 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SecretGen: Privacy Recovery on Pre-Trained Models via Distribution Discrimination
Jul 25, 2022
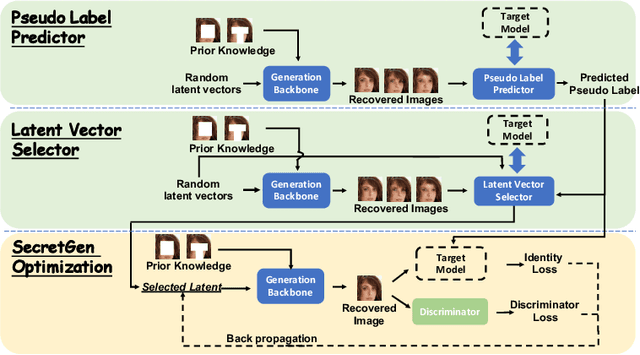

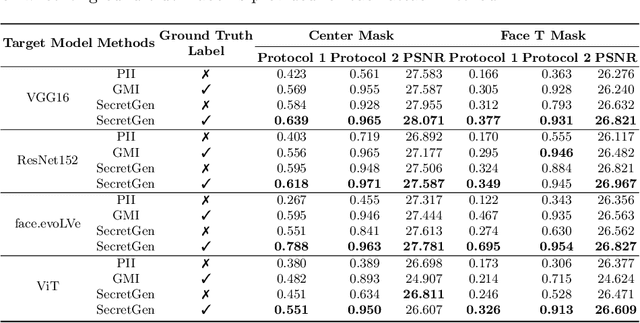
Transfer learning through the use of pre-trained models has become a growing trend for the machine learning community. Consequently, numerous pre-trained models are released online to facilitate further research. However, it raises extensive concerns on whether these pre-trained models would leak privacy-sensitive information of their training data. Thus, in this work, we aim to answer the following questions: "Can we effectively recover private information from these pre-trained models? What are the sufficient conditions to retrieve such sensitive information?" We first explore different statistical information which can discriminate the private training distribution from other distributions. Based on our observations, we propose a novel private data reconstruction framework, SecretGen, to effectively recover private information. Compared with previous methods which can recover private data with the ground true prediction of the targeted recovery instance, SecretGen does not require such prior knowledge, making it more practical. We conduct extensive experiments on different datasets under diverse scenarios to compare SecretGen with other baselines and provide a systematic benchmark to better understand the impact of different auxiliary information and optimization operations. We show that without prior knowledge about true class prediction, SecretGen is able to recover private data with similar performance compared with the ones that leverage such prior knowledge. If the prior knowledge is given, SecretGen will significantly outperform baseline methods. We also propose several quantitative metrics to further quantify the privacy vulnerability of pre-trained models, which will help the model selection for privacy-sensitive applications. Our code is available at: https://github.com/AI-secure/SecretGen.
MTCSNN: Multi-task Clinical Siamese Neural Network for Diabetic Retinopathy Severity Prediction
Aug 14, 2022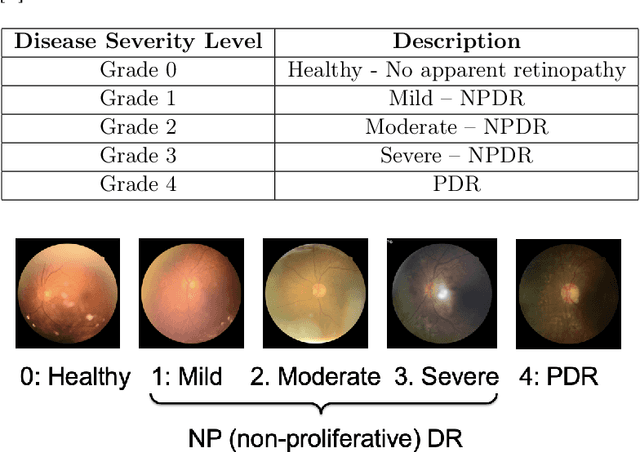

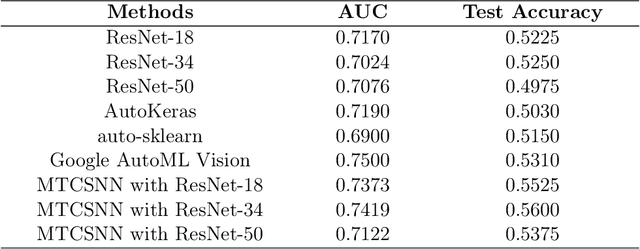
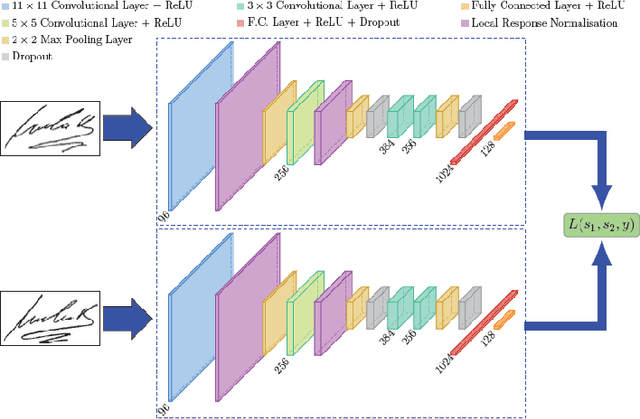
Diabetic Retinopathy (DR) has become one of the leading causes of vision impairment in working-aged people and is a severe problem worldwide. However, most of the works ignored the ordinal information of labels. In this project, we propose a novel design MTCSNN, a Multi-task Clinical Siamese Neural Network for Diabetic Retinopathy severity prediction task. The novelty of this project is to utilize the ordinal information among labels and add a new regression task, which can help the model learn more discriminative feature embedding for fine-grained classification tasks. We perform comprehensive experiments over the RetinaMNIST, comparing MTCSNN with other models like ResNet-18, 34, 50. Our results indicate that MTCSNN outperforms the benchmark models in terms of AUC and accuracy on the test dataset.
Debias the Black-box: A Fair Ranking Framework via Knowledge Distillation
Aug 24, 2022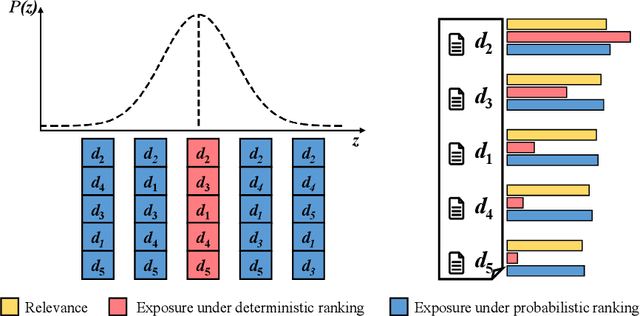
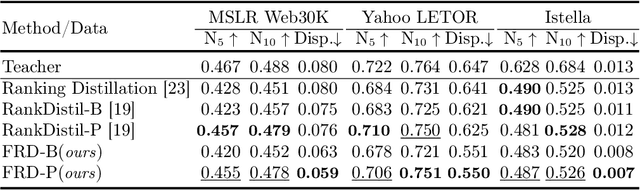
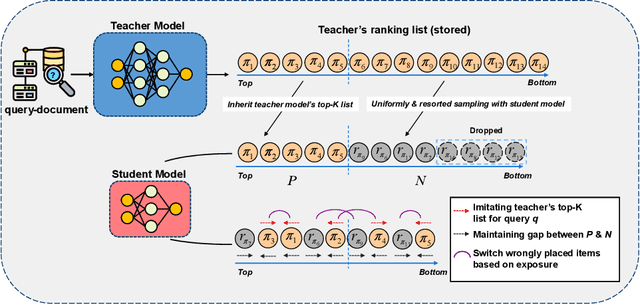
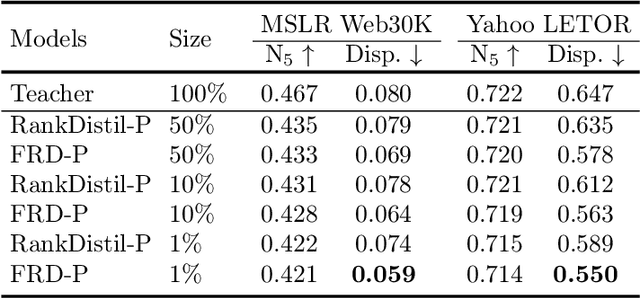
Deep neural networks can capture the intricate interaction history information between queries and documents, because of their many complicated nonlinear units, allowing them to provide correct search recommendations. However, service providers frequently face more complex obstacles in real-world circumstances, such as deployment cost constraints and fairness requirements. Knowledge distillation, which transfers the knowledge of a well-trained complex model (teacher) to a simple model (student), has been proposed to alleviate the former concern, but the best current distillation methods focus only on how to make the student model imitate the predictions of the teacher model. To better facilitate the application of deep models, we propose a fair information retrieval framework based on knowledge distillation. This framework can improve the exposure-based fairness of models while considerably decreasing model size. Our extensive experiments on three huge datasets show that our proposed framework can reduce the model size to a minimum of 1% of its original size while maintaining its black-box state. It also improves fairness performance by 15%~46% while keeping a high level of recommendation effectiveness.
Unsupervised Structure-Consistent Image-to-Image Translation
Aug 24, 2022
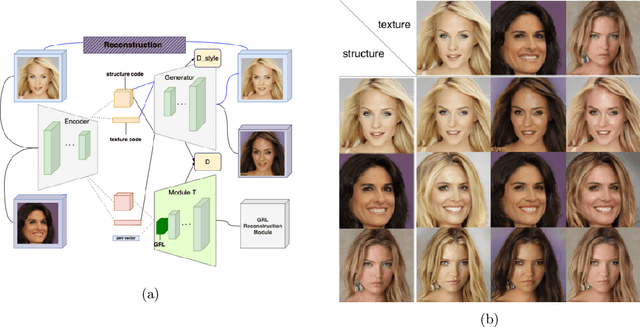


The Swapping Autoencoder achieved state-of-the-art performance in deep image manipulation and image-to-image translation. We improve this work by introducing a simple yet effective auxiliary module based on gradient reversal layers. The auxiliary module's loss forces the generator to learn to reconstruct an image with an all-zero texture code, encouraging better disentanglement between the structure and texture information. The proposed attribute-based transfer method enables refined control in style transfer while preserving structural information without using a semantic mask. To manipulate an image, we encode both the geometry of the objects and the general style of the input images into two latent codes with an additional constraint that enforces structure consistency. Moreover, due to the auxiliary loss, training time is significantly reduced. The superiority of the proposed model is demonstrated in complex domains such as satellite images where state-of-the-art are known to fail. Lastly, we show that our model improves the quality metrics for a wide range of datasets while achieving comparable results with multi-modal image generation techniques.
Centralized Feature Pyramid for Object Detection
Oct 05, 2022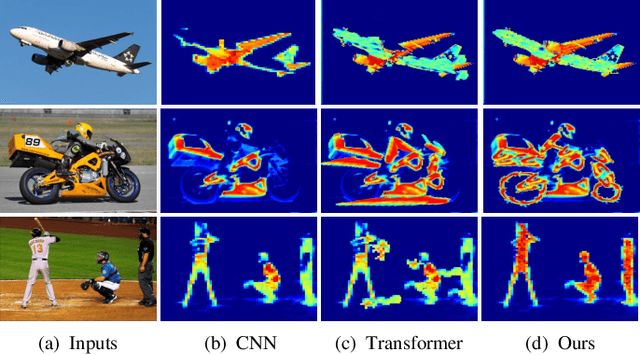
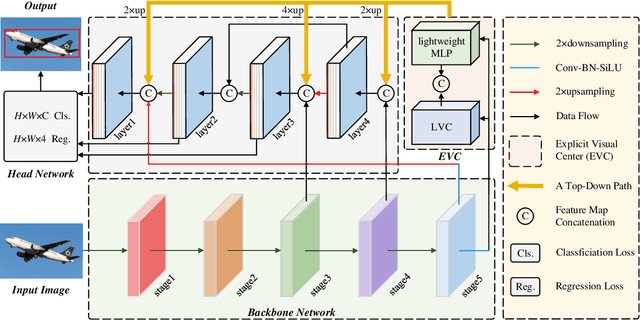
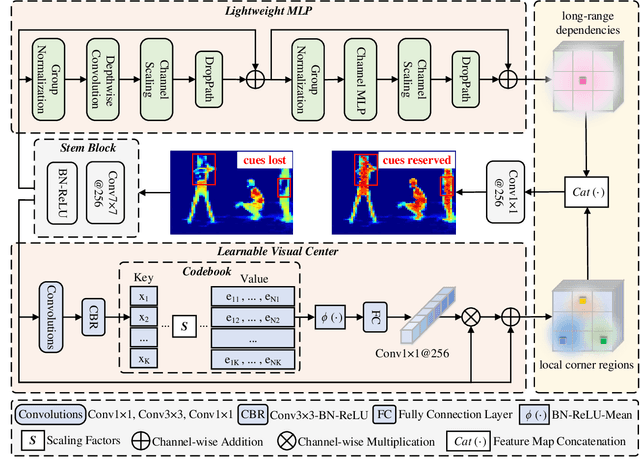
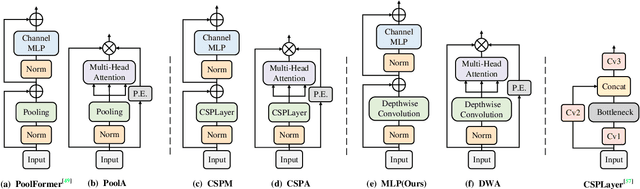
Visual feature pyramid has shown its superiority in both effectiveness and efficiency in a wide range of applications. However, the existing methods exorbitantly concentrate on the inter-layer feature interactions but ignore the intra-layer feature regulations, which are empirically proved beneficial. Although some methods try to learn a compact intra-layer feature representation with the help of the attention mechanism or the vision transformer, they ignore the neglected corner regions that are important for dense prediction tasks. To address this problem, in this paper, we propose a Centralized Feature Pyramid (CFP) for object detection, which is based on a globally explicit centralized feature regulation. Specifically, we first propose a spatial explicit visual center scheme, where a lightweight MLP is used to capture the globally long-range dependencies and a parallel learnable visual center mechanism is used to capture the local corner regions of the input images. Based on this, we then propose a globally centralized regulation for the commonly-used feature pyramid in a top-down fashion, where the explicit visual center information obtained from the deepest intra-layer feature is used to regulate frontal shallow features. Compared to the existing feature pyramids, CFP not only has the ability to capture the global long-range dependencies, but also efficiently obtain an all-round yet discriminative feature representation. Experimental results on the challenging MS-COCO validate that our proposed CFP can achieve the consistent performance gains on the state-of-the-art YOLOv5 and YOLOX object detection baselines.
HyperHawkes: Hypernetwork based Neural Temporal Point Process
Oct 01, 2022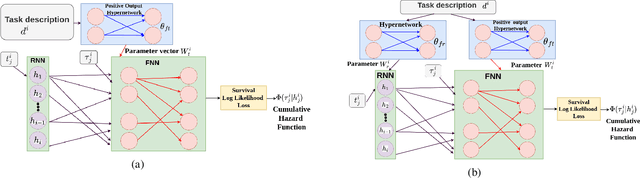
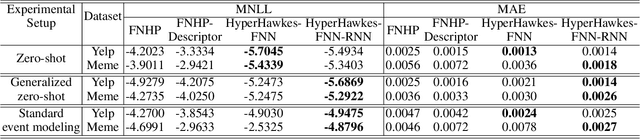

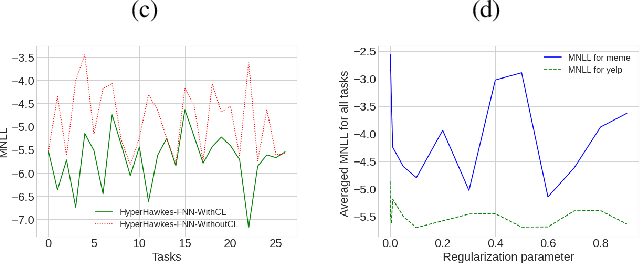
Temporal point process serves as an essential tool for modeling time-to-event data in continuous time space. Despite having massive amounts of event sequence data from various domains like social media, healthcare etc., real world application of temporal point process faces two major challenges: 1) it is not generalizable to predict events from unseen sequences in dynamic environment 2) they are not capable of thriving in continually evolving environment with minimal supervision while retaining previously learnt knowledge. To tackle these issues, we propose \textit{HyperHawkes}, a hypernetwork based temporal point process framework which is capable of modeling time of occurrence of events for unseen sequences. Thereby, we solve the problem of zero-shot learning for time-to-event modeling. We also develop a hypernetwork based continually learning temporal point process for continuous modeling of time-to-event sequences with minimal forgetting. In this way, \textit{HyperHawkes} augments the temporal point process with zero-shot modeling and continual learning capabilities. We demonstrate the application of the proposed framework through our experiments on two real-world datasets. Our results show the efficacy of the proposed approach in terms of predicting future events under zero-shot regime for unseen event sequences. We also show that the proposed model is able to predict sequences continually while retaining information from previous event sequences, hence mitigating catastrophic forgetting for time-to-event data.
Clustering for directed graphs using parametrized random walk diffusion kernels
Oct 01, 2022
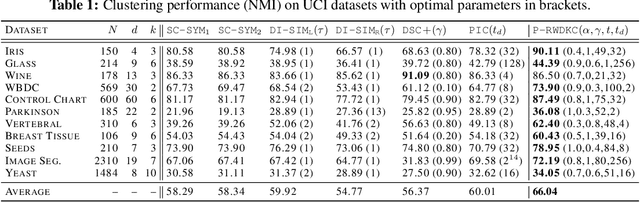

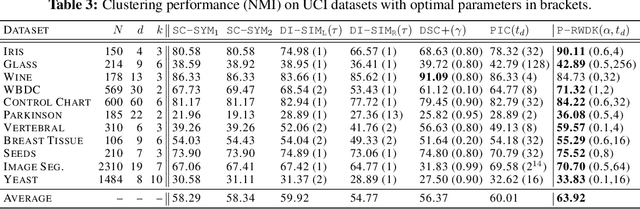
Clustering based on the random walk operator has been proven effective for undirected graphs, but its generalization to directed graphs (digraphs) is much more challenging. Although the random walk operator is well-defined for digraphs, in most cases such graphs are not strongly connected, and hence the associated random walks are not irreducible, which is a crucial property for clustering that exists naturally in the undirected setting. To remedy this, the usual workaround is to either naively symmetrize the adjacency matrix or to replace the natural random walk operator by the teleporting random walk operator, but this can lead to the loss of valuable information carried by edge directionality. In this paper, we introduce a new clustering framework, the Parametrized Random Walk Diffusion Kernel Clustering (P-RWDKC), which is suitable for handling both directed and undirected graphs. Our framework is based on the diffusion geometry and the generalized spectral clustering framework. Accordingly, we propose an algorithm that automatically reveals the cluster structure at a given scale, by considering the random walk dynamics associated with a parametrized kernel operator, and by estimating its critical diffusion time. Experiments on $K$-NN graphs constructed from real-world datasets and real-world graphs show that our clustering approach performs well in all tested cases, and outperforms existing approaches in most of them.
Crowdsourced-based Deep Convolutional Networks for Urban Flood Depth Mapping
Sep 06, 2022
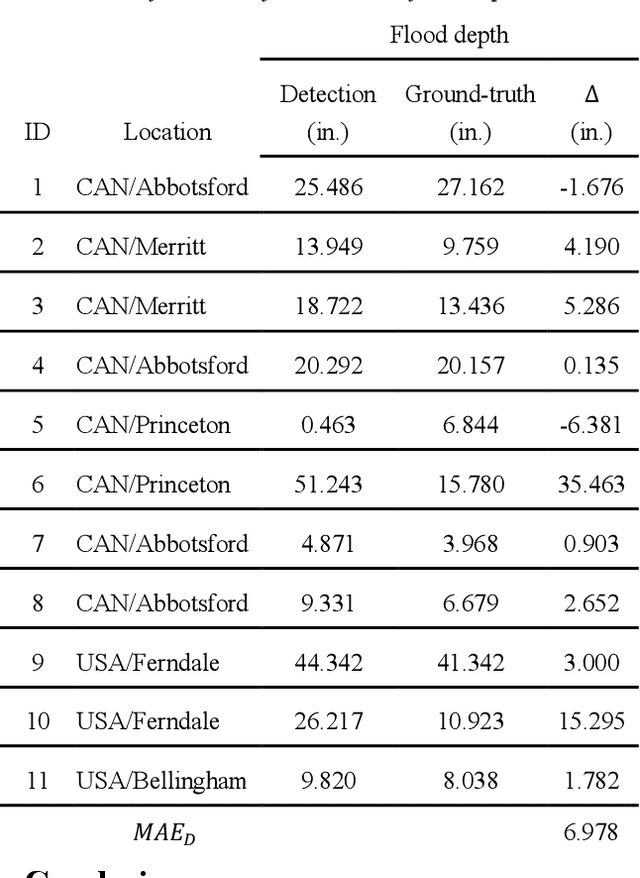
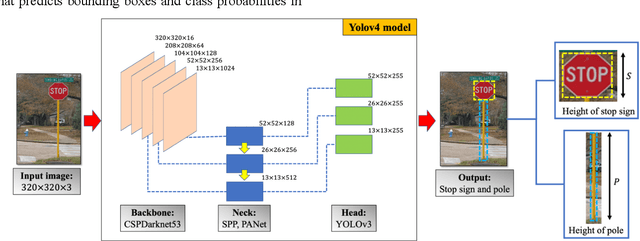

Successful flood recovery and evacuation require access to reliable flood depth information. Most existing flood mapping tools do not provide real-time flood maps of inundated streets in and around residential areas. In this paper, a deep convolutional network is used to determine flood depth with high spatial resolution by analyzing crowdsourced images of submerged traffic signs. Testing the model on photos from a recent flood in the U.S. and Canada yields a mean absolute error of 6.978 in., which is on par with previous studies, thus demonstrating the applicability of this approach to low-cost, accurate, and real-time flood risk mapping.
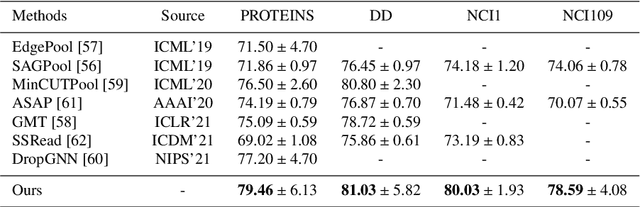
Graph Classification via Discriminative Edge Feature Learning
Oct 05, 2022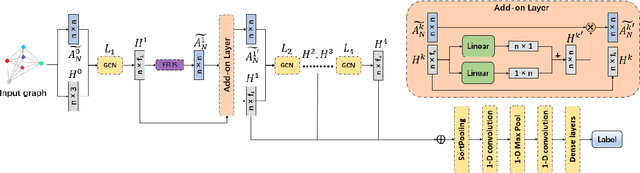
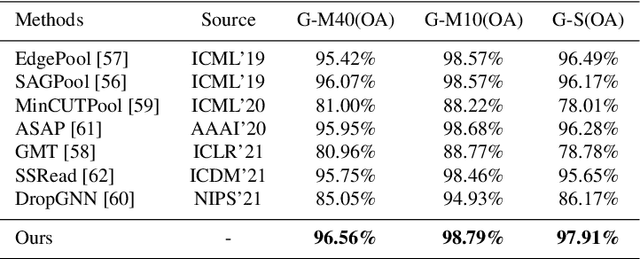
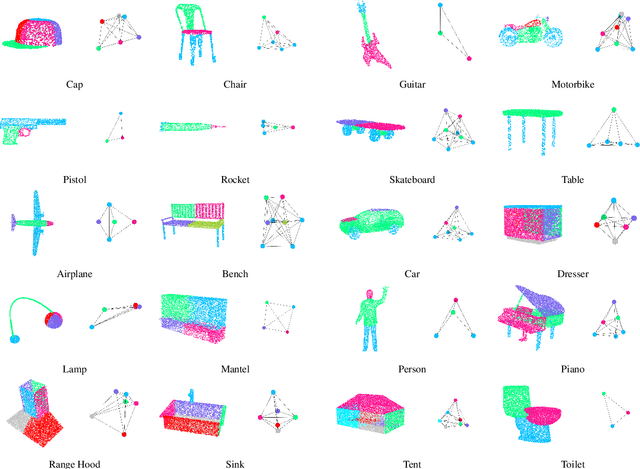
Spectral graph convolutional neural networks (GCNNs) have been producing encouraging results in graph classification tasks. However, most spectral GCNNs utilize fixed graphs when aggregating node features, while omitting edge feature learning and failing to get an optimal graph structure. Moreover, many existing graph datasets do not provide initialized edge features, further restraining the ability of learning edge features via spectral GCNNs. In this paper, we try to address this issue by designing an edge feature scheme and an add-on layer between every two stacked graph convolution layers in GCNN. Both are lightweight while effective in filling the gap between edge feature learning and performance enhancement of graph classification. The edge feature scheme makes edge features adapt to node representations at different graph convolution layers. The add-on layers help adjust the edge features to an optimal graph structure. To test the effectiveness of our method, we take Euclidean positions as initial node features and extract graphs with semantic information from point cloud objects. The node features of our extracted graphs are more scalable for edge feature learning than most existing graph datasets (in one-hot encoded label format). Three new graph datasets are constructed based on ModelNet40, ModelNet10 and ShapeNet Part datasets. Experimental results show that our method outperforms state-of-the-art graph classification methods on the new datasets by reaching 96.56% overall accuracy on Graph-ModelNet40, 98.79% on Graph-ModelNet10 and 97.91% on Graph-ShapeNet Part. The constructed graph datasets will be released to the community.
Tensor-Based Multi-Modality Feature Selection and Regression for Alzheimer's Disease Diagnosis
Sep 23, 2022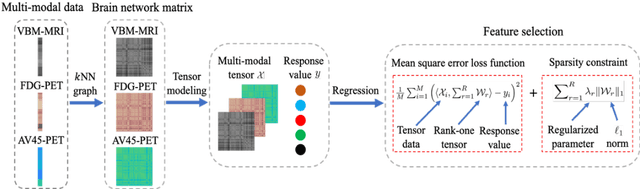
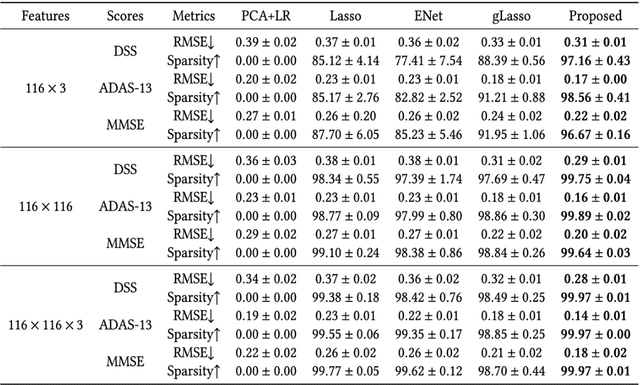
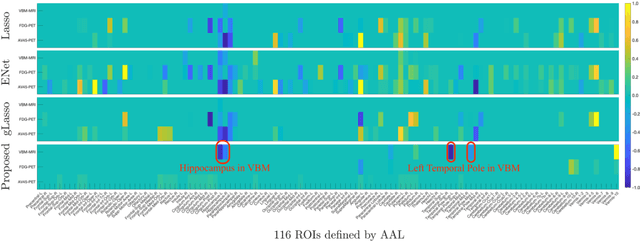
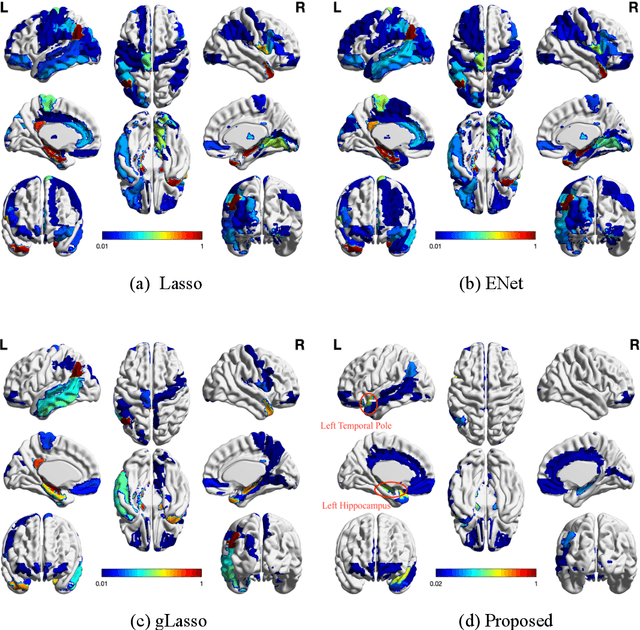
The assessment of Alzheimer's Disease (AD) and Mild Cognitive Impairment (MCI) associated with brain changes remains a challenging task. Recent studies have demonstrated that combination of multi-modality imaging techniques can better reflect pathological characteristics and contribute to more accurate diagnosis of AD and MCI. In this paper, we propose a novel tensor-based multi-modality feature selection and regression method for diagnosis and biomarker identification of AD and MCI from normal controls. Specifically, we leverage the tensor structure to exploit high-level correlation information inherent in the multi-modality data, and investigate tensor-level sparsity in the multilinear regression model. We present the practical advantages of our method for the analysis of ADNI data using three imaging modalities (VBM- MRI, FDG-PET and AV45-PET) with clinical parameters of disease severity and cognitive scores. The experimental results demonstrate the superior performance of our proposed method against the state-of-the-art for the disease diagnosis and the identification of disease-specific regions and modality-related differences. The code for this work is publicly available at https://github.com/junfish/BIOS22.