 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FARA: Future-aware Ranking Algorithm for Fairness Optimization
May 26, 2023
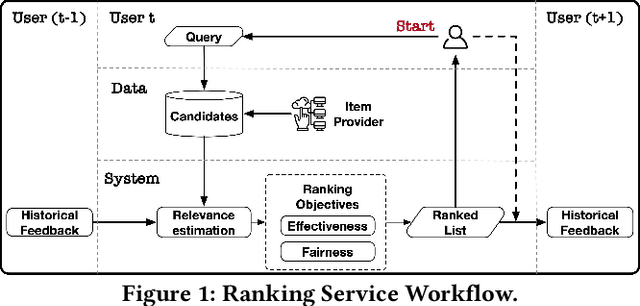
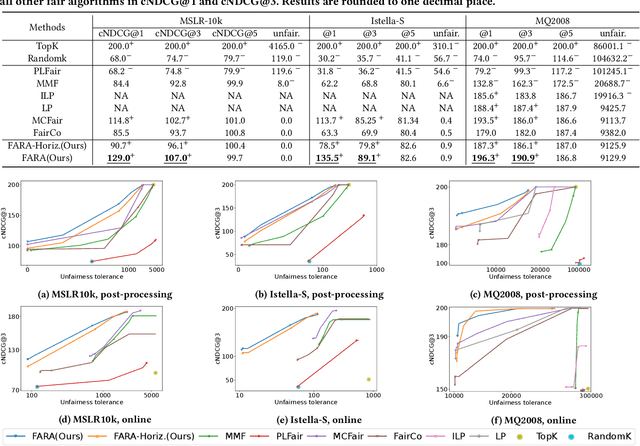
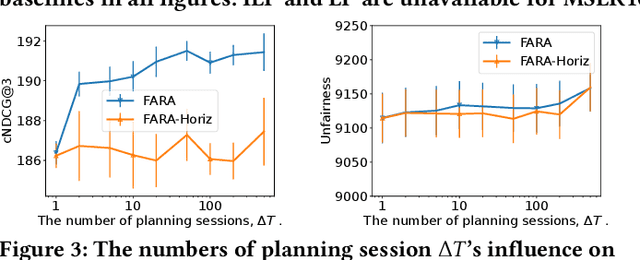
Ranking systems are the key components of modern Information Retrieval (IR) applications, such as search engines and recommender systems. Besides the ranking relevance to users, the exposure fairness to item providers has also been considered an important factor in ranking optimization. Many fair ranking algorithms have been proposed to jointly optimize both ranking relevance and fairness. However, we find that most existing fair ranking methods adopt greedy algorithms that only optimize rankings for the next immediate session or request. As shown in this paper, such a myopic paradigm could limit the upper bound of ranking optimization and lead to suboptimal performance in the long term. To this end, we propose FARA, a novel Future-Aware Ranking Algorithm for ranking relevance and fairness optimization. Instead of greedily optimizing rankings for the next immediate session, FARA plans ahead by jointly optimizing multiple ranklists together and saving them for future sessions. Particularly, FARA first uses the Taylor expansion to investigate how future ranklists will influence the overall fairness of the system. Then, based on the analysis of the Taylor expansion, FARA adopts a two-phase optimization algorithm where we first solve an optimal future exposure planning problem and then construct the optimal ranklists according to the optimal future exposure planning. Theoretically, we show that FARA is optimal for ranking relevance and fairness joint optimization. Empirically, our extensive experiments on three semi-synthesized datasets show that FARA is efficient, effective, and can deliver significantly better ranking performance compared to state-of-the-art fair ranking methods.
Robust Lane Detection through Self Pre-training with Masked Sequential Autoencoders and Fine-tuning with Customized PolyLoss
May 26, 2023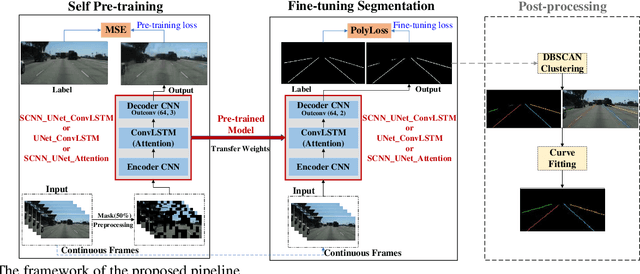
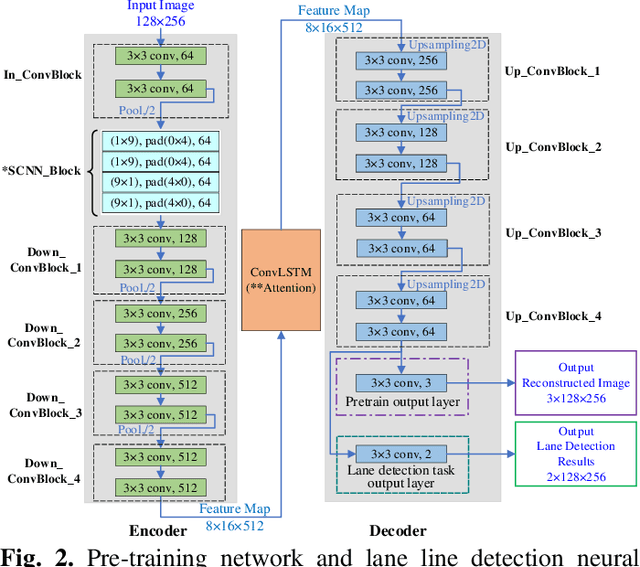

Lane detection is crucial for vehicle localization which makes it the foundation for automated driving and many intelligent and advanced driving assistant systems. Available vision-based lane detection methods do not make full use of the valuable features and aggregate contextual information, especially the interrelationships between lane lines and other regions of the images in continuous frames. To fill this research gap and upgrade lane detection performance, this paper proposes a pipeline consisting of self pre-training with masked sequential autoencoders and fine-tuning with customized PolyLoss for the end-to-end neural network models using multi-continuous image frames. The masked sequential autoencoders are adopted to pre-train the neural network models with reconstructing the missing pixels from a random masked image as the objective. Then, in the fine-tuning segmentation phase where lane detection segmentation is performed, the continuous image frames are served as the inputs, and the pre-trained model weights are transferred and further updated using the backpropagation mechanism with customized PolyLoss calculating the weighted errors between the output lane detection results and the labeled ground truth. Extensive experiment results demonstrate that, with the proposed pipeline, the lane detection model performance on both normal and challenging scenes can be advanced beyond the state-of-the-art, delivering the best testing accuracy (98.38%), precision (0.937), and F1-measure (0.924) on the normal scene testing set, together with the best overall accuracy (98.36%) and precision (0.844) in the challenging scene test set, while the training time can be substantially shortened.
To Collide or Not To Collide -- Exploiting Passive Deformable Quadrotors for Contact-Rich Tasks
May 26, 2023
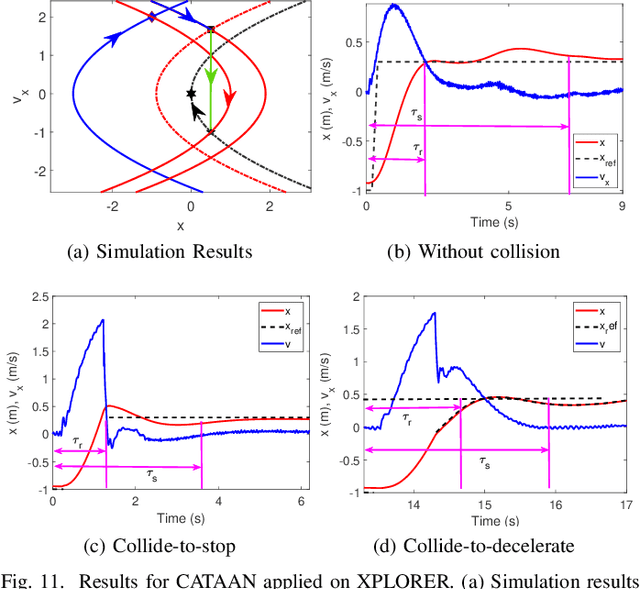
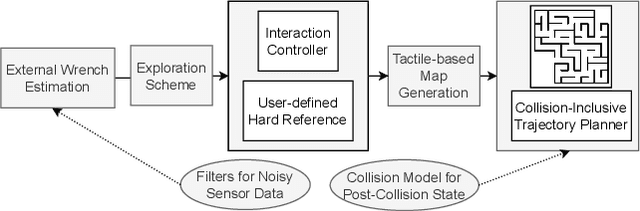
With an increase in aerial vehicle applications, passive deformable quadrotors are getting significant attention in the research community due to their potential to perform physical interaction tasks. Such quadrotors are capable of undergoing collisions, both planned and unplanned, which are harnessed to induce deformation and retain stability by dissipating collision energies. In this article, we utilize one such passive deforming quadrotor, XPLORER, to complete various contact-rich tasks by exploiting its compliant chassis via various impact-aware planning and control algorithms. At the core of these algorithms is a novel external wrench estimation technique developed specifically for the unique multi-linked structure of XPLORER's chassis. The external wrench information is then employed for designing interaction controllers to obtain three additional flight modes: static-wrench application, disturbance rejection and yielding to the disturbance. These modes are then incorporated into a novel online exploration scheme to enable navigation in unknown flight spaces with only tactile feedback and generate a map of the environment without requiring additional sensors. Experiments show the efficacy of this scheme to generate maps of the previously unexplored flight space with an accuracy of 96.72%. Finally, we develop a novel collision-aware trajectory planner (CATAAN) to generate minimum time maneuvers for waypoint tracking by integrating collision-induced state jumps for both elastic and inelastic cases. We experimentally validate that minimum time trajectories can be obtained with CATAAN leading to a 40.38% reduction of settling time accompanied by improved tracking performance of a root mean squared error in position within 0.5cm as compared to 3cm of conventional methods.
pFedSim: Similarity-Aware Model Aggregation Towards Personalized Federated Learning
May 25, 2023
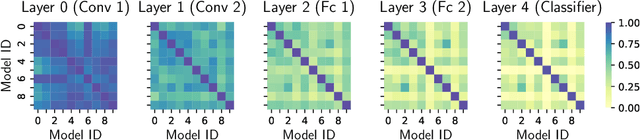
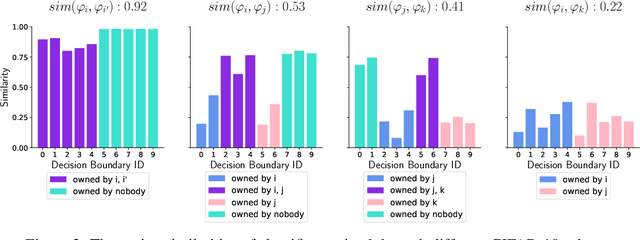
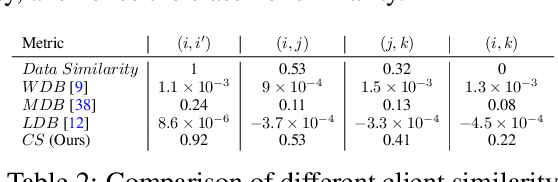
The federated learning (FL) paradigm emerges to preserve data privacy during model training by only exposing clients' model parameters rather than original data. One of the biggest challenges in FL lies in the non-IID (not identical and independently distributed) data (a.k.a., data heterogeneity) distributed on clients. To address this challenge, various personalized FL (pFL) methods are proposed such as similarity-based aggregation and model decoupling. The former one aggregates models from clients of a similar data distribution. The later one decouples a neural network (NN) model into a feature extractor and a classifier. Personalization is captured by classifiers which are obtained by local training. To advance pFL, we propose a novel pFedSim (pFL based on model similarity) algorithm in this work by combining these two kinds of methods. More specifically, we decouple a NN model into a personalized feature extractor, obtained by aggregating models from similar clients, and a classifier, which is obtained by local training and used to estimate client similarity. Compared with the state-of-the-art baselines, the advantages of pFedSim include: 1) significantly improved model accuracy; 2) low communication and computation overhead; 3) a low risk of privacy leakage; 4) no requirement for any external public information. To demonstrate the superiority of pFedSim, extensive experiments are conducted on real datasets. The results validate the superb performance of our algorithm which can significantly outperform baselines under various heterogeneous data settings.
Unbiased Compression Saves Communication in Distributed Optimization: When and How Much?
May 25, 2023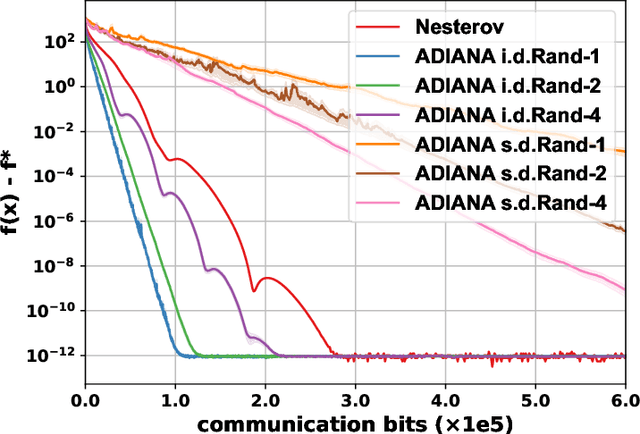

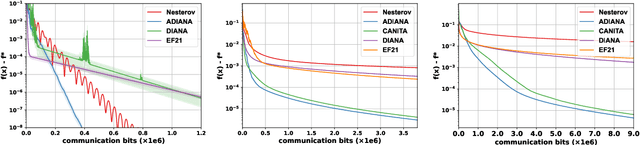

Communication compression is a common technique in distributed optimization that can alleviate communication overhead by transmitting compressed gradients and model parameters. However, compression can introduce information distortion, which slows down convergence and incurs more communication rounds to achieve desired solutions. Given the trade-off between lower per-round communication costs and additional rounds of communication, it is unclear whether communication compression reduces the total communication cost. This paper explores the conditions under which unbiased compression, a widely used form of compression, can reduce the total communication cost, as well as the extent to which it can do so. To this end, we present the first theoretical formulation for characterizing the total communication cost in distributed optimization with communication compression. We demonstrate that unbiased compression alone does not necessarily save the total communication cost, but this outcome can be achieved if the compressors used by all workers are further assumed independent. We establish lower bounds on the communication rounds required by algorithms using independent unbiased compressors to minimize smooth convex functions, and show that these lower bounds are tight by refining the analysis for ADIANA. Our results reveal that using independent unbiased compression can reduce the total communication cost by a factor of up to $\Theta(\sqrt{\min\{n, \kappa\}})$, where $n$ is the number of workers and $\kappa$ is the condition number of the functions being minimized. These theoretical findings are supported by experimental results.
UMat: Uncertainty-Aware Single Image High Resolution Material Capture
May 25, 2023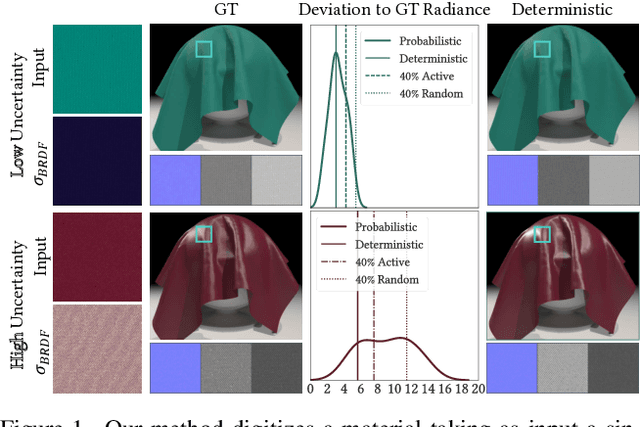
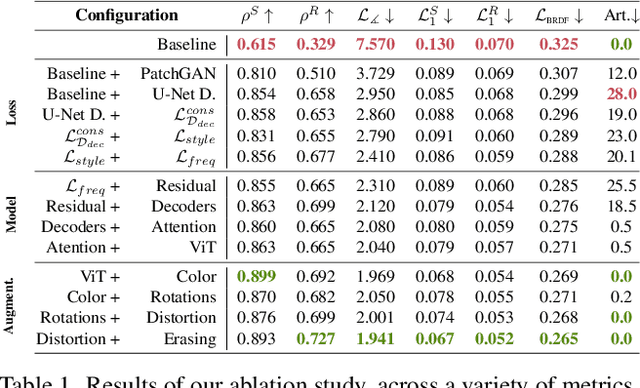

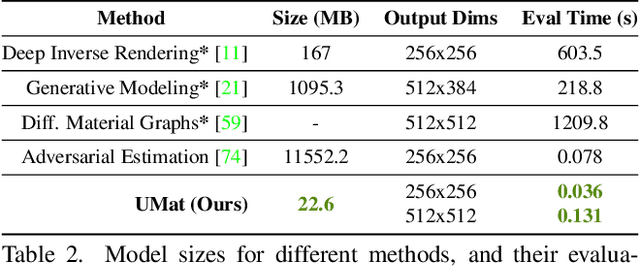
We propose a learning-based method to recover normals, specularity, and roughness from a single diffuse image of a material, using microgeometry appearance as our primary cue. Previous methods that work on single images tend to produce over-smooth outputs with artifacts, operate at limited resolution, or train one model per class with little room for generalization. Previous methods that work on single images tend to produce over-smooth outputs with artifacts, operate at limited resolution, or train one model per class with little room for generalization. In contrast, in this work, we propose a novel capture approach that leverages a generative network with attention and a U-Net discriminator, which shows outstanding performance integrating global information at reduced computational complexity. We showcase the performance of our method with a real dataset of digitized textile materials and show that a commodity flatbed scanner can produce the type of diffuse illumination required as input to our method. Additionally, because the problem might be illposed -more than a single diffuse image might be needed to disambiguate the specular reflection- or because the training dataset is not representative enough of the real distribution, we propose a novel framework to quantify the model's confidence about its prediction at test time. Our method is the first one to deal with the problem of modeling uncertainty in material digitization, increasing the trustworthiness of the process and enabling more intelligent strategies for dataset creation, as we demonstrate with an active learning experiment.
Fake News Detection and Behavioral Analysis: Case of COVID-19
May 25, 2023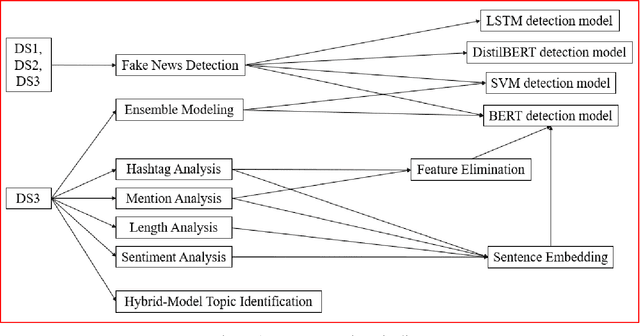


While the world has been combating COVID-19 for over three years, an ongoing "Infodemic" due to the spread of fake news regarding the pandemic has also been a global issue. The existence of the fake news impact different aspect of our daily lives, including politics, public health, economic activities, etc. Readers could mistake fake news for real news, and consequently have less access to authentic information. This phenomenon will likely cause confusion of citizens and conflicts in society. Currently, there are major challenges in fake news research. It is challenging to accurately identify fake news data in social media posts. In-time human identification is infeasible as the amount of the fake news data is overwhelming. Besides, topics discussed in fake news are hard to identify due to their similarity to real news. The goal of this paper is to identify fake news on social media to help stop the spread. We present Deep Learning approaches and an ensemble approach for fake news detection. Our detection models achieved higher accuracy than previous studies. The ensemble approach further improved the detection performance. We discovered feature differences between fake news and real news items. When we added them into the sentence embeddings, we found that they affected the model performance. We applied a hybrid method and built models for recognizing topics from posts. We found half of the identified topics were overlapping in fake news and real news, which could increase confusion in the population.
T-SciQ: Teaching Multimodal Chain-of-Thought Reasoning via Large Language Model Signals for Science Question Answering
May 09, 2023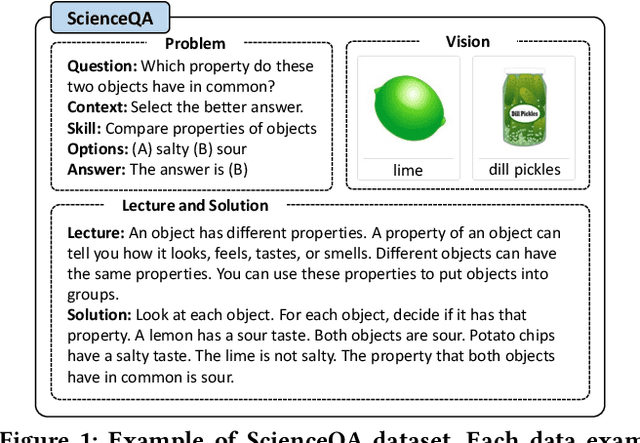
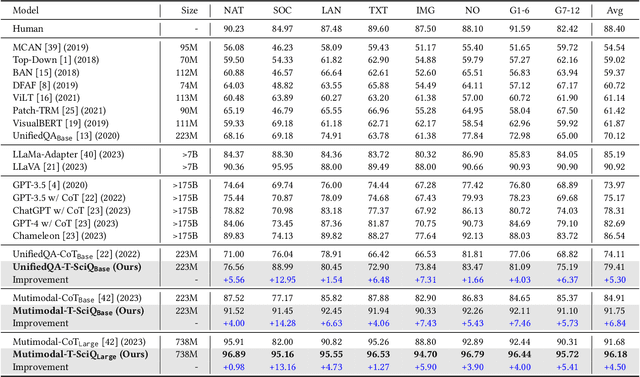
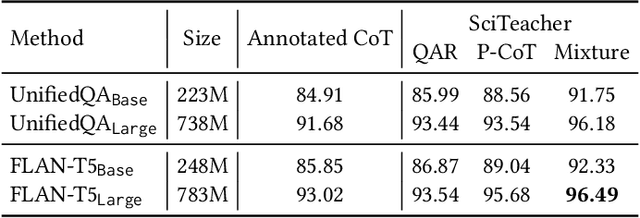
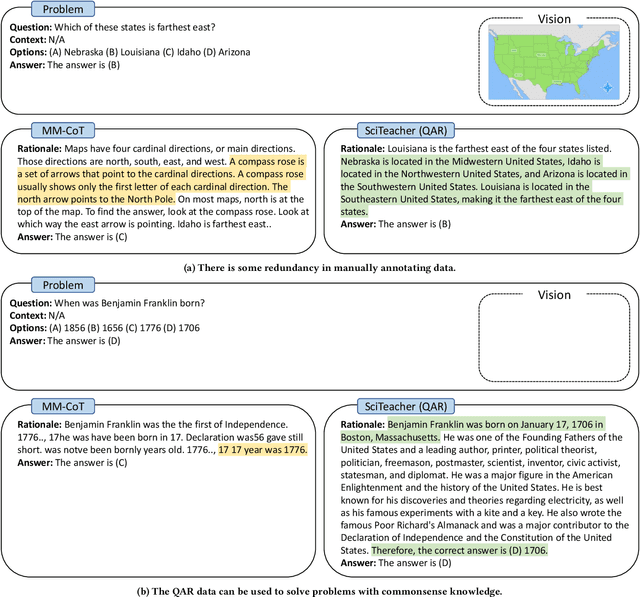
Large Language Models (LLMs) have recently demonstrated exceptional performance in various Natural Language Processing (NLP) tasks. They have also shown the ability to perform chain-of-thought (CoT) reasoning to solve complex problems. Recent studies have explored CoT reasoning in complex multimodal scenarios, such as the science question answering task, by fine-tuning multimodal models with high-quality human-annotated CoT rationales. However, collecting high-quality COT rationales is usually time-consuming and costly. Besides, the annotated rationales are hardly accurate due to the redundant information involved or the essential information missed. To address these issues, we propose a novel method termed \emph{T-SciQ} that aims at teaching science question answering with LLM signals. The T-SciQ approach generates high-quality CoT rationales as teaching signals and is advanced to train much smaller models to perform CoT reasoning in complex modalities. Additionally, we introduce a novel data mixing strategy to produce more effective teaching data samples for simple and complex science question answer problems. Extensive experimental results show that our T-SciQ method achieves a new state-of-the-art performance on the ScienceQA benchmark, with an accuracy of 96.18%. Moreover, our approach outperforms the most powerful fine-tuned baseline by 4.5%.
Reward-agnostic Fine-tuning: Provable Statistical Benefits of Hybrid Reinforcement Learning
May 17, 2023This paper studies tabular reinforcement learning (RL) in the hybrid setting, which assumes access to both an offline dataset and online interactions with the unknown environment. A central question boils down to how to efficiently utilize online data collection to strengthen and complement the offline dataset and enable effective policy fine-tuning. Leveraging recent advances in reward-agnostic exploration and model-based offline RL, we design a three-stage hybrid RL algorithm that beats the best of both worlds -- pure offline RL and pure online RL -- in terms of sample complexities. The proposed algorithm does not require any reward information during data collection. Our theory is developed based on a new notion called single-policy partial concentrability, which captures the trade-off between distribution mismatch and miscoverage and guides the interplay between offline and online data.
Joint Sensing, Communication, and AI: A Trifecta for Resilient THz User Experiences
Apr 29, 2023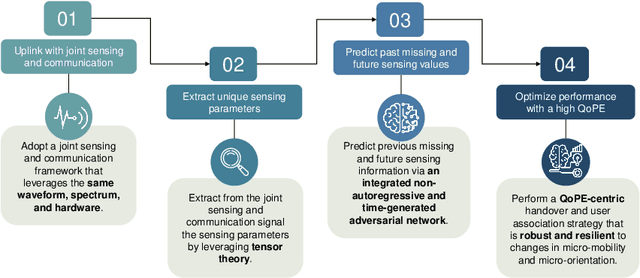
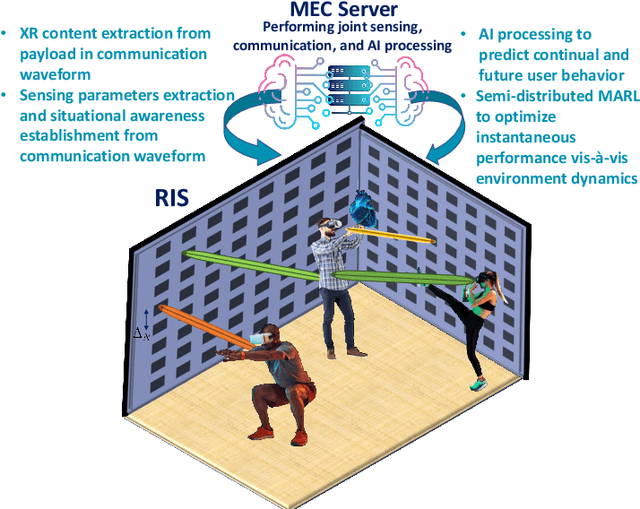
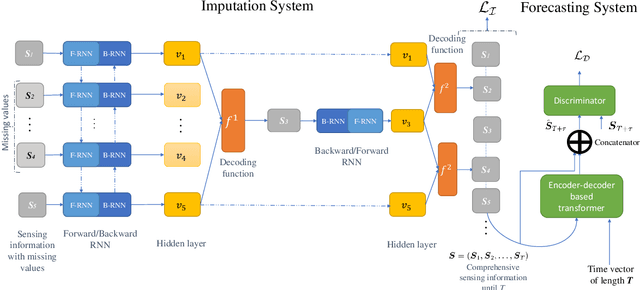
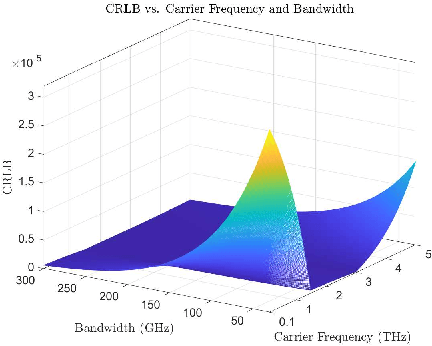
In this paper a novel joint sensing, communication, and artificial intelligence (AI) framework is proposed so as to optimize extended reality (XR) experiences over terahertz (THz) wireless systems. The proposed framework consists of three main components. First, a tensor decomposition framework is proposed to extract unique sensing parameters for XR users and their environment by exploiting then THz channel sparsity. Essentially, THz band's quasi-opticality is exploited and the sensing parameters are extracted from the uplink communication signal, thereby allowing for the use of the same waveform, spectrum, and hardware for both communication and sensing functionalities. Then, the Cramer-Rao lower bound is derived to assess the accuracy of the estimated sensing parameters. Second, a non-autoregressive multi-resolution generative artificial intelligence (AI) framework integrated with an adversarial transformer is proposed to predict missing and future sensing information. The proposed framework offers robust and comprehensive historical sensing information and anticipatory forecasts of future environmental changes, which are generalizable to fluctuations in both known and unforeseen user behaviors and environmental conditions. Third, a multi-agent deep recurrent hysteretic Q-neural network is developed to control the handover policy of reconfigurable intelligent surface (RIS) subarrays, leveraging the informative nature of sensing information to minimize handover cost, maximize the individual quality of personal experiences (QoPEs), and improve the robustness and resilience of THz links. Simulation results show a high generalizability of the proposed unsupervised generative AI framework to fluctuations in user behavior and velocity, leading to a 61 % improvement in instantaneous reliability compared to schemes with known channel state information.