 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mixed-Reality Robot Behavior Replay: A System Implementation
Sep 30, 2022




As robots become increasingly complex, they must explain their behaviors to gain trust and acceptance. However, it may be difficult through verbal explanation alone to fully convey information about past behavior, especially regarding objects no longer present due to robots' or humans' actions. Humans often try to physically mimic past movements to accompany verbal explanations. Inspired by this human-human interaction, we describe the technical implementation of a system for past behavior replay for robots in this tool paper. Specifically, we used Behavior Trees to encode and separate robot behaviors, and schemaless MongoDB to structurally store and query the underlying sensor data and joint control messages for future replay. Our approach generalizes to different types of replays, including both manipulation and navigation replay, and visual (i.e., augmented reality (AR)) and auditory replay. Additionally, we briefly summarize a user study to further provide empirical evidence of its effectiveness and efficiency. Sample code and instructions are available on GitHub at https://github.com/umhan35/robot-behavior-replay.
* 6 pages, 5 figures, the AI-HRI Symposium at AAAI Fall Symposium Series (FSS) 2022
Emergent Communication: Generalization and Overfitting in Lewis Games
Sep 30, 2022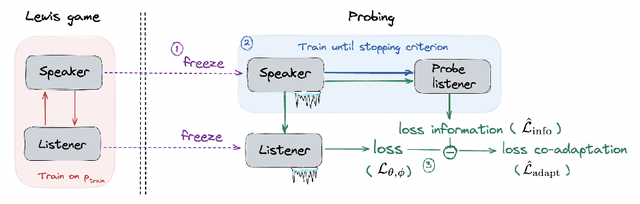

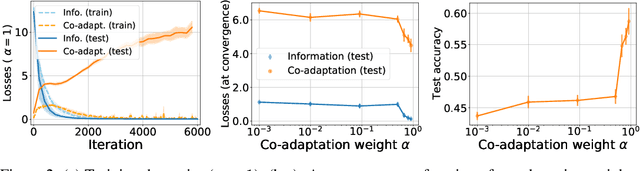

Lewis signaling games are a class of simple communication games for simulating the emergence of language. In these games, two agents must agree on a communication protocol in order to solve a cooperative task. Previous work has shown that agents trained to play this game with reinforcement learning tend to develop languages that display undesirable properties from a linguistic point of view (lack of generalization, lack of compositionality, etc). In this paper, we aim to provide better understanding of this phenomenon by analytically studying the learning problem in Lewis games. As a core contribution, we demonstrate that the standard objective in Lewis games can be decomposed in two components: a co-adaptation loss and an information loss. This decomposition enables us to surface two potential sources of overfitting, which we show may undermine the emergence of a structured communication protocol. In particular, when we control for overfitting on the co-adaptation loss, we recover desired properties in the emergent languages: they are more compositional and generalize better.
ASTF: Visual Abstractions of Time-Varying Patterns in Radio Signals
Sep 30, 2022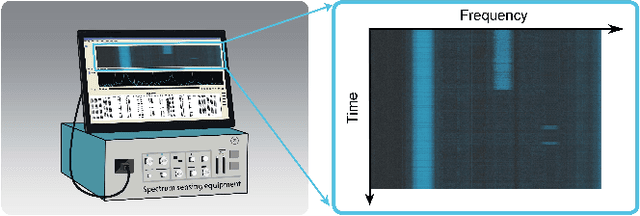
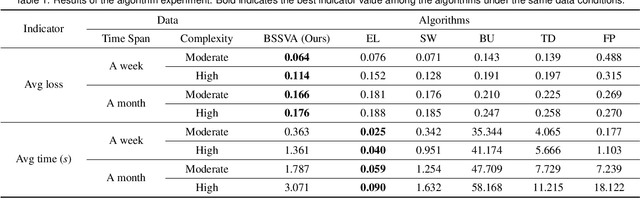
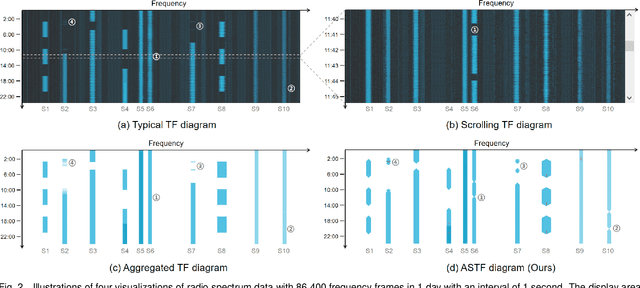
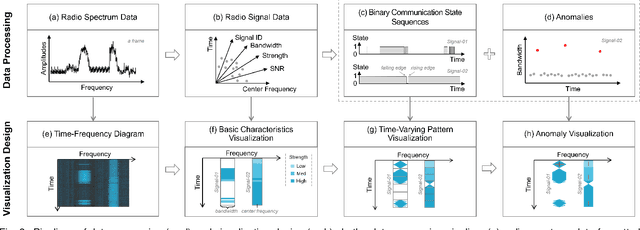
A time-frequency diagram is a commonly used visualization for observing the time-frequency distribution of radio signals and analyzing their time-varying patterns of communication states in radio monitoring and management. While it excels when performing short-term signal analyses, it becomes inadaptable for long-term signal analyses because it cannot adequately depict signal time-varying patterns in a large time span on a space-limited screen. This research thus presents an abstract signal time-frequency (ASTF) diagram to address this problem. In the diagram design, a visual abstraction method is proposed to visually encode signal communication state changes in time slices. A time segmentation algorithm is proposed to divide a large time span into time slices.Three new quantified metrics and a loss function are defined to ensure the preservation of important time-varying information in the time segmentation. An algorithm performance experiment and a user study are conducted to evaluate the effectiveness of the diagram for long-term signal analyses.
Implicit Neural Spatial Representations for Time-dependent PDEs
Sep 30, 2022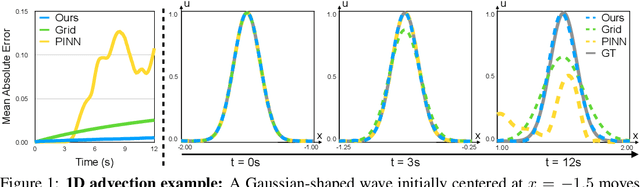

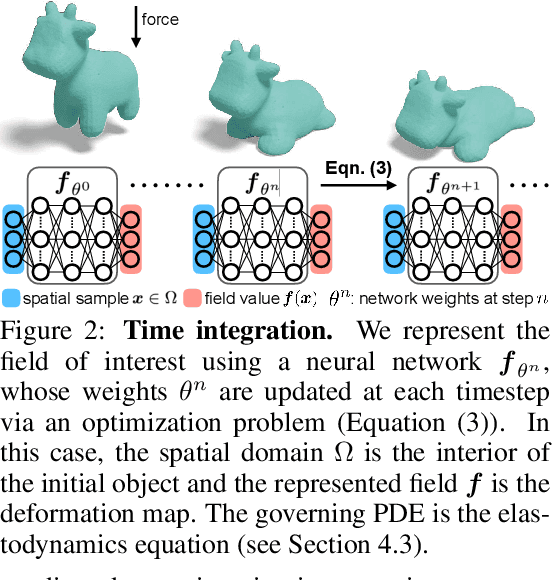

Numerically solving partial differential equations (PDEs) often entails spatial and temporal discretizations. Traditional methods (e.g., finite difference, finite element, smoothed-particle hydrodynamics) frequently adopt explicit spatial discretizations, such as grids, meshes, and point clouds, where each degree-of-freedom corresponds to a location in space. While these explicit spatial correspondences are intuitive to model and understand, these representations are not necessarily optimal for accuracy, memory-usage, or adaptivity. In this work, we explore implicit neural representation as an alternative spatial discretization, where spatial information is implicitly stored in the neural network weights. With implicit neural spatial representation, PDE-constrained time-stepping translates into updating neural network weights, which naturally integrates with commonly adopted optimization time integrators. We validate our approach on a variety of classic PDEs with examples involving large elastic deformations, turbulent fluids, and multiscale phenomena. While slower to compute than traditional representations, our approach exhibits higher accuracy, lower memory consumption, and dynamically adaptive allocation of degrees of freedom without complex remeshing.
Zero-Shot Retrieval with Search Agents and Hybrid Environments
Sep 30, 2022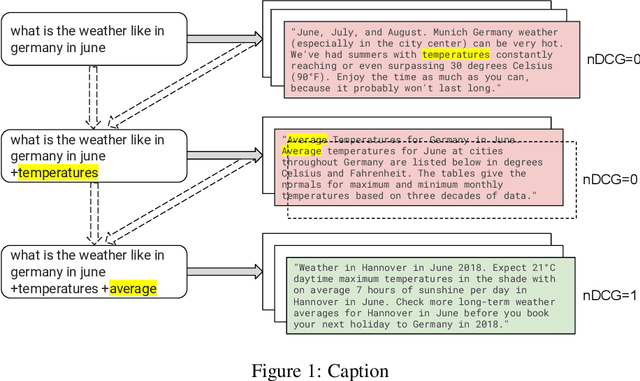
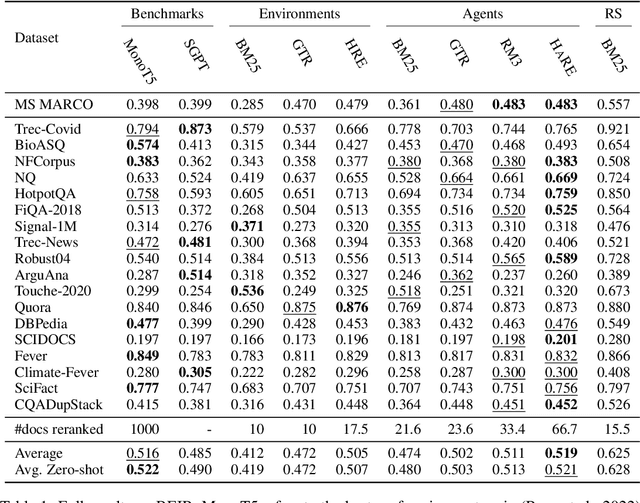
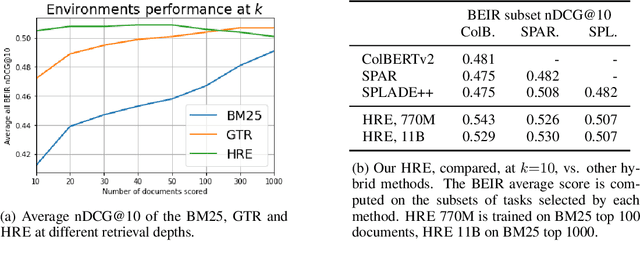
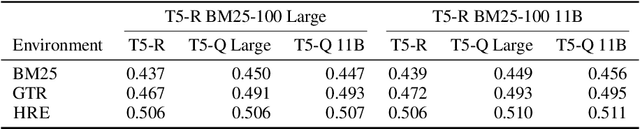
Learning to search is the task of building artificial agents that learn to autonomously use a search box to find information. So far, it has been shown that current language models can learn symbolic query reformulation policies, in combination with traditional term-based retrieval, but fall short of outperforming neural retrievers. We extend the previous learning to search setup to a hybrid environment, which accepts discrete query refinement operations, after a first-pass retrieval step performed by a dual encoder. Experiments on the BEIR task show that search agents, trained via behavioral cloning, outperform the underlying search system based on a combined dual encoder retriever and cross encoder reranker. Furthermore, we find that simple heuristic Hybrid Retrieval Environments (HRE) can improve baseline performance by several nDCG points. The search agent based on HRE (HARE) produces state-of-the-art performance on both zero-shot and in-domain evaluations. We carry out an extensive qualitative analysis to shed light on the agents policies.
Probabilistic Volumetric Fusion for Dense Monocular SLAM
Oct 03, 2022
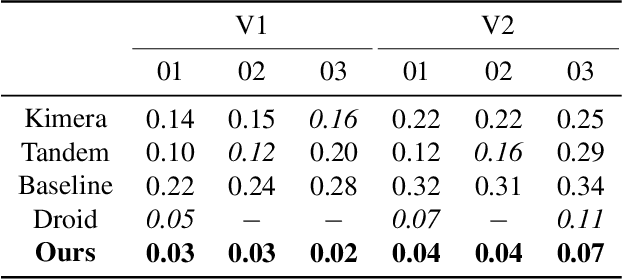
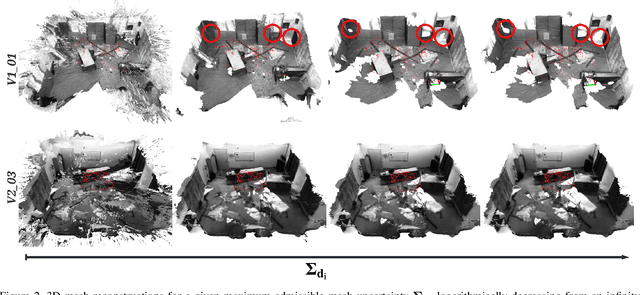
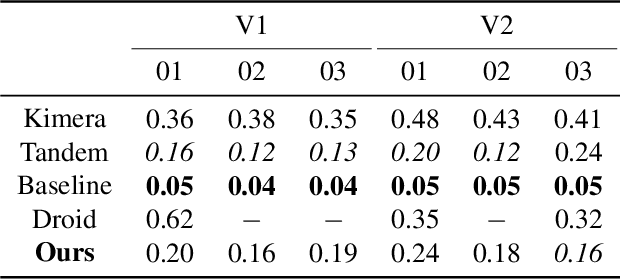
We present a novel method to reconstruct 3D scenes from images by leveraging deep dense monocular SLAM and fast uncertainty propagation. The proposed approach is able to 3D reconstruct scenes densely, accurately, and in real-time while being robust to extremely noisy depth estimates coming from dense monocular SLAM. Differently from previous approaches, that either use ad-hoc depth filters, or that estimate the depth uncertainty from RGB-D cameras' sensor models, our probabilistic depth uncertainty derives directly from the information matrix of the underlying bundle adjustment problem in SLAM. We show that the resulting depth uncertainty provides an excellent signal to weight the depth-maps for volumetric fusion. Without our depth uncertainty, the resulting mesh is noisy and with artifacts, while our approach generates an accurate 3D mesh with significantly fewer artifacts. We provide results on the challenging Euroc dataset, and show that our approach achieves 92% better accuracy than directly fusing depths from monocular SLAM, and up to 90% improvements compared to the best competing approach.
Fine-grained Object Categorization for Service Robots
Oct 03, 2022



A robot working in a human-centered environment is frequently confronted with fine-grained objects that must be distinguished from one another. Fine-grained visual classification (FGVC) still remains a challenging problem due to large intra-category dissimilarity and small inter-category dissimilarity. Furthermore, flaws such as the influence of illumination and information inadequacy persist in fine-grained RGB datasets. We propose a novel deep mixed multi-modality approach based on Vision Transformer (ViT) and Convolutional Neural Network (CNN) to improve the performance of FGVC. Furthermore, we generate two synthetic fine-grained RGB-D datasets consisting of 13 car objects with 720 views and 120 shoes with 7200 sample views. Finally, to assess the performance of the proposed approach, we conducted several experiments using fine-grained RGB-D datasets. Experimental results show that our method outperformed other baselines in terms of recognition accuracy, and achieved 93.40 $\%$ and 91.67 $\%$ recognition accuracy on shoe and car dataset respectively. We made the fine-grained RGB-D datasets publicly available for the benefit of research communities.
Near-Optimal Deployment Efficiency in Reward-Free Reinforcement Learning with Linear Function Approximation
Oct 03, 2022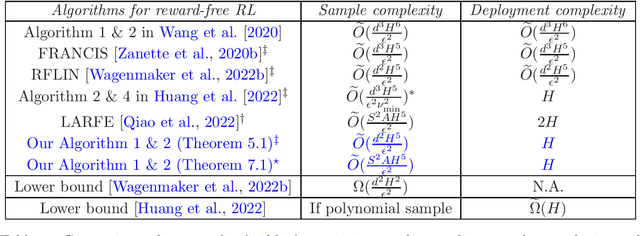

We study the problem of deployment efficient reinforcement learning (RL) with linear function approximation under the \emph{reward-free} exploration setting. This is a well-motivated problem because deploying new policies is costly in real-life RL applications. Under the linear MDP setting with feature dimension $d$ and planning horizon $H$, we propose a new algorithm that collects at most $\widetilde{O}(\frac{d^2H^5}{\epsilon^2})$ trajectories within $H$ deployments to identify $\epsilon$-optimal policy for any (possibly data-dependent) choice of reward functions. To the best of our knowledge, our approach is the first to achieve optimal deployment complexity and optimal $d$ dependence in sample complexity at the same time, even if the reward is known ahead of time. Our novel techniques include an exploration-preserving policy discretization and a generalized G-optimal experiment design, which could be of independent interest. Lastly, we analyze the related problem of regret minimization in low-adaptive RL and provide information-theoretic lower bounds for switching cost and batch complexity.
That Sounds Right: Auditory Self-Supervision for Dynamic Robot Manipulation
Oct 03, 2022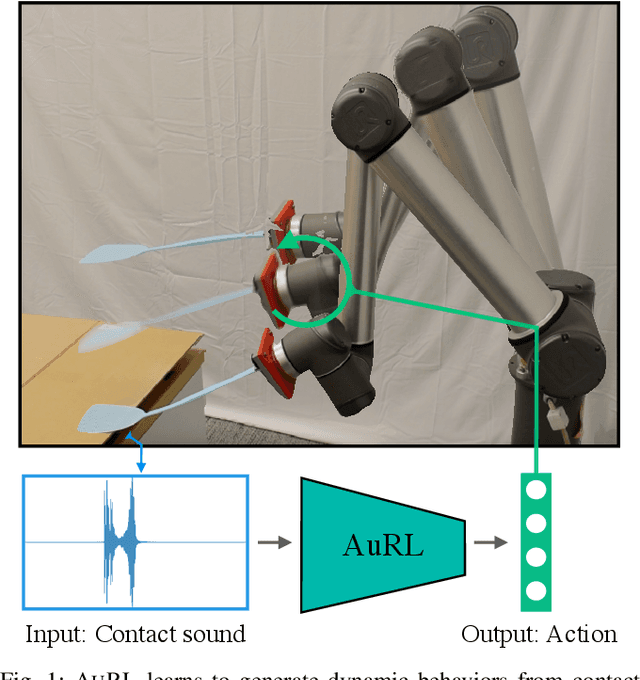

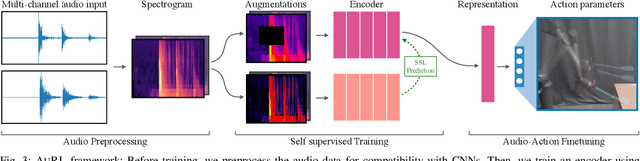
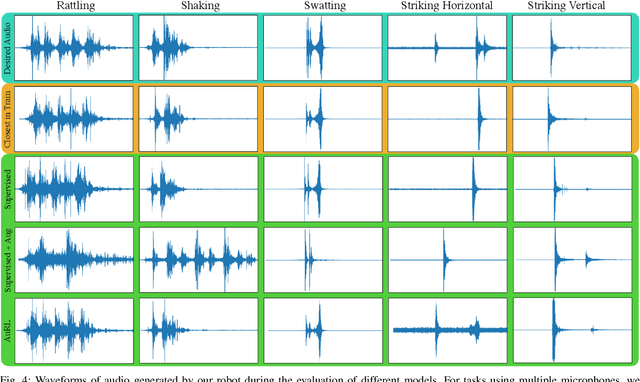
Learning to produce contact-rich, dynamic behaviors from raw sensory data has been a longstanding challenge in robotics. Prominent approaches primarily focus on using visual or tactile sensing, where unfortunately one fails to capture high-frequency interaction, while the other can be too delicate for large-scale data collection. In this work, we propose a data-centric approach to dynamic manipulation that uses an often ignored source of information: sound. We first collect a dataset of 25k interaction-sound pairs across five dynamic tasks using commodity contact microphones. Then, given this data, we leverage self-supervised learning to accelerate behavior prediction from sound. Our experiments indicate that this self-supervised 'pretraining' is crucial to achieving high performance, with a 34.5% lower MSE than plain supervised learning and a 54.3% lower MSE over visual training. Importantly, we find that when asked to generate desired sound profiles, online rollouts of our models on a UR10 robot can produce dynamic behavior that achieves an average of 11.5% improvement over supervised learning on audio similarity metrics.
Eliciting Information with Partial Signals in Repeated Games
Sep 09, 2021

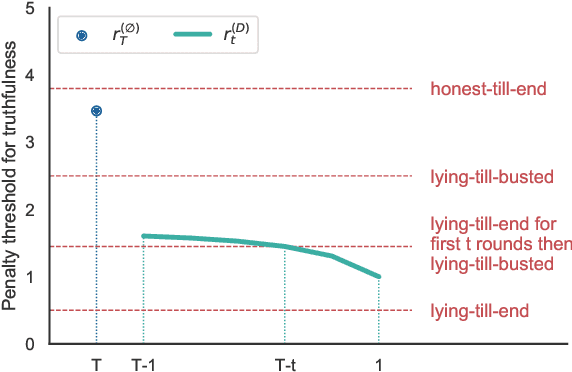
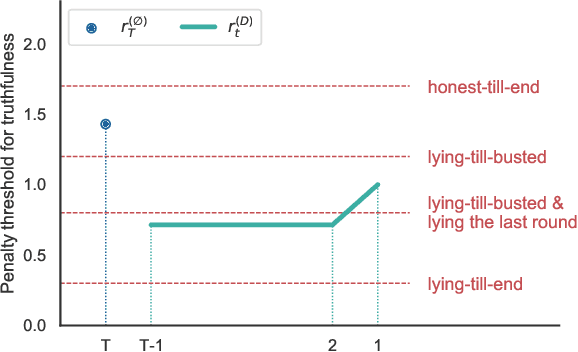
We consider an information elicitation game where the center needs the agent to self-report her actual usage of a service and charges her a payment accordingly. The center can only observe a partial signal, representing part of the agent's true consumption, that is generated randomly from a publicly known distribution. The agent can report any information, as long as it does not contradict the signal, and the center issues a payment based on the reported information. Such problems find application in prosumer pricing, tax filing, etc., when the agent's actual consumption of a service is masked from the center and verification of the submitted reports is impractical. The key difference between the current problem and classic information elicitation problems is that the agent gets to observe the full signal and act strategically, but the center can only see the partial signal. For this seemingly impossible problem, we propose a penalty mechanism that elicits truthful self-reports in a repeated game. In particular, besides charging the agent the reported value, the mechanism charges a penalty proportional to her inconsistent reports. We show how a combination of the penalty rate and the length of the game incentivizes the agent to be truthful for the entire game, a phenomenon we call "fear of tomorrow verification". We show how approximate results for arbitrary distributions can be obtained by analyzing Bernoulli distributions. We extend our mechanism to a multi-agent cost sharing setting and give equilibrium results.