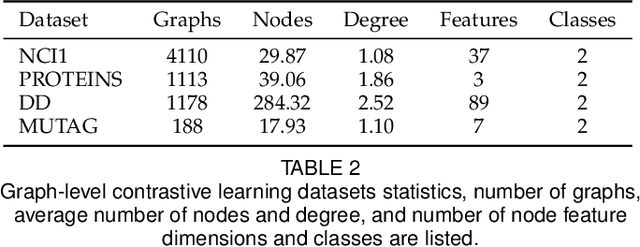
Contrastive learning is an effective unsupervised method in graph representation learning, and the key component of contrastive learning lies in the construction of positive and negative samples. Previous methods usually utilize the proximity of nodes in the graph as the principle. Recently, the data augmentation based contrastive learning method has advanced to show great power in the visual domain, and some works extended this method from images to graphs. However, unlike the data augmentation on images, the data augmentation on graphs is far less intuitive and much harder to provide high-quality contrastive samples, which leaves much space for improvement. In this work, by introducing an adversarial graph view for data augmentation, we propose a simple but effective method, Adversarial Graph Contrastive Learning (ARIEL), to extract informative contrastive samples within reasonable constraints. We develop a new technique called information regularization for stable training and use subgraph sampling for scalability. We generalize our method from node-level contrastive learning to the graph-level by treating each graph instance as a supernode. ARIEL consistently outperforms the current graph contrastive learning methods for both node-level and graph-level classification tasks on real-world datasets. We further demonstrate that ARIEL is more robust in face of adversarial attacks.
A Graph Isomorphism Network with Weighted Multiple Aggregators for Speech Emotion Recognition
Jul 03, 2022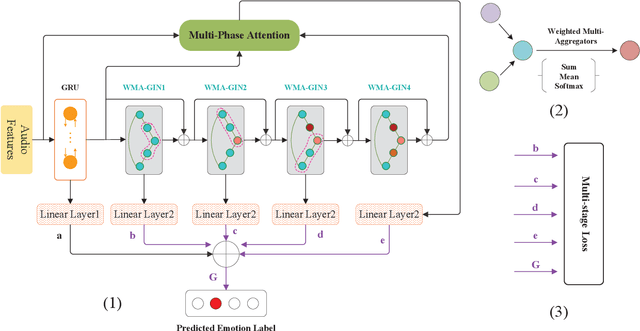

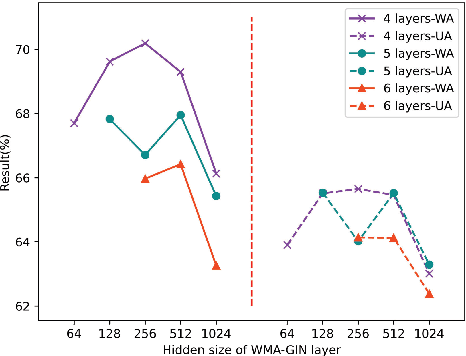
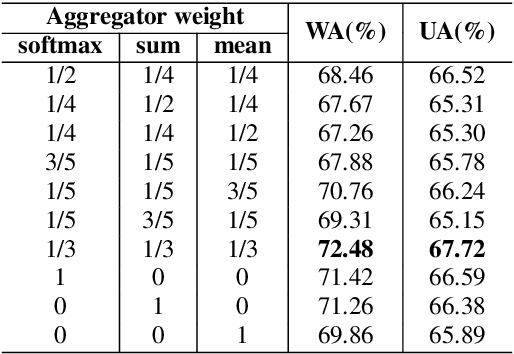
Speech emotion recognition (SER) is an essential part of human-computer interaction. In this paper, we propose an SER network based on a Graph Isomorphism Network with Weighted Multiple Aggregators (WMA-GIN), which can effectively handle the problem of information confusion when neighbour nodes' features are aggregated together in GIN structure. Moreover, a Full-Adjacent (FA) layer is adopted for alleviating the over-squashing problem, which is existed in all Graph Neural Network (GNN) structures, including GIN. Furthermore, a multi-phase attention mechanism and multi-loss training strategy are employed to avoid missing the useful emotional information in the stacked WMA-GIN layers. We evaluated the performance of our proposed WMA-GIN on the popular IEMOCAP dataset. The experimental results show that WMA-GIN outperforms other GNN-based methods and is comparable to some advanced non-graph-based methods by achieving 72.48% of weighted accuracy (WA) and 67.72% of unweighted accuracy (UA).
AntCritic: Argument Mining for Free-Form and Visually-Rich Financial Comments
Aug 20, 2022
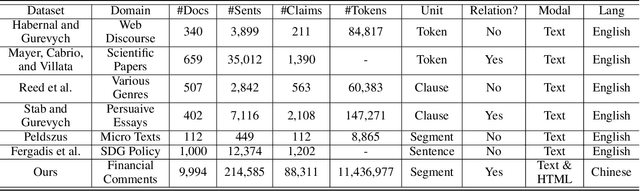
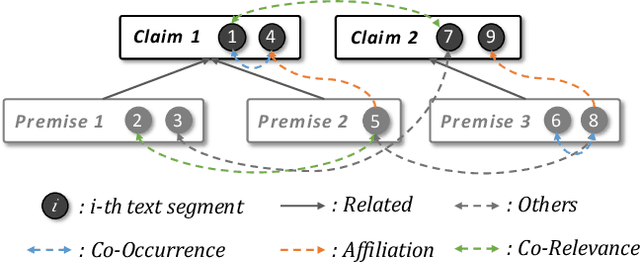
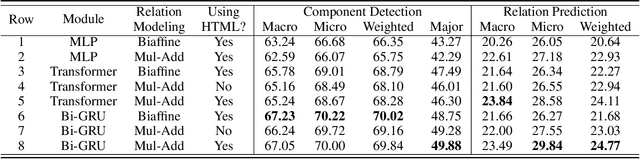
The task of argument mining aims to detect all possible argumentative components and identify their relationships automatically. As a thriving field in natural language processing, there has been a large amount of corpus for academic study and application development in argument mining. However, the research in this area is still constrained by the inherent limitations of existing datasets. Specifically, all the publicly available datasets are relatively small in scale, and few of them provide information from other modalities to facilitate the learning process. Moreover, the statements and expressions in these corpora are usually in a compact form, which means non-adjacent clauses or text segments will always be regarded as multiple individual components, thus restricting the generalization ability of models. To this end, we collect and contribute a novel dataset AntCritic to serve as a helpful complement to this area, which consists of about 10k free-form and visually-rich financial comments and supports both argument component detection and argument relation prediction tasks. Besides, in order to cope with the challenges and difficulties brought by scenario expansion and problem setting modification, we thoroughly explore the fine-grained relation prediction and structure reconstruction scheme for free-form documents and discuss the encoding mechanism for visual styles and layouts. And based on these analyses, we design two simple but effective model architectures and conduct various experiments on this dataset to provide benchmark performances as a reference and verify the practicability of our proposed architecture.
Automated Translation of Rebar Information from GPR Data into As-Built BIM: A Deep Learning-based Approach
Oct 28, 2021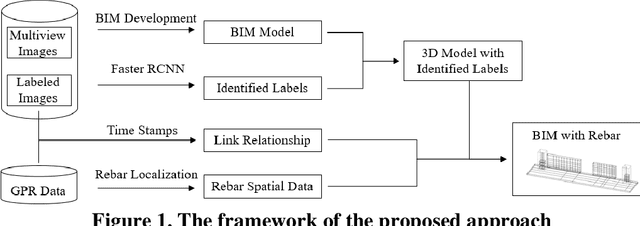

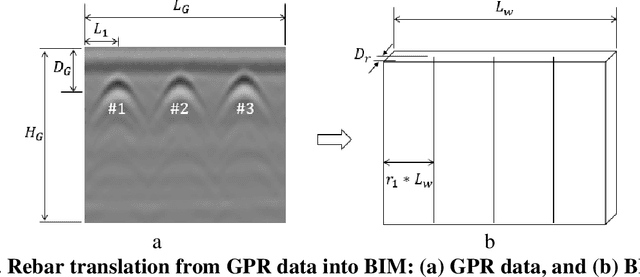

Building Information Modeling (BIM) is increasingly used in the construction industry, but existing studies often ignore embedded rebars. Ground Penetrating Radar (GPR) provides a potential solution to develop as-built BIM with surface elements and rebars. However, automatically translating rebars from GPR into BIM is challenging since GPR cannot provide any information about the scanned element. Thus, we propose an approach to link GPR data and BIM according to Faster R-CNN. A label is attached to each element scanned by GPR for capturing the labeled images, which are used with other images to build a 3D model. Meanwhile, Faster R-CNN is introduced to identify the labels, and the projection relationship between images and the model is used to localize the scanned elements in the 3D model. Two concrete buildings is selected to evaluate the proposed approach, and the results reveal that our method could accurately translate the rebars from GPR data into corresponding elements in BIM with correct distributions.
Supervised and Reinforcement Learning from Observations in Reconnaissance Blind Chess
Aug 03, 2022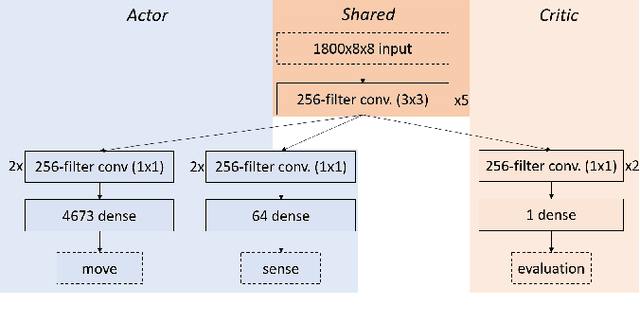
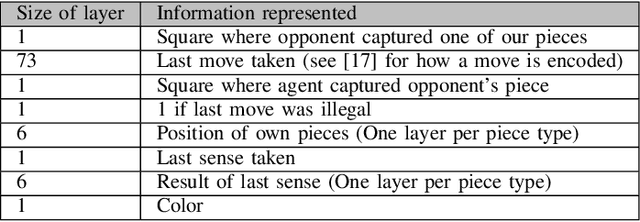
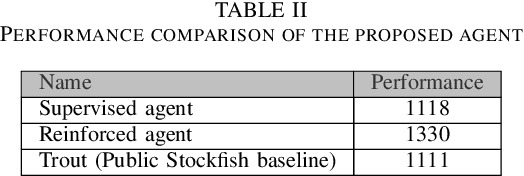
In this work, we adapt a training approach inspired by the original AlphaGo system to play the imperfect information game of Reconnaissance Blind Chess. Using only the observations instead of a full description of the game state, we first train a supervised agent on publicly available game records. Next, we increase the performance of the agent through self-play with the on-policy reinforcement learning algorithm Proximal Policy Optimization. We do not use any search to avoid problems caused by the partial observability of game states and only use the policy network to generate moves when playing. With this approach, we achieve an ELO of 1330 on the RBC leaderboard, which places our agent at position 27 at the time of this writing. We see that self-play significantly improves performance and that the agent plays acceptably well without search and without making assumptions about the true game state.
Gradient-based Uncertainty for Monocular Depth Estimation
Aug 03, 2022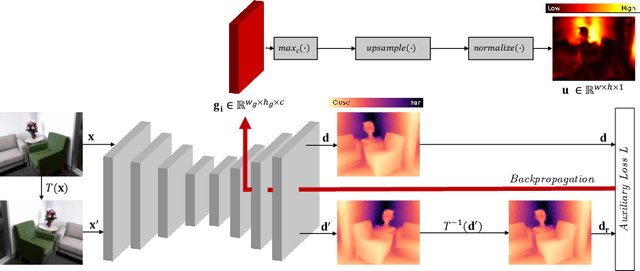
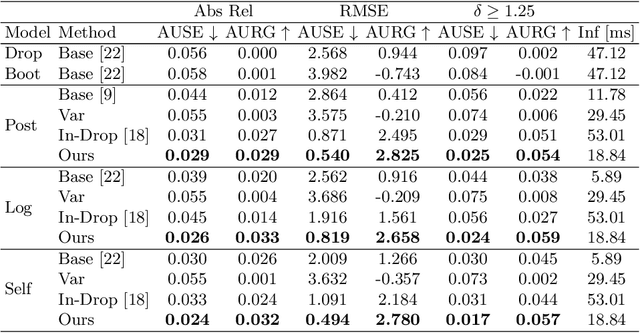
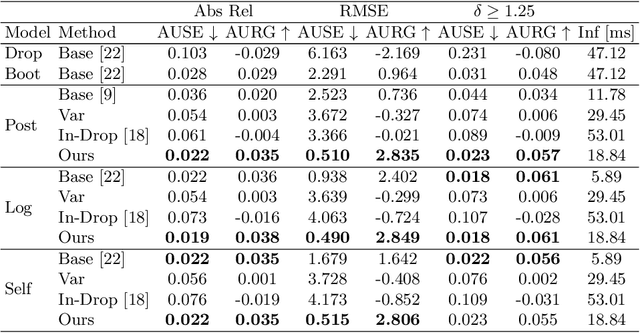
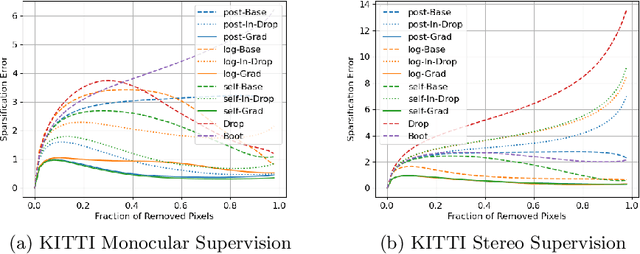
In monocular depth estimation, disturbances in the image context, like moving objects or reflecting materials, can easily lead to erroneous predictions. For that reason, uncertainty estimates for each pixel are necessary, in particular for safety-critical applications such as automated driving. We propose a post hoc uncertainty estimation approach for an already trained and thus fixed depth estimation model, represented by a deep neural network. The uncertainty is estimated with the gradients which are extracted with an auxiliary loss function. To avoid relying on ground-truth information for the loss definition, we present an auxiliary loss function based on the correspondence of the depth prediction for an image and its horizontally flipped counterpart. Our approach achieves state-of-the-art uncertainty estimation results on the KITTI and NYU Depth V2 benchmarks without the need to retrain the neural network. Models and code are publicly available at https://github.com/jhornauer/GrUMoDepth.
Reconfigurable Intelligent Surface-aided $M$-ary FM-DCSK System: a New Design for Noncoherent Chaos-based Communication
Jun 16, 2022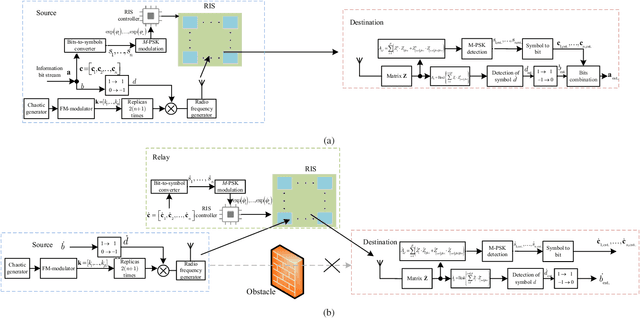
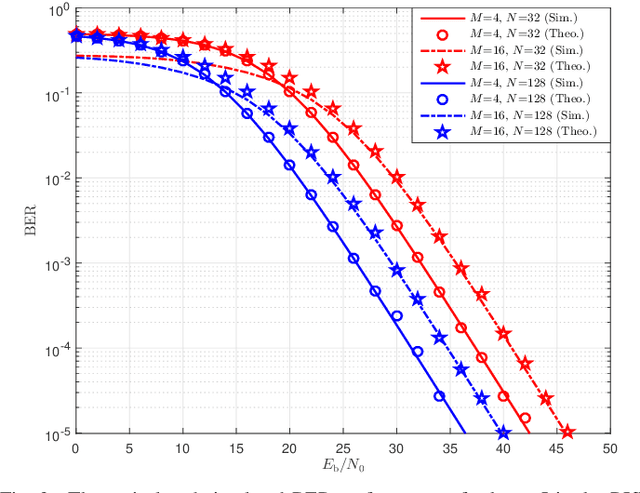
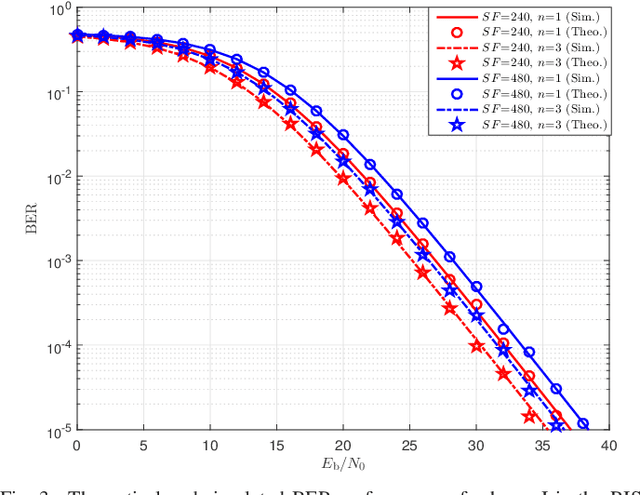
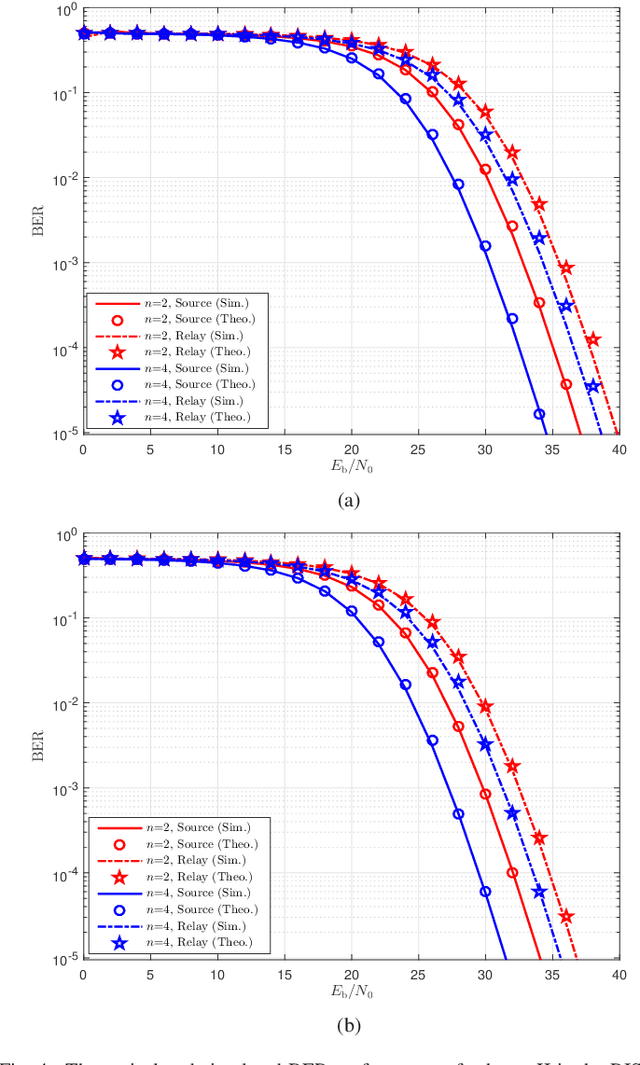
In this paper, we propose two reconfigurable intelligent surface-aided $M$-ary frequency-modulated differential chaos shift keying (RIS-$M$-FM-DCSK) schemes. In scheme I, the RIS is regarded as a transmitter at the source to incorporate the $M$-ary phase-shift-keying ($M$-PSK) symbols into the FM chaotic signal and to reflect the resultant $M$-ary FM chaotic signal toward the destination. The information bits of the source are carried by both the positive/negative state of the FM chaotic signal and the $M$-PSK symbols. In scheme II, the RIS is treated as a relay so that both the source and relay can simultaneously transmit their information bits to the destination. The information bits of the source and relay are carried by the positive/negative state of the FM chaotic signal and $M$-PSK symbols generated by the RIS, respectively. The proposed RIS-$M$-FM-DCSK system has an attractive advantage that it does not require channel state information for detection, thus avoiding complex channel estimation. Moreover, we derive the theoretical expressions for bit error rates (BERs) of the proposed RIS-$M$-FM-DCSK system with both scheme I and scheme II over multipath Rayleigh fading channels. Simulations results not only verify the accuracy of the theoretical derivations, but also demonstrate the superiority of the proposed system. The proposed RIS-$M$-FM-DCSK system is a promising low-cost, low-power, and high-reliability alternative for wireless communication networks.