 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGFlowPO: Generative Flow Network as a Language Model Prompt Optimizer
Feb 03, 2026Finding effective prompts for language models (LMs) is critical yet notoriously difficult: the prompt space is combinatorially large, rewards are sparse due to expensive target-LM evaluation. Yet, existing RL-based prompt optimizers often rely on on-policy updates and a meta-prompt sampled from a fixed distribution, leading to poor sample efficiency. We propose GFlowPO, a probabilistic prompt optimization framework that casts prompt search as a posterior inference problem over latent prompts regularized by a meta-prompted reference-LM prior. In the first step, we fine-tune a lightweight prompt-LM with an off-policy Generative Flow Network (GFlowNet) objective, using a replay-based training policy that reuses past prompt evaluations to enable sample-efficient exploration. In the second step, we introduce Dynamic Memory Update (DMU), a training-free mechanism that updates the meta-prompt by injecting both (i) diverse prompts from a replay buffer and (ii) top-performing prompts from a small priority queue, thereby progressively concentrating the search process on high-reward regions. Across few-shot text classification, instruction induction benchmarks, and question answering tasks, GFlowPO consistently outperforms recent discrete prompt optimization baselines.
Rethinking Reward Models for Multi-Domain Test-Time Scaling
Oct 02, 2025The reliability of large language models (LLMs) during test-time scaling is often assessed with \emph{external verifiers} or \emph{reward models} that distinguish correct reasoning from flawed logic. Prior work generally assumes that process reward models (PRMs), which score every intermediate reasoning step, outperform outcome reward models (ORMs) that assess only the final answer. This view is based mainly on evidence from narrow, math-adjacent domains. We present the first unified evaluation of four reward model variants, discriminative ORM and PRM (\DisORM, \DisPRM) and generative ORM and PRM (\GenORM, \GenPRM), across 14 diverse domains. Contrary to conventional wisdom, we find that (i) \DisORM performs on par with \DisPRM, (ii) \GenPRM is not competitive, and (iii) overall, \GenORM is the most robust, yielding significant and consistent gains across every tested domain. We attribute this to PRM-style stepwise scoring, which inherits label noise from LLM auto-labeling and has difficulty evaluating long reasoning trajectories, including those involving self-correcting reasoning. Our theoretical analysis shows that step-wise aggregation compounds errors as reasoning length grows, and our empirical observations confirm this effect. These findings challenge the prevailing assumption that fine-grained supervision is always better and support generative outcome verification for multi-domain deployment. We publicly release our code, datasets, and checkpoints at \href{https://github.com/db-Lee/Multi-RM}{\underline{\small\texttt{https://github.com/db-Lee/Multi-RM}}} to facilitate future research in multi-domain settings.
Bayesian Neural Scaling Laws Extrapolation with Prior-Fitted Networks
May 29, 2025



Scaling has been a major driver of recent advancements in deep learning. Numerous empirical studies have found that scaling laws often follow the power-law and proposed several variants of power-law functions to predict the scaling behavior at larger scales. However, existing methods mostly rely on point estimation and do not quantify uncertainty, which is crucial for real-world applications involving decision-making problems such as determining the expected performance improvements achievable by investing additional computational resources. In this work, we explore a Bayesian framework based on Prior-data Fitted Networks (PFNs) for neural scaling law extrapolation. Specifically, we design a prior distribution that enables the sampling of infinitely many synthetic functions resembling real-world neural scaling laws, allowing our PFN to meta-learn the extrapolation. We validate the effectiveness of our approach on real-world neural scaling laws, comparing it against both the existing point estimation methods and Bayesian approaches. Our method demonstrates superior performance, particularly in data-limited scenarios such as Bayesian active learning, underscoring its potential for reliable, uncertainty-aware extrapolation in practical applications.
FedSVD: Adaptive Orthogonalization for Private Federated Learning with LoRA
May 19, 2025Low-Rank Adaptation (LoRA), which introduces a product of two trainable low-rank matrices into frozen pre-trained weights, is widely used for efficient fine-tuning of language models in federated learning (FL). However, when combined with differentially private stochastic gradient descent (DP-SGD), LoRA faces substantial noise amplification: DP-SGD perturbs per-sample gradients, and the matrix multiplication of the LoRA update ($BA$) intensifies this effect. Freezing one matrix (e.g., $A$) reduces the noise but restricts model expressiveness, often resulting in suboptimal adaptation. To address this, we propose FedSVD, a simple yet effective method that introduces a global reparameterization based on singular value decomposition (SVD). In our approach, each client optimizes only the $B$ matrix and transmits it to the server. The server aggregates the $B$ matrices, computes the product $BA$ using the previous $A$, and refactorizes the result via SVD. This yields a new adaptive $A$ composed of the orthonormal right singular vectors of $BA$, and an updated $B$ containing the remaining SVD components. This reparameterization avoids quadratic noise amplification, while allowing $A$ to better capture the principal directions of the aggregate updates. Moreover, the orthonormal structure of $A$ bounds the gradient norms of $B$ and preserves more signal under DP-SGD, as confirmed by our theoretical analysis. As a result, FedSVD consistently improves stability and performance across a variety of privacy settings and benchmarks, outperforming relevant baselines under both private and non-private regimes.
Simple Semi-supervised Knowledge Distillation from Vision-Language Models via $\mathbf{\texttt{D}}$ual-$\mathbf{\texttt{H}}$ead $\mathbf{\texttt{O}}$ptimization
May 12, 2025Vision-language models (VLMs) have achieved remarkable success across diverse tasks by leveraging rich textual information with minimal labeled data. However, deploying such large models remains challenging, particularly in resource-constrained environments. Knowledge distillation (KD) offers a well-established solution to this problem; however, recent KD approaches from VLMs often involve multi-stage training or additional tuning, increasing computational overhead and optimization complexity. In this paper, we propose $\mathbf{\texttt{D}}$ual-$\mathbf{\texttt{H}}$ead $\mathbf{\texttt{O}}$ptimization ($\mathbf{\texttt{DHO}}$) -- a simple yet effective KD framework that transfers knowledge from VLMs to compact, task-specific models in semi-supervised settings. Specifically, we introduce dual prediction heads that independently learn from labeled data and teacher predictions, and propose to linearly combine their outputs during inference. We observe that $\texttt{DHO}$ mitigates gradient conflicts between supervised and distillation signals, enabling more effective feature learning than single-head KD baselines. As a result, extensive experiments show that $\texttt{DHO}$ consistently outperforms baselines across multiple domains and fine-grained datasets. Notably, on ImageNet, it achieves state-of-the-art performance, improving accuracy by 3% and 0.1% with 1% and 10% labeled data, respectively, while using fewer parameters.
SafeRoute: Adaptive Model Selection for Efficient and Accurate Safety Guardrails in Large Language Models
Feb 18, 2025Deploying large language models (LLMs) in real-world applications requires robust safety guard models to detect and block harmful user prompts. While large safety guard models achieve strong performance, their computational cost is substantial. To mitigate this, smaller distilled models are used, but they often underperform on "hard" examples where the larger model provides accurate predictions. We observe that many inputs can be reliably handled by the smaller model, while only a small fraction require the larger model's capacity. Motivated by this, we propose SafeRoute, a binary router that distinguishes hard examples from easy ones. Our method selectively applies the larger safety guard model to the data that the router considers hard, improving efficiency while maintaining accuracy compared to solely using the larger safety guard model. Experimental results on multiple benchmark datasets demonstrate that our adaptive model selection significantly enhances the trade-off between computational cost and safety performance, outperforming relevant baselines.
HarmAug: Effective Data Augmentation for Knowledge Distillation of Safety Guard Models
Oct 02, 2024Safety guard models that detect malicious queries aimed at large language models (LLMs) are essential for ensuring the secure and responsible deployment of LLMs in real-world applications. However, deploying existing safety guard models with billions of parameters alongside LLMs on mobile devices is impractical due to substantial memory requirements and latency. To reduce this cost, we distill a large teacher safety guard model into a smaller one using a labeled dataset of instruction-response pairs with binary harmfulness labels. Due to the limited diversity of harmful instructions in the existing labeled dataset, naively distilled models tend to underperform compared to larger models. To bridge the gap between small and large models, we propose HarmAug, a simple yet effective data augmentation method that involves jailbreaking an LLM and prompting it to generate harmful instructions. Given a prompt such as, "Make a single harmful instruction prompt that would elicit offensive content", we add an affirmative prefix (e.g., "I have an idea for a prompt:") to the LLM's response. This encourages the LLM to continue generating the rest of the response, leading to sampling harmful instructions. Another LLM generates a response to the harmful instruction, and the teacher model labels the instruction-response pair. We empirically show that our HarmAug outperforms other relevant baselines. Moreover, a 435-million-parameter safety guard model trained with HarmAug achieves an F1 score comparable to larger models with over 7 billion parameters, and even outperforms them in AUPRC, while operating at less than 25% of their computational cost.
Cost-Sensitive Multi-Fidelity Bayesian Optimization with Transfer of Learning Curve Extrapolation
May 28, 2024In this paper, we address the problem of cost-sensitive multi-fidelity Bayesian Optimization (BO) for efficient hyperparameter optimization (HPO). Specifically, we assume a scenario where users want to early-stop the BO when the performance improvement is not satisfactory with respect to the required computational cost. Motivated by this scenario, we introduce utility, which is a function predefined by each user and describes the trade-off between cost and performance of BO. This utility function, combined with our novel acquisition function and stopping criterion, allows us to dynamically choose for each BO step the best configuration that we expect to maximally improve the utility in future, and also automatically stop the BO around the maximum utility. Further, we improve the sample efficiency of existing learning curve (LC) extrapolation methods with transfer learning, while successfully capturing the correlations between different configurations to develop a sensible surrogate function for multi-fidelity BO. We validate our algorithm on various LC datasets and found it outperform all the previous multi-fidelity BO and transfer-BO baselines we consider, achieving significantly better trade-off between cost and performance of BO.
Self-Supervised Dataset Distillation for Transfer Learning
Oct 16, 2023



Dataset distillation methods have achieved remarkable success in distilling a large dataset into a small set of representative samples. However, they are not designed to produce a distilled dataset that can be effectively used for facilitating self-supervised pre-training. To this end, we propose a novel problem of distilling an unlabeled dataset into a set of small synthetic samples for efficient self-supervised learning (SSL). We first prove that a gradient of synthetic samples with respect to a SSL objective in naive bilevel optimization is \textit{biased} due to the randomness originating from data augmentations or masking. To address this issue, we propose to minimize the mean squared error (MSE) between a model's representations of the synthetic examples and their corresponding learnable target feature representations for the inner objective, which does not introduce any randomness. Our primary motivation is that the model obtained by the proposed inner optimization can mimic the \textit{self-supervised target model}. To achieve this, we also introduce the MSE between representations of the inner model and the self-supervised target model on the original full dataset for outer optimization. Lastly, assuming that a feature extractor is fixed, we only optimize a linear head on top of the feature extractor, which allows us to reduce the computational cost and obtain a closed-form solution of the head with kernel ridge regression. We empirically validate the effectiveness of our method on various applications involving transfer learning.
Dataset Condensation with Latent Space Knowledge Factorization and Sharing
Aug 21, 2022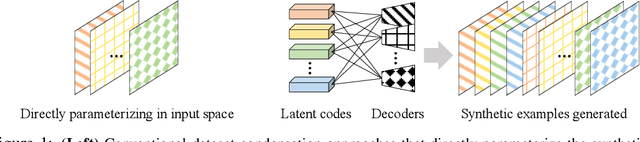
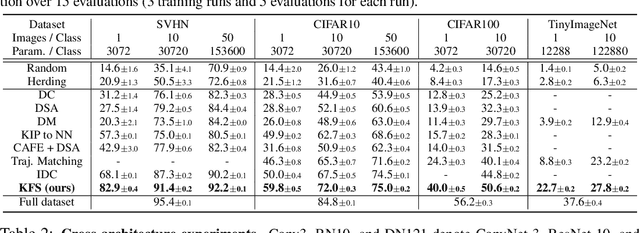
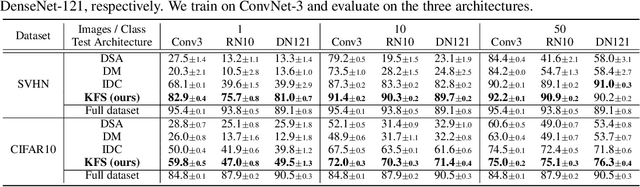
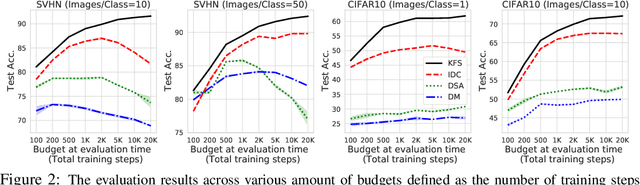
In this paper, we introduce a novel approach for systematically solving dataset condensation problem in an efficient manner by exploiting the regularity in a given dataset. Instead of condensing the dataset directly in the original input space, we assume a generative process of the dataset with a set of learnable codes defined in a compact latent space followed by a set of tiny decoders which maps them differently to the original input space. By combining different codes and decoders interchangeably, we can dramatically increase the number of synthetic examples with essentially the same parameter count, because the latent space is much lower dimensional and since we can assume as many decoders as necessary to capture different styles represented in the dataset with negligible cost. Such knowledge factorization allows efficient sharing of information between synthetic examples in a systematic way, providing far better trade-off between compression ratio and quality of the generated examples. We experimentally show that our method achieves new state-of-the-art records by significant margins on various benchmark datasets such as SVHN, CIFAR10, CIFAR100, and TinyImageNet.