 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Graph Theoretic Exploration of Coronary Vascular Trees
Jul 29, 2022
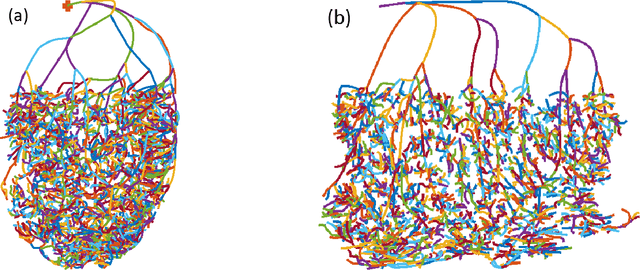

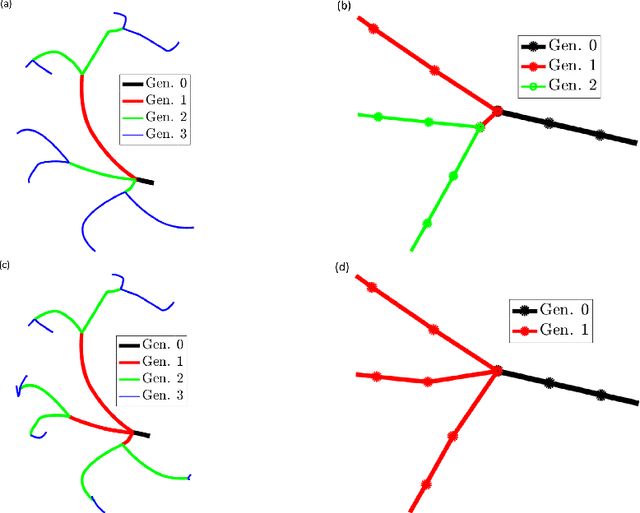
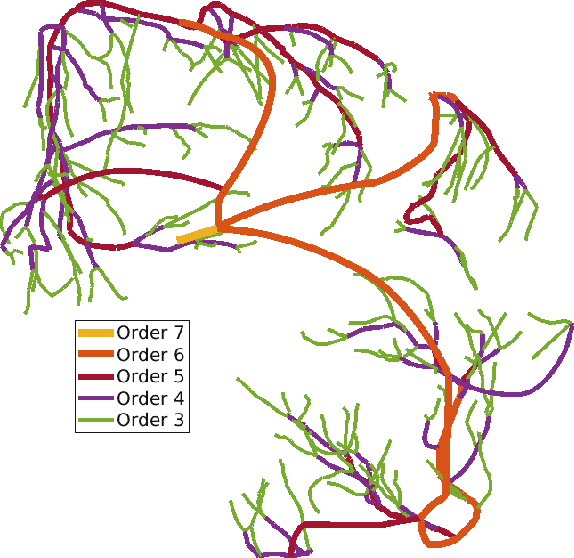
The aim of this study was to automate the generation of small coronary vascular networks from large point clouds that represent the coronary arterial network. Smaller networks that can be generated in a predictable manner can be used to assess the impact of network morphometry on, for example, blood flow in hemodynamic simulations. We develop a set of algorithms for generating coronary vascular networks from large point clouds. These algorithms sort the point cloud, simplify its network structure without information loss, and produce subgraphs based on given, physiologically meaningful parameters. The data were originally collected from optical fluorescence cryomicrotome images and processed before their use here.
FusePose: IMU-Vision Sensor Fusion in Kinematic Space for Parametric Human Pose Estimation
Aug 25, 2022
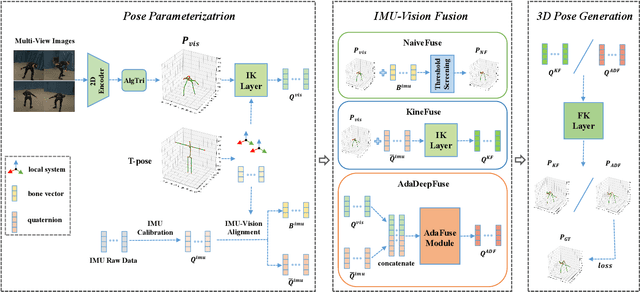
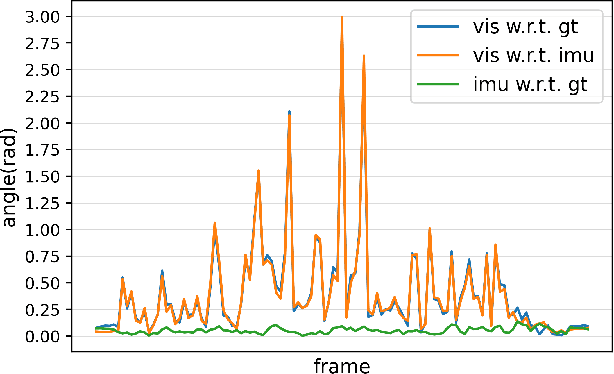
There exist challenging problems in 3D human pose estimation mission, such as poor performance caused by occlusion and self-occlusion. Recently, IMU-vision sensor fusion is regarded as valuable for solving these problems. However, previous researches on the fusion of IMU and vision data, which is heterogeneous, fail to adequately utilize either IMU raw data or reliable high-level vision features. To facilitate a more efficient sensor fusion, in this work we propose a framework called \emph{FusePose} under a parametric human kinematic model. Specifically, we aggregate different information of IMU or vision data and introduce three distinctive sensor fusion approaches: NaiveFuse, KineFuse and AdaDeepFuse. NaiveFuse servers as a basic approach that only fuses simplified IMU data and estimated 3D pose in euclidean space. While in kinematic space, KineFuse is able to integrate the calibrated and aligned IMU raw data with converted 3D pose parameters. AdaDeepFuse further develops this kinematical fusion process to an adaptive and end-to-end trainable manner. Comprehensive experiments with ablation studies demonstrate the rationality and superiority of the proposed framework. The performance of 3D human pose estimation is improved compared to the baseline result. On Total Capture dataset, KineFuse surpasses previous state-of-the-art which uses IMU only for testing by 8.6\%. AdaDeepFuse surpasses state-of-the-art which uses IMU for both training and testing by 8.5\%. Moreover, we validate the generalization capability of our framework through experiments on Human3.6M dataset.
FEVEROUS: Fact Extraction and VERification Over Unstructured and Structured information
Jun 10, 2021
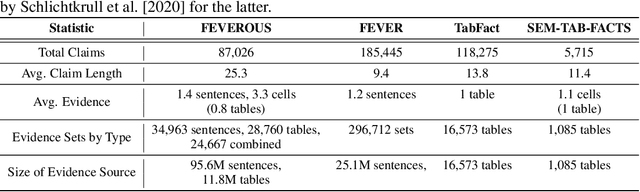
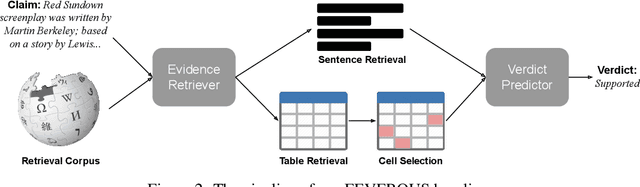
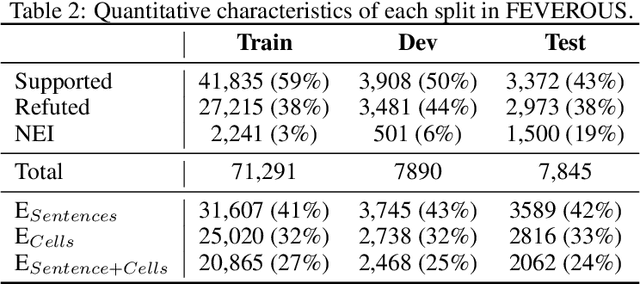
Fact verification has attracted a lot of attention in the machine learning and natural language processing communities, as it is one of the key methods for detecting misinformation. Existing large-scale benchmarks for this task have focused mostly on textual sources, i.e. unstructured information, and thus ignored the wealth of information available in structured formats, such as tables. In this paper we introduce a novel dataset and benchmark, Fact Extraction and VERification Over Unstructured and Structured information (FEVEROUS), which consists of 87,026 verified claims. Each claim is annotated with evidence in the form of sentences and/or cells from tables in Wikipedia, as well as a label indicating whether this evidence supports, refutes, or does not provide enough information to reach a verdict. Furthermore, we detail our efforts to track and minimize the biases present in the dataset and could be exploited by models, e.g. being able to predict the label without using evidence. Finally, we develop a baseline for verifying claims against text and tables which predicts both the correct evidence and verdict for 18% of the claims.
How many labelers do you have? A closer look at gold-standard labels
Jun 24, 2022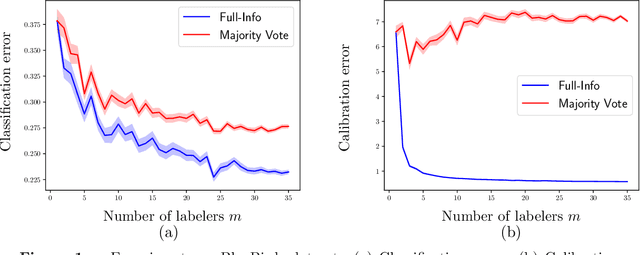
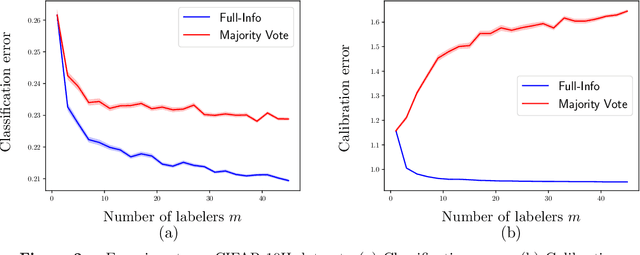
The construction of most supervised learning datasets revolves around collecting multiple labels for each instance, then aggregating the labels to form a type of ``gold-standard.''. We question the wisdom of this pipeline by developing a (stylized) theoretical model of this process and analyzing its statistical consequences, showing how access to non-aggregated label information can make training well-calibrated models easier or -- in some cases -- even feasible, whereas it is impossible with only gold-standard labels. The entire story, however, is subtle, and the contrasts between aggregated and fuller label information depend on the particulars of the problem, where estimators that use aggregated information exhibit robust but slower rates of convergence, while estimators that can effectively leverage all labels converge more quickly if they have fidelity to (or can learn) the true labeling process. The theory we develop in the stylized model makes several predictions for real-world datasets, including when non-aggregate labels should improve learning performance, which we test to corroborate the validity of our predictions.
The Brain-Inspired Decoder for Natural Visual Image Reconstruction
Jul 18, 2022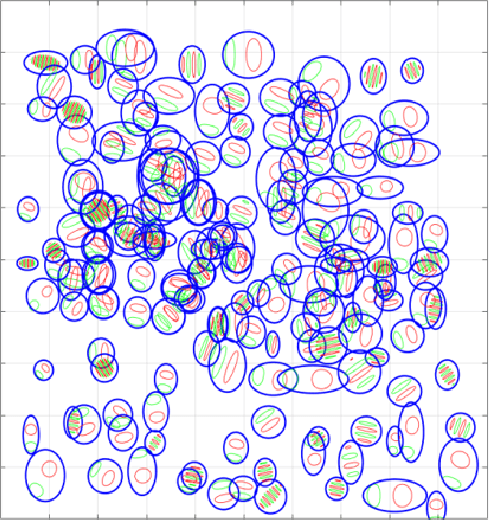

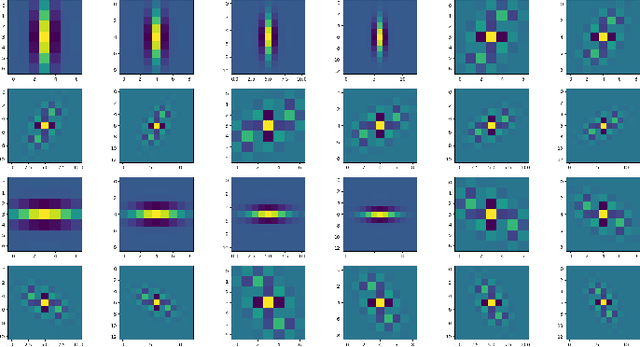
Decoding images from brain activity has been a challenge. Owing to the development of deep learning, there are available tools to solve this problem. The decoded image, which aims to map neural spike trains to low-level visual features and high-level semantic information space. Recently, there are a few studies of decoding from spike trains, however, these studies pay less attention to the foundations of neuroscience and there are few studies that merged receptive field into visual image reconstruction. In this paper, we propose a deep learning neural network architecture with biological properties to reconstruct visual image from spike trains. As far as we know, we implemented a method that integrated receptive field property matrix into loss function at the first time. Our model is an end-to-end decoder from neural spike trains to images. We not only merged Gabor filter into auto-encoder which used to generate images but also proposed a loss function with receptive field properties. We evaluated our decoder on two datasets which contain macaque primary visual cortex neural spikes and salamander retina ganglion cells (RGCs) spikes. Our results show that our method can effectively combine receptive field features to reconstruct images, providing a new approach to visual reconstruction based on neural information.
Temporal Saliency Query Network for Efficient Video Recognition
Jul 21, 2022
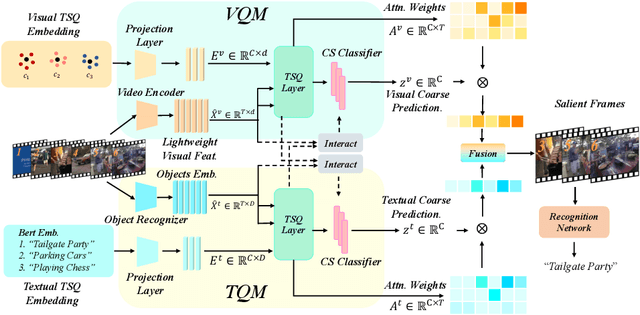
Efficient video recognition is a hot-spot research topic with the explosive growth of multimedia data on the Internet and mobile devices. Most existing methods select the salient frames without awareness of the class-specific saliency scores, which neglect the implicit association between the saliency of frames and its belonging category. To alleviate this issue, we devise a novel Temporal Saliency Query (TSQ) mechanism, which introduces class-specific information to provide fine-grained cues for saliency measurement. Specifically, we model the class-specific saliency measuring process as a query-response task. For each category, the common pattern of it is employed as a query and the most salient frames are responded to it. Then, the calculated similarities are adopted as the frame saliency scores. To achieve it, we propose a Temporal Saliency Query Network (TSQNet) that includes two instantiations of the TSQ mechanism based on visual appearance similarities and textual event-object relations. Afterward, cross-modality interactions are imposed to promote the information exchange between them. Finally, we use the class-specific saliencies of the most confident categories generated by two modalities to perform the selection of salient frames. Extensive experiments demonstrate the effectiveness of our method by achieving state-of-the-art results on ActivityNet, FCVID and Mini-Kinetics datasets. Our project page is at https://lawrencexia2008.github.io/projects/tsqnet .
In the Eye of Transformer: Global-Local Correlation for Egocentric Gaze Estimation
Aug 10, 2022
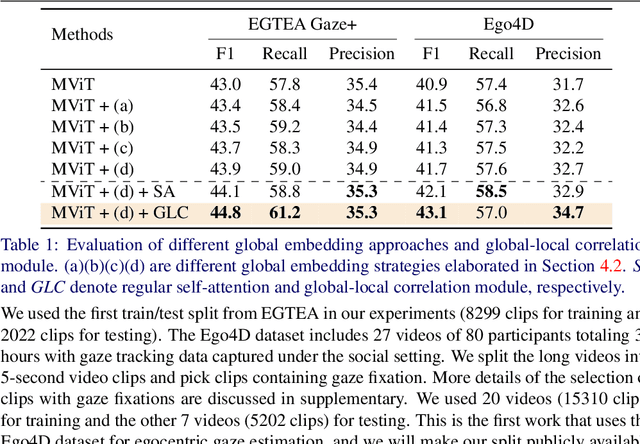
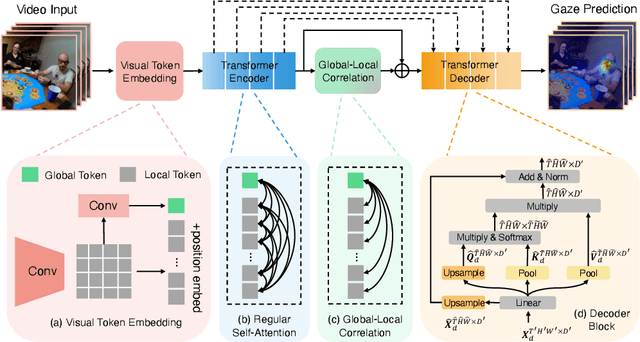
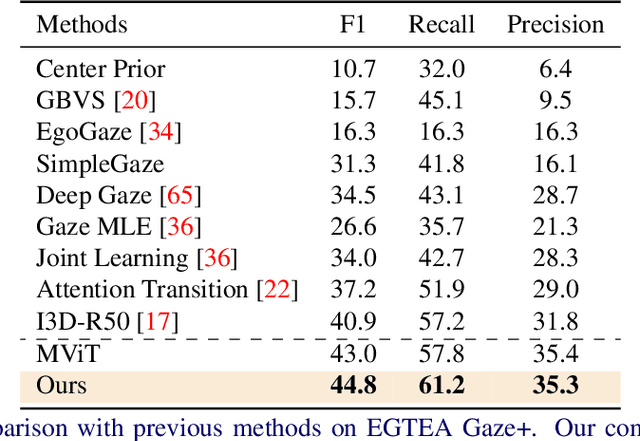
In this paper, we present the first transformer-based model to address the challenging problem of egocentric gaze estimation. We observe that the connection between the global scene context and local visual information is vital for localizing the gaze fixation from egocentric video frames. To this end, we design the transformer encoder to embed the global context as one additional visual token and further propose a novel Global-Local Correlation (GLC) module to explicitly model the correlation of the global token and each local token. We validate our model on two egocentric video datasets - EGTEA Gaze+ and Ego4D. Our detailed ablation studies demonstrate the benefits of our method. In addition, our approach exceeds previous state-of-the-arts by a large margin. We also provide additional visualizations to support our claim that global-local correlation serves a key representation for predicting gaze fixation from egocentric videos. More details can be found in our website (https://bolinlai.github.io/GLC-EgoGazeEst).
Using Affect as a Communication Modality to Improve Human-Robot Communication in Robot-Assisted Search and Rescue Scenarios
Aug 20, 2022
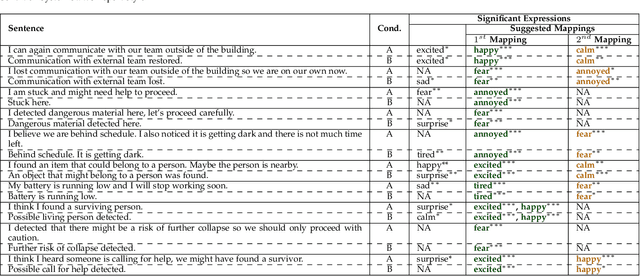

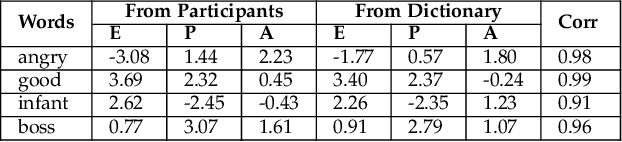
Emotions can provide a natural communication modality to complement the existing multi-modal capabilities of social robots, such as text and speech, in many domains. We conducted three online studies with 112, 223, and 151 participants to investigate the benefits of using emotions as a communication modality for Search And Rescue (SAR) robots. In the first experiment, we investigated the feasibility of conveying information related to SAR situations through robots' emotions, resulting in mappings from SAR situations to emotions. The second study used Affect Control Theory as an alternative method for deriving such mappings. This method is more flexible, e.g. allows for such mappings to be adjusted for different emotion sets and different robots. In the third experiment, we created affective expressions for an appearance-constrained outdoor field research robot using LEDs as an expressive channel. Using these affective expressions in a variety of simulated SAR situations, we evaluated the effect of these expressions on participants' (adopting the role of rescue workers) situational awareness. Our results and proposed methodologies provide (a) insights on how emotions could help conveying messages in the context of SAR, and (b) evidence on the effectiveness of adding emotions as a communication modality in a (simulated) SAR communication context.
Autonomous Agriculture Robot for Smart Farming
Aug 02, 2022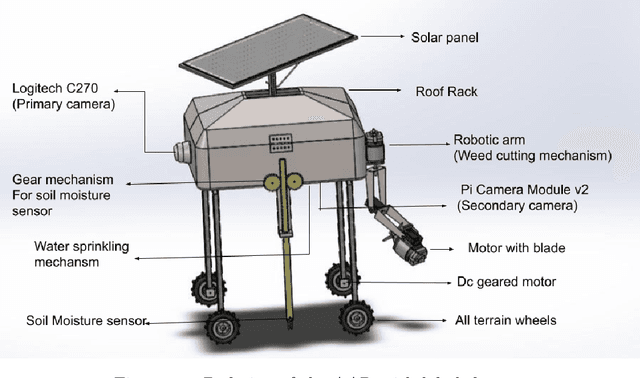



This project aims to develop and demonstrate a ground robot with intelligence capable of conducting semi-autonomous farm operations for different low-heights vegetable crops referred as Agriculture Application Robot(AAR). AAR is a lightweight, solar-electric powered robot that uses intelligent perception for conducting detection and classification of plants and their characteristics. The system also has a robotic arm for the autonomous weed cutting process. The robot can deliver fertilizer spraying, insecticide, herbicide, and other fluids to the targets such as crops, weeds, and other pests. Besides, it provides information for future research into higher-level tasks such as yield estimation, crop, and soil health monitoring. We present the design of robot and the associated experiments which show the promising results in real world environments.
Efficient and Privacy Preserving Group Signature for Federated Learning
Jul 15, 2022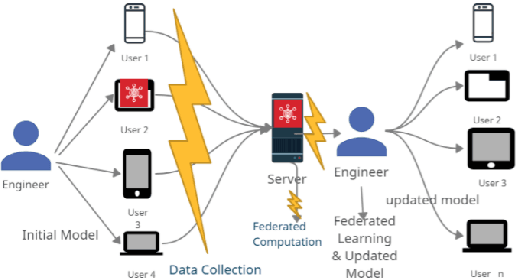

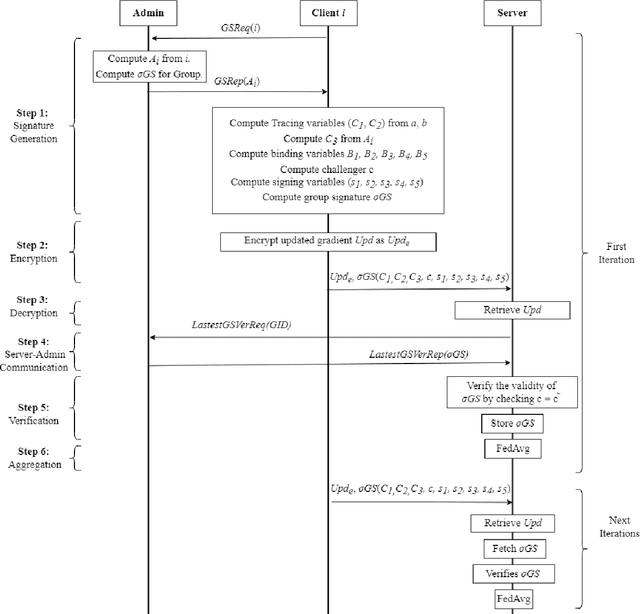

Federated Learning (FL) is a Machine Learning (ML) technique that aims to reduce the threats to user data privacy. Training is done using the raw data on the users' device, called clients, and only the training results, called gradients, are sent to the server to be aggregated and generate an updated model. However, we cannot assume that the server can be trusted with private information, such as metadata related to the owner or source of the data. So, hiding the client information from the server helps reduce privacy-related attacks. Therefore, the privacy of the client's identity, along with the privacy of the client's data, is necessary to make such attacks more difficult. This paper proposes an efficient and privacy-preserving protocol for FL based on group signature. A new group signature for federated learning, called GSFL, is designed to not only protect the privacy of the client's data and identity but also significantly reduce the computation and communication costs considering the iterative process of federated learning. We show that GSFL outperforms existing approaches in terms of computation, communication, and signaling costs. Also, we show that the proposed protocol can handle various security attacks in the federated learning environment.