 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving Multimodal Fusion with Hierarchical Mutual Information Maximization for Multimodal Sentiment Analysis
Sep 16, 2021
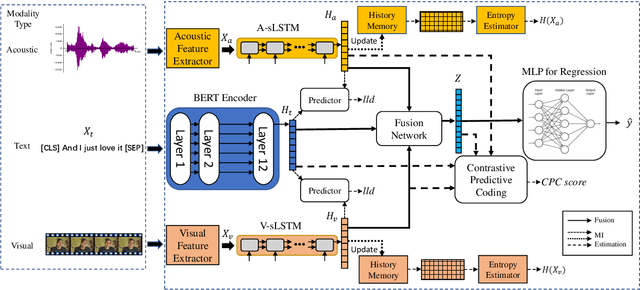
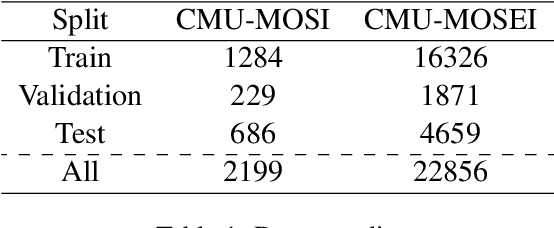
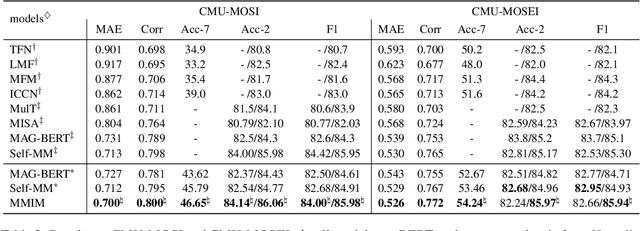
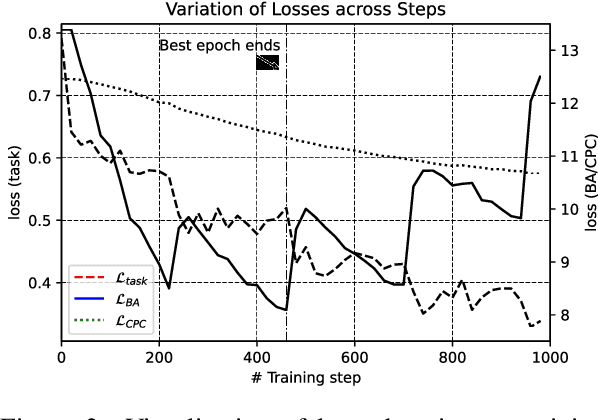
In multimodal sentiment analysis (MSA), the performance of a model highly depends on the quality of synthesized embeddings. These embeddings are generated from the upstream process called multimodal fusion, which aims to extract and combine the input unimodal raw data to produce a richer multimodal representation. Previous work either back-propagates the task loss or manipulates the geometric property of feature spaces to produce favorable fusion results, which neglects the preservation of critical task-related information that flows from input to the fusion results. In this work, we propose a framework named MultiModal InfoMax (MMIM), which hierarchically maximizes the Mutual Information (MI) in unimodal input pairs (inter-modality) and between multimodal fusion result and unimodal input in order to maintain task-related information through multimodal fusion. The framework is jointly trained with the main task (MSA) to improve the performance of the downstream MSA task. To address the intractable issue of MI bounds, we further formulate a set of computationally simple parametric and non-parametric methods to approximate their truth value. Experimental results on the two widely used datasets demonstrate the efficacy of our approach. The implementation of this work is publicly available at https://github.com/declare-lab/Multimodal-Infomax.
Causal Entropy Optimization
Aug 23, 2022
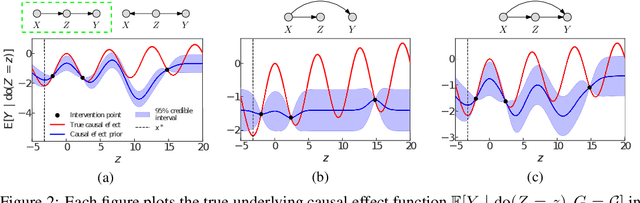

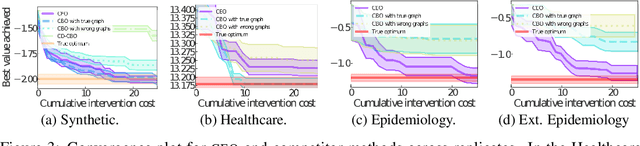
We study the problem of globally optimizing the causal effect on a target variable of an unknown causal graph in which interventions can be performed. This problem arises in many areas of science including biology, operations research and healthcare. We propose Causal Entropy Optimization (CEO), a framework that generalizes Causal Bayesian Optimization (CBO) to account for all sources of uncertainty, including the one arising from the causal graph structure. CEO incorporates the causal structure uncertainty both in the surrogate models for the causal effects and in the mechanism used to select interventions via an information-theoretic acquisition function. The resulting algorithm automatically trades-off structure learning and causal effect optimization, while naturally accounting for observation noise. For various synthetic and real-world structural causal models, CEO achieves faster convergence to the global optimum compared with CBO while also learning the graph. Furthermore, our joint approach to structure learning and causal optimization improves upon sequential, structure-learning-first approaches.
Game State Learning via Game Scene Augmentation
Jul 08, 2022

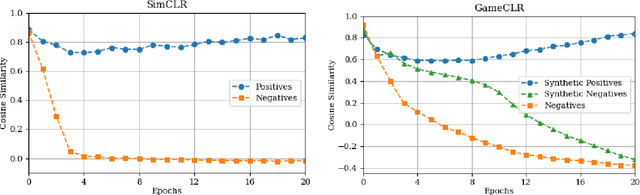
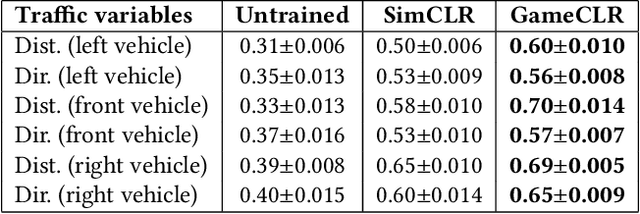
Having access to accurate game state information is of utmost importance for any artificial intelligence task including game-playing, testing, player modeling, and procedural content generation. Self-Supervised Learning (SSL) techniques have shown to be capable of inferring accurate game state information from the high-dimensional pixel input of game footage into compressed latent representations. Contrastive Learning is a popular SSL paradigm where the visual understanding of the game's images comes from contrasting dissimilar and similar game states defined by simple image augmentation methods. In this study, we introduce a new game scene augmentation technique -- named GameCLR -- that takes advantage of the game-engine to define and synthesize specific, highly-controlled renderings of different game states, thereby, boosting contrastive learning performance. We test our GameCLR technique on images of the CARLA driving simulator environment and compare it against the popular SimCLR baseline SSL method. Our results suggest that GameCLR can infer the game's state information from game footage more accurately compared to the baseline. Our proposed approach allows us to conduct game artificial intelligence research by directly utilizing screen pixels as input.
A Scalable Data-Driven Technique for Joint Evacuation Routing and Scheduling Problems
Sep 04, 2022
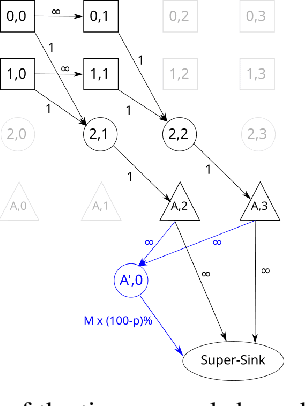
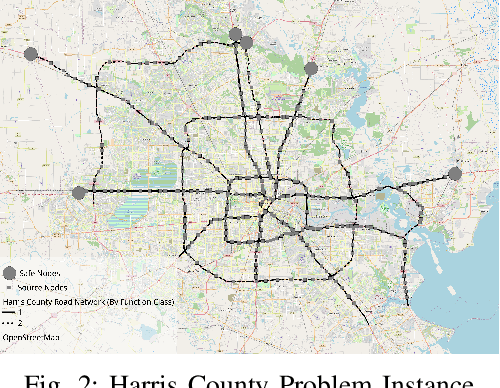
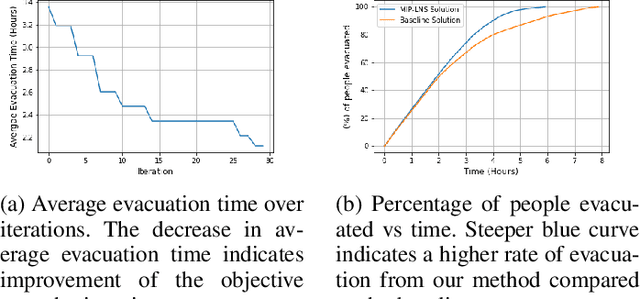
Evacuation planning is a crucial part of disaster management where the goal is to relocate people to safety and minimize casualties. Every evacuation plan has two essential components: routing and scheduling. However, joint optimization of these two components with objectives such as minimizing average evacuation time or evacuation completion time, is a computationally hard problem. To approach it, we present MIP-LNS, a scalable optimization method that combines heuristic search with mathematical optimization and can optimize a variety of objective functions. We use real-world road network and population data from Harris County in Houston, Texas, and apply MIP-LNS to find evacuation routes and schedule for the area. We show that, within a given time limit, our proposed method finds better solutions than existing methods in terms of average evacuation time, evacuation completion time and optimality guarantee of the solutions. We perform agent-based simulations of evacuation in our study area to demonstrate the efficacy and robustness of our solution. We show that our prescribed evacuation plan remains effective even if the evacuees deviate from the suggested schedule upto a certain extent. We also examine how evacuation plans are affected by road failures. Our results show that MIP-LNS can use information regarding estimated deadline of roads to come up with better evacuation plans in terms evacuating more people successfully and conveniently.
An Information-Theoretic Framework for Identifying Age-Related Genes Using Human Dermal Fibroblast Transcriptome Data
Nov 04, 2021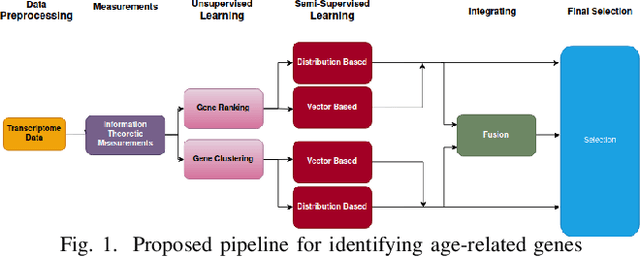
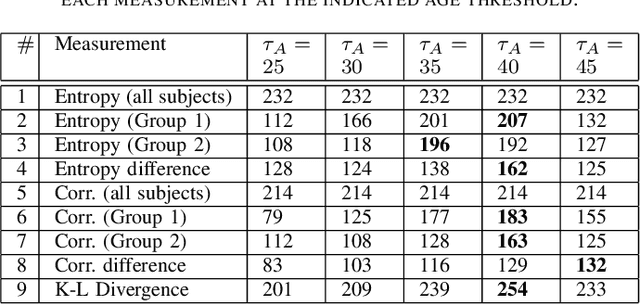
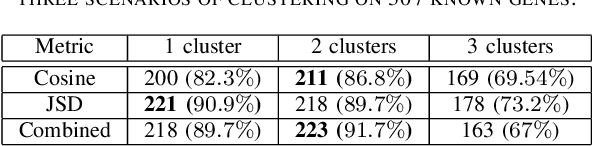

Investigation of age-related genes is of great importance for multiple purposes, for instance, improving our understanding of the mechanism of ageing, increasing life expectancy, age prediction, and other healthcare applications. In his work, starting with a set of 27,142 genes, we develop an information-theoretic framework for identifying genes that are associated with aging by applying unsupervised and semi-supervised learning techniques on human dermal fibroblast gene expression data. First, we use unsupervised learning and apply information-theoretic measures to identify key features for effective representation of gene expression values in the transcriptome data. Using the identified features, we perform clustering on the data. Finally, we apply semi-supervised learning on the clusters using different distance measures to identify novel genes that are potentially associated with aging. Performance assessment for both unsupervised and semi-supervised methods show the effectiveness of the framework.
Bayesian tensor factorization for predicting clinical outcomes using integrated human genetics evidence
Jul 25, 2022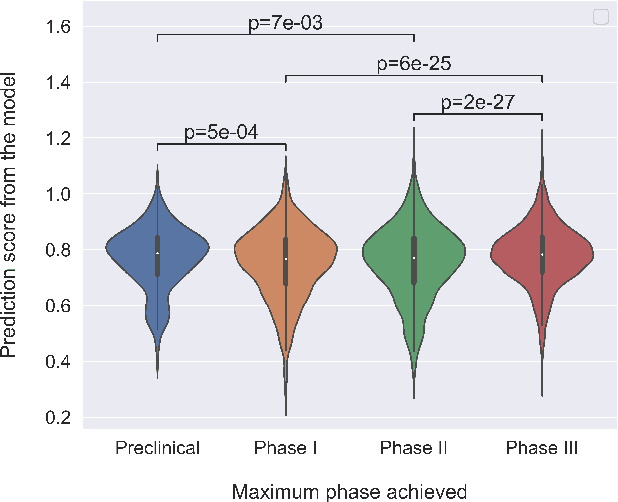

The approval success rate of drug candidates is very low with the majority of failure due to safety and efficacy. Increasingly available high dimensional information on targets, drug molecules and indications provides an opportunity for ML methods to integrate multiple data modalities and better predict clinically promising drug targets. Notably, drug targets with human genetics evidence are shown to have better odds to succeed. However, a recent tensor factorization-based approach found that additional information on targets and indications might not necessarily improve the predictive accuracy. Here we revisit this approach by integrating different types of human genetics evidence collated from publicly available sources to support each target-indication pair. We use Bayesian tensor factorization to show that models incorporating all available human genetics evidence (rare disease, gene burden, common disease) modestly improves the clinical outcome prediction over models using single line of genetics evidence. We provide additional insight into the relative predictive power of different types of human genetics evidence for predicting the success of clinical outcomes.
LFGCF: Light Folksonomy Graph Collaborative Filtering for Tag-Aware Recommendation
Aug 06, 2022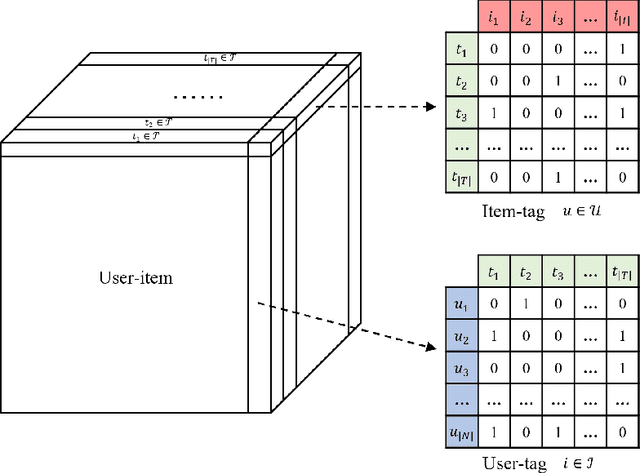
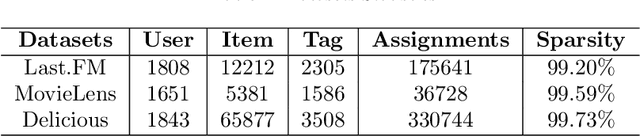
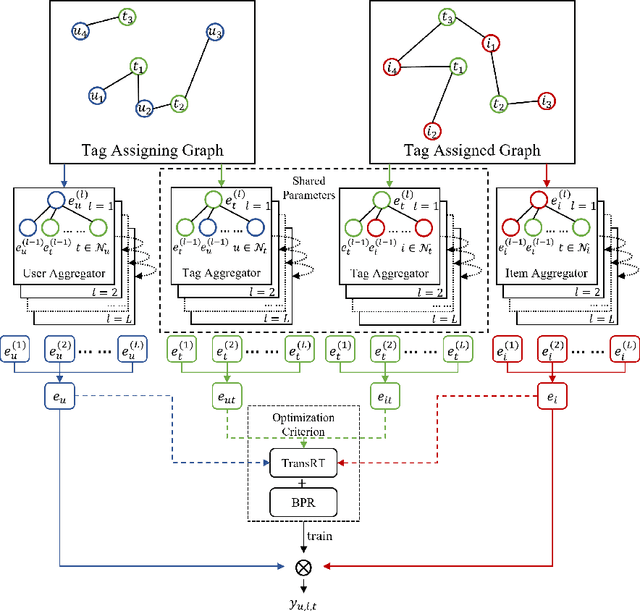
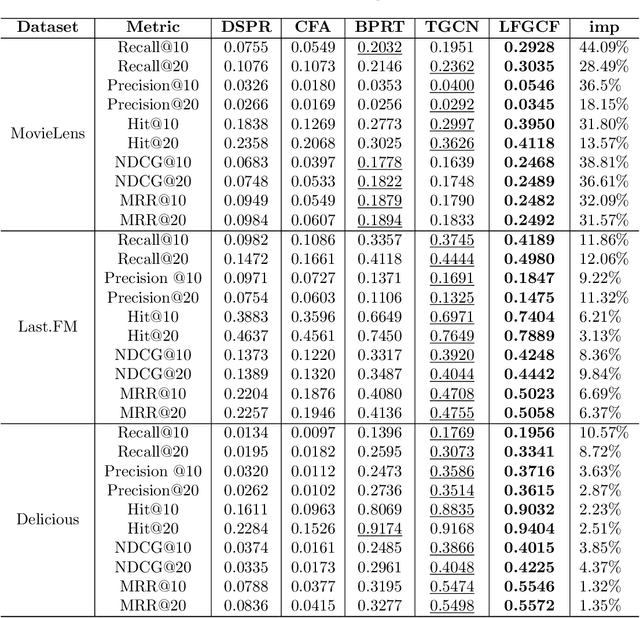
Tag-aware recommendation is a task of predicting a personalized list of items for a user by their tagging behaviors. It is crucial for many applications with tagging capabilities like last.fm or movielens. Recently, many efforts have been devoted to improving Tag-aware recommendation systems (TRS) with Graph Convolutional Networks (GCN), which has become new state-of-the-art for the general recommendation. However, some solutions are directly inherited from GCN without justifications, which is difficult to alleviate the sparsity, ambiguity, and redundancy issues introduced by tags, thus adding to difficulties of training and degrading recommendation performance. In this work, we aim to simplify the design of GCN to make it more concise for TRS. We propose a novel tag-aware recommendation model named Light Folksonomy Graph Collaborative Filtering (LFGCF), which only includes the essential GCN components. Specifically, LFGCF first constructs Folksonomy Graphs from the records of user assigning tags and item getting tagged. Then we leverage the simple design of aggregation to learn the high-order representations on Folksonomy Graphs and use the weighted sum of the embeddings learned at several layers for information updating. We share tags embeddings to bridge the information gap between users and items. Besides, a regularization function named TransRT is proposed to better depict user preferences and item features. Extensive hyperparameters experiments and ablation studies on three real-world datasets show that LFGCF uses fewer parameters and significantly outperforms most baselines for the tag-aware top-N recommendations.
Masked Video Modeling with Correlation-aware Contrastive Learning for Breast Cancer Diagnosis in Ultrasound
Aug 21, 2022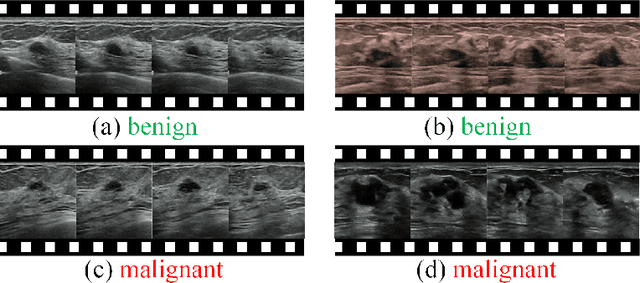
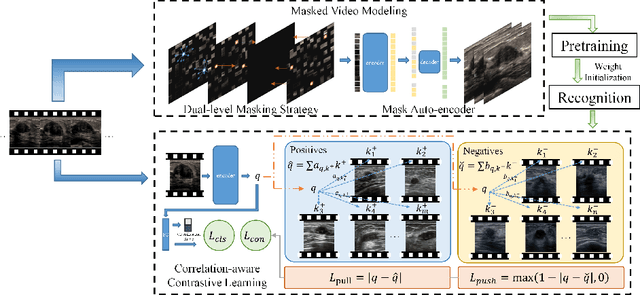
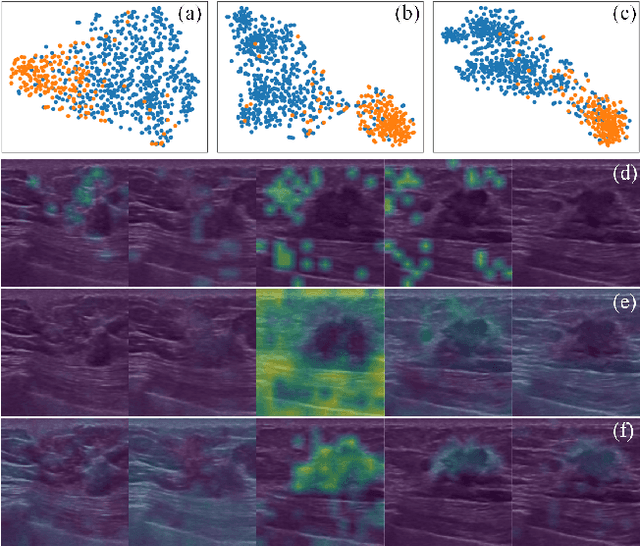
Breast cancer is one of the leading causes of cancer deaths in women. As the primary output of breast screening, breast ultrasound (US) video contains exclusive dynamic information for cancer diagnosis. However, training models for video analysis is non-trivial as it requires a voluminous dataset which is also expensive to annotate. Furthermore, the diagnosis of breast lesion faces unique challenges such as inter-class similarity and intra-class variation. In this paper, we propose a pioneering approach that directly utilizes US videos in computer-aided breast cancer diagnosis. It leverages masked video modeling as pretraning to reduce reliance on dataset size and detailed annotations. Moreover, a correlation-aware contrastive loss is developed to facilitate the identifying of the internal and external relationship between benign and malignant lesions. Experimental results show that our proposed approach achieved promising classification performance and can outperform other state-of-the-art methods.
Transformer Networks for Predictive Group Elevator Control
Aug 15, 2022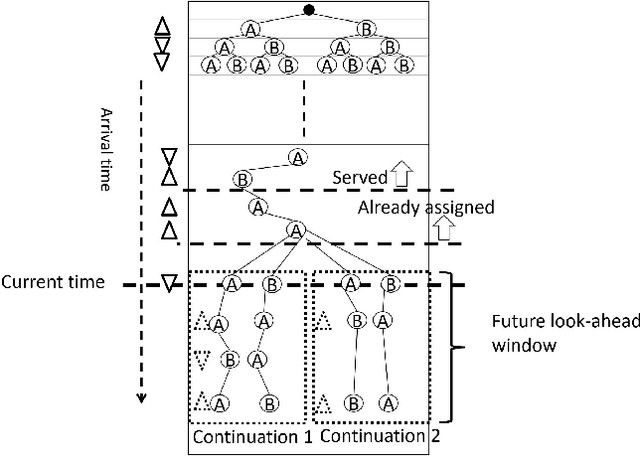
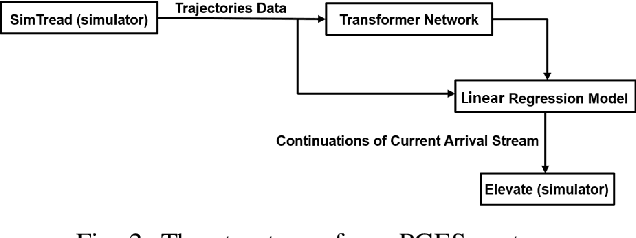
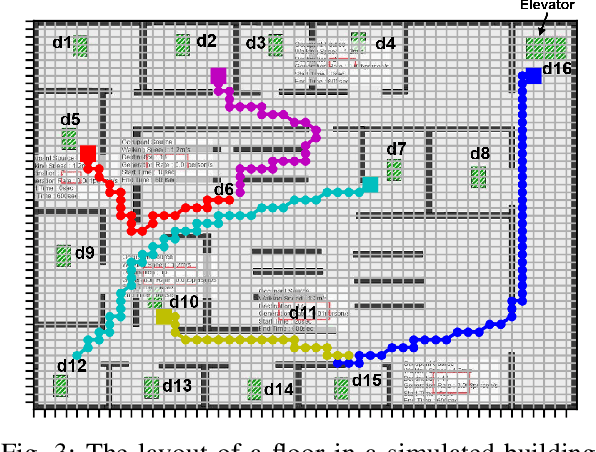
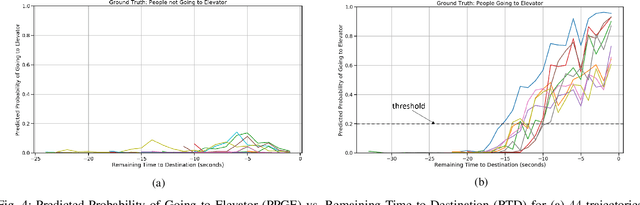
We propose a Predictive Group Elevator Scheduler by using predictive information of passengers arrivals from a Transformer based destination predictor and a linear regression model that predicts remaining time to destinations. Through extensive empirical evaluation, we find that the savings of Average Waiting Time (AWT) could be as high as above 50% for light arrival streams and around 15% for medium arrival streams in afternoon down-peak traffic regimes. Such results can be obtained after carefully setting the Predicted Probability of Going to Elevator (PPGE) threshold, thus avoiding a majority of false predictions for people heading to the elevator, while achieving as high as 80% of true predictive elevator landings as early as after having seen only 60% of the whole trajectory of a passenger.
Neural PCA for Flow-Based Representation Learning
Aug 23, 2022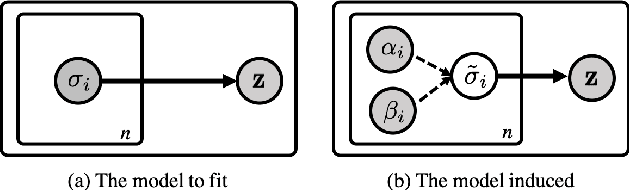
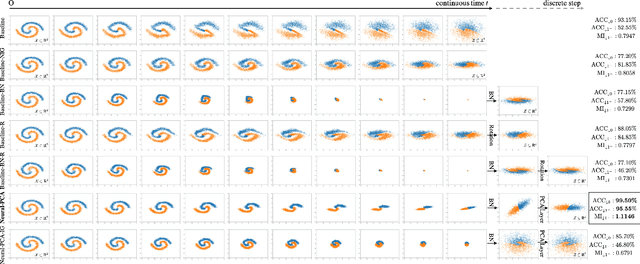
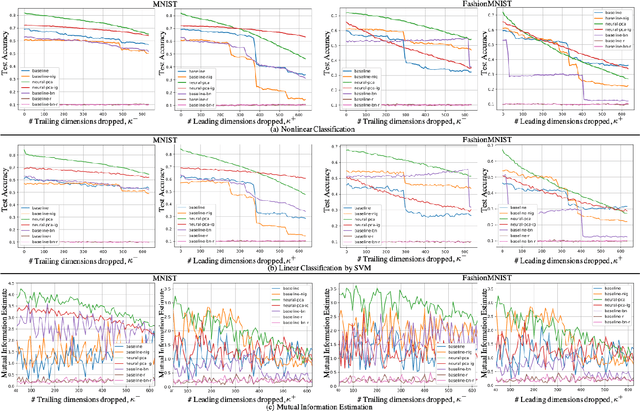
Of particular interest is to discover useful representations solely from observations in an unsupervised generative manner. However, the question of whether existing normalizing flows provide effective representations for downstream tasks remains mostly unanswered despite their strong ability for sample generation and density estimation. This paper investigates this problem for such a family of generative models that admits exact invertibility. We propose Neural Principal Component Analysis (Neural-PCA) that operates in full dimensionality while capturing principal components in \emph{descending} order. Without exploiting any label information, the principal components recovered store the most informative elements in their \emph{leading} dimensions and leave the negligible in the \emph{trailing} ones, allowing for clear performance improvements of $5\%$-$10\%$ in downstream tasks. Such improvements are empirically found consistent irrespective of the number of latent trailing dimensions dropped. Our work suggests that necessary inductive bias be introduced into generative modelling when representation quality is of interest.