 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Model Checking Strategic Abilities in Information-sharing Systems
Apr 19, 2022
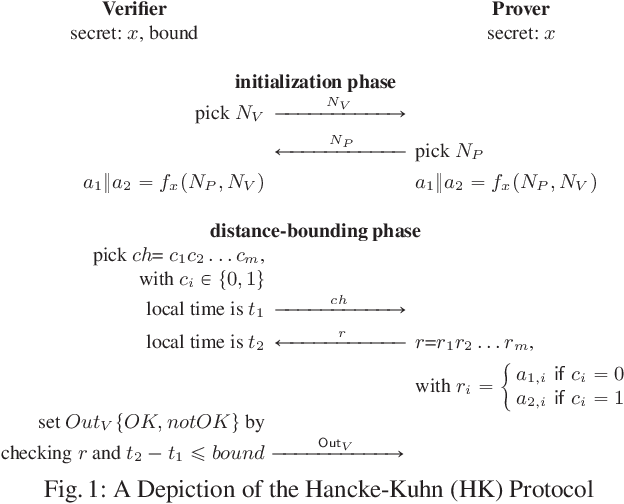
We introduce a subclass of concurrent game structures (CGS) with imperfect information in which agents are endowed with private data-sharing capabilities. Importantly, our CGSs are such that it is still decidable to model-check these CGSs against a relevant fragment of ATL. These systems can be thought as a generalisation of architectures allowing information forks, in the sense that, in the initial states of the system, we allow information forks from agents outside a given set A to agents inside this A. For this reason, together with the fact that the communication in our models underpins a specialised form of broadcast, we call our formalism A-cast systems. To underline, the fragment of ATL for which we show the model-checking problem to be decidable over A-cast is a large and significant one; it expresses coalitions over agents in any subset of the set A. Indeed, as we show, our systems and this ATL fragments can encode security problems that are notoriously hard to express faithfully: terrorist-fraud attacks in identity schemes.
Variational Bayesian inference for CP tensor completion with side information
Jun 29, 2022
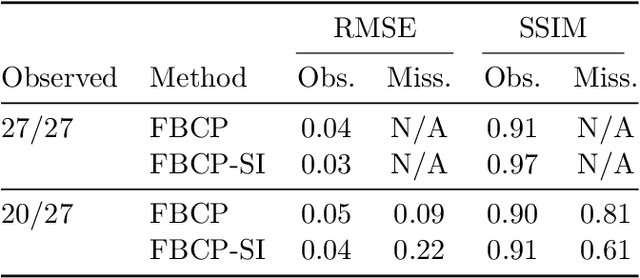
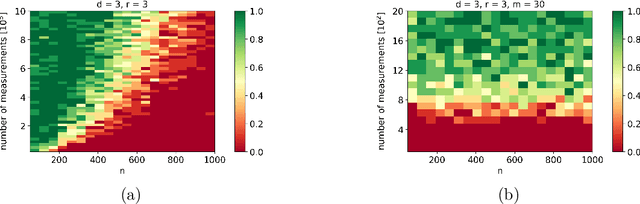
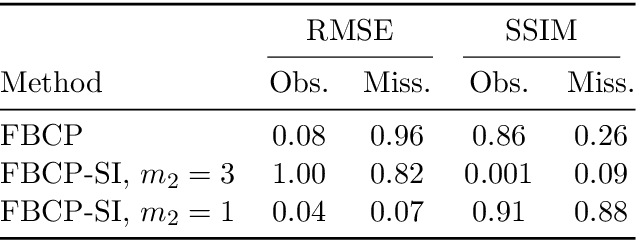
We propose a message passing algorithm, based on variational Bayesian inference, for low-rank tensor completion with automatic rank determination in the canonical polyadic format when additional side information (SI) is given. The SI comes in the form of low-dimensional subspaces the contain the fiber spans of the tensor (columns, rows, tubes, etc.). We validate the regularization properties induced by SI with extensive numerical experiments on synthetic and real-world data and present the results about tensor recovery and rank determination. The results show that the number of samples required for successful completion is significantly reduced in the presence of SI. We also discuss the origin of a bump in the phase transition curves that exists when the dimensionality of SI is comparable with that of the tensor.
Deep Spectral Q-learning with Application to Mobile Health
Jan 03, 2023

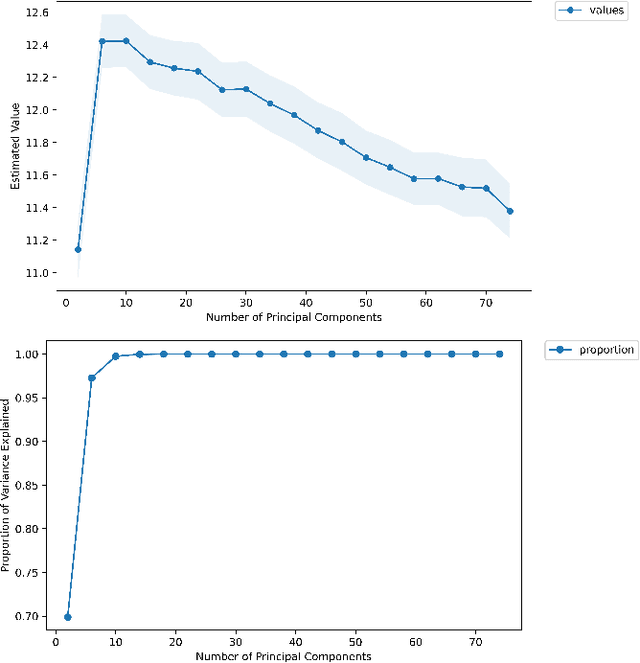
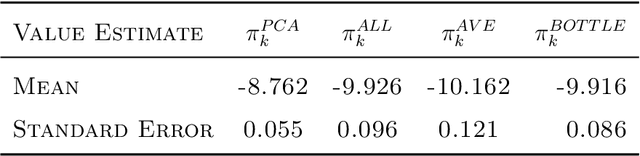
Dynamic treatment regimes assign personalized treatments to patients sequentially over time based on their baseline information and time-varying covariates. In mobile health applications, these covariates are typically collected at different frequencies over a long time horizon. In this paper, we propose a deep spectral Q-learning algorithm, which integrates principal component analysis (PCA) with deep Q-learning to handle the mixed frequency data. In theory, we prove that the mean return under the estimated optimal policy converges to that under the optimal one and establish its rate of convergence. The usefulness of our proposal is further illustrated via simulations and an application to a diabetes dataset.
Adversarially Robust Video Perception by Seeing Motion
Dec 13, 2022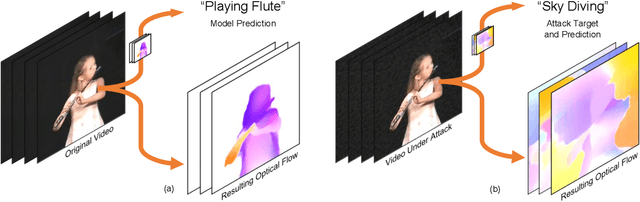
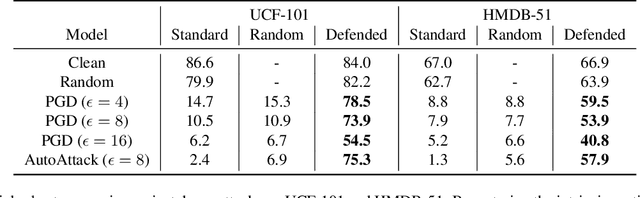
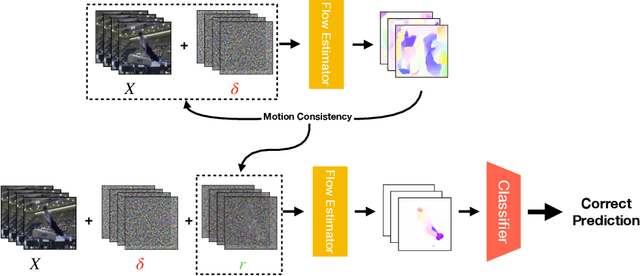
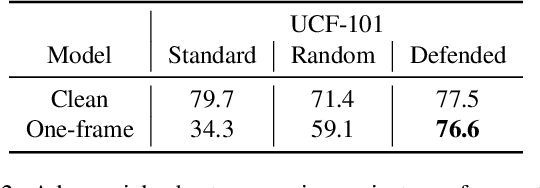
Despite their excellent performance, state-of-the-art computer vision models often fail when they encounter adversarial examples. Video perception models tend to be more fragile under attacks, because the adversary has more places to manipulate in high-dimensional data. In this paper, we find one reason for video models' vulnerability is that they fail to perceive the correct motion under adversarial perturbations. Inspired by the extensive evidence that motion is a key factor for the human visual system, we propose to correct what the model sees by restoring the perceived motion information. Since motion information is an intrinsic structure of the video data, recovering motion signals can be done at inference time without any human annotation, which allows the model to adapt to unforeseen, worst-case inputs. Visualizations and empirical experiments on UCF-101 and HMDB-51 datasets show that restoring motion information in deep vision models improves adversarial robustness. Even under adaptive attacks where the adversary knows our defense, our algorithm is still effective. Our work provides new insight into robust video perception algorithms by using intrinsic structures from the data. Our webpage is available at https://motion4robust.cs.columbia.edu.
Coarse-to-Fine Contrastive Learning on Graphs
Dec 13, 2022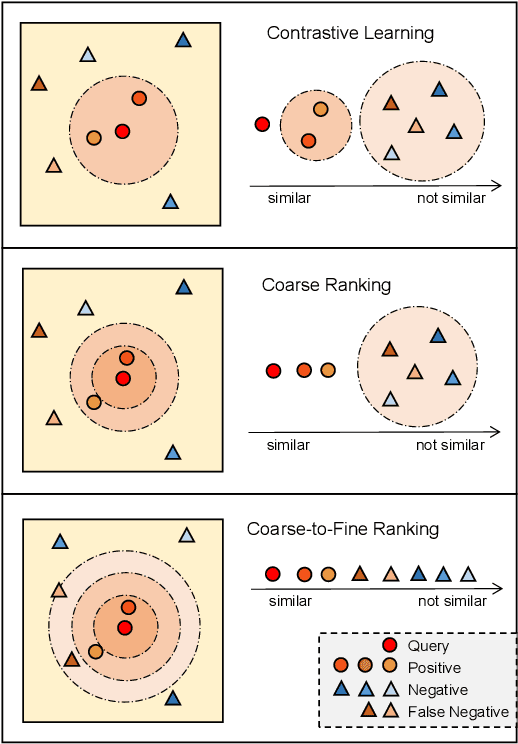

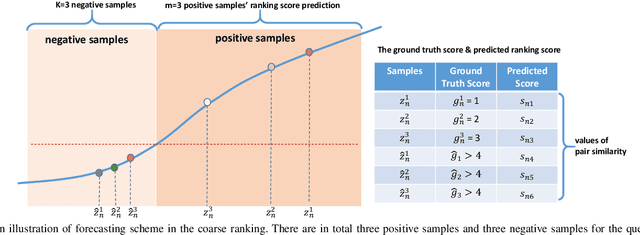
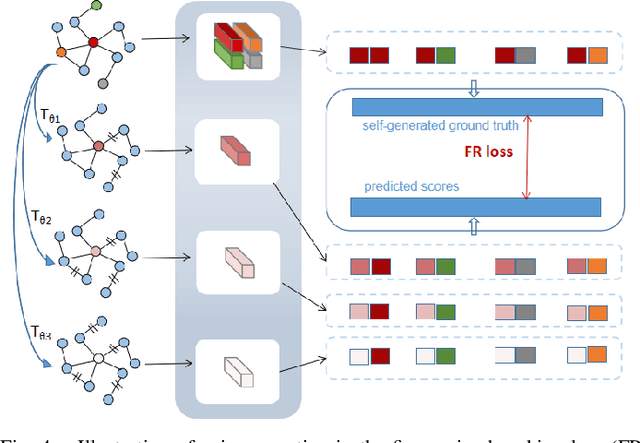
Inspired by the impressive success of contrastive learning (CL), a variety of graph augmentation strategies have been employed to learn node representations in a self-supervised manner. Existing methods construct the contrastive samples by adding perturbations to the graph structure or node attributes. Although impressive results are achieved, it is rather blind to the wealth of prior information assumed: with the increase of the perturbation degree applied on the original graph, 1) the similarity between the original graph and the generated augmented graph gradually decreases; 2) the discrimination between all nodes within each augmented view gradually increases. In this paper, we argue that both such prior information can be incorporated (differently) into the contrastive learning paradigm following our general ranking framework. In particular, we first interpret CL as a special case of learning to rank (L2R), which inspires us to leverage the ranking order among positive augmented views. Meanwhile, we introduce a self-ranking paradigm to ensure that the discriminative information among different nodes can be maintained and also be less altered to the perturbations of different degrees. Experiment results on various benchmark datasets verify the effectiveness of our algorithm compared with the supervised and unsupervised models.
Tacchi: A Pluggable and Low Computational Cost Elastomer Deformation Simulator for Optical Tactile Sensors
Jan 19, 2023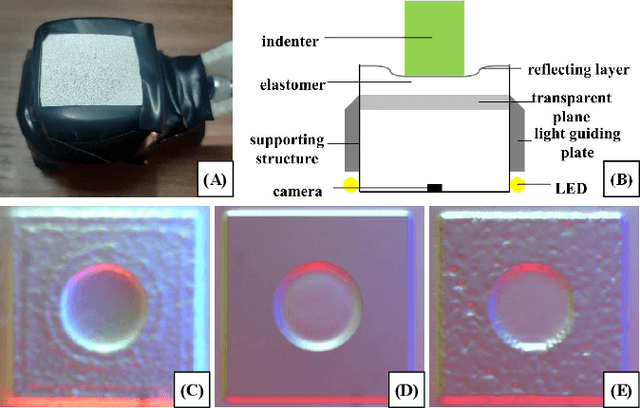
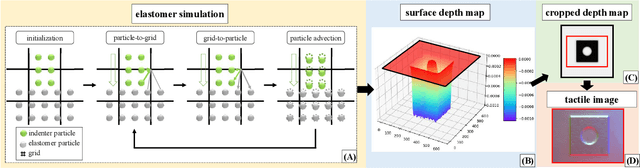
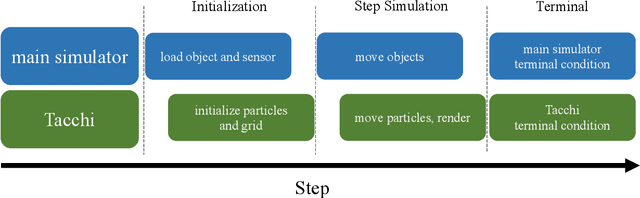

Simulation is widely applied in robotics research to save time and resources. There have been several works to simulate optical tactile sensors that leverage either a smoothing method or Finite Element Method (FEM). However, elastomer deformation physics is not considered in the former method, whereas the latter requires a massive amount of computational resources like a computer cluster. In this work, we propose a pluggable and low computational cost simulator using the Taichi programming language for simulating optical tactile sensors, named as Tacchi . It reconstructs elastomer deformation using particles, which allows deformed elastomer surfaces to be rendered into tactile images and reveals contact information without suffering from high computational costs. Tacchi facilitates creating realistic tactile images in simulation, e.g., ones that capture wear-and-tear defects on object surfaces. In addition, the proposed Tacchi can be integrated with robotics simulators for a robot system simulation. Experiment results showed that Tacchi can produce images with better similarity to real images and achieved higher Sim2Real accuracy compared to the existing methods. Moreover, it can be connected with MuJoCo and Gazebo with only the requirement of 1G memory space in GPU compared to a computer cluster applied for FEM. With Tacchi, physical robot simulation with optical tactile sensors becomes possible. All the materials in this paper are available at https://github.com/zixichen007115/Tacchi .
LoCoNet: Long-Short Context Network for Active Speaker Detection
Jan 19, 2023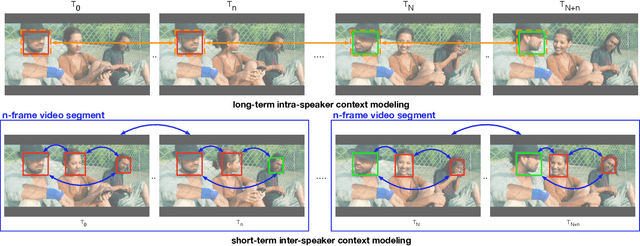
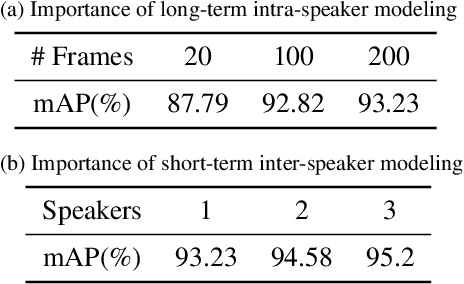
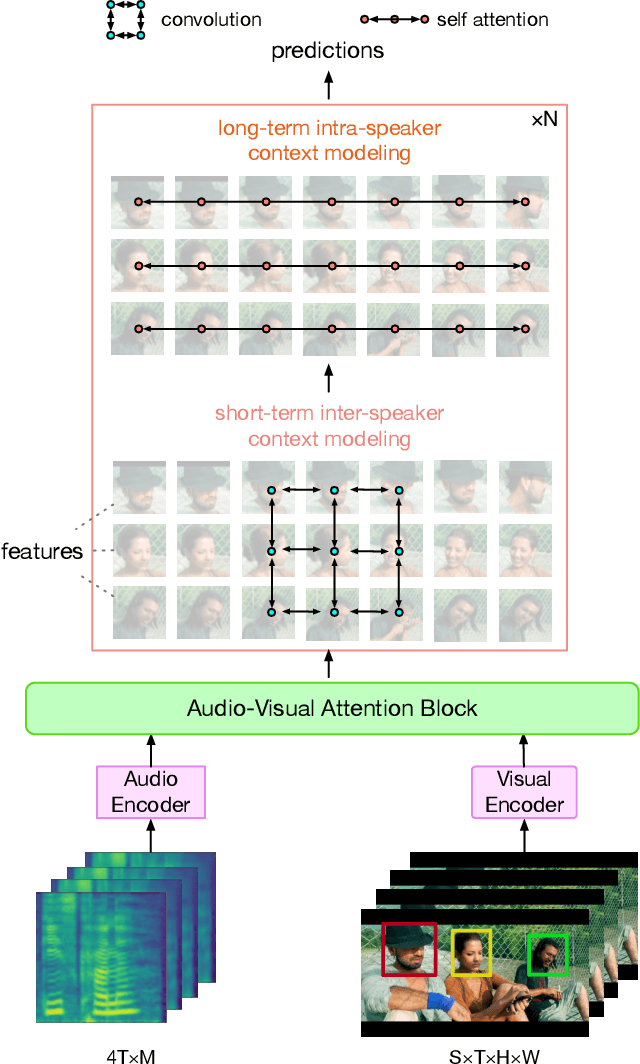

Active Speaker Detection (ASD) aims to identify who is speaking in each frame of a video. ASD reasons from audio and visual information from two contexts: long-term intra-speaker context and short-term inter-speaker context. Long-term intra-speaker context models the temporal dependencies of the same speaker, while short-term inter-speaker context models the interactions of speakers in the same scene. These two contexts are complementary to each other and can help infer the active speaker. Motivated by these observations, we propose LoCoNet, a simple yet effective Long-Short Context Network that models the long-term intra-speaker context and short-term inter-speaker context. We use self-attention to model long-term intra-speaker context due to its effectiveness in modeling long-range dependencies, and convolutional blocks that capture local patterns to model short-term inter-speaker context. Extensive experiments show that LoCoNet achieves state-of-the-art performance on multiple datasets, achieving an mAP of 95.2%(+1.1%) on AVA-ActiveSpeaker, 68.1%(+22%) on Columbia dataset, 97.2%(+2.8%) on Talkies dataset and 59.7%(+8.0%) on Ego4D dataset. Moreover, in challenging cases where multiple speakers are present, or face of active speaker is much smaller than other faces in the same scene, LoCoNet outperforms previous state-of-the-art methods by 3.4% on the AVA-ActiveSpeaker dataset. The code will be released at https://github.com/SJTUwxz/LoCoNet_ASD.
Quantitative phase imaging (QPI) through random diffusers using a diffractive optical network
Jan 19, 2023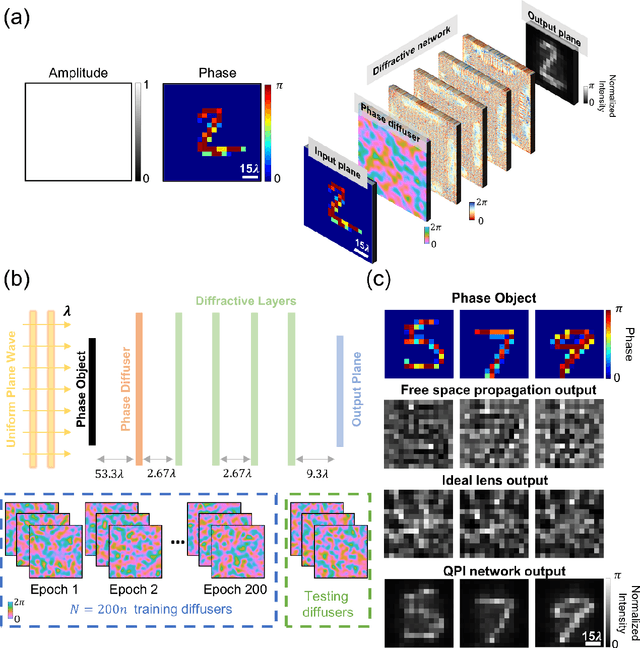
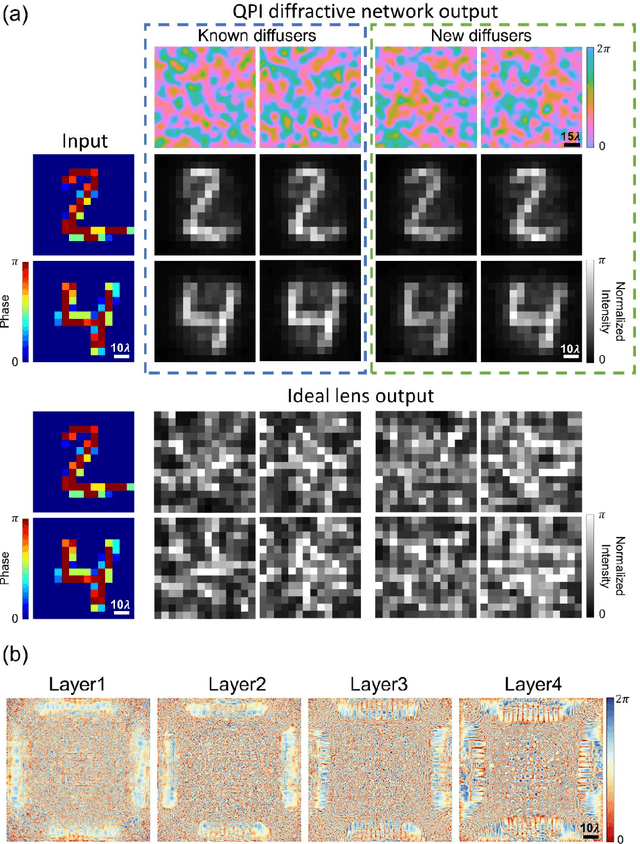
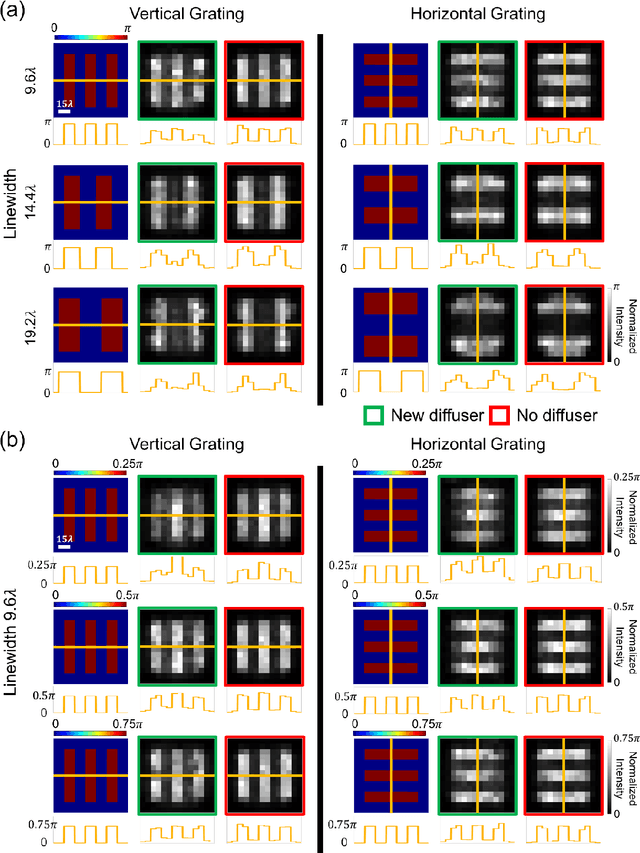

Quantitative phase imaging (QPI) is a label-free computational imaging technique used in various fields, including biology and medical research. Modern QPI systems typically rely on digital processing using iterative algorithms for phase retrieval and image reconstruction. Here, we report a diffractive optical network trained to convert the phase information of input objects positioned behind random diffusers into intensity variations at the output plane, all-optically performing phase recovery and quantitative imaging of phase objects completely hidden by unknown, random phase diffusers. This QPI diffractive network is composed of successive diffractive layers, axially spanning in total ~70 wavelengths; unlike existing digital image reconstruction and phase retrieval methods, it forms an all-optical processor that does not require external power beyond the illumination beam to complete its QPI reconstruction at the speed of light propagation. This all-optical diffractive processor can provide a low-power, high frame rate and compact alternative for quantitative imaging of phase objects through random, unknown diffusers and can operate at different parts of the electromagnetic spectrum for various applications in biomedical imaging and sensing. The presented QPI diffractive designs can be integrated onto the active area of standard CCD/CMOS-based image sensors to convert an existing optical microscope into a diffractive QPI microscope, performing phase recovery and image reconstruction on a chip through light diffraction within passive structured layers.
Revisiting the Spatial and Temporal Modeling for Few-shot Action Recognition
Jan 19, 2023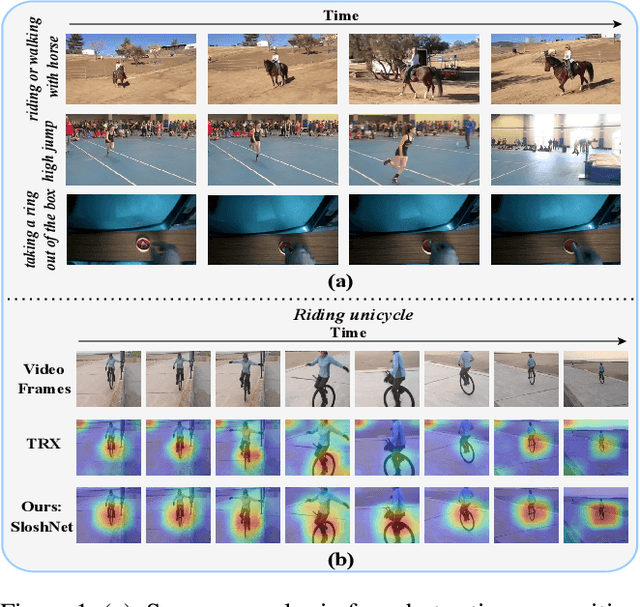
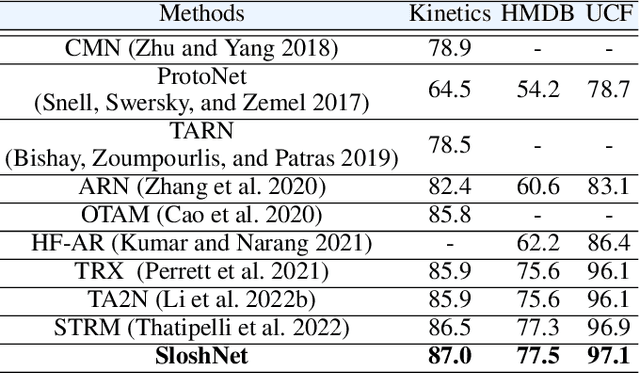
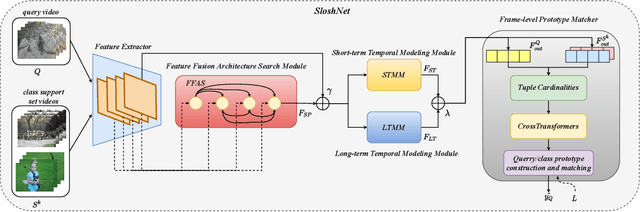
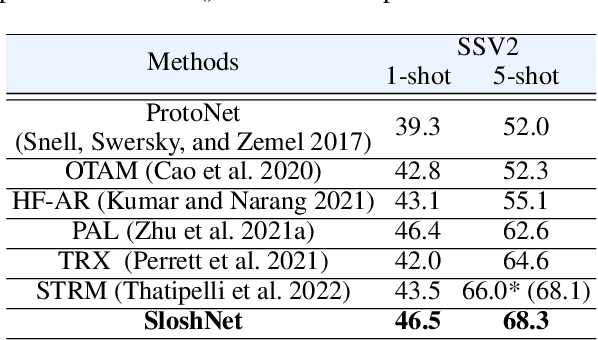
Spatial and temporal modeling is one of the most core aspects of few-shot action recognition. Most previous works mainly focus on long-term temporal relation modeling based on high-level spatial representations, without considering the crucial low-level spatial features and short-term temporal relations. Actually, the former feature could bring rich local semantic information, and the latter feature could represent motion characteristics of adjacent frames, respectively. In this paper, we propose SloshNet, a new framework that revisits the spatial and temporal modeling for few-shot action recognition in a finer manner. First, to exploit the low-level spatial features, we design a feature fusion architecture search module to automatically search for the best combination of the low-level and high-level spatial features. Next, inspired by the recent transformer, we introduce a long-term temporal modeling module to model the global temporal relations based on the extracted spatial appearance features. Meanwhile, we design another short-term temporal modeling module to encode the motion characteristics between adjacent frame representations. After that, the final predictions can be obtained by feeding the embedded rich spatial-temporal features to a common frame-level class prototype matcher. We extensively validate the proposed SloshNet on four few-shot action recognition datasets, including Something-Something V2, Kinetics, UCF101, and HMDB51. It achieves favorable results against state-of-the-art methods in all datasets.
Towards Microstructural State Variables in Materials Systems
Jan 11, 2023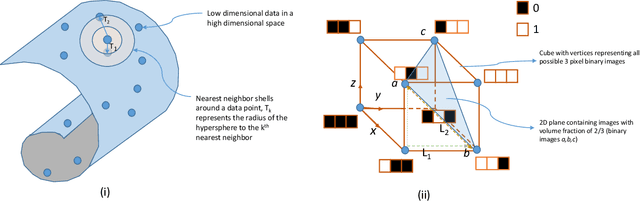
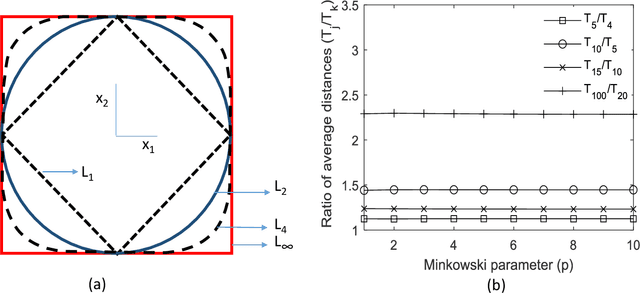
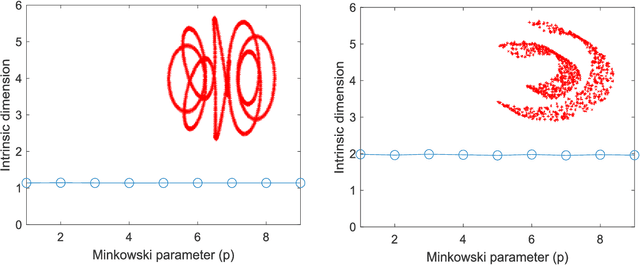
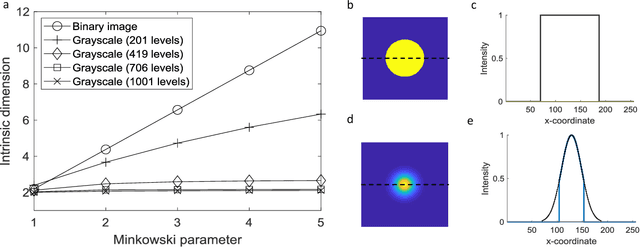
The vast combination of material properties seen in nature are achieved by the complexity of the material microstructure. Advanced characterization and physics based simulation techniques have led to generation of extremely large microstructural datasets. There is a need for machine learning techniques that can manage data complexity by capturing the maximal amount of information about the microstructure using the least number of variables. This paper aims to formulate dimensionality and state variable estimation techniques focused on reducing microstructural image data. It is shown that local dimensionality estimation based on nearest neighbors tend to give consistent dimension estimates for natural images for all p-Minkowski distances. However, it is found that dimensionality estimates have a systematic error for low-bit depth microstructural images. The use of Manhattan distance to alleviate this issue is demonstrated. It is also shown that stacked autoencoders can reconstruct the generator space of high dimensional microstructural data and provide a sparse set of state variables to fully describe the variability in material microstructures.