 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Leveraging Social Interactions to Detect Misinformation on Social Media
Apr 06, 2023
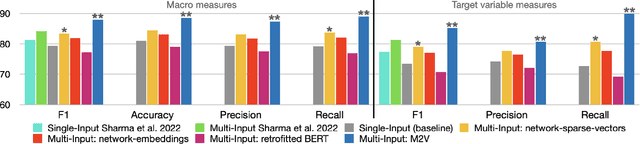
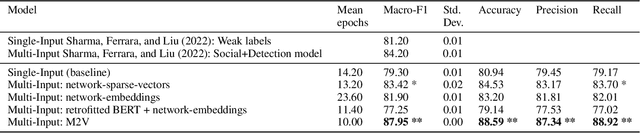
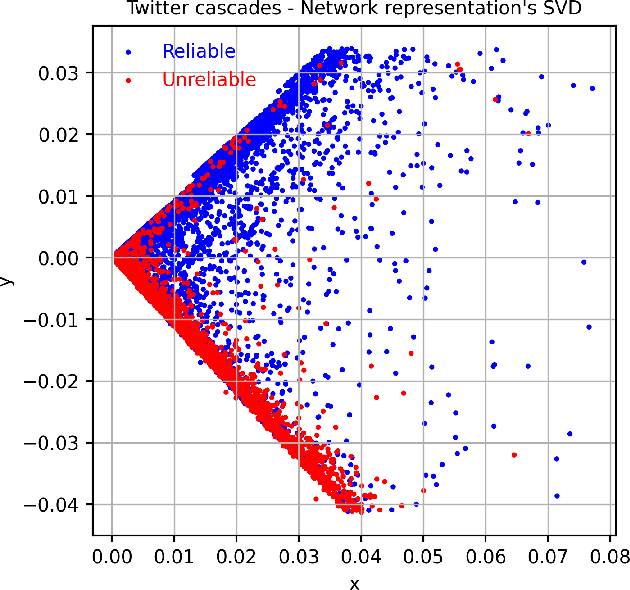
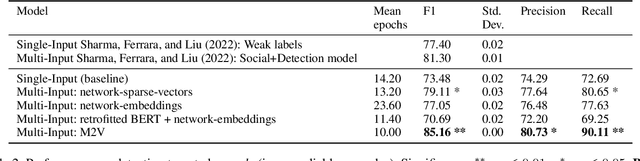
Detecting misinformation threads is crucial to guarantee a healthy environment on social media. We address the problem using the data set created during the COVID-19 pandemic. It contains cascades of tweets discussing information weakly labeled as reliable or unreliable, based on a previous evaluation of the information source. The models identifying unreliable threads usually rely on textual features. But reliability is not just what is said, but by whom and to whom. We additionally leverage on network information. Following the homophily principle, we hypothesize that users who interact are generally interested in similar topics and spreading similar kind of news, which in turn is generally reliable or not. We test several methods to learn representations of the social interactions within the cascades, combining them with deep neural language models in a Multi-Input (MI) framework. Keeping track of the sequence of the interactions during the time, we improve over previous state-of-the-art models.
SoGAR: Self-supervised Spatiotemporal Attention-based Social Group Activity Recognition
Apr 27, 2023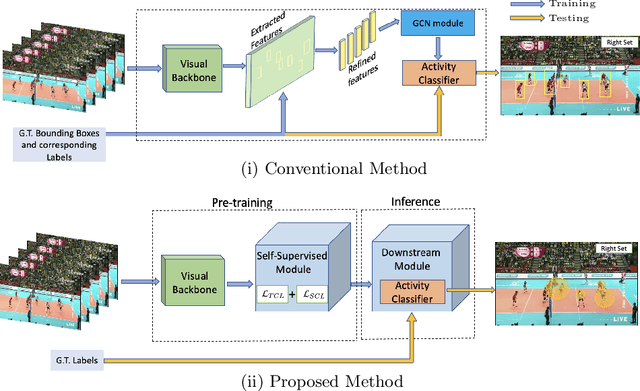
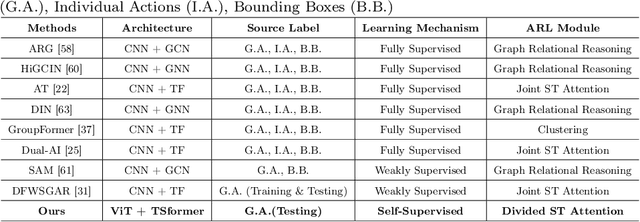
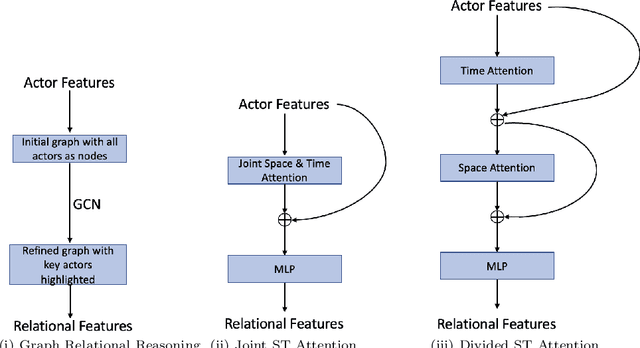
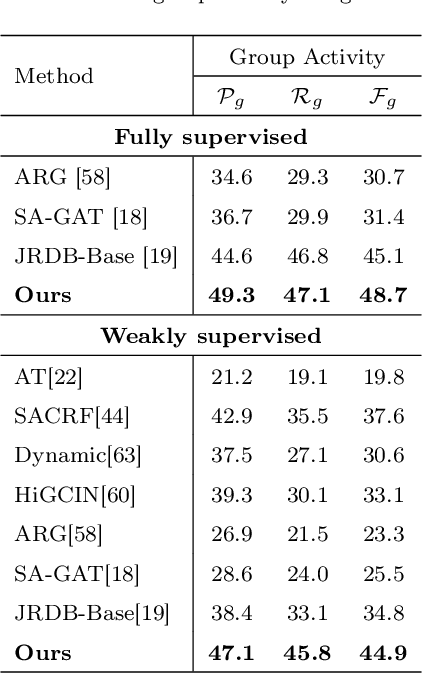
This paper introduces a novel approach to Social Group Activity Recognition (SoGAR) using Self-supervised Transformers network that can effectively utilize unlabeled video data. To extract spatio-temporal information, we create local and global views with varying frame rates. Our self-supervised objective ensures that features extracted from contrasting views of the same video are consistent across spatio-temporal domains. Our proposed approach is efficient in using transformer-based encoders for alleviating the weakly supervised setting of group activity recognition. By leveraging the benefits of transformer models, our approach can model long-term relationships along spatio-temporal dimensions. Our proposed SoGAR method achieves state-of-the-art results on three group activity recognition benchmarks, namely JRDB-PAR, NBA, and Volleyball datasets, surpassing the current state-of-the-art in terms of F1-score, MCA, and MPCA metrics.
CitePrompt: Using Prompts to Identify Citation Intent in Scientific Papers
May 03, 2023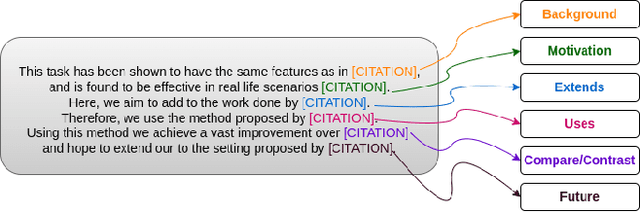
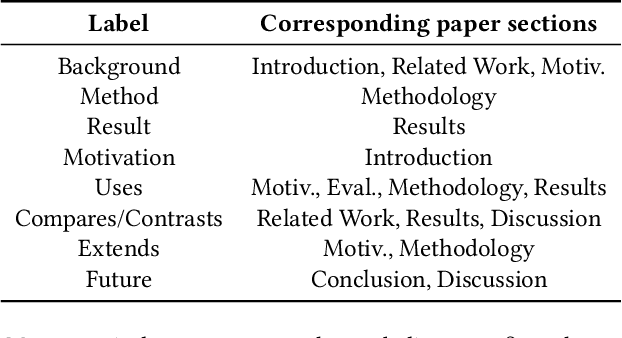
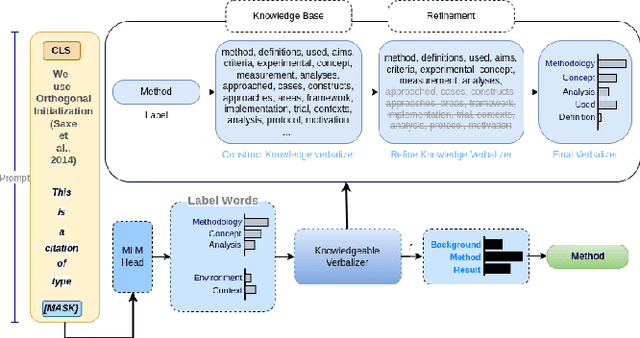

Citations in scientific papers not only help us trace the intellectual lineage but also are a useful indicator of the scientific significance of the work. Citation intents prove beneficial as they specify the role of the citation in a given context. In this paper, we present CitePrompt, a framework which uses the hitherto unexplored approach of prompt-based learning for citation intent classification. We argue that with the proper choice of the pretrained language model, the prompt template, and the prompt verbalizer, we can not only get results that are better than or comparable to those obtained with the state-of-the-art methods but also do it with much less exterior information about the scientific document. We report state-of-the-art results on the ACL-ARC dataset, and also show significant improvement on the SciCite dataset over all baseline models except one. As suitably large labelled datasets for citation intent classification can be quite hard to find, in a first, we propose the conversion of this task to the few-shot and zero-shot settings. For the ACL-ARC dataset, we report a 53.86% F1 score for the zero-shot setting, which improves to 63.61% and 66.99% for the 5-shot and 10-shot settings, respectively.
Zenseact Open Dataset: A large-scale and diverse multimodal dataset for autonomous driving
May 03, 2023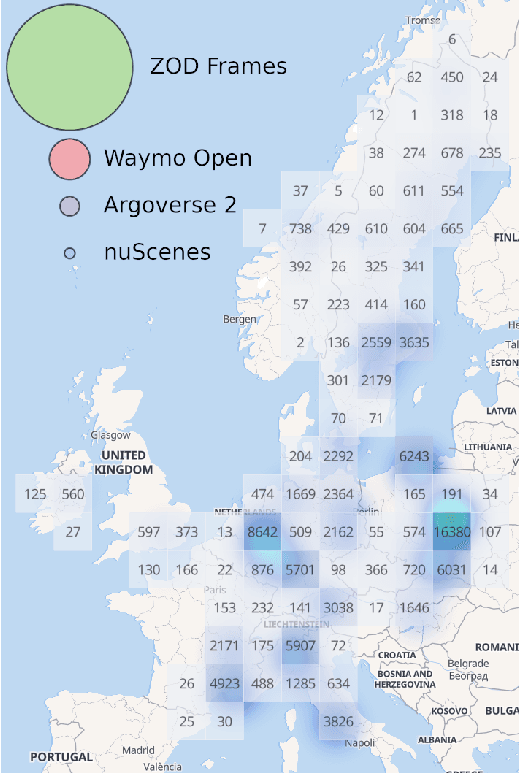
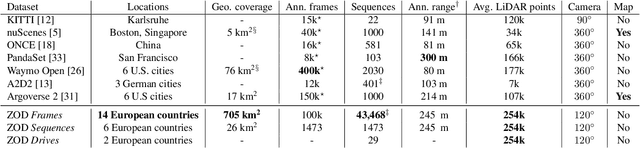

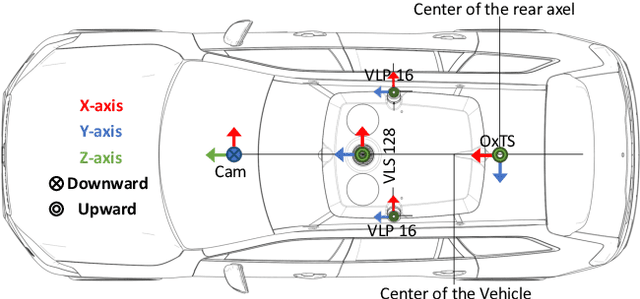
Existing datasets for autonomous driving (AD) often lack diversity and long-range capabilities, focusing instead on 360{\deg} perception and temporal reasoning. To address this gap, we introduce Zenseact Open Dataset (ZOD), a large-scale and diverse multimodal dataset collected over two years in various European countries, covering an area 9x that of existing datasets. ZOD boasts the highest range and resolution sensors among comparable datasets, coupled with detailed keyframe annotations for 2D and 3D objects (up to 245m), road instance/semantic segmentation, traffic sign recognition, and road classification. We believe that this unique combination will facilitate breakthroughs in long-range perception and multi-task learning. The dataset is composed of Frames, Sequences, and Drives, designed to encompass both data diversity and support for spatio-temporal learning, sensor fusion, localization, and mapping. Frames consist of 100k curated camera images with two seconds of other supporting sensor data, while the 1473 Sequences and 29 Drives include the entire sensor suite for 20 seconds and a few minutes, respectively. ZOD is the only large-scale AD dataset released under a permissive license, allowing for both research and commercial use. The dataset is accompanied by an extensive development kit. Data and more information are available online (https://zod.zenseact.com).
A Multi-step Dynamics Modeling Framework For Autonomous Driving In Multiple Environments
May 03, 2023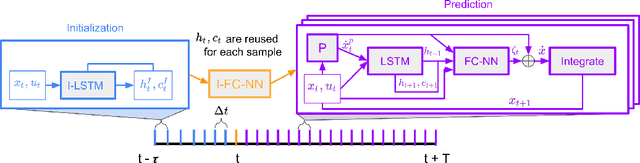
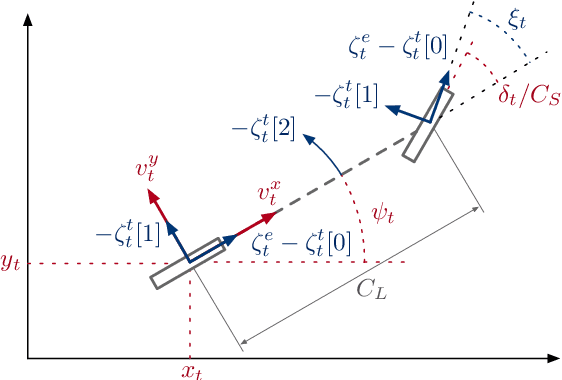

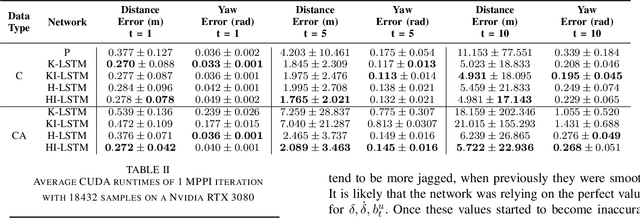
Modeling dynamics is often the first step to making a vehicle autonomous. While on-road autonomous vehicles have been extensively studied, off-road vehicles pose many challenging modeling problems. An off-road vehicle encounters highly complex and difficult-to-model terrain/vehicle interactions, as well as having complex vehicle dynamics of its own. These complexities can create challenges for effective high-speed control and planning. In this paper, we introduce a framework for multistep dynamics prediction that explicitly handles the accumulation of modeling error and remains scalable for sampling-based controllers. Our method uses a specially-initialized Long Short-Term Memory (LSTM) over a limited time horizon as the learned component in a hybrid model to predict the dynamics of a 4-person seating all-terrain vehicle (Polaris S4 1000 RZR) in two distinct environments. By only having the LSTM predict over a fixed time horizon, we negate the need for long term stability that is often a challenge when training recurrent neural networks. Our framework is flexible as it only requires odometry information for labels. Through extensive experimentation, we show that our method is able to predict millions of possible trajectories in real-time, with a time horizon of five seconds in challenging off road driving scenarios.
Multi-user Goal-oriented Communications with Energy-efficient Edge Resource Management
May 03, 2023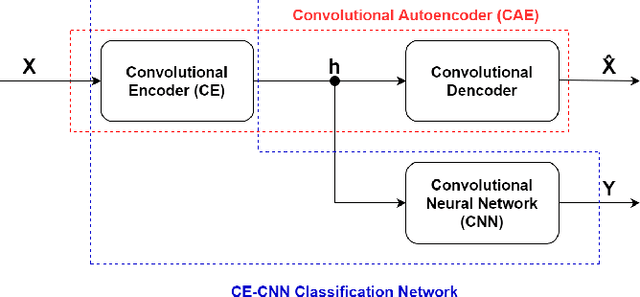
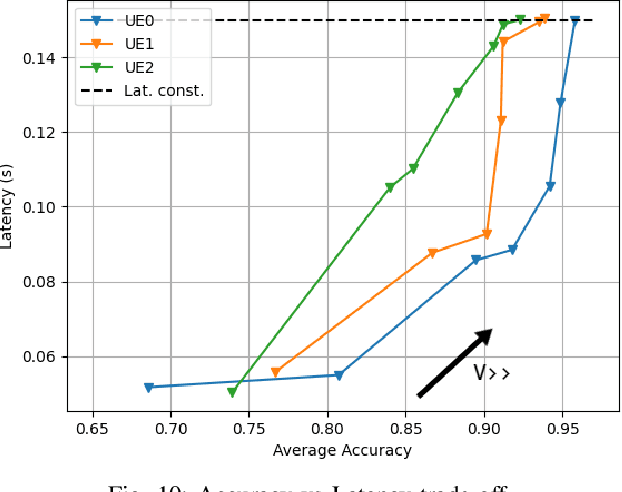
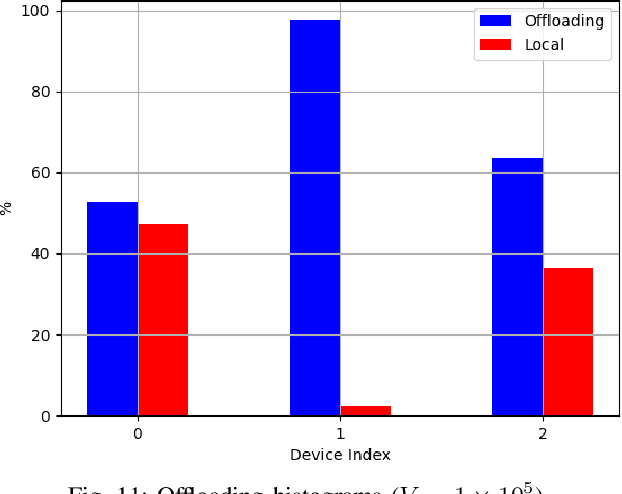
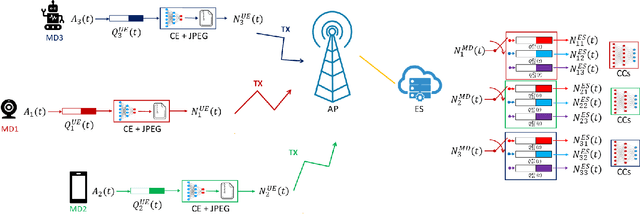
Edge Learning (EL) pushes the computational resources toward the edge of 5G/6G network to assist mobile users requesting delay-sensitive and energy-aware intelligent services. A common challenge in running inference tasks from remote is to extract and transmit only the features that are most significant for the inference task. From this perspective, EL can be effectively coupled with goal-oriented communications, whose aim is to transmit only the information {\it relevant} to perform the inference task, under prescribed accuracy, delay, and energy constraints. In this work, we consider a multi-user/single server wireless network, where the users can opportunistically decide whether to perform the inference task by themselves or, alternatively, to offload the data to the edge server for remote processing. The data to be transmitted undergoes a goal-oriented compression stage performed using a convolutional encoder, jointly trained with a convolutional decoder running at the edge-server side. Employing Lyapunov optimization, we propose a method to jointly and dynamically optimize the selection of the most suitable encoding/decoding scheme, together with the allocation of computational and transmission resources, across all the users and the edge server. Extensive simulations confirm the effectiveness of the proposed approaches and highlight the trade-offs between energy, latency, and learning accuracy.
Quantifying the Dissimilarity of Texts
May 03, 2023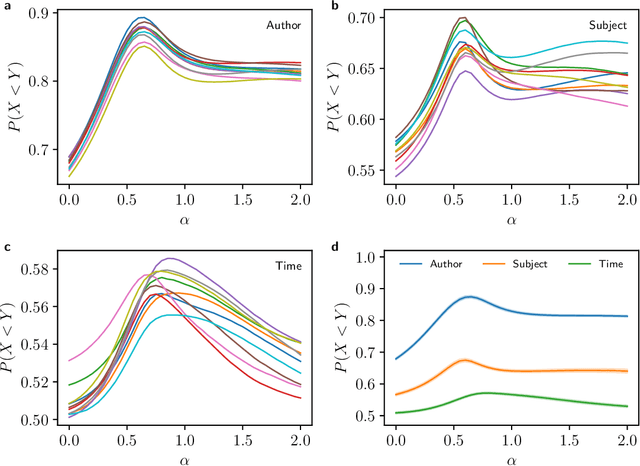
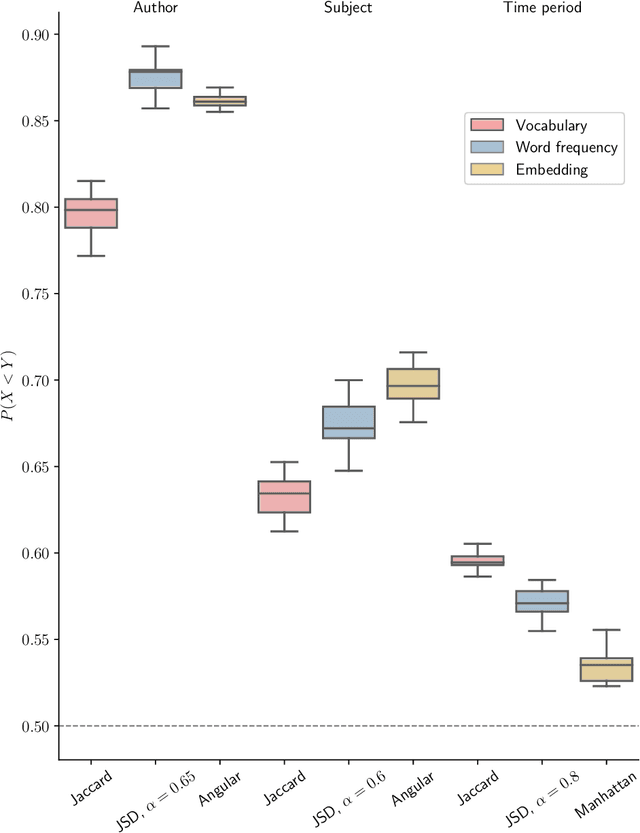
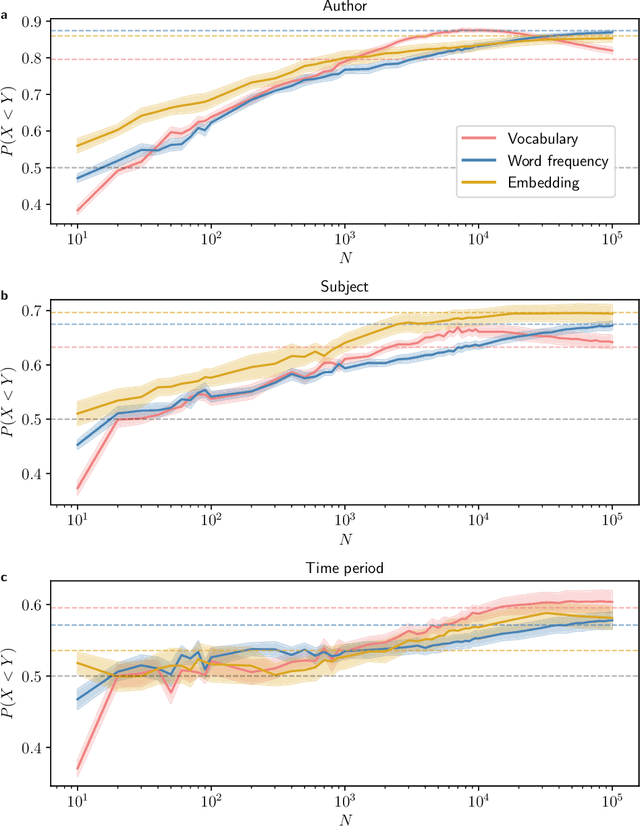
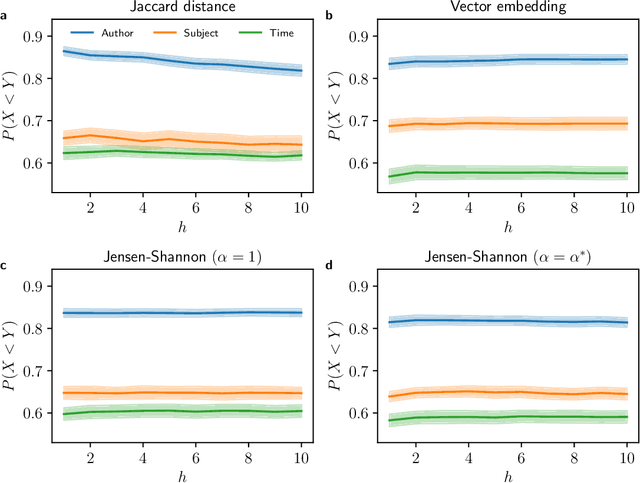
Quantifying the dissimilarity of two texts is an important aspect of a number of natural language processing tasks, including semantic information retrieval, topic classification, and document clustering. In this paper, we compared the properties and performance of different dissimilarity measures $D$ using three different representations of texts -- vocabularies, word frequency distributions, and vector embeddings -- and three simple tasks -- clustering texts by author, subject, and time period. Using the Project Gutenberg database, we found that the generalised Jensen--Shannon divergence applied to word frequencies performed strongly across all tasks, that $D$'s based on vector embedding representations led to stronger performance for smaller texts, and that the optimal choice of approach was ultimately task-dependent. We also investigated, both analytically and numerically, the behaviour of the different $D$'s when the two texts varied in length by a factor $h$. We demonstrated that the (natural) estimator of the Jaccard distance between vocabularies was inconsistent and computed explicitly the $h$-dependency of the bias of the estimator of the generalised Jensen--Shannon divergence applied to word frequencies. We also found numerically that the Jensen--Shannon divergence and embedding-based approaches were robust to changes in $h$, while the Jaccard distance was not.
* 16 pages, 4 figures, part of the Special Issue Novel Methods and Applications in Natural Language Processing
Inference at Scale Significance Testing for Large Search and Recommendation Experiments
May 03, 2023
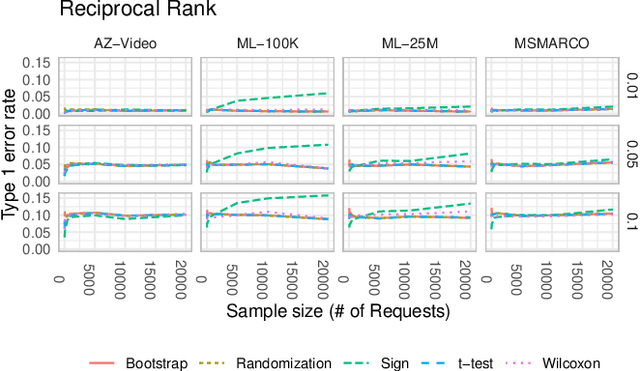
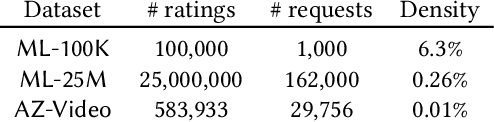
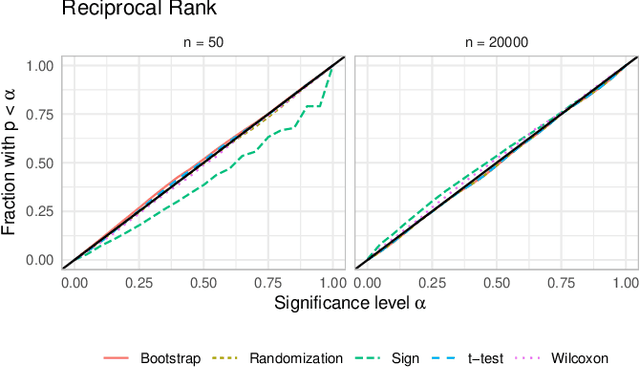
A number of information retrieval studies have been done to assess which statistical techniques are appropriate for comparing systems. However, these studies are focused on TREC-style experiments, which typically have fewer than 100 topics. There is no similar line of work for large search and recommendation experiments; such studies typically have thousands of topics or users and much sparser relevance judgements, so it is not clear if recommendations for analyzing traditional TREC experiments apply to these settings. In this paper, we empirically study the behavior of significance tests with large search and recommendation evaluation data. Our results show that the Wilcoxon and Sign tests show significantly higher Type-1 error rates for large sample sizes than the bootstrap, randomization and t-tests, which were more consistent with the expected error rate. While the statistical tests displayed differences in their power for smaller sample sizes, they showed no difference in their power for large sample sizes. We recommend the sign and Wilcoxon tests should not be used to analyze large scale evaluation results. Our result demonstrate that with Top-N recommendation and large search evaluation data, most tests would have a 100% chance of finding statistically significant results. Therefore, the effect size should be used to determine practical or scientific significance.
An Instance Segmentation Dataset of Yeast Cells in Microstructures
Apr 23, 2023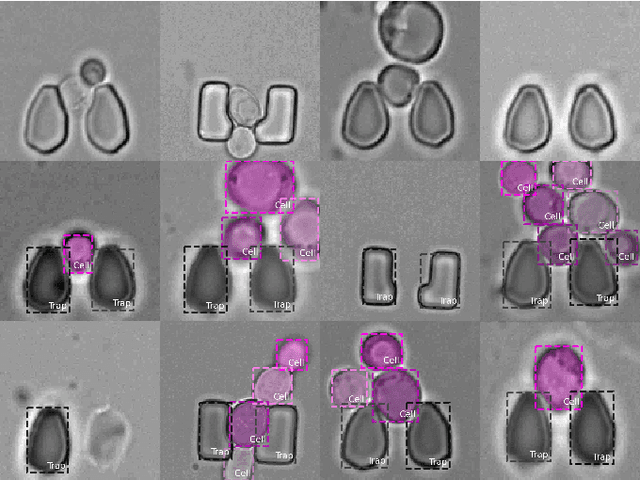
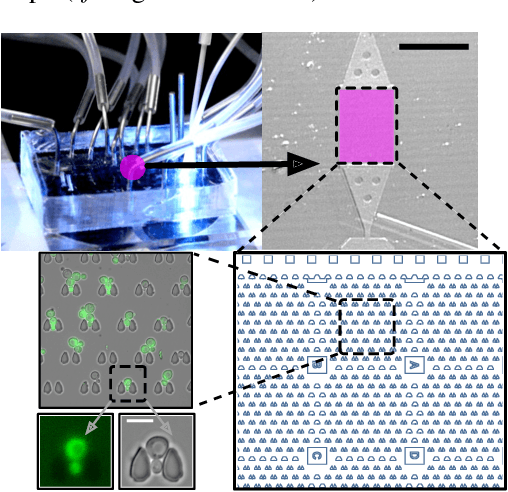
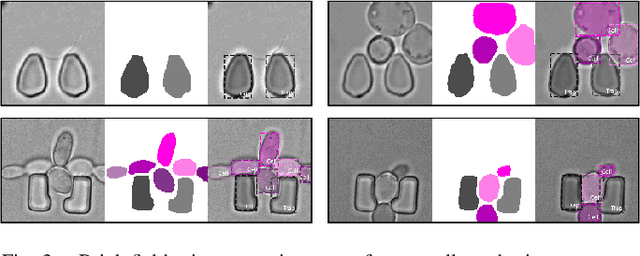
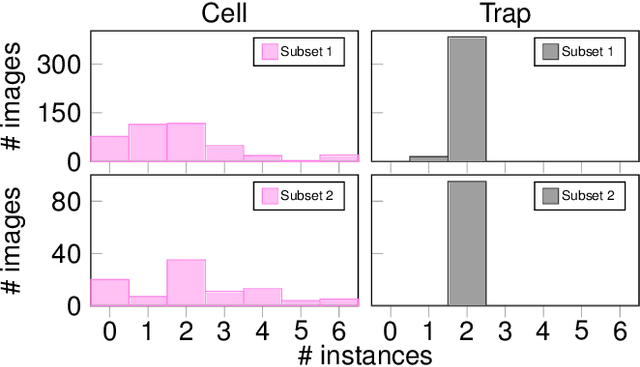
Extracting single-cell information from microscopy data requires accurate instance-wise segmentations. Obtaining pixel-wise segmentations from microscopy imagery remains a challenging task, especially with the added complexity of microstructured environments. This paper presents a novel dataset for segmenting yeast cells in microstructures. We offer pixel-wise instance segmentation labels for both cells and trap microstructures. In total, we release 493 densely annotated microscopy images. To facilitate a unified comparison between novel segmentation algorithms, we propose a standardized evaluation strategy for our dataset. The aim of the dataset and evaluation strategy is to facilitate the development of new cell segmentation approaches. The dataset is publicly available at https://christophreich1996.github.io/yeast_in_microstructures_dataset/ .
System Identification with Copula Entropy
Apr 23, 2023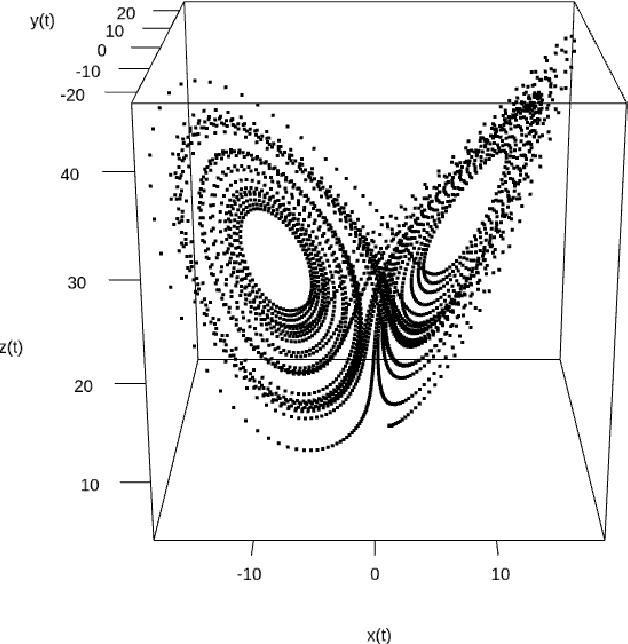
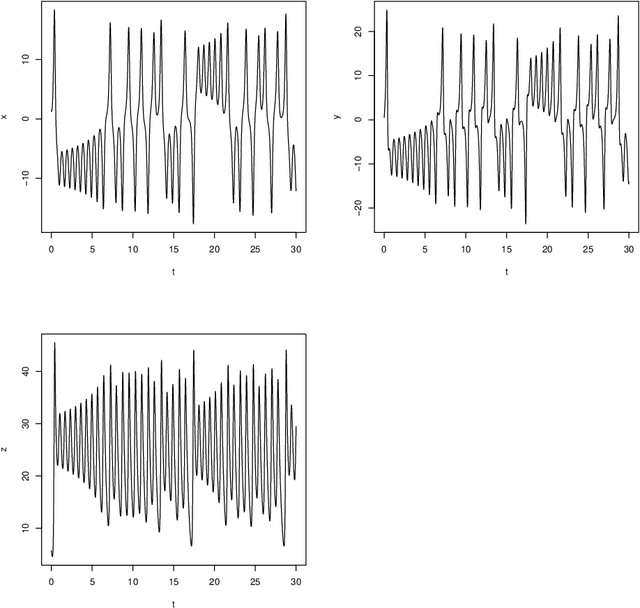
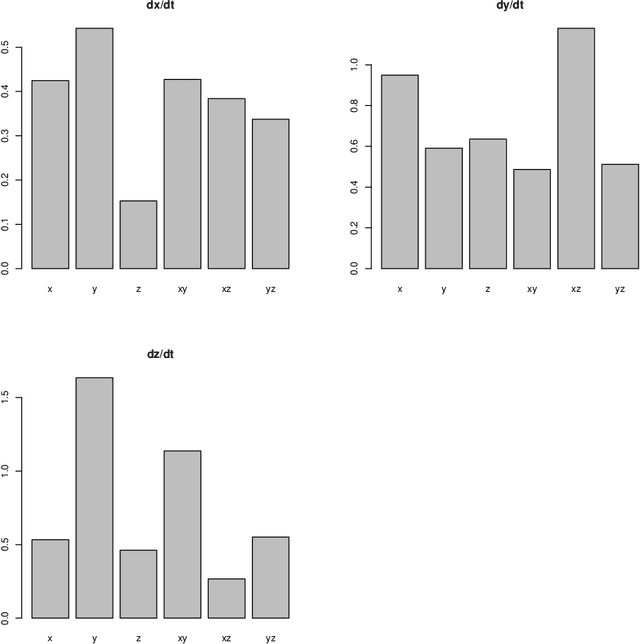
Identifying differential equation governing dynamical system is an important problem with wide applications. Copula Entropy (CE) is a mathematical concept for measuring statistical independence in information theory. In this paper we propose a method for identifying differential equation of dynamical systems with CE. The problem is considered as a variable selection problem and solved with the previously proposed CE-based method for variable selection. The proposed method composed of two components: the difference operator and the CE estimator. Since both components can be done non-parametrically, the proposed method is therefore model-free and hyperparameter-free. The simulation experiment with the 3D Lorenz system verified the effectiveness of the proposed method.