 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Analyzing the Domain Shift Immunity of Deep Homography Estimation
Apr 19, 2023
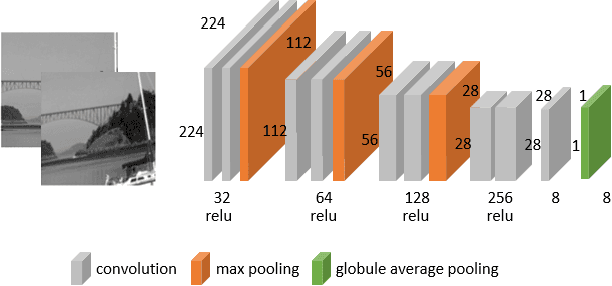



Homography estimation is a basic image-alignment method in many applications. Recently, with the development of convolutional neural networks (CNNs), some learning based approaches have shown great success in this task. However, the performance across different domains has never been researched. Unlike other common tasks (\eg, classification, detection, segmentation), CNN based homography estimation models show a domain shift immunity, which means a model can be trained on one dataset and tested on another without any transfer learning. To explain this unusual performance, we need to determine how CNNs estimate homography. In this study, we first show the domain shift immunity of different deep homography estimation models. We then use a shallow network with a specially designed dataset to analyze the features used for estimation. The results show that networks use low-level texture information to estimate homography. We also design some experiments to compare the performance between different texture densities and image features distorted on some common datasets to demonstrate our findings. Based on these findings, we provide an explanation of the domain shift immunity of deep homography estimation.
MMDR: A Result Feature Fusion Object Detection Approach for Autonomous System
Apr 19, 2023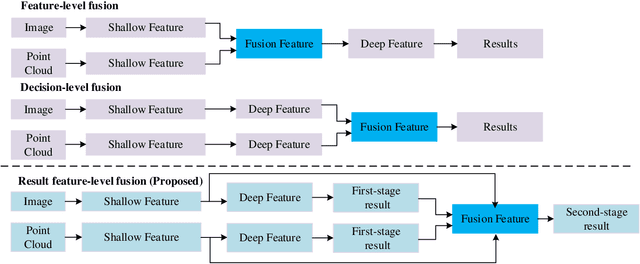



Object detection has been extensively utilized in autonomous systems in recent years, encompassing both 2D and 3D object detection. Recent research in this field has primarily centered around multimodal approaches for addressing this issue.In this paper, a multimodal fusion approach based on result feature-level fusion is proposed. This method utilizes the outcome features generated from single modality sources, and fuses them for downstream tasks.Based on this method, a new post-fusing network is proposed for multimodal object detection, which leverages the single modality outcomes as features. The proposed approach, called Multi-Modal Detector based on Result features (MMDR), is designed to work for both 2D and 3D object detection tasks. Compared to previous multimodal models, the proposed approach in this paper performs feature fusion at a later stage, enabling better representation of the deep-level features of single modality sources. Additionally, the MMDR model incorporates shallow global features during the feature fusion stage, endowing the model with the ability to perceive background information and the overall input, thereby avoiding issues such as missed detections.
Automated Prompting for Non-overlapping Cross-domain Sequential Recommendation
Apr 09, 2023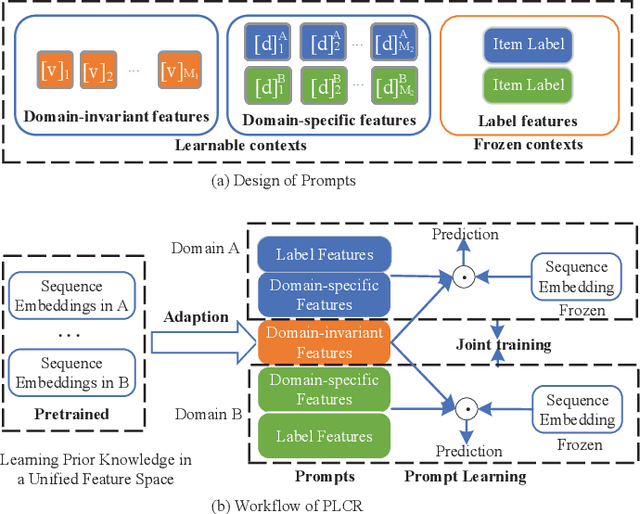
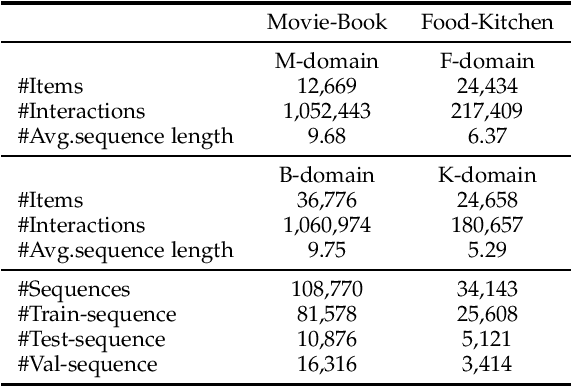
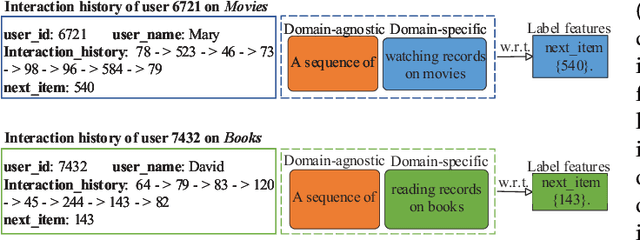
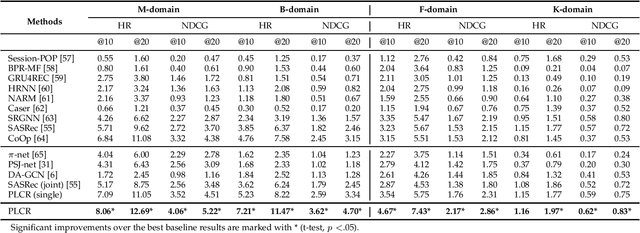
Cross-domain Recommendation (CR) has been extensively studied in recent years to alleviate the data sparsity issue in recommender systems by utilizing different domain information. In this work, we focus on the more general Non-overlapping Cross-domain Sequential Recommendation (NCSR) scenario. NCSR is challenging because there are no overlapped entities (e.g., users and items) between domains, and there is only users' implicit feedback and no content information. Previous CR methods cannot solve NCSR well, since (1) they either need extra content to align domains or need explicit domain alignment constraints to reduce the domain discrepancy from domain-invariant features, (2) they pay more attention to users' explicit feedback (i.e., users' rating data) and cannot well capture their sequential interaction patterns, (3) they usually do a single-target cross-domain recommendation task and seldom investigate the dual-target ones. Considering the above challenges, we propose Prompt Learning-based Cross-domain Recommender (PLCR), an automated prompting-based recommendation framework for the NCSR task. Specifically, to address the challenge (1), PLCR resorts to learning domain-invariant and domain-specific representations via its prompt learning component, where the domain alignment constraint is discarded. For challenges (2) and (3), PLCR introduces a pre-trained sequence encoder to learn users' sequential interaction patterns, and conducts a dual-learning target with a separation constraint to enhance recommendations in both domains. Our empirical study on two sub-collections of Amazon demonstrates the advance of PLCR compared with some related SOTA methods.
Information-guided pixel augmentation for pixel-wise contrastive learning
Nov 14, 2022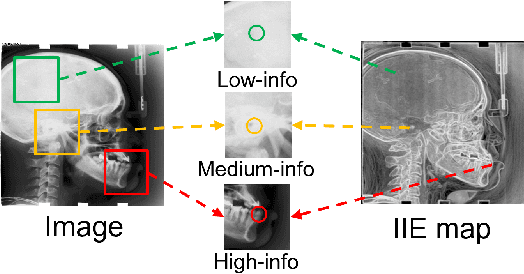
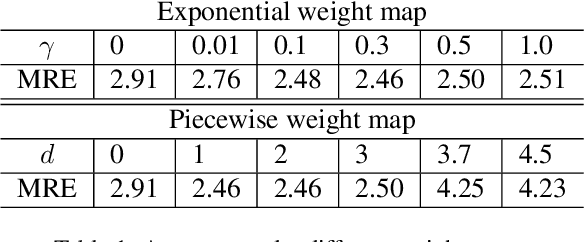
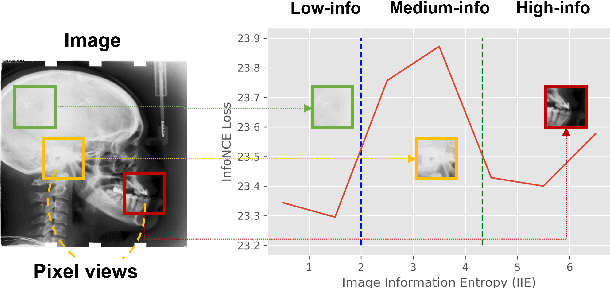

Contrastive learning (CL) is a form of self-supervised learning and has been widely used for various tasks. Different from widely studied instance-level contrastive learning, pixel-wise contrastive learning mainly helps with pixel-wise tasks such as medical landmark detection. The counterpart to an instance in instance-level CL is a pixel, along with its neighboring context, in pixel-wise CL. Aiming to build better feature representation, there is a vast literature about designing instance augmentation strategies for instance-level CL; but there is little similar work on pixel augmentation for pixel-wise CL with a pixel granularity. In this paper, we attempt to bridge this gap. We first classify a pixel into three categories, namely low-, medium-, and high-informative, based on the information quantity the pixel contains. Inspired by the ``InfoMin" principle, we then design separate augmentation strategies for each category in terms of augmentation intensity and sampling ratio. Extensive experiments validate that our information-guided pixel augmentation strategy succeeds in encoding more discriminative representations and surpassing other competitive approaches in unsupervised local feature matching. Furthermore, our pretrained model improves the performance of both one-shot and fully supervised models. To the best of our knowledge, we are the first to propose a pixel augmentation method with a pixel granularity for enhancing unsupervised pixel-wise contrastive learning.
Modeling Fine-grained Information via Knowledge-aware Hierarchical Graph for Zero-shot Entity Retrieval
Nov 20, 2022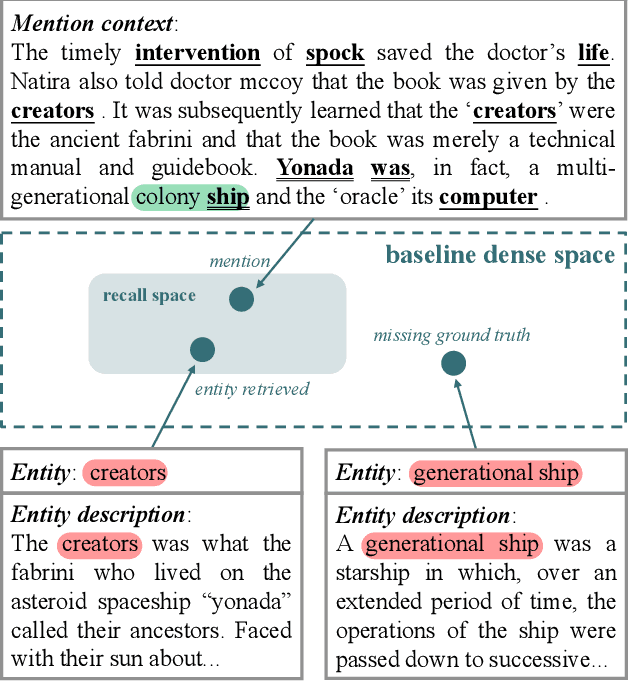
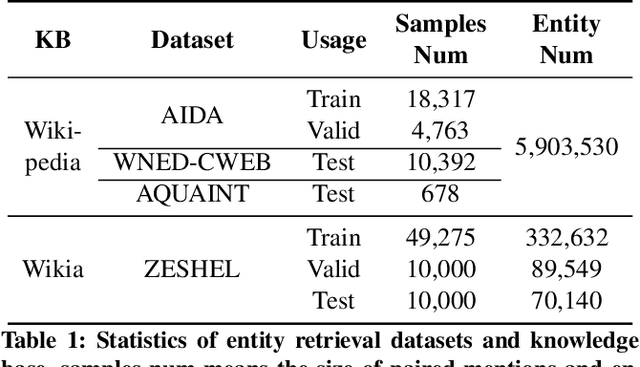
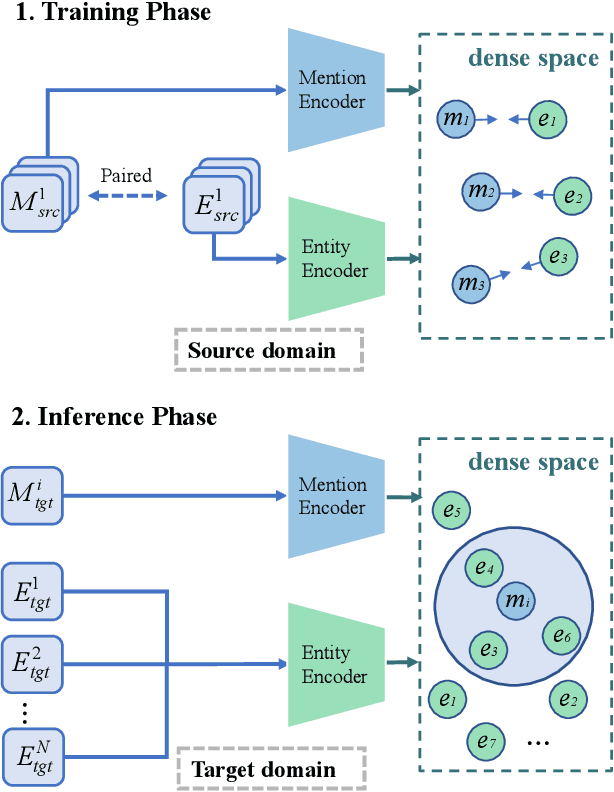
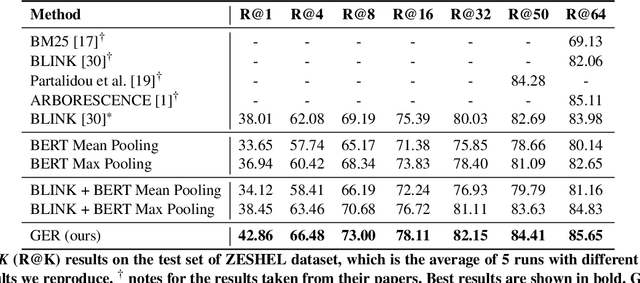
Zero-shot entity retrieval, aiming to link mentions to candidate entities under the zero-shot setting, is vital for many tasks in Natural Language Processing. Most existing methods represent mentions/entities via the sentence embeddings of corresponding context from the Pre-trained Language Model. However, we argue that such coarse-grained sentence embeddings can not fully model the mentions/entities, especially when the attention scores towards mentions/entities are relatively low. In this work, we propose GER, a \textbf{G}raph enhanced \textbf{E}ntity \textbf{R}etrieval framework, to capture more fine-grained information as complementary to sentence embeddings. We extract the knowledge units from the corresponding context and then construct a mention/entity centralized graph. Hence, we can learn the fine-grained information about mention/entity by aggregating information from these knowledge units. To avoid the graph information bottleneck for the central mention/entity node, we construct a hierarchical graph and design a novel Hierarchical Graph Attention Network~(HGAN). Experimental results on popular benchmarks demonstrate that our proposed GER framework performs better than previous state-of-the-art models. The code has been available at https://github.com/wutaiqiang/GER-WSDM2023.
* 9 pages, 5 figures
Minimizing the Age of Information Over an Erasure Channel for Random Packet Arrivals With a Storage Option at the Transmitter
Jan 10, 2023
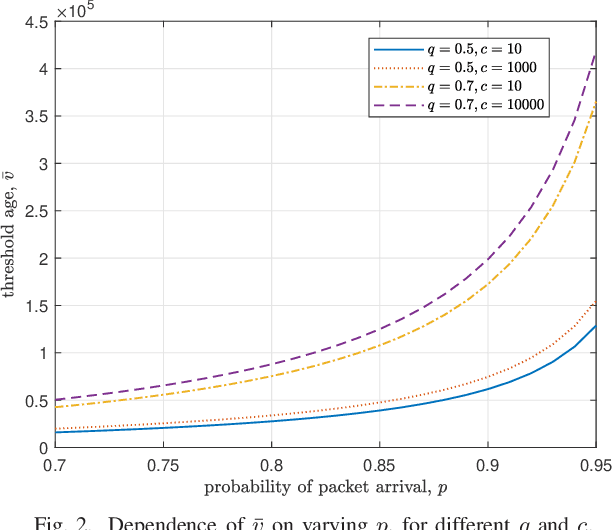
We consider a time slotted communication system consisting of a base station (BS) and a user. At each time slot an update packet arrives at the BS with probability $p$, and the BS successfully transmits the update packet with probability $q$ over an erasure channel. We assume that the BS has a unit size buffer where it can store an update packet upon paying a storage cost $c$. There is a trade-off between the age of information and the storage cost. We formulate this trade-off as a Markov decision process and find an optimal switching type storage policy.
Directional Connectivity-based Segmentation of Medical Images
Mar 31, 2023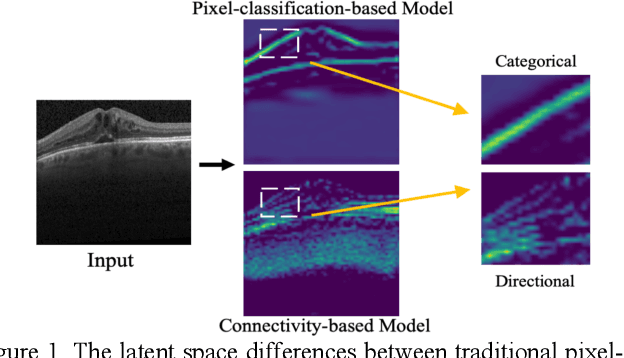
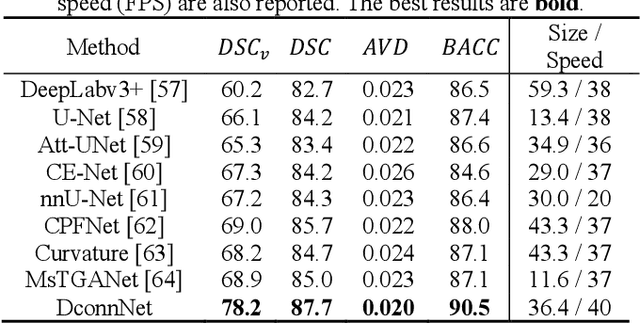
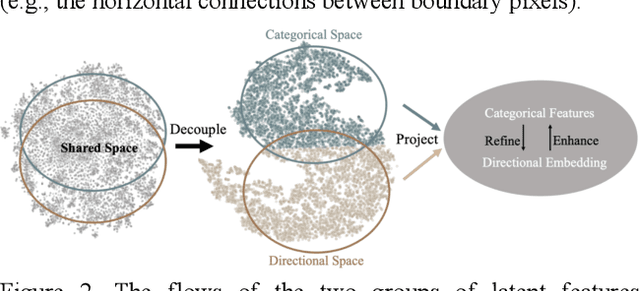
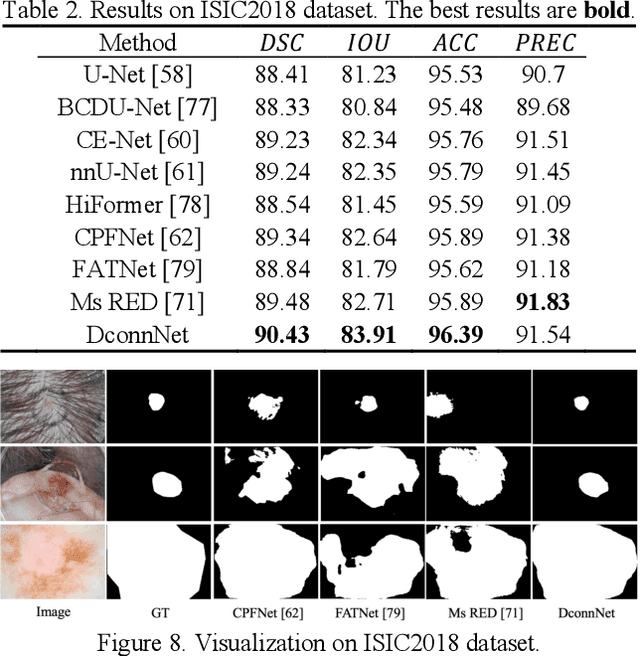
Anatomical consistency in biomarker segmentation is crucial for many medical image analysis tasks. A promising paradigm for achieving anatomically consistent segmentation via deep networks is incorporating pixel connectivity, a basic concept in digital topology, to model inter-pixel relationships. However, previous works on connectivity modeling have ignored the rich channel-wise directional information in the latent space. In this work, we demonstrate that effective disentanglement of directional sub-space from the shared latent space can significantly enhance the feature representation in the connectivity-based network. To this end, we propose a directional connectivity modeling scheme for segmentation that decouples, tracks, and utilizes the directional information across the network. Experiments on various public medical image segmentation benchmarks show the effectiveness of our model as compared to the state-of-the-art methods. Code is available at https://github.com/Zyun-Y/DconnNet.
Co-GRU Enhanced End-to-End Design for Long-haul Coherent Transmission Systems
Apr 23, 2023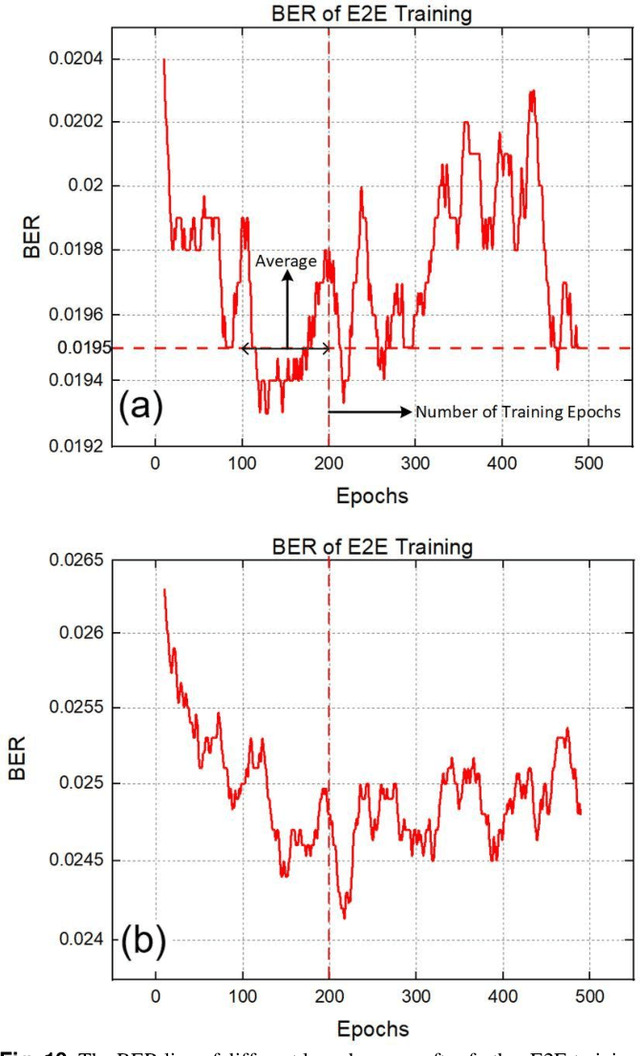
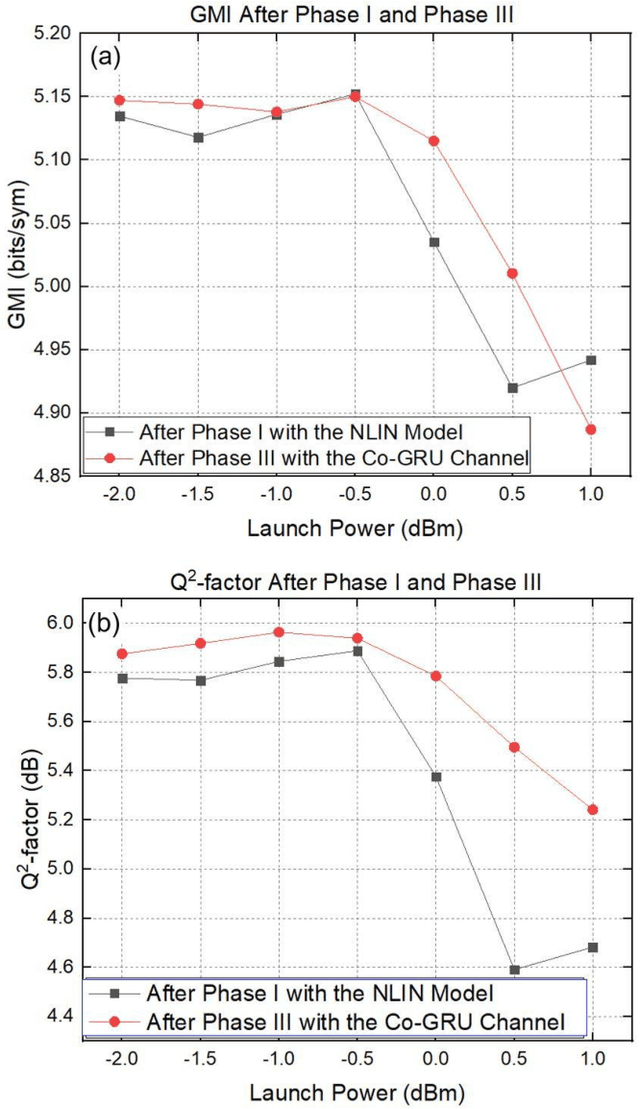
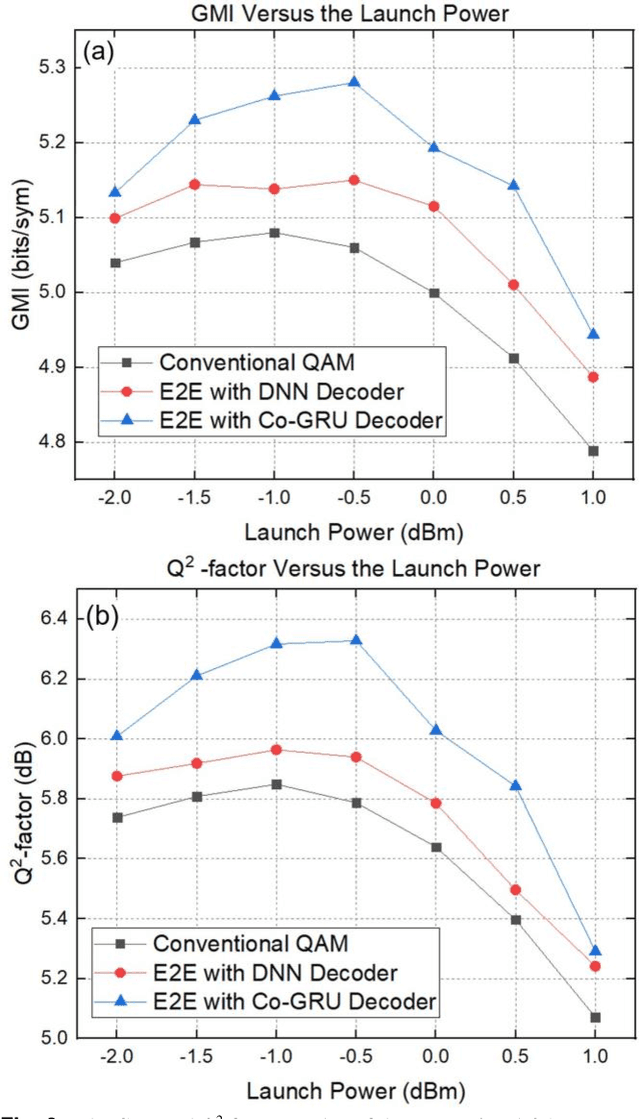
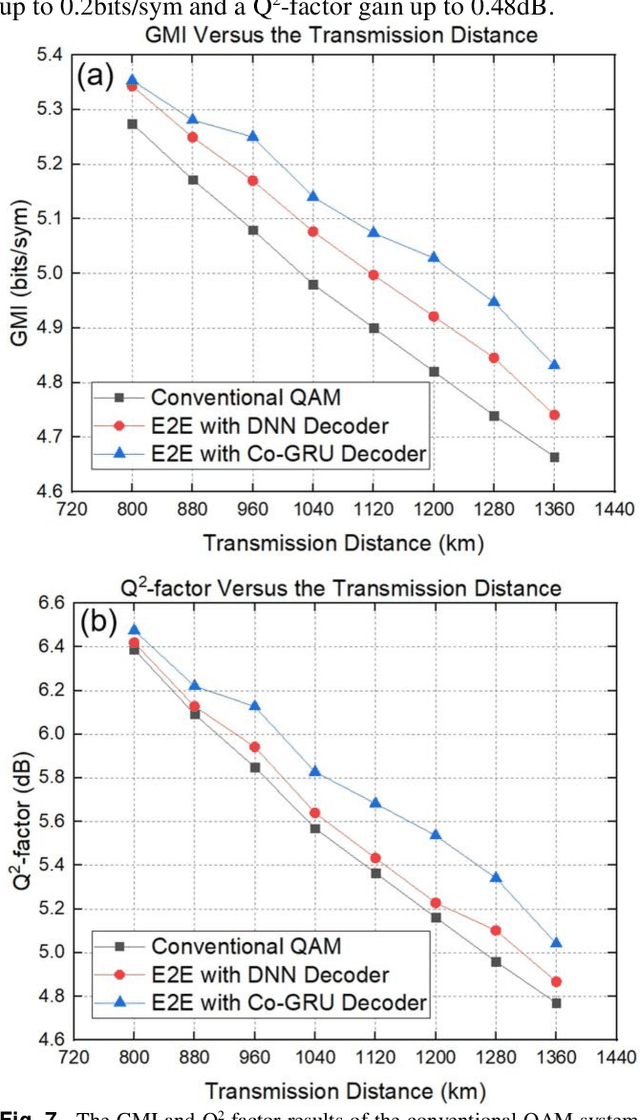
In recent years, the end-to-end (E2E) scheme based on deep learning (DL), jointly optimizes the encoder and decoder parameters located of the system. Since the center-oriented Gated Recurrent Unit (Co-GRU) network structure satisfying gradient BP while having the ability to learn and compensate for intersymbol interference (ISI) with low computation cost, it is adopted for both the channel modeling and decoder implementation in the E2E design scheme proposed. Meanwhile, to obtain the constellation with the symmetrical distribution characteristic, the encoder and decoder are first E2E joint trained through NLIN model, and further trained on the Co-GRU channel replacing the SSFM channel as well as the subsequent digital signal processing (DSP) step. After the E2EDL process, the performance of the encoder and decoder trained is tested on the SSFM channel. For the E2E system with the Co-GRU based decoder, the gain of general mutual information (GMI) and the Q2-factor relative to the conventional QAM system, are respectively improved up to 0.2 bits/sym and 0.48dB for the long-haul 5-channel dual-polarization coherent system with 960 transmission distance at around the optimal launch power point. The work paves the way for the further study of the application for the Co-GRU structure in the data-driven E2E design of the experimental system, both for the channel modeling and the decoder performance improvement.
SPHR-SAR-Net: Superpixel High-resolution SAR Imaging Network Based on Nonlocal Total Variation
Apr 10, 2023
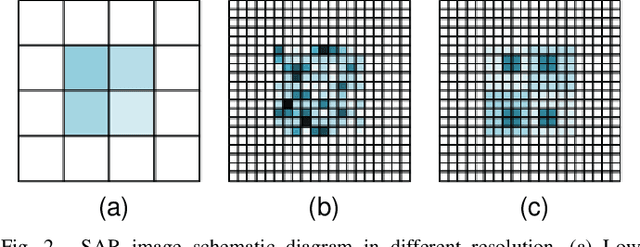
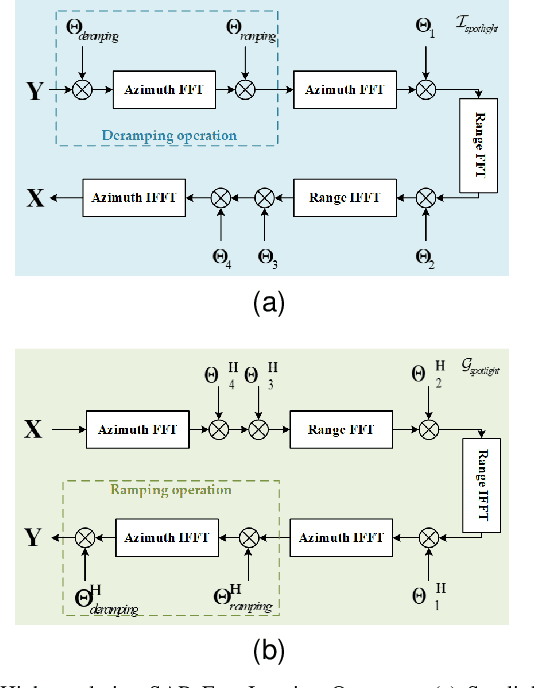

High-resolution is a key trend in the development of synthetic aperture radar (SAR), which enables the capture of fine details and accurate representation of backscattering properties. However, traditional high-resolution SAR imaging algorithms face several challenges. Firstly, these algorithms tend to focus on local information, neglecting non-local information between different pixel patches. Secondly, speckle is more pronounced and difficult to filter out in high-resolution SAR images. Thirdly, the process of high-resolution SAR imaging generally involves high time and computational complexity, making real-time imaging difficult to achieve. To address these issues, we propose a Superpixel High-Resolution SAR Imaging Network (SPHR-SAR-Net) for rapid despeckling in high-resolution SAR mode. Based on the concept of superpixel techniques, we initially combine non-convex and non-local total variation as compound regularization. This approach more effectively despeckles and manages the relationship between pixels while reducing bias effects caused by convex constraints. Subsequently, we solve the compound regularization model using the Alternating Direction Method of Multipliers (ADMM) algorithm and unfold it into a Deep Unfolded Network (DUN). The network's parameters are adaptively learned in a data-driven manner, and the learned network significantly increases imaging speed. Additionally, the Deep Unfolded Network is compatible with high-resolution imaging modes such as spotlight, staring spotlight, and sliding spotlight. In this paper, we demonstrate the superiority of SPHR-SAR-Net through experiments in both simulated and real SAR scenarios. The results indicate that SPHR-SAR-Net can rapidly perform high-resolution SAR imaging from raw echo data, producing accurate imaging results.
Reconstruction-driven Dynamic Refinement based Unsupervised Domain Adaptation for Joint Optic Disc and Cup Segmentation
Apr 10, 2023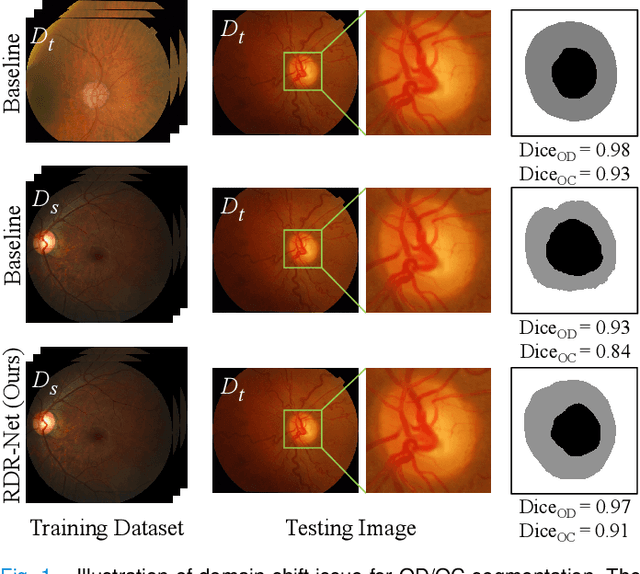
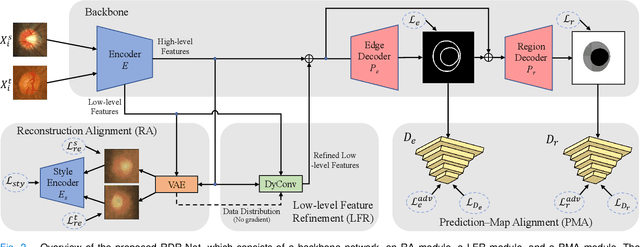
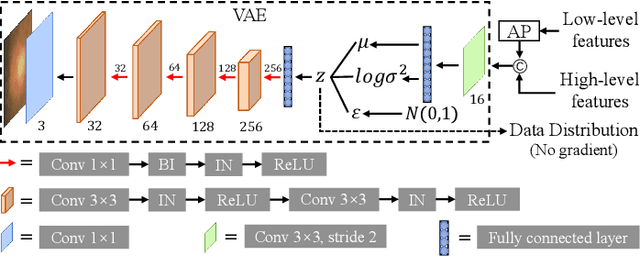
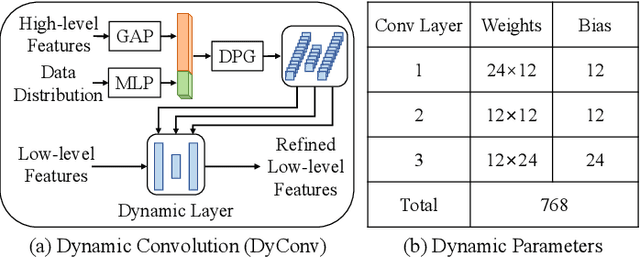
Glaucoma is one of the leading causes of irreversible blindness. Segmentation of optic disc (OD) and optic cup (OC) on fundus images is a crucial step in glaucoma screening. Although many deep learning models have been constructed for this task, it remains challenging to train an OD/OC segmentation model that could be deployed successfully to different healthcare centers. The difficulties mainly comes from the domain shift issue, i.e., the fundus images collected at these centers usually vary greatly in the tone, contrast, and brightness. To address this issue, in this paper, we propose a novel unsupervised domain adaptation (UDA) method called Reconstruction-driven Dynamic Refinement Network (RDR-Net), where we employ a due-path segmentation backbone for simultaneous edge detection and region prediction and design three modules to alleviate the domain gap. The reconstruction alignment (RA) module uses a variational auto-encoder (VAE) to reconstruct the input image and thus boosts the image representation ability of the network in a self-supervised way. It also uses a style-consistency constraint to force the network to retain more domain-invariant information. The low-level feature refinement (LFR) module employs input-specific dynamic convolutions to suppress the domain-variant information in the obtained low-level features. The prediction-map alignment (PMA) module elaborates the entropy-driven adversarial learning to encourage the network to generate source-like boundaries and regions. We evaluated our RDR-Net against state-of-the-art solutions on four public fundus image datasets. Our results indicate that RDR-Net is superior to competing models in both segmentation performance and generalization ability