 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adversarial robustness of amortized Bayesian inference
May 24, 2023
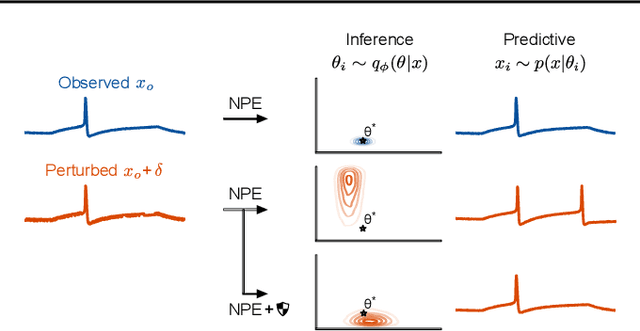
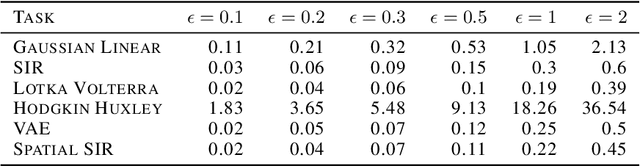
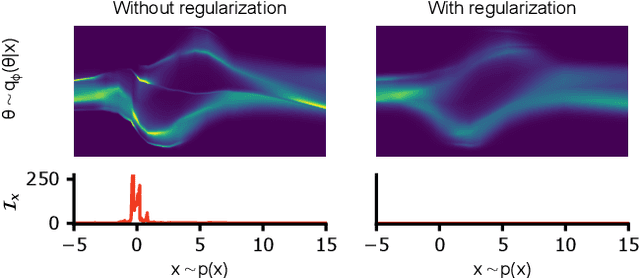
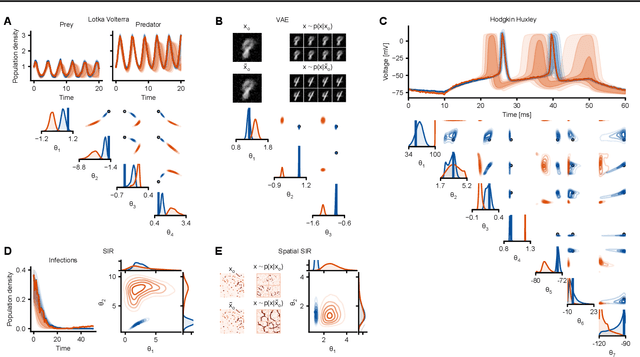
Bayesian inference usually requires running potentially costly inference procedures separately for every new observation. In contrast, the idea of amortized Bayesian inference is to initially invest computational cost in training an inference network on simulated data, which can subsequently be used to rapidly perform inference (i.e., to return estimates of posterior distributions) for new observations. This approach has been applied to many real-world models in the sciences and engineering, but it is unclear how robust the approach is to adversarial perturbations in the observed data. Here, we study the adversarial robustness of amortized Bayesian inference, focusing on simulation-based estimation of multi-dimensional posterior distributions. We show that almost unrecognizable, targeted perturbations of the observations can lead to drastic changes in the predicted posterior and highly unrealistic posterior predictive samples, across several benchmark tasks and a real-world example from neuroscience. We propose a computationally efficient regularization scheme based on penalizing the Fisher information of the conditional density estimator, and show how it improves the adversarial robustness of amortized Bayesian inference.
Cost-aware learning of relevant contextual variables within Bayesian optimization
May 24, 2023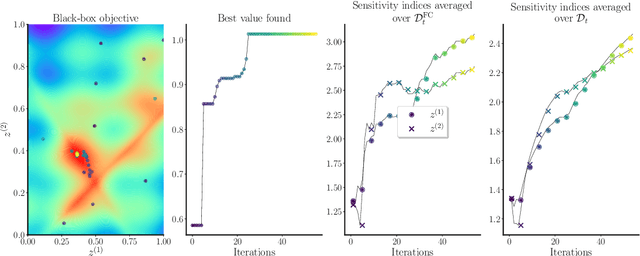

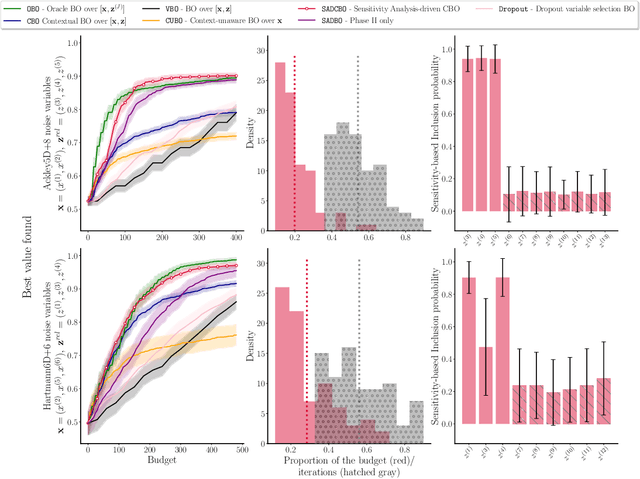
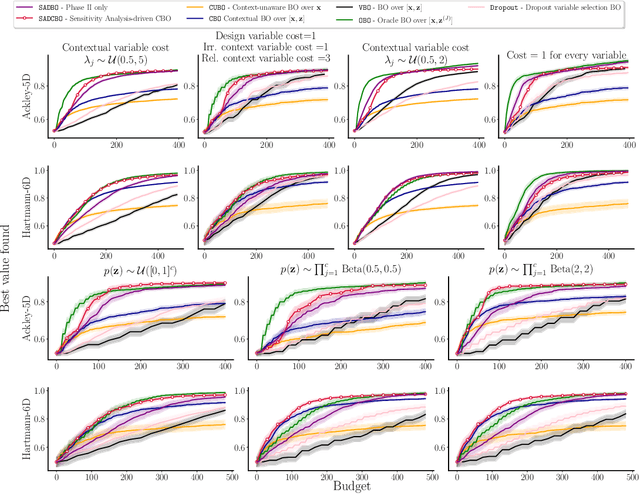
Contextual Bayesian Optimization (CBO) is a powerful framework for optimizing black-box, expensive-to-evaluate functions with respect to design variables, while simultaneously efficiently integrating relevant contextual information regarding the environment, such as experimental conditions. However, in many practical scenarios, the relevance of contextual variables is not necessarily known beforehand. Moreover, the contextual variables can sometimes be optimized themselves, a setting that current CBO algorithms do not take into account. Optimizing contextual variables may be costly, which raises the question of determining a minimal relevant subset. In this paper, we frame this problem as a cost-aware model selection BO task and address it using a novel method, Sensitivity-Analysis-Driven Contextual BO (SADCBO). We learn the relevance of context variables by sensitivity analysis of the posterior surrogate model at specific input points, whilst minimizing the cost of optimization by leveraging recent developments on early stopping for BO. We empirically evaluate our proposed SADCBO against alternatives on synthetic experiments together with extensive ablation studies, and demonstrate a consistent improvement across examples.
Inverse Preference Learning: Preference-based RL without a Reward Function
May 24, 2023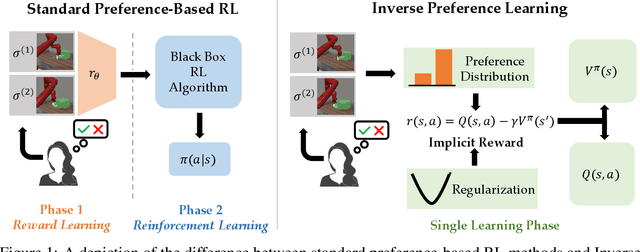
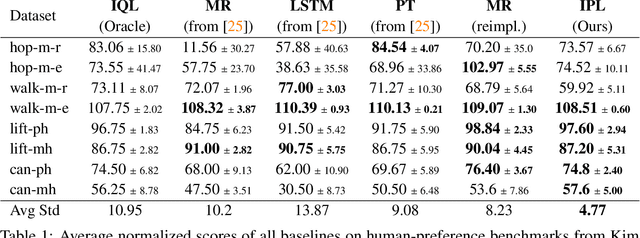
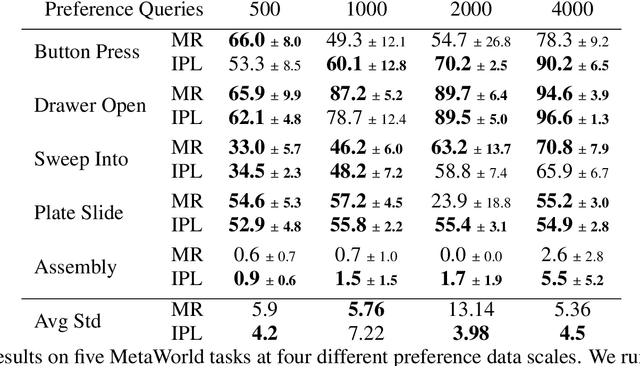
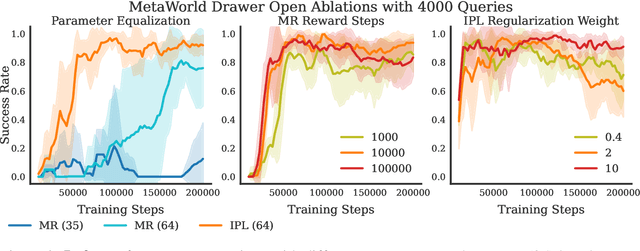
Reward functions are difficult to design and often hard to align with human intent. Preference-based Reinforcement Learning (RL) algorithms address these problems by learning reward functions from human feedback. However, the majority of preference-based RL methods na\"ively combine supervised reward models with off-the-shelf RL algorithms. Contemporary approaches have sought to improve performance and query complexity by using larger and more complex reward architectures such as transformers. Instead of using highly complex architectures, we develop a new and parameter-efficient algorithm, Inverse Preference Learning (IPL), specifically designed for learning from offline preference data. Our key insight is that for a fixed policy, the $Q$-function encodes all information about the reward function, effectively making them interchangeable. Using this insight, we completely eliminate the need for a learned reward function. Our resulting algorithm is simpler and more parameter-efficient. Across a suite of continuous control and robotics benchmarks, IPL attains competitive performance compared to more complex approaches that leverage transformer-based and non-Markovian reward functions while having fewer algorithmic hyperparameters and learned network parameters. Our code is publicly released.
Text encoders are performance bottlenecks in contrastive vision-language models
May 24, 2023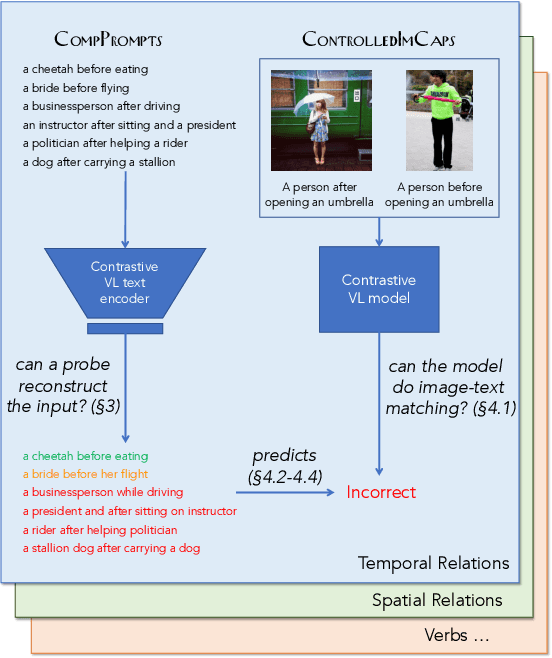
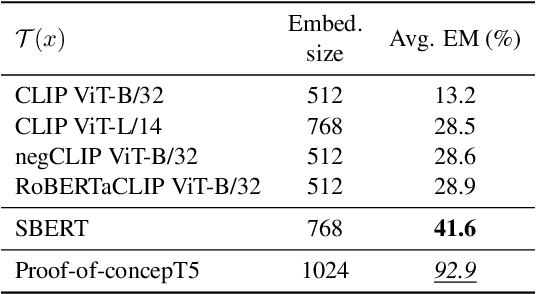
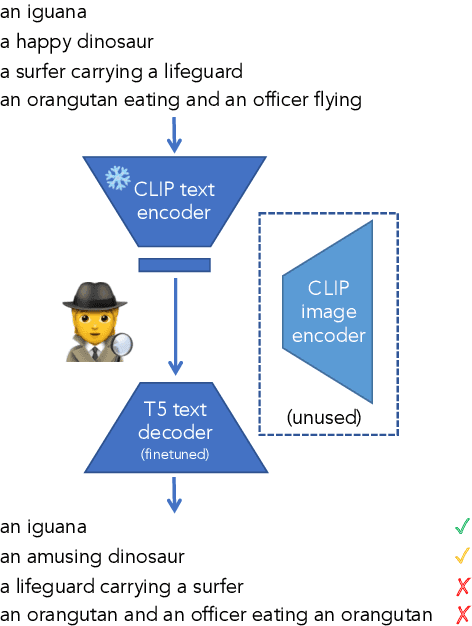
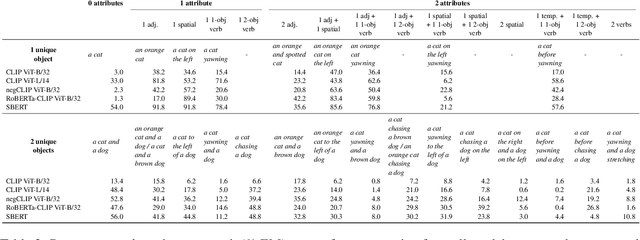
Performant vision-language (VL) models like CLIP represent captions using a single vector. How much information about language is lost in this bottleneck? We first curate CompPrompts, a set of increasingly compositional image captions that VL models should be able to capture (e.g., single object, to object+property, to multiple interacting objects). Then, we train text-only recovery probes that aim to reconstruct captions from single-vector text representations produced by several VL models. This approach doesn't require images, allowing us to test on a broader range of scenes compared to prior work. We find that: 1) CLIP's text encoder falls short on object relationships, attribute-object association, counting, and negations; 2) some text encoders work significantly better than others; and 3) text-only recovery performance predicts multi-modal matching performance on ControlledImCaps: a new evaluation benchmark we collect+release consisting of fine-grained compositional images+captions. Specifically -- our results suggest text-only recoverability is a necessary (but not sufficient) condition for modeling compositional factors in contrastive vision+language models. We release data+code.
Complex Mathematical Symbol Definition Structures: A Dataset and Model for Coordination Resolution in Definition Extraction
May 24, 2023
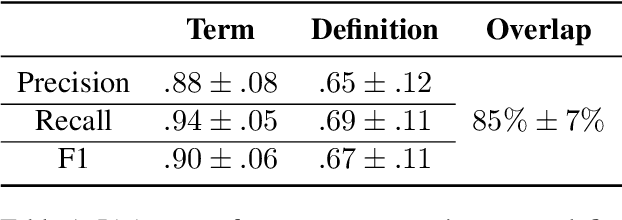


Mathematical symbol definition extraction is important for improving scholarly reading interfaces and scholarly information extraction (IE). However, the task poses several challenges: math symbols are difficult to process as they are not composed of natural language morphemes; and scholarly papers often contain sentences that require resolving complex coordinate structures. We present SymDef, an English language dataset of 5,927 sentences from full-text scientific papers where each sentence is annotated with all mathematical symbols linked with their corresponding definitions. This dataset focuses specifically on complex coordination structures such as "respectively" constructions, which often contain overlapping definition spans. We also introduce a new definition extraction method that masks mathematical symbols, creates a copy of each sentence for each symbol, specifies a target symbol, and predicts its corresponding definition spans using slot filling. Our experiments show that our definition extraction model significantly outperforms RoBERTa and other strong IE baseline systems by 10.9 points with a macro F1 score of 84.82. With our dataset and model, we can detect complex definitions in scholarly documents to make scientific writing more readable.
Reasoning over Hierarchical Question Decomposition Tree for Explainable Question Answering
May 24, 2023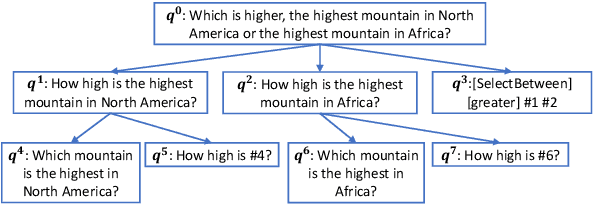
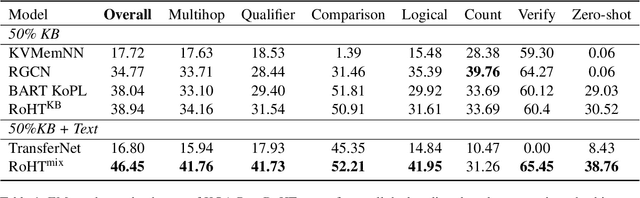
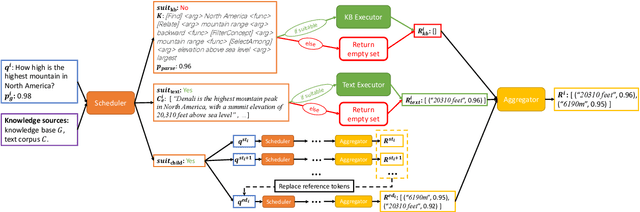
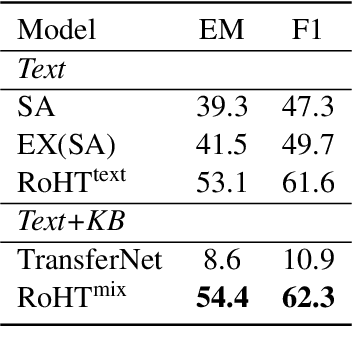
Explainable question answering (XQA) aims to answer a given question and provide an explanation why the answer is selected. Existing XQA methods focus on reasoning on a single knowledge source, e.g., structured knowledge bases, unstructured corpora, etc. However, integrating information from heterogeneous knowledge sources is essential to answer complex questions. In this paper, we propose to leverage question decomposing for heterogeneous knowledge integration, by breaking down a complex question into simpler ones, and selecting the appropriate knowledge source for each sub-question. To facilitate reasoning, we propose a novel two-stage XQA framework, Reasoning over Hierarchical Question Decomposition Tree (RoHT). First, we build the Hierarchical Question Decomposition Tree (HQDT) to understand the semantics of a complex question; then, we conduct probabilistic reasoning over HQDT from root to leaves recursively, to aggregate heterogeneous knowledge at different tree levels and search for a best solution considering the decomposing and answering probabilities. The experiments on complex QA datasets KQA Pro and Musique show that our framework outperforms SOTA methods significantly, demonstrating the effectiveness of leveraging question decomposing for knowledge integration and our RoHT framework.
Revisiting Sentence Union Generation as a Testbed for Text Consolidation
May 24, 2023
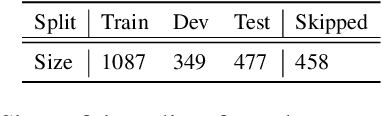
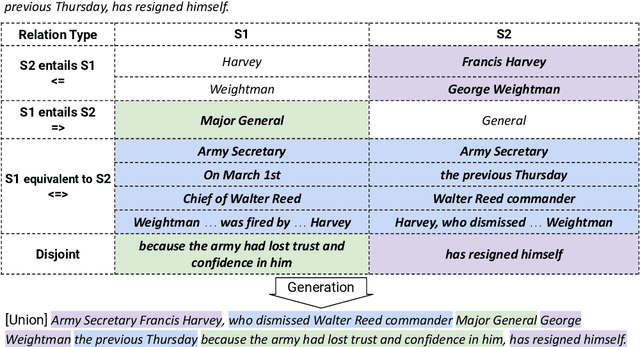
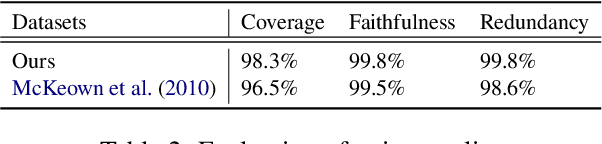
Tasks involving text generation based on multiple input texts, such as multi-document summarization, long-form question answering and contemporary dialogue applications, challenge models for their ability to properly consolidate partly-overlapping multi-text information. However, these tasks entangle the consolidation phase with the often subjective and ill-defined content selection requirement, impeding proper assessment of models' consolidation capabilities. In this paper, we suggest revisiting the sentence union generation task as an effective well-defined testbed for assessing text consolidation capabilities, decoupling the consolidation challenge from subjective content selection. To support research on this task, we present refined annotation methodology and tools for crowdsourcing sentence union, create the largest union dataset to date and provide an analysis of its rich coverage of various consolidation aspects. We then propose a comprehensive evaluation protocol for union generation, including both human and automatic evaluation. Finally, as baselines, we evaluate state-of-the-art language models on the task, along with a detailed analysis of their capacity to address multi-text consolidation challenges and their limitations.
Towards robust paralinguistic assessment for real-world mobile health (mHealth) monitoring: an initial study of reverberation effects on speech
May 21, 2023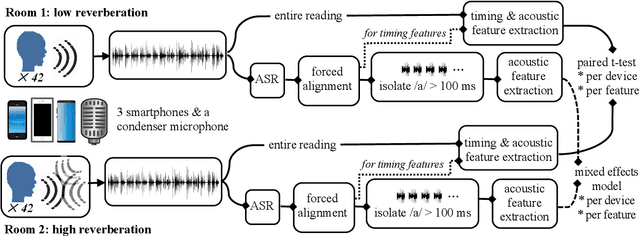

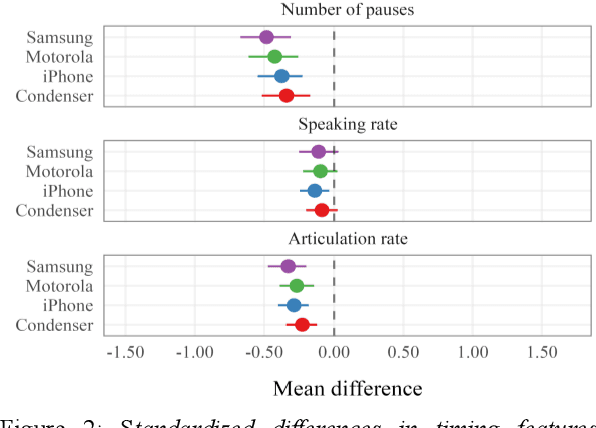
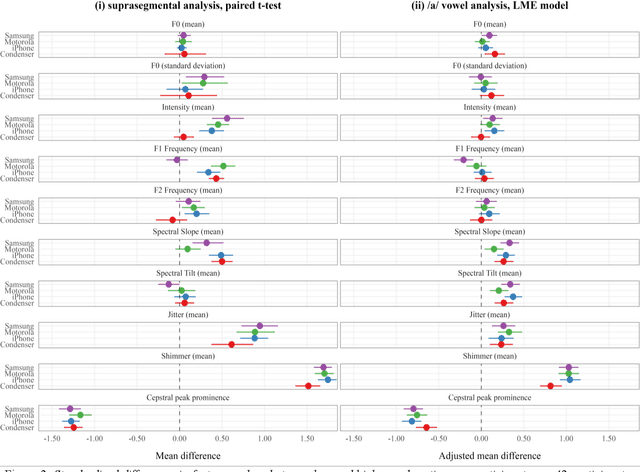
Speech is promising as an objective, convenient tool to monitor health remotely over time using mobile devices. Numerous paralinguistic features have been demonstrated to contain salient information related to an individual's health. However, mobile device specification and acoustic environments vary widely, risking the reliability of the extracted features. In an initial step towards quantifying these effects, we report the variability of 13 exemplar paralinguistic features commonly reported in the speech-health literature and extracted from the speech of 42 healthy volunteers recorded consecutively in rooms with low and high reverberation with one budget and two higher-end smartphones and a condenser microphone. Our results show reverberation has a clear effect on several features, in particular voice quality markers. They point to new research directions investigating how best to record and process in-the-wild speech for reliable longitudinal health state assessment.
SI-LSTM: Speaker Hybrid Long-short Term Memory and Cross Modal Attention for Emotion Recognition in Conversation
May 04, 2023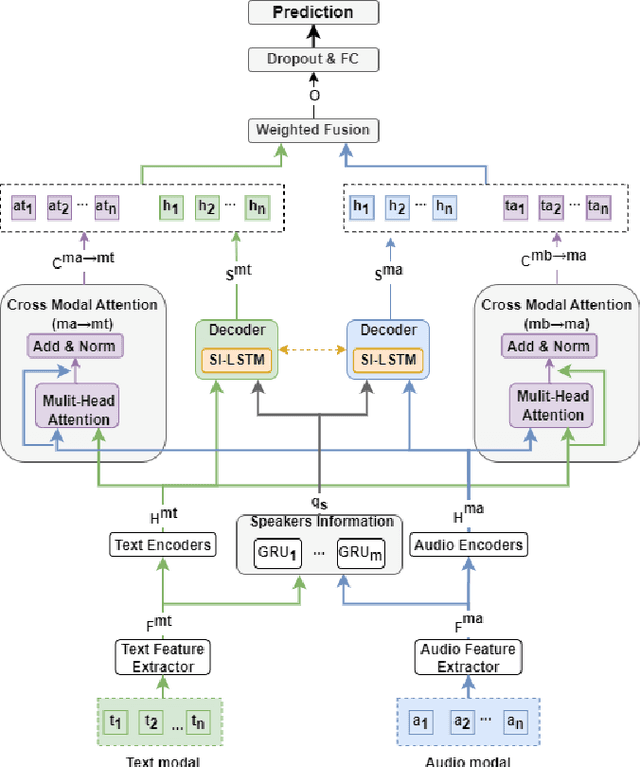
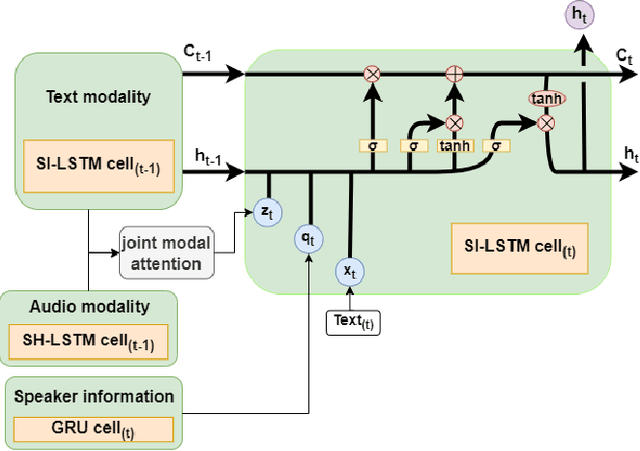
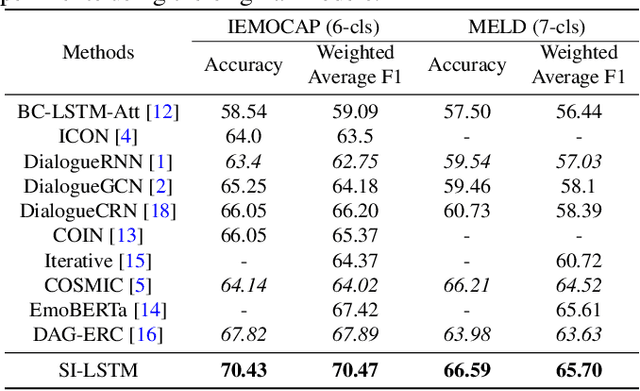
Emotion Recognition in Conversation~(ERC) across modalities is of vital importance for a variety of applications, including intelligent healthcare, artificial intelligence for conversation, and opinion mining over chat history. The crux of ERC is to model both cross-modality and cross-time interactions throughout the conversation. Previous methods have made progress in learning the time series information of conversation while lacking the ability to trace down the different emotional states of each speaker in a conversation. In this paper, we propose a recurrent structure called Speaker Information Enhanced Long-Short Term Memory (SI-LSTM) for the ERC task, where the emotional states of the distinct speaker can be tracked in a sequential way to enhance the learning of the emotion in conversation. Further, to improve the learning of multimodal features in ERC, we utilize a cross-modal attention component to fuse the features between different modalities and model the interaction of the important information from different modalities. Experimental results on two benchmark datasets demonstrate the superiority of the proposed SI-LSTM against the state-of-the-art baseline methods in the ERC task on multimodal data.
Autoregressive Modeling with Lookahead Attention
May 20, 2023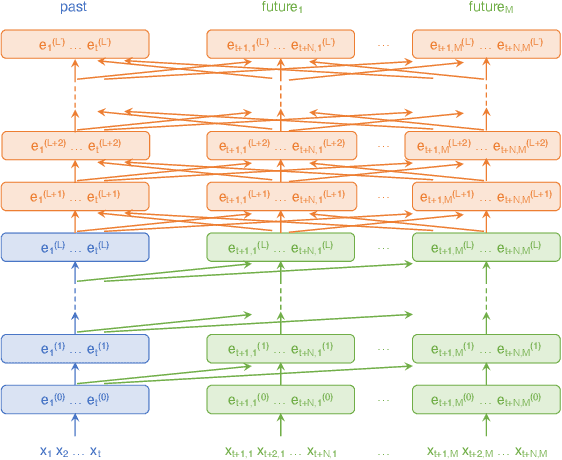
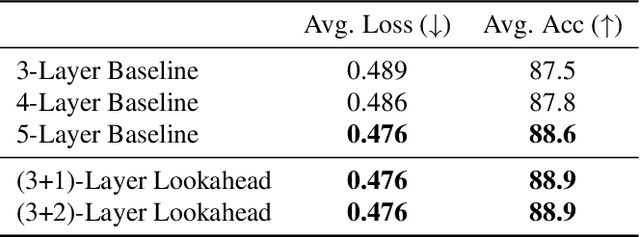
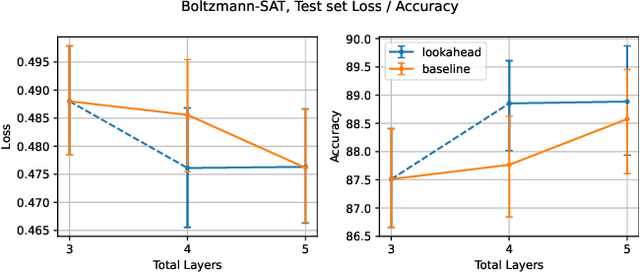
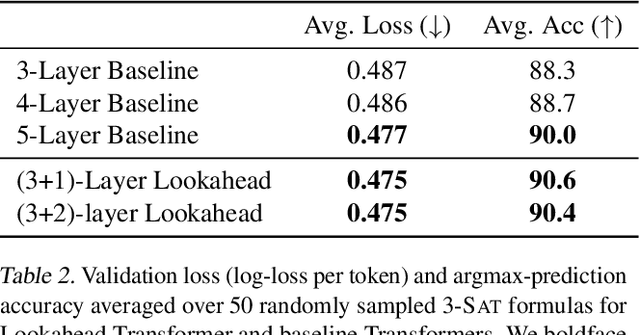
To predict the next token, autoregressive models ordinarily examine the past. Could they also benefit from also examining hypothetical futures? We consider a novel Transformer-based autoregressive architecture that estimates the next-token distribution by extrapolating multiple continuations of the past, according to some proposal distribution, and attending to these extended strings. This architecture draws insights from classical AI systems such as board game players: when making a local decision, a policy may benefit from exploring possible future trajectories and analyzing them. On multiple tasks including morphological inflection and Boolean satisfiability, our lookahead model is able to outperform the ordinary Transformer model of comparable size. However, on some tasks, it appears to be benefiting from the extra computation without actually using the lookahead information. We discuss possible variant architectures as well as future speedups.