 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Explicitly incorporating spatial information to recurrent networks for agriculture
Jun 27, 2022
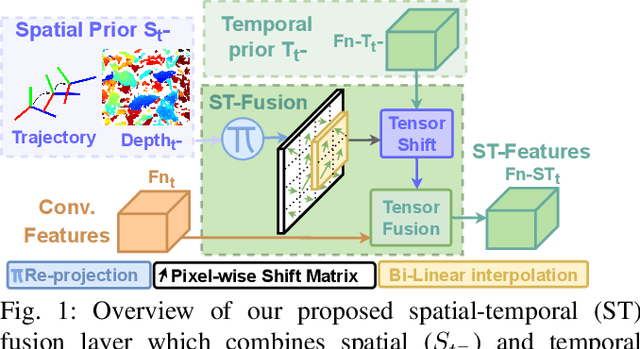
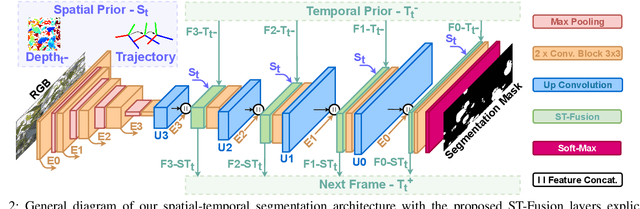
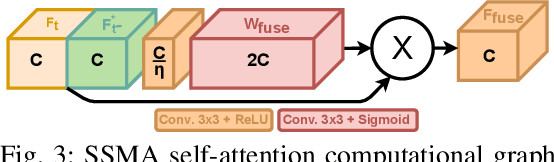

In agriculture, the majority of vision systems perform still image classification. Yet, recent work has highlighted the potential of spatial and temporal cues as a rich source of information to improve the classification performance. In this paper, we propose novel approaches to explicitly capture both spatial and temporal information to improve the classification of deep convolutional neural networks. We leverage available RGB-D images and robot odometry to perform inter-frame feature map spatial registration. This information is then fused within recurrent deep learnt models, to improve their accuracy and robustness. We demonstrate that this can considerably improve the classification performance with our best performing spatial-temporal model (ST-Atte) achieving absolute performance improvements for intersection-over-union (IoU[%]) of 4.7 for crop-weed segmentation and 2.6 for fruit (sweet pepper) segmentation. Furthermore, we show that these approaches are robust to variable framerates and odometry errors, which are frequently observed in real-world applications.
Dif-Fusion: Towards High Color Fidelity in Infrared and Visible Image Fusion with Diffusion Models
Jan 19, 2023


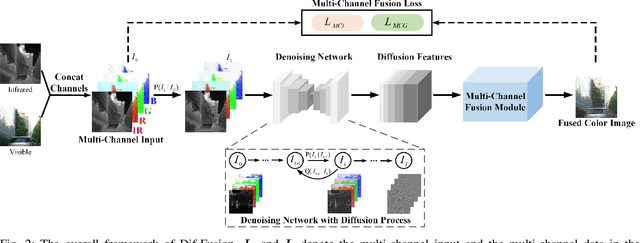
Color plays an important role in human visual perception, reflecting the spectrum of objects. However, the existing infrared and visible image fusion methods rarely explore how to handle multi-spectral/channel data directly and achieve high color fidelity. This paper addresses the above issue by proposing a novel method with diffusion models, termed as Dif-Fusion, to generate the distribution of the multi-channel input data, which increases the ability of multi-source information aggregation and the fidelity of colors. In specific, instead of converting multi-channel images into single-channel data in existing fusion methods, we create the multi-channel data distribution with a denoising network in a latent space with forward and reverse diffusion process. Then, we use the the denoising network to extract the multi-channel diffusion features with both visible and infrared information. Finally, we feed the multi-channel diffusion features to the multi-channel fusion module to directly generate the three-channel fused image. To retain the texture and intensity information, we propose multi-channel gradient loss and intensity loss. Along with the current evaluation metrics for measuring texture and intensity fidelity, we introduce a new evaluation metric to quantify color fidelity. Extensive experiments indicate that our method is more effective than other state-of-the-art image fusion methods, especially in color fidelity.
Adapting Step-size: A Unified Perspective to Analyze and Improve Gradient-based Methods for Adversarial Attacks
Jan 30, 2023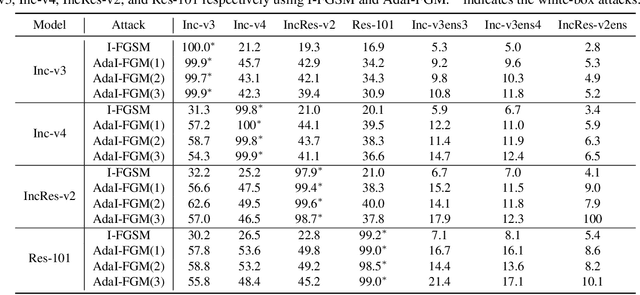
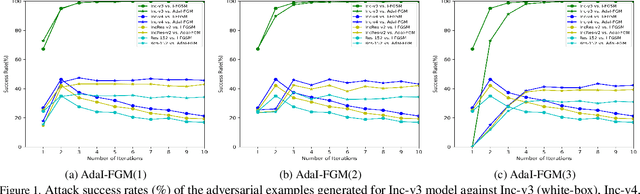
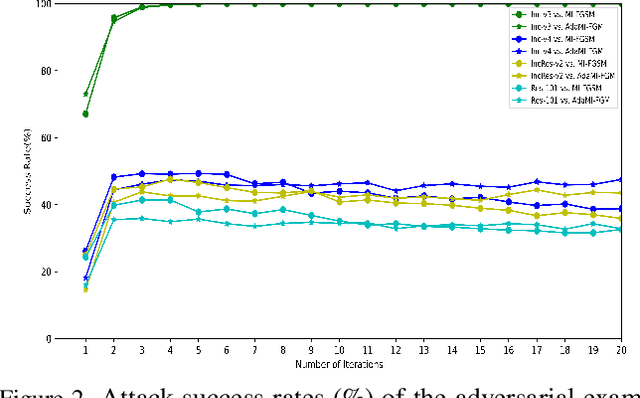

Learning adversarial examples can be formulated as an optimization problem of maximizing the loss function with some box-constraints. However, for solving this induced optimization problem, the state-of-the-art gradient-based methods such as FGSM, I-FGSM and MI-FGSM look different from their original methods especially in updating the direction, which makes it difficult to understand them and then leaves some theoretical issues to be addressed in viewpoint of optimization. In this paper, from the perspective of adapting step-size, we provide a unified theoretical interpretation of these gradient-based adversarial learning methods. We show that each of these algorithms is in fact a specific reformulation of their original gradient methods but using the step-size rules with only current gradient information. Motivated by such analysis, we present a broad class of adaptive gradient-based algorithms based on the regular gradient methods, in which the step-size strategy utilizing information of the accumulated gradients is integrated. Such adaptive step-size strategies directly normalize the scale of the gradients rather than use some empirical operations. The important benefit is that convergence for the iterative algorithms is guaranteed and then the whole optimization process can be stabilized. The experiments demonstrate that our AdaI-FGM consistently outperforms I-FGSM and AdaMI-FGM remains competitive with MI-FGSM for black-box attacks.
MSDC: Exploiting Multi-State Power Consumption in Non-intrusive Load Monitoring based on A Dual-CNN Model
Feb 11, 2023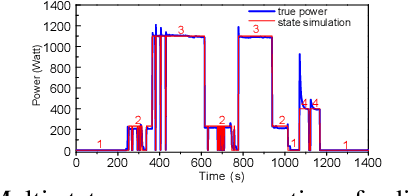
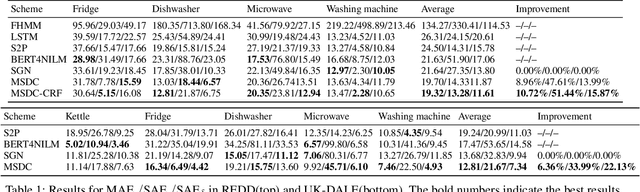
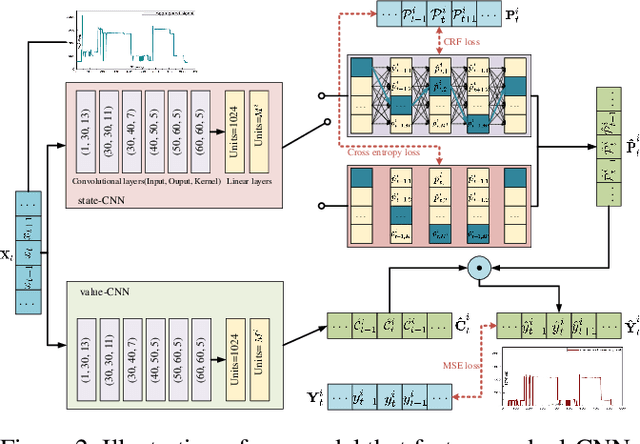
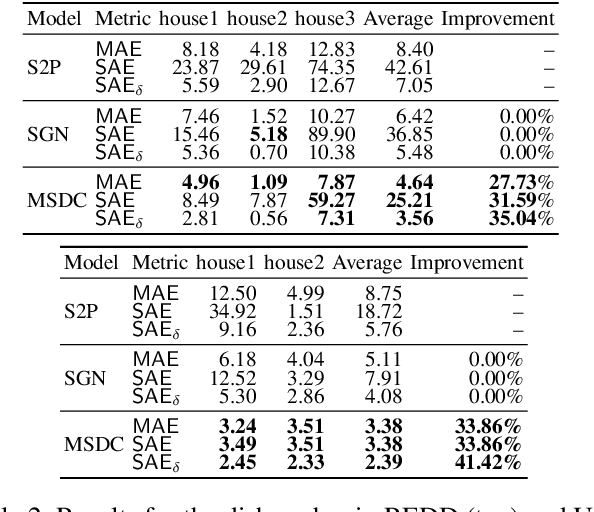
Non-intrusive load monitoring (NILM) aims to decompose aggregated electrical usage signal into appliance-specific power consumption and it amounts to a classical example of blind source separation tasks. Leveraging recent progress on deep learning techniques, we design a new neural NILM model Multi-State Dual CNN (MSDC). Different from previous models, MSDC explicitly extracts information about the appliance's multiple states and state transitions, which in turn regulates the prediction of signals for appliances. More specifically, we employ a dual-CNN architecture: one CNN for outputting state distributions and the other for predicting the power of each state. A new technique is invented that utilizes conditional random fields (CRF) to capture state transitions. Experiments on two real-world datasets REDD and UK-DALE demonstrate that our model significantly outperform state-of-the-art models while having good generalization capacity, achieving 6%-10% MAE gain and 33%-51% SAE gain to unseen appliances.
${S}^{2}$Net: Accurate Panorama Depth Estimation on Spherical Surface
Jan 14, 2023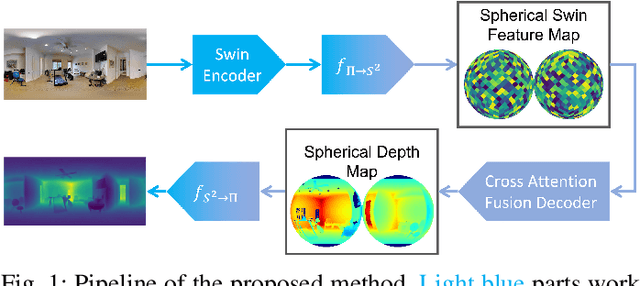

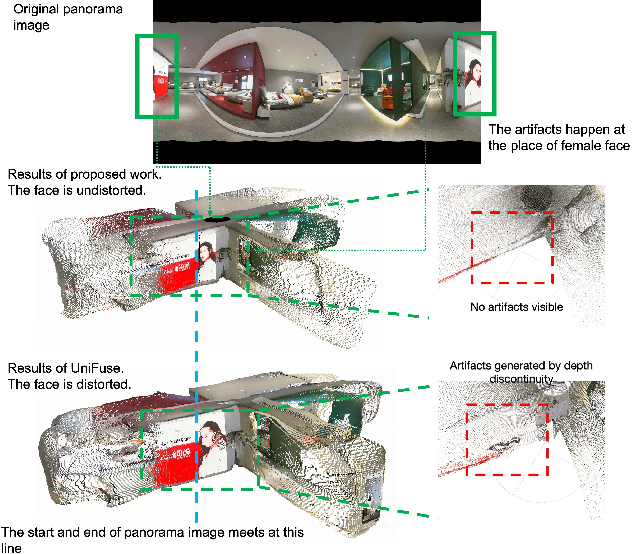
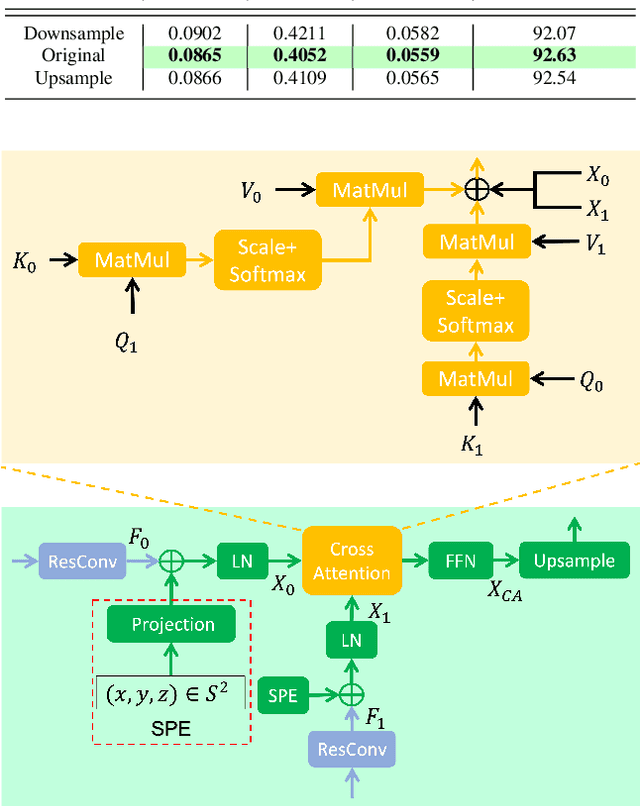
Monocular depth estimation is an ambiguous problem, thus global structural cues play an important role in current data-driven single-view depth estimation methods. Panorama images capture the complete spatial information of their surroundings utilizing the equirectangular projection which introduces large distortion. This requires the depth estimation method to be able to handle the distortion and extract global context information from the image. In this paper, we propose an end-to-end deep network for monocular panorama depth estimation on a unit spherical surface. Specifically, we project the feature maps extracted from equirectangular images onto unit spherical surface sampled by uniformly distributed grids, where the decoder network can aggregate the information from the distortion-reduced feature maps. Meanwhile, we propose a global cross-attention-based fusion module to fuse the feature maps from skip connection and enhance the ability to obtain global context. Experiments are conducted on five panorama depth estimation datasets, and the results demonstrate that the proposed method substantially outperforms previous state-of-the-art methods. All related codes will be open-sourced in the upcoming days.
Explicit3D: Graph Network with Spatial Inference \\for Single Image 3D Object Detection
Feb 13, 2023
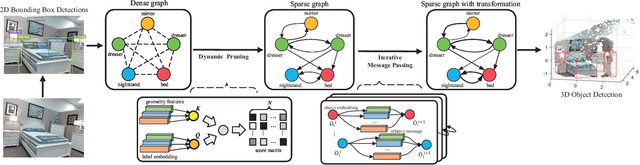
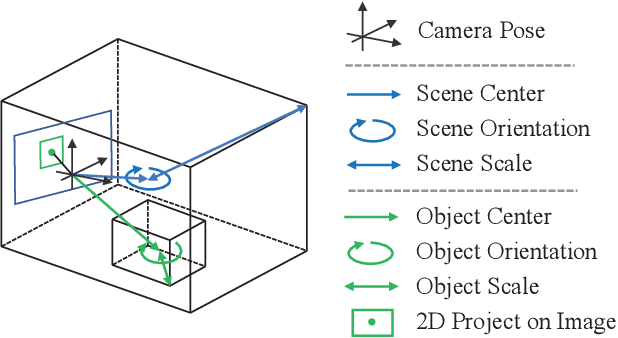
Indoor 3D object detection is an essential task in single image scene understanding, impacting spatial cognition fundamentally in visual reasoning. Existing works on 3D object detection from a single image either pursue this goal through independent predictions of each object or implicitly reason over all possible objects, failing to harness relational geometric information between objects. To address this problem, we propose a dynamic sparse graph pipeline named Explicit3D based on object geometry and semantics features. Taking the efficiency into consideration, we further define a relatedness score and design a novel dynamic pruning algorithm followed by a cluster sampling method for sparse scene graph generation and updating. Furthermore, our Explicit3D introduces homogeneous matrices and defines new relative loss and corner loss to model the spatial difference between target pairs explicitly. Instead of using ground-truth labels as direct supervision, our relative and corner loss are derived from the homogeneous transformation, which renders the model to learn the geometric consistency between objects. The experimental results on the SUN RGB-D dataset demonstrate that our Explicit3D achieves better performance balance than the-state-of-the-art.
Enhancing Multivariate Time Series Classifiers through Self-Attention and Relative Positioning Infusion
Feb 13, 2023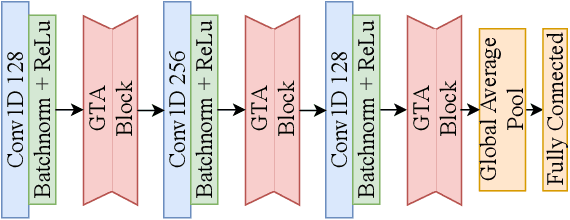
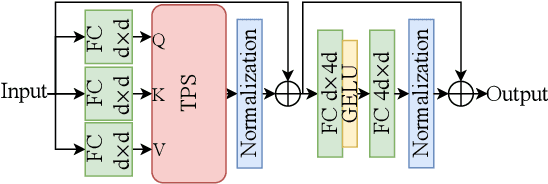
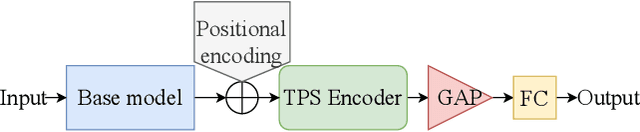
Time Series Classification (TSC) is an important and challenging task for many visual computing applications. Despite the extensive range of methods developed for TSC, relatively few utilized Deep Neural Networks (DNNs). In this paper, we propose two novel attention blocks (Global Temporal Attention and Temporal Pseudo-Gaussian augmented Self-Attention) that can enhance deep learning-based TSC approaches, even when such approaches are designed and optimized for a specific dataset or task. We validate this claim by evaluating multiple state-of-the-art deep learning-based TSC models on the University of East Anglia (UEA) benchmark, a standardized collection of 30 Multivariate Time Series Classification (MTSC) datasets. We show that adding the proposed attention blocks improves base models' average accuracy by up to 3.6%. Additionally, the proposed TPS block uses a new injection module to include the relative positional information in transformers. As a standalone unit with less computational complexity, it enables TPS to perform better than most of the state-of-the-art DNN-based TSC methods. The source codes for our experimental setups and proposed attention blocks are made publicly available.
Towards Writing Style Adaptation in Handwriting Recognition
Feb 13, 2023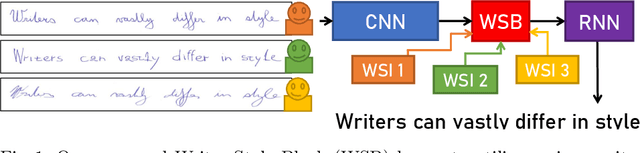
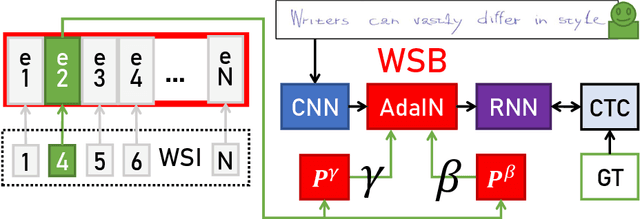

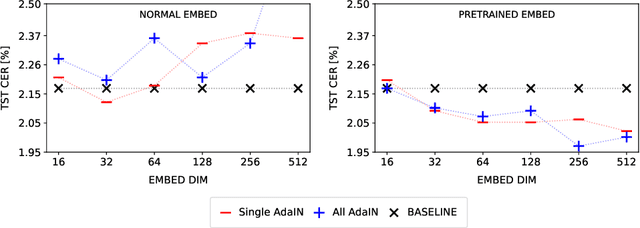
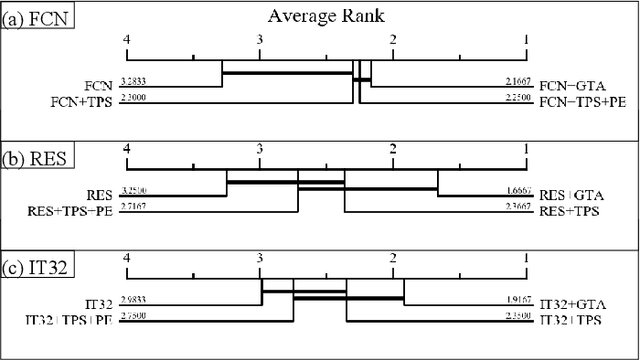
One of the challenges of handwriting recognition is to transcribe a large number of vastly different writing styles. State-of-the-art approaches do not explicitly use information about the writer's style, which may be limiting overall accuracy due to various ambiguities. We explore models with writer-dependent parameters which take the writer's identity as an additional input. The proposed models can be trained on datasets with partitions likely written by a single author (e.g. single letter, diary, or chronicle). We propose a Writer Style Block (WSB), an adaptive instance normalization layer conditioned on learned embeddings of the partitions. We experimented with various placements and settings of WSB and contrastively pre-trained embeddings. We show that our approach outperforms a baseline with no WSB in a writer-dependent scenario and that it is possible to estimate embeddings for new writers. However, domain adaptation using simple finetuning in a writer-independent setting provides superior accuracy at a similar computational cost. The proposed approach should be further investigated in terms of training stability and embedding regularization to overcome such a baseline.
Fourier-RNNs for Modelling Noisy Physics Data
Feb 13, 2023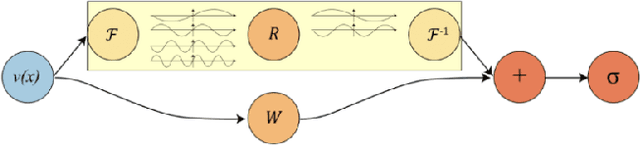
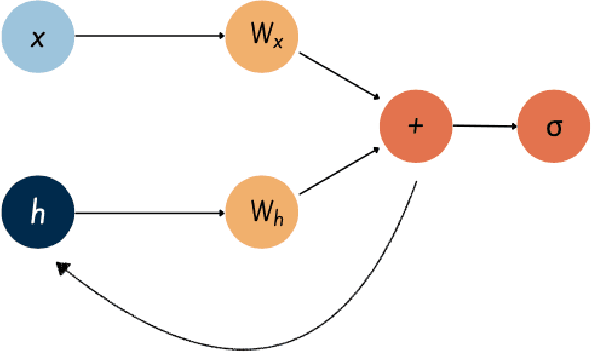
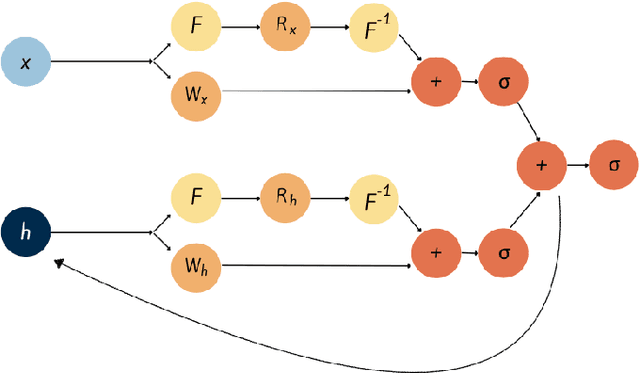
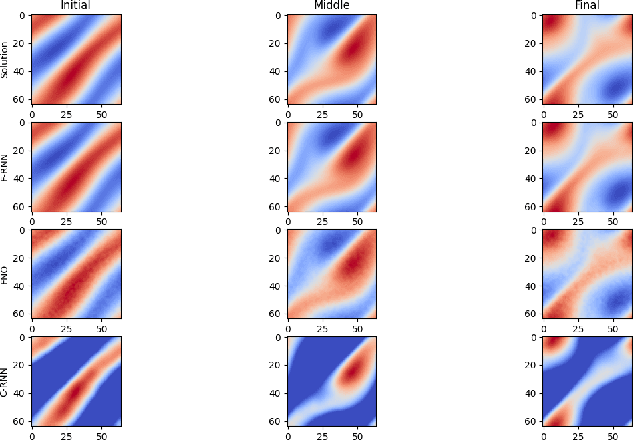
Classical sequential models employed in time-series prediction rely on learning the mappings from the past to the future instances by way of a hidden state. The Hidden states characterise the historical information and encode the required temporal dependencies. However, most existing sequential models operate within finite-dimensional Euclidean spaces which offer limited functionality when employed in modelling physics relevant data. Alternatively recent work with neural operator learning within the Fourier space has shown efficient strategies for parameterising Partial Differential Equations (PDE). In this work, we propose a novel sequential model, built to handle Physics relevant data by way of amalgamating the conventional RNN architecture with that of the Fourier Neural Operators (FNO). The Fourier-RNN allows for learning the mappings from the input to the output as well as to the hidden state within the Fourier space associated with the temporal data. While the Fourier-RNN performs identical to the FNO when handling PDE data, it outperforms the FNO and the conventional RNN when deployed in modelling noisy, non-Markovian data.
A Novel Poisoned Water Detection Method Using Smartphone Embedded Wi-Fi Technology and Machine Learning Algorithms
Feb 13, 2023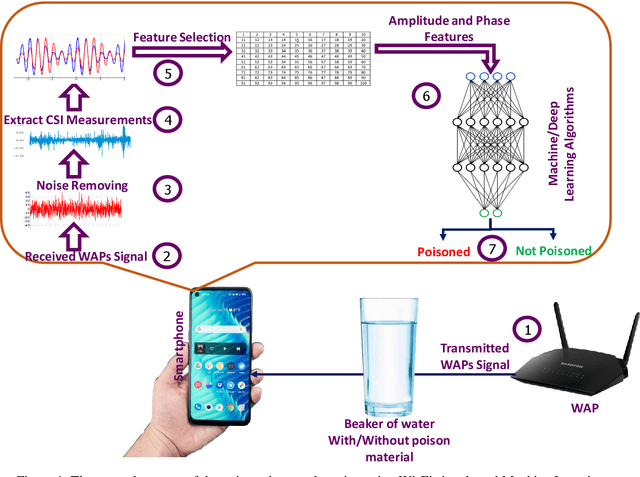


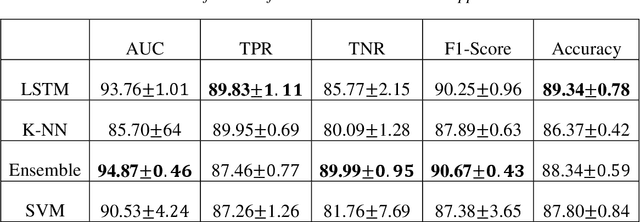
Water is a necessary fluid to the human body and automatic checking of its quality and cleanness is an ongoing area of research. One such approach is to present the liquid to various types of signals and make the amount of signal attenuation an indication of the liquid category. In this article, we have utilized the Wi-Fi signal to distinguish clean water from poisoned water via training different machine learning algorithms. The Wi-Fi access points (WAPs) signal is acquired via equivalent smartphone-embedded Wi-Fi chipsets, and then Channel-State-Information CSI measures are extracted and converted into feature vectors to be used as input for machine learning classification algorithms. The measured amplitude and phase of the CSI data are selected as input features into four classifiers k-NN, SVM, LSTM, and Ensemble. The experimental results show that the model is adequate to differentiate poison water from clean water with a classification accuracy of 89% when LSTM is applied, while 92% classification accuracy is achieved when the AdaBoost-Ensemble classifier is applied.