 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Are Data-driven Explanations Robust against Out-of-distribution Data?
Mar 29, 2023
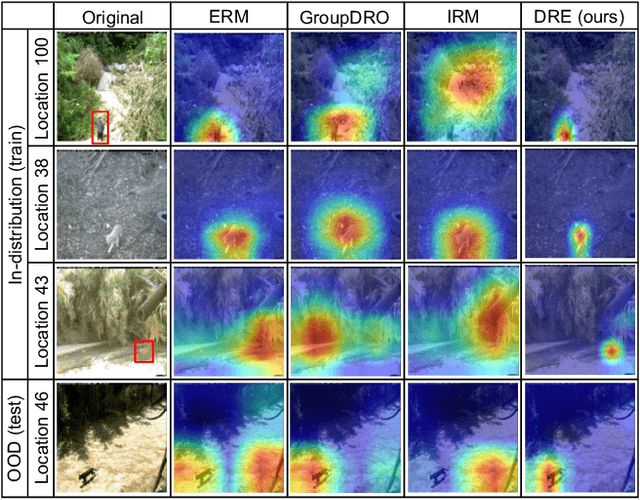
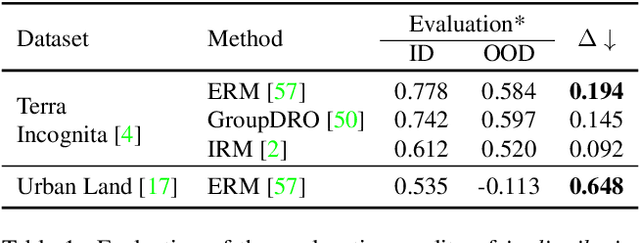
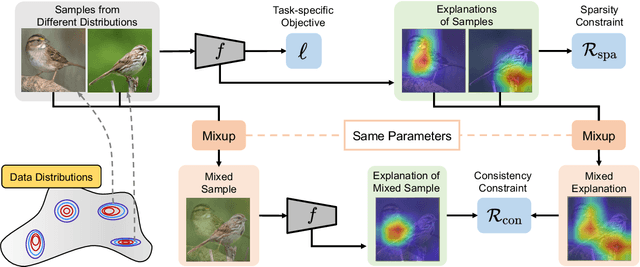

As black-box models increasingly power high-stakes applications, a variety of data-driven explanation methods have been introduced. Meanwhile, machine learning models are constantly challenged by distributional shifts. A question naturally arises: Are data-driven explanations robust against out-of-distribution data? Our empirical results show that even though predict correctly, the model might still yield unreliable explanations under distributional shifts. How to develop robust explanations against out-of-distribution data? To address this problem, we propose an end-to-end model-agnostic learning framework Distributionally Robust Explanations (DRE). The key idea is, inspired by self-supervised learning, to fully utilizes the inter-distribution information to provide supervisory signals for the learning of explanations without human annotation. Can robust explanations benefit the model's generalization capability? We conduct extensive experiments on a wide range of tasks and data types, including classification and regression on image and scientific tabular data. Our results demonstrate that the proposed method significantly improves the model's performance in terms of explanation and prediction robustness against distributional shifts.
Evaluating GPT-3.5 and GPT-4 Models on Brazilian University Admission Exams
Mar 29, 2023


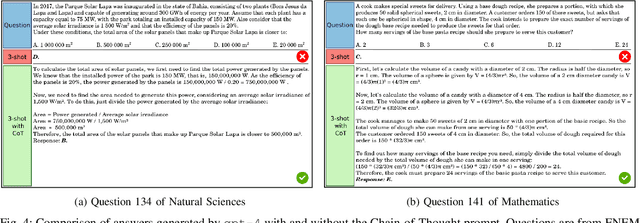
The present study aims to explore the capabilities of Language Models (LMs) in tackling high-stakes multiple-choice tests, represented here by the Exame Nacional do Ensino M\'edio (ENEM), a multidisciplinary entrance examination widely adopted by Brazilian universities. This exam poses challenging tasks for LMs, since its questions may span into multiple fields of knowledge, requiring understanding of information from diverse domains. For instance, a question may require comprehension of both statistics and biology to be solved. This work analyzed responses generated by GPT-3.5 and GPT-4 models for questions presented in the 2009-2017 exams, as well as for questions of the 2022 exam, which were made public after the training of the models was completed. Furthermore, different prompt strategies were tested, including the use of Chain-of-Thought (CoT) prompts to generate explanations for answers. On the 2022 edition, the best-performing model, GPT-4 with CoT, achieved an accuracy of 87%, largely surpassing GPT-3.5 by 11 points. The code and data used on experiments are available at https://github.com/piresramon/gpt-4-enem.
Point2Vec for Self-Supervised Representation Learning on Point Clouds
Mar 29, 2023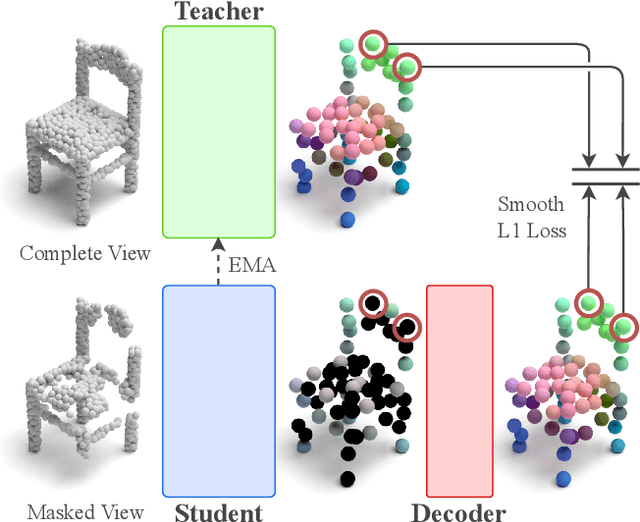
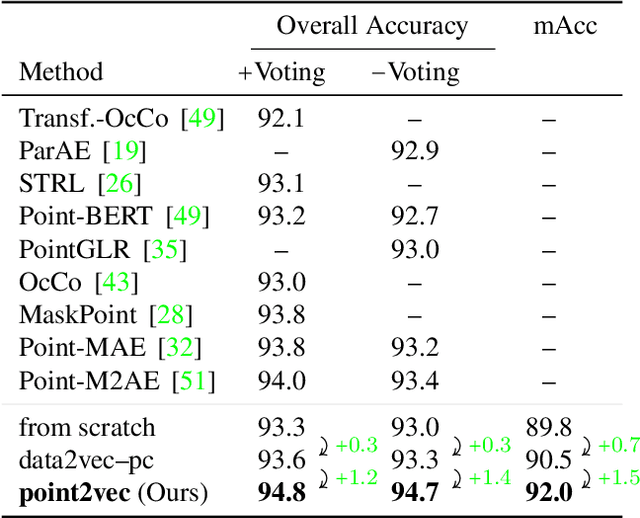
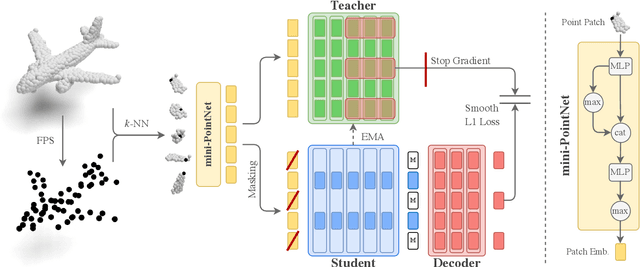
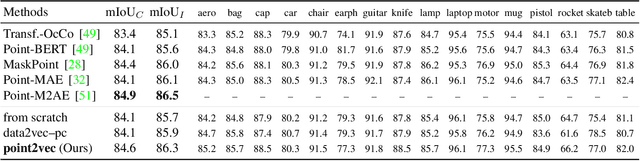
Recently, the self-supervised learning framework data2vec has shown inspiring performance for various modalities using a masked student-teacher approach. However, it remains open whether such a framework generalizes to the unique challenges of 3D point clouds. To answer this question, we extend data2vec to the point cloud domain and report encouraging results on several downstream tasks. In an in-depth analysis, we discover that the leakage of positional information reveals the overall object shape to the student even under heavy masking and thus hampers data2vec to learn strong representations for point clouds. We address this 3D-specific shortcoming by proposing point2vec, which unleashes the full potential of data2vec-like pre-training on point clouds. Our experiments show that point2vec outperforms other self-supervised methods on shape classification and few-shot learning on ModelNet40 and ScanObjectNN, while achieving competitive results on part segmentation on ShapeNetParts. These results suggest that the learned representations are strong and transferable, highlighting point2vec as a promising direction for self-supervised learning of point cloud representations.
An intelligent modular real-time vision-based system for environment perception
Mar 29, 2023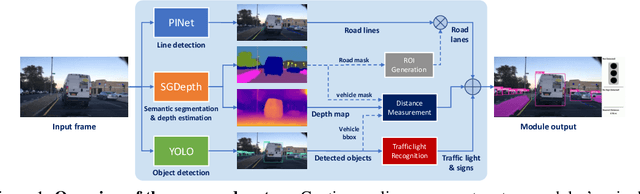

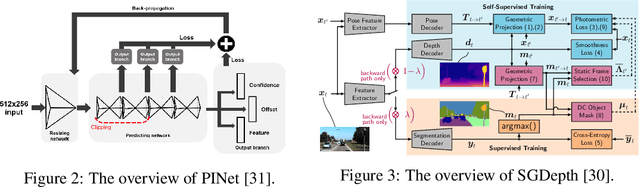
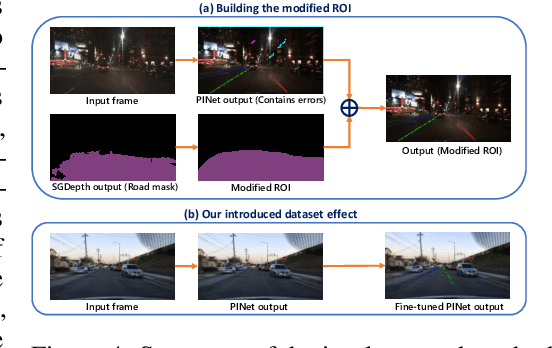
A significant portion of driving hazards is caused by human error and disregard for local driving regulations; Consequently, an intelligent assistance system can be beneficial. This paper proposes a novel vision-based modular package to ensure drivers' safety by perceiving the environment. Each module is designed based on accuracy and inference time to deliver real-time performance. As a result, the proposed system can be implemented on a wide range of vehicles with minimum hardware requirements. Our modular package comprises four main sections: lane detection, object detection, segmentation, and monocular depth estimation. Each section is accompanied by novel techniques to improve the accuracy of others along with the entire system. Furthermore, a GUI is developed to display perceived information to the driver. In addition to using public datasets, like BDD100K, we have also collected and annotated a local dataset that we utilize to fine-tune and evaluate our system. We show that the accuracy of our system is above 80% in all the sections. Our code and data are available at https://github.com/Pandas-Team/Autonomous-Vehicle-Environment-Perception
Improved Multimodal Fusion for Small Datasets with Auxiliary Supervision
Apr 01, 2023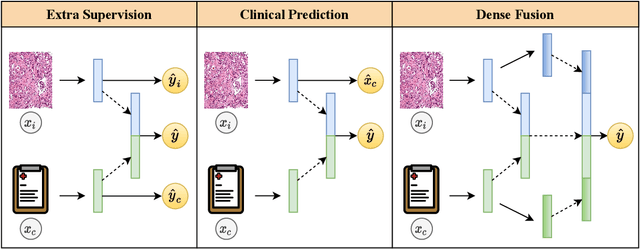
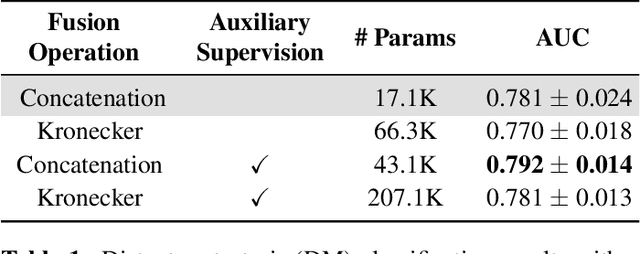
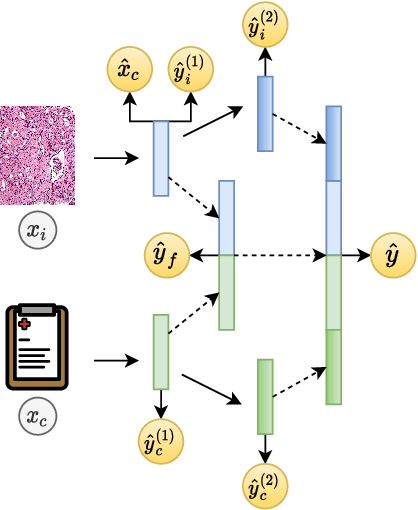
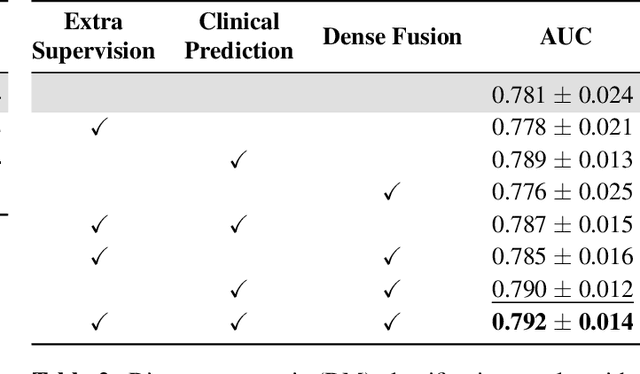
Prostate cancer is one of the leading causes of cancer-related death in men worldwide. Like many cancers, diagnosis involves expert integration of heterogeneous patient information such as imaging, clinical risk factors, and more. For this reason, there have been many recent efforts toward deep multimodal fusion of image and non-image data for clinical decision tasks. Many of these studies propose methods to fuse learned features from each patient modality, providing significant downstream improvements with techniques like cross-modal attention gating, Kronecker product fusion, orthogonality regularization, and more. While these enhanced fusion operations can improve upon feature concatenation, they often come with an extremely high learning capacity, meaning they are likely to overfit when applied even to small or low-dimensional datasets. Rather than designing a highly expressive fusion operation, we propose three simple methods for improved multimodal fusion with small datasets that aid optimization by generating auxiliary sources of supervision during training: extra supervision, clinical prediction, and dense fusion. We validate the proposed approaches on prostate cancer diagnosis from paired histopathology imaging and tabular clinical features. The proposed methods are straightforward to implement and can be applied to any classification task with paired image and non-image data.
Graphical Models of False Information and Fact Checking Ecosystems
Aug 24, 2022
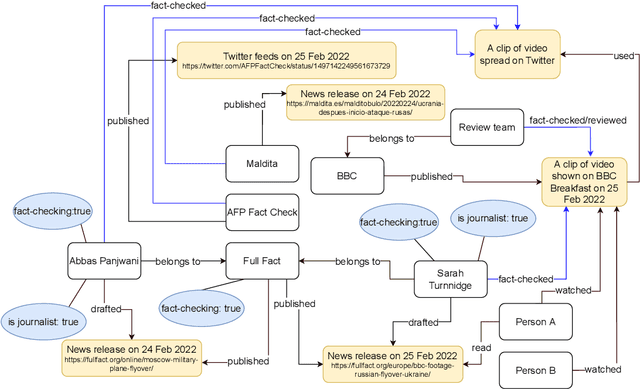
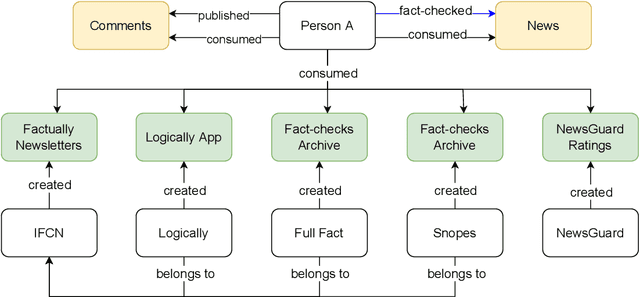
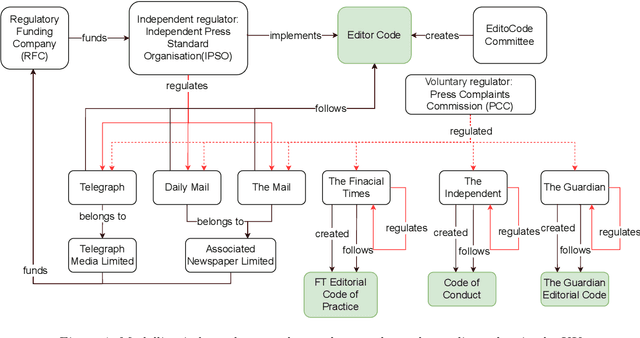
The wide spread of false information online including misinformation and disinformation has become a major problem for our highly digitised and globalised society. A lot of research has been done to better understand different aspects of false information online such as behaviours of different actors and patterns of spreading, and also on better detection and prevention of such information using technical and socio-technical means. One major approach to detect and debunk false information online is to use human fact-checkers, who can be helped by automated tools. Despite a lot of research done, we noticed a significant gap on the lack of conceptual models describing the complicated ecosystems of false information and fact checking. In this paper, we report the first graphical models of such ecosystems, focusing on false information online in multiple contexts, including traditional media outlets and user-generated content. The proposed models cover a wide range of entity types and relationships, and can be a new useful tool for researchers and practitioners to study false information online and the effects of fact checking.
Discovering Hierarchical Process Models: an Approach Based on Events Clustering
Mar 12, 2023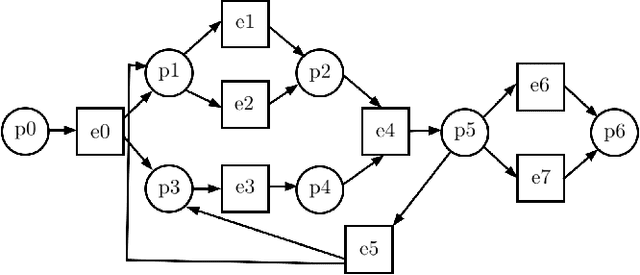

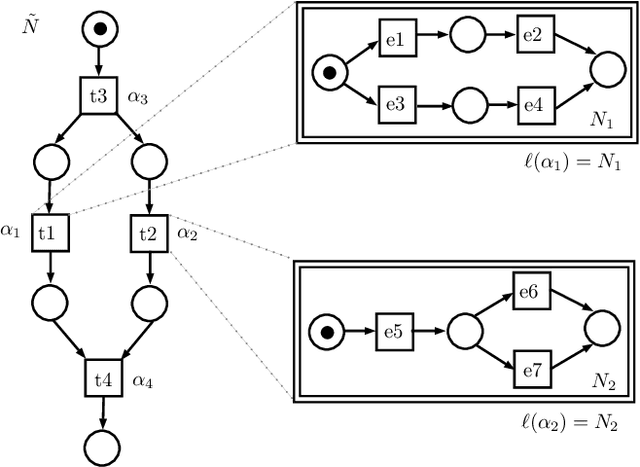
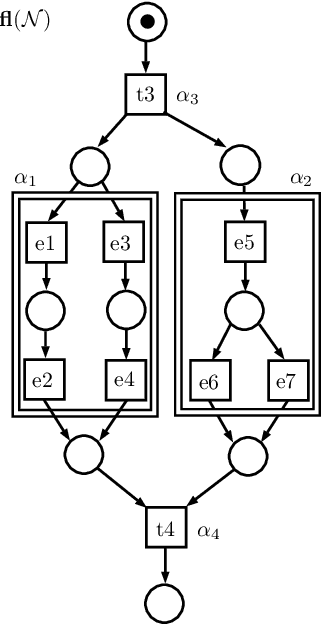
Process mining is a field of computer science that deals with discovery and analysis of process models based on automatically generated event logs. Currently, many companies use this technology for optimization and improving their processes. However, a discovered process model may be too detailed, sophisticated and difficult for experts to understand. In this paper, we consider the problem of discovering a hierarchical business process model from a low-level event log, i.e., the problem of automatic synthesis of more readable and understandable process models based on information stored in event logs of information systems. Discovery of better structured and more readable process models is intensively studied in the frame of process mining research from different perspectives. In this paper, we present an algorithm for discovering hierarchical process models represented as two-level workflow nets. The algorithm is based on predefined event ilustering so that the cluster defines a sub-process corresponding to a high-level transition at the top level of the net. Unlike existing solutions, our algorithm does not impose restrictions on the process control flow and allows for concurrency and iteration.
Physics-Informed Optical Kernel Regression Using Complex-valued Neural Fields
Mar 27, 2023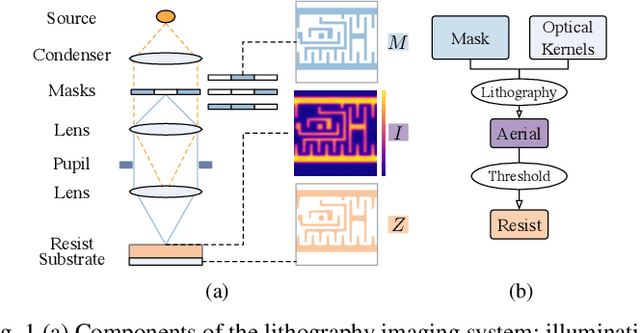
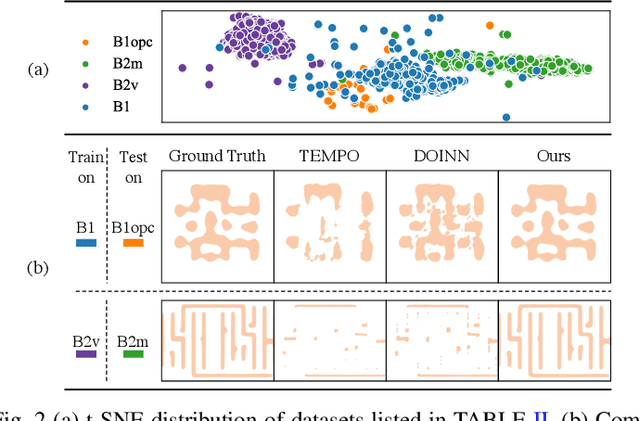
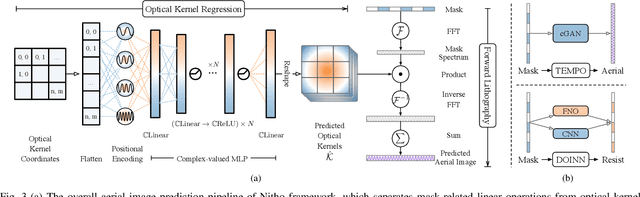
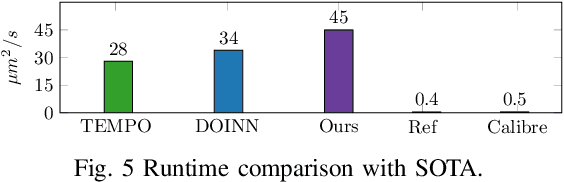
Lithography is fundamental to integrated circuit fabrication, necessitating large computation overhead. The advancement of machine learning (ML)-based lithography models alleviates the trade-offs between manufacturing process expense and capability. However, all previous methods regard the lithography system as an image-to-image black box mapping, utilizing network parameters to learn by rote mappings from massive mask-to-aerial or mask-to-resist image pairs, resulting in poor generalization capability. In this paper, we propose a new ML-based paradigm disassembling the rigorous lithographic model into non-parametric mask operations and learned optical kernels containing determinant source, pupil, and lithography information. By optimizing complex-valued neural fields to perform optical kernel regression from coordinates, our method can accurately restore lithography system using a small-scale training dataset with fewer parameters, demonstrating superior generalization capability as well. Experiments show that our framework can use 31% of parameters while achieving 69$\times$ smaller mean squared error with 1.3$\times$ higher throughput than the state-of-the-art.
Spatio-Temporal AU Relational Graph Representation Learning For Facial Action Units Detection
Mar 27, 2023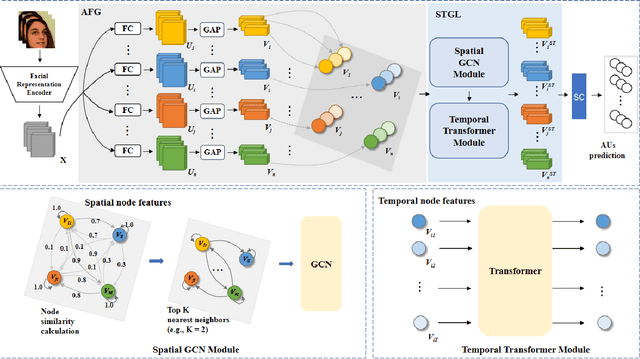

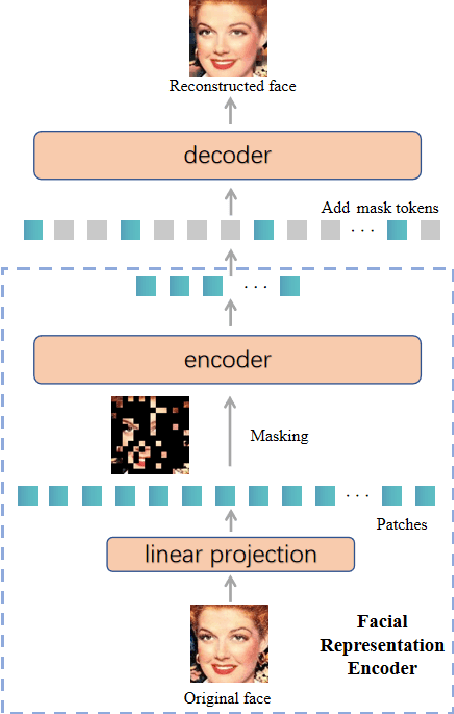

This paper presents our Facial Action Units (AUs) recognition submission to the fifth Affective Behavior Analysis in-the-wild Competition (ABAW). Our approach consists of three main modules: (i) a pre-trained facial representation encoder which produce a strong facial representation from each input face image in the input sequence; (ii) an AU-specific feature generator that specifically learns a set of AU features from each facial representation; and (iii) a spatio-temporal graph learning module that constructs a spatio-temporal graph representation. This graph representation describes AUs contained in all frames and predicts the occurrence of each AU based on both the modeled spatial information within the corresponding face and the learned temporal dynamics among frames. The experimental results show that our approach outperformed the baseline and the spatio-temporal graph representation learning allows our model to generate the best results among all ablated systems. Our model ranks at the 4th place in the AU recognition track at the 5th ABAW Competition.
Knowledge Enhanced Graph Neural Networks
Mar 27, 2023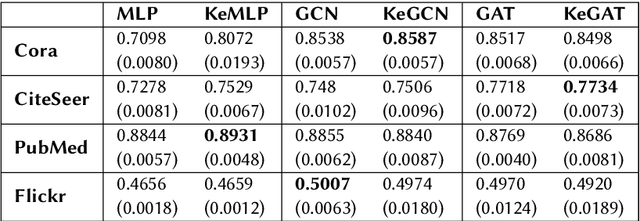
Graph data is omnipresent and has a large variety of applications such as natural science, social networks or semantic web. Though rich in information, graphs are often noisy and incomplete. Therefore, graph completion tasks such as node classification or link prediction have gained attention. On the one hand, neural methods such as graph neural networks have proven to be robust tools for learning rich representations of noisy graphs. On the other hand, symbolic methods enable exact reasoning on graphs. We propose KeGNN, a neuro-symbolic framework for learning on graph data that combines both paradigms and allows for the integration of prior knowledge into a graph neural network model. In essence, KeGNN consists of a graph neural network as a base on which knowledge enhancement layers are stacked with the objective of refining predictions with respect to prior knowledge. We instantiate KeGNN in conjunction with two standard graph neural networks: Graph Convolutional Networks and Graph Attention Networks, and evaluate KeGNN on multiple benchmark datasets for node classification.