 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Maximal Independent Vertex Set applied to Graph Pooling
Aug 02, 2022
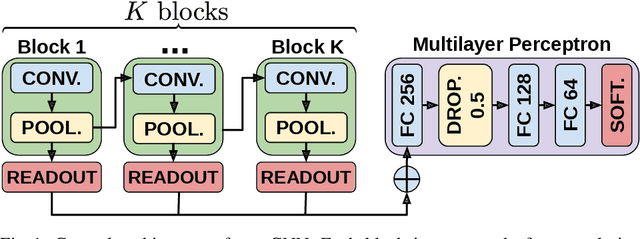
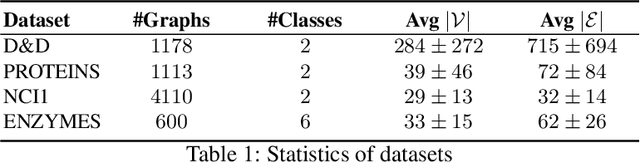
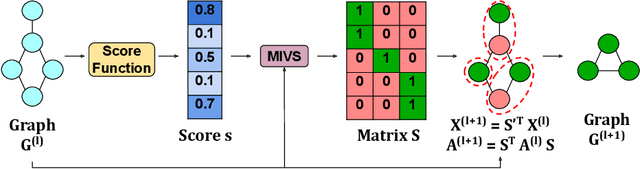

Convolutional neural networks (CNN) have enabled major advances in image classification through convolution and pooling. In particular, image pooling transforms a connected discrete grid into a reduced grid with the same connectivity and allows reduction functions to take into account all the pixels of an image. However, a pooling satisfying such properties does not exist for graphs. Indeed, some methods are based on a vertex selection step which induces an important loss of information. Other methods learn a fuzzy clustering of vertex sets which induces almost complete reduced graphs. We propose to overcome both problems using a new pooling method, named MIVSPool. This method is based on a selection of vertices called surviving vertices using a Maximal Independent Vertex Set (MIVS) and an assignment of the remaining vertices to the survivors. Consequently, our method does not discard any vertex information nor artificially increase the density of the graph. Experimental results show an increase in accuracy for graph classification on various standard datasets.
Information Extraction from Visually Rich Documents with Font Style Embeddings
Nov 07, 2021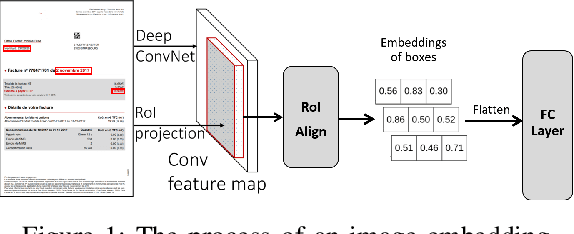
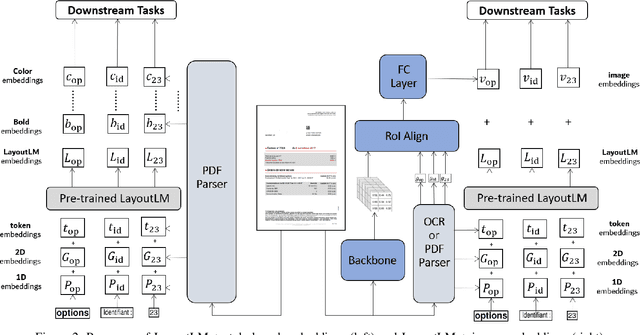

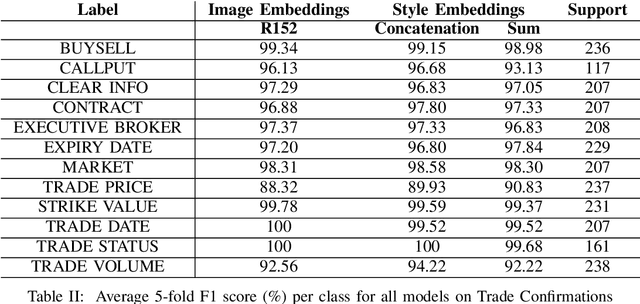
Information extraction (IE) from documents is an intensive area of research with a large set of industrial applications. Current state-of-the-art methods focus on scanned documents with approaches combining computer vision, natural language processing and layout representation. We propose to challenge the usage of computer vision in the case where both token style and visual representation are available (i.e native PDF documents). Our experiments on three real-world complex datasets demonstrate that using token style attributes based embedding instead of a raw visual embedding in LayoutLM model is beneficial. Depending on the dataset, such an embedding yields an improvement of 0.18% to 2.29% in the weighted F1-score with a decrease of 30.7% in the final number of trainable parameters of the model, leading to an improvement in both efficiency and effectiveness.
Graph Information Bottleneck
Oct 24, 2020
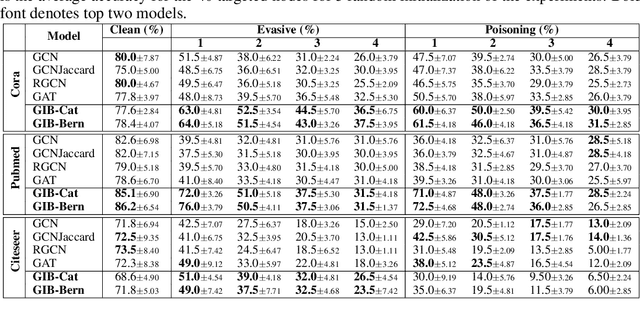
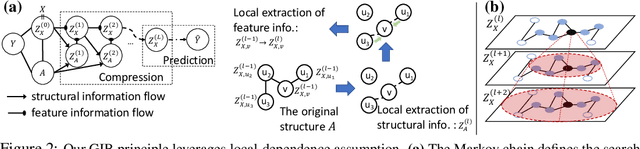

Representation learning of graph-structured data is challenging because both graph structure and node features carry important information. Graph Neural Networks (GNNs) provide an expressive way to fuse information from network structure and node features. However, GNNs are prone to adversarial attacks. Here we introduce Graph Information Bottleneck (GIB), an information-theoretic principle that optimally balances expressiveness and robustness of the learned representation of graph-structured data. Inheriting from the general Information Bottleneck (IB), GIB aims to learn the minimal sufficient representation for a given task by maximizing the mutual information between the representation and the target, and simultaneously constraining the mutual information between the representation and the input data. Different from the general IB, GIB regularizes the structural as well as the feature information. We design two sampling algorithms for structural regularization and instantiate the GIB principle with two new models: GIB-Cat and GIB-Bern, and demonstrate the benefits by evaluating the resilience to adversarial attacks. We show that our proposed models are more robust than state-of-the-art graph defense models. GIB-based models empirically achieve up to 31% improvement with adversarial perturbation of the graph structure as well as node features.
Classifying with Uncertain Data Envelopment Analysis
Sep 02, 2022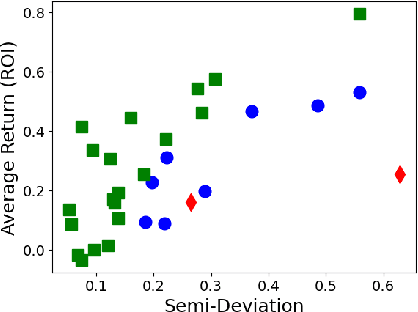
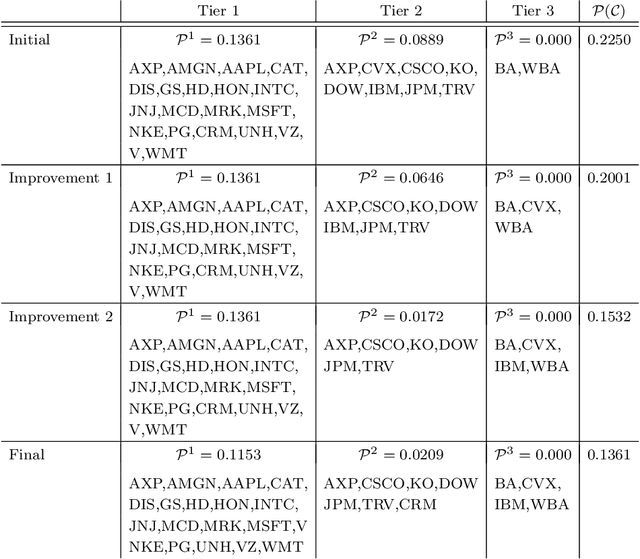
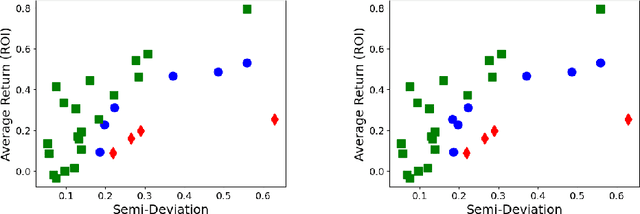
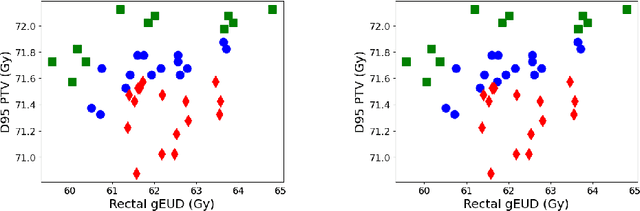
Classifications organize entities into categories that identify similarities within a category and discern dissimilarities among categories, and they powerfully classify information in support of analysis. We propose a new classification scheme premised on the reality of imperfect data. Our computational model uses uncertain data envelopment analysis to define a classification's proximity to equitable efficiency, which is an aggregate measure of intra-similarity within a classification's categories. Our classification process has two overriding computational challenges, those being a loss of convexity and a combinatorially explosive search space. We overcome the first by establishing lower and upper bounds on the proximity value, and then by searching this range with a first-order algorithm. We overcome the second by adapting the p-median problem to initiate our exploration, and by then employing an iterative neighborhood search to finalize a classification. We conclude by classifying the thirty stocks in the Dow Jones Industrial average into performant tiers and by classifying prostate treatments into clinically effectual categories.
Defining Cases and Variants for Object-Centric Event Data
Aug 05, 2022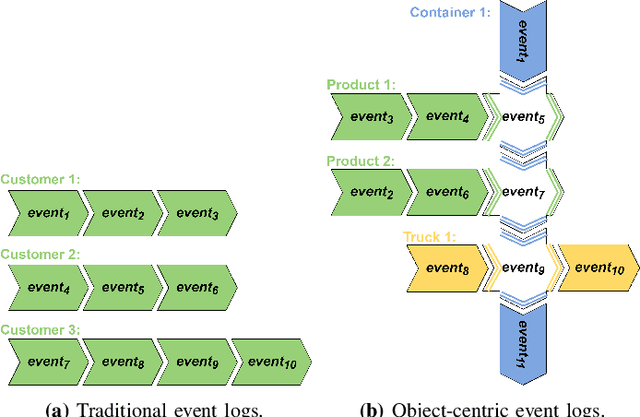
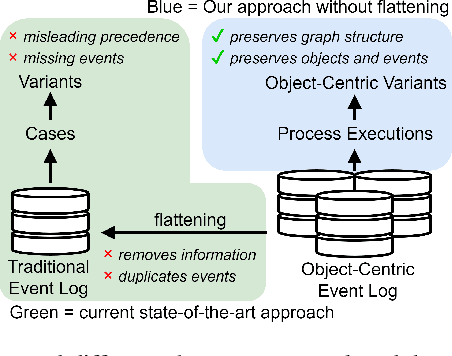
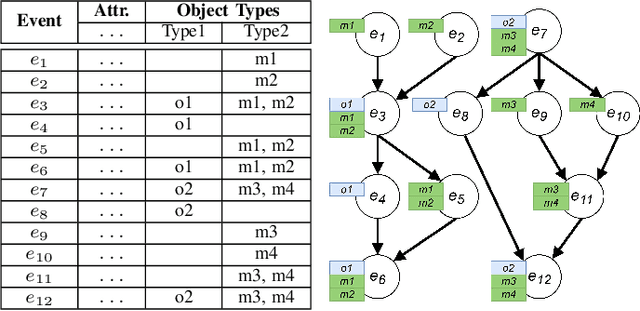
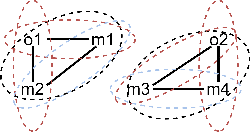
The execution of processes leaves traces of event data in information systems. These event data can be analyzed through process mining techniques. For traditional process mining techniques, one has to associate each event with exactly one object, e.g., the company's customer. Events related to one object form an event sequence called a case. A case describes an end-to-end run through a process. The cases contained in event data can be used to discover a process model, detect frequent bottlenecks, or learn predictive models. However, events encountered in real-life information systems, e.g., ERP systems, can often be associated with multiple objects. The traditional sequential case concept falls short of these object-centric event data as these data exhibit a graph structure. One might force object-centric event data into the traditional case concept by flattening it. However, flattening manipulates the data and removes information. Therefore, a concept analogous to the case concept of traditional event logs is necessary to enable the application of different process mining tasks on object-centric event data. In this paper, we introduce the case concept for object-centric process mining: process executions. These are graph-based generalizations of cases as considered in traditional process mining. Furthermore, we provide techniques to extract process executions. Based on these executions, we determine equivalent process behavior with respect to an attribute using graph isomorphism. Equivalent process executions with respect to the event's activity are object-centric variants, i.e., a generalization of variants in traditional process mining. We provide a visualization technique for object-centric variants. The contribution's scalability and efficiency are extensively evaluated. Furthermore, we provide a case study showing the most frequent object-centric variants of a real-life event log.
GReS: Graphical Cross-domain Recommendation for Supply Chain Platform
Sep 02, 2022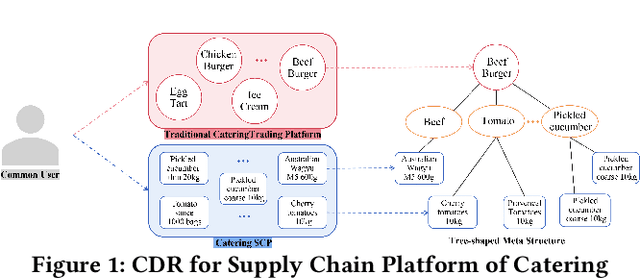
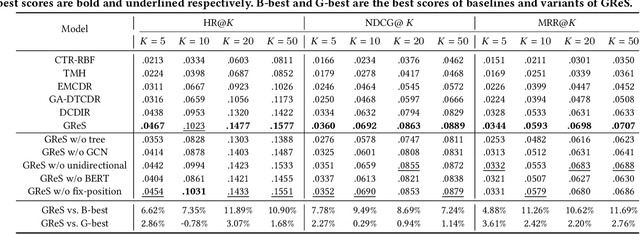
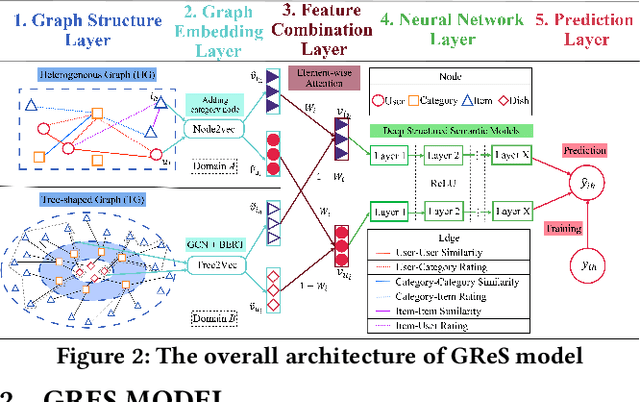
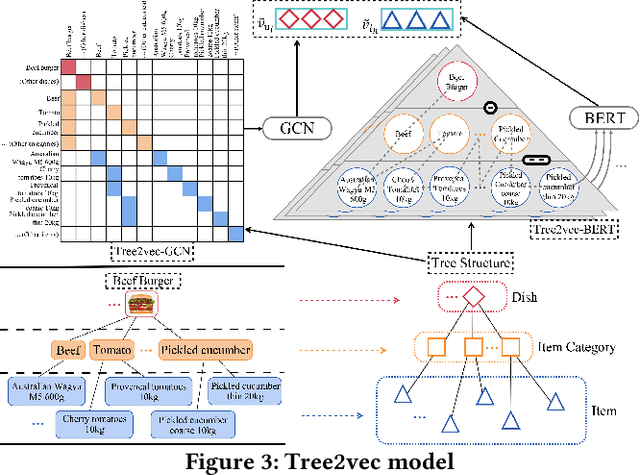
Supply Chain Platforms (SCPs) provide downstream industries with numerous raw materials. Compared with traditional e-commerce platforms, data in SCPs is more sparse due to limited user interests. To tackle the data sparsity problem, one can apply Cross-Domain Recommendation (CDR) which improves the recommendation performance of the target domain with the source domain information. However, applying CDR to SCPs directly ignores the hierarchical structure of commodities in SCPs, which reduce the recommendation performance. To leverage this feature, in this paper, we take the catering platform as an example and propose GReS, a graphical cross-domain recommendation model. The model first constructs a tree-shaped graph to represent the hierarchy of different nodes of dishes and ingredients, and then applies our proposed Tree2vec method combining GCN and BERT models to embed the graph for recommendations. Experimental results on a commercial dataset show that GReS significantly outperforms state-of-the-art methods in Cross-Domain Recommendation for Supply Chain Platforms.
Clustering units in neural networks: upstream vs downstream information
Mar 22, 2022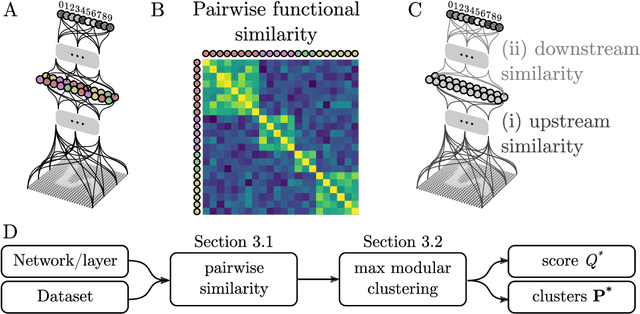
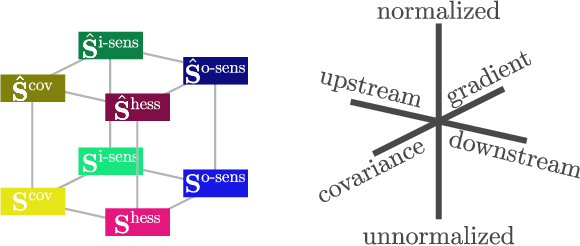
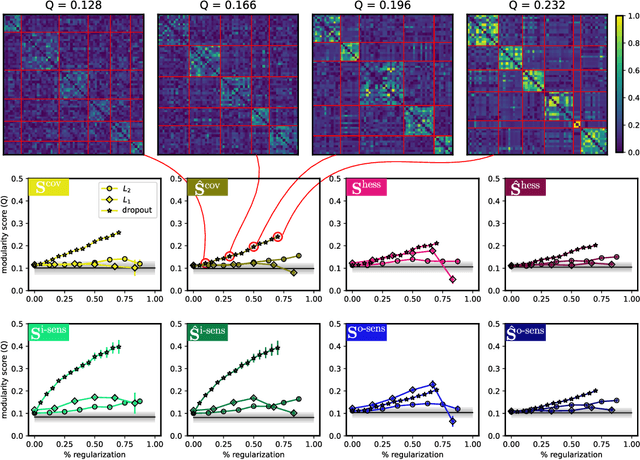
It has been hypothesized that some form of "modular" structure in artificial neural networks should be useful for learning, compositionality, and generalization. However, defining and quantifying modularity remains an open problem. We cast the problem of detecting functional modules into the problem of detecting clusters of similar-functioning units. This begs the question of what makes two units functionally similar. For this, we consider two broad families of methods: those that define similarity based on how units respond to structured variations in inputs ("upstream"), and those based on how variations in hidden unit activations affect outputs ("downstream"). We conduct an empirical study quantifying modularity of hidden layer representations of simple feedforward, fully connected networks, across a range of hyperparameters. For each model, we quantify pairwise associations between hidden units in each layer using a variety of both upstream and downstream measures, then cluster them by maximizing their "modularity score" using established tools from network science. We find two surprising results: first, dropout dramatically increased modularity, while other forms of weight regularization had more modest effects. Second, although we observe that there is usually good agreement about clusters within both upstream methods and downstream methods, there is little agreement about the cluster assignments across these two families of methods. This has important implications for representation-learning, as it suggests that finding modular representations that reflect structure in inputs (e.g. disentanglement) may be a distinct goal from learning modular representations that reflect structure in outputs (e.g. compositionality).
Bridging Music and Text with Crowdsourced Music Comments: A Sequence-to-Sequence Framework for Thematic Music Comments Generation
Sep 05, 2022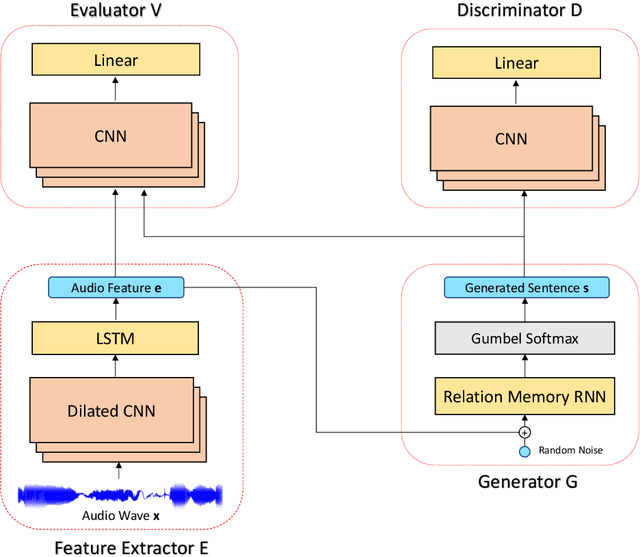
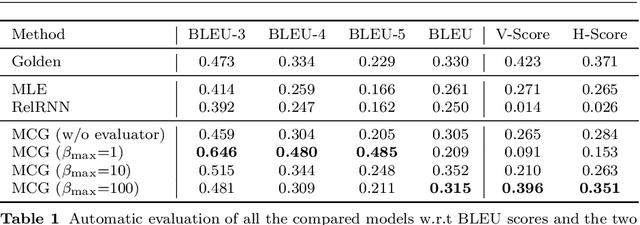
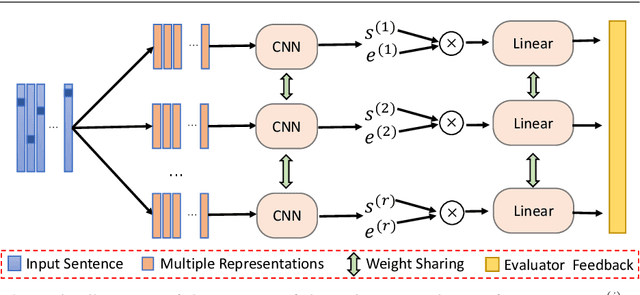

We consider a novel task of automatically generating text descriptions of music. Compared with other well-established text generation tasks such as image caption, the scarcity of well-paired music and text datasets makes it a much more challenging task. In this paper, we exploit the crowd-sourced music comments to construct a new dataset and propose a sequence-to-sequence model to generate text descriptions of music. More concretely, we use the dilated convolutional layer as the basic component of the encoder and a memory based recurrent neural network as the decoder. To enhance the authenticity and thematicity of generated texts, we further propose to fine-tune the model with a discriminator as well as a novel topic evaluator. To measure the quality of generated texts, we also propose two new evaluation metrics, which are more aligned with human evaluation than traditional metrics such as BLEU. Experimental results verify that our model is capable of generating fluent and meaningful comments while containing thematic and content information of the original music.
Multi-channel Nuclear Norm Minus Frobenius Norm Minimization for Color Image Denoising
Sep 16, 2022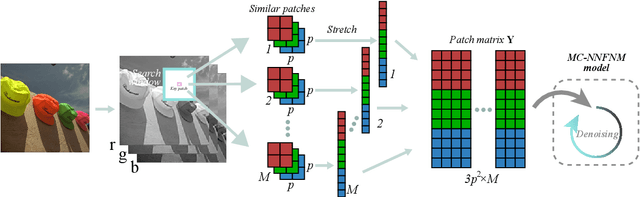
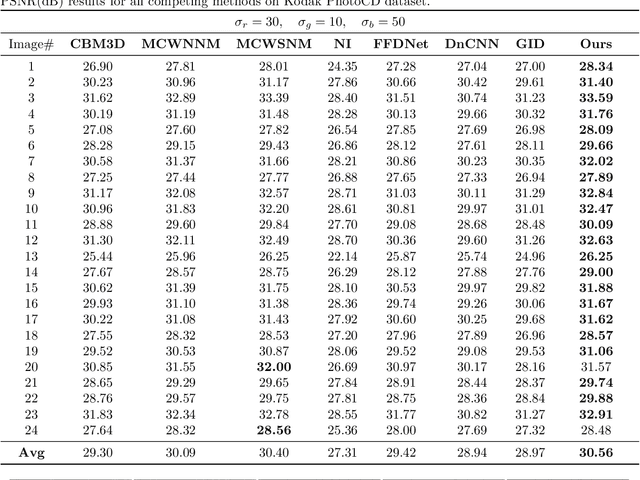
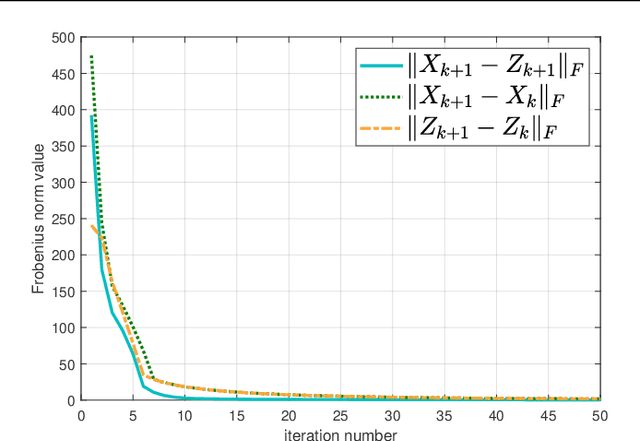
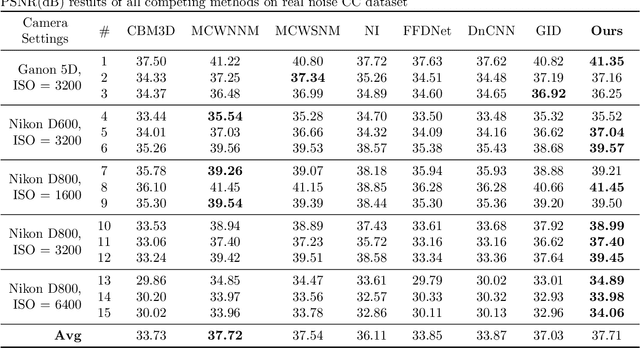
Color image denoising is frequently encountered in various image processing and computer vision tasks. One traditional strategy is to convert the RGB image to a less correlated color space and denoise each channel of the new space separately. However, such a strategy can not fully exploit the correlated information between channels and is inadequate to obtain satisfactory results. To address this issue, this paper proposes a new multi-channel optimization model for color image denoising under the nuclear norm minus Frobenius norm minimization framework. Specifically, based on the block-matching, the color image is decomposed into overlapping RGB patches. For each patch, we stack its similar neighbors to form the corresponding patch matrix. The proposed model is performed on the patch matrix to recover its noise-free version. During the recovery process, a) a weight matrix is introduced to fully utilize the noise difference between channels; b) the singular values are shrunk adaptively without additionally assigning weights. With them, the proposed model can achieve promising results while keeping simplicity. To solve the proposed model, an accurate and effective algorithm is built based on the alternating direction method of multipliers framework. The solution of each updating step can be analytically expressed in closed-from. Rigorous theoretical analysis proves the solution sequences generated by the proposed algorithm converge to their respective stationary points. Experimental results on both synthetic and real noise datasets demonstrate the proposed model outperforms state-of-the-art models.
Automatic Tumor Segmentation via False Positive Reduction Network for Whole-Body Multi-Modal PET/CT Images
Sep 16, 2022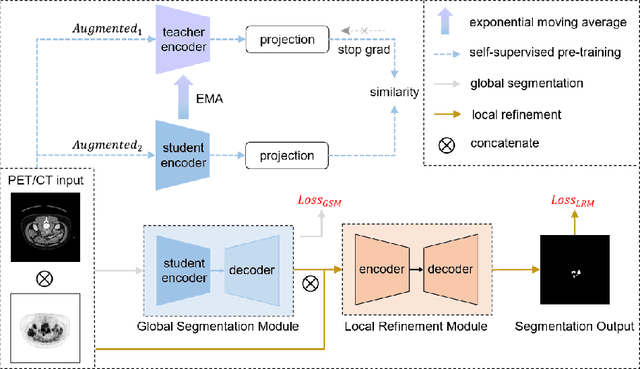
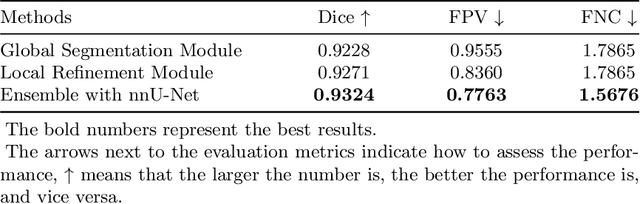
Multi-modality Fluorodeoxyglucose (FDG) positron emission tomography / computed tomography (PET/CT) has been routinely used in the assessment of common cancers, such as lung cancer, lymphoma, and melanoma. This is mainly attributed to the fact that PET/CT combines the high sensitivity for tumor detection of PET and anatomical information from CT. In PET/CT image assessment, automatic tumor segmentation is an important step, and in recent years, deep learning based methods have become the state-of-the-art. Unfortunately, existing methods tend to over-segment the tumor regions and include regions such as the normal high uptake organs, inflammation, and other infections. In this study, we introduce a false positive reduction network to overcome this limitation. We firstly introduced a self-supervised pre-trained global segmentation module to coarsely delineate the candidate tumor regions using a self-supervised pre-trained encoder. The candidate tumor regions were then refined by removing false positives via a local refinement module. Our experiments with the MICCAI 2022 Automated Lesion Segmentation in Whole-Body FDG-PET/CT (AutoPET) challenge dataset showed that our method achieved a dice score of 0.9324 with the preliminary testing data and was ranked 1st place in dice on the leaderboard. Our method was also ranked in the top 7 methods on the final testing data, the final ranking will be announced during the 2022 MICCAI AutoPET workshop. Our code is available at: https://github.com/YigePeng/AutoPET_False_Positive_Reduction.