 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Complex Teamwork Tasks using a Sub-task Curriculum
Feb 09, 2023
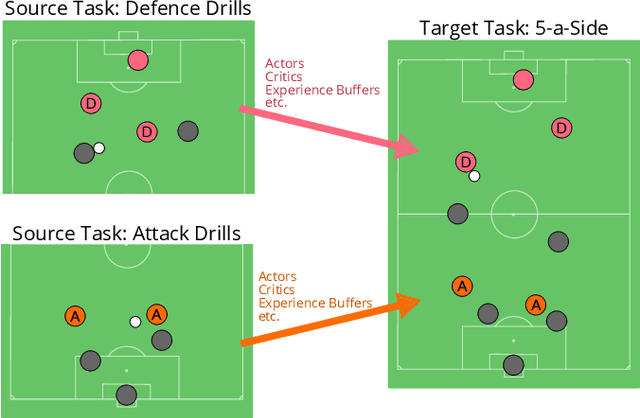
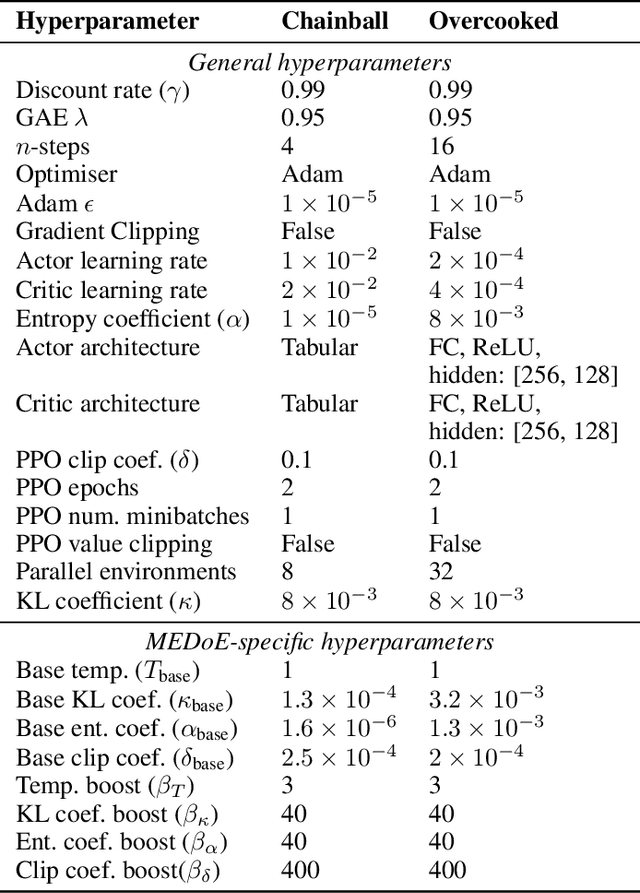
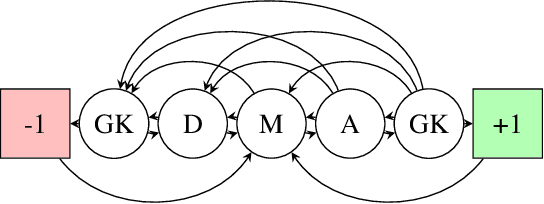
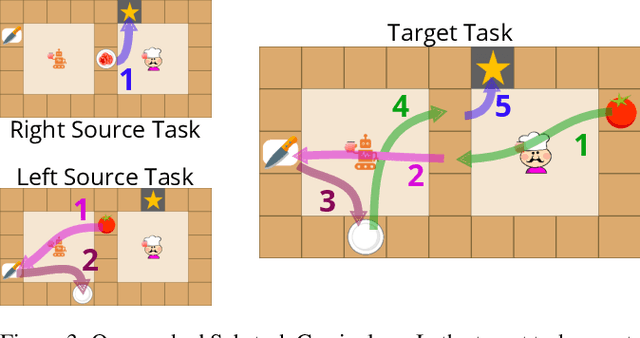
Training a team to complete a complex task via multi-agent reinforcement learning can be difficult due to challenges such as policy search in a large policy space, and non-stationarity caused by mutually adapting agents. To facilitate efficient learning of complex multi-agent tasks, we propose an approach which uses an expert-provided curriculum of simpler multi-agent sub-tasks. In each sub-task of the curriculum, a subset of the entire team is trained to acquire sub-task-specific policies. The sub-teams are then merged and transferred to the target task, where their policies are collectively fined tuned to solve the more complex target task. We present MEDoE, a flexible method which identifies situations in the target task where each agent can use its sub-task-specific skills, and uses this information to modulate hyperparameters for learning and exploration during the fine-tuning process. We compare MEDoE to multi-agent reinforcement learning baselines that train from scratch in the full task, and with na\"ive applications of standard multi-agent reinforcement learning techniques for fine-tuning. We show that MEDoE outperforms baselines which train from scratch or use na\"ive fine-tuning approaches, requiring significantly fewer total training timesteps to solve a range of complex teamwork tasks.
Machine Learning Capability: A standardized metric using case difficulty with applications to individualized deployment of supervised machine learning
Feb 09, 2023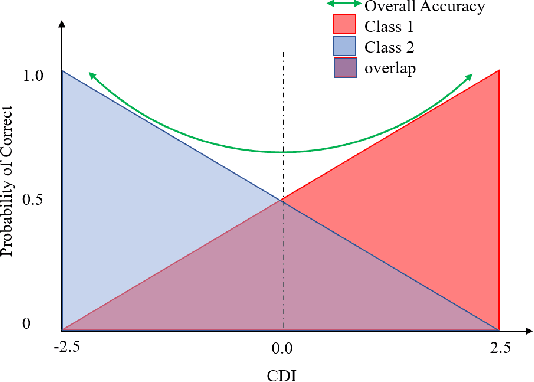
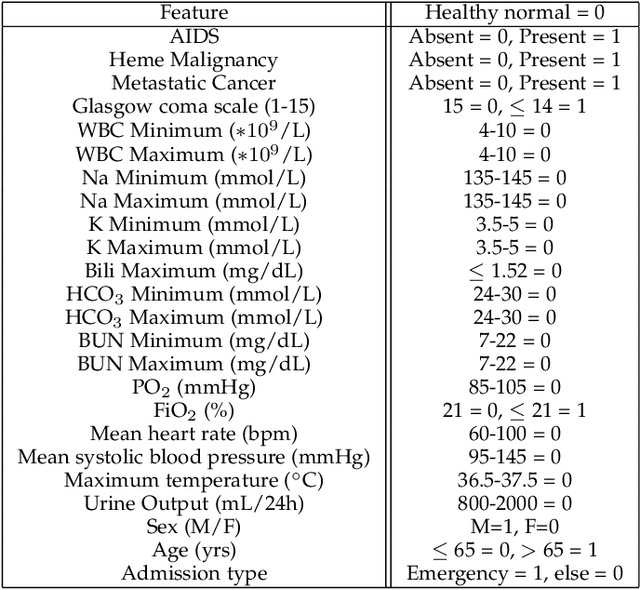
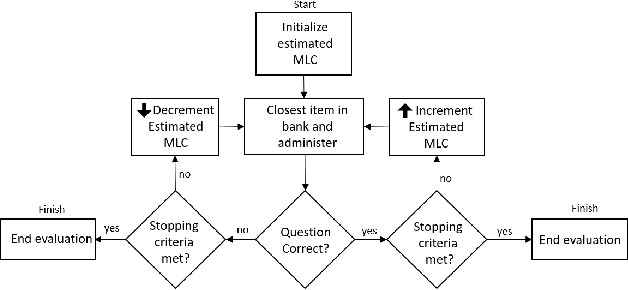

Model evaluation is a critical component in supervised machine learning classification analyses. Traditional metrics do not currently incorporate case difficulty. This renders the classification results unbenchmarked for generalization. Item Response Theory (IRT) and Computer Adaptive Testing (CAT) with machine learning can benchmark datasets independent of the end-classification results. This provides high levels of case-level information regarding evaluation utility. To showcase, two datasets were used: 1) health-related and 2) physical science. For the health dataset a two-parameter IRT model, and for the physical science dataset a polytonomous IRT model, was used to analyze predictive features and place each case on a difficulty continuum. A CAT approach was used to ascertain the algorithms' performance and applicability to new data. This method provides an efficient way to benchmark data, using only a fraction of the dataset (less than 1%) and 22-60x more computationally efficient than traditional metrics. This novel metric, termed Machine Learning Capability (MLC) has additional benefits as it is unbiased to outcome classification and a standardized way to make model comparisons within and across datasets. MLC provides a metric on the limitation of supervised machine learning algorithms. In situations where the algorithm falls short, other input(s) are required for decision-making.
Foundation Models for Natural Language Processing -- Pre-trained Language Models Integrating Media
Feb 16, 2023This open access book provides a comprehensive overview of the state of the art in research and applications of Foundation Models and is intended for readers familiar with basic Natural Language Processing (NLP) concepts. Over the recent years, a revolutionary new paradigm has been developed for training models for NLP. These models are first pre-trained on large collections of text documents to acquire general syntactic knowledge and semantic information. Then, they are fine-tuned for specific tasks, which they can often solve with superhuman accuracy. When the models are large enough, they can be instructed by prompts to solve new tasks without any fine-tuning. Moreover, they can be applied to a wide range of different media and problem domains, ranging from image and video processing to robot control learning. Because they provide a blueprint for solving many tasks in artificial intelligence, they have been called Foundation Models. After a brief introduction to basic NLP models the main pre-trained language models BERT, GPT and sequence-to-sequence transformer are described, as well as the concepts of self-attention and context-sensitive embedding. Then, different approaches to improving these models are discussed, such as expanding the pre-training criteria, increasing the length of input texts, or including extra knowledge. An overview of the best-performing models for about twenty application areas is then presented, e.g., question answering, translation, story generation, dialog systems, generating images from text, etc. For each application area, the strengths and weaknesses of current models are discussed, and an outlook on further developments is given. In addition, links are provided to freely available program code. A concluding chapter summarizes the economic opportunities, mitigation of risks, and potential developments of AI.
Mind the Gap: Offline Policy Optimization for Imperfect Rewards
Feb 03, 2023
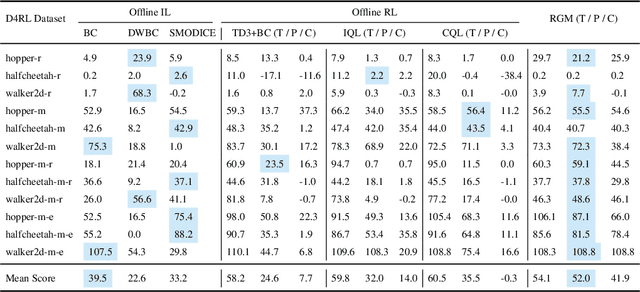
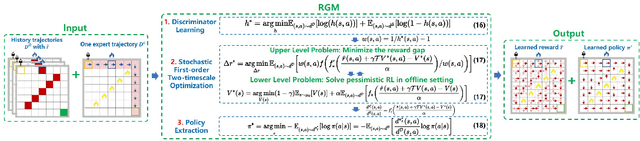
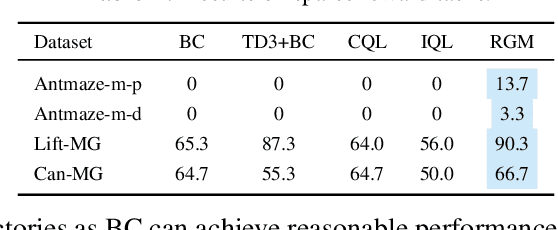
Reward function is essential in reinforcement learning (RL), serving as the guiding signal to incentivize agents to solve given tasks, however, is also notoriously difficult to design. In many cases, only imperfect rewards are available, which inflicts substantial performance loss for RL agents. In this study, we propose a unified offline policy optimization approach, \textit{RGM (Reward Gap Minimization)}, which can smartly handle diverse types of imperfect rewards. RGM is formulated as a bi-level optimization problem: the upper layer optimizes a reward correction term that performs visitation distribution matching w.r.t. some expert data; the lower layer solves a pessimistic RL problem with the corrected rewards. By exploiting the duality of the lower layer, we derive a tractable algorithm that enables sampled-based learning without any online interactions. Comprehensive experiments demonstrate that RGM achieves superior performance to existing methods under diverse settings of imperfect rewards. Further, RGM can effectively correct wrong or inconsistent rewards against expert preference and retrieve useful information from biased rewards.
Revisiting Intermediate Layer Distillation for Compressing Language Models: An Overfitting Perspective
Feb 03, 2023
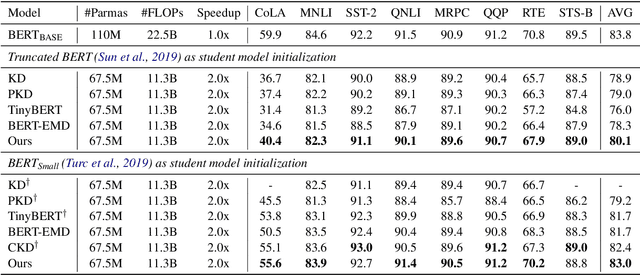

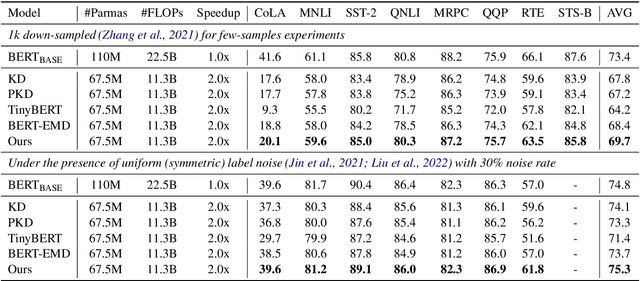
Knowledge distillation (KD) is a highly promising method for mitigating the computational problems of pre-trained language models (PLMs). Among various KD approaches, Intermediate Layer Distillation (ILD) has been a de facto standard KD method with its performance efficacy in the NLP field. In this paper, we find that existing ILD methods are prone to overfitting to training datasets, although these methods transfer more information than the original KD. Next, we present the simple observations to mitigate the overfitting of ILD: distilling only the last Transformer layer and conducting ILD on supplementary tasks. Based on our two findings, we propose a simple yet effective consistency-regularized ILD (CR-ILD), which prevents the student model from overfitting the training dataset. Substantial experiments on distilling BERT on the GLUE benchmark and several synthetic datasets demonstrate that our proposed ILD method outperforms other KD techniques. Our code is available at https://github.com/jongwooko/CR-ILD.
Reliable Natural Language Understanding with Large Language Models and Answer Set Programming
Feb 07, 2023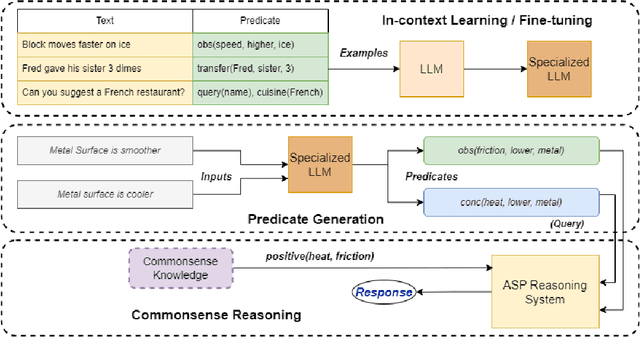
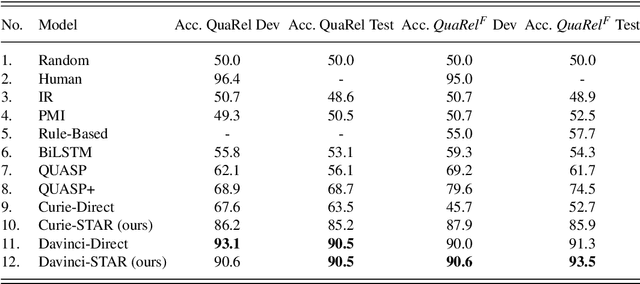

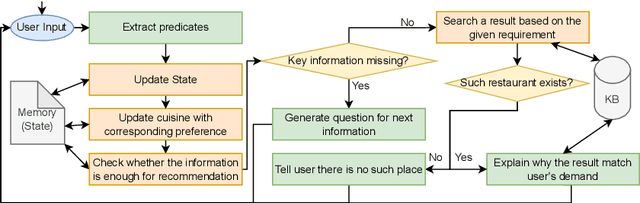
Humans understand language by extracting information (meaning) from sentences, combining it with existing commonsense knowledge, and then performing reasoning to draw conclusions. While large language models (LLMs) such as GPT-3 and ChatGPT are able to leverage patterns in the text to solve a variety of NLP tasks, they fall short in problems that require reasoning. They also cannot reliably explain the answers generated for a given question. In order to emulate humans better, we propose STAR, a framework that combines LLMs with Answer Set Programming (ASP). We show how LLMs can be used to effectively extract knowledge -- represented as predicates -- from language. Goal-directed ASP is then employed to reliably reason over this knowledge. We apply the STAR framework to three different NLU tasks requiring reasoning: qualitative reasoning, mathematical reasoning, and goal-directed conversation. Our experiments reveal that STAR is able to bridge the gap of reasoning in NLU tasks, leading to significant performance improvements, especially for smaller LLMs, i.e., LLMs with a smaller number of parameters. NLU applications developed using the STAR framework are also explainable: along with the predicates generated, a justification in the form of a proof tree can be produced for a given output.
Tetris-inspired detector with neural network for radiation mapping
Feb 07, 2023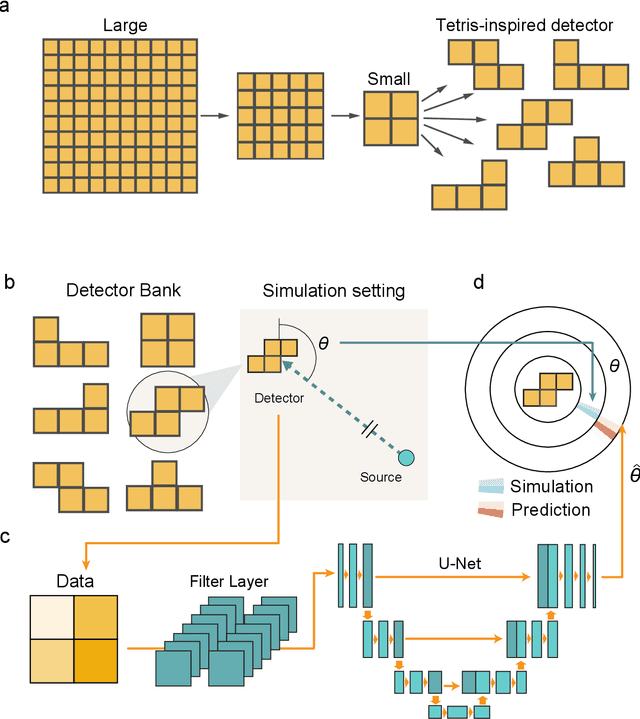
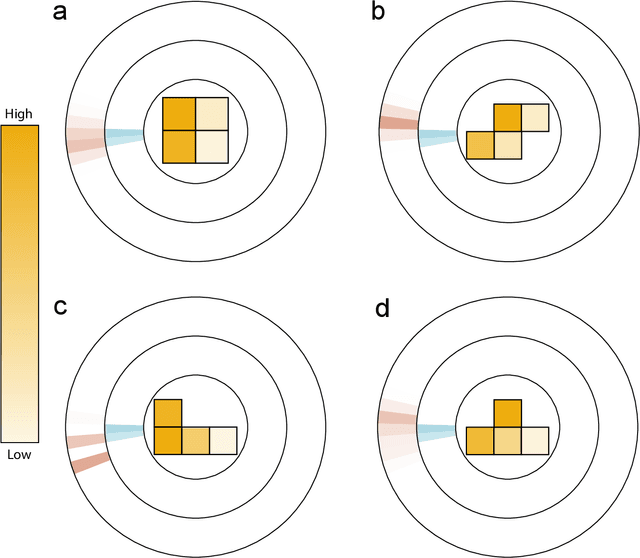
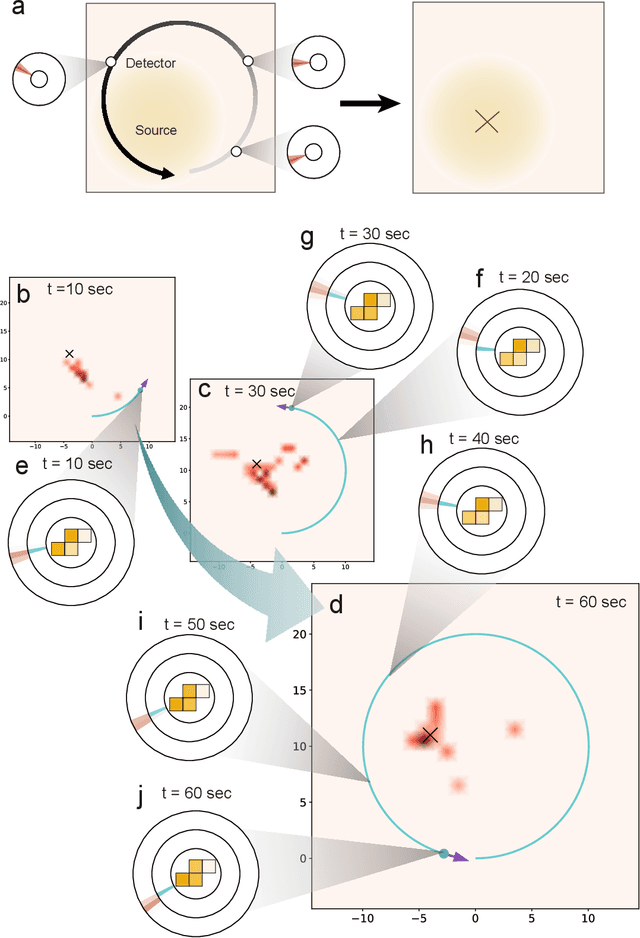
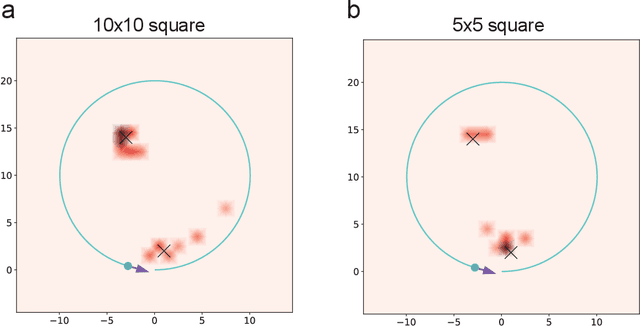
In recent years, radiation mapping has attracted widespread research attention and increased public concerns on environmental monitoring. In terms of both materials and their configurations, radiation detectors have been developed to locate the directions and positions of the radiation sources. In this process, algorithm is essential in converting detector signals to radiation source information. However, due to the complex mechanisms of radiation-matter interaction and the current limitation of data collection, high-performance, low-cost radiation mapping is still challenging. Here we present a computational framework using Tetris-inspired detector pixels and machine learning for radiation mapping. Using inter-pixel padding to increase the contrast between pixels and neural network to analyze the detector readings, a detector with as few as four pixels can achieve high-resolution directional mapping. By further imposing Maximum a Posteriori (MAP) with a moving detector, further radiation position localization is achieved. Non-square, Tetris-shaped detector can further improve performance beyond the conventional grid-shaped detector. Our framework offers a new avenue for high quality radiation mapping with least number of detector pixels possible, and is anticipated to be capable to deploy for real-world radiation detection with moderate validation.
Deep Joint Source-Channel Coding for Wireless Image Transmission with Semantic Importance
Feb 05, 2023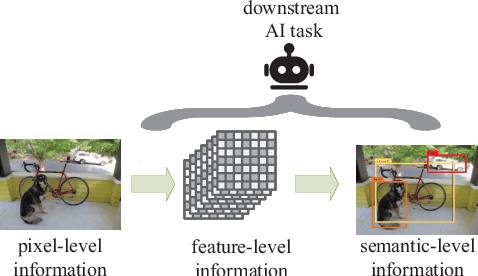
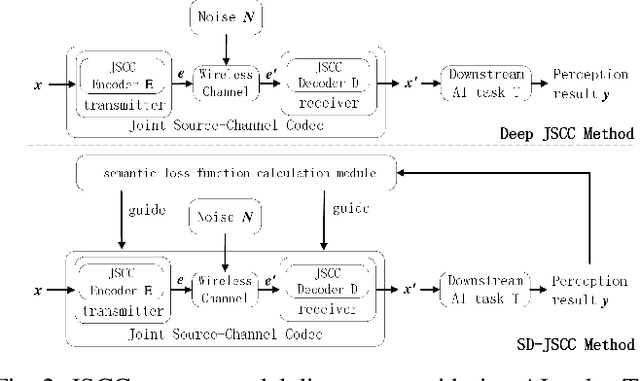
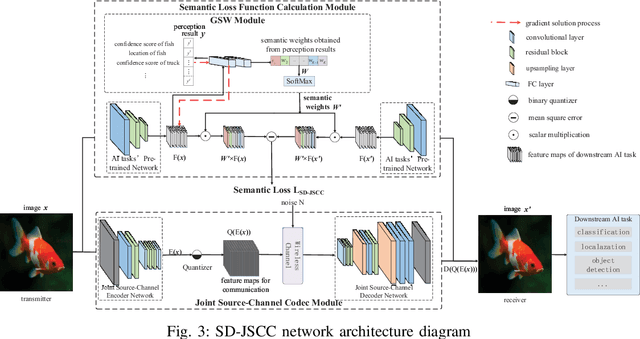
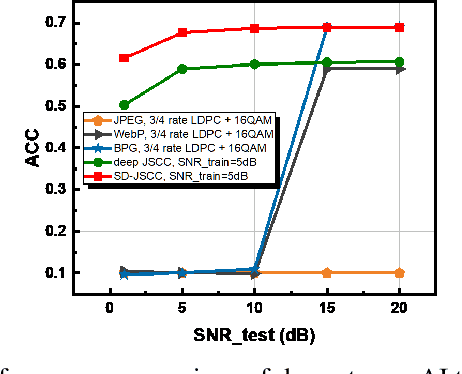
The sixth-generation mobile communication system proposes the vision of smart interconnection of everything, which requires accomplishing communication tasks while ensuring the performance of intelligent tasks. A joint source-channel coding method based on semantic importance is proposed, which aims at preserving semantic information during wireless image transmission and thereby boosting the performance of intelligent tasks for images at the receiver. Specifically, we first propose semantic importance weight calculation method, which is based on the gradient of intelligent task's perception results with respect to the features. Then, we design the semantic loss function in the way of using semantic weights to weight the features. Finally, we train the deep joint source-channel coding network using the semantic loss function. Experiment results demonstrate that the proposed method achieves up to 57.7% and 9.1% improvement in terms of intelligent task's performance compared with the source-channel separation coding method and the deep sourcechannel joint coding method without considering semantics at the same compression rate and signal-to-noise ratio, respectively.
On the Role of Contrastive Representation Learning in Adversarial Robustness: An Empirical Study
Feb 05, 2023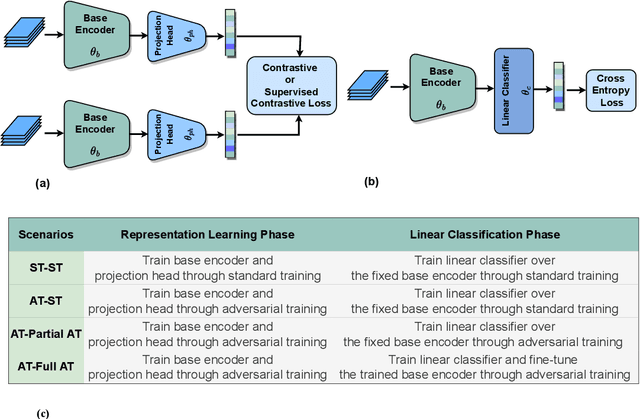
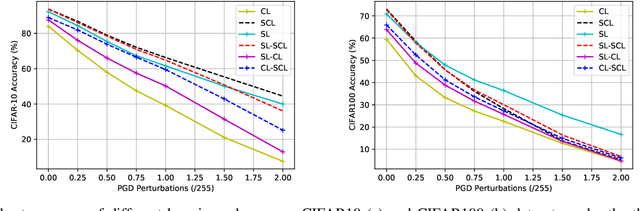
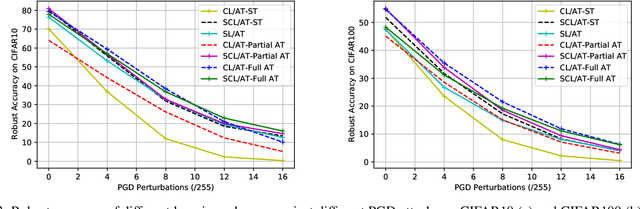
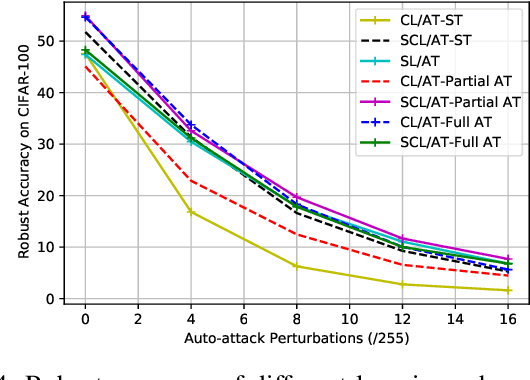
Self-supervised contrastive learning has solved one of the significant obstacles in deep learning by alleviating the annotation cost. This advantage comes with the price of false negative-pair selection without any label information. Supervised contrastive learning has emerged as an extension of contrastive learning to eliminate this issue. However, aside from accuracy, there is a lack of understanding about the impacts of adversarial training on the representations learned by these learning schemes. In this work, we utilize supervised learning as a baseline to comprehensively study the robustness of contrastive and supervised contrastive learning under different adversarial training scenarios. Then, we begin by looking at how adversarial training affects the learned representations in hidden layers, discovering more redundant representations between layers of the model. Our results on CIFAR-10 and CIFAR-100 image classification benchmarks demonstrate that this redundancy is highly reduced by adversarial fine-tuning applied to the contrastive learning scheme, leading to more robust representations. However, adversarial fine-tuning is not very effective for supervised contrastive learning and supervised learning schemes. Our code is released at https://github.com/softsys4ai/CL-Robustness.
Model-based inexact graph matching on top of CNNs for semantic scene understanding
Jan 18, 2023

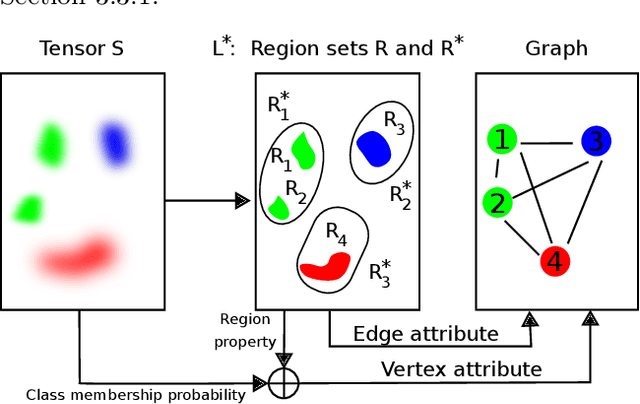
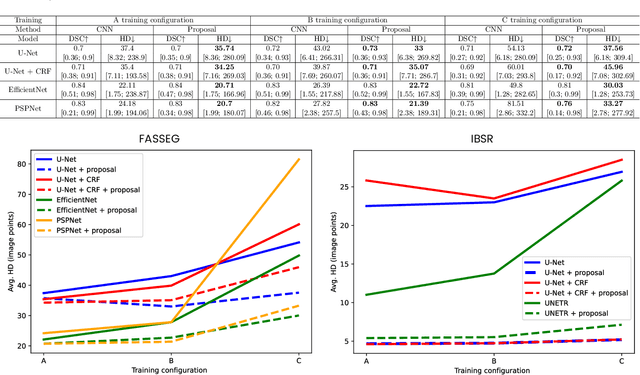
Deep learning based pipelines for semantic segmentation often ignore structural information available on annotated images used for training. We propose a novel post-processing module enforcing structural knowledge about the objects of interest to improve segmentation results provided by deep learning. This module corresponds to a "many-to-one-or-none" inexact graph matching approach, and is formulated as a quadratic assignment problem. Our approach is compared to a CNN-based segmentation (for various CNN backbones) on two public datasets, one for face segmentation from 2D RGB images (FASSEG), and the other for brain segmentation from 3D MRIs (IBSR). Evaluations are performed using two types of structural information (distances and directional relations, , this choice being a hyper-parameter of our generic framework). On FASSEG data, results show that our module improves accuracy of the CNN by about 6.3% (the Hausdorff distance decreases from 22.11 to 20.71). On IBSR data, the improvement is of 51% (the Hausdorff distance decreases from 11.01 to 5.4). In addition, our approach is shown to be resilient to small training datasets that often limit the performance of deep learning methods: the improvement increases as the size of the training dataset decreases.