 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
RoDUS: Robust Decomposition of Static and Dynamic Elements in Urban Scenes
Mar 14, 2024
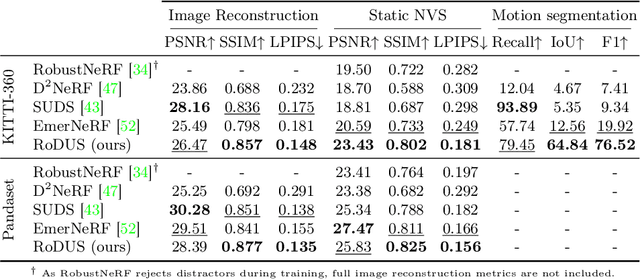
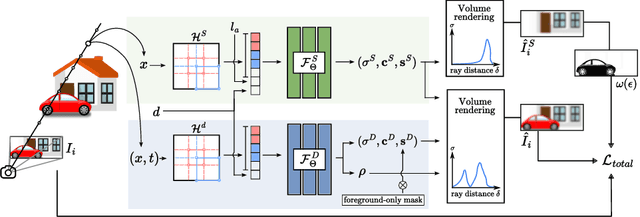
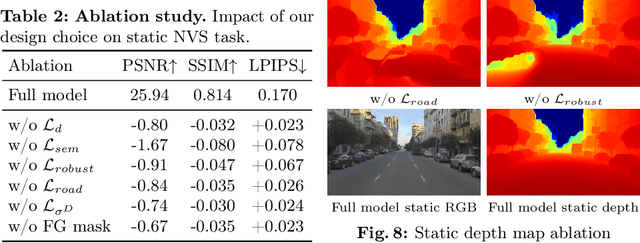
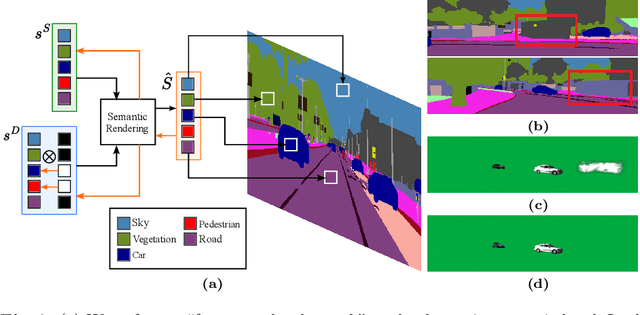
The task of separating dynamic objects from static environments using NeRFs has been widely studied in recent years. However, capturing large-scale scenes still poses a challenge due to their complex geometric structures and unconstrained dynamics. Without the help of 3D motion cues, previous methods often require simplified setups with slow camera motion and only a few/single dynamic actors, leading to suboptimal solutions in most urban setups. To overcome such limitations, we present RoDUS, a pipeline for decomposing static and dynamic elements in urban scenes, with thoughtfully separated NeRF models for moving and non-moving components. Our approach utilizes a robust kernel-based initialization coupled with 4D semantic information to selectively guide the learning process. This strategy enables accurate capturing of the dynamics in the scene, resulting in reduced artifacts caused by NeRF on background reconstruction, all by using self-supervision. Notably, experimental evaluations on KITTI-360 and Pandaset datasets demonstrate the effectiveness of our method in decomposing challenging urban scenes into precise static and dynamic components.
Geographically-Informed Language Identification
Mar 14, 2024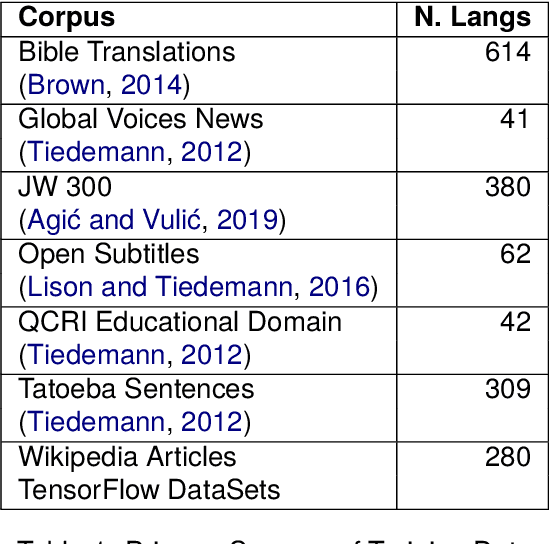
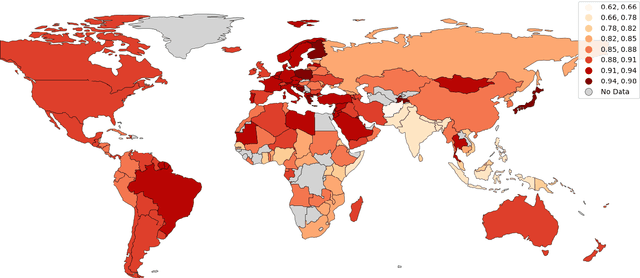
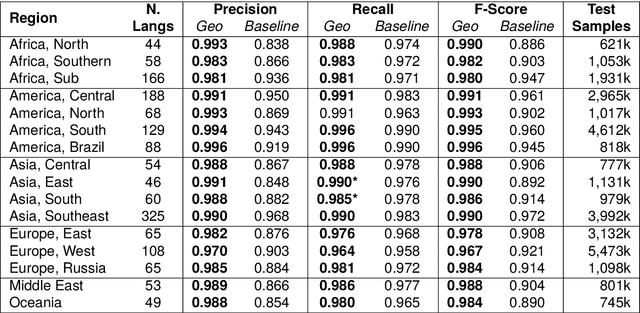
This paper develops an approach to language identification in which the set of languages considered by the model depends on the geographic origin of the text in question. Given that many digital corpora can be geo-referenced at the country level, this paper formulates 16 region-specific models, each of which contains the languages expected to appear in countries within that region. These regional models also each include 31 widely-spoken international languages in order to ensure coverage of these linguae francae regardless of location. An upstream evaluation using traditional language identification testing data shows an improvement in f-score ranging from 1.7 points (Southeast Asia) to as much as 10.4 points (North Africa). A downstream evaluation on social media data shows that this improved performance has a significant impact on the language labels which are applied to large real-world corpora. The result is a highly-accurate model that covers 916 languages at a sample size of 50 characters, the performance improved by incorporating geographic information into the model.
Minimax Optimal and Computationally Efficient Algorithms for Distributionally Robust Offline Reinforcement Learning
Mar 14, 2024
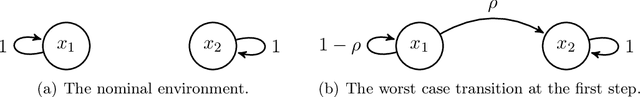
Distributionally robust offline reinforcement learning (RL), which seeks robust policy training against environment perturbation by modeling dynamics uncertainty, calls for function approximations when facing large state-action spaces. However, the consideration of dynamics uncertainty introduces essential nonlinearity and computational burden, posing unique challenges for analyzing and practically employing function approximation. Focusing on a basic setting where the nominal model and perturbed models are linearly parameterized, we propose minimax optimal and computationally efficient algorithms realizing function approximation and initiate the study on instance-dependent suboptimality analysis in the context of robust offline RL. Our results uncover that function approximation in robust offline RL is essentially distinct from and probably harder than that in standard offline RL. Our algorithms and theoretical results crucially depend on a variety of new techniques, involving a novel function approximation mechanism incorporating variance information, a new procedure of suboptimality and estimation uncertainty decomposition, a quantification of the robust value function shrinkage, and a meticulously designed family of hard instances, which might be of independent interest.
Don't Judge by the Look: A Motion Coherent Augmentation for Video Recognition
Mar 14, 2024

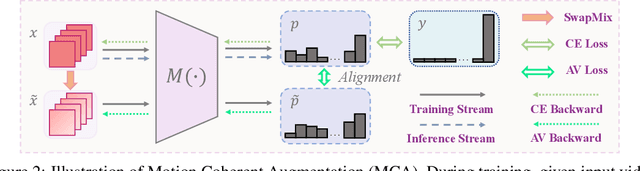

Current training pipelines in object recognition neglect Hue Jittering when doing data augmentation as it not only brings appearance changes that are detrimental to classification, but also the implementation is inefficient in practice. In this study, we investigate the effect of hue variance in the context of video recognition and find this variance to be beneficial since static appearances are less important in videos that contain motion information. Based on this observation, we propose a data augmentation method for video recognition, named Motion Coherent Augmentation (MCA), that introduces appearance variation in videos and implicitly encourages the model to prioritize motion patterns, rather than static appearances. Concretely, we propose an operation SwapMix to efficiently modify the appearance of video samples, and introduce Variation Alignment (VA) to resolve the distribution shift caused by SwapMix, enforcing the model to learn appearance invariant representations. Comprehensive empirical evaluation across various architectures and different datasets solidly validates the effectiveness and generalization ability of MCA, and the application of VA in other augmentation methods. Code is available at https://github.com/BeSpontaneous/MCA-pytorch.
V-PRISM: Probabilistic Mapping of Unknown Tabletop Scenes
Mar 14, 2024

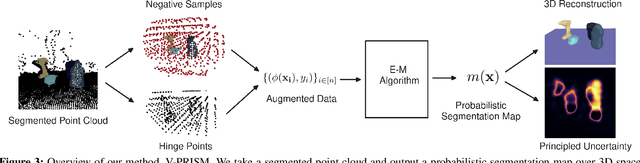
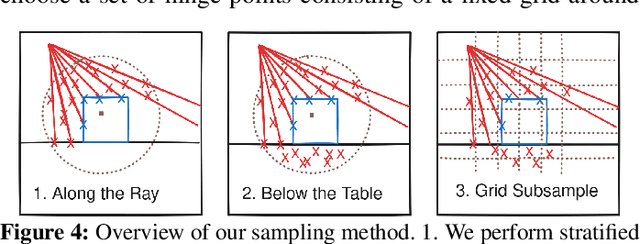
The ability to construct concise scene representations from sensor input is central to the field of robotics. This paper addresses the problem of robustly creating a 3D representation of a tabletop scene from a segmented RGB-D image. These representations are then critical for a range of downstream manipulation tasks. Many previous attempts to tackle this problem do not capture accurate uncertainty, which is required to subsequently produce safe motion plans. In this paper, we cast the representation of 3D tabletop scenes as a multi-class classification problem. To tackle this, we introduce V-PRISM, a framework and method for robustly creating probabilistic 3D segmentation maps of tabletop scenes. Our maps contain both occupancy estimates, segmentation information, and principled uncertainty measures. We evaluate the robustness of our method in (1) procedurally generated scenes using open-source object datasets, and (2) real-world tabletop data collected from a depth camera. Our experiments show that our approach outperforms alternative continuous reconstruction approaches that do not explicitly reason about objects in a multi-class formulation.
WeakSurg: Weakly supervised surgical instrument segmentation using temporal equivariance and semantic continuity
Mar 14, 2024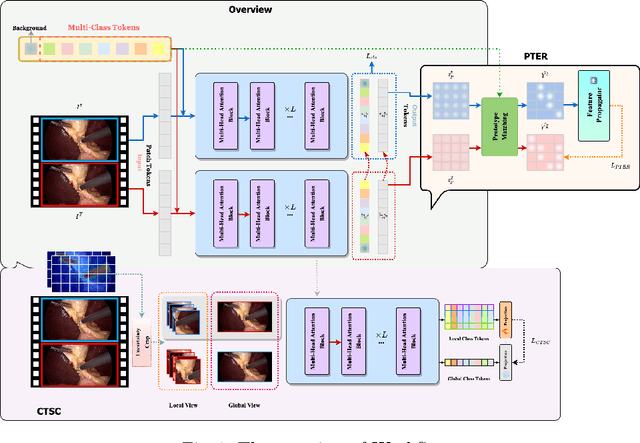
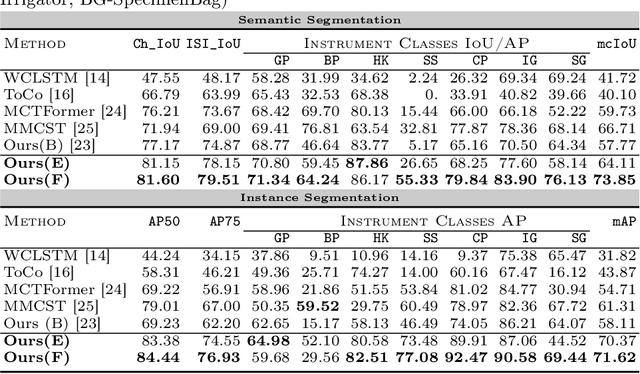
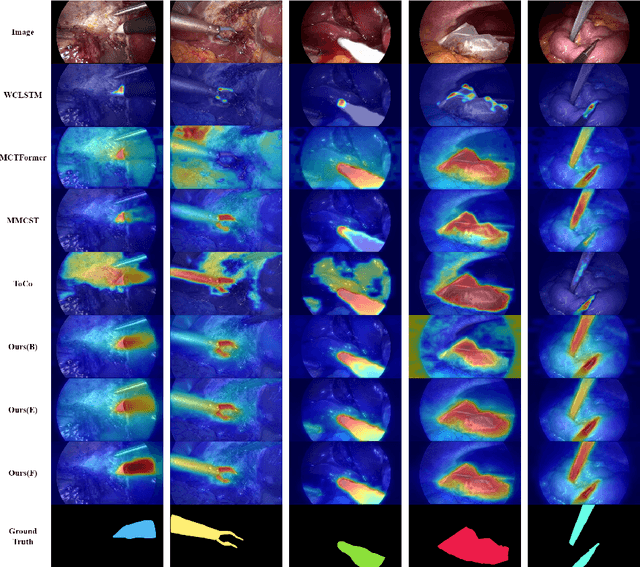
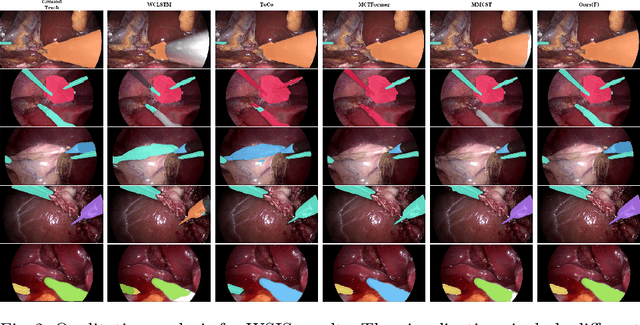
Weakly supervised surgical instrument segmentation with only instrument presence labels has been rarely explored in surgical domain. To mitigate the highly under-constrained challenges, we extend a two-stage weakly supervised segmentation paradigm with temporal attributes from two perspectives. From a temporal equivariance perspective, we propose a prototype-based temporal equivariance regulation loss to enhance pixel-wise consistency between adjacent features. From a semantic continuity perspective, we propose a class-aware temporal semantic continuity loss to constrain the semantic consistency between a global view of target frame and local non-discriminative regions of adjacent reference frame. To the best of our knowledge, WeakSurg is the first instrument-presence-only weakly supervised segmentation architecture to take temporal information into account for surgical scenarios. Extensive experiments are validated on Cholec80, an open benchmark for phase and instrument recognition. We annotate instance-wise instrument labels with fixed time-steps which are double checked by a clinician with 3-years experience. Our results show that WeakSurg compares favorably with state-of-the-art methods not only on semantic segmentation metrics but also on instance segmentation metrics.
Red Teaming Models for Hyperspectral Image Analysis Using Explainable AI
Mar 14, 2024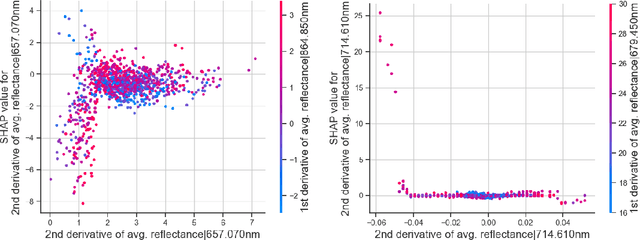
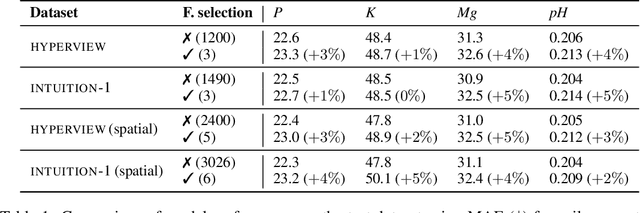
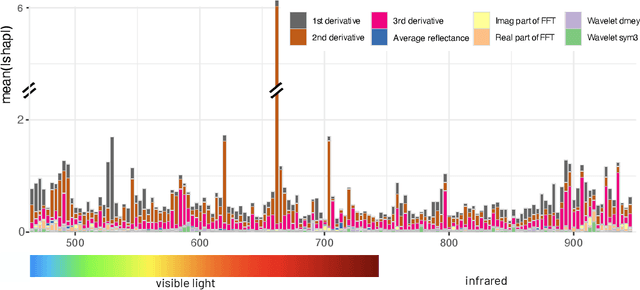
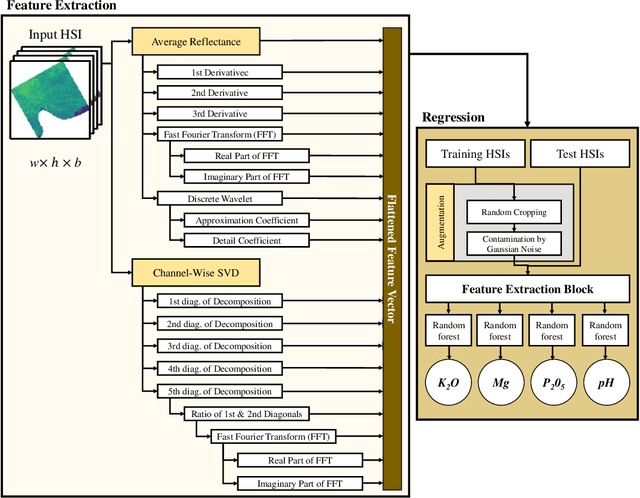
Remote sensing (RS) applications in the space domain demand machine learning (ML) models that are reliable, robust, and quality-assured, making red teaming a vital approach for identifying and exposing potential flaws and biases. Since both fields advance independently, there is a notable gap in integrating red teaming strategies into RS. This paper introduces a methodology for examining ML models operating on hyperspectral images within the HYPERVIEW challenge, focusing on soil parameters' estimation. We use post-hoc explanation methods from the Explainable AI (XAI) domain to critically assess the best performing model that won the HYPERVIEW challenge and served as an inspiration for the model deployed on board the INTUITION-1 hyperspectral mission. Our approach effectively red teams the model by pinpointing and validating key shortcomings, constructing a model that achieves comparable performance using just 1% of the input features and a mere up to 5% performance loss. Additionally, we propose a novel way of visualizing explanations that integrate domain-specific information about hyperspectral bands (wavelengths) and data transformations to better suit interpreting models for hyperspectral image analysis.
How Suboptimal is Training rPPG Models with Videos and Targets from Different Body Sites?
Mar 15, 2024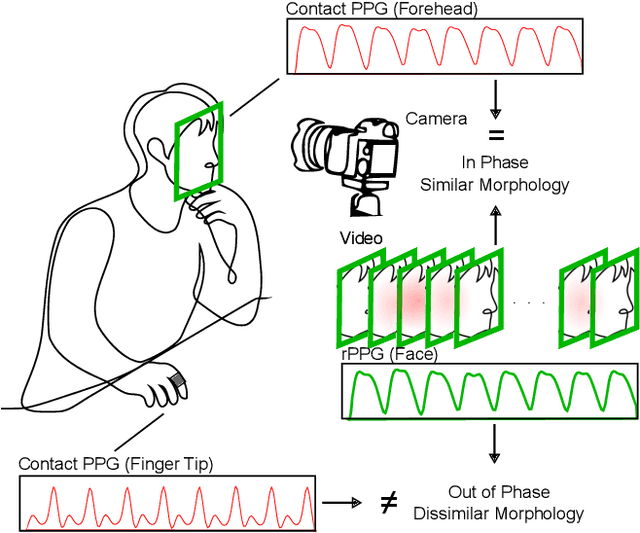


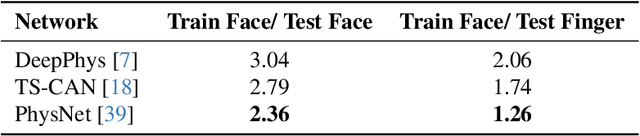
Remote camera measurement of the blood volume pulse via photoplethysmography (rPPG) is a compelling technology for scalable, low-cost, and accessible assessment of cardiovascular information. Neural networks currently provide the state-of-the-art for this task and supervised training or fine-tuning is an important step in creating these models. However, most current models are trained on facial videos using contact PPG measurements from the fingertip as targets/ labels. One of the reasons for this is that few public datasets to date have incorporated contact PPG measurements from the face. Yet there is copious evidence that the PPG signals at different sites on the body have very different morphological features. Is training a facial video rPPG model using contact measurements from another site on the body suboptimal? Using a recently released unique dataset with synchronized contact PPG and video measurements from both the hand and face, we can provide precise and quantitative answers to this question. We obtain up to 40 % lower mean squared errors between the waveforms of the predicted and the ground truth PPG signals using state-of-the-art neural models when using PPG signals from the forehead compared to using PPG signals from the fingertip. We also show qualitatively that the neural models learn to predict the morphology of the ground truth PPG signal better when trained on the forehead PPG signals. However, while models trained from the forehead PPG produce a more faithful waveform, models trained from a finger PPG do still learn the dominant frequency (i.e., the heart rate) well.
ClinicalMamba: A Generative Clinical Language Model on Longitudinal Clinical Notes
Mar 09, 2024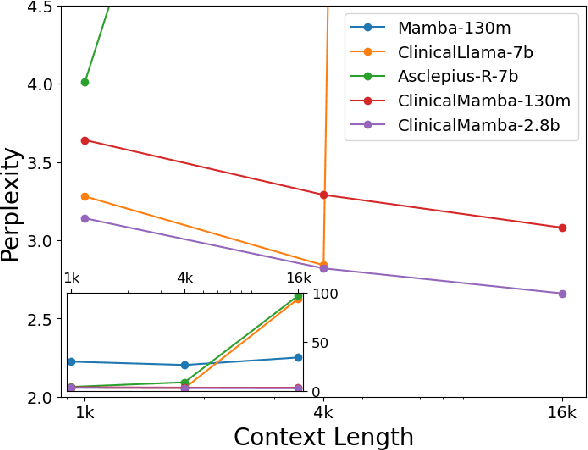
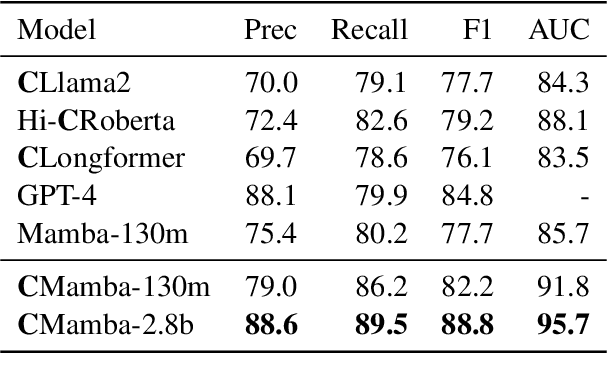
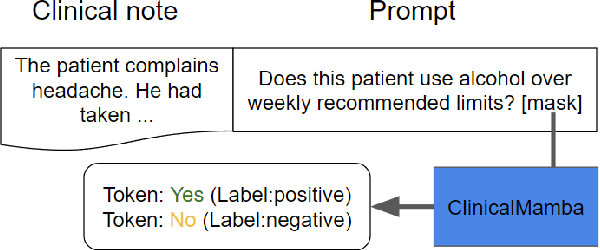
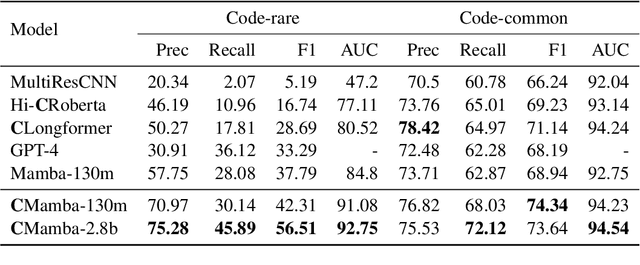
The advancement of natural language processing (NLP) systems in healthcare hinges on language model ability to interpret the intricate information contained within clinical notes. This process often requires integrating information from various time points in a patient's medical history. However, most earlier clinical language models were pretrained with a context length limited to roughly one clinical document. In this study, We introduce ClinicalMamba, a specialized version of the Mamba language model, pretrained on a vast corpus of longitudinal clinical notes to address the unique linguistic characteristics and information processing needs of the medical domain. ClinicalMamba, with 130 million and 2.8 billion parameters, demonstrates a superior performance in modeling clinical language across extended text lengths compared to Mamba and clinical Llama. With few-shot learning, ClinicalMamba achieves notable benchmarks in speed and accuracy, outperforming existing clinical language models and general domain large models like GPT-4 in longitudinal clinical notes information extraction tasks.
Diffusion Models with Implicit Guidance for Medical Anomaly Detection
Mar 13, 2024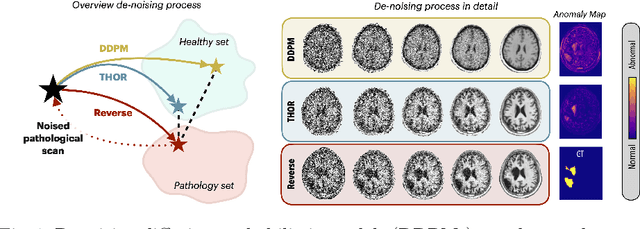
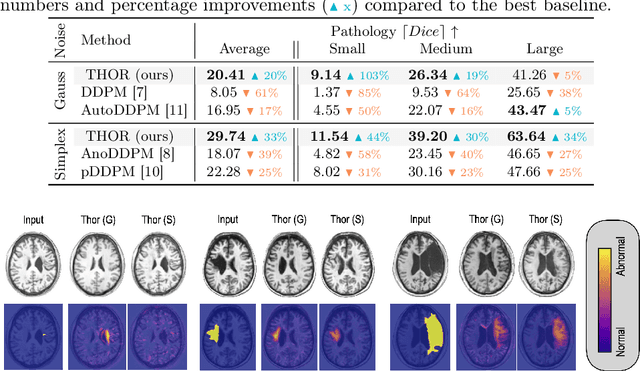
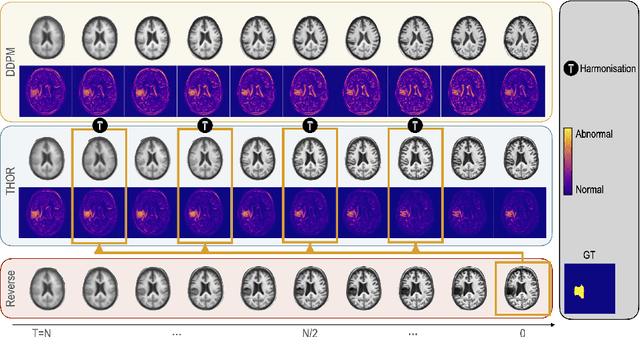
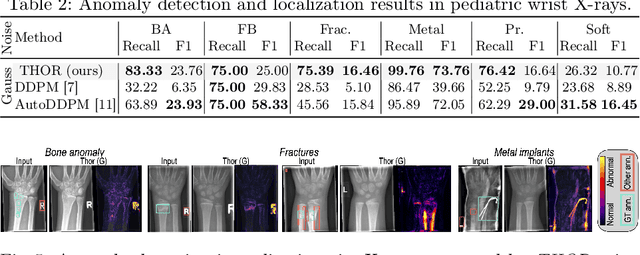
Diffusion models have advanced unsupervised anomaly detection by improving the transformation of pathological images into pseudo-healthy equivalents. Nonetheless, standard approaches may compromise critical information during pathology removal, leading to restorations that do not align with unaffected regions in the original scans. Such discrepancies can inadvertently increase false positive rates and reduce specificity, complicating radiological evaluations. This paper introduces Temporal Harmonization for Optimal Restoration (THOR), which refines the de-noising process by integrating implicit guidance through temporal anomaly maps. THOR aims to preserve the integrity of healthy tissue in areas unaffected by pathology. Comparative evaluations show that THOR surpasses existing diffusion-based methods in detecting and segmenting anomalies in brain MRIs and wrist X-rays. Code: https://github.com/ci-ber/THOR_DDPM.