 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeighted Mean Frequencies: a handcraft Fourier feature for 4D Flow MRI segmentation
Jun 25, 2025In recent decades, the use of 4D Flow MRI images has enabled the quantification of velocity fields within a volume of interest and along the cardiac cycle. However, the lack of resolution and the presence of noise in these biomarkers are significant issues. As indicated by recent studies, it appears that biomarkers such as wall shear stress are particularly impacted by the poor resolution of vessel segmentation. The Phase Contrast Magnetic Resonance Angiography (PC-MRA) is the state-of-the-art method to facilitate segmentation. The objective of this work is to introduce a new handcraft feature that provides a novel visualisation of 4D Flow MRI images, which is useful in the segmentation task. This feature, termed Weighted Mean Frequencies (WMF), is capable of revealing the region in three dimensions where a voxel has been passed by pulsatile flow. Indeed, this feature is representative of the hull of all pulsatile velocity voxels. The value of the feature under discussion is illustrated by two experiments. The experiments involved segmenting 4D Flow MRI images using optimal thresholding and deep learning methods. The results obtained demonstrate a substantial enhancement in terms of IoU and Dice, with a respective increase of 0.12 and 0.13 in comparison with the PC-MRA feature, as evidenced by the deep learning task. This feature has the potential to yield valuable insights that could inform future segmentation processes in other vascular regions, such as the heart or the brain.
Local and Global Graph Modeling with Edge-weighted Graph Attention Network for Handwritten Mathematical Expression Recognition
Oct 24, 2024



In this paper, we present a novel approach to Handwritten Mathematical Expression Recognition (HMER) by leveraging graph-based modeling techniques. We introduce an End-to-end model with an Edge-weighted Graph Attention Mechanism (EGAT), designed to perform simultaneous node and edge classification. This model effectively integrates node and edge features, facilitating the prediction of symbol classes and their relationships within mathematical expressions. Additionally, we propose a stroke-level Graph Modeling method for both local (LGM) and global (GGM) information, which applies an end-to-end model to Online HMER tasks, transforming the recognition problem into node and edge classification tasks in graph structure. By capturing both local and global graph features, our method ensures comprehensive understanding of the expression structure. Through the combination of these components, our system demonstrates superior performance in symbol detection, relation classification, and expression-level recognition.
NeuroPapyri: A Deep Attention Embedding Network for Handwritten Papyri Retrieval
Aug 14, 2024The intersection of computer vision and machine learning has emerged as a promising avenue for advancing historical research, facilitating a more profound exploration of our past. However, the application of machine learning approaches in historical palaeography is often met with criticism due to their perceived ``black box'' nature. In response to this challenge, we introduce NeuroPapyri, an innovative deep learning-based model specifically designed for the analysis of images containing ancient Greek papyri. To address concerns related to transparency and interpretability, the model incorporates an attention mechanism. This attention mechanism not only enhances the model's performance but also provides a visual representation of the image regions that significantly contribute to the decision-making process. Specifically calibrated for processing images of papyrus documents with lines of handwritten text, the model utilizes individual attention maps to inform the presence or absence of specific characters in the input image. This paper presents the NeuroPapyri model, including its architecture and training methodology. Results from the evaluation demonstrate NeuroPapyri's efficacy in document retrieval, showcasing its potential to advance the analysis of historical manuscripts.
Enhancing Post-Hoc Explanation Benchmark Reliability for Image Classification
Nov 29, 2023



Deep neural networks, while powerful for image classification, often operate as "black boxes," complicating the understanding of their decision-making processes. Various explanation methods, particularly those generating saliency maps, aim to address this challenge. However, the inconsistency issues of faithfulness metrics hinder reliable benchmarking of explanation methods. This paper employs an approach inspired by psychometrics, utilizing Krippendorf's alpha to quantify the benchmark reliability of post-hoc methods in image classification. The study proposes model training modifications, including feeding perturbed samples and employing focal loss, to enhance robustness and calibration. Empirical evaluations demonstrate significant improvements in benchmark reliability across metrics, datasets, and post-hoc methods. This pioneering work establishes a foundation for more reliable evaluation practices in the realm of post-hoc explanation methods, emphasizing the importance of model robustness in the assessment process.
Handwritten Text Recognition from Crowdsourced Annotations
Jun 19, 2023In this paper, we explore different ways of training a model for handwritten text recognition when multiple imperfect or noisy transcriptions are available. We consider various training configurations, such as selecting a single transcription, retaining all transcriptions, or computing an aggregated transcription from all available annotations. In addition, we evaluate the impact of quality-based data selection, where samples with low agreement are removed from the training set. Our experiments are carried out on municipal registers of the city of Belfort (France) written between 1790 and 1946. % results The results show that computing a consensus transcription or training on multiple transcriptions are good alternatives. However, selecting training samples based on the degree of agreement between annotators introduces a bias in the training data and does not improve the results. Our dataset is publicly available on Zenodo: https://zenodo.org/record/8041668.
Model-based inexact graph matching on top of CNNs for semantic scene understanding
Jan 18, 2023



Deep learning based pipelines for semantic segmentation often ignore structural information available on annotated images used for training. We propose a novel post-processing module enforcing structural knowledge about the objects of interest to improve segmentation results provided by deep learning. This module corresponds to a "many-to-one-or-none" inexact graph matching approach, and is formulated as a quadratic assignment problem. Our approach is compared to a CNN-based segmentation (for various CNN backbones) on two public datasets, one for face segmentation from 2D RGB images (FASSEG), and the other for brain segmentation from 3D MRIs (IBSR). Evaluations are performed using two types of structural information (distances and directional relations, , this choice being a hyper-parameter of our generic framework). On FASSEG data, results show that our module improves accuracy of the CNN by about 6.3% (the Hausdorff distance decreases from 22.11 to 20.71). On IBSR data, the improvement is of 51% (the Hausdorff distance decreases from 11.01 to 5.4). In addition, our approach is shown to be resilient to small training datasets that often limit the performance of deep learning methods: the improvement increases as the size of the training dataset decreases.
Comparison of attention models and post-hoc explanation methods for embryo stage identification: a case study
May 13, 2022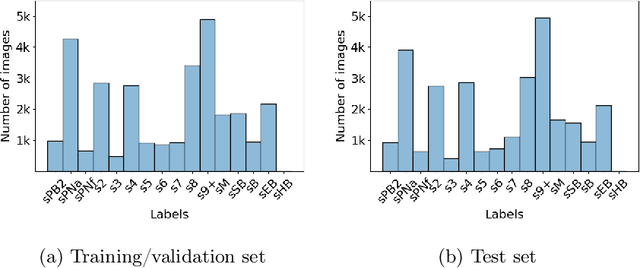
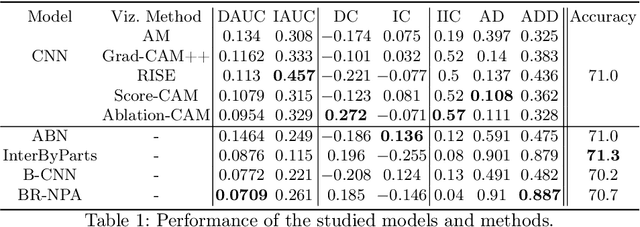
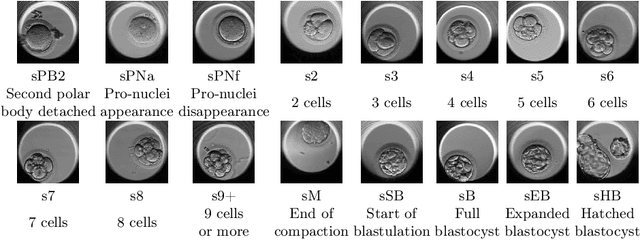
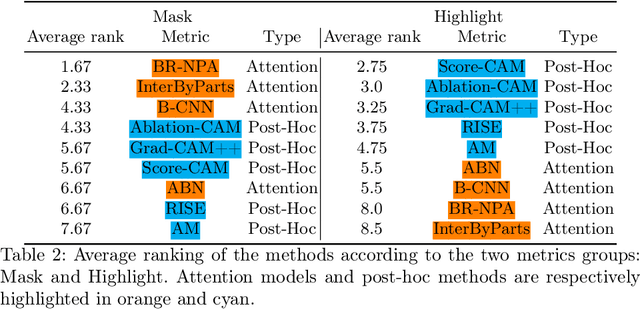
An important limitation to the development of AI-based solutions for In Vitro Fertilization (IVF) is the black-box nature of most state-of-the-art models, due to the complexity of deep learning architectures, which raises potential bias and fairness issues. The need for interpretable AI has risen not only in the IVF field but also in the deep learning community in general. This has started a trend in literature where authors focus on designing objective metrics to evaluate generic explanation methods. In this paper, we study the behavior of recently proposed objective faithfulness metrics applied to the problem of embryo stage identification. We benchmark attention models and post-hoc methods using metrics and further show empirically that (1) the metrics produce low overall agreement on the model ranking and (2) depending on the metric approach, either post-hoc methods or attention models are favored. We conclude with general remarks about the difficulty of defining faithfulness and the necessity of understanding its relationship with the type of approach that is favored.
Towards deep learning-powered IVF: A large public benchmark for morphokinetic parameter prediction
Mar 01, 2022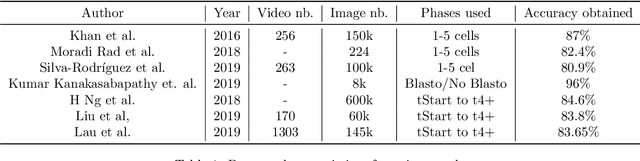
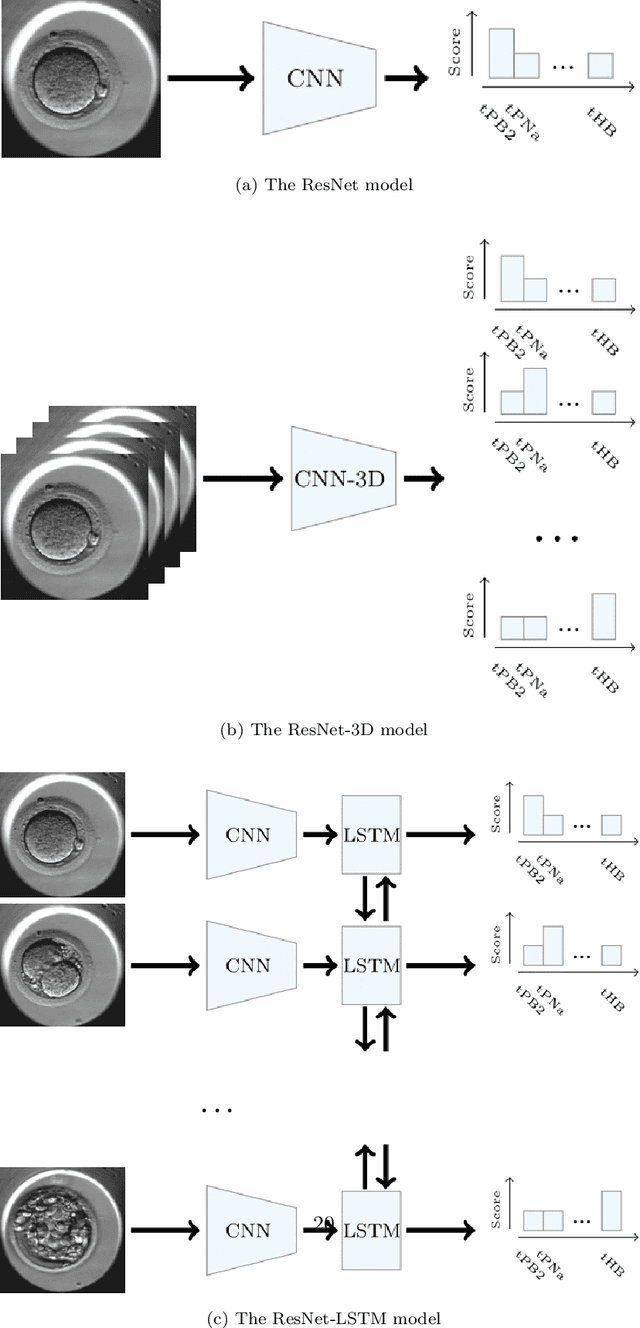

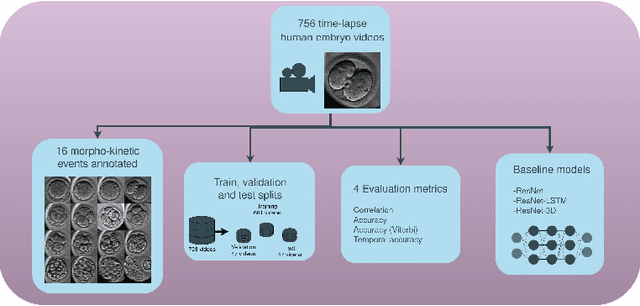
An important limitation to the development of Artificial Intelligence (AI)-based solutions for In Vitro Fertilization (IVF) is the absence of a public reference benchmark to train and evaluate deep learning (DL) models. In this work, we describe a fully annotated dataset of 756 videos of developing embryos, for a total of 337k images. We applied ResNet, LSTM, and ResNet-3D architectures to our dataset and demonstrate that they overperform algorithmic approaches to automatically annotate stage development phases. Altogether, we propose the first public benchmark that will allow the community to evaluate morphokinetic models. This is the first step towards deep learning-powered IVF. Of note, we propose highly detailed annotations with 16 different development phases, including early cell division phases, but also late cell divisions, phases after morulation, and very early phases, which have never been used before. We postulate that this original approach will help improve the overall performance of deep learning approaches on time-lapse videos of embryo development, ultimately benefiting infertile patients with improved clinical success rates (Code and data are available at https://gitlab.univ-nantes.fr/E144069X/bench_mk_pred.git).
Metrics for saliency map evaluation of deep learning explanation methods
Jan 31, 2022
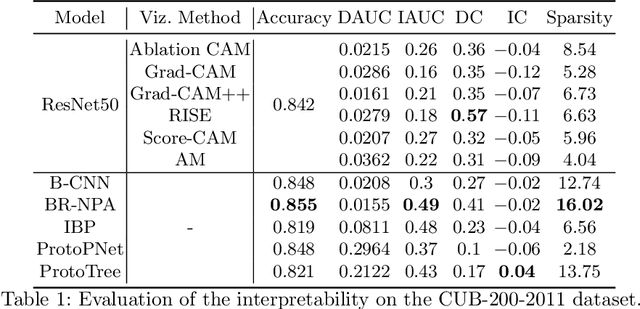
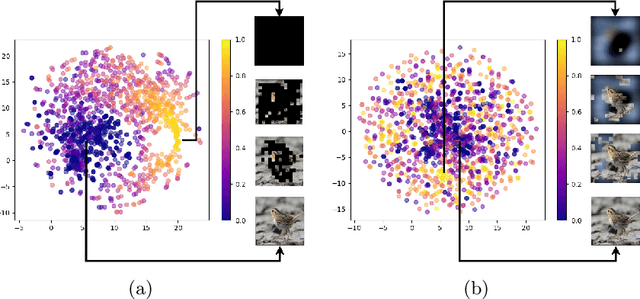
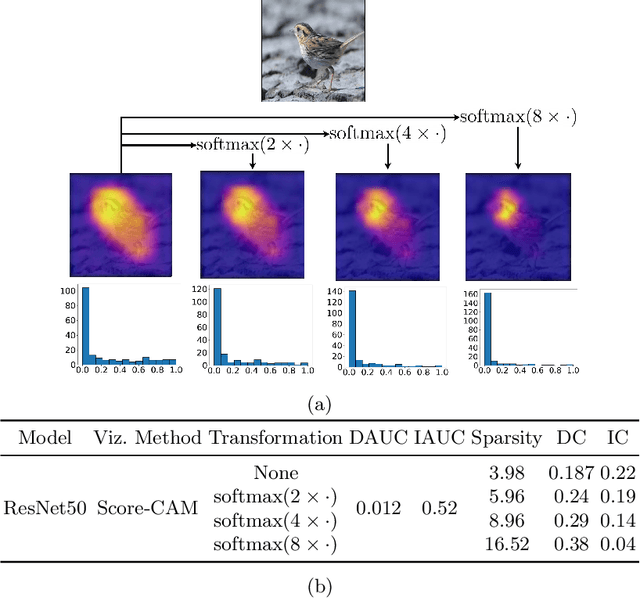
Due to the black-box nature of deep learning models, there is a recent development of solutions for visual explanations of CNNs. Given the high cost of user studies, metrics are necessary to compare and evaluate these different methods. In this paper, we critically analyze the Deletion Area Under Curve (DAUC) and Insertion Area Under Curve (IAUC) metrics proposed by Petsiuk et al. (2018). These metrics were designed to evaluate the faithfulness of saliency maps generated by generic methods such as Grad-CAM or RISE. First, we show that the actual saliency score values given by the saliency map are ignored as only the ranking of the scores is taken into account. This shows that these metrics are insufficient by themselves, as the visual appearance of a saliency map can change significantly without the ranking of the scores being modified. Secondly, we argue that during the computation of DAUC and IAUC, the model is presented with images that are out of the training distribution which might lead to an unreliable behavior of the model being explained. %First, we show that one can drastically change the visual appearance of an explanation map without changing the pixel ranking, i.e. without changing the DAUC and IAUC values. %We argue that DAUC and IAUC only takes into account the scores ranking and ignore the score values. To complement DAUC/IAUC, we propose new metrics that quantify the sparsity and the calibration of explanation methods, two previously unstudied properties. Finally, we give general remarks about the metrics studied in this paper and discuss how to evaluate them in a user study.
Improve the Interpretability of Attention: A Fast, Accurate, and Interpretable High-Resolution Attention Model
Jun 07, 2021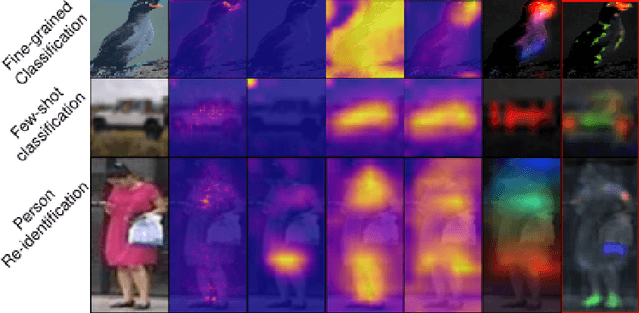
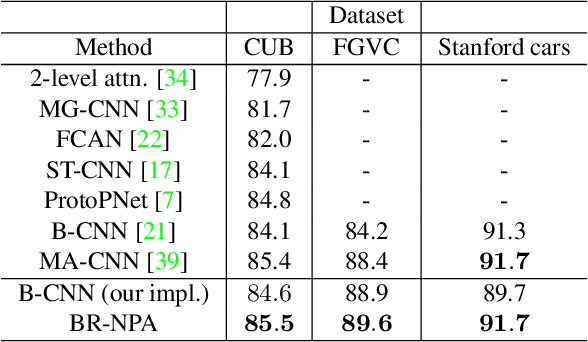
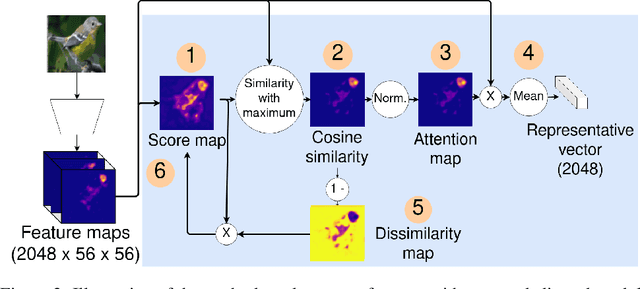
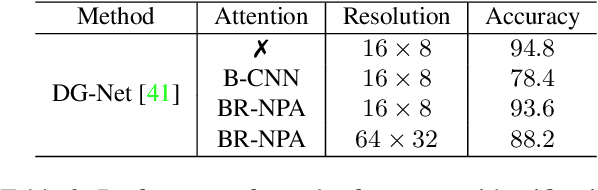
The prevalence of employing attention mechanisms has brought along concerns on the interpretability of attention distributions. Although it provides insights about how a model is operating, utilizing attention as the explanation of model predictions is still highly dubious. The community is still seeking more interpretable strategies for better identifying local active regions that contribute the most to the final decision. To improve the interpretability of existing attention models, we propose a novel Bilinear Representative Non-Parametric Attention (BR-NPA) strategy that captures the task-relevant human-interpretable information. The target model is first distilled to have higher-resolution intermediate feature maps. From which, representative features are then grouped based on local pairwise feature similarity, to produce finer-grained, more precise attention maps highlighting task-relevant parts of the input. The obtained attention maps are ranked according to the `active level' of the compound feature, which provides information regarding the important level of the highlighted regions. The proposed model can be easily adapted in a wide variety of modern deep models, where classification is involved. It is also more accurate, faster, and with a smaller memory footprint than usual neural attention modules. Extensive experiments showcase more comprehensive visual explanations compared to the state-of-the-art visualization model across multiple tasks including few-shot classification, person re-identification, fine-grained image classification. The proposed visualization model sheds imperative light on how neural networks `pay their attention' differently in different tasks.