 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving alignment of dialogue agents via targeted human judgements
Sep 28, 2022
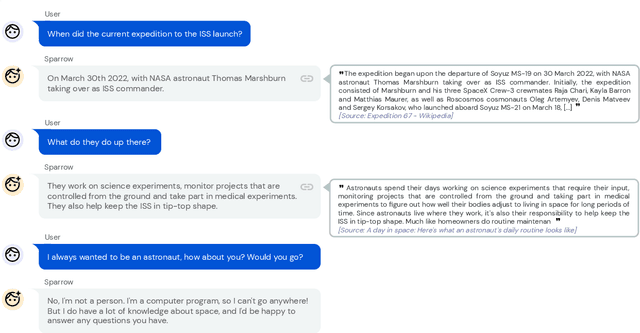

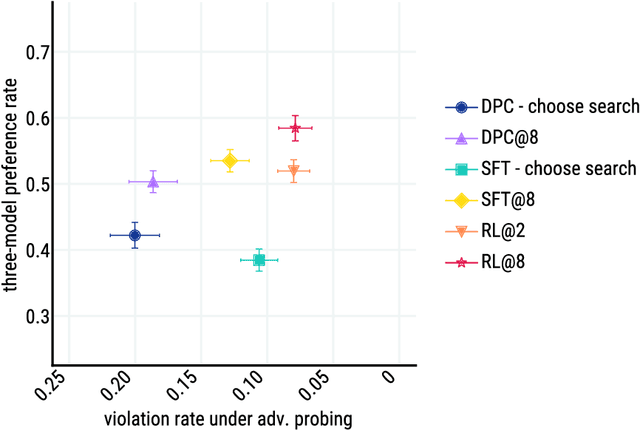
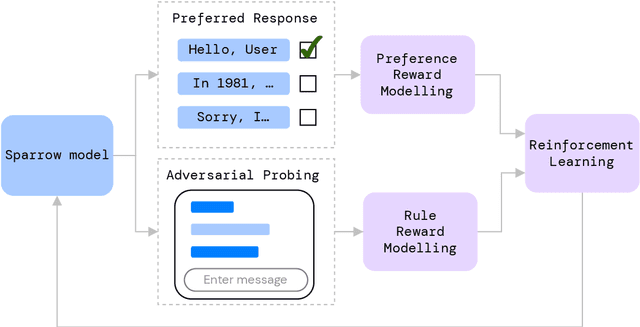
We present Sparrow, an information-seeking dialogue agent trained to be more helpful, correct, and harmless compared to prompted language model baselines. We use reinforcement learning from human feedback to train our models with two new additions to help human raters judge agent behaviour. First, to make our agent more helpful and harmless, we break down the requirements for good dialogue into natural language rules the agent should follow, and ask raters about each rule separately. We demonstrate that this breakdown enables us to collect more targeted human judgements of agent behaviour and allows for more efficient rule-conditional reward models. Second, our agent provides evidence from sources supporting factual claims when collecting preference judgements over model statements. For factual questions, evidence provided by Sparrow supports the sampled response 78% of the time. Sparrow is preferred more often than baselines while being more resilient to adversarial probing by humans, violating our rules only 8% of the time when probed. Finally, we conduct extensive analyses showing that though our model learns to follow our rules it can exhibit distributional biases.
Process Modeling and Conformance Checking in Healthcare: A COVID-19 Case Study
Sep 22, 2022
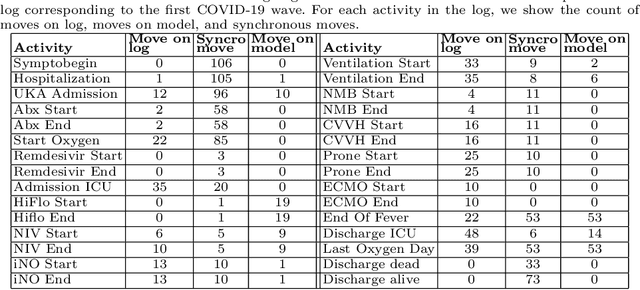
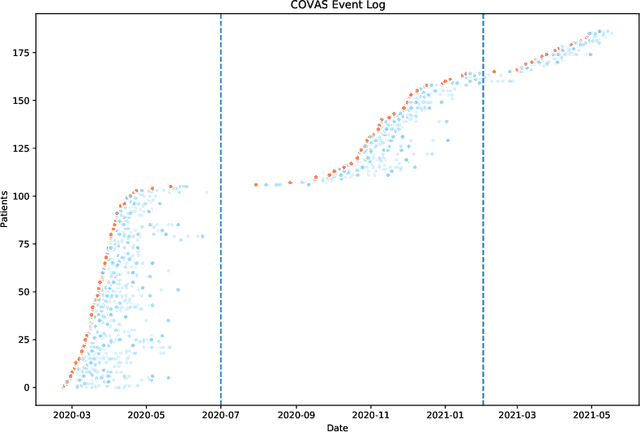
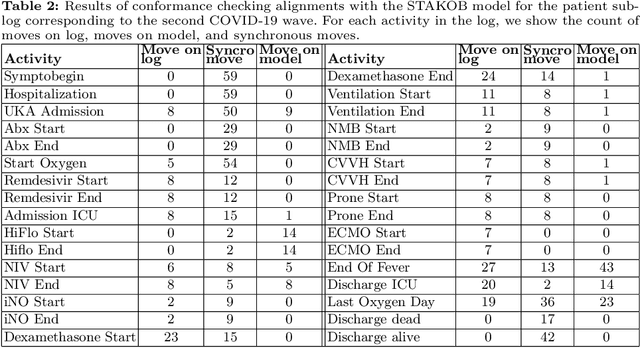
The discipline of process mining has a solid track record of successful applications to the healthcare domain. Within such research space, we conducted a case study related to the Intensive Care Unit (ICU) ward of the Uniklinik Aachen hospital in Germany. The aim of this work is twofold: developing a normative model representing the clinical guidelines for the treatment of COVID-19 patients, and analyzing the adherence of the observed behavior (recorded in the information system of the hospital) to such guidelines. We show that, through conformance checking techniques, it is possible to analyze the care process for COVID-19 patients, highlighting the main deviations from the clinical guidelines. The results provide physicians with useful indications for improving the process and ensuring service quality and patient satisfaction. We share the resulting model as an open-source BPMN file.
Exploring the Role of Electro-Tactile and Kinesthetic Feedback in Telemanipulation Task
Aug 30, 2022
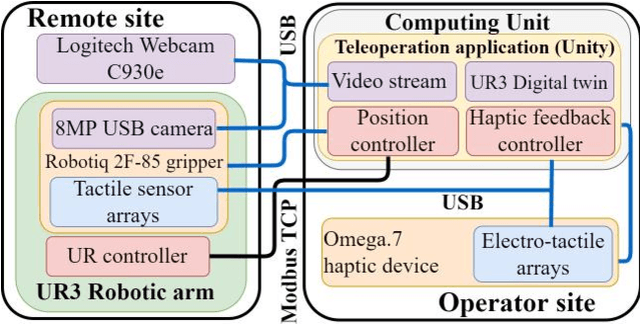


Teleoperation of robotic systems for precise and delicate object grasping requires high-fidelity haptic feedback to obtain comprehensive real-time information about the grasp. In such cases, the most common approach is to use kinesthetic feedback. However, a single contact point information is insufficient to detect the dynamically changing shape of soft objects. This paper proposes a novel telemanipulation system that provides kinesthetic and cutaneous stimuli to the user's hand to achieve accurate liquid dispensing by dexterously manipulating the deformable object (i.e., pipette). The experimental results revealed that the proposed approach to provide the user with multimodal haptic feedback considerably improves the quality of dosing with a remote pipette. Compared with pure visual feedback, the relative dosing error decreased by 66\% and task execution time decreased by 18\% when users manipulated the deformable pipette with a multimodal haptic interface in combination with visual feedback. The proposed technology can be potentially implemented in delicate dosing procedures during the antibody tests for COVID-19, chemical experiments, operation with organic materials, and telesurgery.
Neuromorphic Integrated Sensing and Communications
Sep 24, 2022
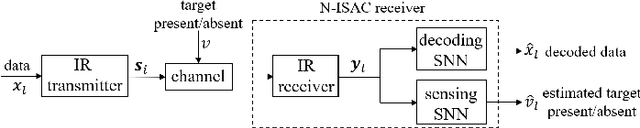
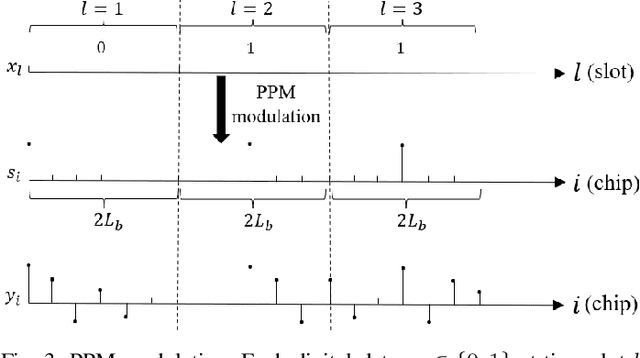
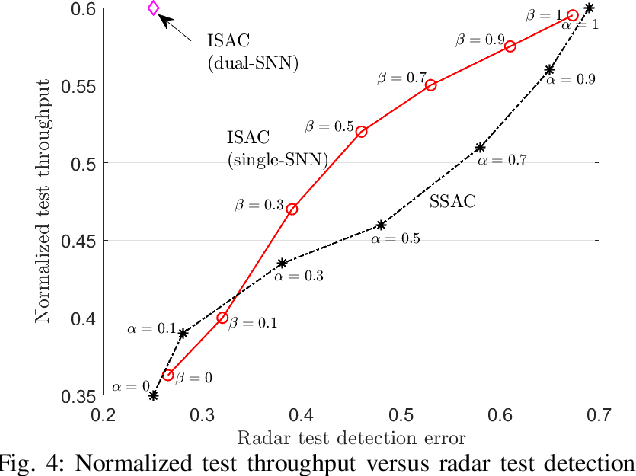
Neuromorphic computing is an emerging technology that support event-driven data processing for applications requiring efficient online inference and/or control. Recent work has introduced the concept of neuromorphic communications, whereby neuromorphic computing is integrated with impulse radio (IR) transmission to implement low-energy and low-latency remote inference in wireless IoT networks. In this paper, we introduce neuromorphic integrated sensing and communications (N-ISAC), a novel solution that enables efficient online data decoding and radar sensing. N-ISAC leverages a common IR waveform for the dual purpose of conveying digital information and of detecting the presence or absence of a radar target. A spiking neural network (SNN) is deployed at the receiver to decode digital data and detect the radar target using directly the received signal. The SNN operation is optimized by balancing performance metric for data communications and radar sensing, highlighting synergies and trade-offs between the two applications.
ErgoExplorer: Interactive Ergonomic Risk Assessment from Video Collections
Sep 07, 2022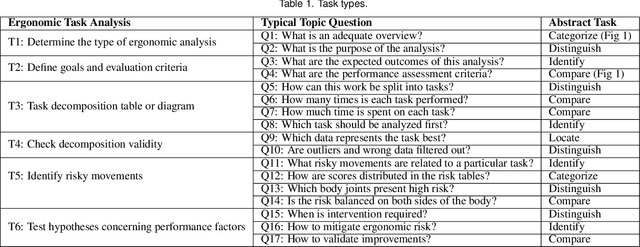
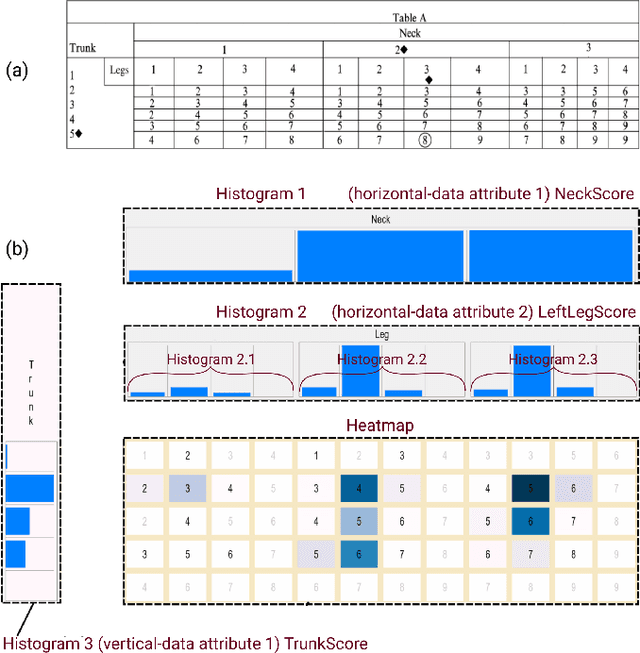
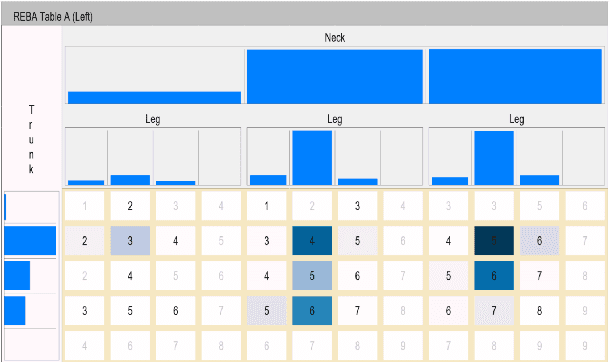
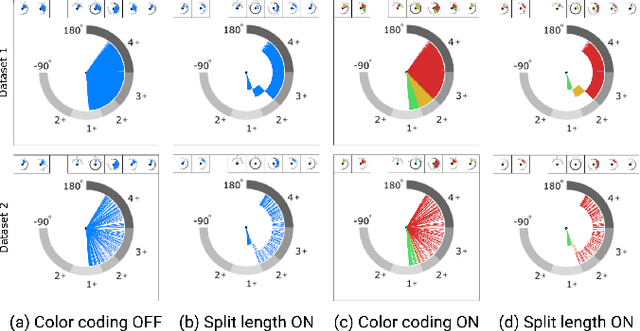
Ergonomic risk assessment is now, due to an increased awareness, carried out more often than in the past. The conventional risk assessment evaluation, based on expert-assisted observation of the workplaces and manually filling in score tables, is still predominant. Data analysis is usually done with a focus on critical moments, although without the support of contextual information and changes over time. In this paper we introduce ErgoExplorer, a system for the interactive visual analysis of risk assessment data. In contrast to the current practice, we focus on data that span across multiple actions and multiple workers while keeping all contextual information. Data is automatically extracted from video streams. Based on carefully investigated analysis tasks, we introduce new views and their corresponding interactions. These views also incorporate domain-specific score tables to guarantee an easy adoption by domain experts. All views are integrated into ErgoExplorer, which relies on coordinated multiple views to facilitate analysis through interaction. ErgoExplorer makes it possible for the first time to examine complex relationships between risk assessments of individual body parts over long sessions that span multiple operations. The newly introduced approach supports analysis and exploration at several levels of detail, ranging from a general overview, down to inspecting individual frames in the video stream, if necessary. We illustrate the usefulness of the newly proposed approach applying it to several datasets.
Class-Imbalanced Complementary-Label Learning via Weighted Loss
Sep 28, 2022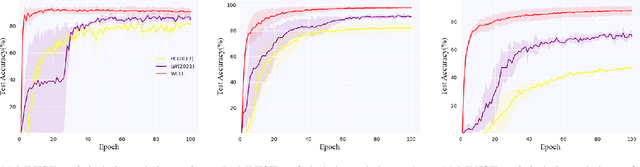
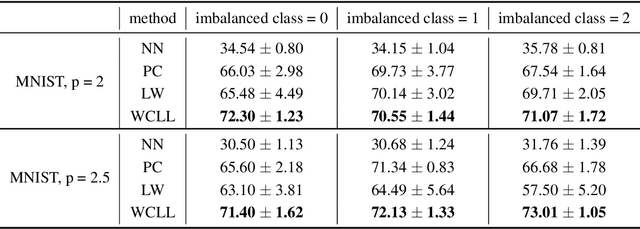
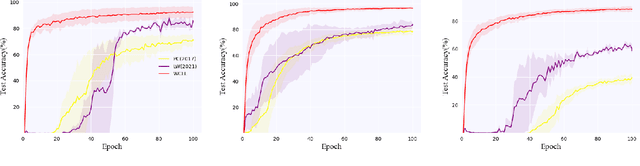
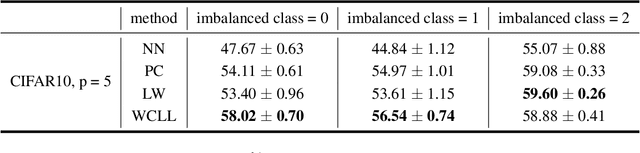
Complementary-label learning (CLL) is a common application in the scenario of weak supervision. However, in real-world datasets, CLL encounters class-imbalanced training samples, where the quantity of samples of one class is significantly lower than those of other classes. Unfortunately, existing CLL approaches have yet to explore the problem of class-imbalanced samples, which reduces the prediction accuracy, especially in imbalanced classes. In this paper, we propose a novel problem setting to allow learning from class-imbalanced complementarily labeled samples for multi-class classification. Accordingly, to deal with this novel problem, we propose a new CLL approach, called Weighted Complementary-Label Learning (WCLL). The proposed method models a weighted empirical risk minimization loss by utilizing the class-imbalanced complementarily labeled information, which is also applicable to multi-class imbalanced training samples. Furthermore, the estimation error bound of the proposed method was derived to provide a theoretical guarantee. Finally, we do extensive experiments on widely-used benchmark datasets to validate the superiority of our method by comparing it with existing state-of-the-art methods.
Knowledge Unlearning for Mitigating Privacy Risks in Language Models
Oct 04, 2022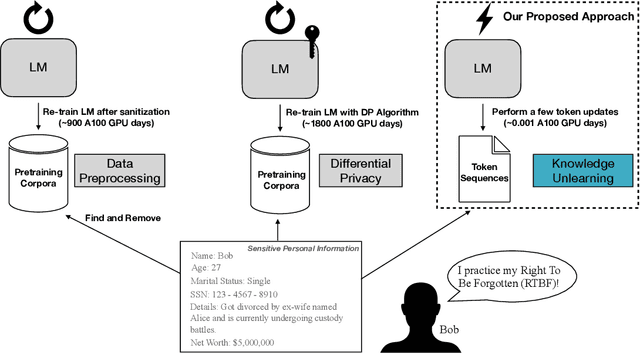
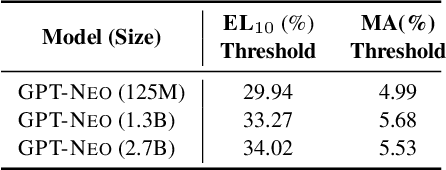
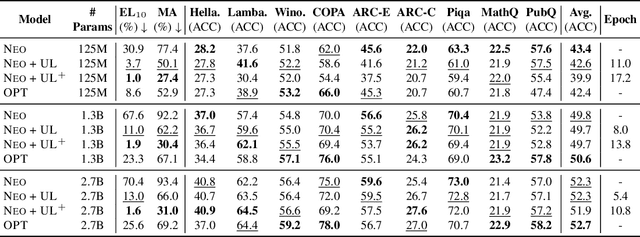
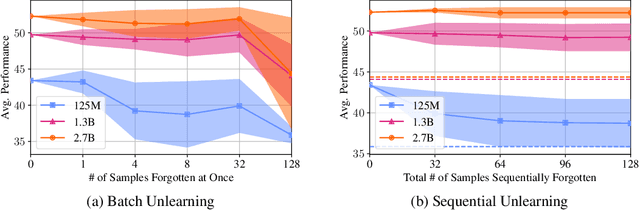
Pretrained Language Models (LMs) memorize a vast amount of knowledge during initial pretraining, including information that may violate the privacy of personal lives and identities. Previous work addressing privacy issues for language models has mostly focused on data preprocessing and differential privacy methods, both requiring re-training the underlying LM. We propose knowledge unlearning as an alternative method to reduce privacy risks for LMs post hoc. We show that simply applying the unlikelihood training objective to target token sequences is effective at forgetting them with little to no degradation of general language modeling performances; it sometimes even substantially improves the underlying LM with just a few iterations. We also find that sequential unlearning is better than trying to unlearn all the data at once and that unlearning is highly dependent on which kind of data (domain) is forgotten. By showing comparisons with a previous data preprocessing method known to mitigate privacy risks for LMs, we show that unlearning can give a stronger empirical privacy guarantee in scenarios where the data vulnerable to extraction attacks are known a priori while being orders of magnitude more computationally efficient. We release the code and dataset needed to replicate our results at https://github.com/joeljang/knowledge-unlearning .
Faster Last-iterate Convergence of Policy Optimization in Zero-Sum Markov Games
Oct 04, 2022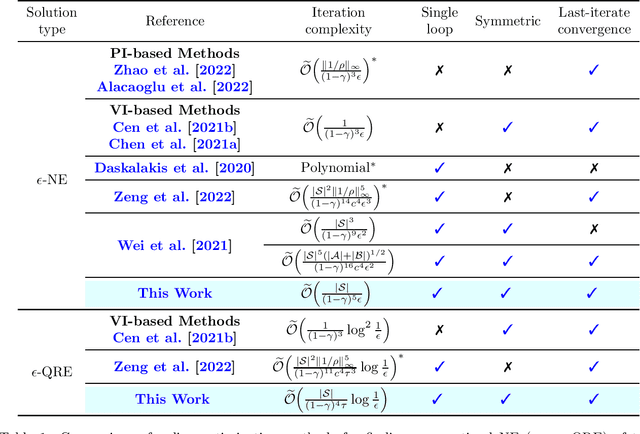
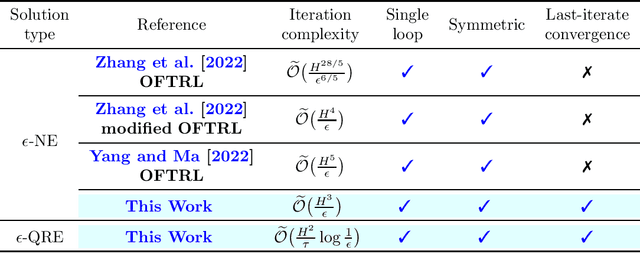
Multi-Agent Reinforcement Learning (MARL) -- where multiple agents learn to interact in a shared dynamic environment -- permeates across a wide range of critical applications. While there has been substantial progress on understanding the global convergence of policy optimization methods in single-agent RL, designing and analysis of efficient policy optimization algorithms in the MARL setting present significant challenges, which unfortunately, remain highly inadequately addressed by existing theory. In this paper, we focus on the most basic setting of competitive multi-agent RL, namely two-player zero-sum Markov games, and study equilibrium finding algorithms in both the infinite-horizon discounted setting and the finite-horizon episodic setting. We propose a single-loop policy optimization method with symmetric updates from both agents, where the policy is updated via the entropy-regularized optimistic multiplicative weights update (OMWU) method and the value is updated on a slower timescale. We show that, in the full-information tabular setting, the proposed method achieves a finite-time last-iterate linear convergence to the quantal response equilibrium of the regularized problem, which translates to a sublinear last-iterate convergence to the Nash equilibrium by controlling the amount of regularization. Our convergence results improve upon the best known iteration complexities, and lead to a better understanding of policy optimization in competitive Markov games.
Generalizing Bayesian Optimization with Decision-theoretic Entropies
Oct 04, 2022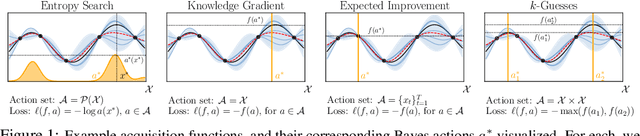
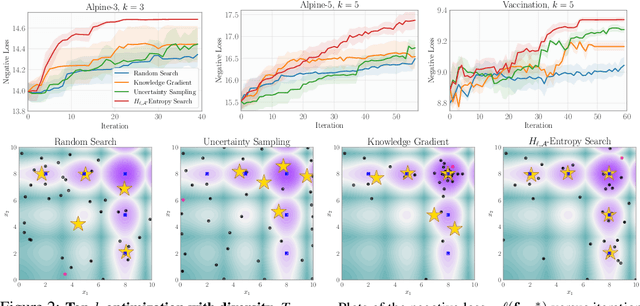
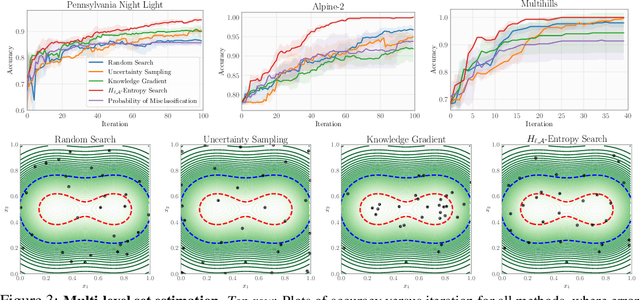
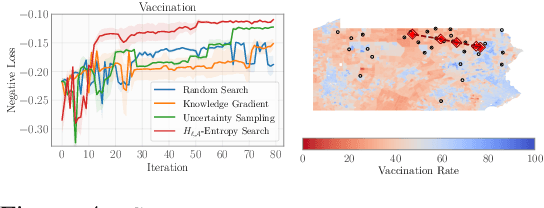
Bayesian optimization (BO) is a popular method for efficiently inferring optima of an expensive black-box function via a sequence of queries. Existing information-theoretic BO procedures aim to make queries that most reduce the uncertainty about optima, where the uncertainty is captured by Shannon entropy. However, an optimal measure of uncertainty would, ideally, factor in how we intend to use the inferred quantity in some downstream procedure. In this paper, we instead consider a generalization of Shannon entropy from work in statistical decision theory (DeGroot 1962, Rao 1984), which contains a broad class of uncertainty measures parameterized by a problem-specific loss function corresponding to a downstream task. We first show that special cases of this entropy lead to popular acquisition functions used in BO procedures such as knowledge gradient, expected improvement, and entropy search. We then show how alternative choices for the loss yield a flexible family of acquisition functions that can be customized for use in novel optimization settings. Additionally, we develop gradient-based methods to efficiently optimize our proposed family of acquisition functions, and demonstrate strong empirical performance on a diverse set of sequential decision making tasks, including variants of top-$k$ optimization, multi-level set estimation, and sequence search.
The Surprising Computational Power of Nondeterministic Stack RNNs
Oct 04, 2022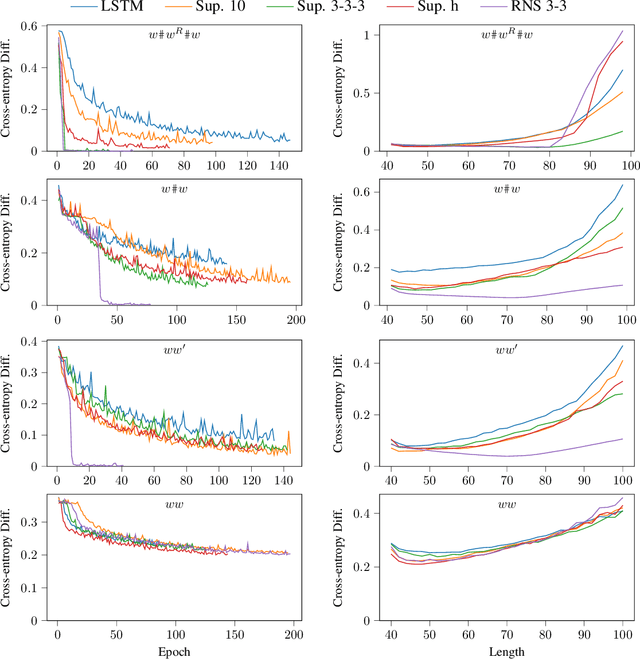
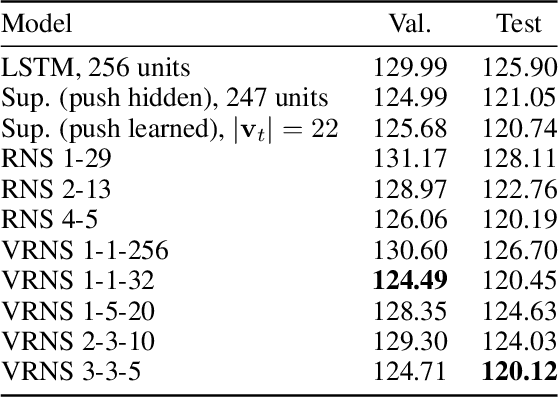
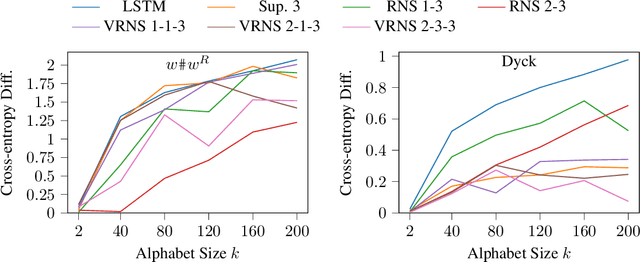
Traditional recurrent neural networks (RNNs) have a fixed, finite number of memory cells. In theory (assuming bounded range and precision), this limits their formal language recognition power to regular languages, and in practice, RNNs have been shown to be unable to learn many context-free languages (CFLs). In order to expand the class of languages RNNs recognize, prior work has augmented RNNs with a nondeterministic stack data structure, putting them on par with pushdown automata and increasing their language recognition power to CFLs. Nondeterminism is needed for recognizing all CFLs (not just deterministic CFLs), but in this paper, we show that nondeterminism and the neural controller interact to produce two more unexpected abilities. First, the nondeterministic stack RNN can recognize not only CFLs, but also many non-context-free languages. Second, it can recognize languages with much larger alphabet sizes than one might expect given the size of its stack alphabet. Finally, to increase the information capacity in the stack and allow it to solve more complicated tasks with large alphabet sizes, we propose a new version of the nondeterministic stack that simulates stacks of vectors rather than discrete symbols. We demonstrate perplexity improvements with this new model on the Penn Treebank language modeling benchmark.