 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Subword-Delimited Downsampling for Better Character-Level Translation
Dec 02, 2022
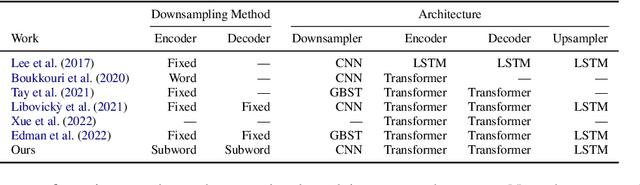
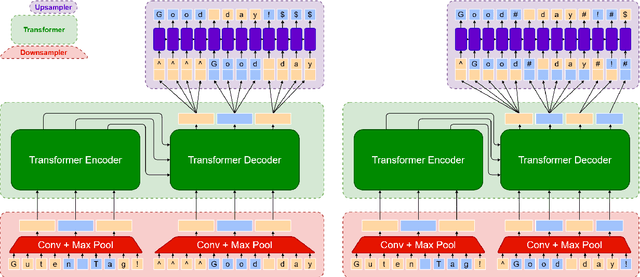
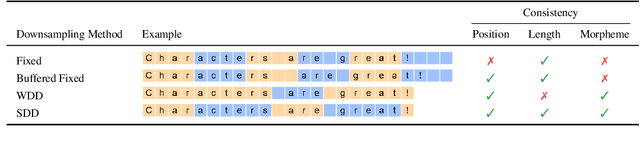
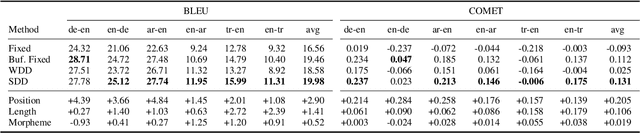
Subword-level models have been the dominant paradigm in NLP. However, character-level models have the benefit of seeing each character individually, providing the model with more detailed information that ultimately could lead to better models. Recent works have shown character-level models to be competitive with subword models, but costly in terms of time and computation. Character-level models with a downsampling component alleviate this, but at the cost of quality, particularly for machine translation. This work analyzes the problems of previous downsampling methods and introduces a novel downsampling method which is informed by subwords. This new downsampling method not only outperforms existing downsampling methods, showing that downsampling characters can be done without sacrificing quality, but also leads to promising performance compared to subword models for translation.
Non-IID Transfer Learning on Graphs
Dec 15, 2022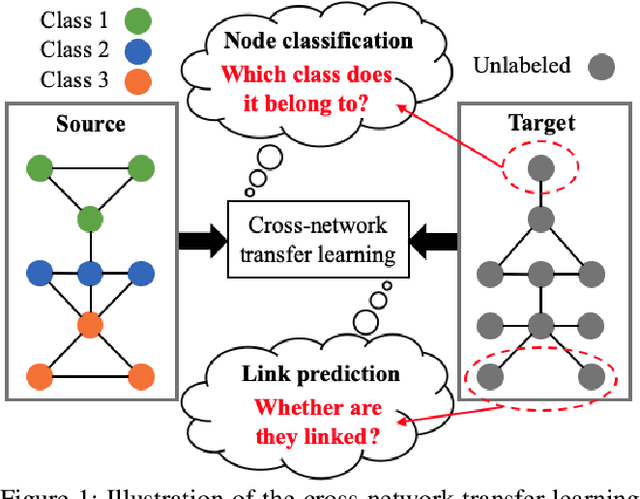
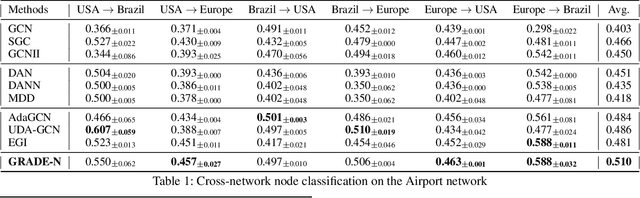
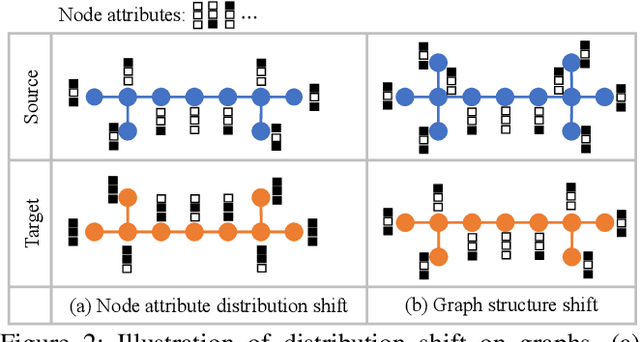
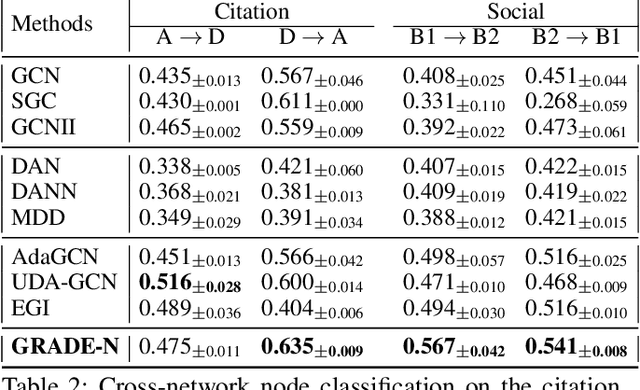
Transfer learning refers to the transfer of knowledge or information from a relevant source domain to a target domain. However, most existing transfer learning theories and algorithms focus on IID tasks, where the source/target samples are assumed to be independent and identically distributed. Very little effort is devoted to theoretically studying the knowledge transferability on non-IID tasks, e.g., cross-network mining. To bridge the gap, in this paper, we propose rigorous generalization bounds and algorithms for cross-network transfer learning from a source graph to a target graph. The crucial idea is to characterize the cross-network knowledge transferability from the perspective of the Weisfeiler-Lehman graph isomorphism test. To this end, we propose a novel Graph Subtree Discrepancy to measure the graph distribution shift between source and target graphs. Then the generalization error bounds on cross-network transfer learning, including both cross-network node classification and link prediction tasks, can be derived in terms of the source knowledge and the Graph Subtree Discrepancy across domains. This thereby motivates us to propose a generic graph adaptive network (GRADE) to minimize the distribution shift between source and target graphs for cross-network transfer learning. Experimental results verify the effectiveness and efficiency of our GRADE framework on both cross-network node classification and cross-domain recommendation tasks.
DeepLSD: Line Segment Detection and Refinement with Deep Image Gradients
Dec 15, 2022
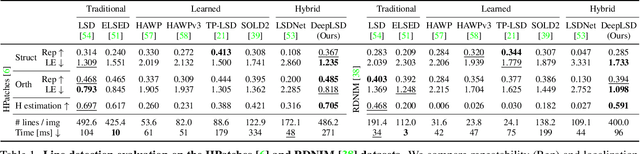
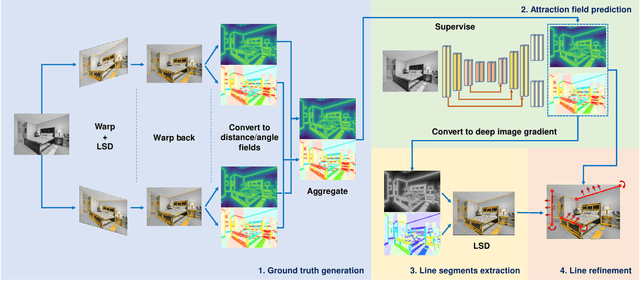
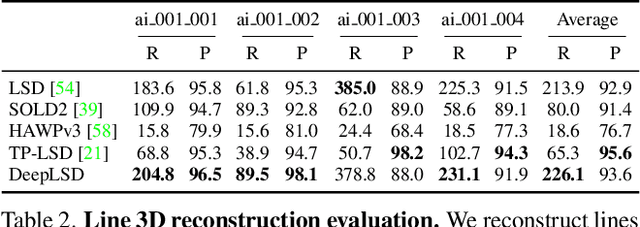
Line segments are ubiquitous in our human-made world and are increasingly used in vision tasks. They are complementary to feature points thanks to their spatial extent and the structural information they provide. Traditional line detectors based on the image gradient are extremely fast and accurate, but lack robustness in noisy images and challenging conditions. Their learned counterparts are more repeatable and can handle challenging images, but at the cost of a lower accuracy and a bias towards wireframe lines. We propose to combine traditional and learned approaches to get the best of both worlds: an accurate and robust line detector that can be trained in the wild without ground truth lines. Our new line segment detector, DeepLSD, processes images with a deep network to generate a line attraction field, before converting it to a surrogate image gradient magnitude and angle, which is then fed to any existing handcrafted line detector. Additionally, we propose a new optimization tool to refine line segments based on the attraction field and vanishing points. This refinement improves the accuracy of current deep detectors by a large margin. We demonstrate the performance of our method on low-level line detection metrics, as well as on several downstream tasks using multiple challenging datasets. The source code and models are available at https://github.com/cvg/DeepLSD.
OAMixer: Object-aware Mixing Layer for Vision Transformers
Dec 13, 2022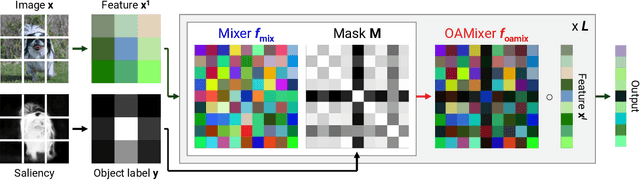
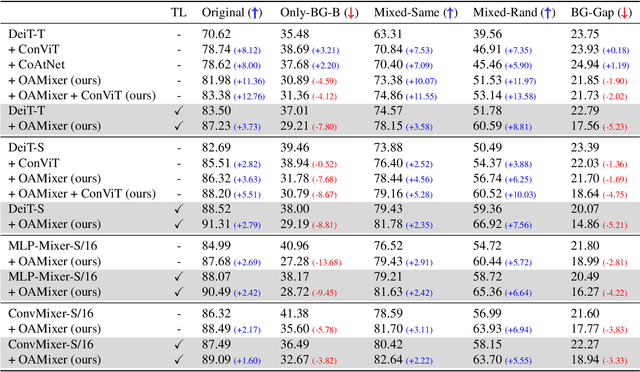
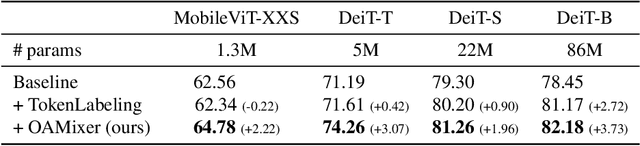

Patch-based models, e.g., Vision Transformers (ViTs) and Mixers, have shown impressive results on various visual recognition tasks, alternating classic convolutional networks. While the initial patch-based models (ViTs) treated all patches equally, recent studies reveal that incorporating inductive bias like spatiality benefits the representations. However, most prior works solely focused on the location of patches, overlooking the scene structure of images. Thus, we aim to further guide the interaction of patches using the object information. Specifically, we propose OAMixer (object-aware mixing layer), which calibrates the patch mixing layers of patch-based models based on the object labels. Here, we obtain the object labels in unsupervised or weakly-supervised manners, i.e., no additional human-annotating cost is necessary. Using the object labels, OAMixer computes a reweighting mask with a learnable scale parameter that intensifies the interaction of patches containing similar objects and applies the mask to the patch mixing layers. By learning an object-centric representation, we demonstrate that OAMixer improves the classification accuracy and background robustness of various patch-based models, including ViTs, MLP-Mixers, and ConvMixers. Moreover, we show that OAMixer enhances various downstream tasks, including large-scale classification, self-supervised learning, and multi-object recognition, verifying the generic applicability of OAMixer
DiffStack: A Differentiable and Modular Control Stack for Autonomous Vehicles
Dec 13, 2022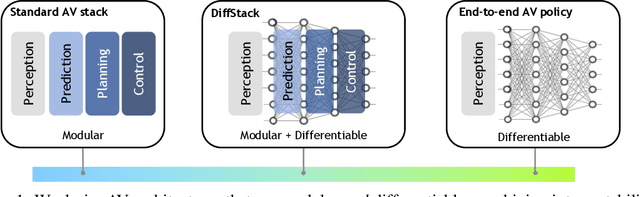
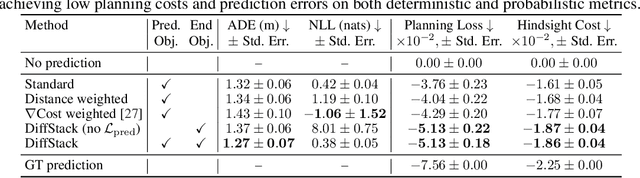
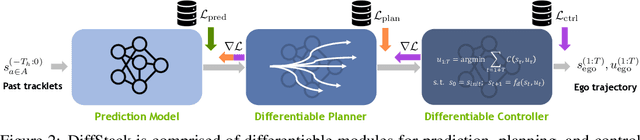
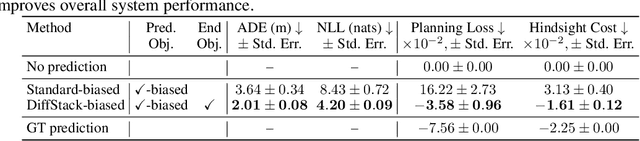
Autonomous vehicle (AV) stacks are typically built in a modular fashion, with explicit components performing detection, tracking, prediction, planning, control, etc. While modularity improves reusability, interpretability, and generalizability, it also suffers from compounding errors, information bottlenecks, and integration challenges. To overcome these challenges, a prominent approach is to convert the AV stack into an end-to-end neural network and train it with data. While such approaches have achieved impressive results, they typically lack interpretability and reusability, and they eschew principled analytical components, such as planning and control, in favor of deep neural networks. To enable the joint optimization of AV stacks while retaining modularity, we present DiffStack, a differentiable and modular stack for prediction, planning, and control. Crucially, our model-based planning and control algorithms leverage recent advancements in differentiable optimization to produce gradients, enabling optimization of upstream components, such as prediction, via backpropagation through planning and control. Our results on the nuScenes dataset indicate that end-to-end training with DiffStack yields substantial improvements in open-loop and closed-loop planning metrics by, e.g., learning to make fewer prediction errors that would affect planning. Beyond these immediate benefits, DiffStack opens up new opportunities for fully data-driven yet modular and interpretable AV architectures. Project website: https://sites.google.com/view/diffstack
On the Evolution of (Hateful) Memes by Means of Multimodal Contrastive Learning
Dec 13, 2022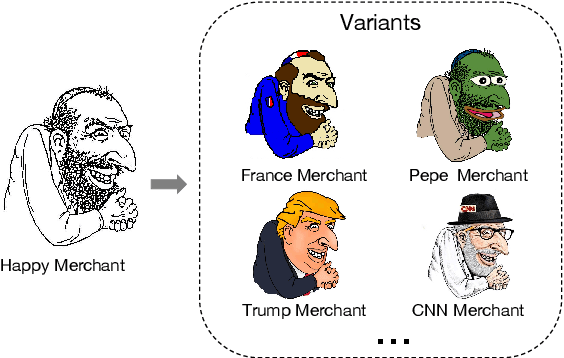


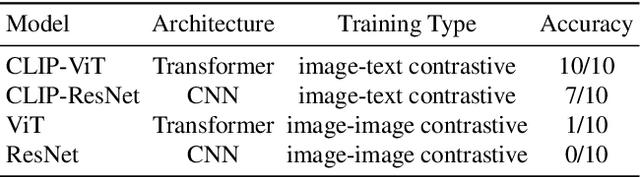
The dissemination of hateful memes online has adverse effects on social media platforms and the real world. Detecting hateful memes is challenging, one of the reasons being the evolutionary nature of memes; new hateful memes can emerge by fusing hateful connotations with other cultural ideas or symbols. In this paper, we propose a framework that leverages multimodal contrastive learning models, in particular OpenAI's CLIP, to identify targets of hateful content and systematically investigate the evolution of hateful memes. We find that semantic regularities exist in CLIP-generated embeddings that describe semantic relationships within the same modality (images) or across modalities (images and text). Leveraging this property, we study how hateful memes are created by combining visual elements from multiple images or fusing textual information with a hateful image. We demonstrate the capabilities of our framework for analyzing the evolution of hateful memes by focusing on antisemitic memes, particularly the Happy Merchant meme. Using our framework on a dataset extracted from 4chan, we find 3.3K variants of the Happy Merchant meme, with some linked to specific countries, persons, or organizations. We envision that our framework can be used to aid human moderators by flagging new variants of hateful memes so that moderators can manually verify them and mitigate the problem of hateful content online.
Scalable and Sample Efficient Distributed Policy Gradient Algorithms in Multi-Agent Networked Systems
Dec 13, 2022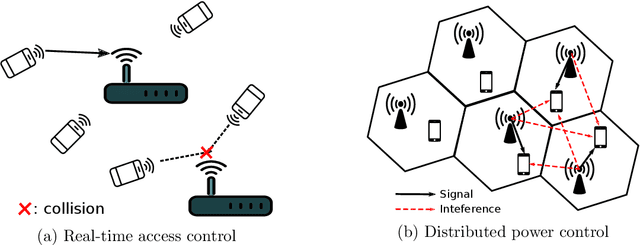
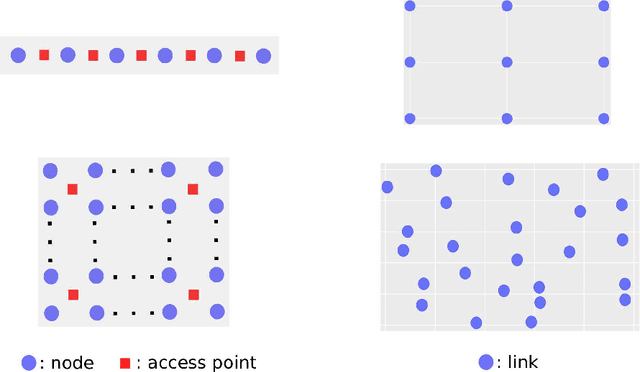
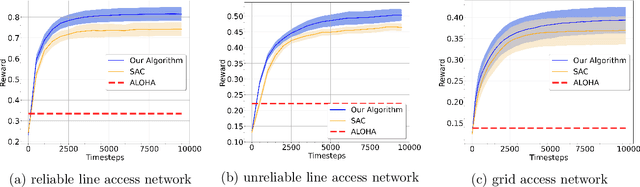
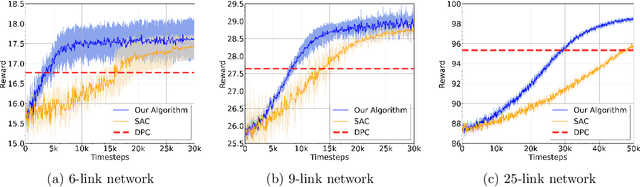
This paper studies a class of multi-agent reinforcement learning (MARL) problems where the reward that an agent receives depends on the states of other agents, but the next state only depends on the agent's own current state and action. We name it REC-MARL standing for REward-Coupled Multi-Agent Reinforcement Learning. REC-MARL has a range of important applications such as real-time access control and distributed power control in wireless networks. This paper presents a distributed and optimal policy gradient algorithm for REC-MARL. The proposed algorithm is distributed in two aspects: (i) the learned policy is a distributed policy that maps a local state of an agent to its local action and (ii) the learning/training is distributed, during which each agent updates its policy based on its own and neighbors' information. The learned policy is provably optimal among all local policies and its regret bounds depend on the dimension of local states and actions. This distinguishes our result from most existing results on MARL, which often obtain stationary-point policies. The experimental results of our algorithm for the real-time access control and power control in wireless networks show that our policy significantly outperforms the state-of-the-art algorithms and well-known benchmarks.
ALSO: Automotive Lidar Self-supervision by Occupancy estimation
Dec 13, 2022
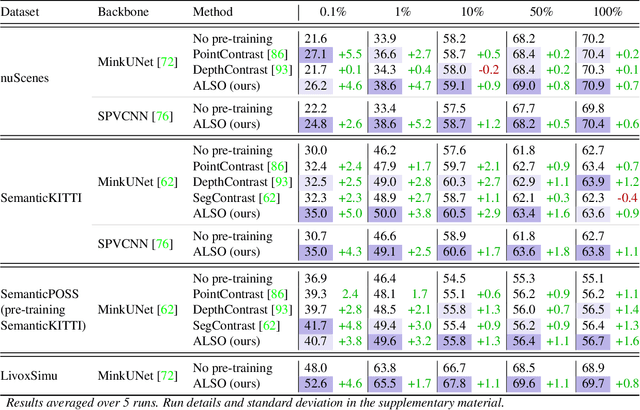
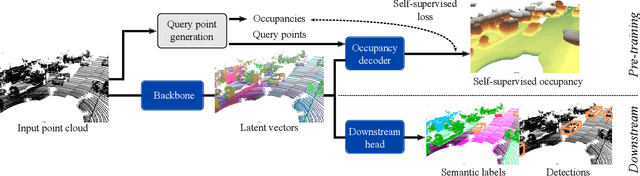
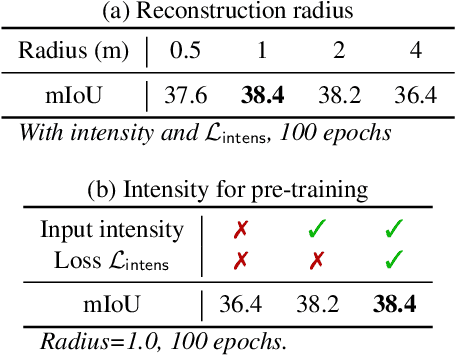
We propose a new self-supervised method for pre-training the backbone of deep perception models operating on point clouds. The core idea is to train the model on a pretext task which is the reconstruction of the surface on which the 3D points are sampled, and to use the underlying latent vectors as input to the perception head. The intuition is that if the network is able to reconstruct the scene surface, given only sparse input points, then it probably also captures some fragments of semantic information, that can be used to boost an actual perception task. This principle has a very simple formulation, which makes it both easy to implement and widely applicable to a large range of 3D sensors and deep networks performing semantic segmentation or object detection. In fact, it supports a single-stream pipeline, as opposed to most contrastive learning approaches, allowing training on limited resources. We conducted extensive experiments on various autonomous driving datasets, involving very different kinds of lidars, for both semantic segmentation and object detection. The results show the effectiveness of our method to learn useful representations without any annotation, compared to existing approaches. Code is available at https://github.com/valeoai/ALSO
A Novel Deep Reinforcement Learning Based Automated Stock Trading System Using Cascaded LSTM Networks
Dec 06, 2022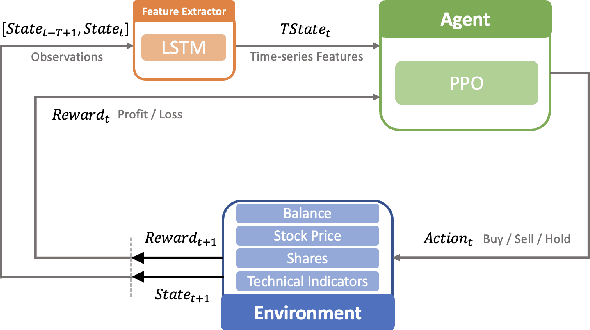
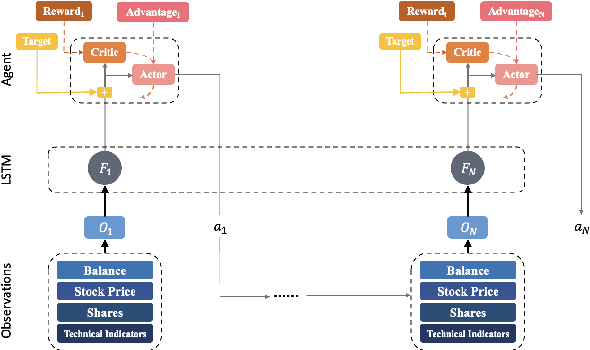

More and more stock trading strategies are constructed using deep reinforcement learning (DRL) algorithms, but DRL methods originally widely used in the gaming community are not directly adaptable to financial data with low signal-to-noise ratios and unevenness, and thus suffer from performance shortcomings. In this paper, to capture the hidden information, we propose a DRL based stock trading system using cascaded LSTM, which first uses LSTM to extract the time-series features from stock daily data, and then the features extracted are fed to the agent for training, while the strategy functions in reinforcement learning also use another LSTM for training. Experiments in DJI in the US market and SSE50 in the Chinese stock market show that our model outperforms previous baseline models in terms of cumulative returns and Sharp ratio, and this advantage is more significant in the Chinese stock market, a merging market. It indicates that our proposed method is a promising way to build a automated stock trading system.
Document-Level Abstractive Summarization
Dec 06, 2022
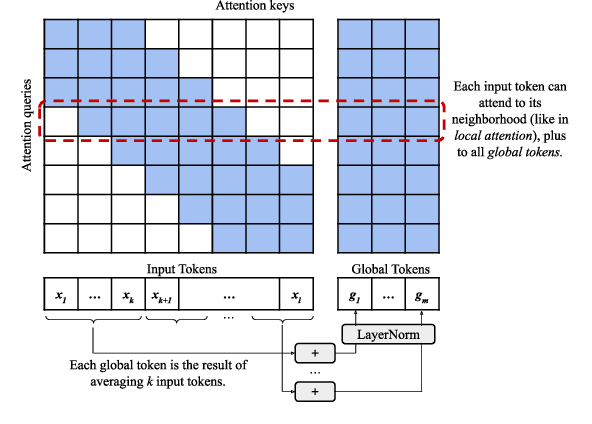
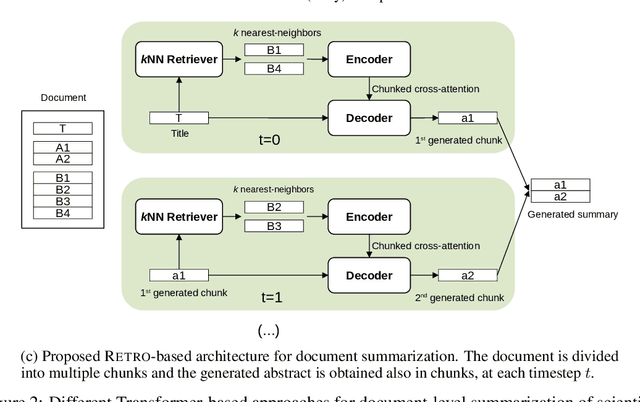

The task of automatic text summarization produces a concise and fluent text summary while preserving key information and overall meaning. Recent approaches to document-level summarization have seen significant improvements in recent years by using models based on the Transformer architecture. However, the quadratic memory and time complexities with respect to the sequence length make them very expensive to use, especially with long sequences, as required by document-level summarization. Our work addresses the problem of document-level summarization by studying how efficient Transformer techniques can be used to improve the automatic summarization of very long texts. In particular, we will use the arXiv dataset, consisting of several scientific papers and the corresponding abstracts, as baselines for this work. Then, we propose a novel retrieval-enhanced approach based on the architecture which reduces the cost of generating a summary of the entire document by processing smaller chunks. The results were below the baselines but suggest a more efficient memory a consumption and truthfulness.