 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pattern recognition in the nucleation kinetics of non-equilibrium self-assembly
Jul 13, 2022
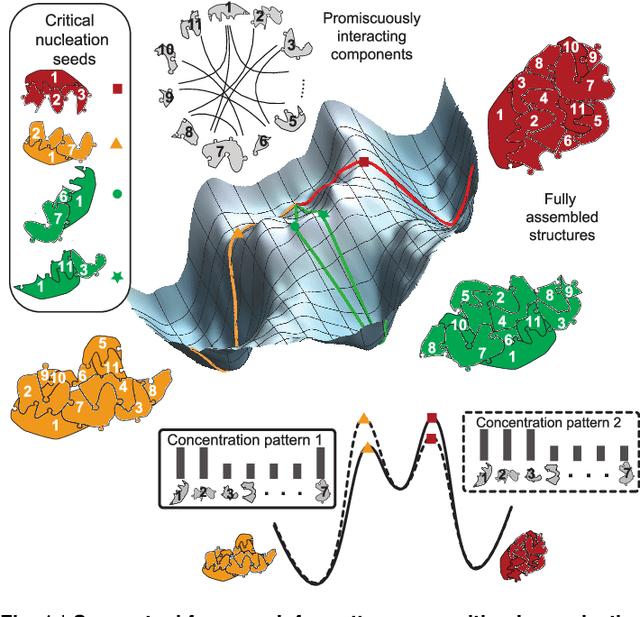

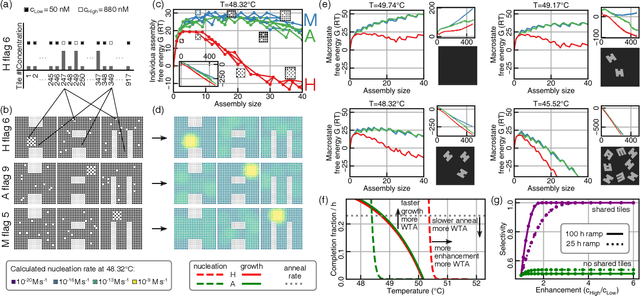
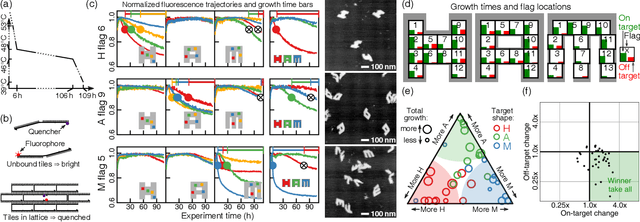
Inspired by biology's most sophisticated computer, the brain, neural networks constitute a profound reformulation of computational principles. Remarkably, analogous high-dimensional, highly-interconnected computational architectures also arise within information-processing molecular systems inside living cells, such as signal transduction cascades and genetic regulatory networks. Might neuromorphic collective modes be found more broadly in other physical and chemical processes, even those that ostensibly play non-information-processing roles such as protein synthesis, metabolism, or structural self-assembly? Here we examine nucleation during self-assembly of multicomponent structures, showing that high-dimensional patterns of concentrations can be discriminated and classified in a manner similar to neural network computation. Specifically, we design a set of 917 DNA tiles that can self-assemble in three alternative ways such that competitive nucleation depends sensitively on the extent of co-localization of high-concentration tiles within the three structures. The system was trained in-silico to classify a set of 18 grayscale 30 x 30 pixel images into three categories. Experimentally, fluorescence and atomic force microscopy monitoring during and after a 150-hour anneal established that all trained images were correctly classified, while a test set of image variations probed the robustness of the results. While slow compared to prior biochemical neural networks, our approach is surprisingly compact, robust, and scalable. This success suggests that ubiquitous physical phenomena, such as nucleation, may hold powerful information processing capabilities when scaled up as high-dimensional multicomponent systems.
RLang: A Declarative Language for Expression Prior Knowledge for Reinforcement Learning
Aug 16, 2022

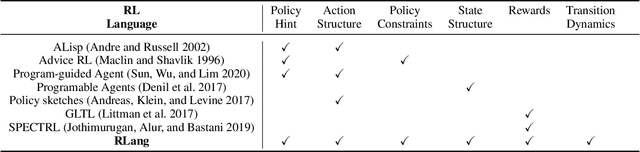
Communicating useful background knowledge to reinforcement learning (RL) agents is an important and effective method for accelerating learning. We introduce RLang, a domain-specific language (DSL) for communicating domain knowledge to an RL agent. Unlike other existing DSLs proposed by the RL community that ground to single elements of a decision-making formalism (e.g., the reward function or policy function), RLang can specify information about every element of a Markov decision process. We define precise syntax and grounding semantics for RLang, and provide a parser implementation that grounds RLang programs to an algorithm-agnostic partial world model and policy that can be exploited by an RL agent. We provide a series of example RLang programs, and demonstrate how different RL methods can exploit the resulting knowledge, including model-free and model-based tabular algorithms, hierarchical approaches, and deep RL algorithms (including both policy gradient and value-based methods).
Boosting Night-time Scene Parsing with Learnable Frequency
Aug 30, 2022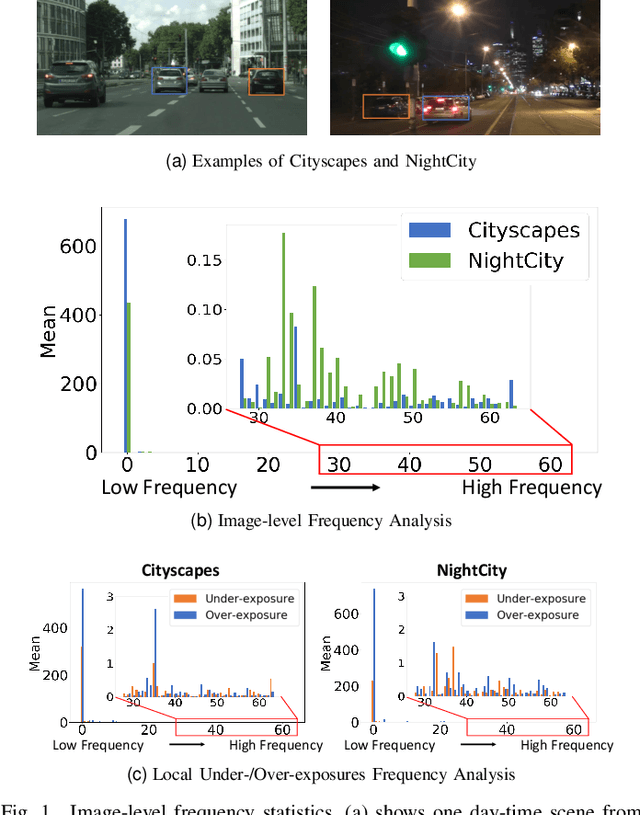
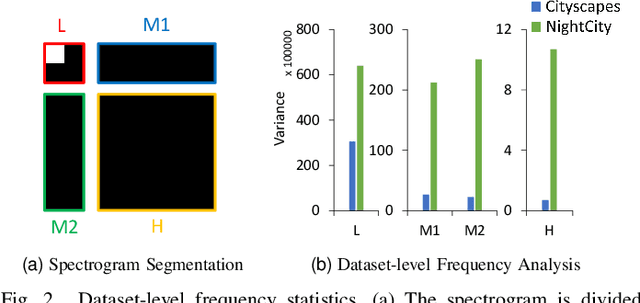
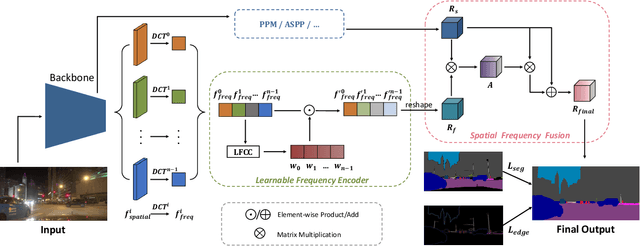
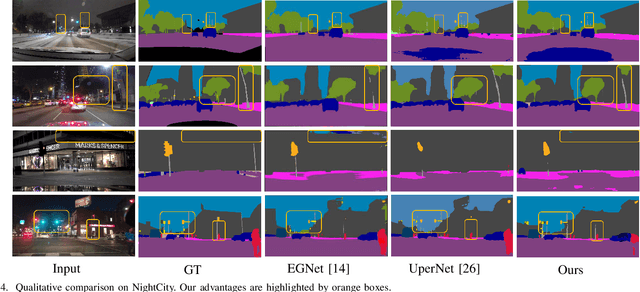
Night-Time Scene Parsing (NTSP) is essential to many vision applications, especially for autonomous driving. Most of the existing methods are proposed for day-time scene parsing. They rely on modeling pixel intensity-based spatial contextual cues under even illumination. Hence, these methods do not perform well in night-time scenes as such spatial contextual cues are buried in the over-/under-exposed regions in night-time scenes. In this paper, we first conduct an image frequency-based statistical experiment to interpret the day-time and night-time scene discrepancies. We find that image frequency distributions differ significantly between day-time and night-time scenes, and understanding such frequency distributions is critical to NTSP problem. Based on this, we propose to exploit the image frequency distributions for night-time scene parsing. First, we propose a Learnable Frequency Encoder (LFE) to model the relationship between different frequency coefficients to measure all frequency components dynamically. Second, we propose a Spatial Frequency Fusion module (SFF) that fuses both spatial and frequency information to guide the extraction of spatial context features. Extensive experiments show that our method performs favorably against the state-of-the-art methods on the NightCity, NightCity+ and BDD100K-night datasets. In addition, we demonstrate that our method can be applied to existing day-time scene parsing methods and boost their performance on night-time scenes.
Estimating Appearance Models for Image Segmentation via Tensor Factorization
Aug 16, 2022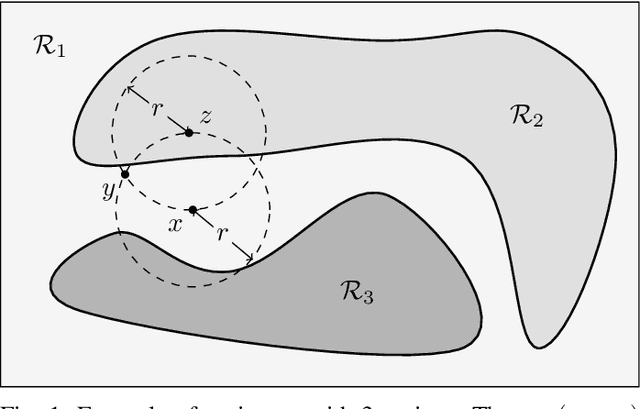
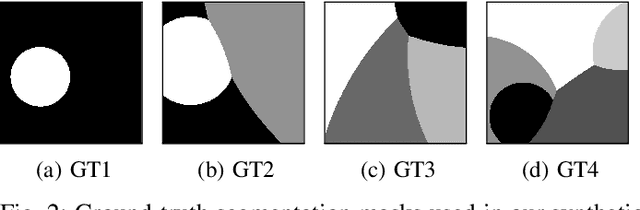

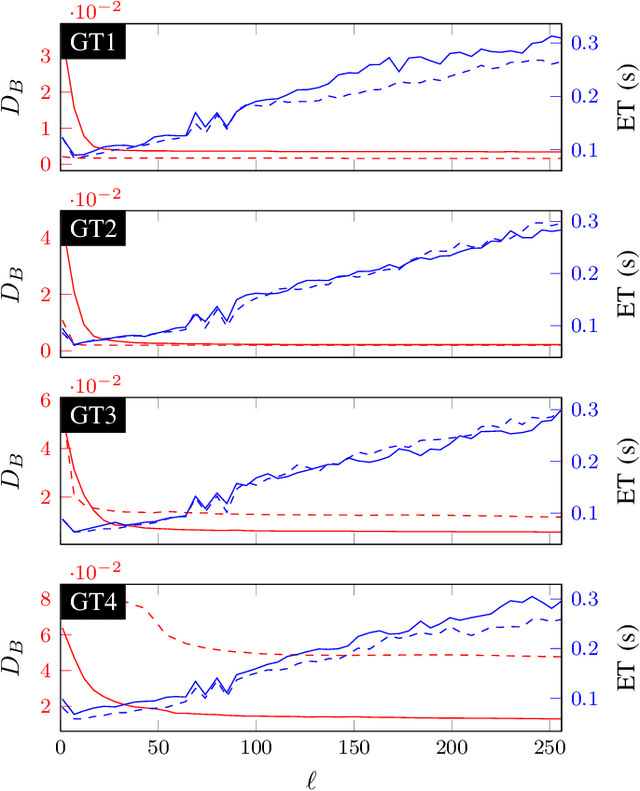
Image Segmentation is one of the core tasks in Computer Vision and solving it often depends on modeling the image appearance data via the color distributions of each it its constituent regions. Whereas many segmentation algorithms handle the appearance models dependence using alternation or implicit methods, we propose here a new approach to directly estimate them from the image without prior information on the underlying segmentation. Our method uses local high order color statistics from the image as an input to tensor factorization-based estimator for latent variable models. This approach is able to estimate models in multiregion images and automatically output the regions proportions without prior user interaction, overcoming the drawbacks from a prior attempt to this problem. We also demonstrate the performance of our proposed method in many challenging synthetic and real imaging scenarios and show that it leads to an efficient segmentation algorithm.
Prediction Errors for Penalized Regressions based on Generalized Approximate Message Passing
Jun 29, 2022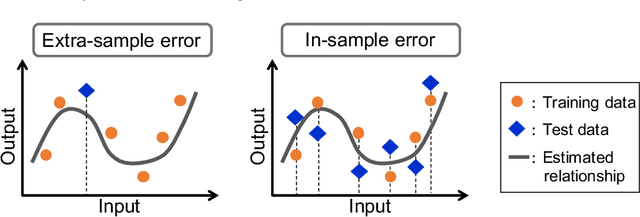

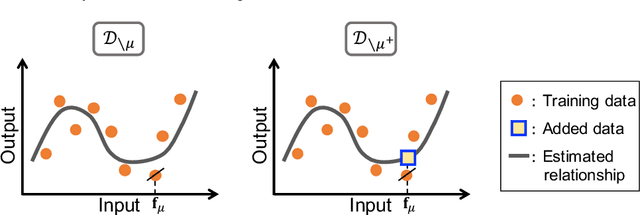
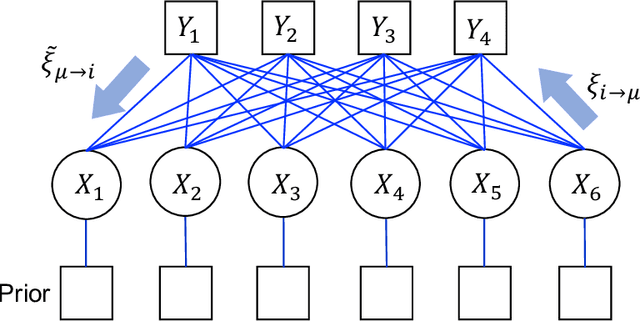
We discuss the prediction accuracy of assumed statistical models in terms of prediction errors for the generalized linear model and penalized maximum likelihood methods. We derive the forms of estimators for the prediction errors: $C_p$ criterion, information criteria, and leave-one-out cross validation (LOOCV) error, using the generalized approximate message passing (GAMP) algorithm and replica method. These estimators coincide with each other when the number of model parameters is sufficiently small; however, there is a discrepancy between them in particular in the overparametrized region where the number of model parameters is larger than the data dimension. In this paper, we review the prediction errors and corresponding estimators, and discuss their differences. In the framework of GAMP, we show that the information criteria can be expressed by using the variance of the estimates. Further, we demonstrate how to approach LOOCV error from the information criteria by utilizing the expression provided by GAMP.
Parallel Hierarchical Transformer with Attention Alignment for Abstractive Multi-Document Summarization
Aug 16, 2022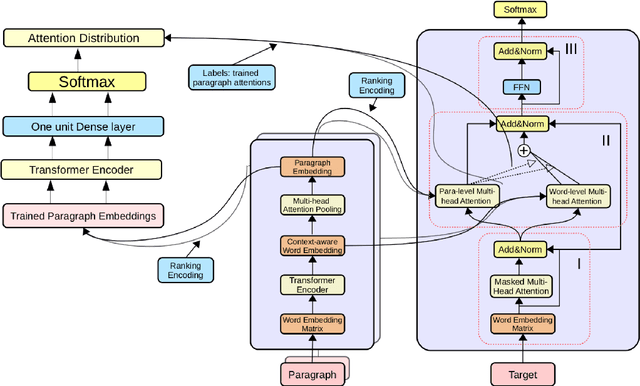
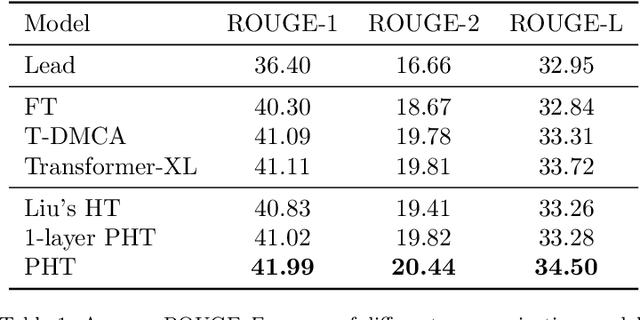
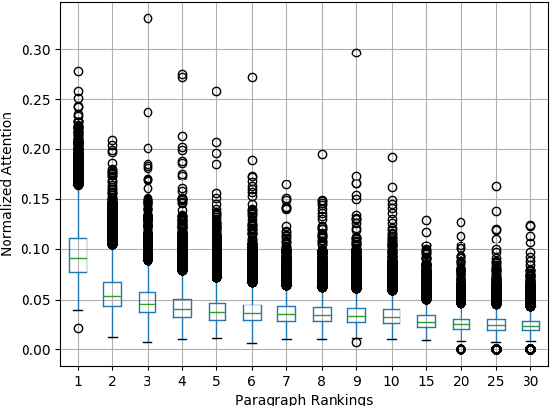
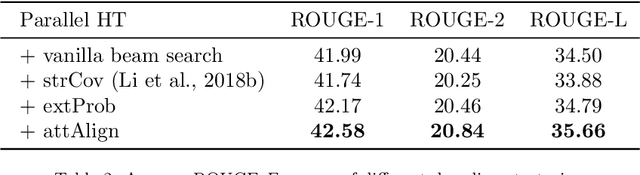
In comparison to single-document summarization, abstractive Multi-Document Summarization (MDS) brings challenges on the representation and coverage of its lengthy and linked sources. This study develops a Parallel Hierarchical Transformer (PHT) with attention alignment for MDS. By incorporating word- and paragraph-level multi-head attentions, the hierarchical architecture of PHT allows better processing of dependencies at both token and document levels. To guide the decoding towards a better coverage of the source documents, the attention-alignment mechanism is then introduced to calibrate beam search with predicted optimal attention distributions. Based on the WikiSum data, a comprehensive evaluation is conducted to test improvements on MDS by the proposed architecture. By better handling the inner- and cross-document information, results in both ROUGE and human evaluation suggest that our hierarchical model generates summaries of higher quality relative to other Transformer-based baselines at relatively low computational cost.
Constant Weight Codes with Gabor Dictionaries and Bayesian Decoding for Massive Random Access
Jul 26, 2022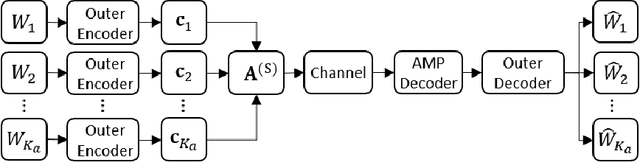
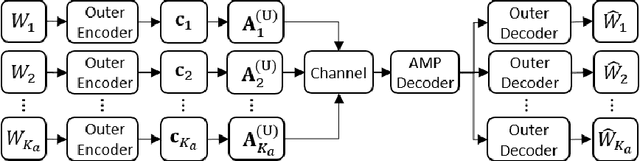
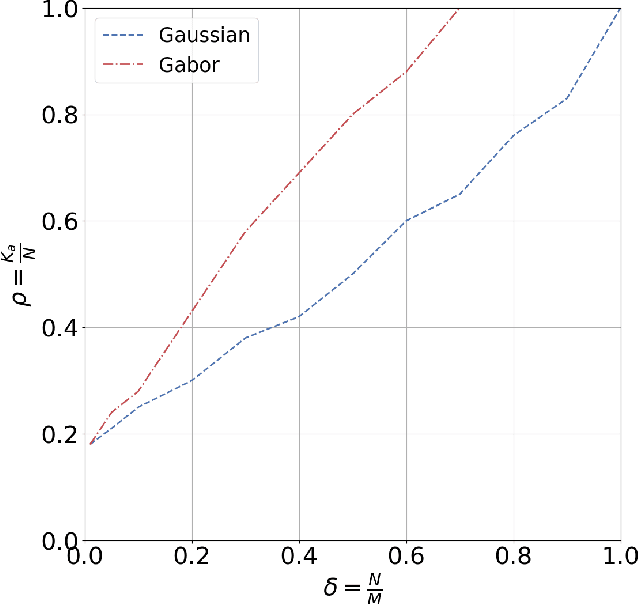
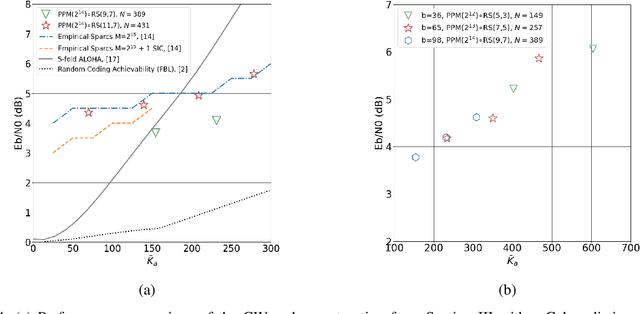
This paper considers a general framework for massive random access based on sparse superposition coding. We provide guidelines for the code design and propose the use of constant-weight codes in combination with a dictionary design based on Gabor frames. The decoder applies an extension of approximate message passing (AMP) by iteratively exchanging soft information between an AMP module that accounts for the dictionary structure, and a second inference module that utilizes the structure of the involved constant-weight code. We apply the encoding structure to (i) the unsourced random access setting, where all users employ a common dictionary, and (ii) to the "sourced" random access setting with user-specific dictionaries. When applied to a fading scenario, the communication scheme essentially operates non-coherently, as channel state information is required neither at the transmitter nor at the receiver. We observe that in regimes of practical interest, the proposed scheme compares favorably with state-of-the art schemes, in terms of the (per-user) energy-per-bit requirement, as well as the number of active users that can be simultaneously accommodated in the system. Importantly, this is achieved with a considerably smaller size of the transmitted codewords, potentially yielding lower latency and bandwidth occupancy, as well as lower implementation complexity.
DAHiTrA: Damage Assessment Using a Novel Hierarchical Transformer Architecture
Aug 03, 2022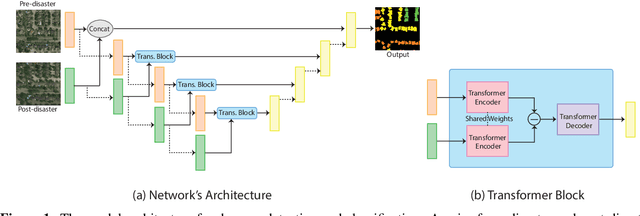
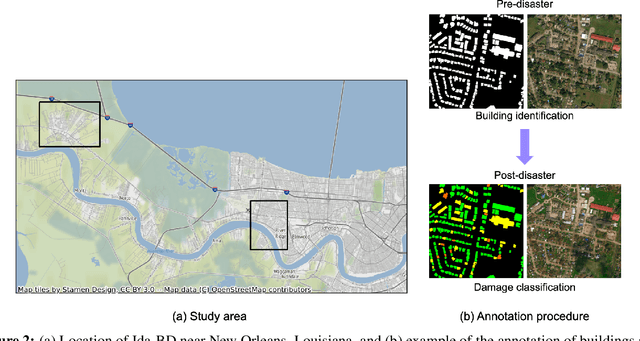


This paper presents DAHiTrA, a novel deep-learning model with hierarchical transformers to classify building damages based on satellite images in the aftermath of hurricanes. An automated building damage assessment provides critical information for decision making and resource allocation for rapid emergency response. Satellite imagery provides real-time, high-coverage information and offers opportunities to inform large-scale post-disaster building damage assessment. In addition, deep-learning methods have shown to be promising in classifying building damage. In this work, a novel transformer-based network is proposed for assessing building damage. This network leverages hierarchical spatial features of multiple resolutions and captures temporal difference in the feature domain after applying a transformer encoder on the spatial features. The proposed network achieves state-of-the-art-performance when tested on a large-scale disaster damage dataset (xBD) for building localization and damage classification, as well as on LEVIR-CD dataset for change detection tasks. In addition, we introduce a new high-resolution satellite imagery dataset, Ida-BD (related to the 2021 Hurricane Ida in Louisiana in 2021, for domain adaptation to further evaluate the capability of the model to be applied to newly damaged areas with scarce data. The domain adaptation results indicate that the proposed model can be adapted to a new event with only limited fine-tuning. Hence, the proposed model advances the current state of the art through better performance and domain adaptation. Also, Ida-BD provides a higher-resolution annotated dataset for future studies in this field.
Symmetric Pruning in Quantum Neural Networks
Aug 30, 2022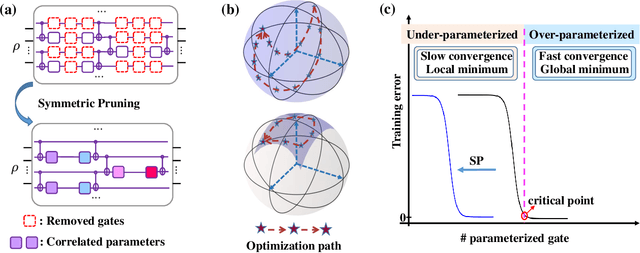
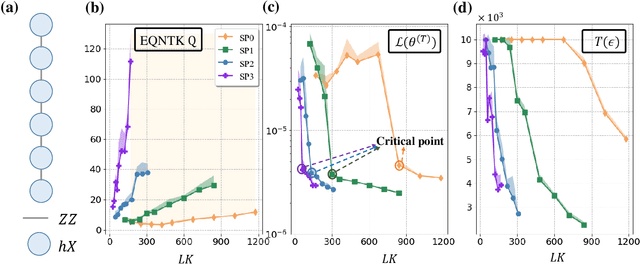
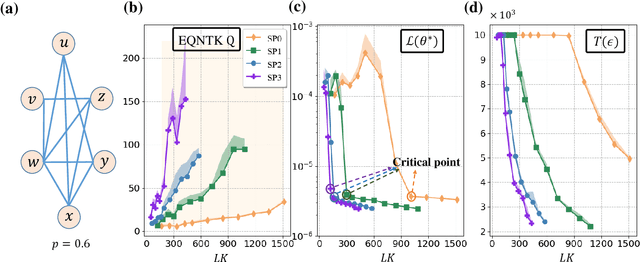
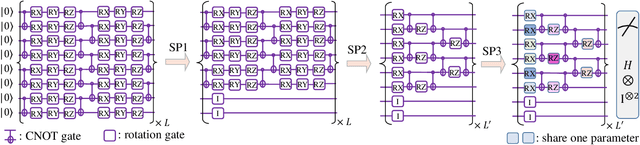
Many fundamental properties of a quantum system are captured by its Hamiltonian and ground state. Despite the significance of ground states preparation (GSP), this task is classically intractable for large-scale Hamiltonians. Quantum neural networks (QNNs), which exert the power of modern quantum machines, have emerged as a leading protocol to conquer this issue. As such, how to enhance the performance of QNNs becomes a crucial topic in GSP. Empirical evidence showed that QNNs with handcraft symmetric ansatzes generally experience better trainability than those with asymmetric ansatzes, while theoretical explanations have not been explored. To fill this knowledge gap, here we propose the effective quantum neural tangent kernel (EQNTK) and connect this concept with over-parameterization theory to quantify the convergence of QNNs towards the global optima. We uncover that the advance of symmetric ansatzes attributes to their large EQNTK value with low effective dimension, which requests few parameters and quantum circuit depth to reach the over-parameterization regime permitting a benign loss landscape and fast convergence. Guided by EQNTK, we further devise a symmetric pruning (SP) scheme to automatically tailor a symmetric ansatz from an over-parameterized and asymmetric one to greatly improve the performance of QNNs when the explicit symmetry information of Hamiltonian is unavailable. Extensive numerical simulations are conducted to validate the analytical results of EQNTK and the effectiveness of SP.
Dataset Condensation with Latent Space Knowledge Factorization and Sharing
Aug 21, 2022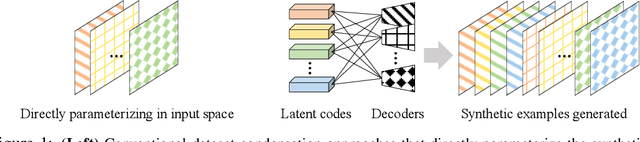
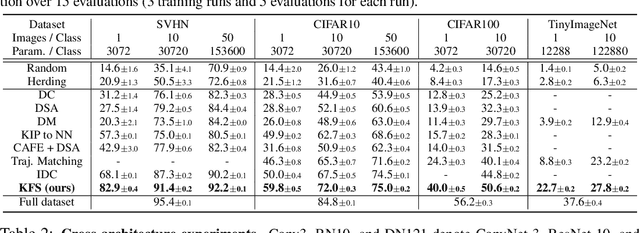
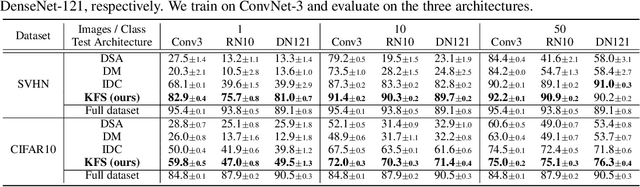
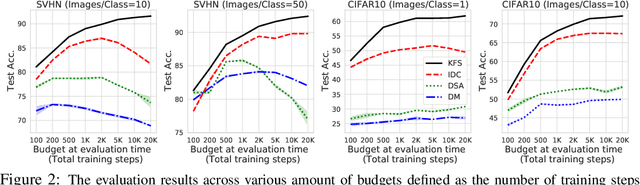
In this paper, we introduce a novel approach for systematically solving dataset condensation problem in an efficient manner by exploiting the regularity in a given dataset. Instead of condensing the dataset directly in the original input space, we assume a generative process of the dataset with a set of learnable codes defined in a compact latent space followed by a set of tiny decoders which maps them differently to the original input space. By combining different codes and decoders interchangeably, we can dramatically increase the number of synthetic examples with essentially the same parameter count, because the latent space is much lower dimensional and since we can assume as many decoders as necessary to capture different styles represented in the dataset with negligible cost. Such knowledge factorization allows efficient sharing of information between synthetic examples in a systematic way, providing far better trade-off between compression ratio and quality of the generated examples. We experimentally show that our method achieves new state-of-the-art records by significant margins on various benchmark datasets such as SVHN, CIFAR10, CIFAR100, and TinyImageNet.