 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Boosting Differentiable Causal Discovery via Adaptive Sample Reweighting
Mar 06, 2023
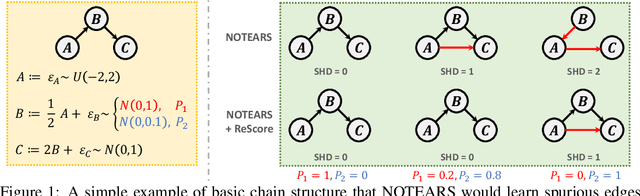
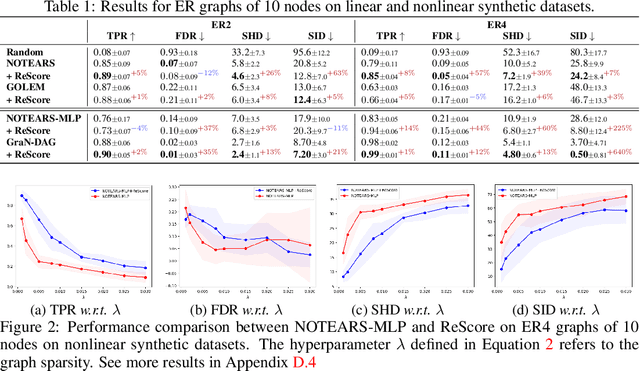
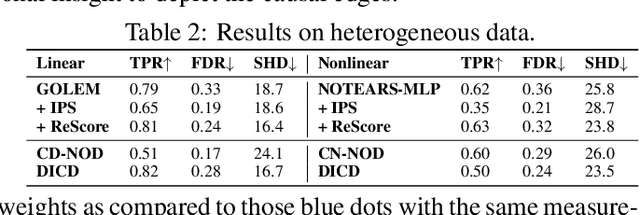
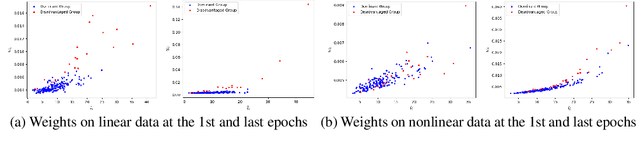
Under stringent model type and variable distribution assumptions, differentiable score-based causal discovery methods learn a directed acyclic graph (DAG) from observational data by evaluating candidate graphs over an average score function. Despite great success in low-dimensional linear systems, it has been observed that these approaches overly exploit easier-to-fit samples, thus inevitably learning spurious edges. Worse still, inherent mostly in these methods the common homogeneity assumption can be easily violated, due to the widespread existence of heterogeneous data in the real world, resulting in performance vulnerability when noise distributions vary. We propose a simple yet effective model-agnostic framework to boost causal discovery performance by dynamically learning the adaptive weights for the Reweighted Score function, ReScore for short, where the weights tailor quantitatively to the importance degree of each sample. Intuitively, we leverage the bilevel optimization scheme to \wx{alternately train a standard DAG learner and reweight samples -- that is, upweight the samples the learner fails to fit and downweight the samples that the learner easily extracts the spurious information from. Extensive experiments on both synthetic and real-world datasets are carried out to validate the effectiveness of ReScore. We observe consistent and significant boosts in structure learning performance. Furthermore, we visualize that ReScore concurrently mitigates the influence of spurious edges and generalizes to heterogeneous data. Finally, we perform the theoretical analysis to guarantee the structure identifiability and the weight adaptive properties of ReScore in linear systems. Our codes are available at https://github.com/anzhang314/ReScore.
CTG-Net: An Efficient Cascaded Framework Driven by Terminal Guidance Mechanism for Dilated Pancreatic Duct Segmentation
Mar 06, 2023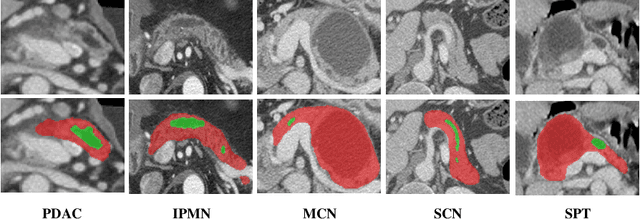

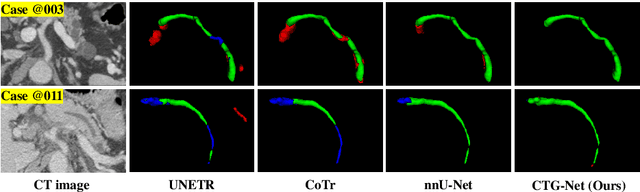
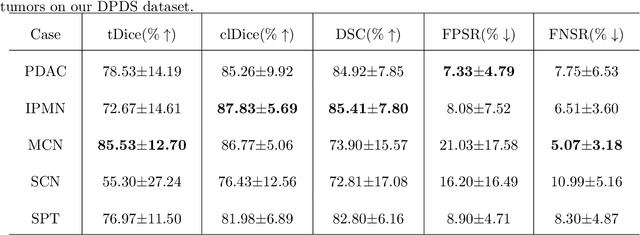
Pancreatic duct dilation indicates a high risk of various pancreatic diseases. Segmentation of dilated pancreatic ducts on computed tomography (CT) images shows the potential to assist the early diagnosis, surgical planning and prognosis. Because of the ducts' tiny sizes, slender tubular structures and the surrounding distractions, most current researches on pancreatic duct segmentation achieve low accuracy and always have segmentation errors on the terminal parts of the ducts. To address these problems, we propose a terminal guidance mechanism called cascaded terminal guidance network (CTG-Net). Firstly, a terminal attention mechanism is established on the skeletons extracted from the coarse predictions. Then, to get fine terminal segmentation, a subnetwork is designed for jointly learning the local intensity from the original images, feature cues from coarse predictions and global anatomy information from the pancreas distance transform maps. Finally, a terminal distraction attention module which explicitly learns the distribution of the terminal distraction is proposed to reduce the false positive and false negative predictions. We also propose a new metric called tDice to measure the terminal segmentation accuracy for targets with tubular structures and two segmentation metrics for distractions. We collect our dilated pancreatic duct segmentation dataset with 150 CT scans from patients with 5 types of pancreatic tumors. Experimental results on our dataset show that our proposed approach boosts dilated pancreatic duct segmentation accuracy by nearly 20% compared with the existing results, and achieves more than 9% improvement for the terminal segmentation accuracy compared with the state-of-the-art methods.
Dual Feedback Attention Framework via Boundary-Aware Auxiliary and Progressive Semantic Optimization for Salient Object Detection in Optical Remote Sensing Imagery
Mar 06, 2023
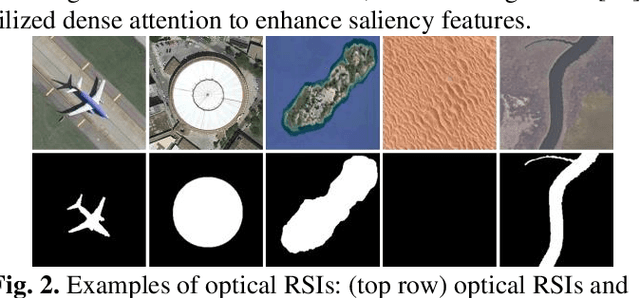
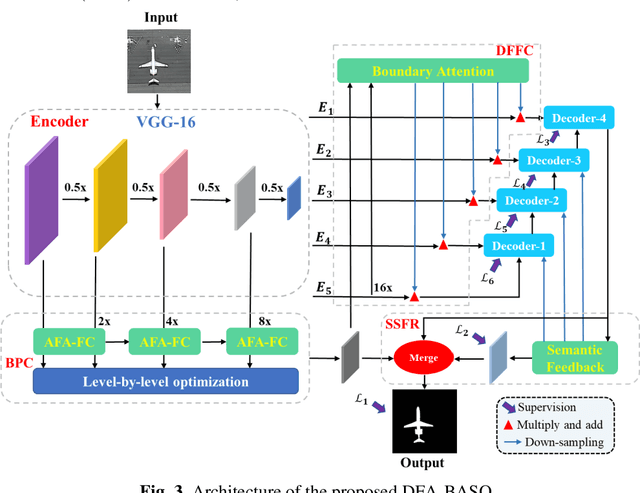
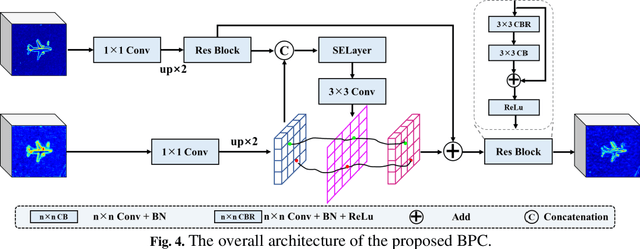
Salient object detection in optical remote sensing image (ORSI-SOD) has gradually attracted attention thanks to the development of deep learning (DL) and salient object detection in natural scene image (NSI-SOD). However, NSI and ORSI are different in many aspects, such as large coverage, complex background, and large differences in target types and scales. Therefore, a new dedicated method is needed for ORSI-SOD. In addition, existing methods do not pay sufficient attention to the boundary of the object, and the completeness of the final saliency map still needs improvement. To address these issues, we propose a novel method called Dual Feedback Attention Framework via Boundary-Aware Auxiliary and Progressive Semantic Optimization (DFA-BASO). First, Boundary Protection Calibration (BPC) module is proposed to reduce the loss of edge position information during forward propagation and suppress noise in low-level features. Second, a Dual Feature Feedback Complementary (DFFC) module is proposed based on BPC module. It aggregates boundary-semantic dual features and provides effective feedback to coordinate features across different layers. Finally, a Strong Semantic Feedback Refinement (SSFR) module is proposed to obtain more complete saliency maps. This module further refines feature representation and eliminates feature differences through a unique feedback mechanism. Extensive experiments on two public datasets show that DFA-BASO outperforms 15 state-of-the-art methods. Furthermore, this paper strongly demonstrates the true contribution of DFA-BASO to ORSI-SOD by in-depth analysis of the visualization figure. All codes can be found at https://github.com/YUHsss/DFA-BASO.
Pyramid Self-attention Polymerization Learning for Semi-supervised Skeleton-based Action Recognition
Feb 05, 2023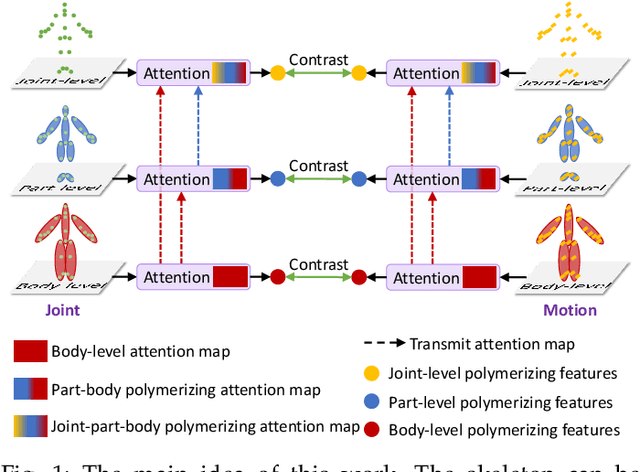

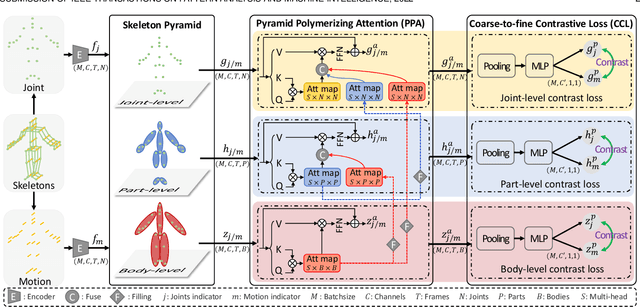
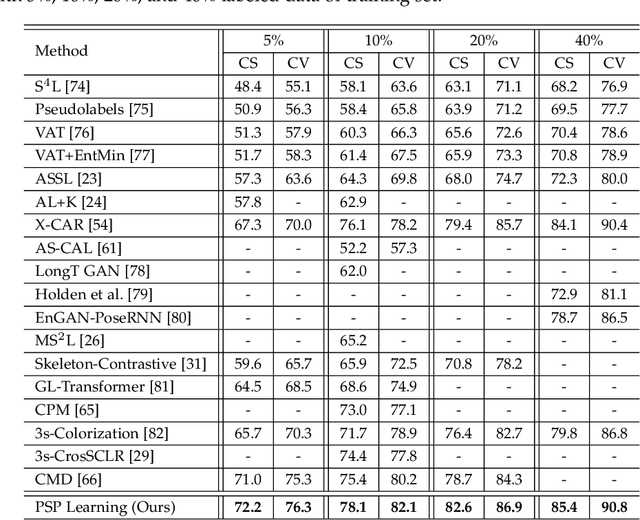
Most semi-supervised skeleton-based action recognition approaches aim to learn the skeleton action representations only at the joint level, but neglect the crucial motion characteristics at the coarser-grained body (e.g., limb, trunk) level that provide rich additional semantic information, though the number of labeled data is limited. In this work, we propose a novel Pyramid Self-attention Polymerization Learning (dubbed as PSP Learning) framework to jointly learn body-level, part-level, and joint-level action representations of joint and motion data containing abundant and complementary semantic information via contrastive learning covering coarse-to-fine granularity. Specifically, to complement semantic information from coarse to fine granularity in skeleton actions, we design a new Pyramid Polymerizing Attention (PPA) mechanism that firstly calculates the body-level attention map, part-level attention map, and joint-level attention map, as well as polymerizes these attention maps in a level-by-level way (i.e., from body level to part level, and further to joint level). Moreover, we present a new Coarse-to-fine Contrastive Loss (CCL) including body-level contrast loss, part-level contrast loss, and joint-level contrast loss to jointly measure the similarity between the body/part/joint-level contrasting features of joint and motion data. Finally, extensive experiments are conducted on the NTU RGB+D and North-Western UCLA datasets to demonstrate the competitive performance of the proposed PSP Learning in the semi-supervised skeleton-based action recognition task. The source codes of PSP Learning are publicly available at https://github.com/1xbq1/PSP-Learning.
JPEG Steganalysis Based on Steganographic Feature Enhancement and Graph Attention Learning
Feb 05, 2023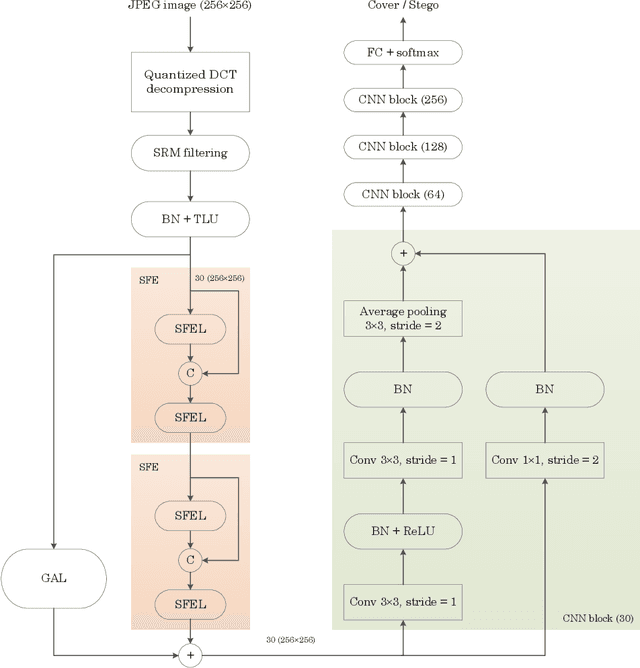

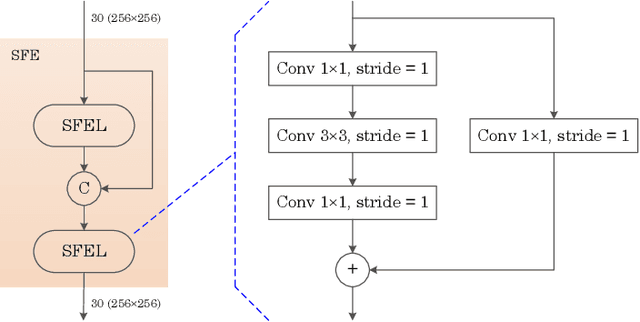
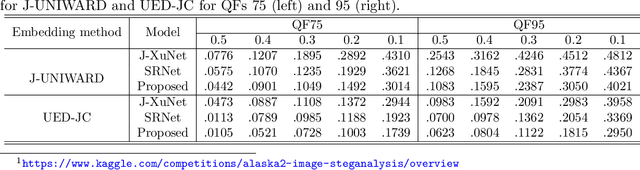
The purpose of image steganalysis is to determine whether the carrier image contains hidden information or not. Since JEPG is the most commonly used image format over social networks, steganalysis in JPEG images is also the most urgently needed to be explored. However, in order to detect whether secret information is hidden within JEPG images, the majority of existing algorithms are designed in conjunction with the popular computer vision related networks, without considering the key characteristics appeared in image steganalysis. It is crucial that the steganographic signal, as an extremely weak signal, can be enhanced during its representation learning process. Motivated by this insight, in this paper, we introduce a novel representation learning algorithm for JPEG steganalysis that is mainly consisting of a graph attention learning module and a feature enhancement module. The graph attention learning module is designed to avoid global feature loss caused by the local feature learning of convolutional neural network and reliance on depth stacking to extend the perceptual domain. The feature enhancement module is applied to prevent the stacking of convolutional layers from weakening the steganographic information. In addition, pretraining as a way to initialize the network weights with a large-scale dataset is utilized to enhance the ability of the network to extract discriminative features. We advocate pretraining with ALASKA2 for the model trained with BOSSBase+BOWS2. The experimental results indicate that the proposed algorithm outperforms previous arts in terms of detection accuracy, which has verified the superiority and applicability of the proposed work.
Supervised Attribute Information Removal and Reconstruction for Image Manipulation
Jul 13, 2022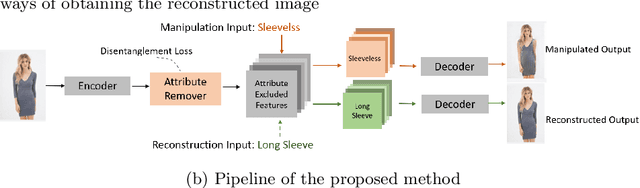
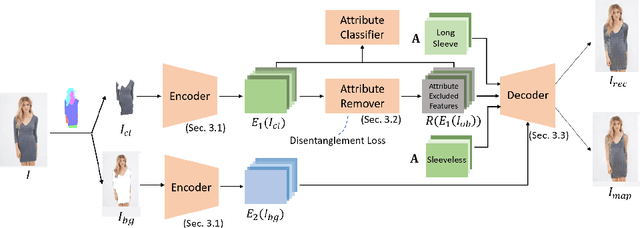
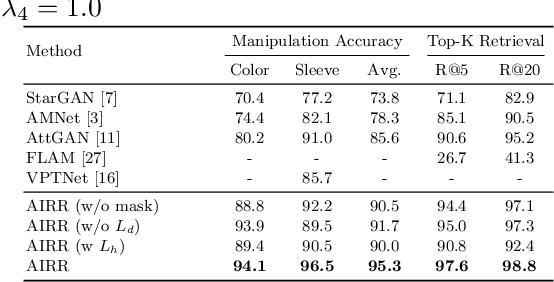
The goal of attribute manipulation is to control specified attribute(s) in given images. Prior work approaches this problem by learning disentangled representations for each attribute that enables it to manipulate the encoded source attributes to the target attributes. However, encoded attributes are often correlated with relevant image content. Thus, the source attribute information can often be hidden in the disentangled features, leading to unwanted image editing effects. In this paper, we propose an Attribute Information Removal and Reconstruction (AIRR) network that prevents such information hiding by learning how to remove the attribute information entirely, creating attribute excluded features, and then learns to directly inject the desired attributes in a reconstructed image. We evaluate our approach on four diverse datasets with a variety of attributes including DeepFashion Synthesis, DeepFashion Fine-grained Attribute, CelebA and CelebA-HQ, where our model improves attribute manipulation accuracy and top-k retrieval rate by 10% on average over prior work. A user study also reports that AIRR manipulated images are preferred over prior work in up to 76% of cases.
Multimodal Trajectory Prediction: A Survey
Feb 21, 2023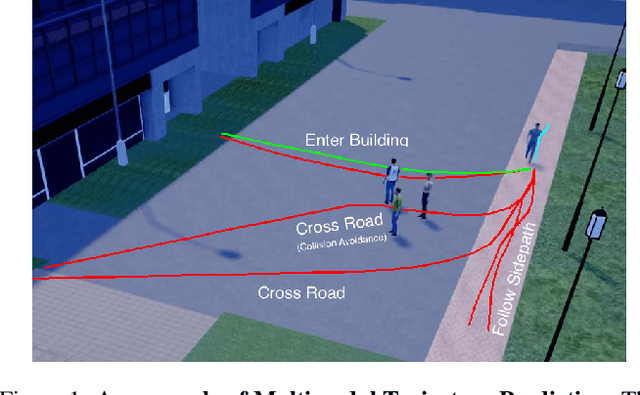
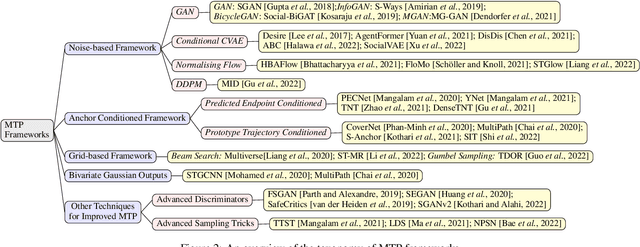
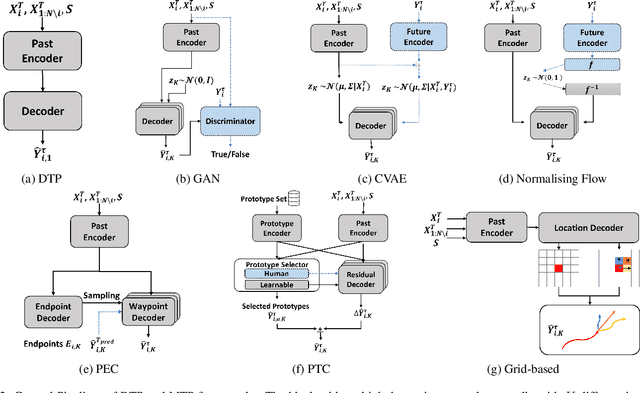
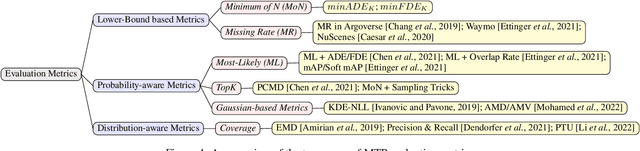
Trajectory prediction is an important task to support safe and intelligent behaviours in autonomous systems. Many advanced approaches have been proposed over the years with improved spatial and temporal feature extraction. However, human behaviour is naturally multimodal and uncertain: given the past trajectory and surrounding environment information, an agent can have multiple plausible trajectories in the future. To tackle this problem, an essential task named multimodal trajectory prediction (MTP) has recently been studied, which aims to generate a diverse, acceptable and explainable distribution of future predictions for each agent. In this paper, we present the first survey for MTP with our unique taxonomies and comprehensive analysis of frameworks, datasets and evaluation metrics. In addition, we discuss multiple future directions that can help researchers develop novel multimodal trajectory prediction systems.
Multi-Agent Reinforcement Learning for Pragmatic Communication and Control
Feb 28, 2023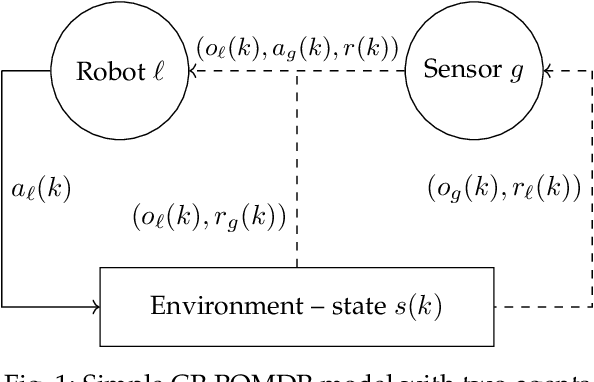
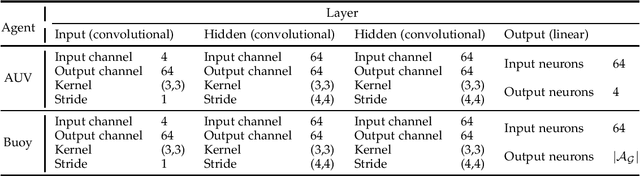
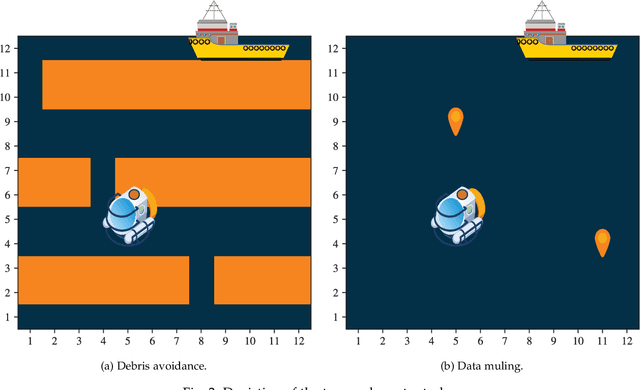
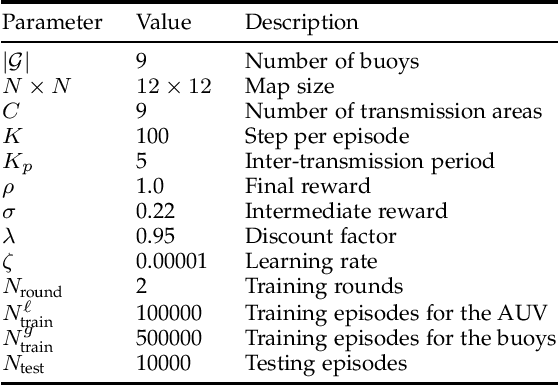
The automation of factories and manufacturing processes has been accelerating over the past few years, boosted by the Industry 4.0 paradigm, including diverse scenarios with mobile, flexible agents. Efficient coordination between mobile robots requires reliable wireless transmission in highly dynamic environments, often with strict timing requirements. Goal-oriented communication is a possible solution for this problem: communication decisions should be optimized for the target control task, providing the information that is most relevant to decide which action to take. From the control perspective, networked control design takes the communication impairments into account in its optmization of physical actions. In this work, we propose a joint design that combines goal-oriented communication and networked control into a single optimization model, an extension of a multiagent POMDP which we call Cyber-Physical POMDP (CP-POMDP). The model is flexible enough to represent several swarm and cooperative scenarios, and we illustrate its potential with two simple reference scenarios with a single agent and a set of supporting sensors. Joint training of the communication and control systems can significantly improve the overall performance, particularly if communication is severely constrained, and can even lead to implicit coordination of communication actions.
Because Every Sensor Is Unique, so Is Every Pair: Handling Dynamicity in Traffic Forecasting
Feb 28, 2023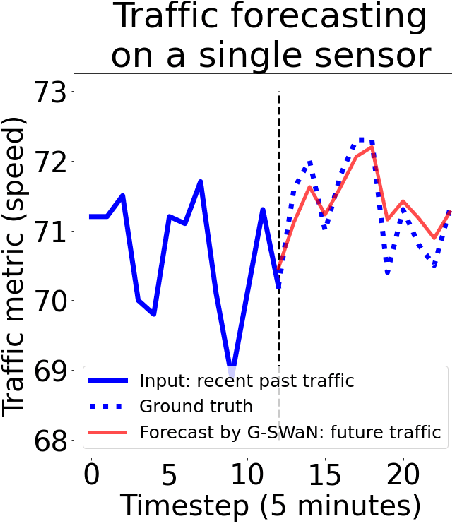

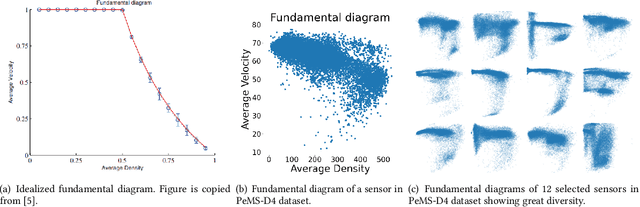

Traffic forecasting is a critical task to extract values from cyber-physical infrastructures, which is the backbone of smart transportation. However owing to external contexts, the dynamics at each sensor are unique. For example, the afternoon peaks at sensors near schools are more likely to occur earlier than those near residential areas. In this paper, we first analyze real-world traffic data to show that each sensor has a unique dynamic. Further analysis also shows that each pair of sensors also has a unique dynamic. Then, we explore how node embedding learns the unique dynamics at every sensor location. Next, we propose a novel module called Spatial Graph Transformers (SGT) where we use node embedding to leverage the self-attention mechanism to ensure that the information flow between two sensors is adaptive with respect to the unique dynamic of each pair. Finally, we present Graph Self-attention WaveNet (G-SWaN) to address the complex, non-linear spatiotemporal traffic dynamics. Through empirical experiments on four real-world, open datasets, we show that the proposed method achieves superior performance on both traffic speed and flow forecasting. Code is available at: https://github.com/aprbw/G-SWaN
* 20 pages, IoTDI 2023; Correction on Fig. 4
Robust Secrecy via Aerial Reflection and Jamming: Joint Optimization of Deployment and Transmission
Feb 28, 2023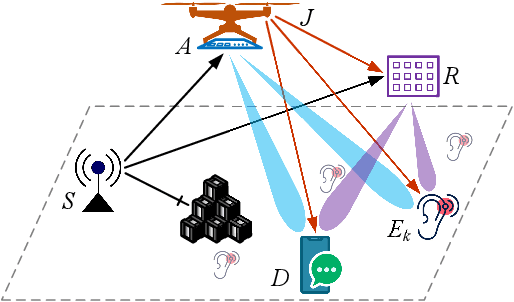
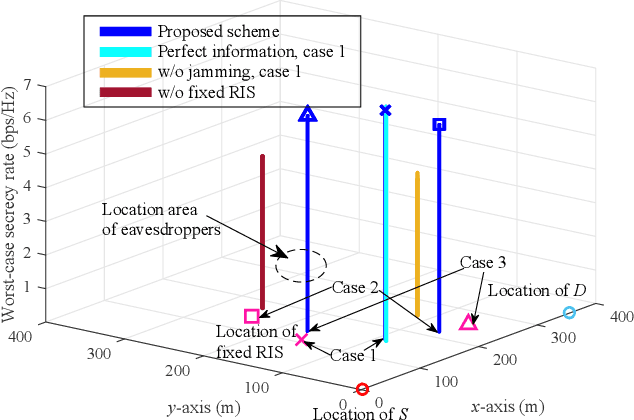
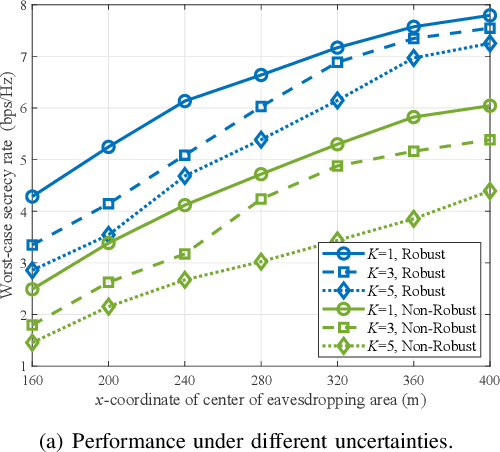
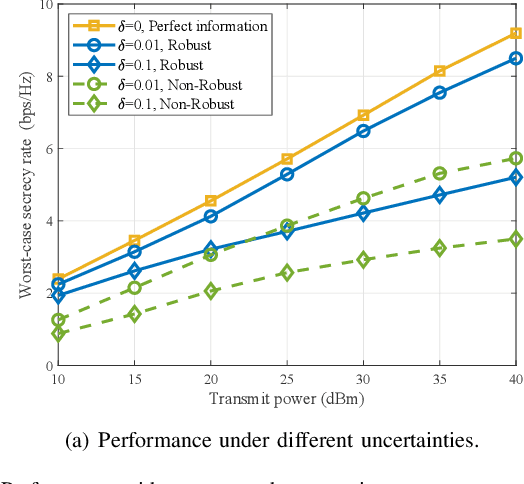
Reconfigurable intelligent surfaces (RISs) are recognized with great potential to strengthen wireless security, yet the performance gain largely depends on the deployment location of RISs in the network topology. In this paper, we consider the anti-eavesdropping communication established through a RIS at a fixed location, as well as an aerial platform mounting another RIS and a friendly jammer to further improve the secrecy. The aerial RIS helps enhance the legitimate signal and the aerial cooperative jamming is strengthened through the fixed RIS. The security gain with aerial reflection and jamming is further improved with the optimized deployment of the aerial platform. We particularly consider the imperfect channel state information issue and address the worst-case secrecy for robust performance. The formulated robust secrecy rate maximization problem is decomposed into two layers, where the inner layer solves for reflection and jamming with robust optimization, and the outer layer tackles the aerial deployment through deep reinforcement learning. Simulation results show the deployment under different network topologies and demonstrate the performance superiority of our proposal in terms of the worst-case security provisioning as compared with the baselines.