 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Properties of the log-cosh Loss Function Used in Machine Learning
Aug 12, 2022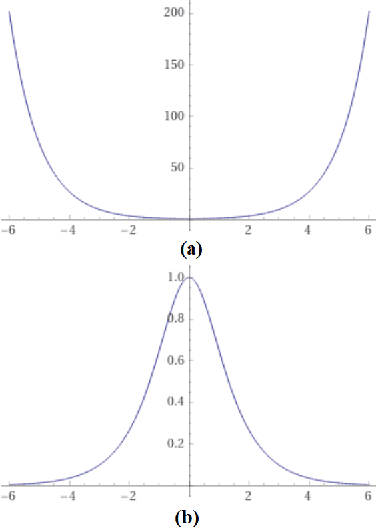
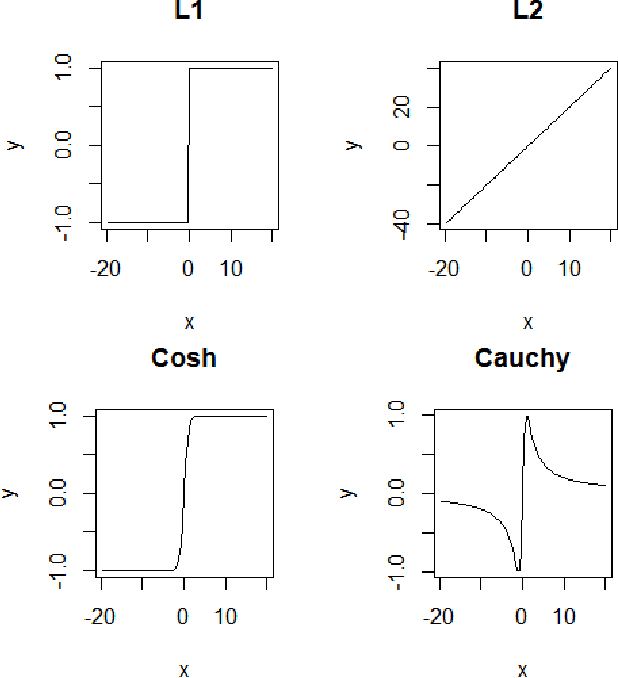
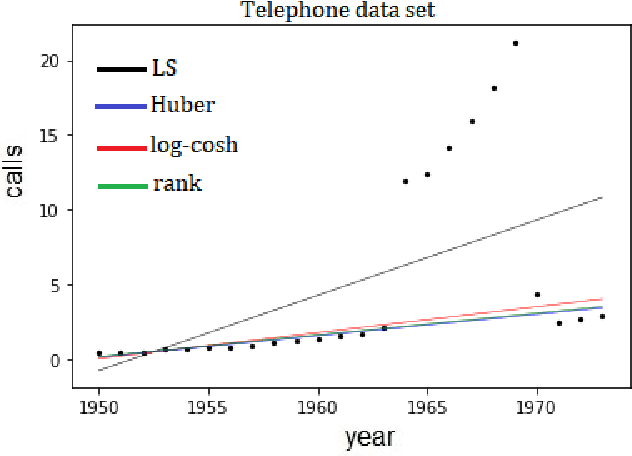
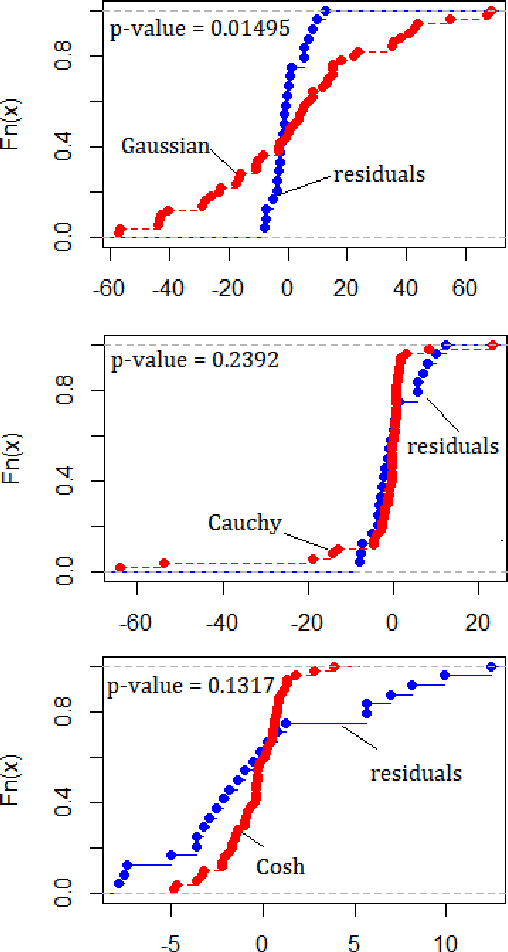
This paper analyzes a popular loss function used in machine learning called the log-cosh loss function. A number of papers have been published using this loss function but, to date, no statistical analysis has been presented in the literature. In this paper, we present the distribution function from which the log-cosh loss arises. We compare it to a similar distribution, called the Cauchy distribution, and carry out various statistical procedures that characterize its properties. In particular, we examine its associated pdf, cdf, likelihood function and Fisher information. Side-by-side we consider the Cauchy and Cosh distributions as well as the MLE of the location parameter with asymptotic bias, asymptotic variance, and confidence intervals. We also provide a comparison of robust estimators from several other loss functions, including the Huber loss function and the rank dispersion function. Further, we examine the use of the log-cosh function for quantile regression. In particular, we identify a quantile distribution function from which a maximum likelihood estimator for quantile regression can be derived. Finally, we compare a quantile M-estimator based on log-cosh with robust monotonicity against another approach to quantile regression based on convolutional smoothing.
Solution to the Non-Monotonicity and Crossing Problems in Quantile Regression
Nov 24, 2021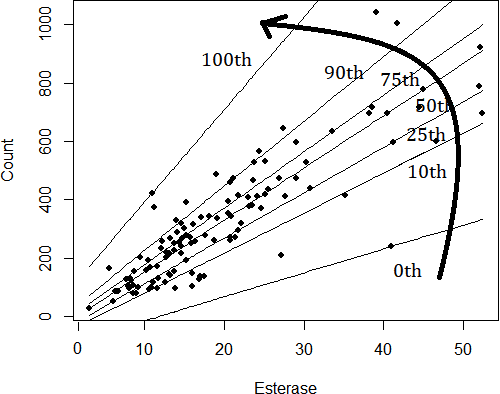
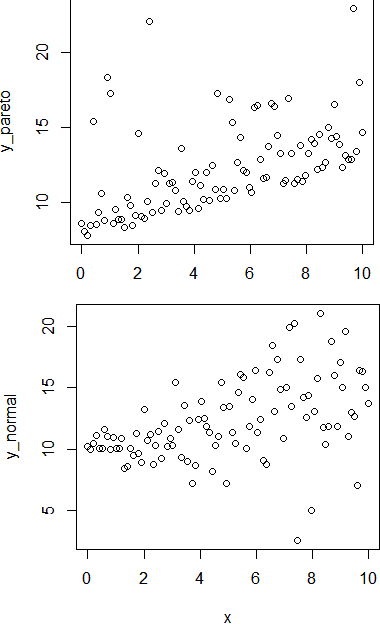
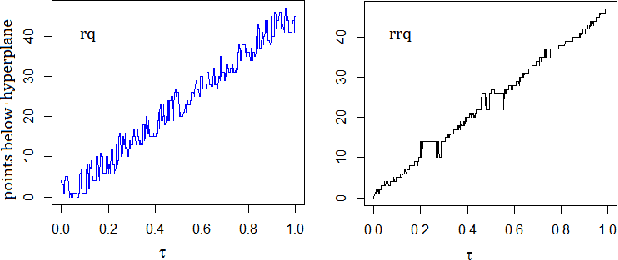
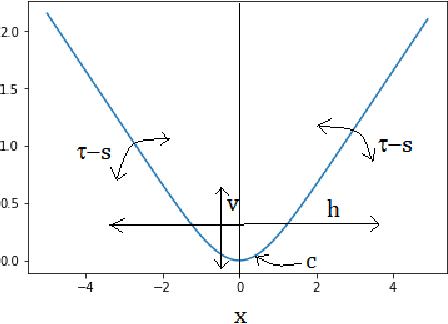
This paper proposes a new method to address the long-standing problem of lack of monotonicity in estimation of the conditional and structural quantile function, also known as quantile crossing problem. Quantile regression is a very powerful tool in data science in general and econometrics in particular. Unfortunately, the crossing problem has been confounding researchers and practitioners alike for over 4 decades. Numerous attempts have been made to find a simple and general solution. This paper describes a unique and elegant solution to the problem based on a flexible check function that is easy to understand and implement in R and Python, while greatly reducing or even eliminating the crossing problem entirely. It will be very important in all areas where quantile regression is routinely used and may also find application in robust regression, especially in the context of machine learning. From this perspective, we also utilize the flexible check function to provide insights into the root causes of the crossing problem.
Penalty, Shrinkage, and Preliminary Test Estimators under Full Model Hypothesis
Mar 24, 2015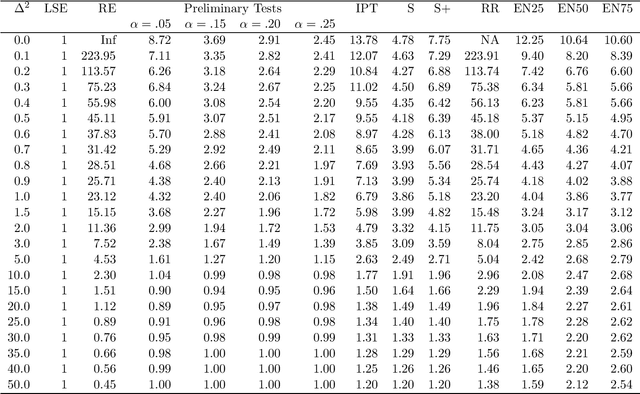
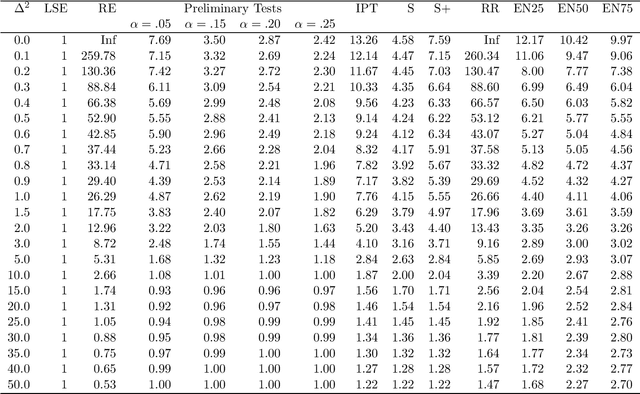
This paper considers a multiple regression model and compares, under full model hypothesis, analytically as well as by simulation, the performance characteristics of some popular penalty estimators such as ridge regression, LASSO, adaptive LASSO, SCAD, and elastic net versus Least Squares Estimator, restricted estimator, preliminary test estimator, and Stein-type estimators when the dimension of the parameter space is smaller than the sample space dimension. We find that RR uniformly dominates LSE, RE, PTE, SE and PRSE while LASSO, aLASSO, SCAD, and EN uniformly dominates LSE only. Further, it is observed that neither penalty estimators nor Stein-type estimator dominate one another.
Improved LASSO
Mar 17, 2015
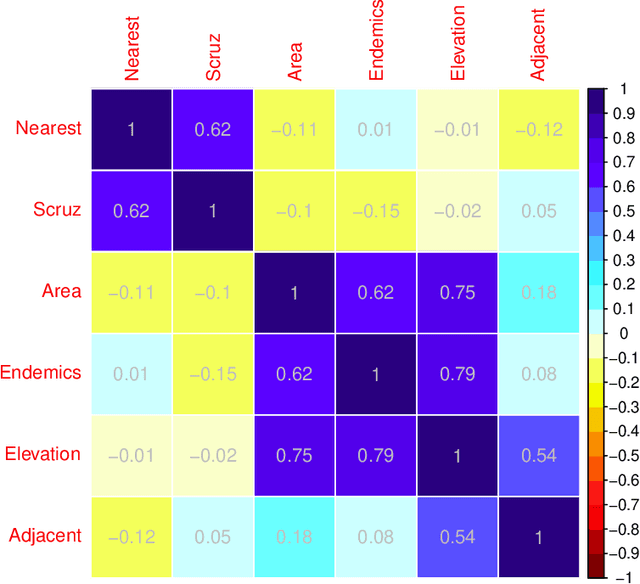
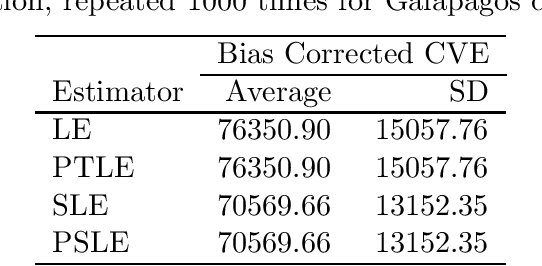
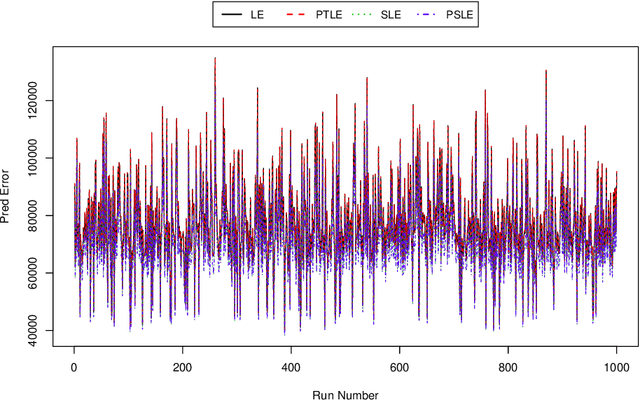
We propose an improved LASSO estimation technique based on Stein-rule. We shrink classical LASSO estimator using preliminary test, shrinkage, and positive-rule shrinkage principle. Simulation results have been carried out for various configurations of correlation coefficients ($r$), size of the parameter vector ($\beta$), error variance ($\sigma^2$) and number of non-zero coefficients ($k$) in the model parameter vector. Several real data examples have been used to demonstrate the practical usefulness of the proposed estimators. Our study shows that the risk ordering given by LSE $>$ LASSO $>$ Stein-type LASSO $>$ Stein-type positive rule LASSO, remains the same uniformly in the divergence parameter $\Delta^2$ as in the traditional case.