 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Trajectories are Generalization Indicators
May 04, 2023

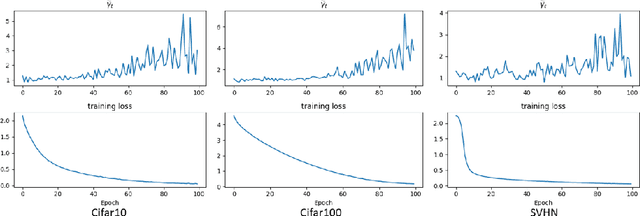

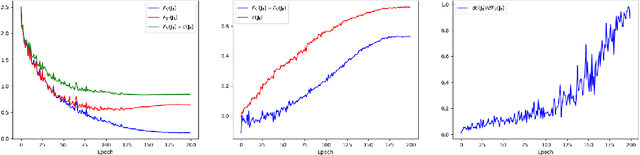
The aim of this paper is to investigate the connection between learning trajectories of the Deep Neural Networks (DNNs) and their corresponding generalization capabilities when being optimized with broadly used gradient descent and stochastic gradient descent algorithms. In this paper, we construct Linear Approximation Function to model the trajectory information and we propose a new generalization bound with richer trajectory information based on it. Our proposed generalization bound relies on the complexity of learning trajectory and the ratio between the bias and diversity of training set. Experimental results indicate that the proposed method effectively captures the generalization trend across various training steps, learning rates, and label noise levels.
Correcting for Selection Bias and Missing Response in Regression using Privileged Information
Mar 29, 2023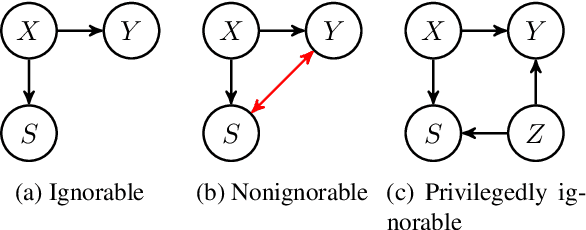
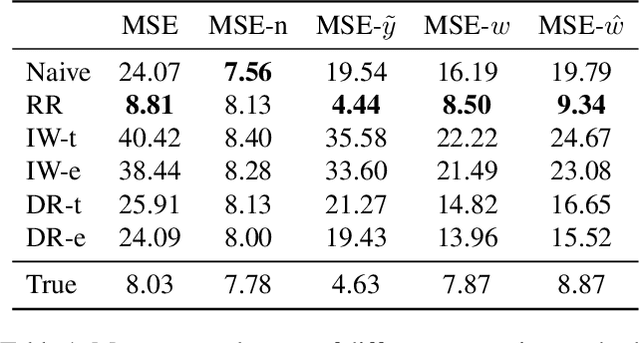
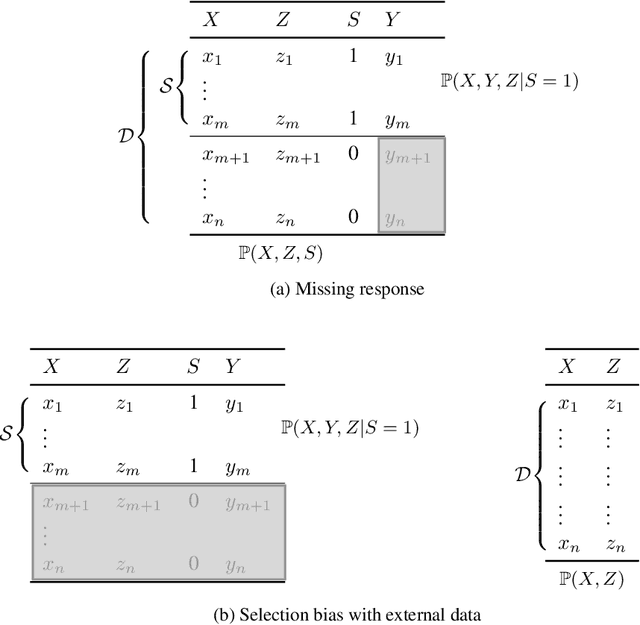
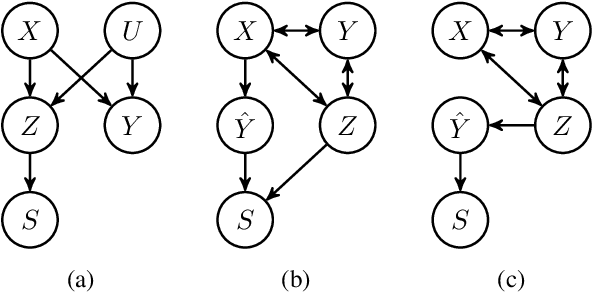
When estimating a regression model, we might have data where some labels are missing, or our data might be biased by a selection mechanism. When the response or selection mechanism is ignorable (i.e., independent of the response variable given the features) one can use off-the-shelf regression methods; in the nonignorable case one typically has to adjust for bias. We observe that privileged data (i.e. data that is only available during training) might render a nonignorable selection mechanism ignorable, and we refer to this scenario as Privilegedly Missing at Random (PMAR). We propose a novel imputation-based regression method, named repeated regression, that is suitable for PMAR. We also consider an importance weighted regression method, and a doubly robust combination of the two. The proposed methods are easy to implement with most popular out-of-the-box regression algorithms. We empirically assess the performance of the proposed methods with extensive simulated experiments and on a synthetically augmented real-world dataset. We conclude that repeated regression can appropriately correct for bias, and can have considerable advantage over weighted regression, especially when extrapolating to regions of the feature space where response is never observed.
Trajectories for the Optimal Collection of Information
Jan 12, 2023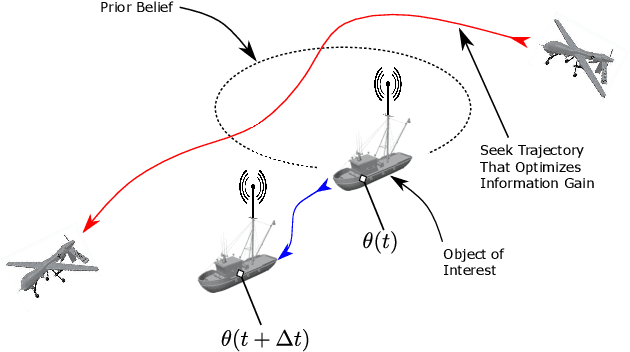
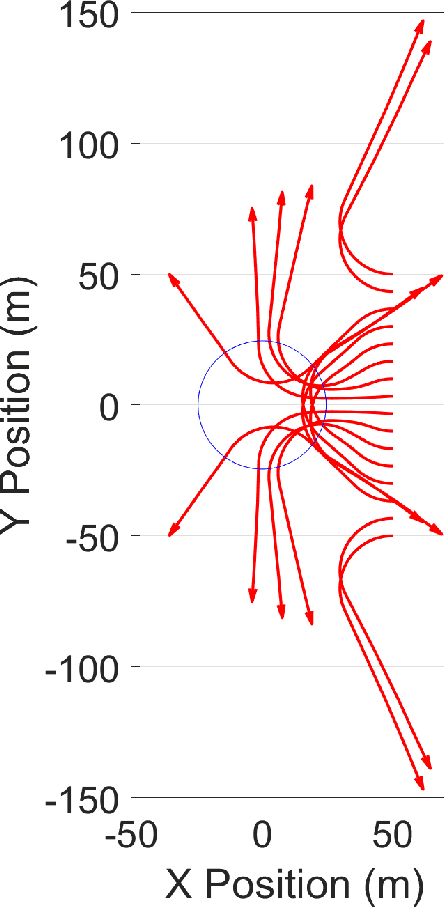
We study a scenario where an aircraft has multiple heterogeneous sensors collecting measurements to track a target vehicle of unknown location. The measurements are sampled along the flight path and our goals to optimize sensor placement to minimize estimation error. We select as a metric the Fisher Information Matrix (FIM), as "minimizing" the inverse of the FIM is required to achieve small estimation error. We propose to generate the optimal path from the Hamilton-Jacobi (HJ) partial differential equation (PDE) as it is the necessary and sufficient condition for optimality. A traditional method of lines (MOL) approach, based on a spatial grid, lends itself well to the highly non-linear and non-convex structure of the problem induced by the FIM matrix. However, the sensor placement problem results in a state space dimension that renders a naive MOL approach intractable. We present a new hybrid approach, whereby we decompose the state space into two parts: a smaller subspace that still uses a grid and takes advantage of the robustness to non-linearities and non-convexities, and the remaining state space that can by found efficiently from a system of ODEs, avoiding formation of a spatial grid.
General Neural Gauge Fields
May 05, 2023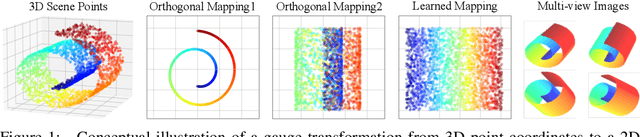
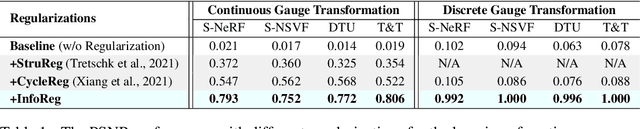

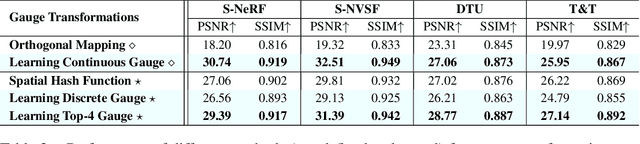
The recent advance of neural fields, such as neural radiance fields, has significantly pushed the boundary of scene representation learning. Aiming to boost the computation efficiency and rendering quality of 3D scenes, a popular line of research maps the 3D coordinate system to another measuring system, e.g., 2D manifolds and hash tables, for modeling neural fields. The conversion of coordinate systems can be typically dubbed as gauge transformation, which is usually a pre-defined mapping function, e.g., orthogonal projection or spatial hash function. This begs a question: can we directly learn a desired gauge transformation along with the neural field in an end-to-end manner? In this work, we extend this problem to a general paradigm with a taxonomy of discrete & continuous cases, and develop an end-to-end learning framework to jointly optimize the gauge transformation and neural fields. To counter the problem that the learning of gauge transformations can collapse easily, we derive a general regularization mechanism from the principle of information conservation during the gauge transformation. To circumvent the high computation cost in gauge learning with regularization, we directly derive an information-invariant gauge transformation which allows to preserve scene information inherently and yield superior performance.
Shape-Net: Room Layout Estimation from Panoramic Images Robust to Occlusion using Knowledge Distillation with 3D Shapes as Additional Inputs
Apr 25, 2023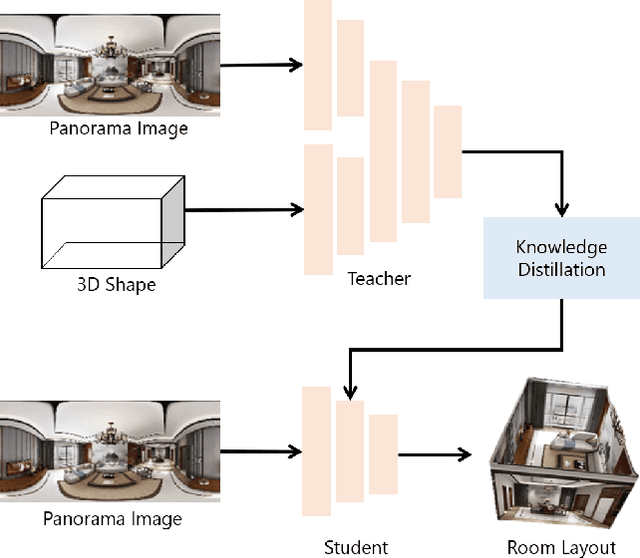

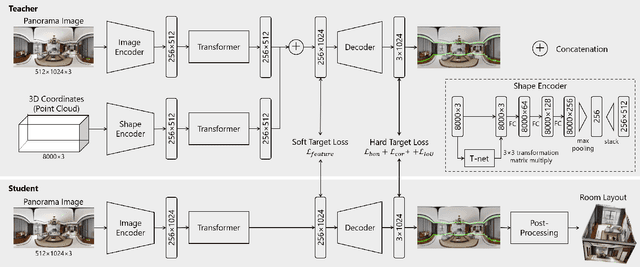

Estimating the layout of a room from a single-shot panoramic image is important in virtual/augmented reality and furniture layout simulation. This involves identifying three-dimensional (3D) geometry, such as the location of corners and boundaries, and performing 3D reconstruction. However, occlusion is a common issue that can negatively impact room layout estimation, and this has not been thoroughly studied to date. It is possible to obtain 3D shape information of rooms as drawings of buildings and coordinates of corners from image datasets, thus we propose providing both 2D panoramic and 3D information to a model to effectively deal with occlusion. However, simply feeding 3D information to a model is not sufficient to utilize the shape information for an occluded area. Therefore, we improve the model by introducing 3D Intersection over Union (IoU) loss to effectively use 3D information. In some cases, drawings are not available or the construction deviates from a drawing. Considering such practical cases, we propose a method for distilling knowledge from a model trained with both images and 3D information to a model that takes only images as input. The proposed model, which is called Shape-Net, achieves state-of-the-art (SOTA) performance on benchmark datasets. We also confirmed its effectiveness in dealing with occlusion through significantly improved accuracy on images with occlusion compared with existing models.
ST-GIN: An Uncertainty Quantification Approach in Traffic Data Imputation with Spatio-temporal Graph Attention and Bidirectional Recurrent United Neural Networks
May 19, 2023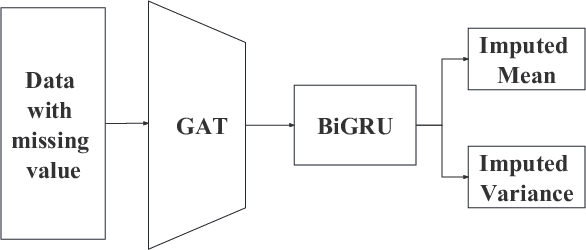
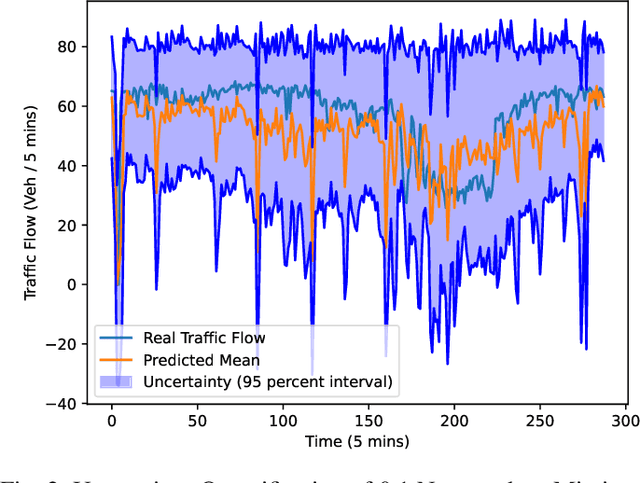
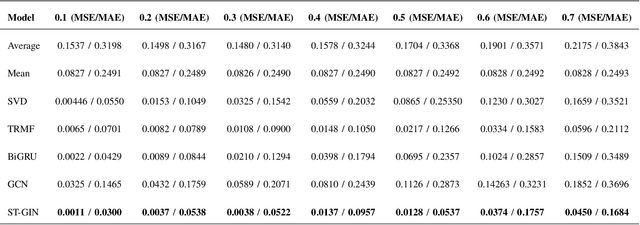
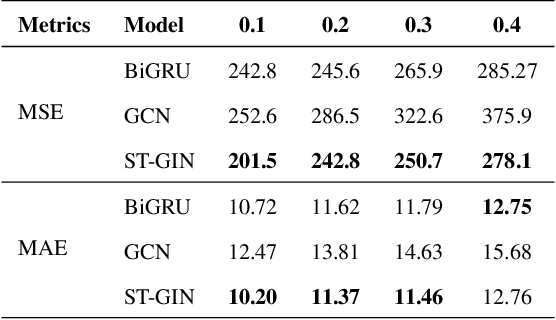
Traffic data serves as a fundamental component in both research and applications within intelligent transportation systems. However, real-world transportation data, collected from loop detectors or similar sources, often contain missing values (MVs), which can adversely impact associated applications and research. Instead of discarding this incomplete data, researchers have sought to recover these missing values through numerical statistics, tensor decomposition, and deep learning techniques. In this paper, we propose an innovative deep-learning approach for imputing missing data. A graph attention architecture is employed to capture the spatial correlations present in traffic data, while a bidirectional neural network is utilized to learn temporal information. Experimental results indicate that our proposed method outperforms all other benchmark techniques, thus demonstrating its effectiveness.
Dynamic Context Pruning for Efficient and Interpretable Autoregressive Transformers
May 25, 2023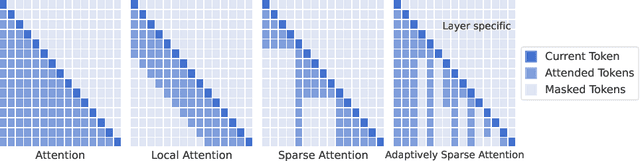

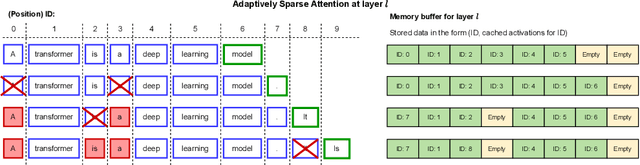
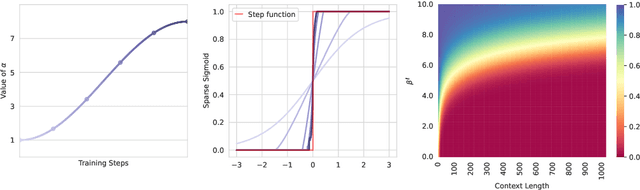
Autoregressive Transformers adopted in Large Language Models (LLMs) are hard to scale to long sequences. Despite several works trying to reduce their computational cost, most of LLMs still adopt attention layers between all pairs of tokens in the sequence, thus incurring a quadratic cost. In this study, we present a novel approach that dynamically prunes contextual information while preserving the model's expressiveness, resulting in reduced memory and computational requirements during inference. Our method employs a learnable mechanism that determines which uninformative tokens can be dropped from the context at any point across the generation process. By doing so, our approach not only addresses performance concerns but also enhances interpretability, providing valuable insight into the model's decision-making process. Our technique can be applied to existing pre-trained models through a straightforward fine-tuning process, and the pruning strength can be specified by a sparsity parameter. Notably, our empirical findings demonstrate that we can effectively prune up to 80\% of the context without significant performance degradation on downstream tasks, offering a valuable tool for mitigating inference costs. Our reference implementation achieves up to $2\times$ increase in inference throughput and even greater memory savings.
Emergency Response Person Localization and Vital Sign Estimation Using a Semi-Autonomous Robot Mounted SFCW Radar
May 25, 2023
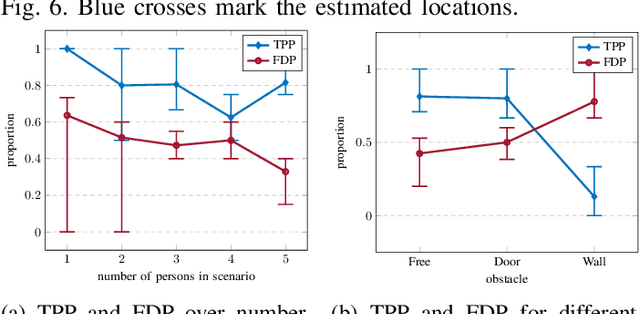
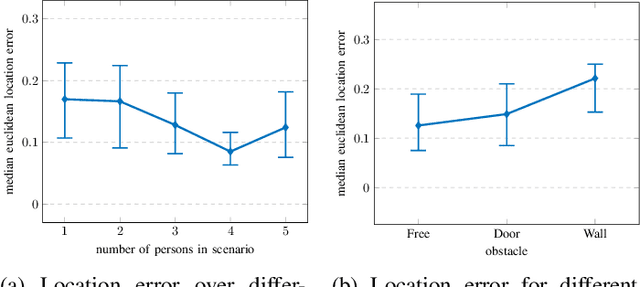
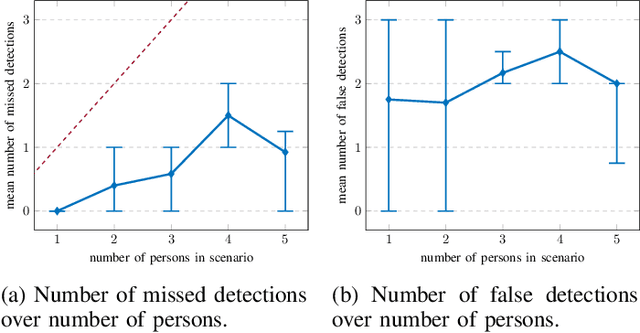
The large number and scale of natural and man-made disasters have led to an urgent demand for technologies that enhance the safety and efficiency of search and rescue teams. Semi-autonomous rescue robots are beneficial, especially when searching inaccessible terrains, or dangerous environments, such as collapsed infrastructures. For search and rescue missions in degraded visual conditions or non-line of sight scenarios, radar-based approaches may contribute to acquire valuable, and otherwise unavailable information. This article presents a complete signal processing chain for radar-based multi-person detection, 2D-MUSIC localization and breathing frequency estimation. The proposed method shows promising results on a challenging emergency response dataset that we collected using a semi-autonomous robot equipped with a commercially available through-wall radar system. The dataset is composed of 62 scenarios of various difficulty levels with up to five persons captured in different postures, angles and ranges including wooden and stone obstacles that block the radar line of sight. Ground truth data for reference locations, respiration, electrocardiogram, and acceleration signals are included. The full emergency response benchmark data set as well as all codes to reproduce our results, are publicly available at https://doi.org/10.21227/4bzd-jm32.
DDDM-VC: Decoupled Denoising Diffusion Models with Disentangled Representation and Prior Mixup for Verified Robust Voice Conversion
May 25, 2023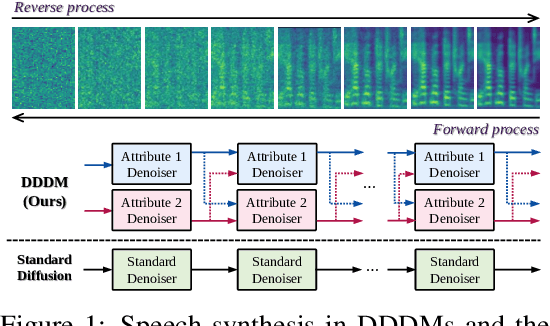
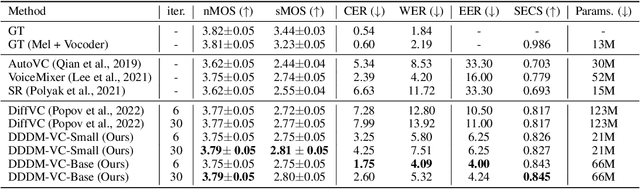
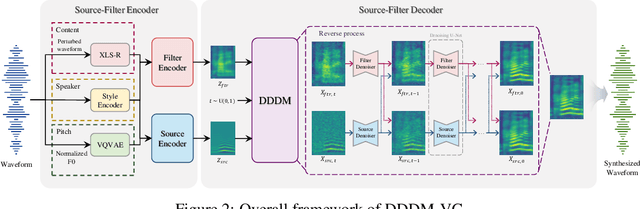
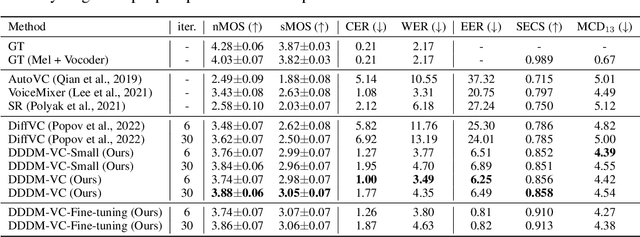
Diffusion-based generative models have exhibited powerful generative performance in recent years. However, as many attributes exist in the data distribution and owing to several limitations of sharing the model parameters across all levels of the generation process, it remains challenging to control specific styles for each attribute. To address the above problem, this paper presents decoupled denoising diffusion models (DDDMs) with disentangled representations, which can control the style for each attribute in generative models. We apply DDDMs to voice conversion (VC) tasks to address the challenges of disentangling and controlling each speech attribute (e.g., linguistic information, intonation, and timbre). First, we use a self-supervised representation to disentangle the speech representation. Subsequently, the DDDMs are applied to resynthesize the speech from the disentangled representations for denoising with respect to each attribute. Moreover, we also propose the prior mixup for robust voice style transfer, which uses the converted representation of the mixed style as a prior distribution for the diffusion models. The experimental results reveal that our method outperforms publicly available VC models. Furthermore, we show that our method provides robust generative performance regardless of the model size. Audio samples are available https://hayeong0.github.io/DDDM-VC-demo/.
Multi-Prompt with Depth Partitioned Cross-Modal Learning
May 25, 2023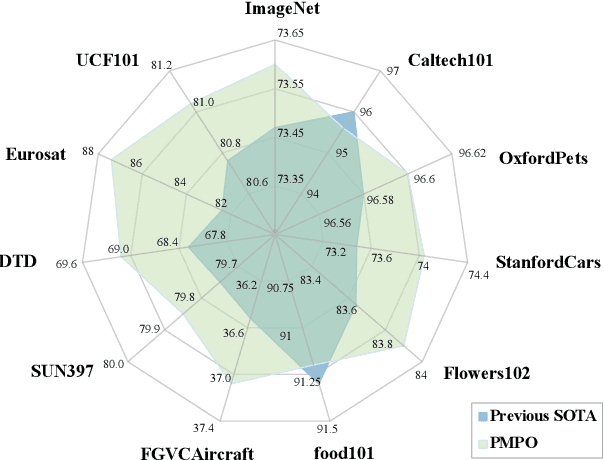
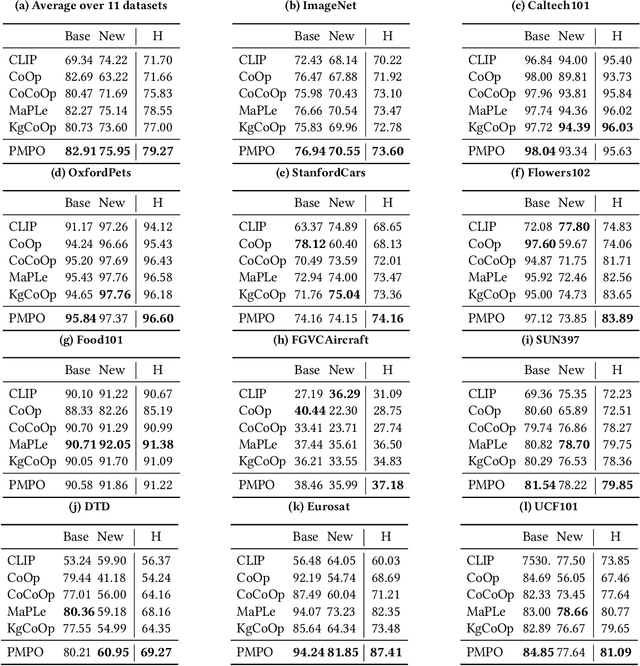

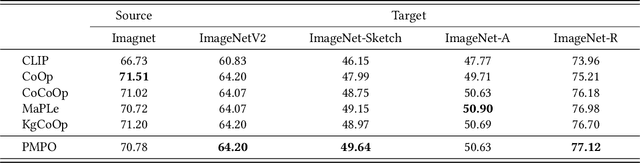
In recent years, soft prompt learning methods have been proposed to fine-tune large-scale vision-language pre-trained models for various downstream tasks. These methods typically combine learnable textual tokens with class tokens as input for models with frozen parameters. However, they often employ a single prompt to describe class contexts, failing to capture categories' diverse attributes adequately. This study introduces the Partitioned Multi-modal Prompt (PMPO), a multi-modal prompting technique that extends the soft prompt from a single learnable prompt to multiple prompts. Our method divides the visual encoder depths and connects learnable prompts to the separated visual depths, enabling different prompts to capture the hierarchical contextual depths of visual representations. Furthermore, to maximize the advantages of multi-prompt learning, we incorporate prior information from manually designed templates and learnable multi-prompts, thus improving the generalization capabilities of our approach. We evaluate the effectiveness of our approach on three challenging tasks: new class generalization, cross-dataset evaluation, and domain generalization. For instance, our method achieves a $79.28$ harmonic mean, averaged over 11 diverse image recognition datasets ($+7.62$ compared to CoOp), demonstrating significant competitiveness compared to state-of-the-art prompting methods.