 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoicePrompter: Robust Zero-Shot Voice Conversion with Voice Prompt and Conditional Flow Matching
Jan 29, 2025



Despite remarkable advancements in recent voice conversion (VC) systems, enhancing speaker similarity in zero-shot scenarios remains challenging. This challenge arises from the difficulty of generalizing and adapting speaker characteristics in speech within zero-shot environments, which is further complicated by mismatch between the training and inference processes. To address these challenges, we propose VoicePrompter, a robust zero-shot VC model that leverages in-context learning with voice prompts. VoicePrompter is composed of (1) a factorization method that disentangles speech components and (2) a DiT-based conditional flow matching (CFM) decoder that conditions on these factorized features and voice prompts. Additionally, (3) latent mixup is used to enhance in-context learning by combining various speaker features. This approach improves speaker similarity and naturalness in zero-shot VC by applying mixup to latent representations. Experimental results demonstrate that VoicePrompter outperforms existing zero-shot VC systems in terms of speaker similarity, speech intelligibility, and audio quality. Our demo is available at \url{https://hayeong0.github.io/VoicePrompter-demo/}.
Accelerating High-Fidelity Waveform Generation via Adversarial Flow Matching Optimization
Aug 15, 2024



This paper introduces PeriodWave-Turbo, a high-fidelity and high-efficient waveform generation model via adversarial flow matching optimization. Recently, conditional flow matching (CFM) generative models have been successfully adopted for waveform generation tasks, leveraging a single vector field estimation objective for training. Although these models can generate high-fidelity waveform signals, they require significantly more ODE steps compared to GAN-based models, which only need a single generation step. Additionally, the generated samples often lack high-frequency information due to noisy vector field estimation, which fails to ensure high-frequency reproduction. To address this limitation, we enhance pre-trained CFM-based generative models by incorporating a fixed-step generator modification. We utilized reconstruction losses and adversarial feedback to accelerate high-fidelity waveform generation. Through adversarial flow matching optimization, it only requires 1,000 steps of fine-tuning to achieve state-of-the-art performance across various objective metrics. Moreover, we significantly reduce inference speed from 16 steps to 2 or 4 steps. Additionally, by scaling up the backbone of PeriodWave from 29M to 70M parameters for improved generalization, PeriodWave-Turbo achieves unprecedented performance, with a perceptual evaluation of speech quality (PESQ) score of 4.454 on the LibriTTS dataset. Audio samples, source code and checkpoints will be available at https://github.com/sh-lee-prml/PeriodWave.
PeriodWave: Multi-Period Flow Matching for High-Fidelity Waveform Generation
Aug 14, 2024



Recently, universal waveform generation tasks have been investigated conditioned on various out-of-distribution scenarios. Although GAN-based methods have shown their strength in fast waveform generation, they are vulnerable to train-inference mismatch scenarios such as two-stage text-to-speech. Meanwhile, diffusion-based models have shown their powerful generative performance in other domains; however, they stay out of the limelight due to slow inference speed in waveform generation tasks. Above all, there is no generator architecture that can explicitly disentangle the natural periodic features of high-resolution waveform signals. In this paper, we propose PeriodWave, a novel universal waveform generation model. First, we introduce a period-aware flow matching estimator that can capture the periodic features of the waveform signal when estimating the vector fields. Additionally, we utilize a multi-period estimator that avoids overlaps to capture different periodic features of waveform signals. Although increasing the number of periods can improve the performance significantly, this requires more computational costs. To reduce this issue, we also propose a single period-conditional universal estimator that can feed-forward parallel by period-wise batch inference. Additionally, we utilize discrete wavelet transform to losslessly disentangle the frequency information of waveform signals for high-frequency modeling, and introduce FreeU to reduce the high-frequency noise for waveform generation. The experimental results demonstrated that our model outperforms the previous models both in Mel-spectrogram reconstruction and text-to-speech tasks. All source code will be available at \url{https://github.com/sh-lee-prml/PeriodWave}.
HierSpeech++: Bridging the Gap between Semantic and Acoustic Representation of Speech by Hierarchical Variational Inference for Zero-shot Speech Synthesis
Nov 27, 2023Large language models (LLM)-based speech synthesis has been widely adopted in zero-shot speech synthesis. However, they require a large-scale data and possess the same limitations as previous autoregressive speech models, including slow inference speed and lack of robustness. This paper proposes HierSpeech++, a fast and strong zero-shot speech synthesizer for text-to-speech (TTS) and voice conversion (VC). We verified that hierarchical speech synthesis frameworks could significantly improve the robustness and expressiveness of the synthetic speech. Furthermore, we significantly improve the naturalness and speaker similarity of synthetic speech even in zero-shot speech synthesis scenarios. For text-to-speech, we adopt the text-to-vec framework, which generates a self-supervised speech representation and an F0 representation based on text representations and prosody prompts. Then, HierSpeech++ generates speech from the generated vector, F0, and voice prompt. We further introduce a high-efficient speech super-resolution framework from 16 kHz to 48 kHz. The experimental results demonstrated that the hierarchical variational autoencoder could be a strong zero-shot speech synthesizer given that it outperforms LLM-based and diffusion-based models. Moreover, we achieved the first human-level quality zero-shot speech synthesis. Audio samples and source code are available at https://github.com/sh-lee-prml/HierSpeechpp.
Diff-HierVC: Diffusion-based Hierarchical Voice Conversion with Robust Pitch Generation and Masked Prior for Zero-shot Speaker Adaptation
Nov 08, 2023Although voice conversion (VC) systems have shown a remarkable ability to transfer voice style, existing methods still have an inaccurate pitch and low speaker adaptation quality. To address these challenges, we introduce Diff-HierVC, a hierarchical VC system based on two diffusion models. We first introduce DiffPitch, which can effectively generate F0 with the target voice style. Subsequently, the generated F0 is fed to DiffVoice to convert the speech with a target voice style. Furthermore, using the source-filter encoder, we disentangle the speech and use the converted Mel-spectrogram as a data-driven prior in DiffVoice to improve the voice style transfer capacity. Finally, by using the masked prior in diffusion models, our model can improve the speaker adaptation quality. Experimental results verify the superiority of our model in pitch generation and voice style transfer performance, and our model also achieves a CER of 0.83% and EER of 3.29% in zero-shot VC scenarios.
HierVST: Hierarchical Adaptive Zero-shot Voice Style Transfer
Jul 30, 2023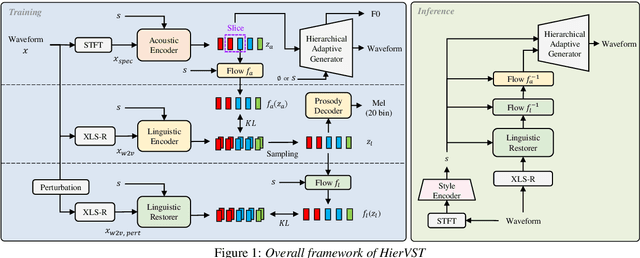
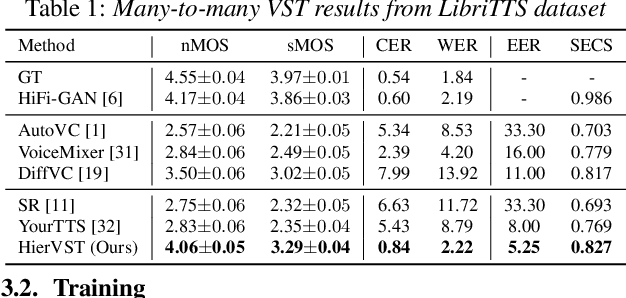
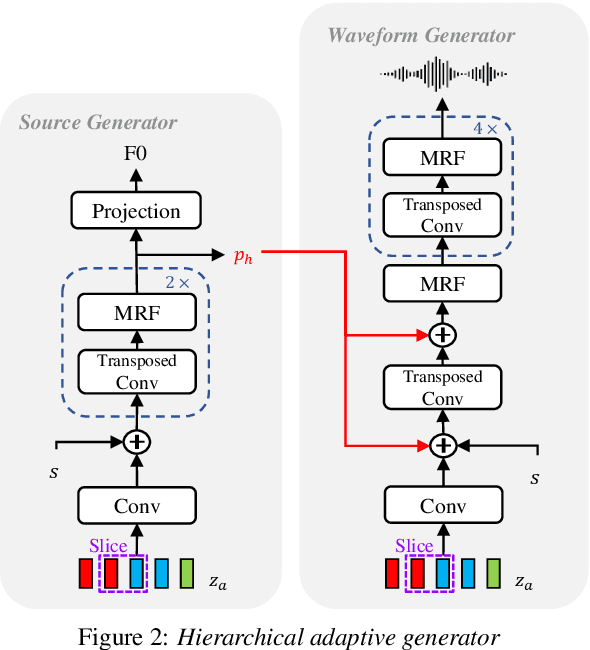
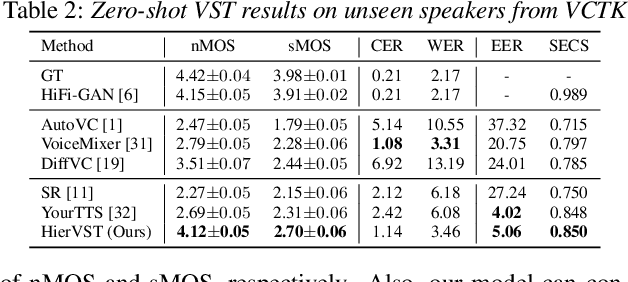
Despite rapid progress in the voice style transfer (VST) field, recent zero-shot VST systems still lack the ability to transfer the voice style of a novel speaker. In this paper, we present HierVST, a hierarchical adaptive end-to-end zero-shot VST model. Without any text transcripts, we only use the speech dataset to train the model by utilizing hierarchical variational inference and self-supervised representation. In addition, we adopt a hierarchical adaptive generator that generates the pitch representation and waveform audio sequentially. Moreover, we utilize unconditional generation to improve the speaker-relative acoustic capacity in the acoustic representation. With a hierarchical adaptive structure, the model can adapt to a novel voice style and convert speech progressively. The experimental results demonstrate that our method outperforms other VST models in zero-shot VST scenarios. Audio samples are available at \url{https://hiervst.github.io/}.
DDDM-VC: Decoupled Denoising Diffusion Models with Disentangled Representation and Prior Mixup for Verified Robust Voice Conversion
May 25, 2023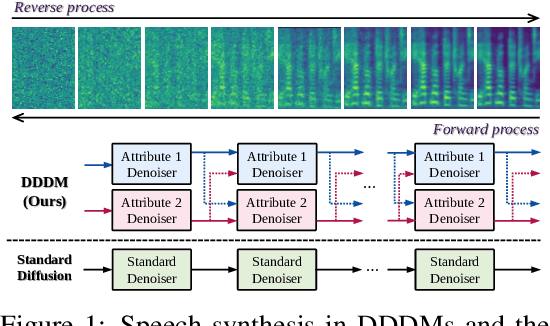
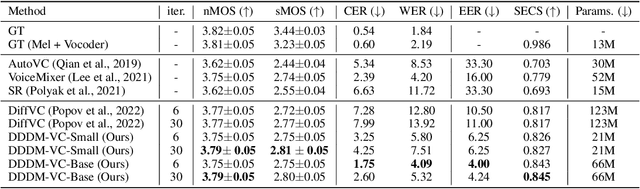
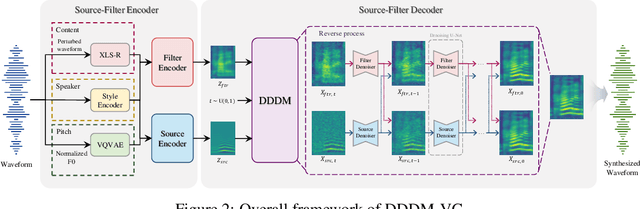
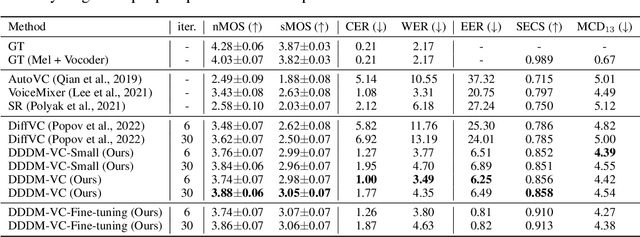
Diffusion-based generative models have exhibited powerful generative performance in recent years. However, as many attributes exist in the data distribution and owing to several limitations of sharing the model parameters across all levels of the generation process, it remains challenging to control specific styles for each attribute. To address the above problem, this paper presents decoupled denoising diffusion models (DDDMs) with disentangled representations, which can control the style for each attribute in generative models. We apply DDDMs to voice conversion (VC) tasks to address the challenges of disentangling and controlling each speech attribute (e.g., linguistic information, intonation, and timbre). First, we use a self-supervised representation to disentangle the speech representation. Subsequently, the DDDMs are applied to resynthesize the speech from the disentangled representations for denoising with respect to each attribute. Moreover, we also propose the prior mixup for robust voice style transfer, which uses the converted representation of the mixed style as a prior distribution for the diffusion models. The experimental results reveal that our method outperforms publicly available VC models. Furthermore, we show that our method provides robust generative performance regardless of the model size. Audio samples are available https://hayeong0.github.io/DDDM-VC-demo/.