 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffloading Score: Measuring AI Reliance Through Counterfactual Workflows
May 28, 2026AI tools are increasingly integrated into real-world workflows. However, existing measures of reliance on these tools focus on AI output adoption or on self-reported indicators, rather than how task effort is distributed between users and tools. Here, we introduce offloading score, a measure of reliance that quantifies the fraction of cognitive effort offloaded to an AI tool. Offloading Score is simulation-based -- we construct a counterfactual workflow by estimating how the user would have completed the task without the tool, and then computing the fraction of steps saved by using the tool. We validate offloading score through intrinsic evaluations of metric validity, and a controlled user study ($n=40$) with developers performing programming tasks using AI tools. We vary time pressure to test whether reliance measures capture the known increase in reliance under time pressure. We show that offloading score detects significantly higher reliance in time-constrained settings ($+43\%$, $p=0.018$), while usage-based and self-reported baseline measures of reliance do not distinguish the conditions. We complement this with descriptive insights showing that higher reliance manifests as greater delegation of subtasks to the tool and more direct reuse of AI outputs. Finally, we demonstrate an approach of using offloading score in combination with target outcomes of a task (e.g., code understanding) to identify when reliance may be (in)appropriate. Our framework offers two contributions: an instrument users can apply to measure and reflect on their own reliance, and a quantitative signal that agent designers can utilize to mitigate overreliance.
Do AI Companies Make Good on Voluntary Commitments to the White House?
Aug 11, 2025Voluntary commitments are central to international AI governance, as demonstrated by recent voluntary guidelines from the White House to the G7, from Bletchley Park to Seoul. How do major AI companies make good on their commitments? We score companies based on their publicly disclosed behavior by developing a detailed rubric based on their eight voluntary commitments to the White House in 2023. We find significant heterogeneity: while the highest-scoring company (OpenAI) scores a 83% overall on our rubric, the average score across all companies is just 52%. The companies demonstrate systemically poor performance for their commitment to model weight security with an average score of 17%: 11 of the 16 companies receive 0% for this commitment. Our analysis highlights a clear structural shortcoming that future AI governance initiatives should correct: when companies make public commitments, they should proactively disclose how they meet their commitments to provide accountability, and these disclosures should be verifiable. To advance policymaking on corporate AI governance, we provide three directed recommendations that address underspecified commitments, the role of complex AI supply chains, and public transparency that could be applied towards AI governance initiatives worldwide.
Towards Best Practices for Open Datasets for LLM Training
Jan 14, 2025Many AI companies are training their large language models (LLMs) on data without the permission of the copyright owners. The permissibility of doing so varies by jurisdiction: in countries like the EU and Japan, this is allowed under certain restrictions, while in the United States, the legal landscape is more ambiguous. Regardless of the legal status, concerns from creative producers have led to several high-profile copyright lawsuits, and the threat of litigation is commonly cited as a reason for the recent trend towards minimizing the information shared about training datasets by both corporate and public interest actors. This trend in limiting data information causes harm by hindering transparency, accountability, and innovation in the broader ecosystem by denying researchers, auditors, and impacted individuals access to the information needed to understand AI models. While this could be mitigated by training language models on open access and public domain data, at the time of writing, there are no such models (trained at a meaningful scale) due to the substantial technical and sociological challenges in assembling the necessary corpus. These challenges include incomplete and unreliable metadata, the cost and complexity of digitizing physical records, and the diverse set of legal and technical skills required to ensure relevance and responsibility in a quickly changing landscape. Building towards a future where AI systems can be trained on openly licensed data that is responsibly curated and governed requires collaboration across legal, technical, and policy domains, along with investments in metadata standards, digitization, and fostering a culture of openness.
Designerly Understanding: Information Needs for Model Transparency to Support Design Ideation for AI-Powered User Experience
Feb 21, 2023



Despite the widespread use of artificial intelligence (AI), designing user experiences (UX) for AI-powered systems remains challenging. UX designers face hurdles understanding AI technologies, such as pre-trained language models, as design materials. This limits their ability to ideate and make decisions about whether, where, and how to use AI. To address this problem, we bridge the literature on AI design and AI transparency to explore whether and how frameworks for transparent model reporting can support design ideation with pre-trained models. By interviewing 23 UX practitioners, we find that practitioners frequently work with pre-trained models, but lack support for UX-led ideation. Through a scenario-based design task, we identify common goals that designers seek model understanding for and pinpoint their model transparency information needs. Our study highlights the pivotal role that UX designers can play in Responsible AI and calls for supporting their understanding of AI limitations through model transparency and interrogation.
RLang: A Declarative Language for Expression Prior Knowledge for Reinforcement Learning
Aug 16, 2022

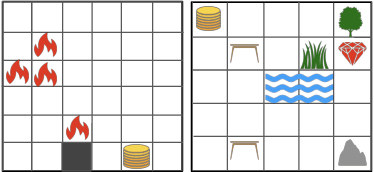
Communicating useful background knowledge to reinforcement learning (RL) agents is an important and effective method for accelerating learning. We introduce RLang, a domain-specific language (DSL) for communicating domain knowledge to an RL agent. Unlike other existing DSLs proposed by the RL community that ground to single elements of a decision-making formalism (e.g., the reward function or policy function), RLang can specify information about every element of a Markov decision process. We define precise syntax and grounding semantics for RLang, and provide a parser implementation that grounds RLang programs to an algorithm-agnostic partial world model and policy that can be exploited by an RL agent. We provide a series of example RLang programs, and demonstrate how different RL methods can exploit the resulting knowledge, including model-free and model-based tabular algorithms, hierarchical approaches, and deep RL algorithms (including both policy gradient and value-based methods).
A New Vision for Smart Objects and the Internet of Things: Mobile Robots and Long-Range UHF RFID Sensor Tags
Jul 09, 2015

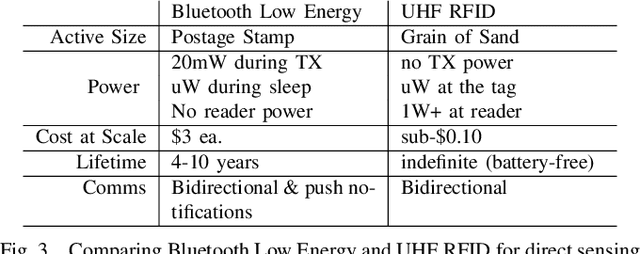
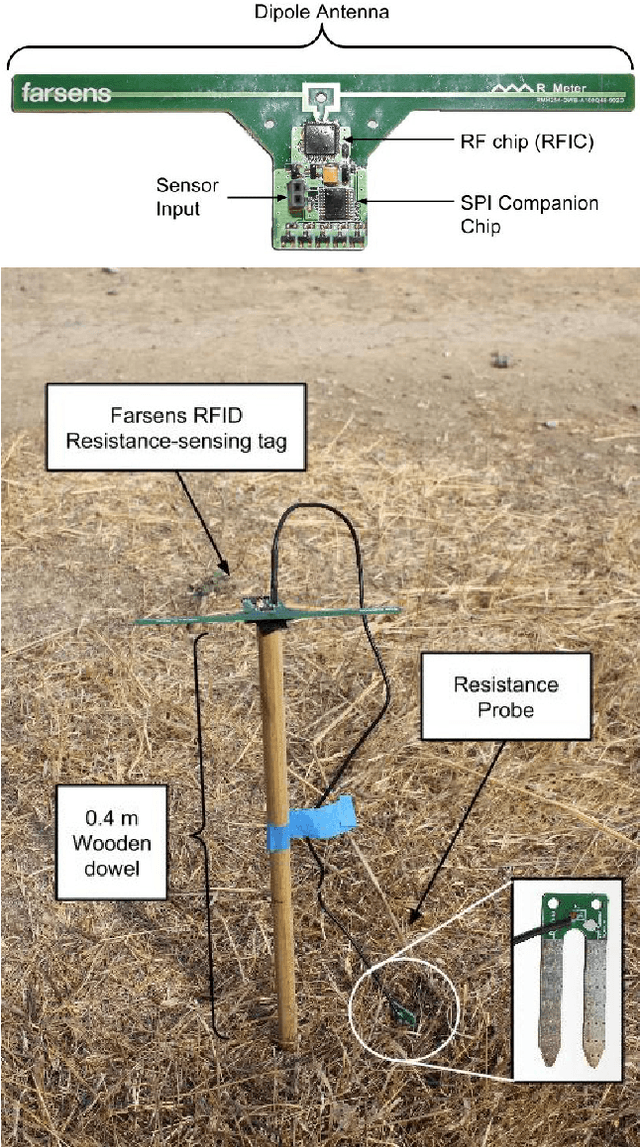
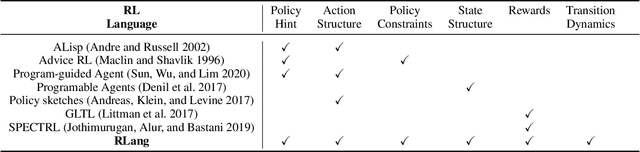
We present a new vision for smart objects and the Internet of Things wherein mobile robots interact with wirelessly-powered, long-range, ultra-high frequency radio frequency identification (UHF RFID) tags outfitted with sensing capabilities. We explore the technology innovations driving this vision by examining recently-commercialized sensor tags that could be affixed-to or embedded-in objects or the environment to yield true embodied intelligence. Using a pair of autonomous mobile robots outfitted with UHF RFID readers, we explore several potential applications where mobile robots interact with sensor tags to perform tasks such as: soil moisture sensing, remote crop monitoring, infrastructure monitoring, water quality monitoring, and remote sensor deployment.