 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Time-Series Representations by Hierarchical Uniformity-Tolerance Latent Balancing
Oct 02, 2025We propose TimeHUT, a novel method for learning time-series representations by hierarchical uniformity-tolerance balancing of contrastive representations. Our method uses two distinct losses to learn strong representations with the aim of striking an effective balance between uniformity and tolerance in the embedding space. First, TimeHUT uses a hierarchical setup to learn both instance-wise and temporal information from input time-series. Next, we integrate a temperature scheduler within the vanilla contrastive loss to balance the uniformity and tolerance characteristics of the embeddings. Additionally, a hierarchical angular margin loss enforces instance-wise and temporal contrast losses, creating geometric margins between positive and negative pairs of temporal sequences. This approach improves the coherence of positive pairs and their separation from the negatives, enhancing the capture of temporal dependencies within a time-series sample. We evaluate our approach on a wide range of tasks, namely 128 UCR and 30 UAE datasets for univariate and multivariate classification, as well as Yahoo and KPI datasets for anomaly detection. The results demonstrate that TimeHUT outperforms prior methods by considerable margins on classification, while obtaining competitive results for anomaly detection. Finally, detailed sensitivity and ablation studies are performed to evaluate different components and hyperparameters of our method.
Federated Domain Generalization with Label Smoothing and Balanced Decentralized Training
Dec 16, 2024



In this paper, we propose a novel approach, Federated Domain Generalization with Label Smoothing and Balanced Decentralized Training (FedSB), to address the challenges of data heterogeneity within a federated learning framework. FedSB utilizes label smoothing at the client level to prevent overfitting to domain-specific features, thereby enhancing generalization capabilities across diverse domains when aggregating local models into a global model. Additionally, FedSB incorporates a decentralized budgeting mechanism which balances training among clients, which is shown to improve the performance of the aggregated global model. Extensive experiments on four commonly used multi-domain datasets, PACS, VLCS, OfficeHome, and TerraInc, demonstrate that FedSB outperforms competing methods, achieving state-of-the-art results on three out of four datasets, indicating the effectiveness of FedSB in addressing data heterogeneity.
Federated Unsupervised Domain Generalization using Global and Local Alignment of Gradients
May 25, 2024



We address the problem of federated domain generalization in an unsupervised setting for the first time. We first theoretically establish a connection between domain shift and alignment of gradients in unsupervised federated learning and show that aligning the gradients at both client and server levels can facilitate the generalization of the model to new (target) domains. Building on this insight, we propose a novel method named FedGaLA, which performs gradient alignment at the client level to encourage clients to learn domain-invariant features, as well as global gradient alignment at the server to obtain a more generalized aggregated model. To empirically evaluate our method, we perform various experiments on four commonly used multi-domain datasets, PACS, OfficeHome, DomainNet, and TerraInc. The results demonstrate the effectiveness of our method which outperforms comparable baselines. Ablation and sensitivity studies demonstrate the impact of different components and parameters in our approach. The source code will be available online upon publication.
An intelligent modular real-time vision-based system for environment perception
Mar 29, 2023



A significant portion of driving hazards is caused by human error and disregard for local driving regulations; Consequently, an intelligent assistance system can be beneficial. This paper proposes a novel vision-based modular package to ensure drivers' safety by perceiving the environment. Each module is designed based on accuracy and inference time to deliver real-time performance. As a result, the proposed system can be implemented on a wide range of vehicles with minimum hardware requirements. Our modular package comprises four main sections: lane detection, object detection, segmentation, and monocular depth estimation. Each section is accompanied by novel techniques to improve the accuracy of others along with the entire system. Furthermore, a GUI is developed to display perceived information to the driver. In addition to using public datasets, like BDD100K, we have also collected and annotated a local dataset that we utilize to fine-tune and evaluate our system. We show that the accuracy of our system is above 80% in all the sections. Our code and data are available at https://github.com/Pandas-Team/Autonomous-Vehicle-Environment-Perception
HiFormer: Hierarchical Multi-scale Representations Using Transformers for Medical Image Segmentation
Jul 18, 2022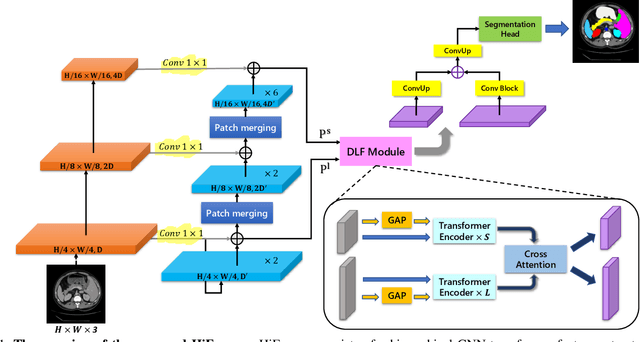
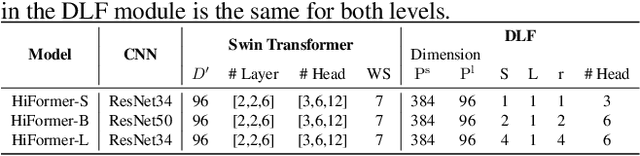
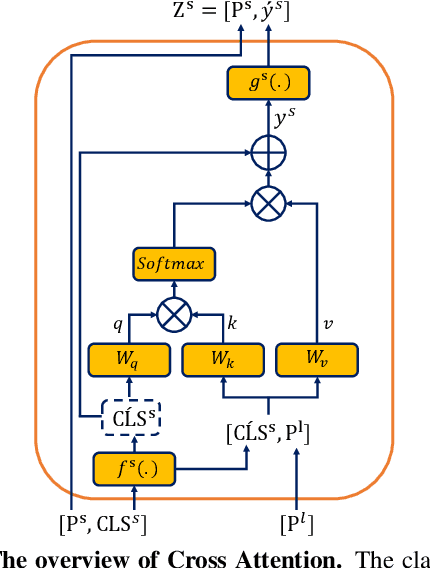
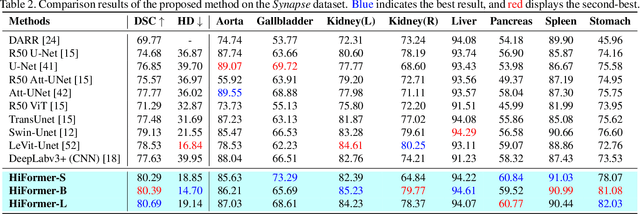
Convolutional neural networks (CNNs) have been the consensus for medical image segmentation tasks. However, they suffer from the limitation in modeling long-range dependencies and spatial correlations due to the nature of convolution operation. Although transformers were first developed to address this issue, they fail to capture low-level features. In contrast, it is demonstrated that both local and global features are crucial for dense prediction, such as segmenting in challenging contexts. In this paper, we propose HiFormer, a novel method that efficiently bridges a CNN and a transformer for medical image segmentation. Specifically, we design two multi-scale feature representations using the seminal Swin Transformer module and a CNN-based encoder. To secure a fine fusion of global and local features obtained from the two aforementioned representations, we propose a Double-Level Fusion (DLF) module in the skip connection of the encoder-decoder structure. Extensive experiments on various medical image segmentation datasets demonstrate the effectiveness of HiFormer over other CNN-based, transformer-based, and hybrid methods in terms of computational complexity, and quantitative and qualitative results. Our code is publicly available at: https://github.com/amirhossein-kz/HiFormer