 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Surface Reconstruction from Point Clouds with Visibility Information
Feb 03, 2022
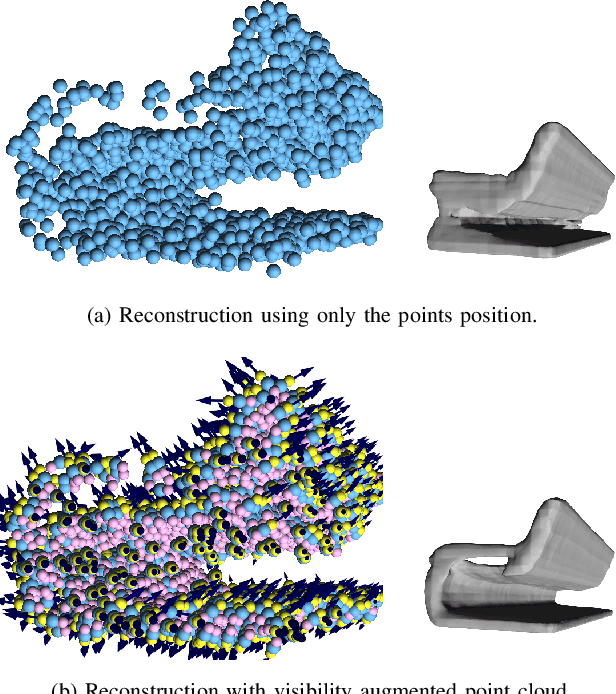


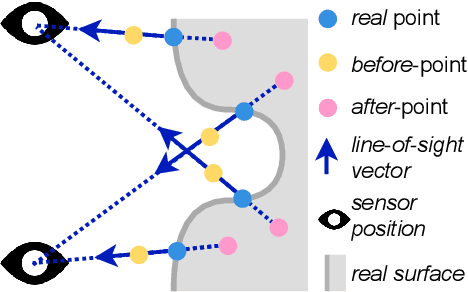
Most current neural networks for reconstructing surfaces from point clouds ignore sensor poses and only operate on raw point locations. Sensor visibility, however, holds meaningful information regarding space occupancy and surface orientation. In this paper, we present two simple ways to augment raw point clouds with visibility information, so it can directly be leveraged by surface reconstruction networks with minimal adaptation. Our proposed modifications consistently improve the accuracy of generated surfaces as well as the generalization ability of the networks to unseen shape domains. Our code and data is available at https://github.com/raphaelsulzer/dsrv-data.
RobustLoc: Robust Camera Pose Regression in Challenging Driving Environments
Nov 21, 2022
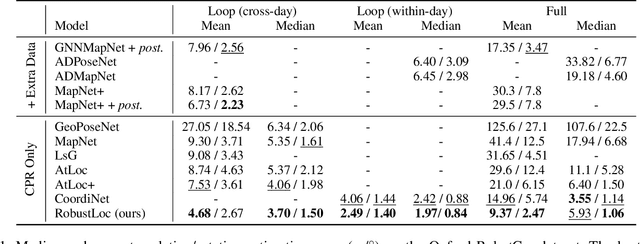
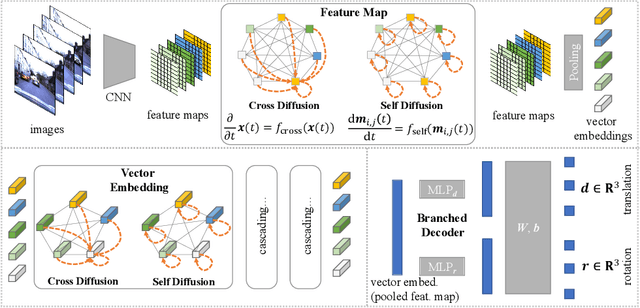
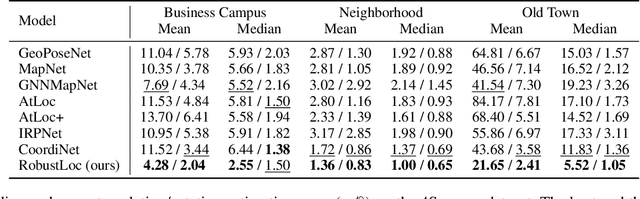
Camera relocalization has various applications in autonomous driving. Previous camera pose regression models consider only ideal scenarios where there is little environmental perturbation. To deal with challenging driving environments that may have changing seasons, weather, illumination, and the presence of unstable objects, we propose RobustLoc, which derives its robustness against perturbations from neural differential equations. Our model uses a convolutional neural network to extract feature maps from multi-view images, a robust neural differential equation diffusion block module to diffuse information interactively, and a branched pose decoder with multi-layer training to estimate the vehicle poses. Experiments demonstrate that RobustLoc surpasses current state-of-the-art camera pose regression models and achieves robust performance in various environments. Our code is released at: https://github.com/sijieaaa/RobustLoc
Intermediate Prototype Mining Transformer for Few-Shot Semantic Segmentation
Oct 13, 2022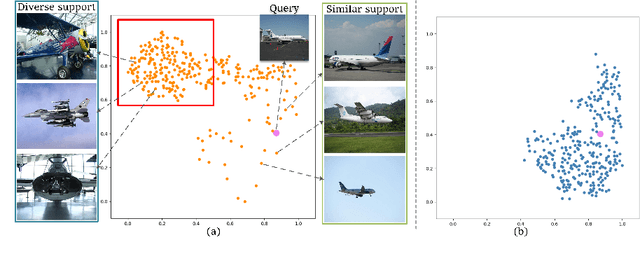
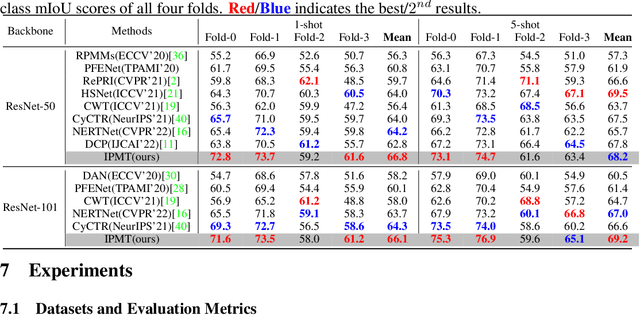
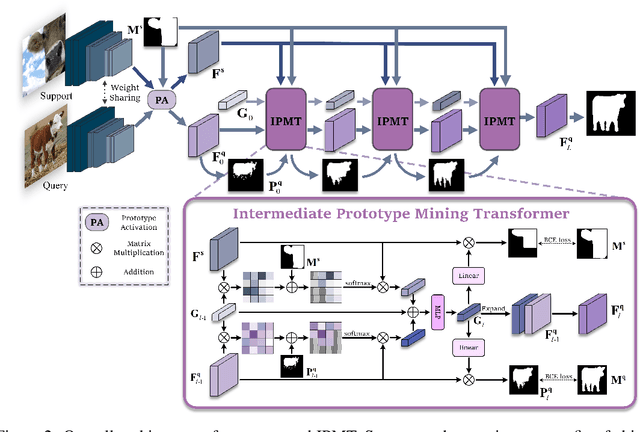
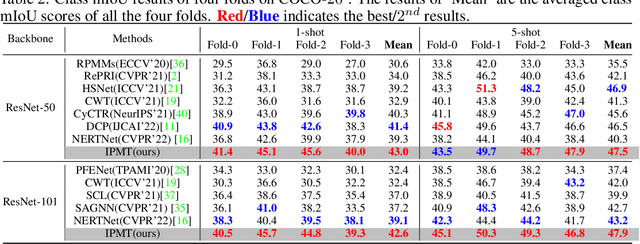
Few-shot semantic segmentation aims to segment the target objects in query under the condition of a few annotated support images. Most previous works strive to mine more effective category information from the support to match with the corresponding objects in query. However, they all ignored the category information gap between query and support images. If the objects in them show large intra-class diversity, forcibly migrating the category information from the support to the query is ineffective. To solve this problem, we are the first to introduce an intermediate prototype for mining both deterministic category information from the support and adaptive category knowledge from the query. Specifically, we design an Intermediate Prototype Mining Transformer (IPMT) to learn the prototype in an iterative way. In each IPMT layer, we propagate the object information in both support and query features to the prototype and then use it to activate the query feature map. By conducting this process iteratively, both the intermediate prototype and the query feature can be progressively improved. At last, the final query feature is used to yield precise segmentation prediction. Extensive experiments on both PASCAL-5i and COCO-20i datasets clearly verify the effectiveness of our IPMT and show that it outperforms previous state-of-the-art methods by a large margin. Code is available at https://github.com/LIUYUANWEI98/IPMT
Probabilistic Autoencoder using Fisher Information
Oct 28, 2021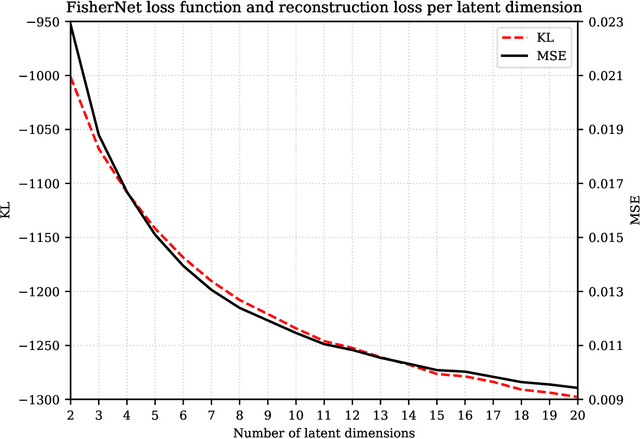
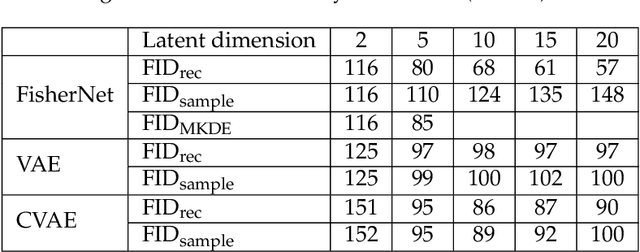
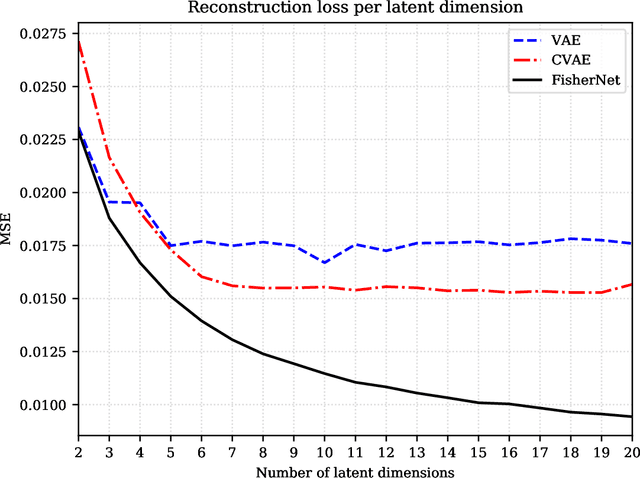

Neural Networks play a growing role in many science disciplines, including physics. Variational Autoencoders (VAEs) are neural networks that are able to represent the essential information of a high dimensional data set in a low dimensional latent space, which have a probabilistic interpretation. In particular the so-called encoder network, the first part of the VAE, which maps its input onto a position in latent space, additionally provides uncertainty information in terms of a variance around this position. In this work, an extension to the Autoencoder architecture is introduced, the FisherNet. In this architecture, the latent space uncertainty is not generated using an additional information channel in the encoder, but derived from the decoder, by means of the Fisher information metric. This architecture has advantages from a theoretical point of view as it provides a direct uncertainty quantification derived from the model, and also accounts for uncertainty cross-correlations. We can show experimentally that the FisherNet produces more accurate data reconstructions than a comparable VAE and its learning performance also apparently scales better with the number of latent space dimensions.
Deepfake Detection via Joint Unsupervised Reconstruction and Supervised Classification
Dec 11, 2022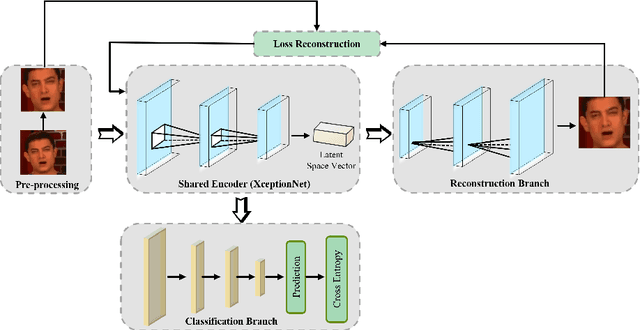
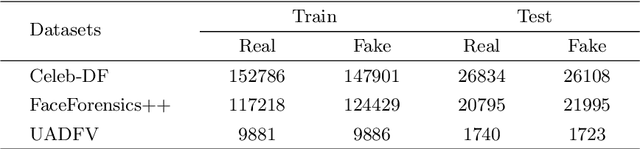

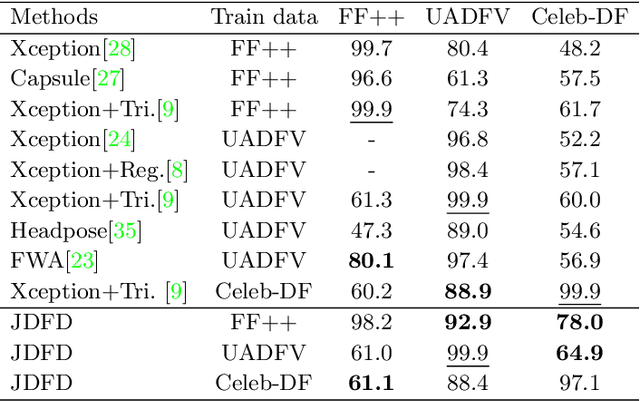
Deep learning has enabled realistic face manipulation (i.e., deepfake), which poses significant concerns over the integrity of the media in circulation. Most existing deep learning techniques for deepfake detection can achieve promising performance in the intra-dataset evaluation setting (i.e., training and testing on the same dataset), but are unable to perform satisfactorily in the inter-dataset evaluation setting (i.e., training on one dataset and testing on another). Most of the previous methods use the backbone network to extract global features for making predictions and only employ binary supervision (i.e., indicating whether the training instances are fake or authentic) to train the network. Classification merely based on the learning of global features leads often leads to weak generalizability to unseen manipulation methods. In addition, the reconstruction task can improve the learned representations. In this paper, we introduce a novel approach for deepfake detection, which considers the reconstruction and classification tasks simultaneously to address these problems. This method shares the information learned by one task with the other, which focuses on a different aspect other existing works rarely consider and hence boosts the overall performance. In particular, we design a two-branch Convolutional AutoEncoder (CAE), in which the Convolutional Encoder used to compress the feature map into the latent representation is shared by both branches. Then the latent representation of the input data is fed to a simple classifier and the unsupervised reconstruction component simultaneously. Our network is trained end-to-end. Experiments demonstrate that our method achieves state-of-the-art performance on three commonly-used datasets, particularly in the cross-dataset evaluation setting.
ResFed: Communication Efficient Federated Learning by Transmitting Deep Compressed Residuals
Dec 11, 2022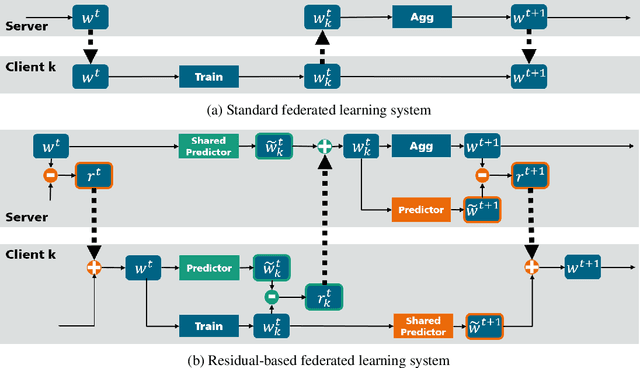
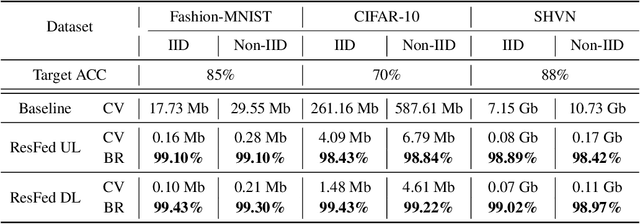
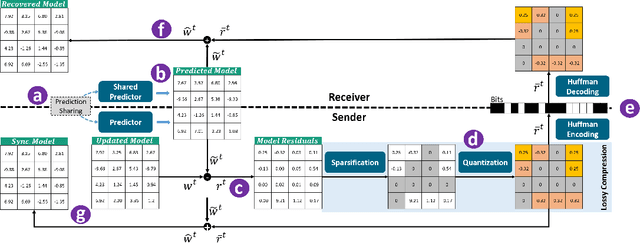
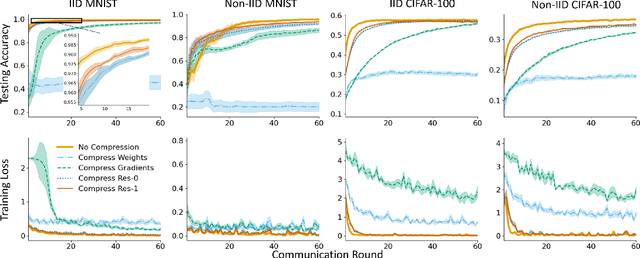
Federated learning enables cooperative training among massively distributed clients by sharing their learned local model parameters. However, with increasing model size, deploying federated learning requires a large communication bandwidth, which limits its deployment in wireless networks. To address this bottleneck, we introduce a residual-based federated learning framework (ResFed), where residuals rather than model parameters are transmitted in communication networks for training. In particular, we integrate two pairs of shared predictors for the model prediction in both server-to-client and client-to-server communication. By employing a common prediction rule, both locally and globally updated models are always fully recoverable in clients and the server. We highlight that the residuals only indicate the quasi-update of a model in a single inter-round, and hence contain more dense information and have a lower entropy than the model, comparing to model weights and gradients. Based on this property, we further conduct lossy compression of the residuals by sparsification and quantization and encode them for efficient communication. The experimental evaluation shows that our ResFed needs remarkably less communication costs and achieves better accuracy by leveraging less sensitive residuals, compared to standard federated learning. For instance, to train a 4.08 MB CNN model on CIFAR-10 with 10 clients under non-independent and identically distributed (Non-IID) setting, our approach achieves a compression ratio over 700X in each communication round with minimum impact on the accuracy. To reach an accuracy of 70%, it saves around 99% of the total communication volume from 587.61 Mb to 6.79 Mb in up-streaming and to 4.61 Mb in down-streaming on average for all clients.
Hi,KIA: A Speech Emotion Recognition Dataset for Wake-Up Words
Nov 07, 2022
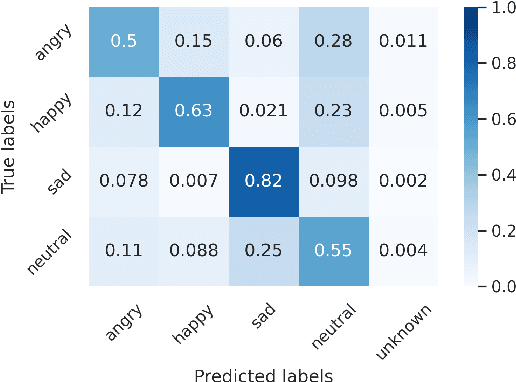
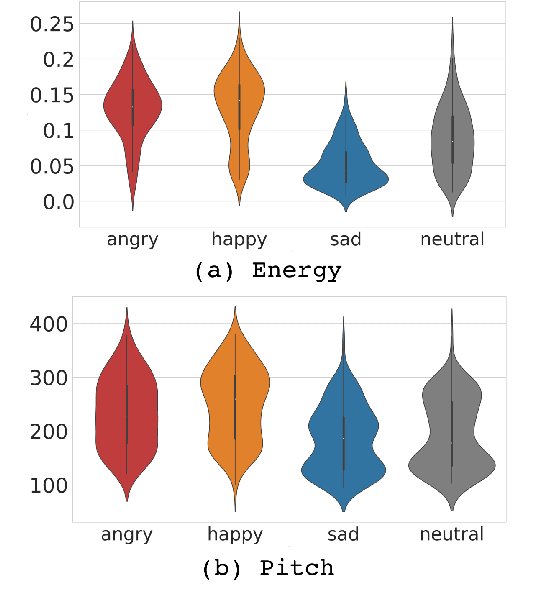
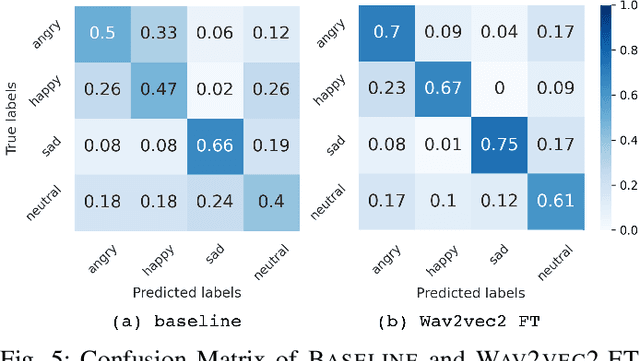
Wake-up words (WUW) is a short sentence used to activate a speech recognition system to receive the user's speech input. WUW utterances include not only the lexical information for waking up the system but also non-lexical information such as speaker identity or emotion. In particular, recognizing the user's emotional state may elaborate the voice communication. However, there is few dataset where the emotional state of the WUW utterances is labeled. In this paper, we introduce Hi, KIA, a new WUW dataset which consists of 488 Korean accent emotional utterances collected from four male and four female speakers and each of utterances is labeled with four emotional states including anger, happy, sad, or neutral. We present the step-by-step procedure to build the dataset, covering scenario selection, post-processing, and human validation for label agreement. Also, we provide two classification models for WUW speech emotion recognition using the dataset. One is based on traditional hand-craft features and the other is a transfer-learning approach using a pre-trained neural network. These classification models could be used as benchmarks in further research.
Fixing Model Bugs with Natural Language Patches
Nov 07, 2022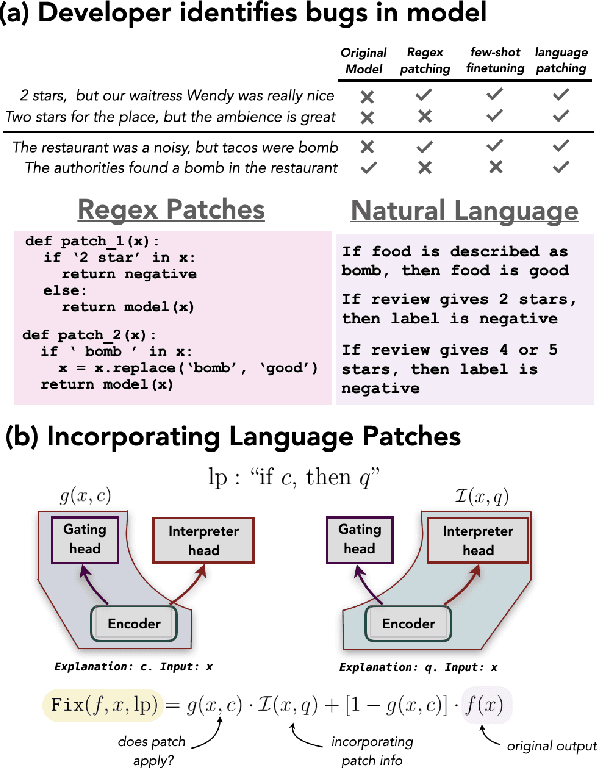
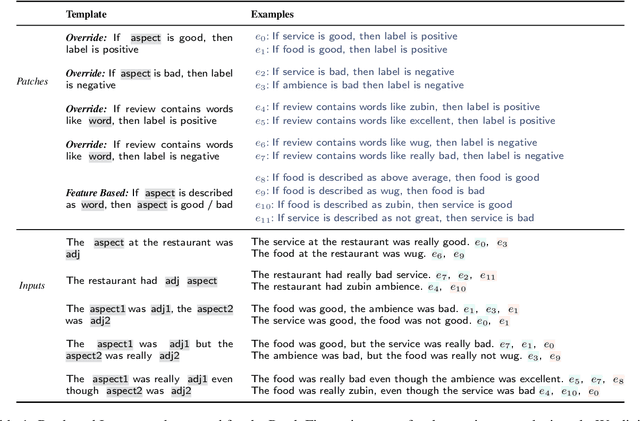

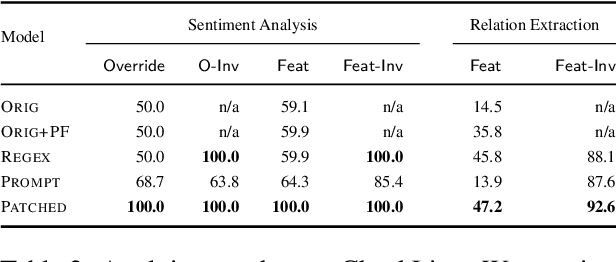
Current approaches for fixing systematic problems in NLP models (e.g. regex patches, finetuning on more data) are either brittle, or labor-intensive and liable to shortcuts. In contrast, humans often provide corrections to each other through natural language. Taking inspiration from this, we explore natural language patches -- declarative statements that allow developers to provide corrective feedback at the right level of abstraction, either overriding the model (``if a review gives 2 stars, the sentiment is negative'') or providing additional information the model may lack (``if something is described as the bomb, then it is good''). We model the task of determining if a patch applies separately from the task of integrating patch information, and show that with a small amount of synthetic data, we can teach models to effectively use real patches on real data -- 1 to 7 patches improve accuracy by ~1-4 accuracy points on different slices of a sentiment analysis dataset, and F1 by 7 points on a relation extraction dataset. Finally, we show that finetuning on as many as 100 labeled examples may be needed to match the performance of a small set of language patches.
Compact Graph Structure Learning via Mutual Information Compression
Jan 14, 2022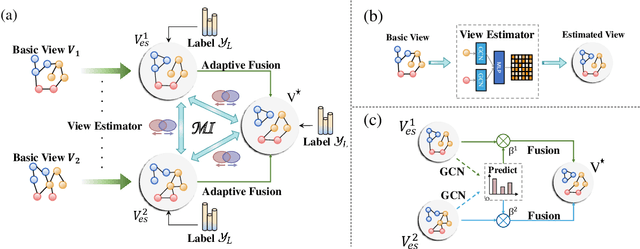
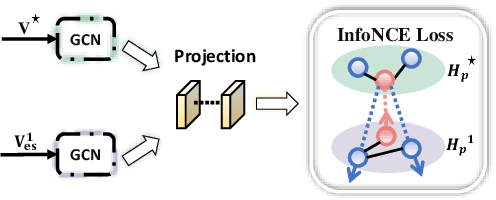
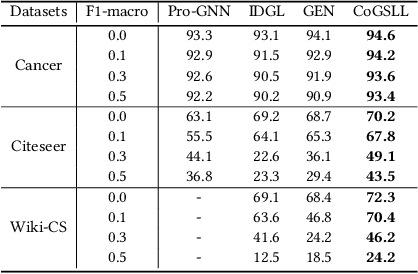
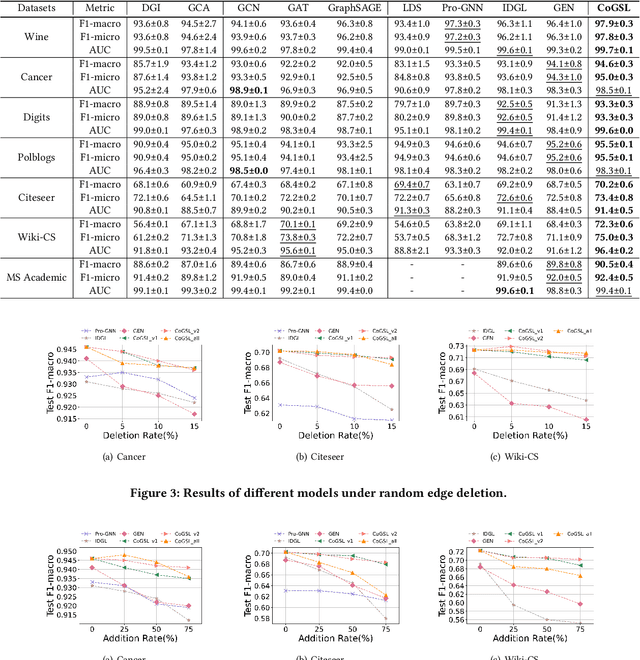
Graph Structure Learning (GSL) recently has attracted considerable attentions in its capacity of optimizing graph structure as well as learning suitable parameters of Graph Neural Networks (GNNs) simultaneously. Current GSL methods mainly learn an optimal graph structure (final view) from single or multiple information sources (basic views), however the theoretical guidance on what is the optimal graph structure is still unexplored. In essence, an optimal graph structure should only contain the information about tasks while compress redundant noise as much as possible, which is defined as "minimal sufficient structure", so as to maintain the accurancy and robustness. How to obtain such structure in a principled way? In this paper, we theoretically prove that if we optimize basic views and final view based on mutual information, and keep their performance on labels simultaneously, the final view will be a minimal sufficient structure. With this guidance, we propose a Compact GSL architecture by MI compression, named CoGSL. Specifically, two basic views are extracted from original graph as two inputs of the model, which are refinedly reestimated by a view estimator. Then, we propose an adaptive technique to fuse estimated views into the final view. Furthermore, we maintain the performance of estimated views and the final view and reduce the mutual information of every two views. To comprehensively evaluate the performance of CoGSL, we conduct extensive experiments on several datasets under clean and attacked conditions, which demonstrate the effectiveness and robustness of CoGSL.
WITT: A Wireless Image Transmission Transformer for Semantic Communications
Nov 02, 2022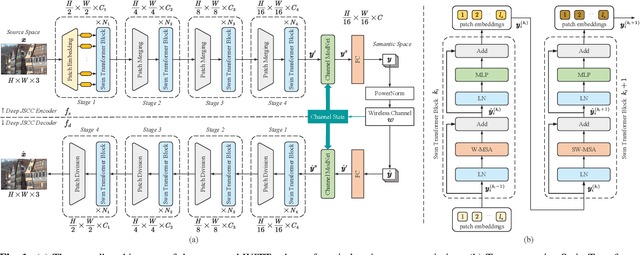

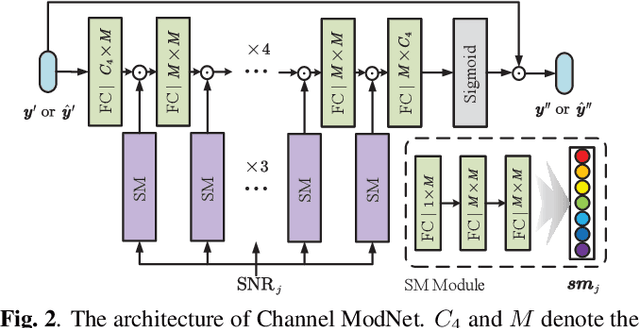
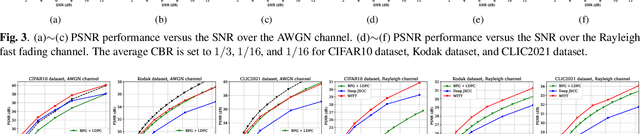
In this paper, we aim to redesign the vision Transformer (ViT) as a new backbone to realize semantic image transmission, termed wireless image transmission transformer (WITT). Previous works build upon convolutional neural networks (CNNs), which are inefficient in capturing global dependencies, resulting in degraded end-to-end transmission performance especially for high-resolution images. To tackle this, the proposed WITT employs Swin Transformers as a more capable backbone to extract long-range information. Different from ViTs in image classification tasks, WITT is highly optimized for image transmission while considering the effect of the wireless channel. Specifically, we propose a spatial modulation module to scale the latent representations according to channel state information, which enhances the ability of a single model to deal with various channel conditions. As a result, extensive experiments verify that our WITT attains better performance for different image resolutions, distortion metrics, and channel conditions. The code is available at https://github.com/KeYang8/WITT.