 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hard Negatives or False Negatives: Correcting Pooling Bias in Training Neural Ranking Models
Sep 12, 2022
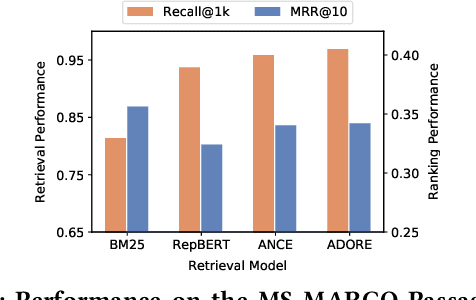
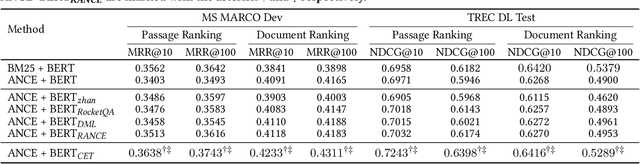
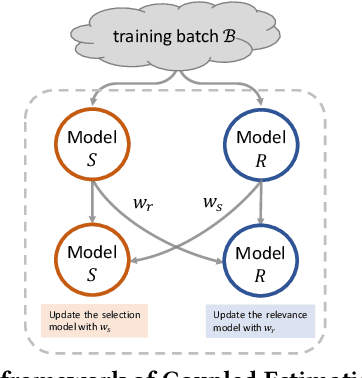
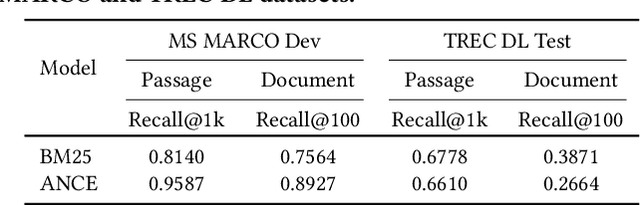
Neural ranking models (NRMs) have become one of the most important techniques in information retrieval (IR). Due to the limitation of relevance labels, the training of NRMs heavily relies on negative sampling over unlabeled data. In general machine learning scenarios, it has shown that training with hard negatives (i.e., samples that are close to positives) could lead to better performance. Surprisingly, we find opposite results from our empirical studies in IR. When sampling top-ranked results (excluding the labeled positives) as negatives from a stronger retriever, the performance of the learned NRM becomes even worse. Based on our investigation, the superficial reason is that there are more false negatives (i.e., unlabeled positives) in the top-ranked results with a stronger retriever, which may hurt the training process; The root is the existence of pooling bias in the dataset constructing process, where annotators only judge and label very few samples selected by some basic retrievers. Therefore, in principle, we can formulate the false negative issue in training NRMs as learning from labeled datasets with pooling bias. To solve this problem, we propose a novel Coupled Estimation Technique (CET) that learns both a relevance model and a selection model simultaneously to correct the pooling bias for training NRMs. Empirical results on three retrieval benchmarks show that NRMs trained with our technique can achieve significant gains on ranking effectiveness against other baseline strategies.
MLRIP: Pre-training a military language representation model with informative factual knowledge and professional knowledge base
Jul 28, 2022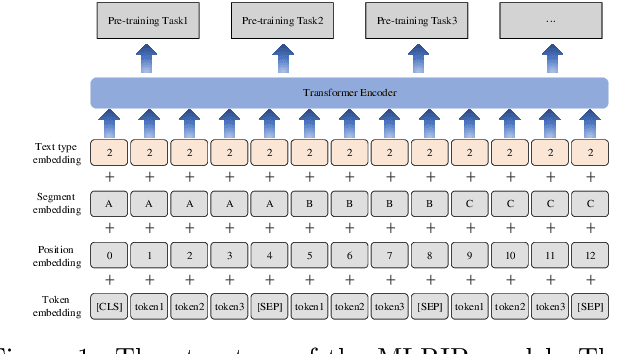

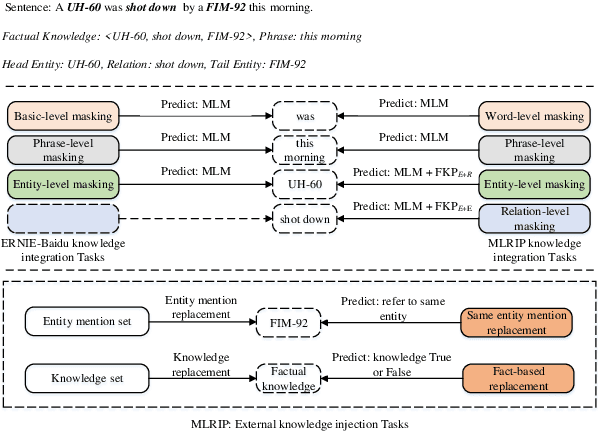

Incorporating prior knowledge into pre-trained language models has proven to be effective for knowledge-driven NLP tasks, such as entity typing and relation extraction. Current pre-training procedures usually inject external knowledge into models by using knowledge masking, knowledge fusion and knowledge replacement. However, factual information contained in the input sentences have not been fully mined, and the external knowledge for injecting have not been strictly checked. As a result, the context information cannot be fully exploited and extra noise will be introduced or the amount of knowledge injected is limited. To address these issues, we propose MLRIP, which modifies the knowledge masking strategies proposed by ERNIE-Baidu, and introduce a two-stage entity replacement strategy. Extensive experiments with comprehensive analyses illustrate the superiority of MLRIP over BERT-based models in military knowledge-driven NLP tasks.
SplitMixer: Fat Trimmed From MLP-like Models
Jul 25, 2022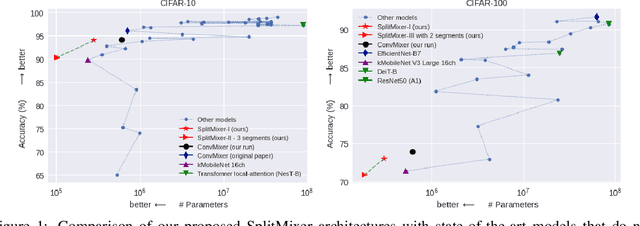
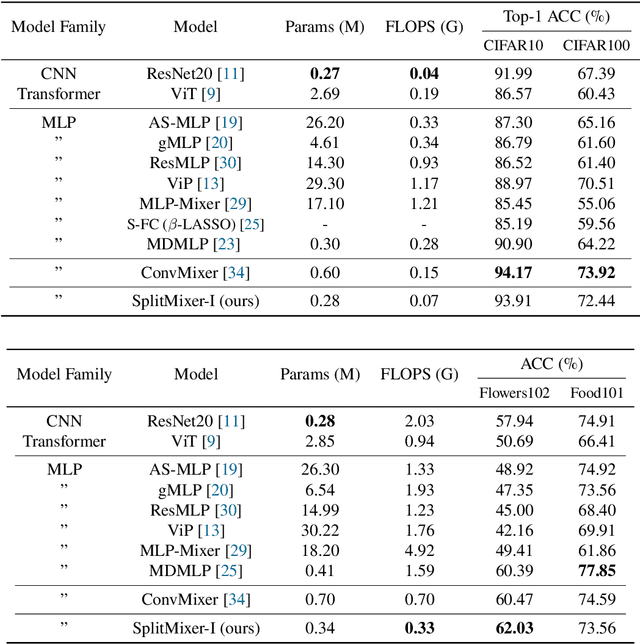
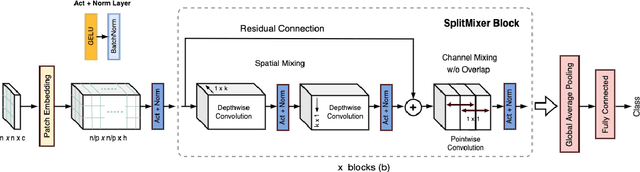
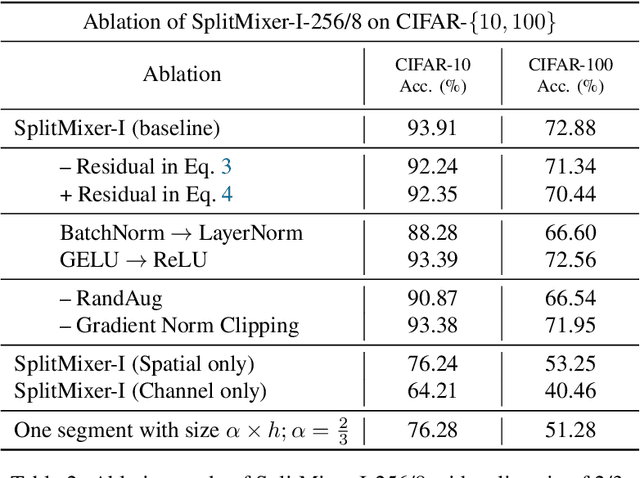
We present SplitMixer, a simple and lightweight isotropic MLP-like architecture, for visual recognition. It contains two types of interleaving convolutional operations to mix information across spatial locations (spatial mixing) and channels (channel mixing). The first one includes sequentially applying two depthwise 1D kernels, instead of a 2D kernel, to mix spatial information. The second one is splitting the channels into overlapping or non-overlapping segments, with or without shared parameters, and applying our proposed channel mixing approaches or 3D convolution to mix channel information. Depending on design choices, a number of SplitMixer variants can be constructed to balance accuracy, the number of parameters, and speed. We show, both theoretically and experimentally, that SplitMixer performs on par with the state-of-the-art MLP-like models while having a significantly lower number of parameters and FLOPS. For example, without strong data augmentation and optimization, SplitMixer achieves around 94% accuracy on CIFAR-10 with only 0.28M parameters, while ConvMixer achieves the same accuracy with about 0.6M parameters. The well-known MLP-Mixer achieves 85.45% with 17.1M parameters. On CIFAR-100 dataset, SplitMixer achieves around 73% accuracy, on par with ConvMixer, but with about 52% fewer parameters and FLOPS. We hope that our results spark further research towards finding more efficient vision architectures and facilitate the development of MLP-like models. Code is available at https://github.com/aliborji/splitmixer.
The Impact of Feature Quantity on Recommendation Algorithm Performance: A Movielens-100K Case Study
Jul 13, 2022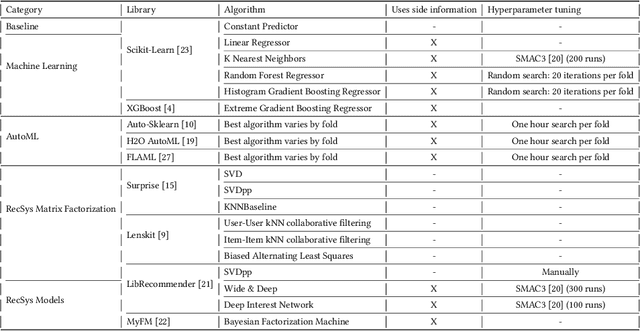
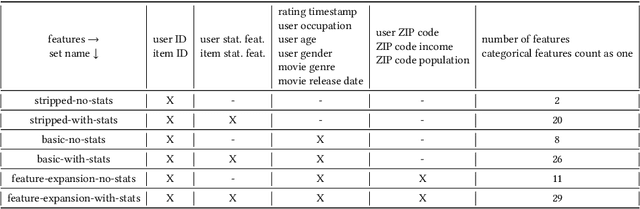
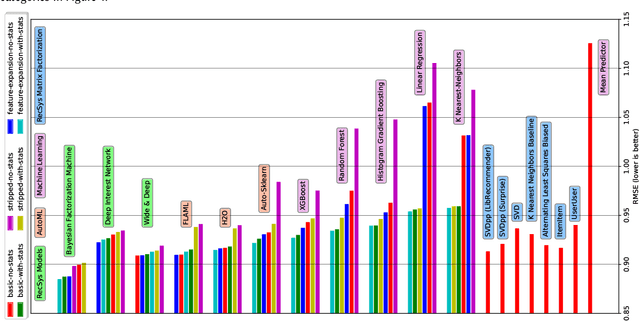
Recent model-based Recommender Systems (RecSys) algorithms emphasize on the use of features, also called side information, in their design similar to algorithms in Machine Learning (ML). In contrast, some of the most popular and traditional algorithms for RecSys solely focus on a given user-item-rating relation without including side information. The goal of this case study is to provide a performance comparison and assessment of RecSys and ML algorithms when side information is included. We chose the Movielens-100K data set since it is a standard for comparing RecSys algorithms. We compared six different feature sets with varying quantities of features which were generated from the baseline data and evaluated on a total of 19 RecSys algorithms, baseline ML algorithms, Automated Machine Learning (AutoML) pipelines, and state-of-the-art RecSys algorithms that incorporate side information. The results show that additional features benefit all algorithms we evaluated. However, the correlation between feature quantity and performance is not monotonous for AutoML and RecSys. In these categories, an analysis of feature importance revealed that the quality of features matters more than quantity. Throughout our experiments, the average performance on the feature set with the lowest number of features is about 6% worse compared to that with the highest in terms of the Root Mean Squared Error. An interesting observation is that AutoML outperforms matrix factorization-based RecSys algorithms when additional features are used. Almost all algorithms that can include side information have higher performance when using the highest quantity of features. In the other cases, the performance difference is negligible (<1%). The results show a clear positive trend for the effect of feature quantity as well as the important effects of feature quality on the evaluated algorithms.
ParaColorizer: Realistic Image Colorization using Parallel Generative Networks
Aug 17, 2022


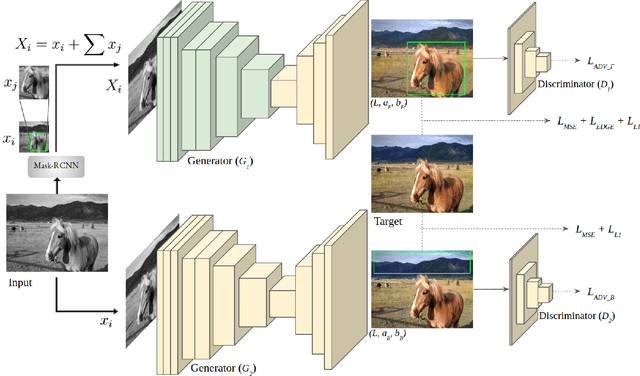
Grayscale image colorization is a fascinating application of AI for information restoration. The inherently ill-posed nature of the problem makes it even more challenging since the outputs could be multi-modal. The learning-based methods currently in use produce acceptable results for straightforward cases but usually fail to restore the contextual information in the absence of clear figure-ground separation. Also, the images suffer from color bleeding and desaturated backgrounds since a single model trained on full image features is insufficient for learning the diverse data modes. To address these issues, we present a parallel GAN-based colorization framework. In our approach, each separately tailored GAN pipeline colorizes the foreground (using object-level features) or the background (using full-image features). The foreground pipeline employs a Residual-UNet with self-attention as its generator trained using the full-image features and the corresponding object-level features from the COCO dataset. The background pipeline relies on full-image features and additional training examples from the Places dataset. We design a DenseFuse-based fusion network to obtain the final colorized image by feature-based fusion of the parallelly generated outputs. We show the shortcomings of the non-perceptual evaluation metrics commonly used to assess multi-modal problems like image colorization and perform extensive performance evaluation of our framework using multiple perceptual metrics. Our approach outperforms most of the existing learning-based methods and produces results comparable to the state-of-the-art. Further, we performed a runtime analysis and obtained an average inference time of 24ms per image.
RényiCL: Contrastive Representation Learning with Skew Rényi Divergence
Aug 12, 2022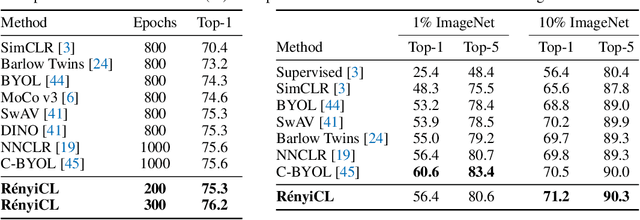
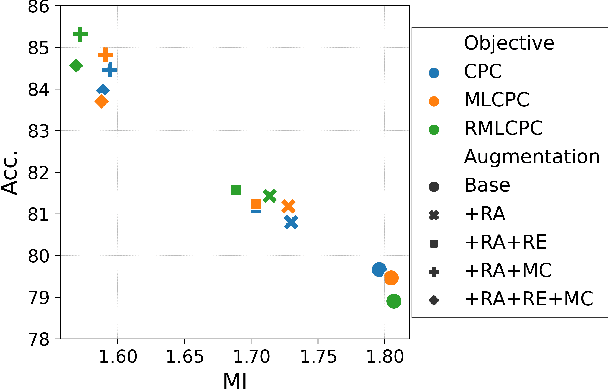
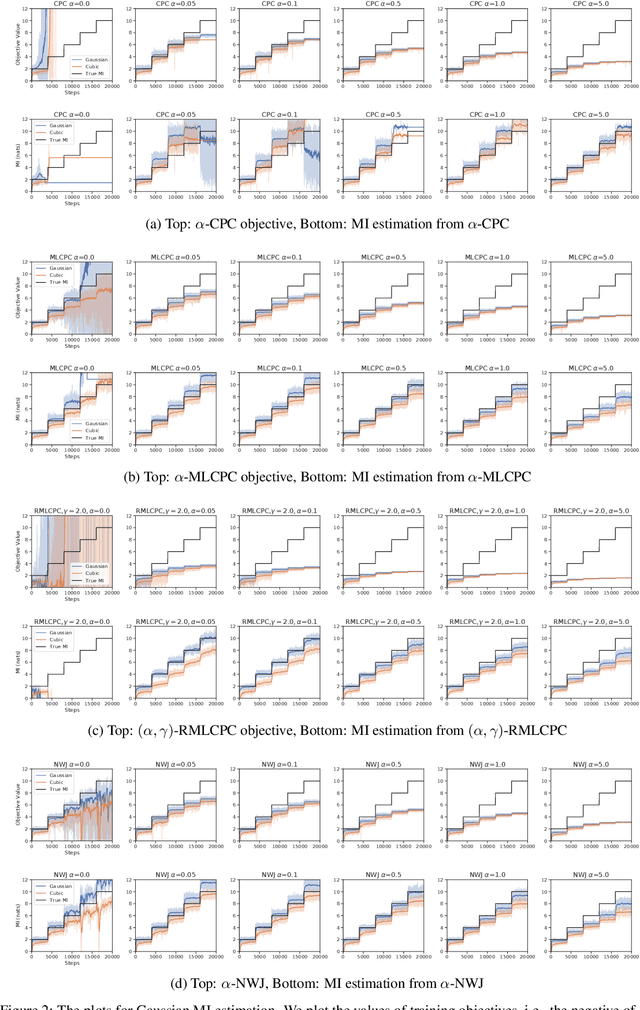
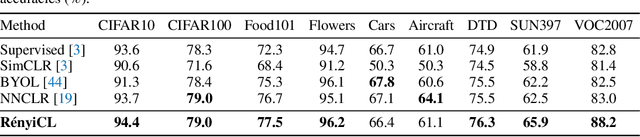
Contrastive representation learning seeks to acquire useful representations by estimating the shared information between multiple views of data. Here, the choice of data augmentation is sensitive to the quality of learned representations: as harder the data augmentations are applied, the views share more task-relevant information, but also task-irrelevant one that can hinder the generalization capability of representation. Motivated by this, we present a new robust contrastive learning scheme, coined R\'enyiCL, which can effectively manage harder augmentations by utilizing R\'enyi divergence. Our method is built upon the variational lower bound of R\'enyi divergence, but a na\"ive usage of a variational method is impractical due to the large variance. To tackle this challenge, we propose a novel contrastive objective that conducts variational estimation of a skew R\'enyi divergence and provide a theoretical guarantee on how variational estimation of skew divergence leads to stable training. We show that R\'enyi contrastive learning objectives perform innate hard negative sampling and easy positive sampling simultaneously so that it can selectively learn useful features and ignore nuisance features. Through experiments on ImageNet, we show that R\'enyi contrastive learning with stronger augmentations outperforms other self-supervised methods without extra regularization or computational overhead. Moreover, we also validate our method on other domains such as graph and tabular, showing empirical gain over other contrastive methods.
Expected Worst Case Regret via Stochastic Sequential Covering
Sep 09, 2022
We study the problem of sequential prediction and online minimax regret with stochastically generated features under a general loss function. We introduce a notion of expected worst case minimax regret that generalizes and encompasses prior known minimax regrets. For such minimax regrets we establish tight upper bounds via a novel concept of stochastic global sequential covering. We show that for a hypothesis class of VC-dimension $\mathsf{VC}$ and $i.i.d.$ generated features of length $T$, the cardinality of the stochastic global sequential covering can be upper bounded with high probability (whp) by $e^{O(\mathsf{VC} \cdot \log^2 T)}$. We then improve this bound by introducing a new complexity measure called the Star-Littlestone dimension, and show that classes with Star-Littlestone dimension $\mathsf{SL}$ admit a stochastic global sequential covering of order $e^{O(\mathsf{SL} \cdot \log T)}$. We further establish upper bounds for real valued classes with finite fat-shattering numbers. Finally, by applying information-theoretic tools of the fixed design minimax regrets, we provide lower bounds for the expected worst case minimax regret. We demonstrate the effectiveness of our approach by establishing tight bounds on the expected worst case minimax regrets for logarithmic loss and general mixable losses.
Continuous locomotion mode recognition and gait phase estimation based on a shank-mounted IMU with artificial neural networks
Aug 01, 2022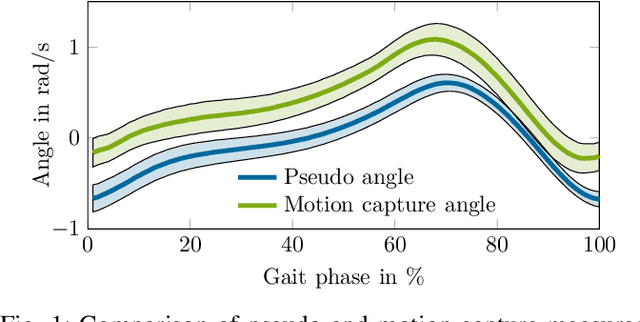

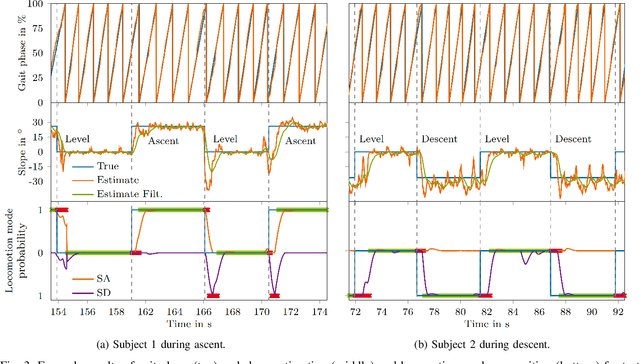

To improve the control of wearable robotics for gait assistance, we present an approach for continuous locomotion mode recognition as well as gait phase and stair slope estimation based on artificial neural networks that include time history information. The input features consist exclusively of processed variables that can be measured with a single shank-mounted inertial measurement unit. We introduce a wearable device to acquire real-world environment test data to demonstrate the performance and the robustness of the approach. Mean absolute error (gait phase, stair slope) and accuracy (locomotion mode) were determined for steady level walking and steady stair ambulation. Robustness was assessed using test data from different sensor hardware, sensor fixations, ambulation environments and subjects. The mean absolute error from the steady gait test data for the gait phase was 2.0-3.5 % for gait phase estimation and 3.3-3.8{\deg} for stair slope estimation. The accuracy of classifying the correct locomotion mode on the test data with the utilization of time history information was in between 98.51 % and 99.67 %. Results show high performance and robustness for continuously predicting gait phase, stair slope and locomotion mode during steady gait. As hypothesized, time history information improves the locomotion mode recognition. However, while the gait phase estimation performed well for untrained transitions between locomotion modes, our qualitative analysis revealed that it may be beneficial to include transition data into the training of the neural network to improve the prediction of the slope and the locomotion mode. Our results suggest that artificial neural networks could be used for high level control of wearable lower limb robotics.
Invariant Information Bottleneck for Domain Generalization
Jun 14, 2021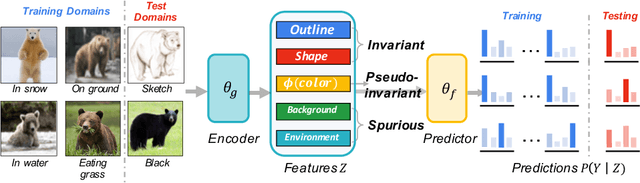
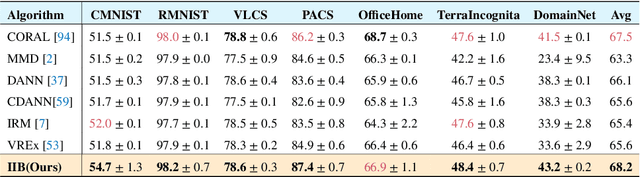
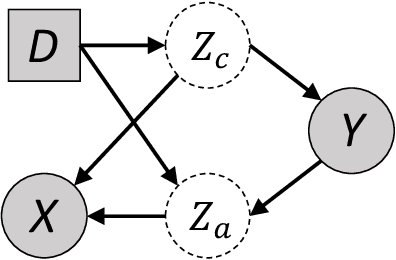
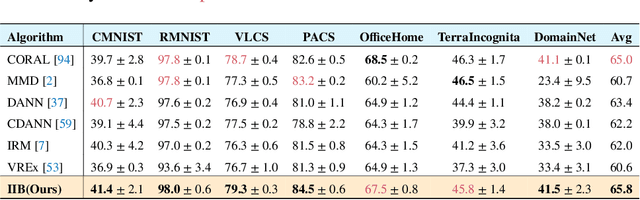
The main challenge for domain generalization (DG) is to overcome the potential distributional shift between multiple training domains and unseen test domains. One popular class of DG algorithms aims to learn representations that have an invariant causal relation across the training domains. However, certain features, called \emph{pseudo-invariant features}, may be invariant in the training domain but not the test domain and can substantially decreases the performance of existing algorithms. To address this issue, we propose a novel algorithm, called Invariant Information Bottleneck (IIB), that learns a minimally sufficient representation that is invariant across training and testing domains. By minimizing the mutual information between the representation and inputs, IIB alleviates its reliance on pseudo-invariant features, which is desirable for DG. To verify the effectiveness of the IIB principle, we conduct extensive experiments on large-scale DG benchmarks. The results show that IIB outperforms invariant learning baseline (e.g. IRM) by an average of 2.8\% and 3.8\% accuracy over two evaluation metrics.
LaTTe: Language Trajectory TransformEr
Aug 09, 2022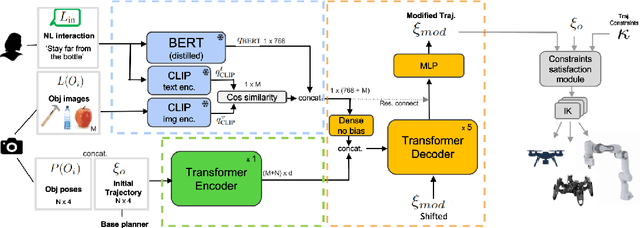
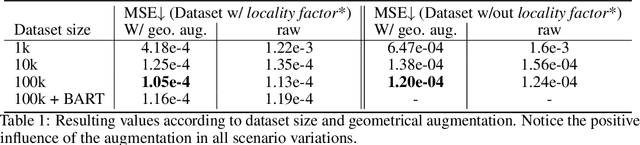
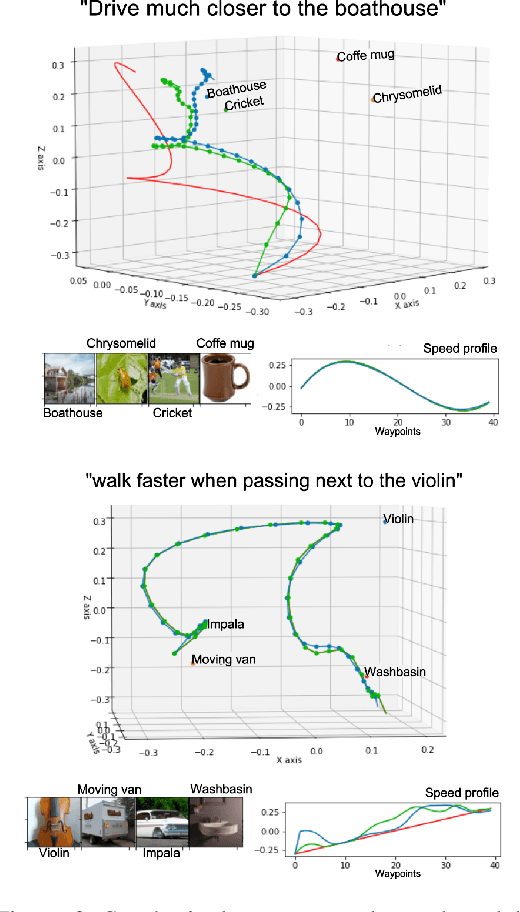

Natural language is one of the most intuitive ways to express human intent. However, translating instructions and commands towards robotic motion generation, and deployment in the real world, is far from being an easy task. Indeed, combining robotic's inherent low-level geometric and kinodynamic constraints with human's high-level semantic information reinvigorates and raises new challenges to the task-design problem -- typically leading to task or hardware specific solutions with a static set of action targets and commands. This work instead proposes a flexible language-based framework that allows to modify generic 3D robotic trajectories using language commands with reduced constraints about prior task or robot information. By taking advantage of pre-trained language models, we employ an auto-regressive transformer to map natural language inputs and contextual images into changes in 3D trajectories. We show through simulations and real-life experiments that the model can successfully follow human intent, modifying the shape and speed of trajectories for multiple robotic platforms and contexts. This study takes a step into building large pre-trained foundational models for robotics and shows how such models can create more intuitive and flexible interactions between human and machines. Codebase available at: https://github.com/arthurfenderbucker/NL_trajectory_reshaper.