 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Distributed Bayesian Learning of Dynamic States
Dec 05, 2022
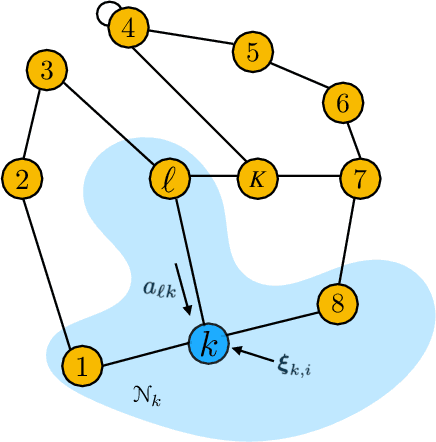
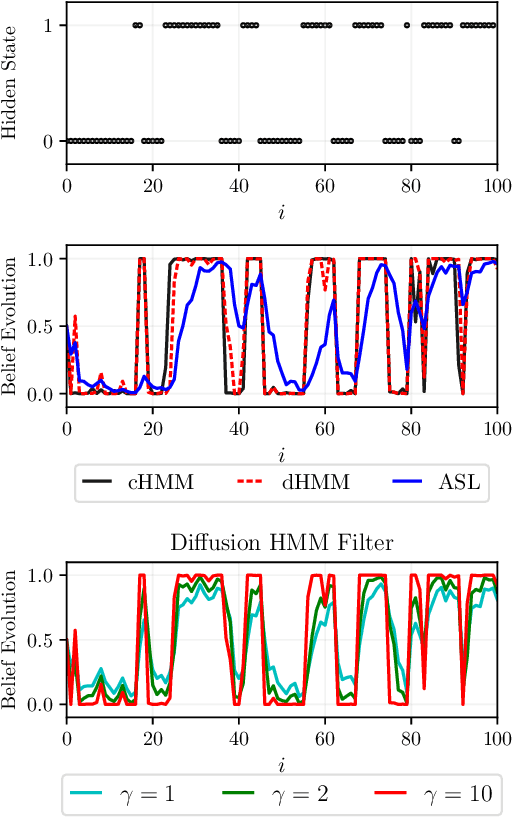
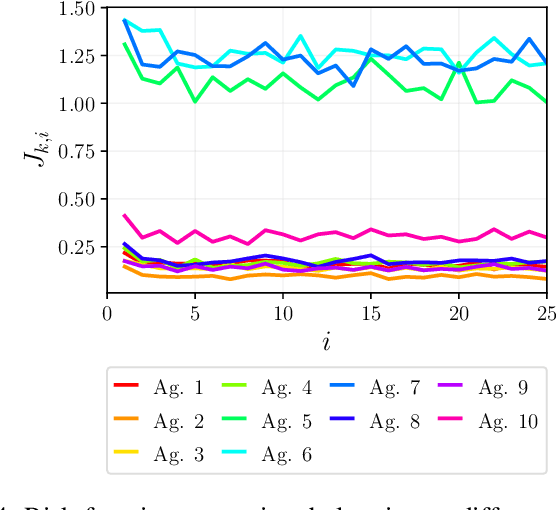
This work studies networked agents cooperating to track a dynamical state of nature under partial information. The proposed algorithm is a distributed Bayesian filtering algorithm for finite-state hidden Markov models (HMMs). It can be used for sequential state estimation tasks, as well as for modeling opinion formation over social networks under dynamic environments. We show that the disagreement with the optimal centralized solution is asymptotically bounded for the class of geometrically ergodic state transition models, which includes rapidly changing models. We also derive recursions for calculating the probability of error and establish convergence under Gaussian observation models. Simulations are provided to illustrate the theory and to compare against alternative approaches.
Finding Inverse Document Frequency Information in BERT
Feb 24, 2022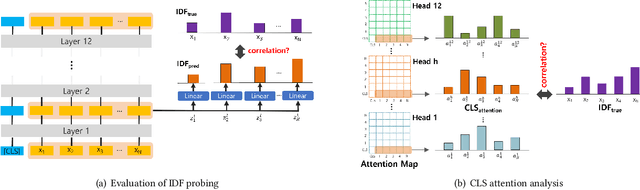

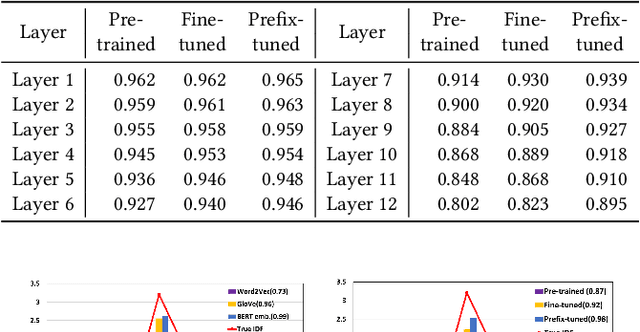
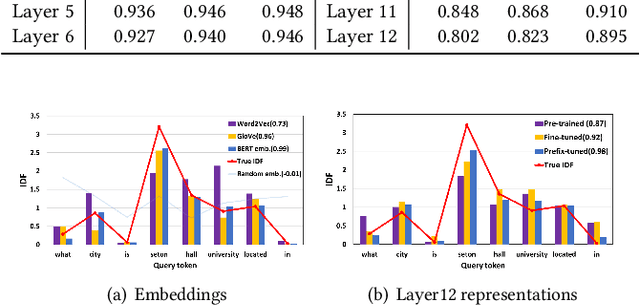
For many decades, BM25 and its variants have been the dominant document retrieval approach, where their two underlying features are Term Frequency (TF) and Inverse Document Frequency (IDF). The traditional approach, however, is being rapidly replaced by Neural Ranking Models (NRMs) that can exploit semantic features. In this work, we consider BERT-based NRMs and study if IDF information is present in the NRMs. This simple question is interesting because IDF has been indispensable for the traditional lexical matching, but global features like IDF are not explicitly learned by neural language models including BERT. We adopt linear probing as the main analysis tool because typical BERT based NRMs utilize linear or inner-product based score aggregators. We analyze input embeddings, representations of all BERT layers, and the self-attention weights of CLS. By studying MS-MARCO dataset with three BERT-based models, we show that all of them contain information that is strongly dependent on IDF.
C3SASR: Cheap Causal Convolutions for Self-Attentive Sequential Recommendation
Nov 10, 2022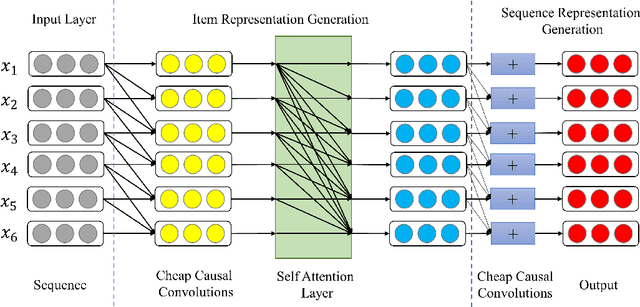
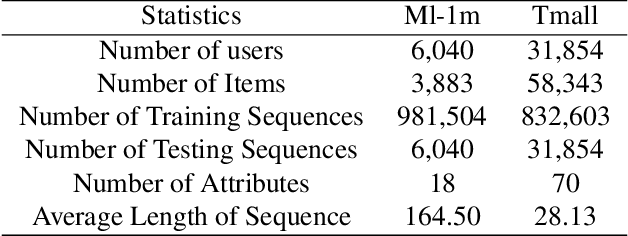

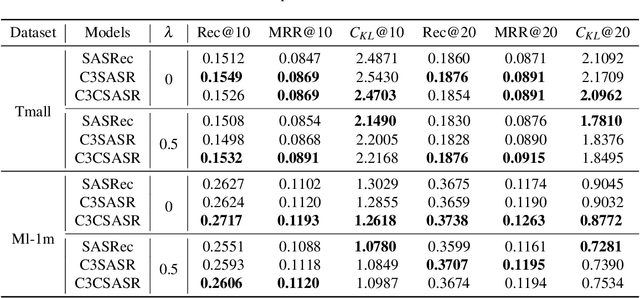
Sequential Recommendation is a prominent topic in current research, which uses user behavior sequence as an input to predict future behavior. By assessing the correlation strength of historical behavior through the dot product, the model based on the self-attention mechanism can capture the long-term preference of the sequence. However, it has two limitations. On the one hand, it does not effectively utilize the items' local context information when determining the attention and creating the sequence representation. On the other hand, the convolution and linear layers often contain redundant information, which limits the ability to encode sequences. In this paper, we propose a self-attentive sequential recommendation model based on cheap causal convolution. It utilizes causal convolutions to capture items' local information for calculating attention and generating sequence embedding. It also uses cheap convolutions to improve the representations by lightweight structure. We evaluate the effectiveness of the proposed model in terms of both accurate and calibrated sequential recommendation. Experiments on benchmark datasets show that the proposed model can perform better in single- and multi-objective recommendation scenarios.
MCFFA-Net: Multi-Contextual Feature Fusion and Attention Guided Network for Apple Foliar Disease Classification
Nov 25, 2022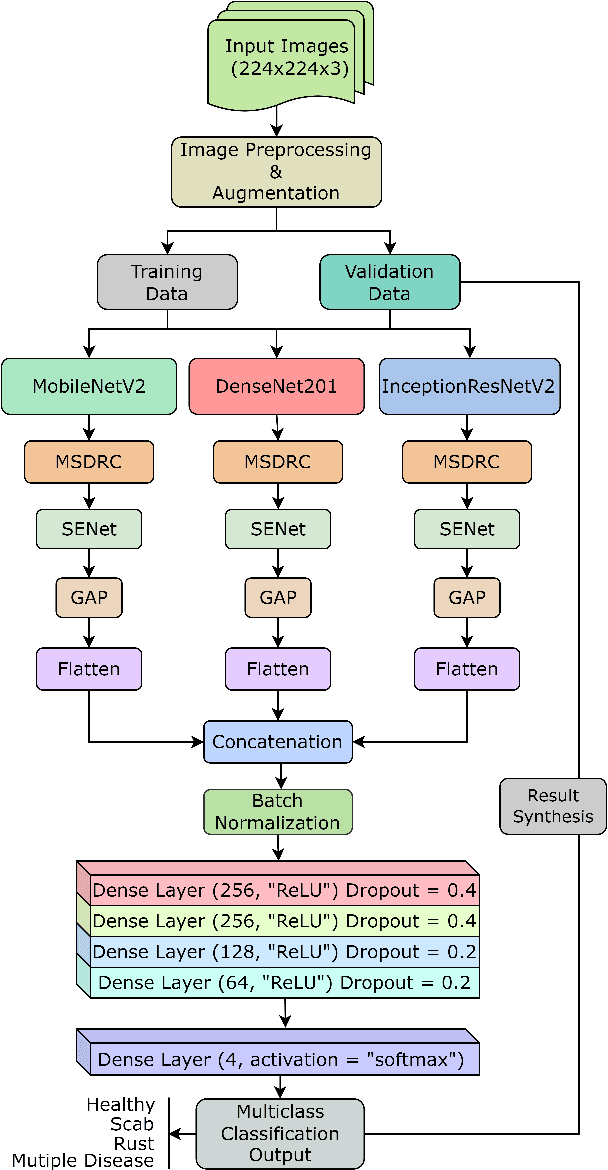
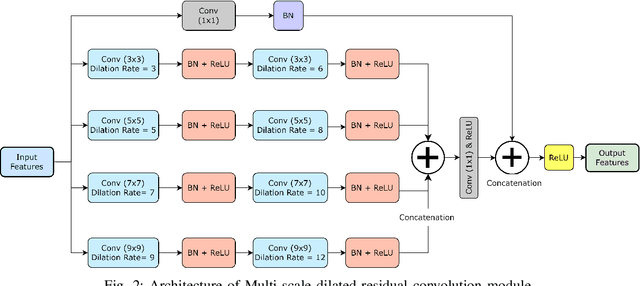
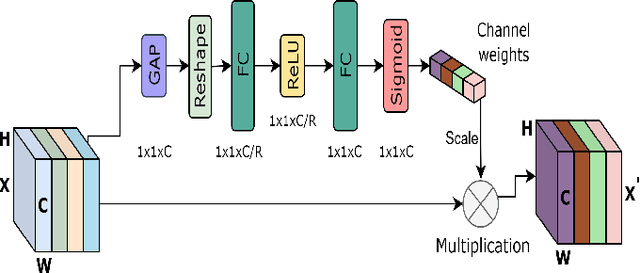
Numerous diseases cause severe economic loss in the apple production-based industry. Early disease identification in apple leaves can help to stop the spread of infections and provide better productivity. Therefore, it is crucial to study the identification and classification of different apple foliar diseases. Various traditional machine learning and deep learning methods have addressed and investigated this issue. However, it is still challenging to classify these diseases because of their complex background, variation in the diseased spot in the images, and the presence of several symptoms of multiple diseases on the same leaf. This paper proposes a novel transfer learning-based stacked ensemble architecture named MCFFA-Net, which is composed of three pre-trained architectures named MobileNetV2, DenseNet201, and InceptionResNetV2 as backbone networks. We also propose a novel multi-scale dilated residual convolution module to capture multi-scale contextual information with several dilated receptive fields from the extracted features. Channel-based attention mechanism is provided through squeeze and excitation networks to make the MCFFA-Net focused on the relevant information in the multi-receptive fields. The proposed MCFFA-Net achieves a classification accuracy of 90.86%.
Normal Transformer: Extracting Surface Geometry from LiDAR Points Enhanced by Visual Semantics
Nov 19, 2022

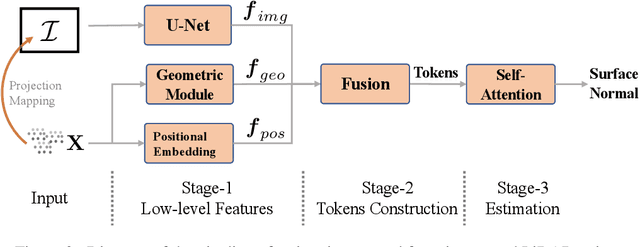
High-quality estimation of surface normal can help reduce ambiguity in many geometry understanding problems, such as collision avoidance and occlusion inference. This paper presents a technique for estimating the normal from 3D point clouds and 2D colour images. We have developed a transformer neural network that learns to utilise the hybrid information of visual semantic and 3D geometric data, as well as effective learning strategies. Compared to existing methods, the information fusion of the proposed method is more effective, which is supported by experiments. We have also built a simulation environment of outdoor traffic scenes in a 3D rendering engine to obtain annotated data to train the normal estimator. The model trained on synthetic data is tested on the real scenes in the KITTI dataset. And subsequent tasks built upon the estimated normal directions in the KITTI dataset show that the proposed estimator has advantage over existing methods.
Adjacent Slice Feature Guided 2.5D Network for Pulmonary Nodule Segmentation
Nov 19, 2022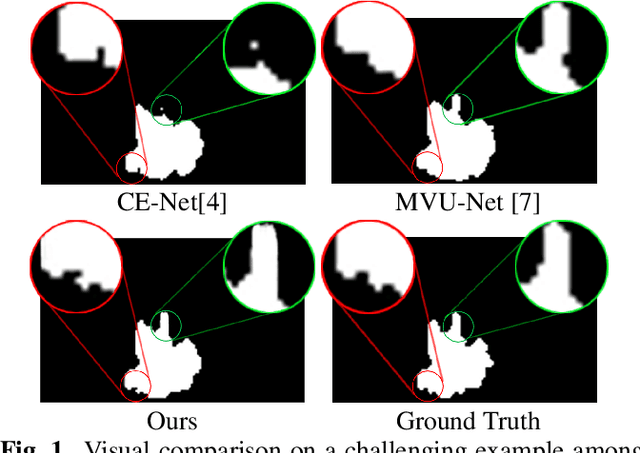
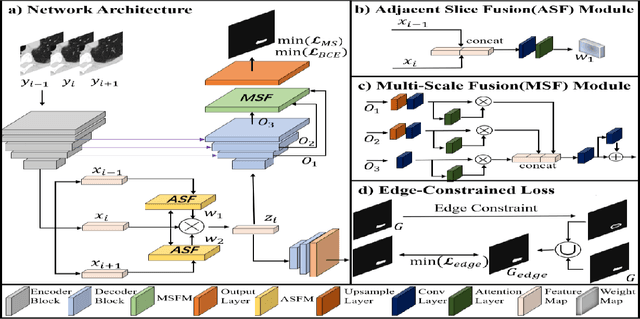
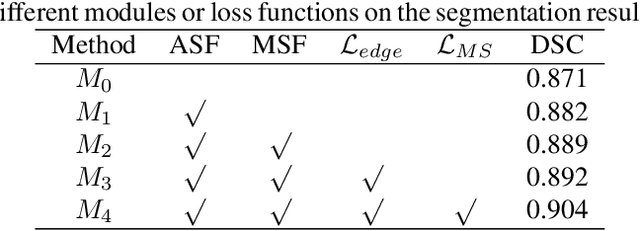

More and more attention has been paid to the segmentation of pulmonary nodules. Among the current methods based on deep learning, 3D segmentation methods directly input 3D images, which takes up a lot of memory and brings huge computation. However, most of the 2D segmentation methods with less parameters and calculation have the problem of lacking spatial relations between slices, resulting in poor segmentation performance. In order to solve these problems, we propose an adjacent slice feature guided 2.5D network. In this paper, we design an adjacent slice feature fusion model to introduce information from adjacent slices. To further improve the model performance, we construct a multi-scale fusion module to capture more context information, in addition, we design an edge-constrained loss function to optimize the segmentation results in the edge region. Fully experiments show that our method performs better than other existing methods in pulmonary nodule segmentation task.
DONEX: Real-time occupancy grid based dynamic echo classification for 3D point cloud
Dec 08, 2022
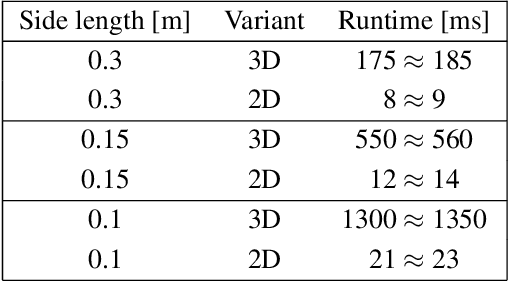
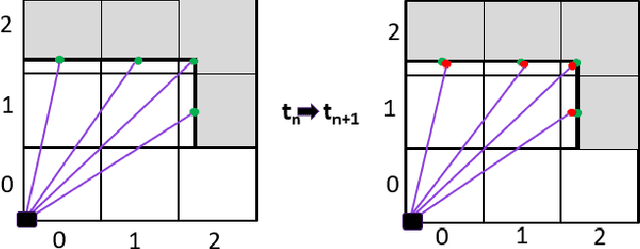
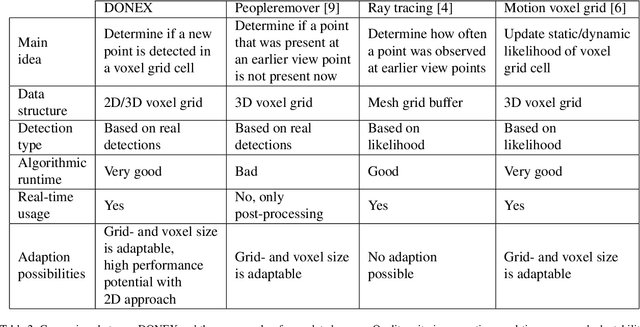
For driving assistance and autonomous driving systems, it is important to differentiate between dynamic objects such as moving vehicles and static objects such as guard rails. Among all the sensor modalities, RADAR and FMCW LiDAR can provide information regarding the motion state of the raw measurement data. On the other hand, perception pipelines using measurement data from ToF LiDAR typically can only differentiate between dynamic and static states on the object level. In this work, a new algorithm called DONEX was developed to classify the motion state of 3D LiDAR point cloud echoes using an occupancy grid approach. Through algorithmic improvements, e.g. 2D grid approach, it was possible to reduce the runtime. Scenarios, in which the measuring sensor is located in a moving vehicle, were also considered.
Low-Bitrate Redundancy Coding of Speech Using a Rate-Distortion-Optimized Variational Autoencoder
Dec 08, 2022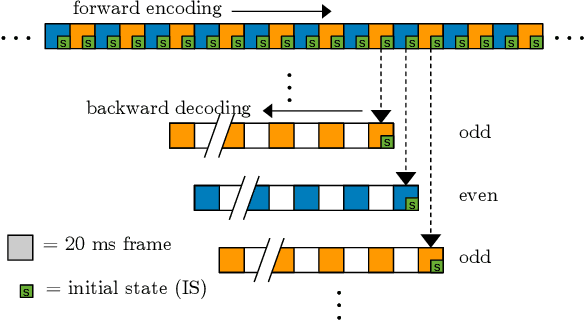
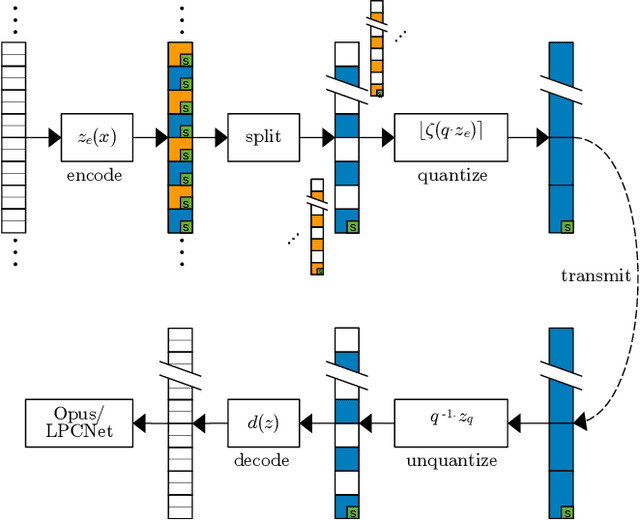
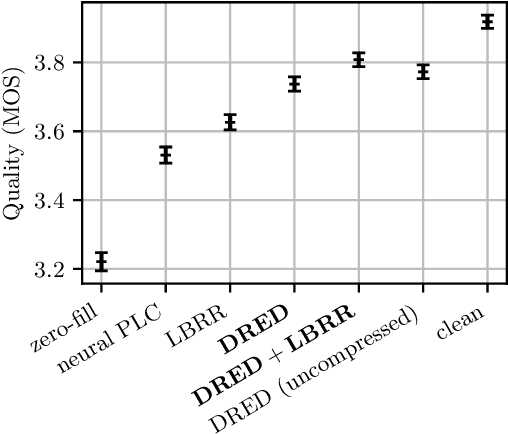
Robustness to packet loss is one of the main ongoing challenges in real-time speech communication. Deep packet loss concealment (PLC) techniques have recently demonstrated improved quality compared to traditional PLC. Despite that, all PLC techniques hit fundamental limitations when too much acoustic information is lost. To reduce losses in the first place, data is commonly sent multiple times using various redundancy mechanisms. We propose a neural speech coder specifically optimized to transmit a large amount of overlapping redundancy at a very low bitrate, up to 50x redundancy using less than 32~kb/s. Results show that the proposed redundancy is more effective than the existing Opus codec redundancy, and that the two can be combined for even greater robustness.
Fast-moving object counting with an event camera
Dec 16, 2022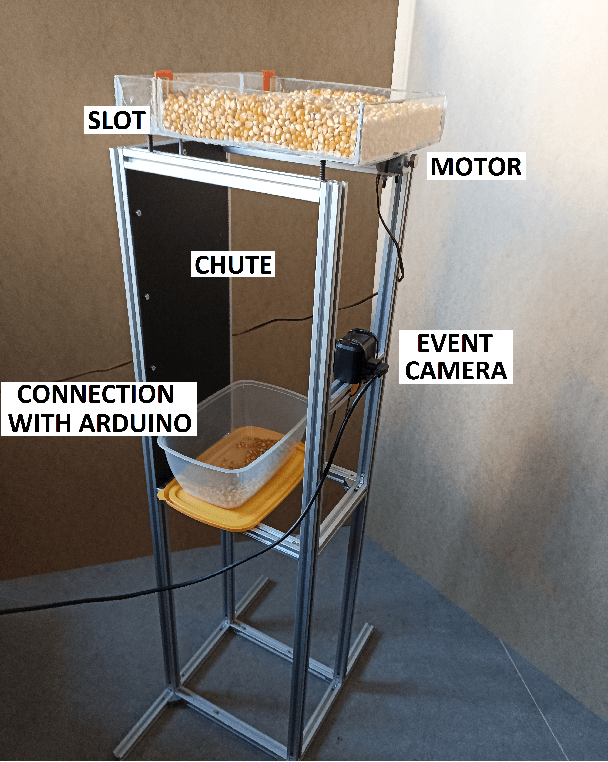

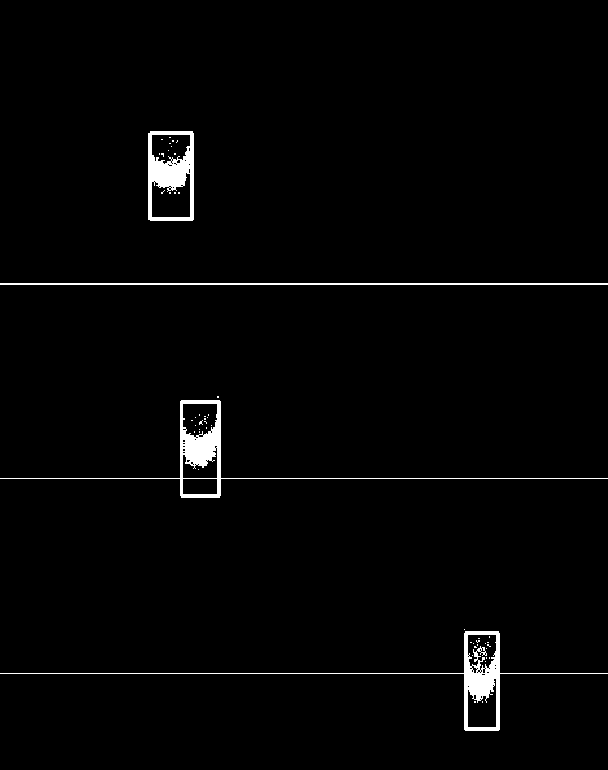

This paper proposes the use of an event camera as a component of a vision system that enables counting of fast-moving objects - in this case, falling corn grains. These type of cameras transmit information about the change in brightness of individual pixels and are characterised by low latency, no motion blur, correct operation in different lighting conditions, as well as very low power consumption. The proposed counting algorithm processes events in real time. The operation of the solution was demonstrated on a stand consisting of a chute with a vibrating feeder, which allowed the number of grains falling to be adjusted. The objective of the control system with a PID controller was to maintain a constant average number of falling objects. The proposed solution was subjected to a series of tests to determine the correctness of the developed method operation. On their basis, the validity of using an event camera to count small, fast-moving objects and the associated wide range of potential industrial applications can be confirmed.
An Upper Bound for the Distribution Overlap Index and Its Applications
Dec 16, 2022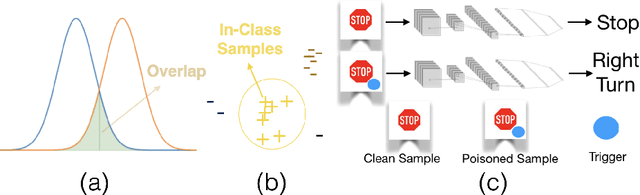
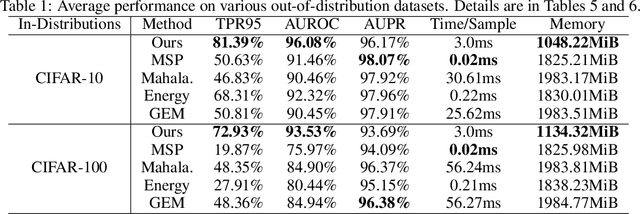
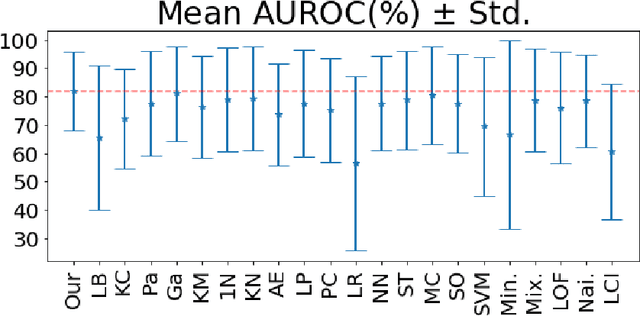

This paper proposes an easy-to-compute upper bound for the overlap index between two probability distributions without requiring any knowledge of the distribution models. The computation of our bound is time-efficient and memory-efficient and only requires finite samples. The proposed bound shows its value in one-class classification and domain shift analysis. Specifically, in one-class classification, we build a novel one-class classifier by converting the bound into a confidence score function. Unlike most one-class classifiers, the training process is not needed for our classifier. Additionally, the experimental results show that our classifier \textcolor{\colorname}{can be accurate with} only a small number of in-class samples and outperforms many state-of-the-art methods on various datasets in different one-class classification scenarios. In domain shift analysis, we propose a theorem based on our bound. The theorem is useful in detecting the existence of domain shift and inferring data information. The detection and inference processes are both computation-efficient and memory-efficient. Our work shows significant promise toward broadening the applications of overlap-based metrics.