 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Alignment: A simple and effective proxy for model merging in computer vision
Apr 14, 2026Efficiently merging several models fine-tuned for different tasks, but stemming from the same pretrained base model, is of great practical interest. Despite extensive prior work, most evaluations of model merging in computer vision are restricted to image classification using CLIP, where different classification datasets define different tasks. In this work, our goal is to make model merging more practical and show its relevance on challenging scenarios beyond this specific setting. In most vision scenarios, different tasks rely on trainable and usually heterogeneous decoders. Differently from previous studies with frozen decoders, where merged models can be evaluated right away, the non-trivial cost of decoder training renders hyperparameter selection based on downstream performance impractical. To address this, we introduce the task alignment proxy, and show how it can be used to speed up hyperparameter selection by orders of magnitude while retaining performance. Equipped with the task alignment proxy, we extend the applicability of model merging to multi-task vision models beyond CLIP-based classification.
Train Till You Drop: Towards Stable and Robust Source-free Unsupervised 3D Domain Adaptation
Sep 06, 2024We tackle the challenging problem of source-free unsupervised domain adaptation (SFUDA) for 3D semantic segmentation. It amounts to performing domain adaptation on an unlabeled target domain without any access to source data; the available information is a model trained to achieve good performance on the source domain. A common issue with existing SFUDA approaches is that performance degrades after some training time, which is a by product of an under-constrained and ill-posed problem. We discuss two strategies to alleviate this issue. First, we propose a sensible way to regularize the learning problem. Second, we introduce a novel criterion based on agreement with a reference model. It is used (1) to stop the training when appropriate and (2) as validator to select hyperparameters without any knowledge on the target domain. Our contributions are easy to implement and readily amenable for all SFUDA methods, ensuring stable improvements over all baselines. We validate our findings on various 3D lidar settings, achieving state-of-the-art performance. The project repository (with code) is: github.com/valeoai/TTYD.
ALSO: Automotive Lidar Self-supervision by Occupancy estimation
Dec 13, 2022



We propose a new self-supervised method for pre-training the backbone of deep perception models operating on point clouds. The core idea is to train the model on a pretext task which is the reconstruction of the surface on which the 3D points are sampled, and to use the underlying latent vectors as input to the perception head. The intuition is that if the network is able to reconstruct the scene surface, given only sparse input points, then it probably also captures some fragments of semantic information, that can be used to boost an actual perception task. This principle has a very simple formulation, which makes it both easy to implement and widely applicable to a large range of 3D sensors and deep networks performing semantic segmentation or object detection. In fact, it supports a single-stream pipeline, as opposed to most contrastive learning approaches, allowing training on limited resources. We conducted extensive experiments on various autonomous driving datasets, involving very different kinds of lidars, for both semantic segmentation and object detection. The results show the effectiveness of our method to learn useful representations without any annotation, compared to existing approaches. Code is available at https://github.com/valeoai/ALSO
Generative Zero-Shot Learning for Semantic Segmentation of 3D Point Cloud
Aug 23, 2021
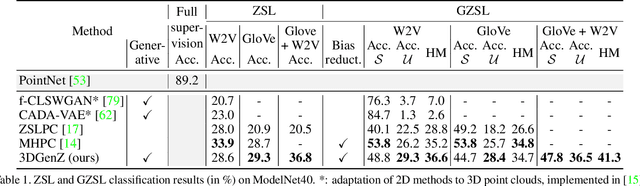
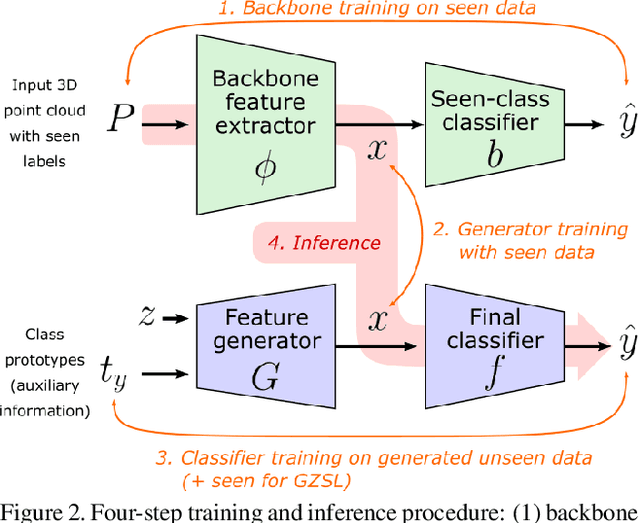
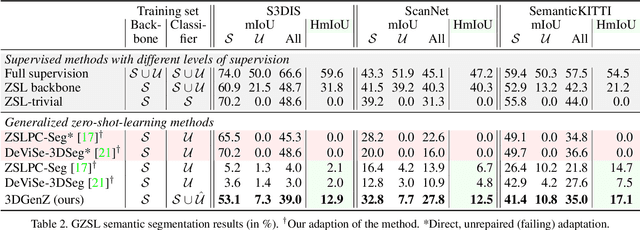
While there has been a number of studies on Zero-Shot Learning (ZSL) for 2D images, its application to 3D data is still recent and scarce, with just a few methods limited to classification. We present the first generative approach for both ZSL and Generalized ZSL (GZSL) on 3D data, that can handle both classification and, for the first time, semantic segmentation. We show that it reaches or outperforms the state of the art on ModelNet40 classification for both inductive ZSL and inductive GZSL. For semantic segmentation, we created three benchmarks for evaluating this new ZSL task, using S3DIS, ScanNet and SemanticKITTI. Our experiments show that our method outperforms strong baselines, which we additionally propose for this task.