 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MIntRec: A New Dataset for Multimodal Intent Recognition
Sep 09, 2022
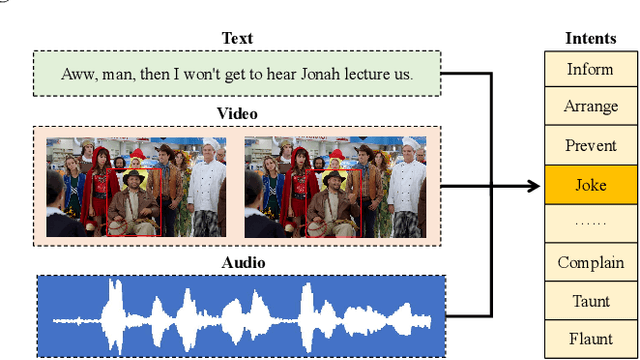

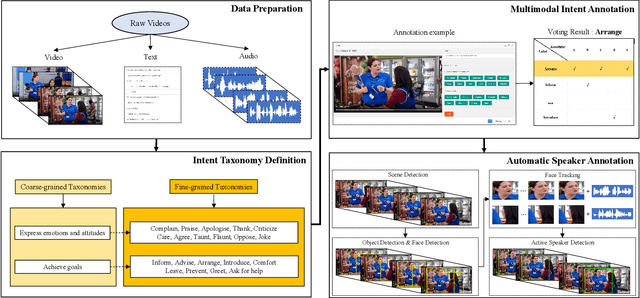
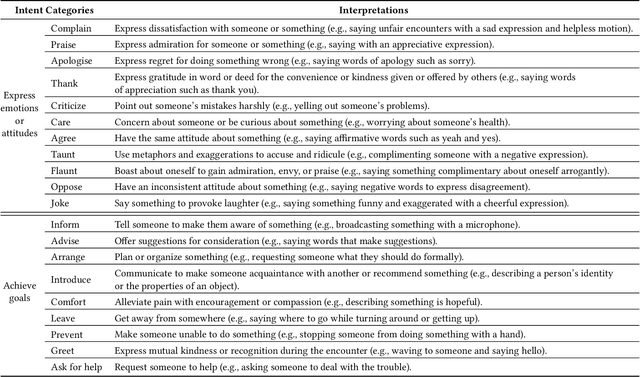
Multimodal intent recognition is a significant task for understanding human language in real-world multimodal scenes. Most existing intent recognition methods have limitations in leveraging the multimodal information due to the restrictions of the benchmark datasets with only text information. This paper introduces a novel dataset for multimodal intent recognition (MIntRec) to address this issue. It formulates coarse-grained and fine-grained intent taxonomies based on the data collected from the TV series Superstore. The dataset consists of 2,224 high-quality samples with text, video, and audio modalities and has multimodal annotations among twenty intent categories. Furthermore, we provide annotated bounding boxes of speakers in each video segment and achieve an automatic process for speaker annotation. MIntRec is helpful for researchers to mine relationships between different modalities to enhance the capability of intent recognition. We extract features from each modality and model cross-modal interactions by adapting three powerful multimodal fusion methods to build baselines. Extensive experiments show that employing the non-verbal modalities achieves substantial improvements compared with the text-only modality, demonstrating the effectiveness of using multimodal information for intent recognition. The gap between the best-performing methods and humans indicates the challenge and importance of this task for the community. The full dataset and codes are available for use at https://github.com/thuiar/MIntRec.
Smart Cup: An impedance sensing based fluid intake monitoring system for beverages classification and freshness detection
Oct 08, 2022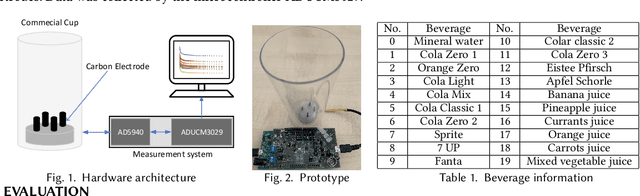
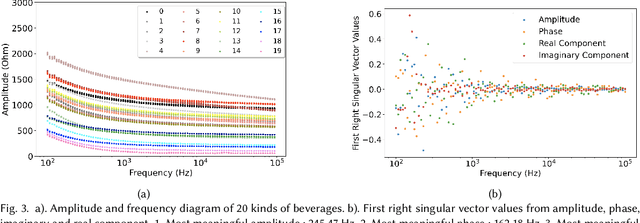
This paper presents a novel beverage intake monitoring system that can accurately recognize beverage kinds and freshness. By mounting carbon electrodes on the commercial cup, the system measures the electrochemical impedance spectrum of the fluid in the cup. We studied the frequency sensitivity of the electrochemical impedance spectrum regarding distinct beverages and the importance of features like amplitude, phase, and real and imaginary components for beverage classification. The results show that features from a low-frequency domain (100 Hz to 1000 Hz) provide more meaningful information for beverage classification than the higher frequency domain. Twenty beverages, including carbonated drinks and juices, were classified with nearly perfect accuracy using a supervised machine learning approach. The same performance was also observed in the freshness recognition, where four different kinds of milk and fruit juice were studied.
LGDN: Language-Guided Denoising Network for Video-Language Modeling
Sep 23, 2022
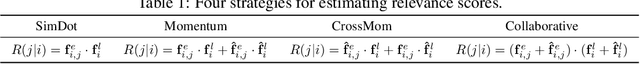
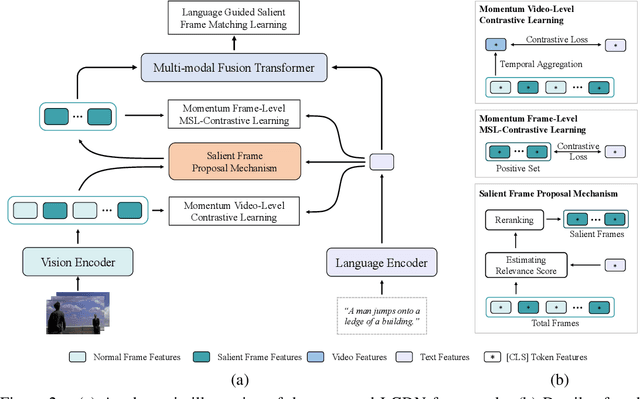
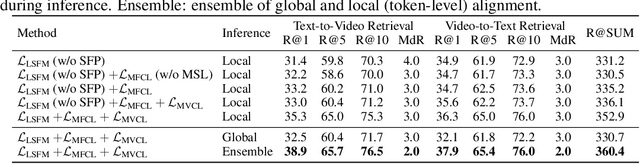
Video-language modeling has attracted much attention with the rapid growth of web videos. Most existing methods assume that the video frames and text description are semantically correlated, and focus on video-language modeling at video level. However, this hypothesis often fails for two reasons: (1) With the rich semantics of video contents, it is difficult to cover all frames with a single video-level description; (2) A raw video typically has noisy/meaningless information (e.g., scenery shot, transition or teaser). Although a number of recent works deploy attention mechanism to alleviate this problem, the irrelevant/noisy information still makes it very difficult to address. To overcome such challenge, we thus propose an efficient and effective model, termed Language-Guided Denoising Network (LGDN), for video-language modeling. Different from most existing methods that utilize all extracted video frames, LGDN dynamically filters out the misaligned or redundant frames under the language supervision and obtains only 2--4 salient frames per video for cross-modal token-level alignment. Extensive experiments on five public datasets show that our LGDN outperforms the state-of-the-arts by large margins. We also provide detailed ablation study to reveal the critical importance of solving the noise issue, in hope of inspiring future video-language work.
Instance-Dependent Noisy Label Learning via Graphical Modelling
Sep 02, 2022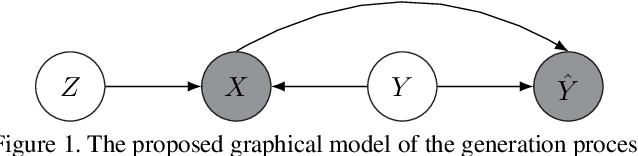
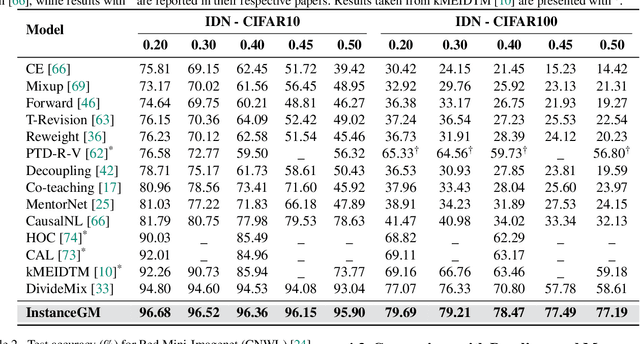
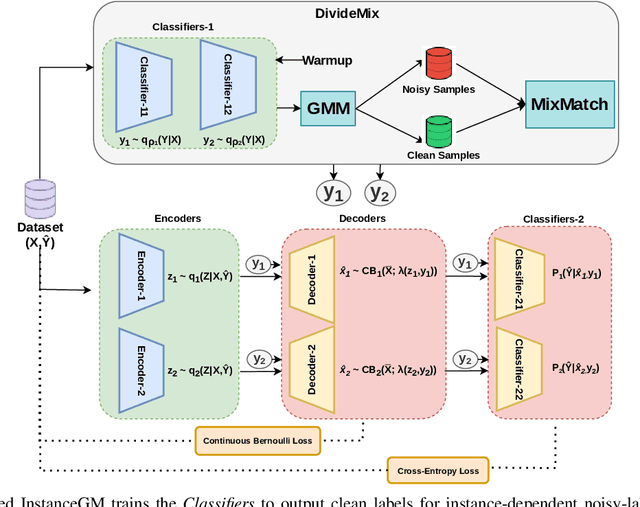
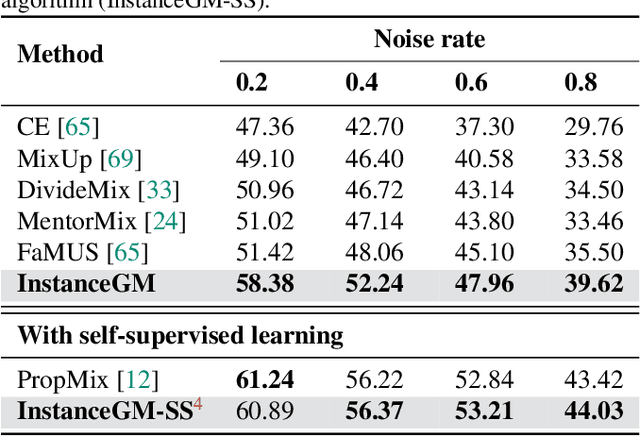
Noisy labels are unavoidable yet troublesome in the ecosystem of deep learning because models can easily overfit them. There are many types of label noise, such as symmetric, asymmetric and instance-dependent noise (IDN), with IDN being the only type that depends on image information. Such dependence on image information makes IDN a critical type of label noise to study, given that labelling mistakes are caused in large part by insufficient or ambiguous information about the visual classes present in images. Aiming to provide an effective technique to address IDN, we present a new graphical modelling approach called InstanceGM, that combines discriminative and generative models. The main contributions of InstanceGM are: i) the use of the continuous Bernoulli distribution to train the generative model, offering significant training advantages, and ii) the exploration of a state-of-the-art noisy-label discriminative classifier to generate clean labels from instance-dependent noisy-label samples. InstanceGM is competitive with current noisy-label learning approaches, particularly in IDN benchmarks using synthetic and real-world datasets, where our method shows better accuracy than the competitors in most experiments.
Autonomous Resource Management in Construction Companies Using Deep Reinforcement Learning Based on IoT
Aug 17, 2022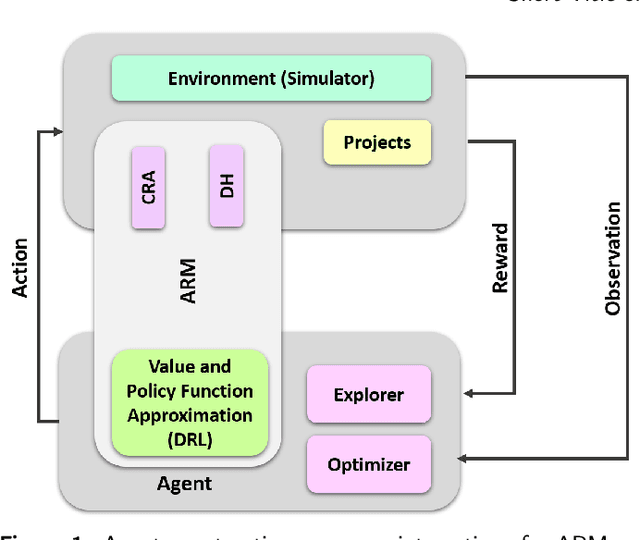
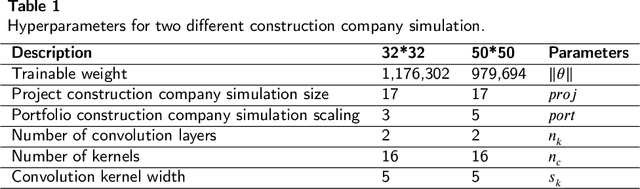
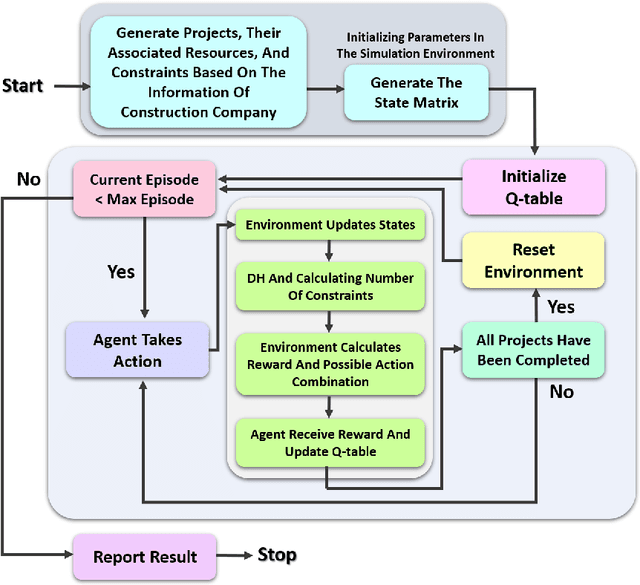

Resource allocation is one of the most critical issues in planning construction projects, due to its direct impact on cost, time, and quality. There are usually specific allocation methods for autonomous resource management according to the projects objectives. However, integrated planning and optimization of utilizing resources in an entire construction organization are scarce. The purpose of this study is to present an automatic resource allocation structure for construction companies based on Deep Reinforcement Learning (DRL), which can be used in various situations. In this structure, Data Harvesting (DH) gathers resource information from the distributed Internet of Things (IoT) sensor devices all over the companys projects to be employed in the autonomous resource management approach. Then, Coverage Resources Allocation (CRA) is compared to the information obtained from DH in which the Autonomous Resource Management (ARM) determines the project of interest. Likewise, Double Deep Q-Networks (DDQNs) with similar models are trained on two distinct assignment situations based on structured resource information of the company to balance objectives with resource constraints. The suggested technique in this paper can efficiently adjust to large resource management systems by combining portfolio information with adopted individual project information. Also, the effects of important information processing parameters on resource allocation performance are analyzed in detail. Moreover, the results of the generalizability of management approaches are presented, indicating no need for additional training when the variables of situations change.
Calibrationless Reconstruction of Uniformly-Undersampled Multi-Channel MR Data with Deep Learning Estimated ESPIRiT Maps
Oct 27, 2022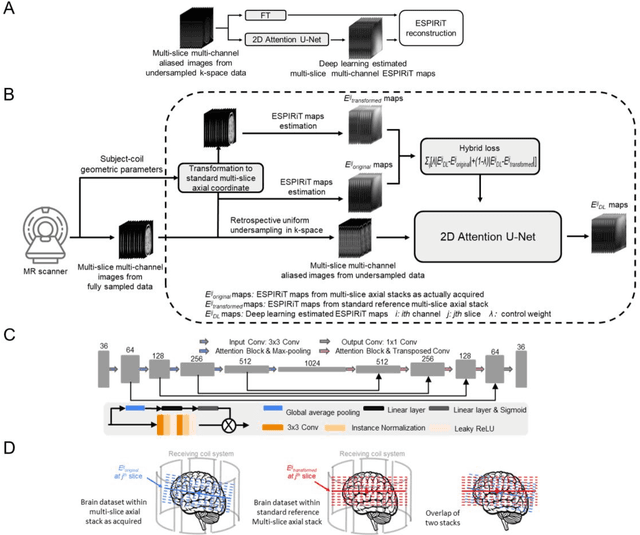
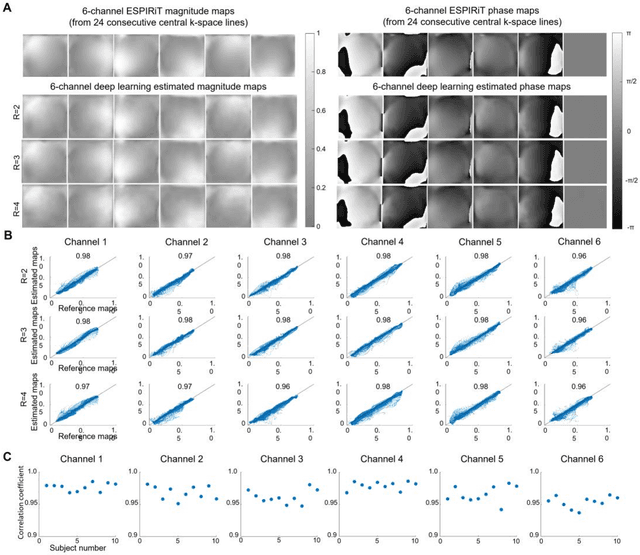
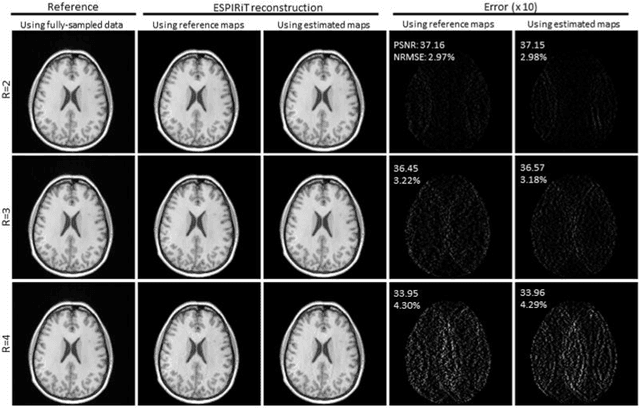
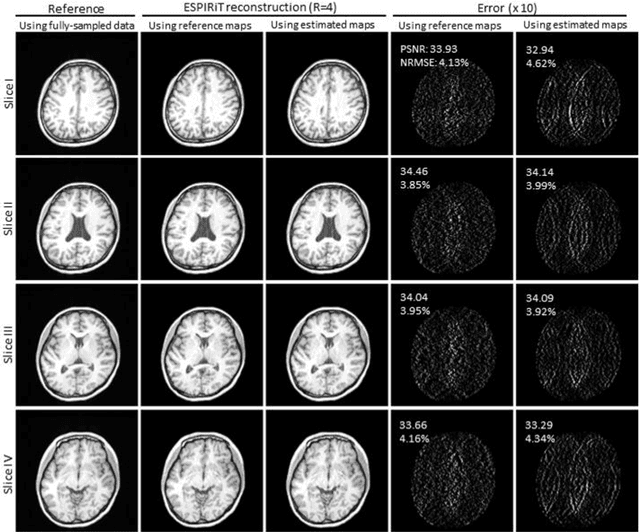
Purpose: To develop a truly calibrationless reconstruction method that derives ESPIRiT maps from uniformly-undersampled multi-channel MR data by deep learning. Methods: ESPIRiT, one commonly used parallel imaging reconstruction technique, forms the images from undersampled MR k-space data using ESPIRiT maps that effectively represents coil sensitivity information. Accurate ESPIRiT map estimation requires quality coil sensitivity calibration or autocalibration data. We present a U-Net based deep learning model to estimate the multi-channel ESPIRiT maps directly from uniformly-undersampled multi-channel multi-slice MR data. The model is trained using fully-sampled multi-slice axial brain datasets from the same MR receiving coil system. To utilize subject-coil geometric parameters available for each dataset, the training imposes a hybrid loss on ESPIRiT maps at the original locations as well as their corresponding locations within the standard reference multi-slice axial stack. The performance of the approach was evaluated using publicly available T1-weighed brain and cardiac data. Results: The proposed model robustly predicted multi-channel ESPIRiT maps from uniformly-undersampled k-space data. They were highly comparable to the reference ESPIRiT maps directly computed from 24 consecutive central k-space lines. Further, they led to excellent ESPIRiT reconstruction performance even at high acceleration, exhibiting a similar level of errors and artifacts to that by using reference ESPIRiT maps. Conclusion: A new deep learning approach is developed to estimate ESPIRiT maps directly from uniformly-undersampled MR data. It presents a general strategy for calibrationless parallel imaging reconstruction through learning from coil and protocol specific data.
LyricJam Sonic: A Generative System for Real-Time Composition and Musical Improvisation
Oct 27, 2022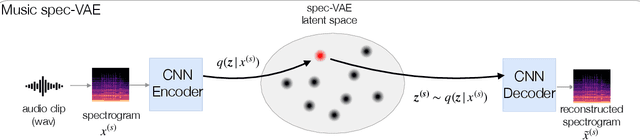

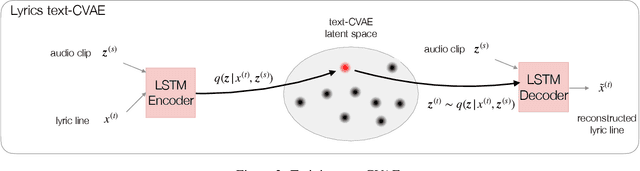
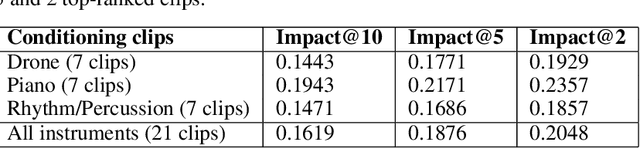
Electronic music artists and sound designers have unique workflow practices that necessitate specialized approaches for developing music information retrieval and creativity support tools. Furthermore, electronic music instruments, such as modular synthesizers, have near-infinite possibilities for sound creation and can be combined to create unique and complex audio paths. The process of discovering interesting sounds is often serendipitous and impossible to replicate. For this reason, many musicians in electronic genres record audio output at all times while they work in the studio. Subsequently, it is difficult for artists to rediscover audio segments that might be suitable for use in their compositions from thousands of hours of recordings. In this paper, we describe LyricJam Sonic -- a novel creative tool for musicians to rediscover their previous recordings, re-contextualize them with other recordings, and create original live music compositions in real-time. A bi-modal AI-driven approach uses generated lyric lines to find matching audio clips from the artist's past studio recordings, and uses them to generate new lyric lines, which in turn are used to find other clips, thus creating a continuous and evolving stream of music and lyrics. The intent is to keep the artists in a state of creative flow conducive to music creation rather than taking them into an analytical/critical state of deliberately searching for past audio segments. The system can run in either a fully autonomous mode without user input, or in a live performance mode, where the artist plays live music, while the system "listens" and creates a continuous stream of music and lyrics in response.
Self-Supervised Training of Speaker Encoder with Multi-Modal Diverse Positive Pairs
Oct 27, 2022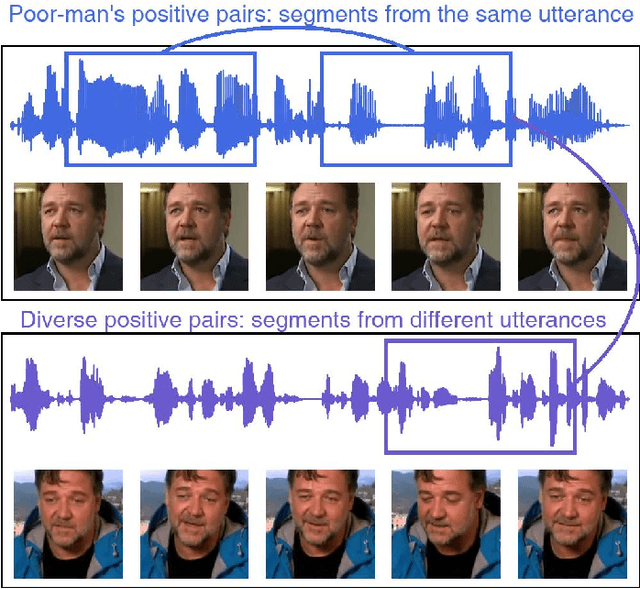
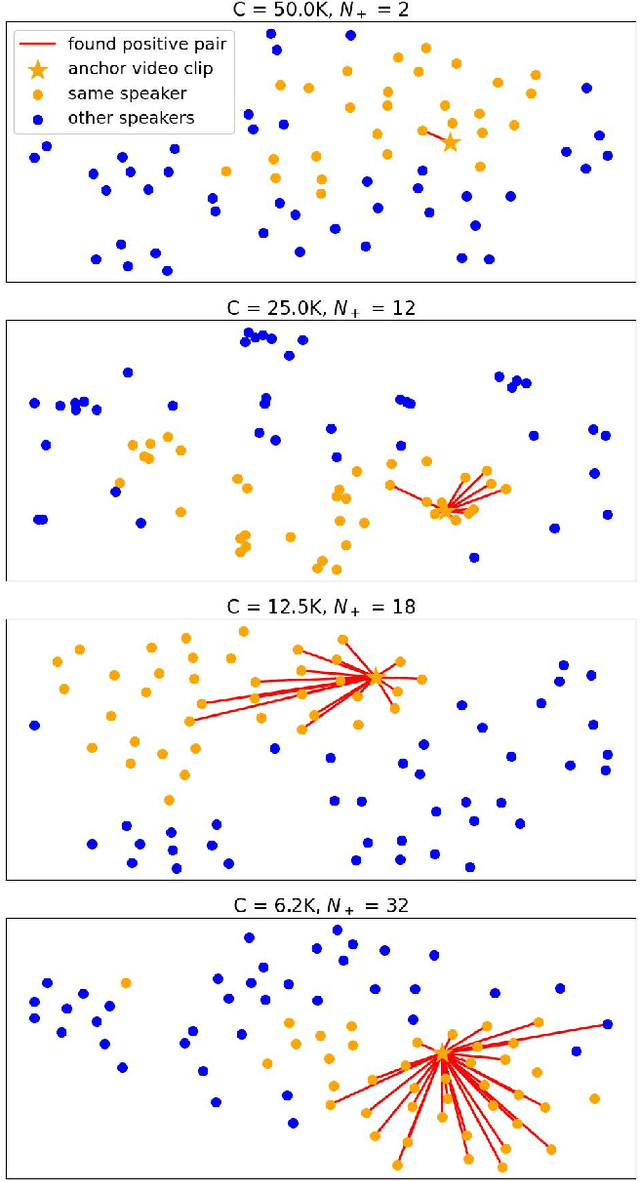
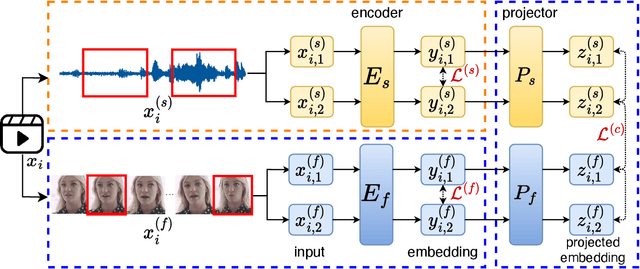
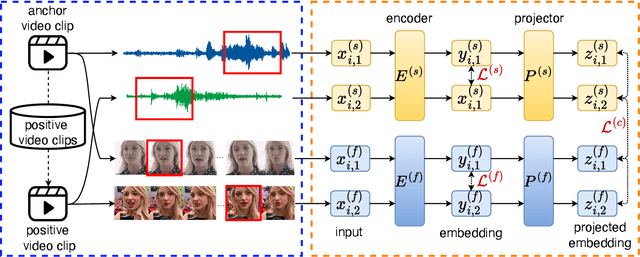
We study a novel neural architecture and its training strategies of speaker encoder for speaker recognition without using any identity labels. The speaker encoder is trained to extract a fixed-size speaker embedding from a spoken utterance of various length. Contrastive learning is a typical self-supervised learning technique. However, the quality of the speaker encoder depends very much on the sampling strategy of positive and negative pairs. It is common that we sample a positive pair of segments from the same utterance. Unfortunately, such poor-man's positive pairs (PPP) lack necessary diversity for the training of a robust encoder. In this work, we propose a multi-modal contrastive learning technique with novel sampling strategies. By cross-referencing between speech and face data, we study a method that finds diverse positive pairs (DPP) for contrastive learning, thus improving the robustness of the speaker encoder. We train the speaker encoder on the VoxCeleb2 dataset without any speaker labels, and achieve an equal error rate (EER) of 2.89\%, 3.17\% and 6.27\% under the proposed progressive clustering strategy, and an EER of 1.44\%, 1.77\% and 3.27\% under the two-stage learning strategy with pseudo labels, on the three test sets of VoxCeleb1. This novel solution outperforms the state-of-the-art self-supervised learning methods by a large margin, at the same time, achieves comparable results with the supervised learning counterpart. We also evaluate our self-supervised learning technique on LRS2 and LRW datasets, where the speaker information is unknown. All experiments suggest that the proposed neural architecture and sampling strategies are robust across datasets.
Supervised Contrastive Learning for Affect Modelling
Aug 25, 2022
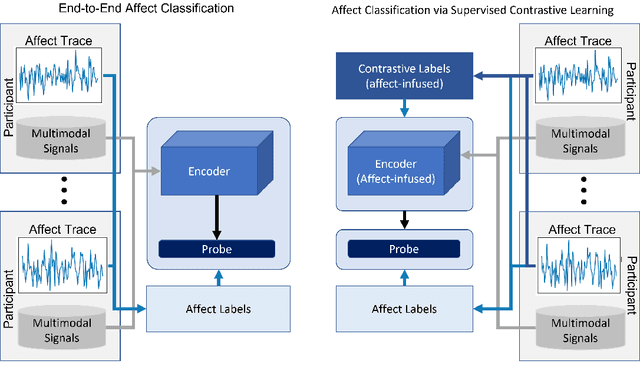
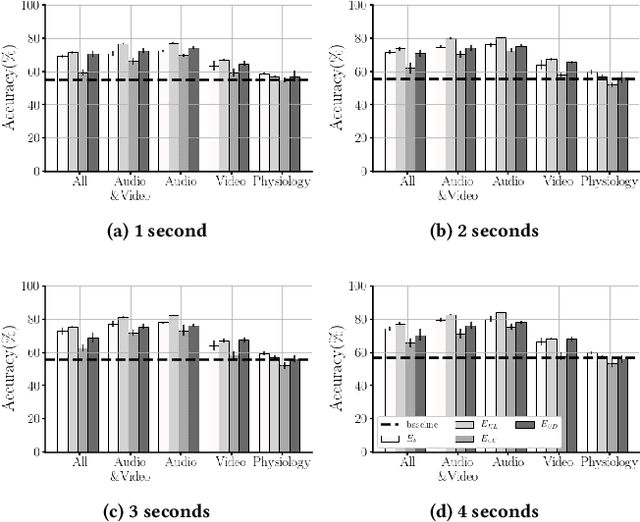
Affect modeling is viewed, traditionally, as the process of mapping measurable affect manifestations from multiple modalities of user input to affect labels. That mapping is usually inferred through end-to-end (manifestation-to-affect) machine learning processes. What if, instead, one trains general, subject-invariant representations that consider affect information and then uses such representations to model affect? In this paper we assume that affect labels form an integral part, and not just the training signal, of an affect representation and we explore how the recent paradigm of contrastive learning can be employed to discover general high-level affect-infused representations for the purpose of modeling affect. We introduce three different supervised contrastive learning approaches for training representations that consider affect information. In this initial study we test the proposed methods for arousal prediction in the RECOLA dataset based on user information from multiple modalities. Results demonstrate the representation capacity of contrastive learning and its efficiency in boosting the accuracy of affect models. Beyond their evidenced higher performance compared to end-to-end arousal classification, the resulting representations are general-purpose and subject-agnostic, as training is guided though general affect information available in any multimodal corpus.
Online Cross-Layer Knowledge Distillation on Graph Neural Networks with Deep Supervision
Oct 25, 2022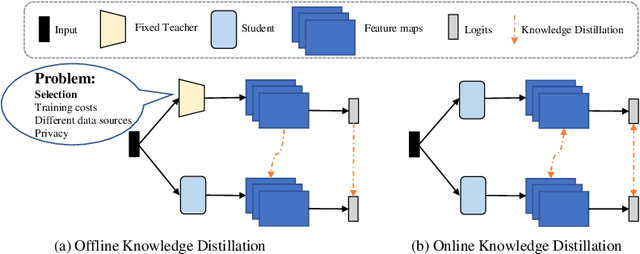
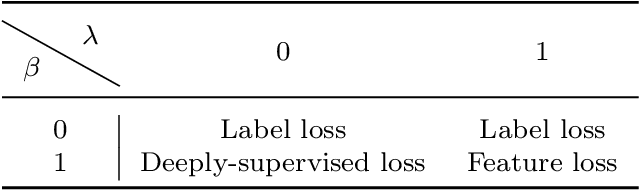
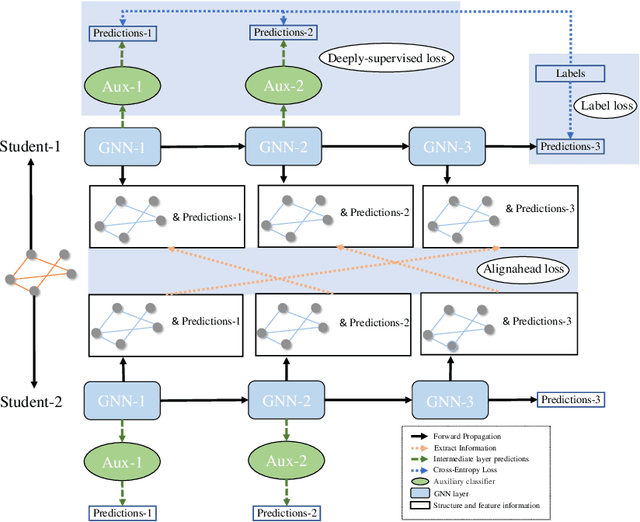
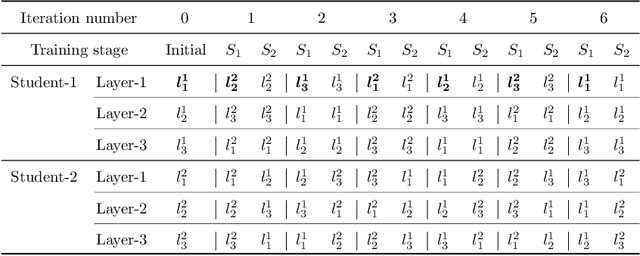
Graph neural networks (GNNs) have become one of the most popular research topics in both academia and industry communities for their strong ability in handling irregular graph data. However, large-scale datasets are posing great challenges for deploying GNNs in edge devices with limited resources and model compression techniques have drawn considerable research attention. Existing model compression techniques such as knowledge distillation (KD) mainly focus on convolutional neural networks (CNNs). Only limited attempts have been made recently for distilling knowledge from GNNs in an offline manner. As the performance of the teacher model does not necessarily improve as the number of layers increases in GNNs, selecting an appropriate teacher model will require substantial efforts. To address these challenges, we propose a novel online knowledge distillation framework called Alignahead++ in this paper. Alignahead++ transfers structure and feature information in a student layer to the previous layer of another simultaneously trained student model in an alternating training procedure. Meanwhile, to avoid over-smoothing problem in GNNs, deep supervision is employed in Alignahead++ by adding an auxiliary classifier in each intermediate layer to prevent the collapse of the node feature embeddings. Experimental results on four datasets including PPI, Cora, PubMed and CiteSeer demonstrate that the student performance is consistently boosted in our collaborative training framework without the supervision of a pre-trained teacher model and its effectiveness can generally be improved by increasing the number of students.