 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Role of Semantic Parsing in Understanding Procedural Text
Feb 14, 2023

In this paper, we investigate whether symbolic semantic representations, extracted from deep semantic parsers, can help reasoning over the states of involved entities in a procedural text. We consider a deep semantic parser~(TRIPS) and semantic role labeling as two sources of semantic parsing knowledge. First, we propose PROPOLIS, a symbolic parsing-based procedural reasoning framework. Second, we integrate semantic parsing information into state-of-the-art neural models to conduct procedural reasoning. Our experiments indicate that explicitly incorporating such semantic knowledge improves procedural understanding. This paper presents new metrics for evaluating procedural reasoning tasks that clarify the challenges and identify differences among neural, symbolic, and integrated models.
Active learning for structural reliability analysis with multiple limit state functions through variance-enhanced PC-Kriging surrogate models
Feb 23, 2023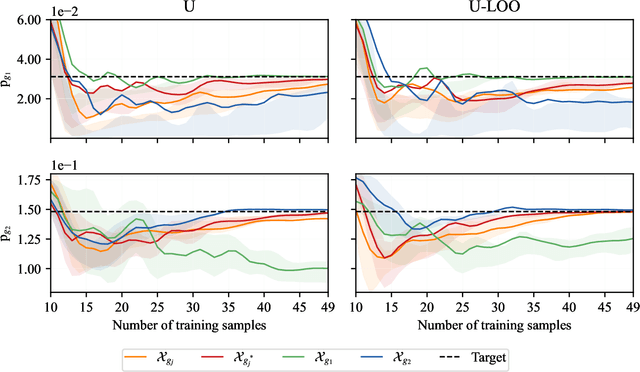

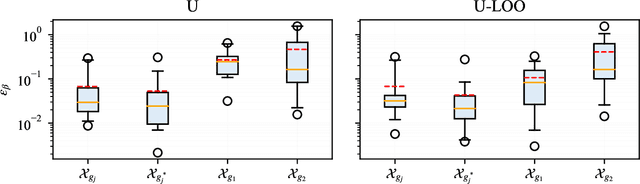
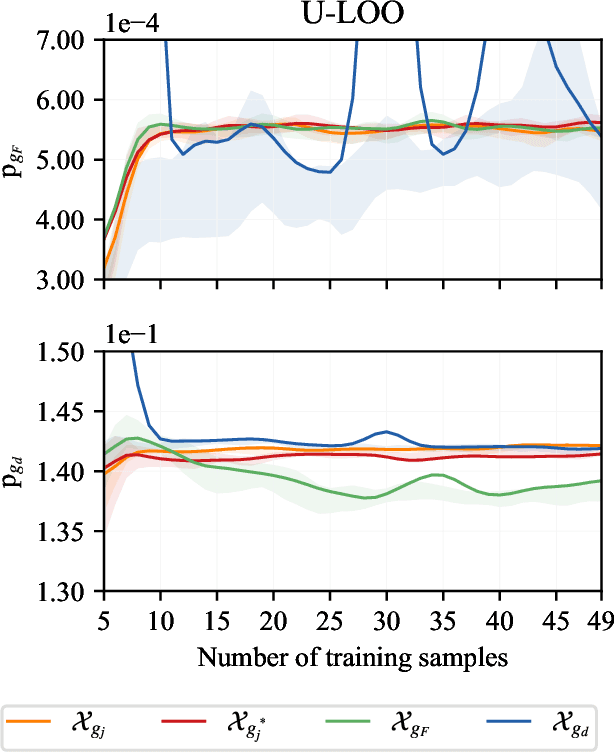
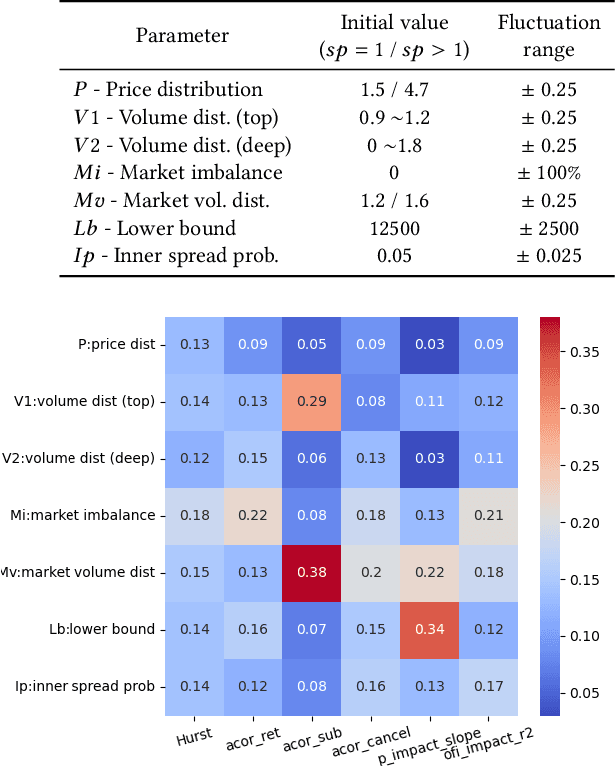
Existing active strategies for training surrogate models yield accurate structural reliability estimates by aiming at design space regions in the vicinity of a specified limit state function. In many practical engineering applications, various damage conditions, e.g. repair, failure, should be probabilistically characterized, thus demanding the estimation of multiple performance functions. In this work, we investigate the capability of active learning approaches for efficiently selecting training samples under a limited computational budget while still preserving the accuracy associated with multiple surrogated limit states. Specifically, PC-Kriging-based surrogate models are actively trained considering a variance correction derived from leave-one-out cross-validation error information, whereas the sequential learning scheme relies on U-function-derived metrics. The proposed active learning approaches are tested in a highly nonlinear structural reliability setting, whereas in a more practical application, failure and repair events are stochastically predicted in the aftermath of a ship collision against an offshore wind substructure. The results show that a balanced computational budget administration can be effectively achieved by successively targeting the specified multiple limit state functions within a unified active learning scheme.
Amos-SLAM: An Anti-Dynamics Two-stage SLAM Approach
Feb 23, 2023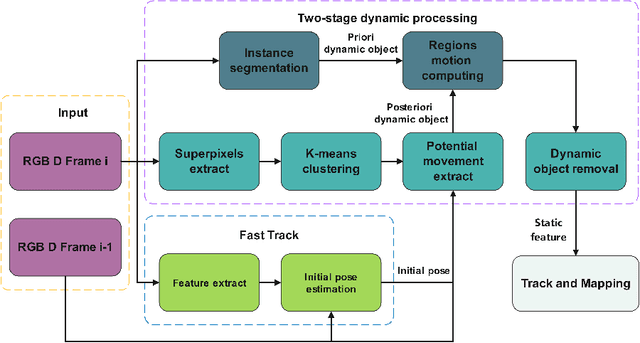

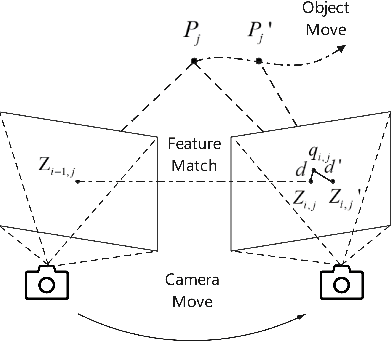

The traditional Simultaneous Localization And Mapping (SLAM) systems rely on the assumption of a static environment and fail to accurately estimate the system's location when dynamic objects are present in the background. While learning-based dynamic SLAM systems have difficulties in handling unknown moving objects, geometry-based methods have limited success in addressing the residual effects of unidentified dynamic objects on location estimation. To address these issues, we propose an anti-dynamics two-stage SLAM approach. Firstly, the potential motion regions of both prior and non-prior dynamic objects are extracted and pose estimates for dynamic discrimination are quickly obtained using optical flow tracking and model generation methods. Secondly, dynamic points in each frame are removed through dynamic judgment. For non-prior dynamic objects, we present a approach that uses super-pixel extraction and geometric clustering to determine the potential motion regions based on color and geometric information in the image. Evaluations on multiple low and high dynamic sequences in a public RGB-D dataset show that our proposed method outperforms state-of-the-art dynamic SLAM methods.
A Gradient Boosting Approach for Training Convolutional and Deep Neural Networks
Feb 23, 2023
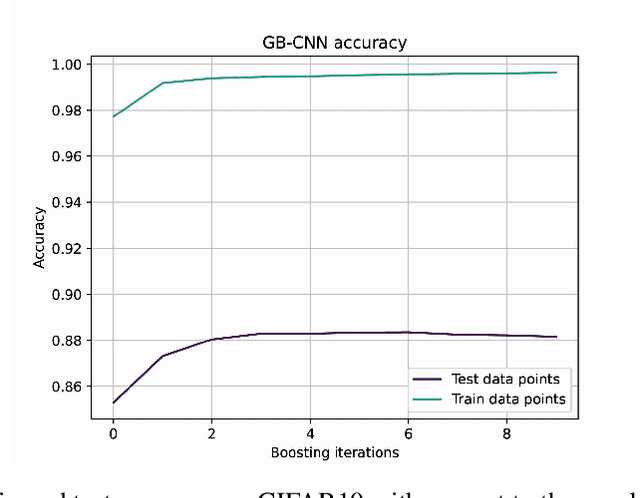
Deep learning has revolutionized the computer vision and image classification domains. In this context Convolutional Neural Networks (CNNs) based architectures are the most widely applied models. In this article, we introduced two procedures for training Convolutional Neural Networks (CNNs) and Deep Neural Network based on Gradient Boosting (GB), namely GB-CNN and GB-DNN. These models are trained to fit the gradient of the loss function or pseudo-residuals of previous models. At each iteration, the proposed method adds one dense layer to an exact copy of the previous deep NN model. The weights of the dense layers trained on previous iterations are frozen to prevent over-fitting, permitting the model to fit the new dense as well as to fine-tune the convolutional layers (for GB-CNN) while still utilizing the information already learned. Through extensive experimentation on different 2D-image classification and tabular datasets, the presented models show superior performance in terms of classification accuracy with respect to standard CNN and Deep-NN with the same architectures.
Dealing with Collinearity in Large-Scale Linear System Identification Using Gaussian Regression
Feb 28, 2023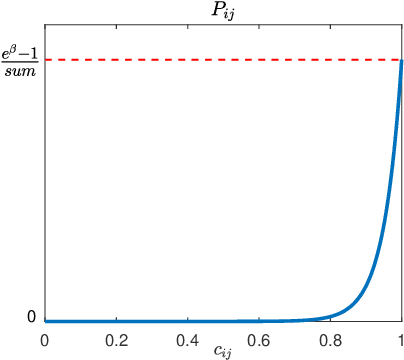
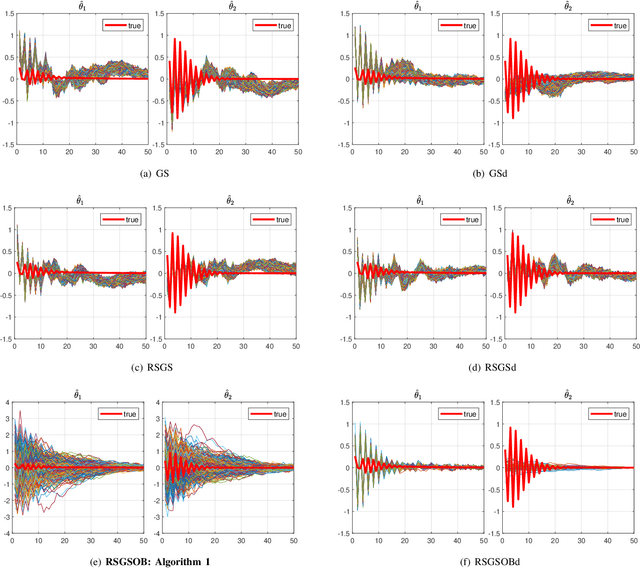
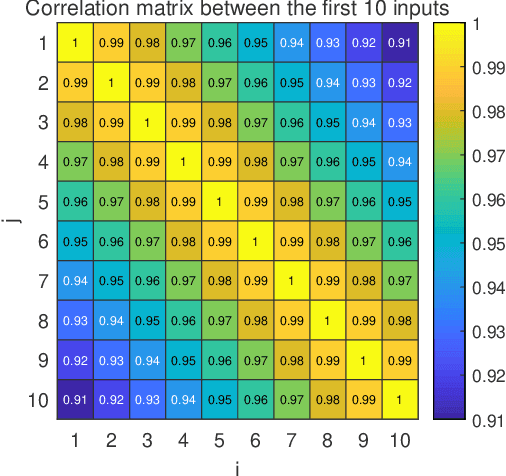
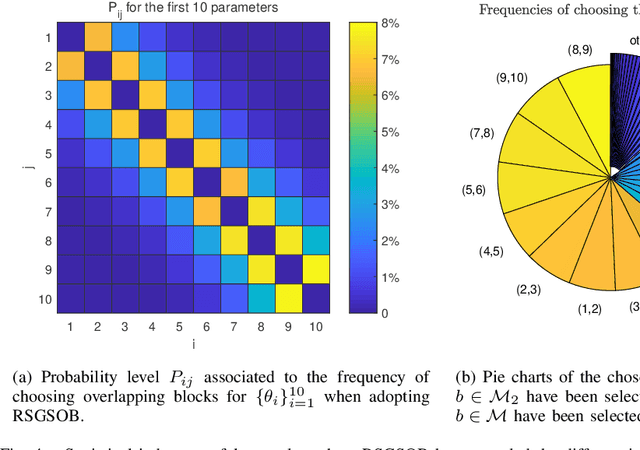
Many problems arising in control require the determination of a mathematical model of the application. This has often to be performed starting from input-output data, leading to a task known as system identification in the engineering literature. One emerging topic in this field is estimation of networks consisting of several interconnected dynamic systems. We consider the linear setting assuming that system outputs are the result of many correlated inputs, hence making system identification severely ill-conditioned. This is a scenario often encountered when modeling complex cybernetics systems composed by many sub-units with feedback and algebraic loops. We develop a strategy cast in a Bayesian regularization framework where any impulse response is seen as realization of a zero-mean Gaussian process. Any covariance is defined by the so called stable spline kernel which includes information on smooth exponential decay. We design a novel Markov chain Monte Carlo scheme able to reconstruct the impulse responses posterior by efficiently dealing with collinearity. Our scheme relies on a variation of the Gibbs sampling technique: beyond considering blocks forming a partition of the parameter space, some other (overlapping) blocks are also updated on the basis of the level of collinearity of the system inputs. Theoretical properties of the algorithm are studied obtaining its convergence rate. Numerical experiments are included using systems containing hundreds of impulse responses and highly correlated inputs.
Active Velocity Estimation using Light Curtains via Self-Supervised Multi-Armed Bandits
Feb 28, 2023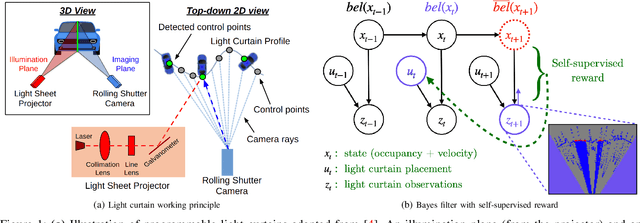
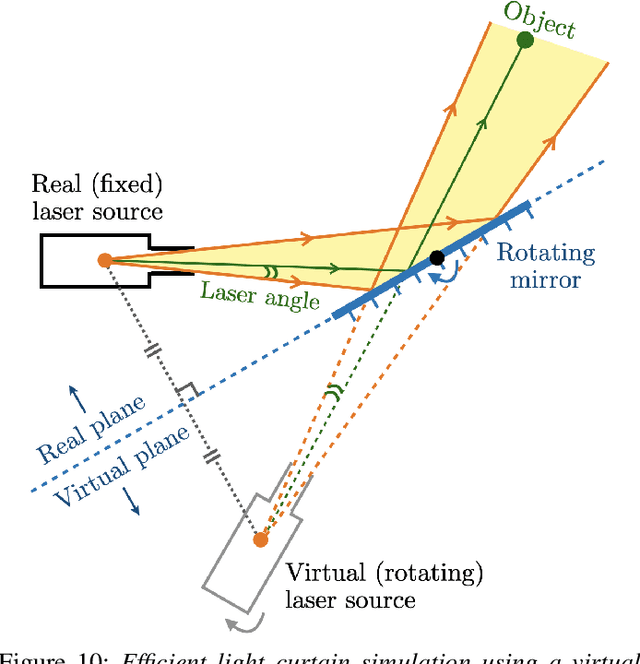

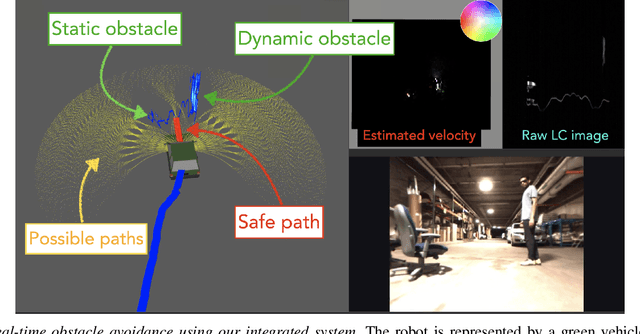
To navigate in an environment safely and autonomously, robots must accurately estimate where obstacles are and how they move. Instead of using expensive traditional 3D sensors, we explore the use of a much cheaper, faster, and higher resolution alternative: programmable light curtains. Light curtains are a controllable depth sensor that sense only along a surface that the user selects. We adapt a probabilistic method based on particle filters and occupancy grids to explicitly estimate the position and velocity of 3D points in the scene using partial measurements made by light curtains. The central challenge is to decide where to place the light curtain to accurately perform this task. We propose multiple curtain placement strategies guided by maximizing information gain and verifying predicted object locations. Then, we combine these strategies using an online learning framework. We propose a novel self-supervised reward function that evaluates the accuracy of current velocity estimates using future light curtain placements. We use a multi-armed bandit framework to intelligently switch between placement policies in real time, outperforming fixed policies. We develop a full-stack navigation system that uses position and velocity estimates from light curtains for downstream tasks such as localization, mapping, path-planning, and obstacle avoidance. This work paves the way for controllable light curtains to accurately, efficiently, and purposefully perceive and navigate complex and dynamic environments. Project website: https://siddancha.github.io/projects/active-velocity-estimation/
Neural Stochastic Agent-Based Limit Order Book Simulation: A Hybrid Methodology
Feb 28, 2023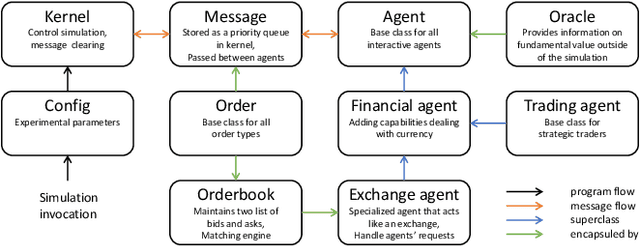
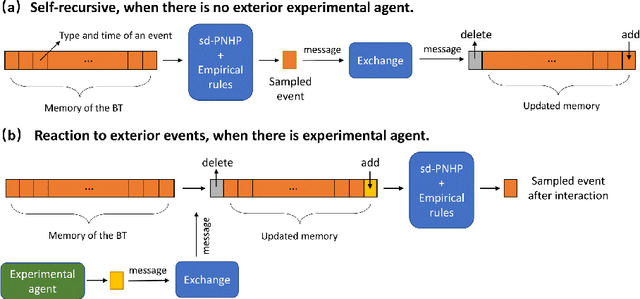

Modern financial exchanges use an electronic limit order book (LOB) to store bid and ask orders for a specific financial asset. As the most fine-grained information depicting the demand and supply of an asset, LOB data is essential in understanding market dynamics. Therefore, realistic LOB simulations offer a valuable methodology for explaining empirical properties of markets. Mainstream simulation models include agent-based models (ABMs) and stochastic models (SMs). However, ABMs tend not to be grounded on real historical data, while SMs tend not to enable dynamic agent-interaction. To overcome these limitations, we propose a novel hybrid LOB simulation paradigm characterised by: (1) representing the aggregation of market events' logic by a neural stochastic background trader that is pre-trained on historical LOB data through a neural point process model; and (2) embedding the background trader in a multi-agent simulation with other trading agents. We instantiate this hybrid NS-ABM model using the ABIDES platform. We first run the background trader in isolation and show that the simulated LOB can recreate a comprehensive list of stylised facts that demonstrate realistic market behaviour. We then introduce a population of `trend' and `value' trading agents, which interact with the background trader. We show that the stylised facts remain and we demonstrate order flow impact and financial herding behaviours that are in accordance with empirical observations of real markets.
Learned Risk Metric Maps for Kinodynamic Systems
Feb 28, 2023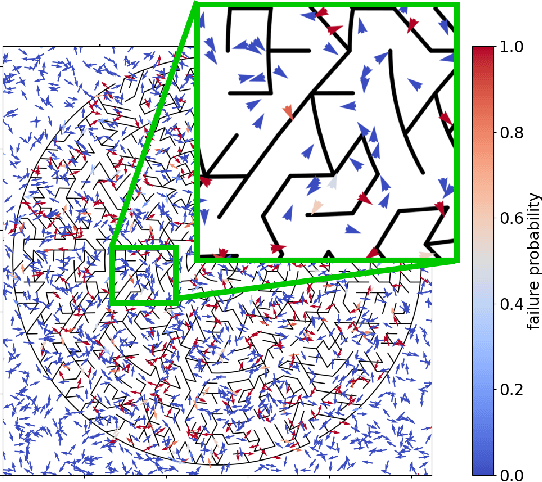

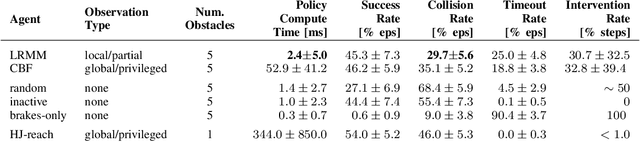
We present Learned Risk Metric Maps (LRMM) for real-time estimation of coherent risk metrics of high dimensional dynamical systems operating in unstructured, partially observed environments. LRMM models are simple to design and train -- requiring only procedural generation of obstacle sets, state and control sampling, and supervised training of a function approximator -- which makes them broadly applicable to arbitrary system dynamics and obstacle sets. In a parallel autonomy setting, we demonstrate the model's ability to rapidly infer collision probabilities of a fast-moving car-like robot driving recklessly in an obstructed environment; allowing the LRMM agent to intervene, take control of the vehicle, and avoid collisions. In this time-critical scenario, we show that LRMMs can evaluate risk metrics 20-100x times faster than alternative safety algorithms based on control barrier functions (CBFs) and Hamilton-Jacobi reachability (HJ-reach), leading to 5-15\% fewer obstacle collisions by the LRMM agent than CBFs and HJ-reach. This performance improvement comes in spite of the fact that the LRMM model only has access to local/partial observation of obstacles, whereas the CBF and HJ-reach agents are granted privileged/global information. We also show that our model can be equally well trained on a 12-dimensional quadrotor system operating in an obstructed indoor environment. The LRMM codebase is provided at https://github.com/mit-drl/pyrmm.
DFR-FastMOT: Detection Failure Resistant Tracker for Fast Multi-Object Tracking Based on Sensor Fusion
Feb 28, 2023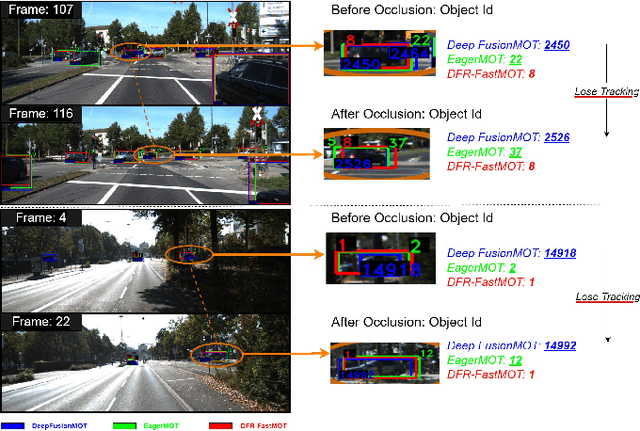
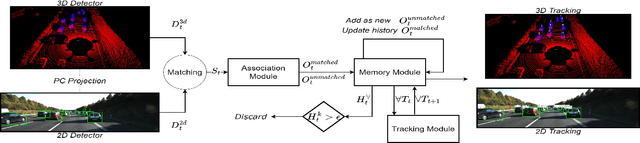

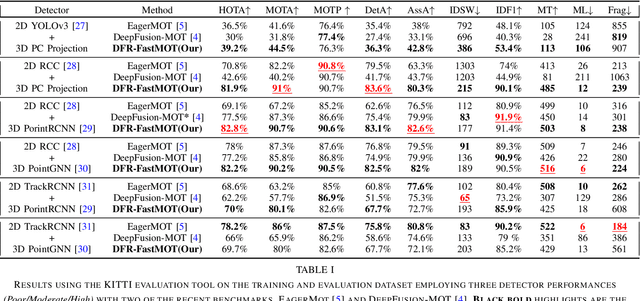
Persistent multi-object tracking (MOT) allows autonomous vehicles to navigate safely in highly dynamic environments. One of the well-known challenges in MOT is object occlusion when an object becomes unobservant for subsequent frames. The current MOT methods store objects information, like objects' trajectory, in internal memory to recover the objects after occlusions. However, they retain short-term memory to save computational time and avoid slowing down the MOT method. As a result, they lose track of objects in some occlusion scenarios, particularly long ones. In this paper, we propose DFR-FastMOT, a light MOT method that uses data from a camera and LiDAR sensors and relies on an algebraic formulation for object association and fusion. The formulation boosts the computational time and permits long-term memory that tackles more occlusion scenarios. Our method shows outstanding tracking performance over recent learning and non-learning benchmarks with about 3% and 4% margin in MOTA, respectively. Also, we conduct extensive experiments that simulate occlusion phenomena by employing detectors with various distortion levels. The proposed solution enables superior performance under various distortion levels in detection over current state-of-art methods. Our framework processes about 7,763 frames in 1.48 seconds, which is seven times faster than recent benchmarks. The framework will be available at https://github.com/MohamedNagyMostafa/DFR-FastMOT.
Safe-DS: A Domain Specific Language to Make Data Science Safe
Feb 28, 2023
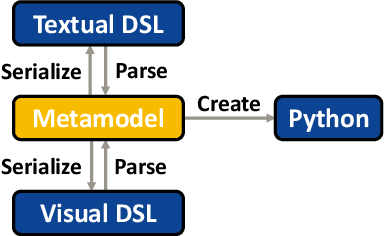
Due to the long runtime of Data Science (DS) pipelines, even small programming mistakes can be very costly, if they are not detected statically. However, even basic static type checking of DS pipelines is difficult because most are written in Python. Static typing is available in Python only via external linters. These require static type annotations for parameters or results of functions, which many DS libraries do not provide. In this paper, we show how the wealth of Python DS libraries can be used in a statically safe way via Safe-DS, a domain specific language (DSL) for DS. Safe-DS catches conventional type errors plus errors related to range restrictions, data manipulation, and call order of functions, going well beyond the abilities of current Python linters. Python libraries are integrated into Safe-DS via a stub language for specifying the interface of its declarations, and an API-Editor that is able to extract type information from the code and documentation of Python libraries, and automatically generate suitable stubs. Moreover, Safe-DS complements textual DS pipelines with a graphical representation that eases safe development by preventing syntax errors. The seamless synchronization of textual and graphic view lets developers always choose the one best suited for their skills and current task. We think that Safe-DS can make DS development easier, faster, and more reliable, significantly reducing development costs.