 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Generalizing Across Diverse Team Strategies in Competitive Pokémon
Jun 12, 2025Developing AI agents that can robustly adapt to dramatically different strategic landscapes without retraining is a central challenge for multi-agent learning. Pok\'emon Video Game Championships (VGC) is a domain with an extraordinarily large space of possible team configurations of approximately $10^{139}$ - far larger than those of Dota or Starcraft. The highly discrete, combinatorial nature of team building in Pok\'emon VGC causes optimal strategies to shift dramatically depending on both the team being piloted and the opponent's team, making generalization uniquely challenging. To advance research on this problem, we introduce VGC-Bench: a benchmark that provides critical infrastructure, standardizes evaluation protocols, and supplies human-play datasets and a range of baselines - from large-language-model agents and behavior cloning to reinforcement learning and empirical game-theoretic methods such as self-play, fictitious play, and double oracle. In the restricted setting where an agent is trained and evaluated on a single-team configuration, our methods are able to win against a professional VGC competitor. We extensively evaluated all baseline methods over progressively larger team sets and find that even the best-performing algorithm in the single-team setting struggles at scaling up as team size grows. Thus, policy generalization across diverse team strategies remains an open challenge for the community. Our code is open sourced at https://github.com/cameronangliss/VGC-Bench.
ROTATE: Regret-driven Open-ended Training for Ad Hoc Teamwork
May 29, 2025Developing AI agents capable of collaborating with previously unseen partners is a fundamental generalization challenge in multi-agent learning, known as Ad Hoc Teamwork (AHT). Existing AHT approaches typically adopt a two-stage pipeline, where first, a fixed population of teammates is generated with the idea that they should be representative of the teammates that will be seen at deployment time, and second, an AHT agent is trained to collaborate well with agents in the population. To date, the research community has focused on designing separate algorithms for each stage. This separation has led to algorithms that generate teammate pools with limited coverage of possible behaviors, and that ignore whether the generated teammates are easy to learn from for the AHT agent. Furthermore, algorithms for training AHT agents typically treat the set of training teammates as static, thus attempting to generalize to previously unseen partner agents without assuming any control over the distribution of training teammates. In this paper, we present a unified framework for AHT by reformulating the problem as an open-ended learning process between an ad hoc agent and an adversarial teammate generator. We introduce ROTATE, a regret-driven, open-ended training algorithm that alternates between improving the AHT agent and generating teammates that probe its deficiencies. Extensive experiments across diverse AHT environments demonstrate that ROTATE significantly outperforms baselines at generalizing to an unseen set of evaluation teammates, thus establishing a new standard for robust and generalizable teamwork.
HyperMARL: Adaptive Hypernetworks for Multi-Agent RL
Dec 05, 2024



Balancing individual specialisation and shared behaviours is a critical challenge in multi-agent reinforcement learning (MARL). Existing methods typically focus on encouraging diversity or leveraging shared representations. Full parameter sharing (FuPS) improves sample efficiency but struggles to learn diverse behaviours when required, while no parameter sharing (NoPS) enables diversity but is computationally expensive and sample inefficient. To address these challenges, we introduce HyperMARL, a novel approach using hypernetworks to balance efficiency and specialisation. HyperMARL generates agent-specific actor and critic parameters, enabling agents to adaptively exhibit diverse or homogeneous behaviours as needed, without modifying the learning objective or requiring prior knowledge of the optimal diversity. Furthermore, HyperMARL decouples agent-specific and state-based gradients, which empirically correlates with reduced policy gradient variance, potentially offering insights into its ability to capture diverse behaviours. Across MARL benchmarks requiring homogeneous, heterogeneous, or mixed behaviours, HyperMARL consistently matches or outperforms FuPS, NoPS, and diversity-focused methods, achieving NoPS-level diversity with a shared architecture. These results highlight the potential of hypernetworks as a versatile approach to the trade-off between specialisation and shared behaviours in MARL.
N-Agent Ad Hoc Teamwork
Apr 16, 2024Current approaches to learning cooperative behaviors in multi-agent settings assume relatively restrictive settings. In standard fully cooperative multi-agent reinforcement learning, the learning algorithm controls \textit{all} agents in the scenario, while in ad hoc teamwork, the learning algorithm usually assumes control over only a $\textit{single}$ agent in the scenario. However, many cooperative settings in the real world are much less restrictive. For example, in an autonomous driving scenario, a company might train its cars with the same learning algorithm, yet once on the road, these cars must cooperate with cars from another company. Towards generalizing the class of scenarios that cooperative learning methods can address, we introduce $N$-agent ad hoc teamwork, in which a set of autonomous agents must interact and cooperate with dynamically varying numbers and types of teammates at evaluation time. This paper formalizes the problem, and proposes the $\textit{Policy Optimization with Agent Modelling}$ (POAM) algorithm. POAM is a policy gradient, multi-agent reinforcement learning approach to the NAHT problem, that enables adaptation to diverse teammate behaviors by learning representations of teammate behaviors. Empirical evaluation on StarCraft II tasks shows that POAM improves cooperative task returns compared to baseline approaches, and enables out-of-distribution generalization to unseen teammates.
Minimum Coverage Sets for Training Robust Ad Hoc Teamwork Agents
Aug 18, 2023Robustly cooperating with unseen agents and human partners presents significant challenges due to the diverse cooperative conventions these partners may adopt. Existing Ad Hoc Teamwork (AHT) methods address this challenge by training an agent with a population of diverse teammate policies obtained through maximizing specific diversity metrics. However, these heuristic diversity metrics do not always maximize the agent's robustness in all cooperative problems. In this work, we first propose that maximizing an AHT agent's robustness requires it to emulate policies in the minimum coverage set (MCS), the set of best-response policies to any partner policies in the environment. We then introduce the L-BRDiv algorithm that generates a set of teammate policies that, when used for AHT training, encourage agents to emulate policies from the MCS. L-BRDiv works by solving a constrained optimization problem to jointly train teammate policies for AHT training and approximating AHT agent policies that are members of the MCS. We empirically demonstrate that L-BRDiv produces more robust AHT agents than state-of-the-art methods in a broader range of two-player cooperative problems without the need for extensive hyperparameter tuning for its objectives. Our study shows that L-BRDiv outperforms the baseline methods by prioritizing discovering distinct members of the MCS instead of repeatedly finding redundant policies.
Learning Complex Teamwork Tasks using a Sub-task Curriculum
Feb 09, 2023



Training a team to complete a complex task via multi-agent reinforcement learning can be difficult due to challenges such as policy search in a large policy space, and non-stationarity caused by mutually adapting agents. To facilitate efficient learning of complex multi-agent tasks, we propose an approach which uses an expert-provided curriculum of simpler multi-agent sub-tasks. In each sub-task of the curriculum, a subset of the entire team is trained to acquire sub-task-specific policies. The sub-teams are then merged and transferred to the target task, where their policies are collectively fined tuned to solve the more complex target task. We present MEDoE, a flexible method which identifies situations in the target task where each agent can use its sub-task-specific skills, and uses this information to modulate hyperparameters for learning and exploration during the fine-tuning process. We compare MEDoE to multi-agent reinforcement learning baselines that train from scratch in the full task, and with na\"ive applications of standard multi-agent reinforcement learning techniques for fine-tuning. We show that MEDoE outperforms baselines which train from scratch or use na\"ive fine-tuning approaches, requiring significantly fewer total training timesteps to solve a range of complex teamwork tasks.
A General Learning Framework for Open Ad Hoc Teamwork Using Graph-based Policy Learning
Oct 11, 2022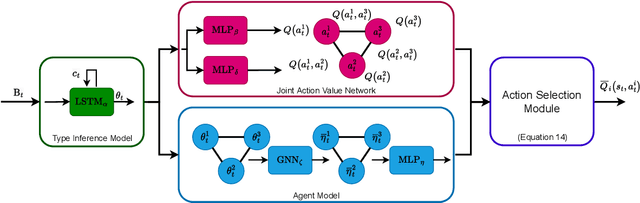
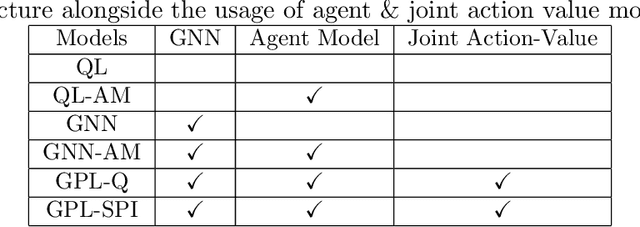
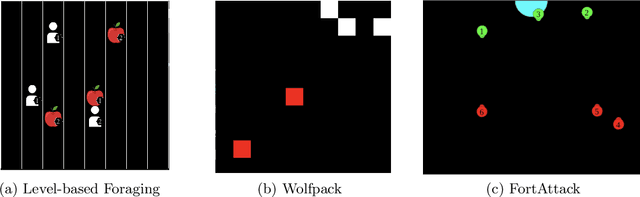
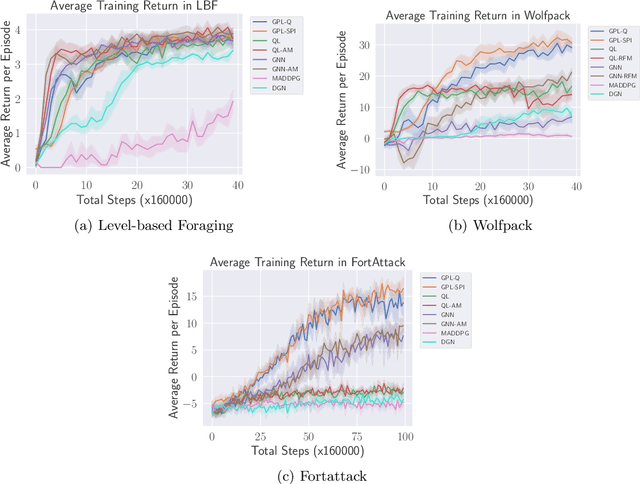
Open ad hoc teamwork is the problem of training a single agent to efficiently collaborate with an unknown group of teammates whose composition may change over time. A variable team composition creates challenges for the agent, such as the requirement to adapt to new team dynamics and dealing with changing state vector sizes. These challenges are aggravated in real-world applications where the controlled agent has no access to the full state of the environment. In this work, we develop a class of solutions for open ad hoc teamwork under full and partial observability. We start by developing a solution for the fully observable case that leverages graph neural network architectures to obtain an optimal policy based on reinforcement learning. We then extend this solution to partially observable scenarios by proposing different methodologies that maintain belief estimates over the latent environment states and team composition. These belief estimates are combined with our solution for the fully observable case to compute an agent's optimal policy under partial observability in open ad hoc teamwork. Empirical results demonstrate that our approach can learn efficient policies in open ad hoc teamwork in full and partially observable cases. Further analysis demonstrates that our methods' success is a result of effectively learning the effects of teammates' actions while also inferring the inherent state of the environment under partial observability
Deep Reinforcement Learning for Multi-Agent Interaction
Aug 02, 2022The development of autonomous agents which can interact with other agents to accomplish a given task is a core area of research in artificial intelligence and machine learning. Towards this goal, the Autonomous Agents Research Group develops novel machine learning algorithms for autonomous systems control, with a specific focus on deep reinforcement learning and multi-agent reinforcement learning. Research problems include scalable learning of coordinated agent policies and inter-agent communication; reasoning about the behaviours, goals, and composition of other agents from limited observations; and sample-efficient learning based on intrinsic motivation, curriculum learning, causal inference, and representation learning. This article provides a broad overview of the ongoing research portfolio of the group and discusses open problems for future directions.
Towards Robust Ad Hoc Teamwork Agents By Creating Diverse Training Teammates
Jul 28, 2022



Ad hoc teamwork (AHT) is the problem of creating an agent that must collaborate with previously unseen teammates without prior coordination. Many existing AHT methods can be categorised as type-based methods, which require a set of predefined teammates for training. Designing teammate types for training is a challenging issue that determines the generalisation performance of agents when dealing with teammate types unseen during training. In this work, we propose a method to discover diverse teammate types based on maximising best response diversity metrics. We show that our proposed approach yields teammate types that require a wider range of best responses from the learner during collaboration, which potentially improves the robustness of a learner's performance in AHT compared to alternative methods.
Few-Shot Teamwork
Jul 19, 2022We propose the novel few-shot teamwork (FST) problem, where skilled agents trained in a team to complete one task are combined with skilled agents from different tasks, and together must learn to adapt to an unseen but related task. We discuss how the FST problem can be seen as addressing two separate problems: one of reducing the experience required to train a team of agents to complete a complex task; and one of collaborating with unfamiliar teammates to complete a new task. Progress towards solving FST could lead to progress in both multi-agent reinforcement learning and ad hoc teamwork.