 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Energy-Efficient Lane Changes Planning and Control for Connected Autonomous Vehicles on Urban Roads
Apr 17, 2023
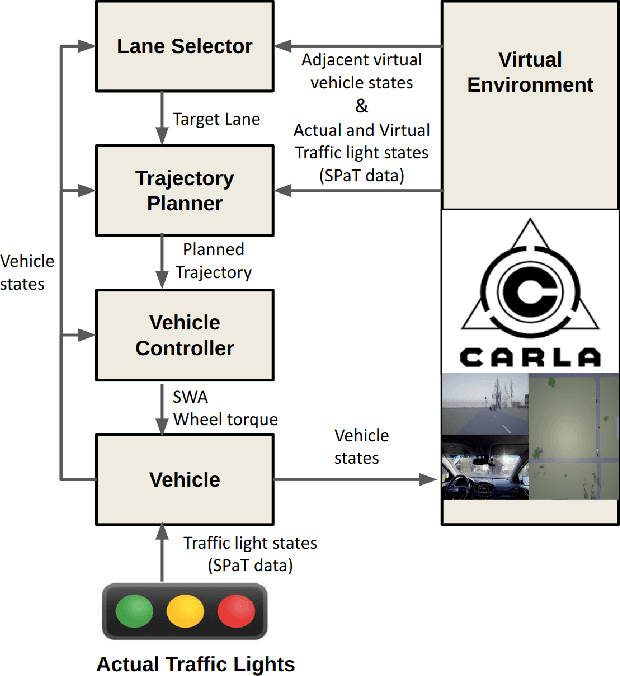
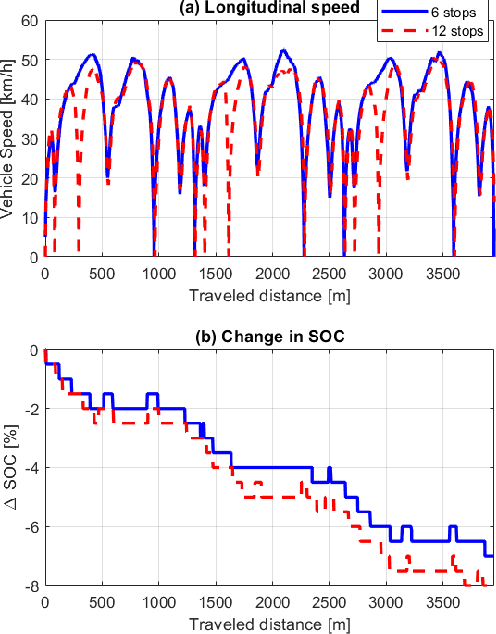
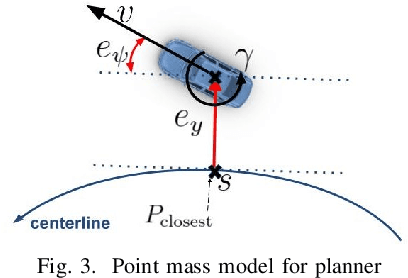
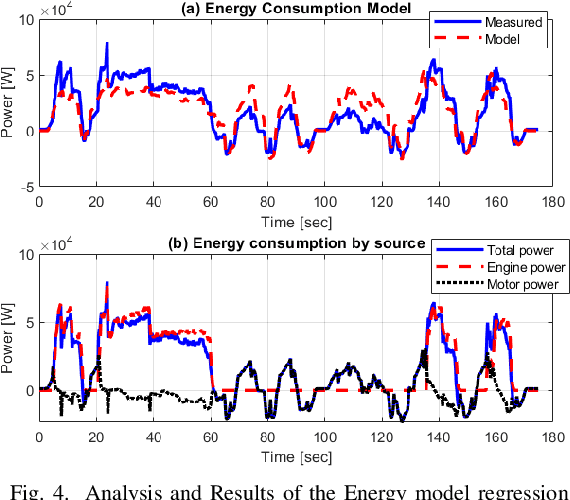
This paper presents a novel energy-efficient motion planning algorithm for Connected Autonomous Vehicles (CAVs) on urban roads. The approach consists of two components: a decision-making algorithm and an optimization-based trajectory planner. The decision-making algorithm leverages Signal Phase and Timing (SPaT) information from connected traffic lights to select a lane with the aim of reducing energy consumption. The algorithm is based on a heuristic rule which is learned from human driving data. The optimization-based trajectory planner generates a safe, smooth, and energy-efficient trajectory toward the selected lane. The proposed strategy is experimentally evaluated in a Vehicle-in-the-Loop (VIL) setting, where a real test vehicle receives SPaT information from both actual and virtual traffic lights and autonomously drives on a testing site, while the surrounding vehicles are simulated. The results demonstrate that the use of SPaT information in autonomous driving leads to improved energy efficiency, with the proposed strategy saving 37.1% energy consumption compared to a lane-keeping algorithm.
Causalainer: Causal Explainer for Automatic Video Summarization
Apr 30, 2023
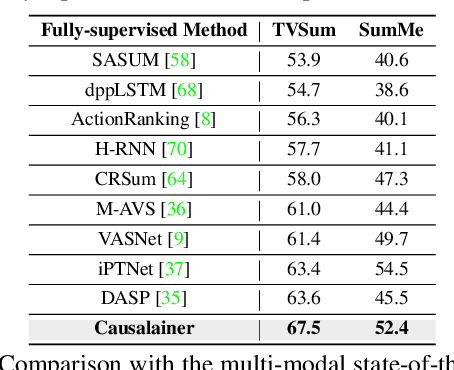
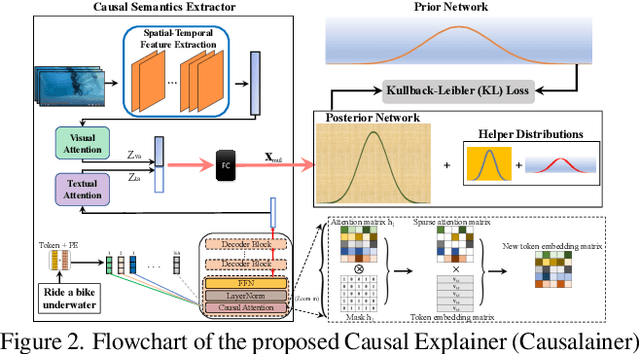
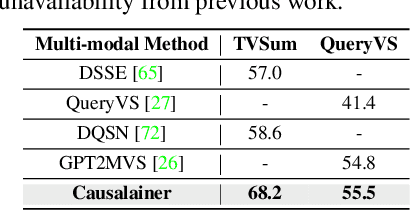
The goal of video summarization is to automatically shorten videos such that it conveys the overall story without losing relevant information. In many application scenarios, improper video summarization can have a large impact. For example in forensics, the quality of the generated video summary will affect an investigator's judgment while in journalism it might yield undesired bias. Because of this, modeling explainability is a key concern. One of the best ways to address the explainability challenge is to uncover the causal relations that steer the process and lead to the result. Current machine learning-based video summarization algorithms learn optimal parameters but do not uncover causal relationships. Hence, they suffer from a relative lack of explainability. In this work, a Causal Explainer, dubbed Causalainer, is proposed to address this issue. Multiple meaningful random variables and their joint distributions are introduced to characterize the behaviors of key components in the problem of video summarization. In addition, helper distributions are introduced to enhance the effectiveness of model training. In visual-textual input scenarios, the extra input can decrease the model performance. A causal semantics extractor is designed to tackle this issue by effectively distilling the mutual information from the visual and textual inputs. Experimental results on commonly used benchmarks demonstrate that the proposed method achieves state-of-the-art performance while being more explainable.
Constructing a Knowledge Graph from Textual Descriptions of Software Vulnerabilities in the National Vulnerability Database
Apr 30, 2023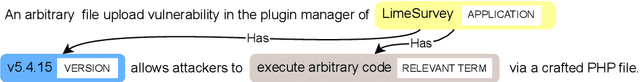
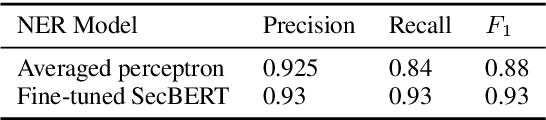

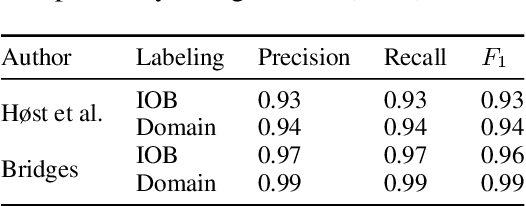
Knowledge graphs have shown promise for several cybersecurity tasks, such as vulnerability assessment and threat analysis. In this work, we present a new method for constructing a vulnerability knowledge graph from information in the National Vulnerability Database (NVD). Our approach combines named entity recognition (NER), relation extraction (RE), and entity prediction using a combination of neural models, heuristic rules, and knowledge graph embeddings. We demonstrate how our method helps to fix missing entities in knowledge graphs used for cybersecurity and evaluate the performance.
Towards Zero-Shot Personalized Table-to-Text Generation with Contrastive Persona Distillation
Apr 18, 2023

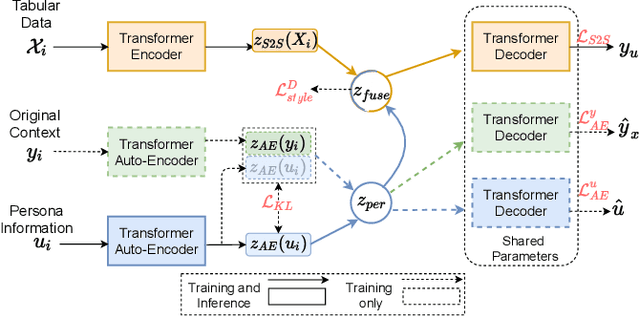
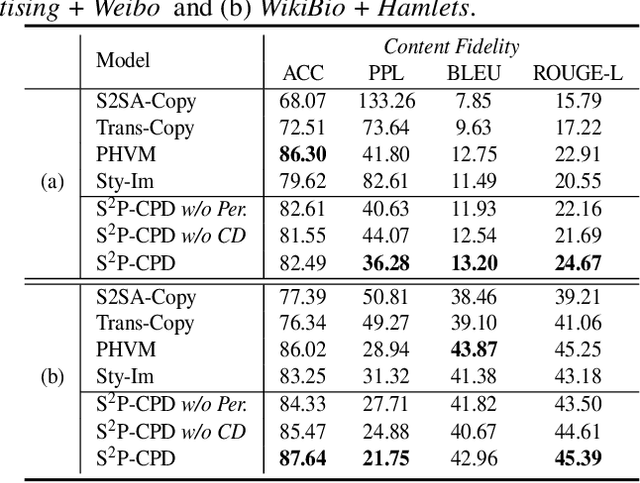
Existing neural methods have shown great potentials towards generating informative text from structured tabular data as well as maintaining high content fidelity. However, few of them shed light on generating personalized expressions, which often requires well-aligned persona-table-text datasets that are difficult to obtain. To overcome these obstacles, we explore personalized table-to-text generation under a zero-shot setting, by assuming no well-aligned persona-table-text triples are required during training. To this end, we firstly collect a set of unpaired persona information and then propose a semi-supervised approach with contrastive persona distillation (S2P-CPD) to generate personalized context. Specifically, tabular data and persona information are firstly represented as latent variables separately. Then, we devise a latent space fusion technique to distill persona information into the table representation. Besides, a contrastive-based discriminator is employed to guarantee the style consistency between the generated context and its corresponding persona. Experimental results on two benchmarks demonstrate S2P-CPD's ability on keeping both content fidelity and personalized expressions.
A New Quantum Dempster Rule of Combination
Apr 28, 2023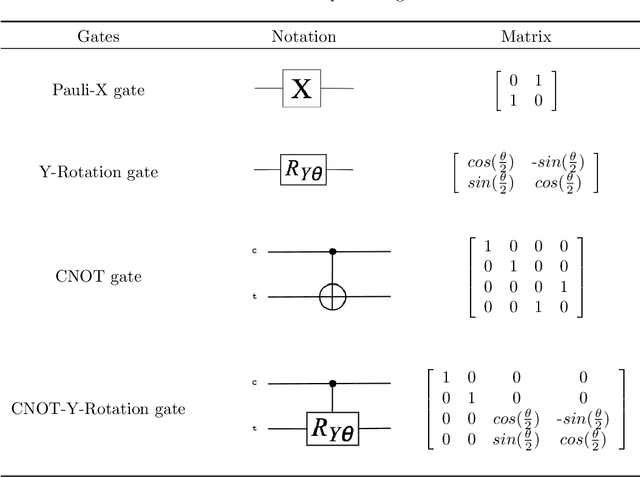
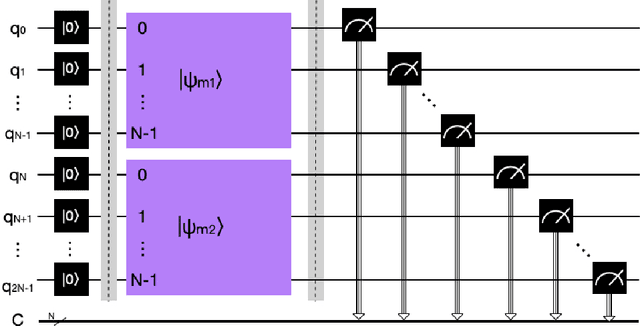
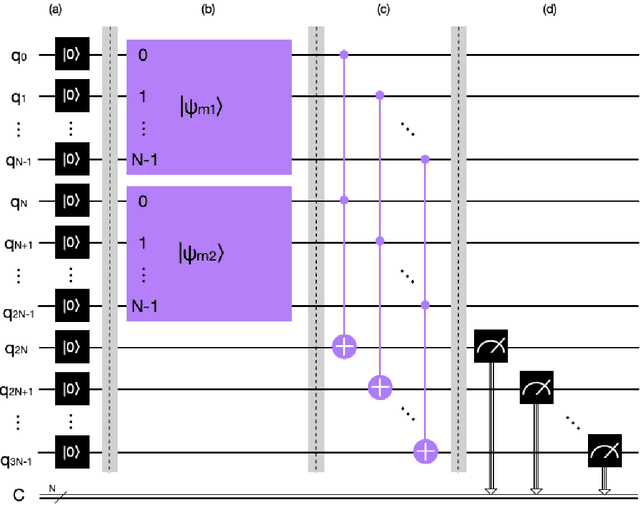
Dempster rule of combination (DRC) is widely used for uncertainty reasoning in intelligent information system, which is generalized to complex domain recently. However, as the increase of identification framework elements, the computational complexity of Dempster Rule of Combination increases exponentially. To address this issue, we propose a novel quantum Dempster rule of combination (QDRC) by means of Toffoli gate. The QDRC combination process is completely implemented using quantum circuits.
HIORE: Leveraging High-order Interactions for Unified Entity Relation Extraction
May 07, 2023
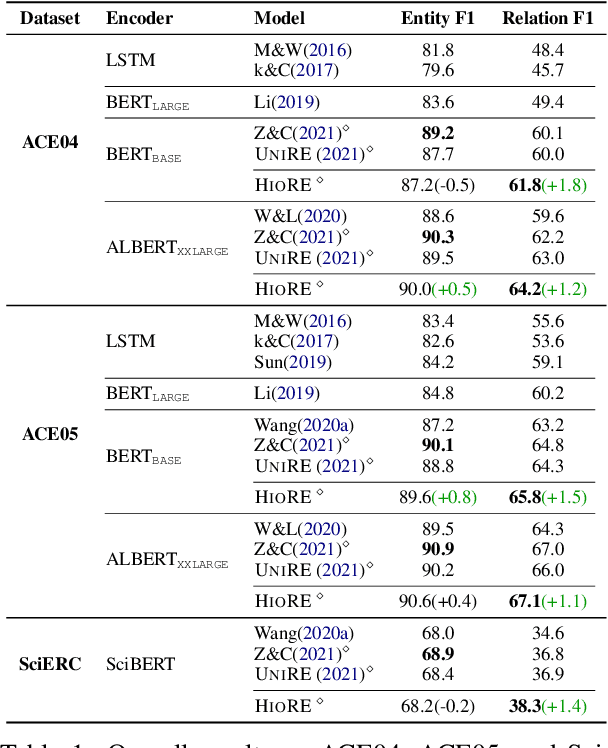
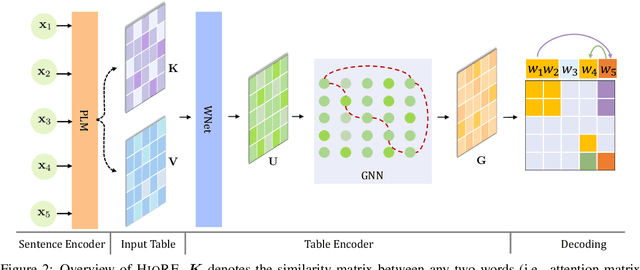
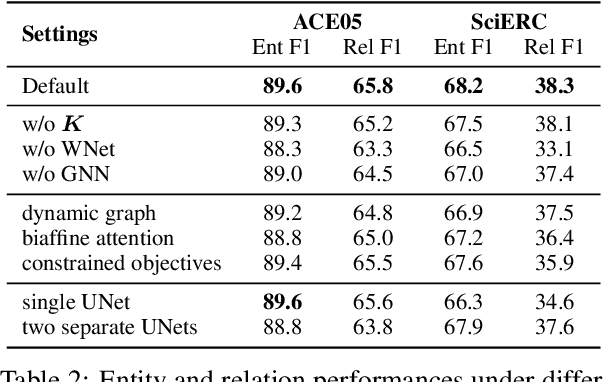
Entity relation extraction consists of two sub-tasks: entity recognition and relation extraction. Existing methods either tackle these two tasks separately or unify them with word-by-word interactions. In this paper, we propose HIORE, a new method for unified entity relation extraction. The key insight is to leverage the high-order interactions, i.e., the complex association among word pairs, which contains richer information than the first-order word-by-word interactions. For this purpose, we first devise a W-shape DNN (WNet) to capture coarse-level high-order connections. Then, we build a heuristic high-order graph and further calibrate the representations with a graph neural network (GNN). Experiments on three benchmarks (ACE04, ACE05, SciERC) show that HIORE achieves the state-of-the-art performance on relation extraction and an improvement of 1.1~1.8 F1 points over the prior best unified model.
Quantum Operation of Affective Artificial Intelligence
May 14, 2023The review analyzes the fundamental principles which Artificial Intelligence should be based on in order to imitate the realistic process of taking decisions by humans experiencing emotions. Two approaches are compared, one based on quantum theory and the other employing classical terms. Both these approaches have a number of similarities, being principally probabilistic. The analogies between quantum measurements under intrinsic noise and affective decision making are elucidated. It is shown that cognitive processes have many features that are formally similar to quantum measurements. This, however, in no way means that for the imitation of human decision making Affective Artificial Intelligence has necessarily to rely on the functioning of quantum systems. Appreciating the common features between quantum measurements and decision making helps for the formulation of an axiomatic approach employing only classical notions. Artificial Intelligence, following this approach, operates similarly to humans, by taking into account the utility of the considered alternatives as well as their emotional attractiveness. Affective Artificial Intelligence, whose operation takes account of the cognition-emotion duality, avoids numerous behavioural paradoxes of traditional decision making. A society of intelligent agents, interacting through the repeated multistep exchange of information, forms a network accomplishing dynamic decision making. The considered intelligent networks can characterize the operation of either a human society of affective decision makers, or the brain composed of neurons, or a typical probabilistic network of an artificial intelligence.
* Review, Latex file, 123 pages, 14 figures
On enhancing the robustness of Vision Transformers: Defensive Diffusion
May 14, 2023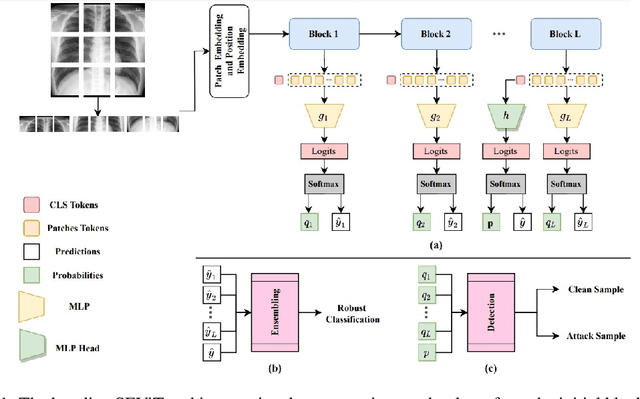
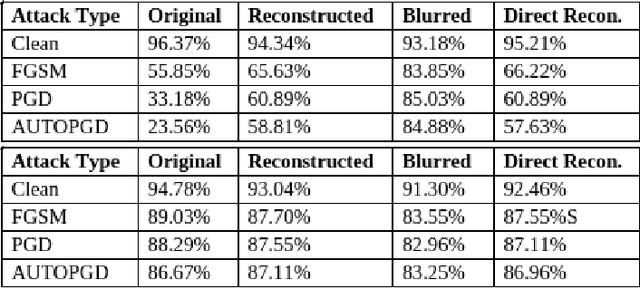
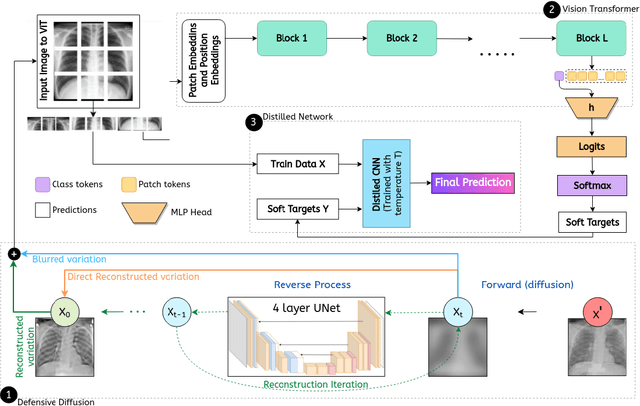
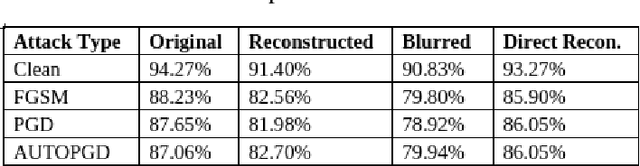
Privacy and confidentiality of medical data are of utmost importance in healthcare settings. ViTs, the SOTA vision model, rely on large amounts of patient data for training, which raises concerns about data security and the potential for unauthorized access. Adversaries may exploit vulnerabilities in ViTs to extract sensitive patient information and compromising patient privacy. This work address these vulnerabilities to ensure the trustworthiness and reliability of ViTs in medical applications. In this work, we introduced a defensive diffusion technique as an adversarial purifier to eliminate adversarial noise introduced by attackers in the original image. By utilizing the denoising capabilities of the diffusion model, we employ a reverse diffusion process to effectively eliminate the adversarial noise from the attack sample, resulting in a cleaner image that is then fed into the ViT blocks. Our findings demonstrate the effectiveness of the diffusion model in eliminating attack-agnostic adversarial noise from images. Additionally, we propose combining knowledge distillation with our framework to obtain a lightweight student model that is both computationally efficient and robust against gray box attacks. Comparison of our method with a SOTA baseline method, SEViT, shows that our work is able to outperform the baseline. Extensive experiments conducted on a publicly available Tuberculosis X-ray dataset validate the computational efficiency and improved robustness achieved by our proposed architecture.
Model-driven CT reconstruction algorithm for nano-resolution X-ray phase contrast imaging
May 14, 2023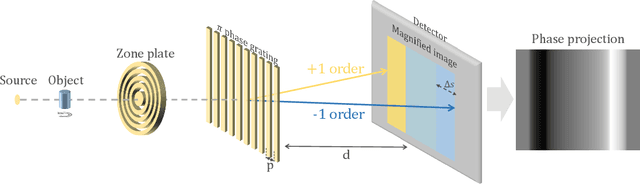
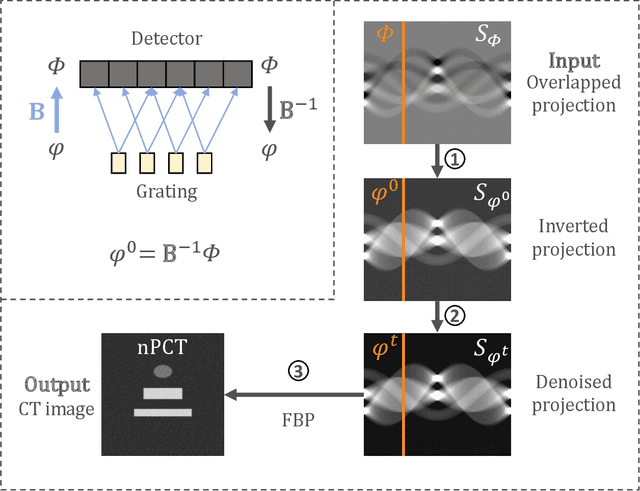
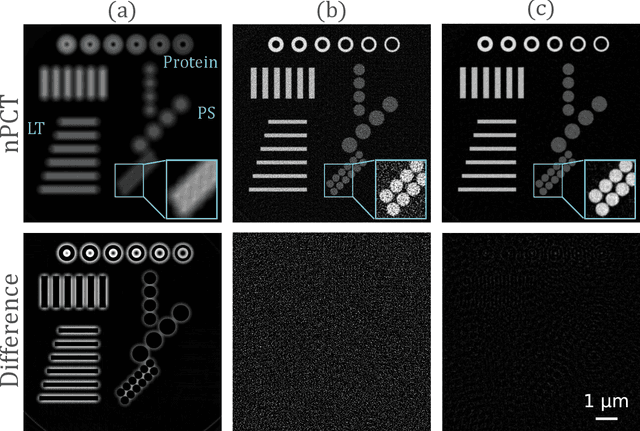
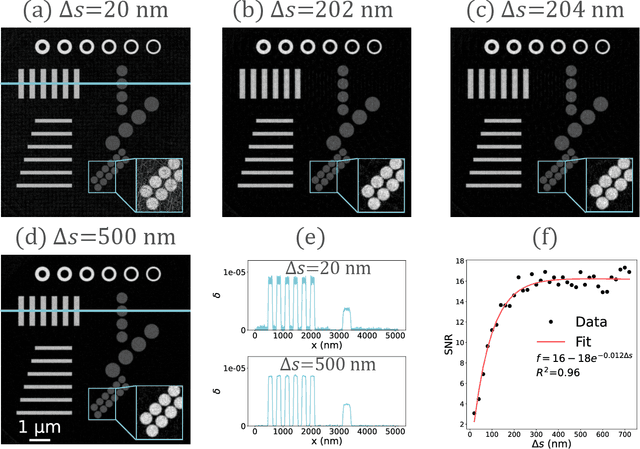
The limited imaging performance of low-density objects in a zone plate based nano-resolution hard X-ray computed tomography (CT) system can be significantly improved by accessing the phase information. To do so, a grating-based Lau interferometer needs to be integrated. However, the nano-resolution phase contrast CT, denoted as nPCT, reconstructed from such an interferometer system may suffer resolution loss due to the strong signal diffraction. Aimed at performing accurate nPCT image reconstruction directly from these diffracted projections, a new model-driven nPCT image reconstruction algorithm is developed. First, the diffraction procedure is mathematically modeled into a matrix B, from which the projections without signal splitting can be generated invertedly. Second, a penalized weighed least-square model with total variation (PWLS-TV) is employed to denoise these projections. Finally, nPCT images with high resolution and high accuracy are reconstructed using the filtered-back-projection (FBP) method. Numerical simulations demonstrate that this algorithm is able to deal with diffracted projections having any splitting distances. Interestingly, results reveal that nPCT images with higher signal-to-noise-ratio (SNR) can be reconstructed from projections with larger signal splittings. In conclusion, a novel model-driven nPCT image reconstruction algorithm with high accuracy and robustness is verified for the Lau interferometer based hard X-ray nPCT imaging system.
ProgSG: Cross-Modality Representation Learning for Programs in Electronic Design Automation
May 18, 2023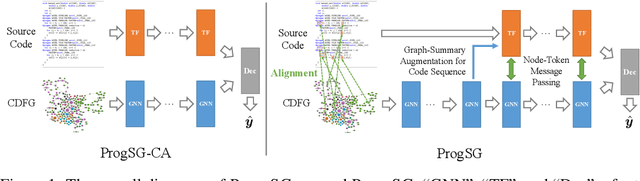
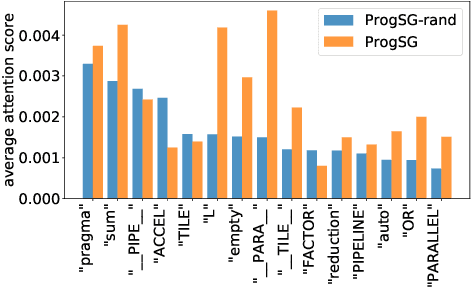
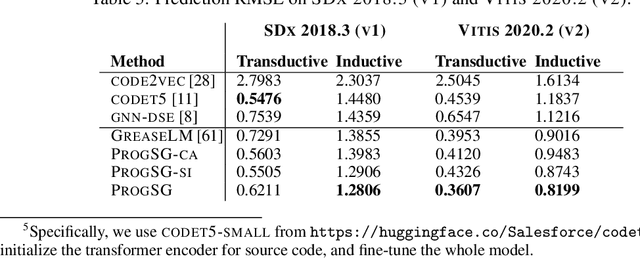
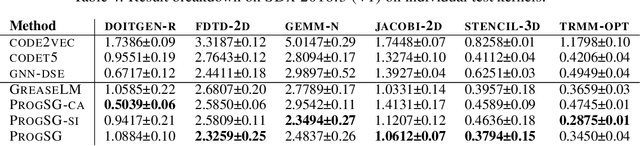
Recent years have witnessed the growing popularity of domain-specific accelerators (DSAs), such as Google's TPUs, for accelerating various applications such as deep learning, search, autonomous driving, etc. To facilitate DSA designs, high-level synthesis (HLS) is used, which allows a developer to compile a high-level description in the form of software code in C and C++ into a design in low-level hardware description languages (such as VHDL or Verilog) and eventually synthesized into a DSA on an ASIC (application-specific integrated circuit) or FPGA (field-programmable gate arrays). However, existing HLS tools still require microarchitecture decisions, expressed in terms of pragmas (such as directives for parallelization and pipelining). To enable more people to design DSAs, it is desirable to automate such decisions with the help of deep learning for predicting the quality of HLS designs. This requires us a deeper understanding of the program, which is a combination of original code and pragmas. Naturally, these programs can be considered as sequence data, for which large language models (LLM) can help. In addition, these programs can be compiled and converted into a control data flow graph (CDFG), and the compiler also provides fine-grained alignment between the code tokens and the CDFG nodes. However, existing works either fail to leverage both modalities or combine the two in shallow or coarse ways. We propose ProgSG allowing the source code sequence modality and the graph modalities to interact with each other in a deep and fine-grained way. To alleviate the scarcity of labeled designs, a pre-training method is proposed based on a suite of compiler's data flow analysis tasks. Experimental results on two benchmark datasets show the superiority of ProgSG over baseline methods that either only consider one modality or combine the two without utilizing the alignment information.