 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CLASSLA-web: Comparable Web Corpora of South Slavic Languages Enriched with Linguistic and Genre Annotation
Mar 19, 2024
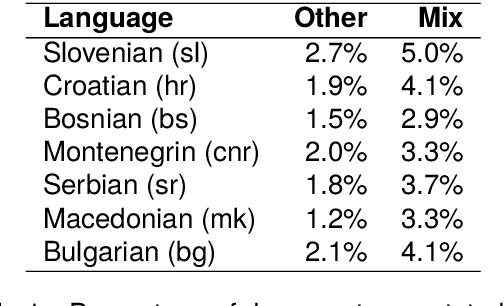
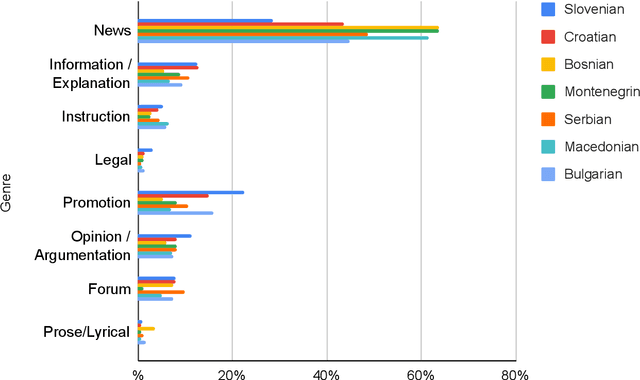
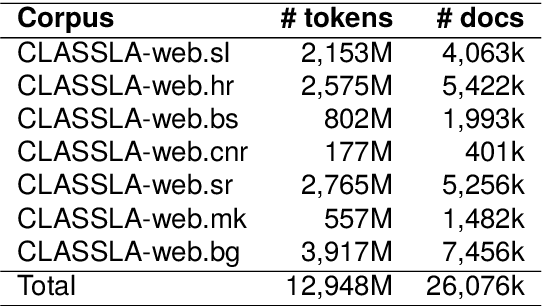
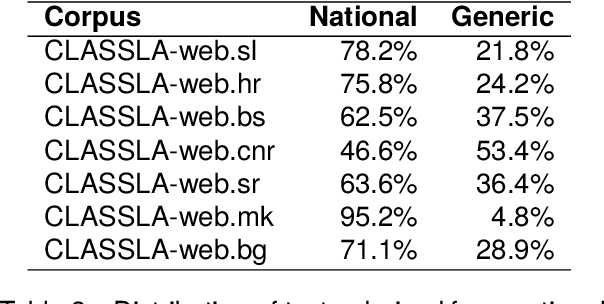
This paper presents a collection of highly comparable web corpora of Slovenian, Croatian, Bosnian, Montenegrin, Serbian, Macedonian, and Bulgarian, covering thereby the whole spectrum of official languages in the South Slavic language space. The collection of these corpora comprises a total of 13 billion tokens of texts from 26 million documents. The comparability of the corpora is ensured by a comparable crawling setup and the usage of identical crawling and post-processing technology. All the corpora were linguistically annotated with the state-of-the-art CLASSLA-Stanza linguistic processing pipeline, and enriched with document-level genre information via the Transformer-based multilingual X-GENRE classifier, which further enhances comparability at the level of linguistic annotation and metadata enrichment. The genre-focused analysis of the resulting corpora shows a rather consistent distribution of genres throughout the seven corpora, with variations in the most prominent genre categories being well-explained by the economic strength of each language community. A comparison of the distribution of genre categories across the corpora indicates that web corpora from less developed countries primarily consist of news articles. Conversely, web corpora from economically more developed countries exhibit a smaller proportion of news content, with a greater presence of promotional and opinionated texts.
Dr3: Ask Large Language Models Not to Give Off-Topic Answers in Open Domain Multi-Hop Question Answering
Mar 19, 2024
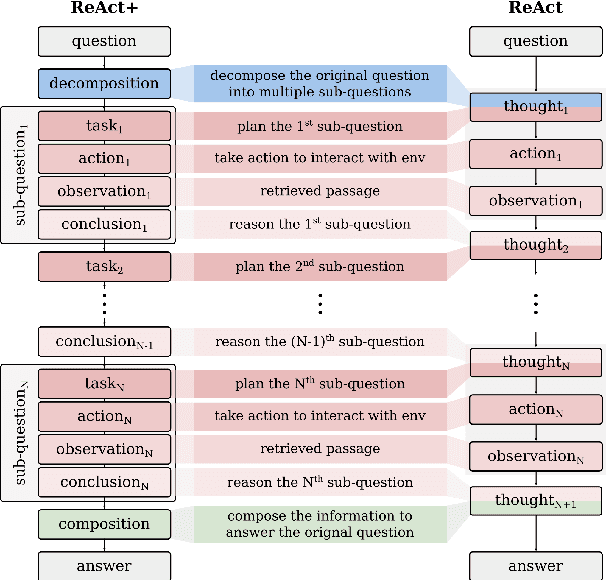
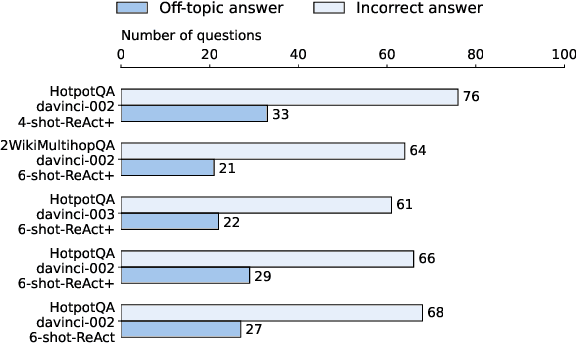
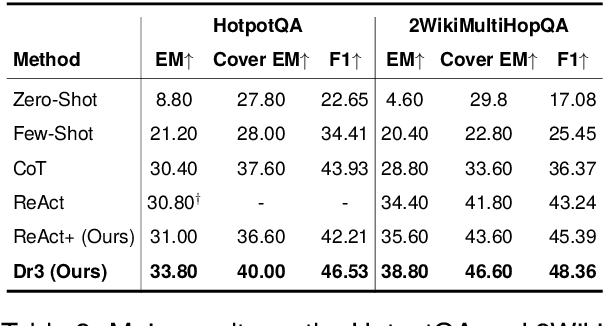
Open Domain Multi-Hop Question Answering (ODMHQA) plays a crucial role in Natural Language Processing (NLP) by aiming to answer complex questions through multi-step reasoning over retrieved information from external knowledge sources. Recently, Large Language Models (LLMs) have demonstrated remarkable performance in solving ODMHQA owing to their capabilities including planning, reasoning, and utilizing tools. However, LLMs may generate off-topic answers when attempting to solve ODMHQA, namely the generated answers are irrelevant to the original questions. This issue of off-topic answers accounts for approximately one-third of incorrect answers, yet remains underexplored despite its significance. To alleviate this issue, we propose the Discriminate->Re-Compose->Re- Solve->Re-Decompose (Dr3) mechanism. Specifically, the Discriminator leverages the intrinsic capabilities of LLMs to judge whether the generated answers are off-topic. In cases where an off-topic answer is detected, the Corrector performs step-wise revisions along the reversed reasoning chain (Re-Compose->Re-Solve->Re-Decompose) until the final answer becomes on-topic. Experimental results on the HotpotQA and 2WikiMultiHopQA datasets demonstrate that our Dr3 mechanism considerably reduces the occurrence of off-topic answers in ODMHQA by nearly 13%, improving the performance in Exact Match (EM) by nearly 3% compared to the baseline method without the Dr3 mechanism.
Meta-Prompting for Automating Zero-shot Visual Recognition with LLMs
Mar 19, 2024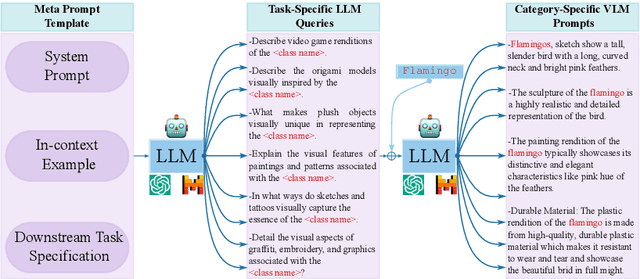
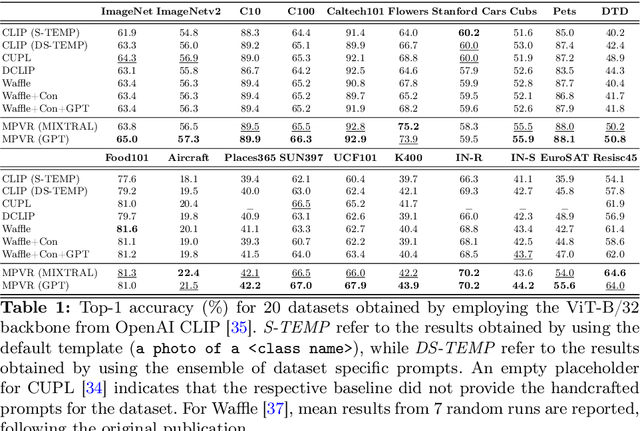
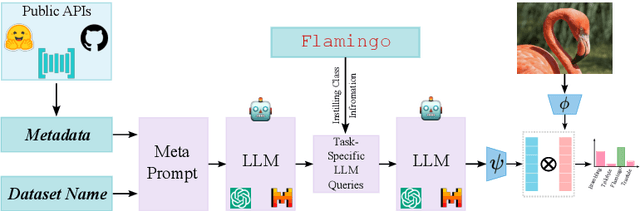
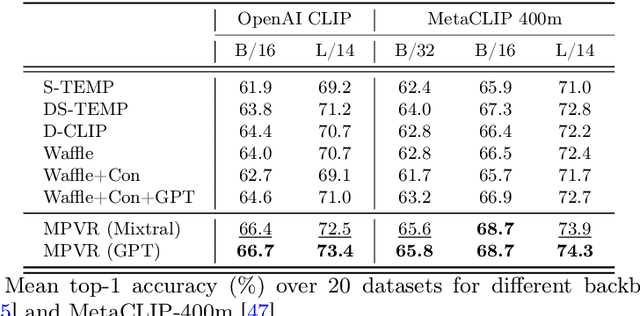
Prompt ensembling of Large Language Model (LLM) generated category-specific prompts has emerged as an effective method to enhance zero-shot recognition ability of Vision-Language Models (VLMs). To obtain these category-specific prompts, the present methods rely on hand-crafting the prompts to the LLMs for generating VLM prompts for the downstream tasks. However, this requires manually composing these task-specific prompts and still, they might not cover the diverse set of visual concepts and task-specific styles associated with the categories of interest. To effectively take humans out of the loop and completely automate the prompt generation process for zero-shot recognition, we propose Meta-Prompting for Visual Recognition (MPVR). Taking as input only minimal information about the target task, in the form of its short natural language description, and a list of associated class labels, MPVR automatically produces a diverse set of category-specific prompts resulting in a strong zero-shot classifier. MPVR generalizes effectively across various popular zero-shot image recognition benchmarks belonging to widely different domains when tested with multiple LLMs and VLMs. For example, MPVR obtains a zero-shot recognition improvement over CLIP by up to 19.8% and 18.2% (5.0% and 4.5% on average over 20 datasets) leveraging GPT and Mixtral LLMs, respectively
Private graphon estimation via sum-of-squares
Mar 18, 2024We develop the first pure node-differentially-private algorithms for learning stochastic block models and for graphon estimation with polynomial running time for any constant number of blocks. The statistical utility guarantees match those of the previous best information-theoretic (exponential-time) node-private mechanisms for these problems. The algorithm is based on an exponential mechanism for a score function defined in terms of a sum-of-squares relaxation whose level depends on the number of blocks. The key ingredients of our results are (1) a characterization of the distance between the block graphons in terms of a quadratic optimization over the polytope of doubly stochastic matrices, (2) a general sum-of-squares convergence result for polynomial optimization over arbitrary polytopes, and (3) a general approach to perform Lipschitz extensions of score functions as part of the sum-of-squares algorithmic paradigm.
Loops On Retrieval Augmented Generation (LoRAG)
Mar 18, 2024This paper presents Loops On Retrieval Augmented Generation (LoRAG), a new framework designed to enhance the quality of retrieval-augmented text generation through the incorporation of an iterative loop mechanism. The architecture integrates a generative model, a retrieval mechanism, and a dynamic loop module, allowing for iterative refinement of the generated text through interactions with relevant information retrieved from the input context. Experimental evaluations on benchmark datasets demonstrate that LoRAG surpasses existing state-of-the-art models in terms of BLEU score, ROUGE score, and perplexity, showcasing its effectiveness in achieving both coherence and relevance in generated text. The qualitative assessment further illustrates LoRAG's capability to produce contextually rich and coherent outputs. This research contributes valuable insights into the potential of iterative loops in mitigating challenges in text generation, positioning LoRAG as a promising advancement in the field.
InTeX: Interactive Text-to-texture Synthesis via Unified Depth-aware Inpainting
Mar 18, 2024
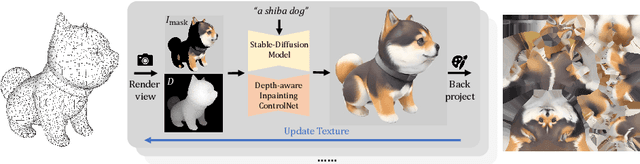


Text-to-texture synthesis has become a new frontier in 3D content creation thanks to the recent advances in text-to-image models. Existing methods primarily adopt a combination of pretrained depth-aware diffusion and inpainting models, yet they exhibit shortcomings such as 3D inconsistency and limited controllability. To address these challenges, we introduce InteX, a novel framework for interactive text-to-texture synthesis. 1) InteX includes a user-friendly interface that facilitates interaction and control throughout the synthesis process, enabling region-specific repainting and precise texture editing. 2) Additionally, we develop a unified depth-aware inpainting model that integrates depth information with inpainting cues, effectively mitigating 3D inconsistencies and improving generation speed. Through extensive experiments, our framework has proven to be both practical and effective in text-to-texture synthesis, paving the way for high-quality 3D content creation.
Fusing Domain-Specific Content from Large Language Models into Knowledge Graphs for Enhanced Zero Shot Object State Classification
Mar 18, 2024
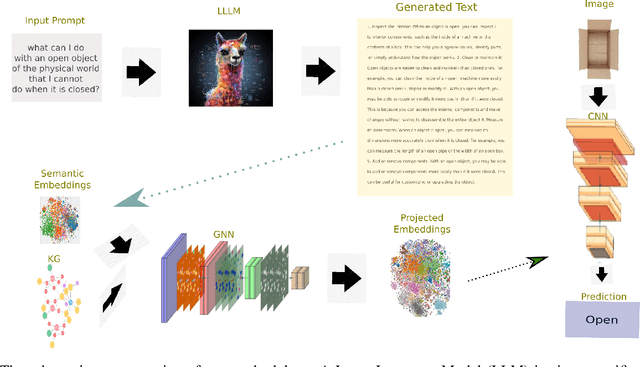


Domain-specific knowledge can significantly contribute to addressing a wide variety of vision tasks. However, the generation of such knowledge entails considerable human labor and time costs. This study investigates the potential of Large Language Models (LLMs) in generating and providing domain-specific information through semantic embeddings. To achieve this, an LLM is integrated into a pipeline that utilizes Knowledge Graphs and pre-trained semantic vectors in the context of the Vision-based Zero-shot Object State Classification task. We thoroughly examine the behavior of the LLM through an extensive ablation study. Our findings reveal that the integration of LLM-based embeddings, in combination with general-purpose pre-trained embeddings, leads to substantial performance improvements. Drawing insights from this ablation study, we conduct a comparative analysis against competing models, thereby highlighting the state-of-the-art performance achieved by the proposed approach.
Context-aware LLM-based Safe Control Against Latent Risks
Mar 18, 2024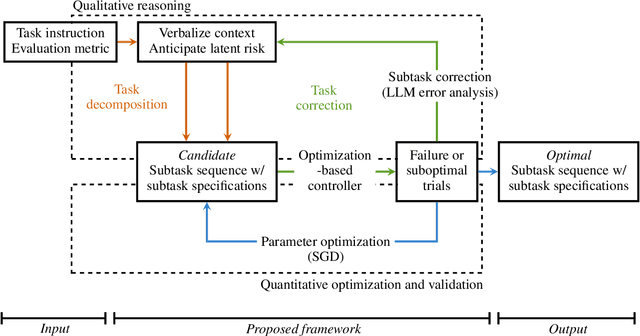
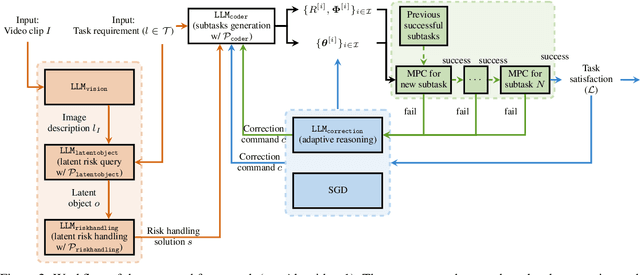
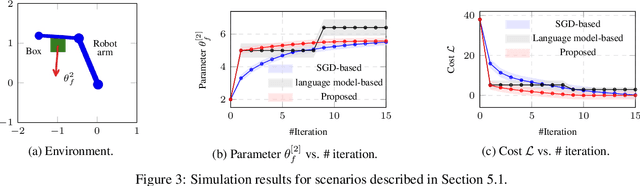
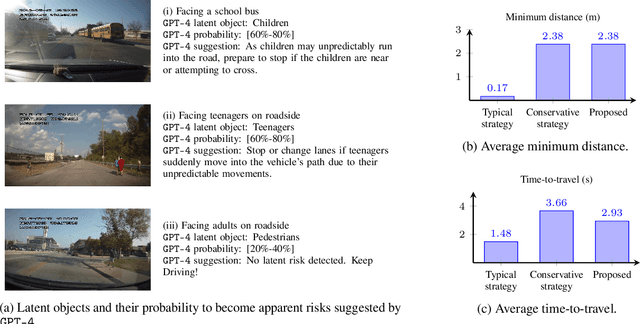
It is challenging for autonomous control systems to perform complex tasks in the presence of latent risks. Motivated by this challenge, this paper proposes an integrated framework that involves Large Language Models (LLMs), stochastic gradient descent (SGD), and optimization-based control. In the first phrase, the proposed framework breaks down complex tasks into a sequence of smaller subtasks, whose specifications account for contextual information and latent risks. In the second phase, these subtasks and their parameters are refined through a dual process involving LLMs and SGD. LLMs are used to generate rough guesses and failure explanations, and SGD is used to fine-tune parameters. The proposed framework is tested using simulated case studies of robots and vehicles. The experiments demonstrate that the proposed framework can mediate actions based on the context and latent risks and learn complex behaviors efficiently.
Multiscale Matching Driven by Cross-Modal Similarity Consistency for Audio-Text Retrieval
Mar 15, 2024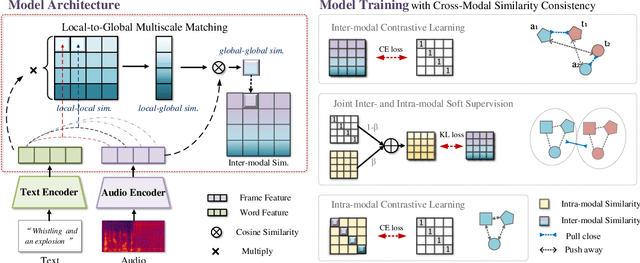
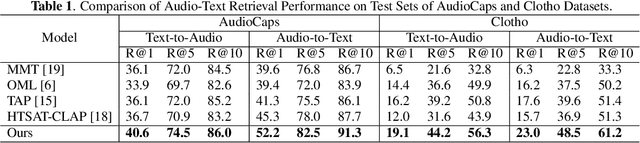
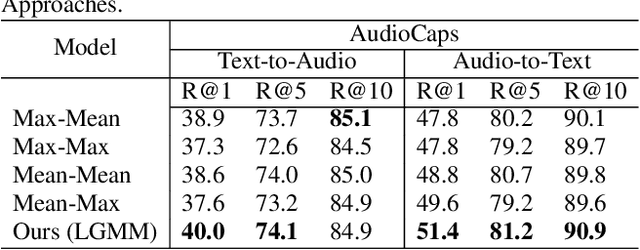
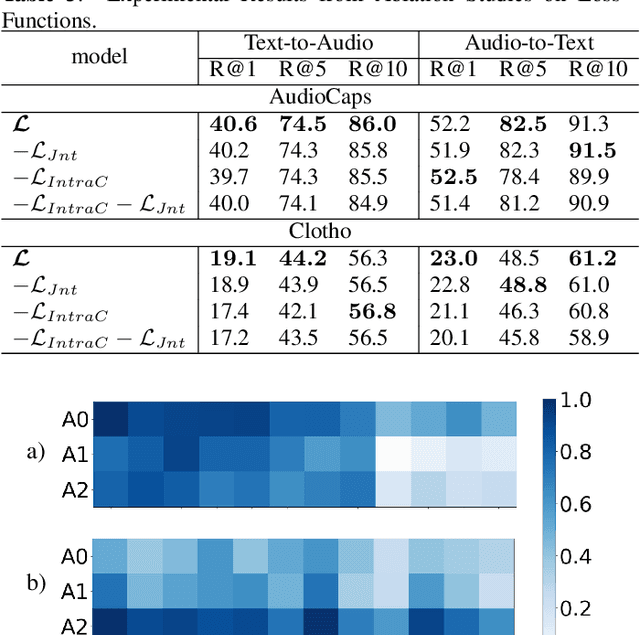
Audio-text retrieval (ATR), which retrieves a relevant caption given an audio clip (A2T) and vice versa (T2A), has recently attracted much research attention. Existing methods typically aggregate information from each modality into a single vector for matching, but this sacrifices local details and can hardly capture intricate relationships within and between modalities. Furthermore, current ATR datasets lack comprehensive alignment information, and simple binary contrastive learning labels overlook the measurement of fine-grained semantic differences between samples. To counter these challenges, we present a novel ATR framework that comprehensively captures the matching relationships of multimodal information from different perspectives and finer granularities. Specifically, a fine-grained alignment method is introduced, achieving a more detail-oriented matching through a multiscale process from local to global levels to capture meticulous cross-modal relationships. In addition, we pioneer the application of cross-modal similarity consistency, leveraging intra-modal similarity relationships as soft supervision to boost more intricate alignment. Extensive experiments validate the effectiveness of our approach, outperforming previous methods by significant margins of at least 3.9% (T2A) / 6.9% (A2T) R@1 on the AudioCaps dataset and 2.9% (T2A) / 5.4% (A2T) R@1 on the Clotho dataset.
CSI Transfer From Sub-6G to mmWave: Reduced-Overhead Multi-User Hybrid Beamforming
Mar 16, 2024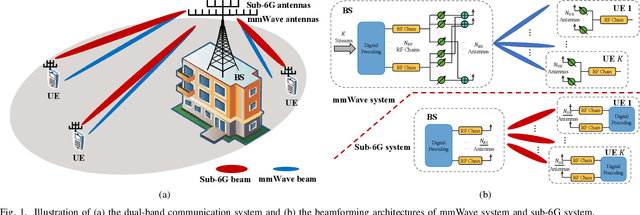
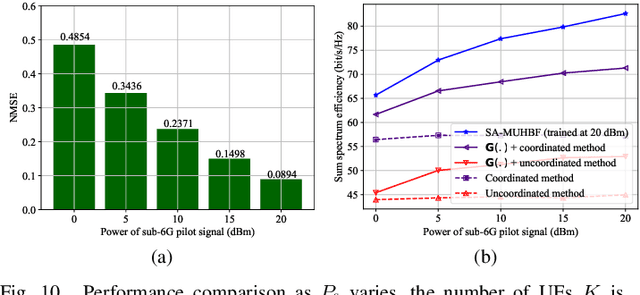
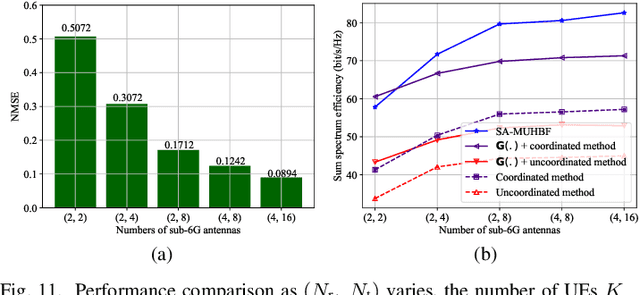
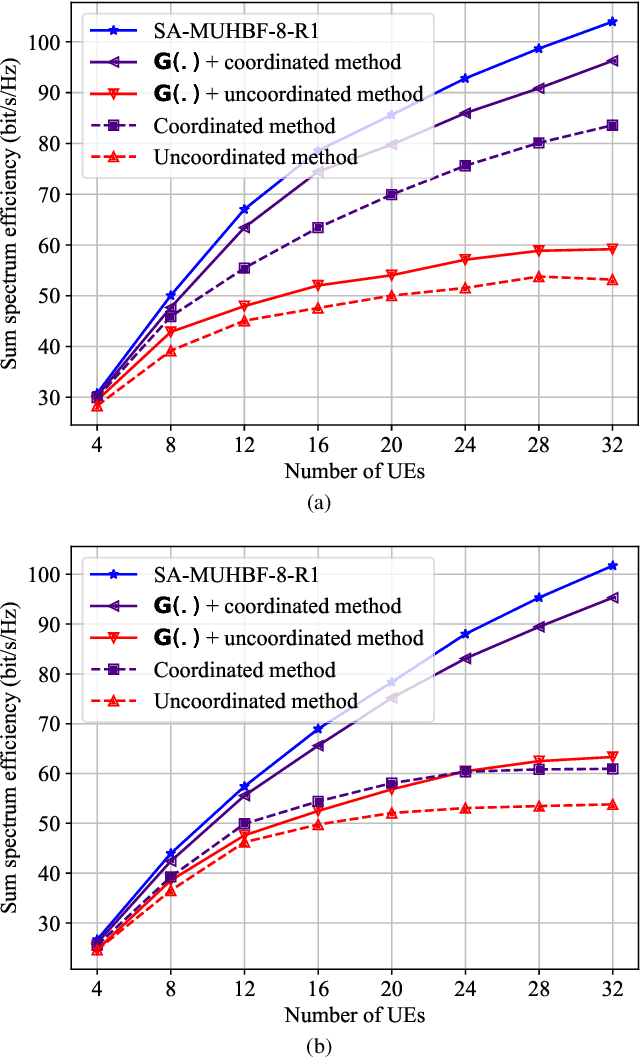
Hybrid beamforming is vital in modern wireless systems, especially for massive MIMO and millimeter-wave deployments, offering efficient directional transmission with reduced hardware complexity. However, effective beamforming in multi-user scenarios relies heavily on accurate channel state information, the acquisition of which often incurs excessive pilot overhead, degrading system performance. To address this and inspired by the spatial congruence between sub-6GHz (sub-6G) and mmWave channels, we propose a Sub-6G information Aided Multi-User Hybrid Beamforming (SA-MUHBF) framework, avoiding excessive use of pilots. SA-MUHBF employs a convolutional neural network to predict mmWave beamspace from sub-6G channel estimate, followed by a novel multi-layer graph neural network for analog beam selection and a linear minimum mean-square error algorithm for digital beamforming. Numerical results demonstrate that SA-MUHBF efficiently predicts the mmWave beamspace representation and achieves superior spectrum efficiency over state-of-the-art benchmarks. Moreover, SA-MUHBF demonstrates robust performance across varied sub-6G system configurations and exhibits strong generalization to unseen scenarios.