 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Eye Tracking as a Source of Implicit Feedback in Recommender Systems: A Preliminary Analysis
May 12, 2023

Eye tracking in recommender systems can provide an additional source of implicit feedback, while helping to evaluate other sources of feedback. In this study, we use eye tracking data to inform a collaborative filtering model for movie recommendation providing an improvement over the click-based implementations and additionally analyze the area of interest (AOI) duration as related to the known information of click data and movies seen previously, showing AOI information consistently coincides with these items of interest.
A Kriging-Random Forest Hybrid Model for Real-time Ground Property Prediction during Earth Pressure Balance Shield Tunneling
May 09, 2023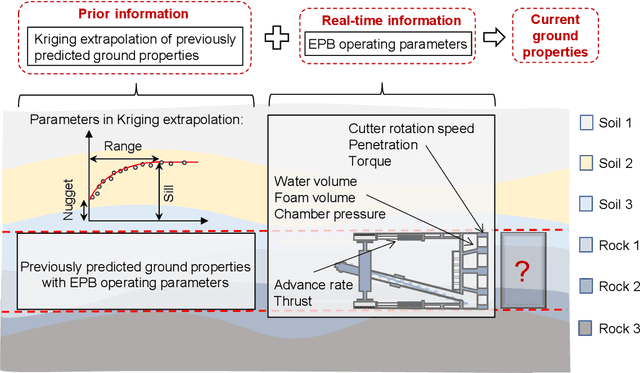
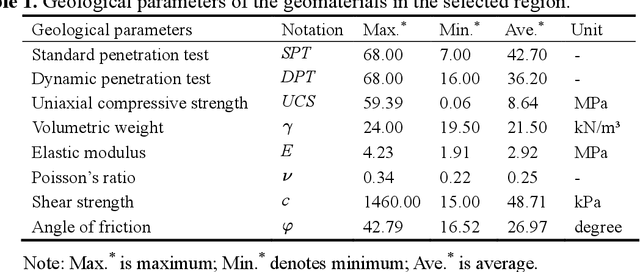
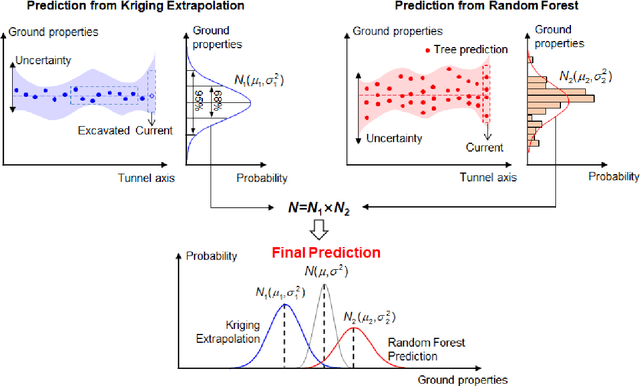
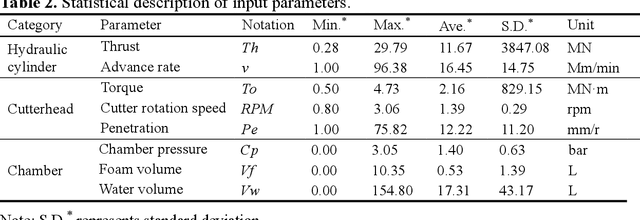
A kriging-random forest hybrid model is developed for real-time ground property prediction ahead of the earth pressure balanced shield by integrating Kriging extrapolation and random forest, which can guide shield operating parameter selection thereby mitigate construction risks. The proposed KRF algorithm synergizes two types of information: prior information and real-time information. The previously predicted ground properties with EPB operating parameters are extrapolated via the Kriging algorithm to provide prior information for the prediction of currently being excavated ground properties. The real-time information refers to the real-time operating parameters of the EPB shield, which are input into random forest to provide a real-time prediction of ground properties. The integration of these two predictions is achieved by assigning weights to each prediction according to their uncertainties, ensuring the prediction of KRF with minimum uncertainty. The performance of the KRF algorithm is assessed via a case study of the Changsha Metro Line 4 project. It reveals that the proposed KRF algorithm can predict ground properties with an accuracy of 93%, overperforming the existing algorithms of LightGBM, AdaBoost-CART, and DNN by 29%, 8%, and 12%, respectively. Another dataset from Shenzhen Metro Line 13 project is utilized to further evaluate the model generalization performance, revealing that the model can transfer its learned knowledge from one region to another with an accuracy of 89%.
Content-aware Token Sharing for Efficient Semantic Segmentation with Vision Transformers
Jun 03, 2023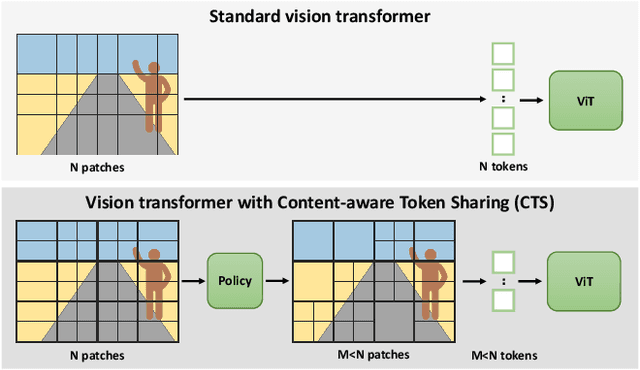
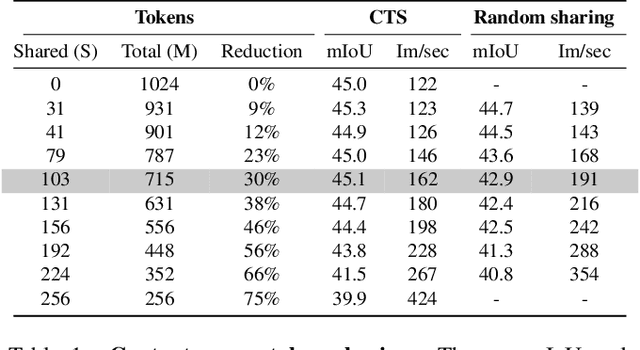
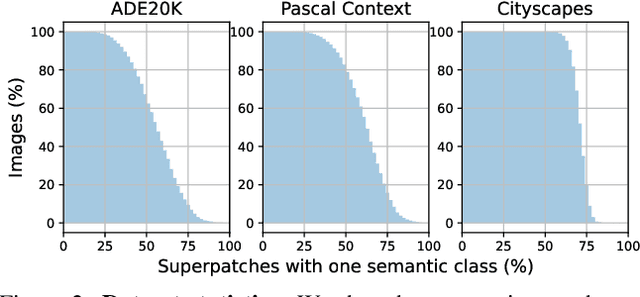
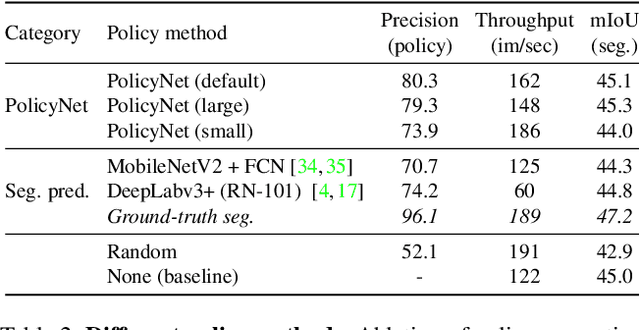
This paper introduces Content-aware Token Sharing (CTS), a token reduction approach that improves the computational efficiency of semantic segmentation networks that use Vision Transformers (ViTs). Existing works have proposed token reduction approaches to improve the efficiency of ViT-based image classification networks, but these methods are not directly applicable to semantic segmentation, which we address in this work. We observe that, for semantic segmentation, multiple image patches can share a token if they contain the same semantic class, as they contain redundant information. Our approach leverages this by employing an efficient, class-agnostic policy network that predicts if image patches contain the same semantic class, and lets them share a token if they do. With experiments, we explore the critical design choices of CTS and show its effectiveness on the ADE20K, Pascal Context and Cityscapes datasets, various ViT backbones, and different segmentation decoders. With Content-aware Token Sharing, we are able to reduce the number of processed tokens by up to 44%, without diminishing the segmentation quality.
Unsupervised Low Light Image Enhancement Using SNR-Aware Swin Transformer
Jun 03, 2023
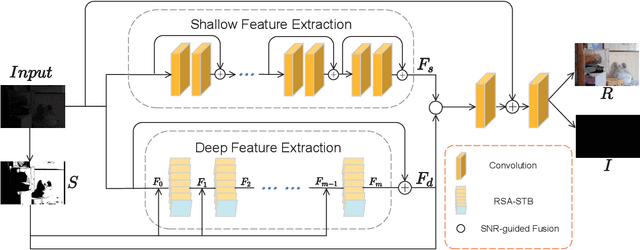
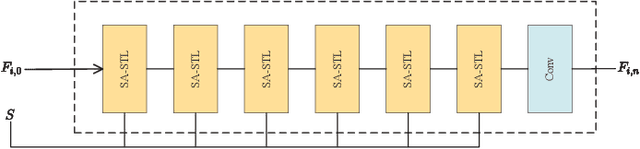
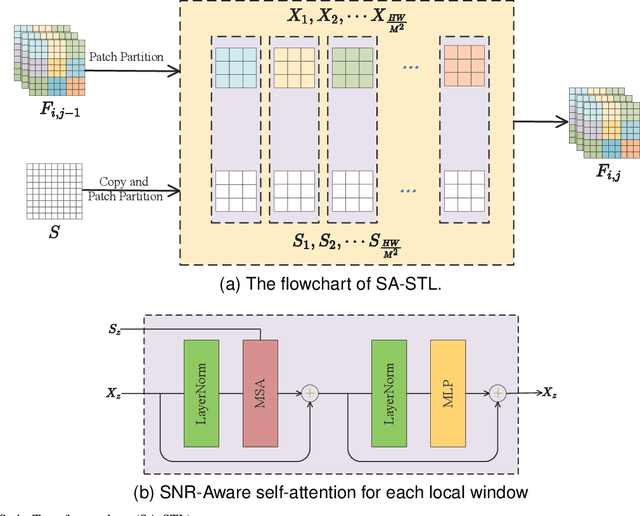
Image captured under low-light conditions presents unpleasing artifacts, which debilitate the performance of feature extraction for many upstream visual tasks. Low-light image enhancement aims at improving brightness and contrast, and further reducing noise that corrupts the visual quality. Recently, many image restoration methods based on Swin Transformer have been proposed and achieve impressive performance. However, On one hand, trivially employing Swin Transformer for low-light image enhancement would expose some artifacts, including over-exposure, brightness imbalance and noise corruption, etc. On the other hand, it is impractical to capture image pairs of low-light images and corresponding ground-truth, i.e. well-exposed image in same visual scene. In this paper, we propose a dual-branch network based on Swin Transformer, guided by a signal-to-noise ratio prior map which provides the spatial-varying information for low-light image enhancement. Moreover, we leverage unsupervised learning to construct the optimization objective based on Retinex model, to guide the training of proposed network. Experimental results demonstrate that the proposed model is competitive with the baseline models.
Small Moving Object Detection Algorithm Based on Motion Information
Jan 05, 2023
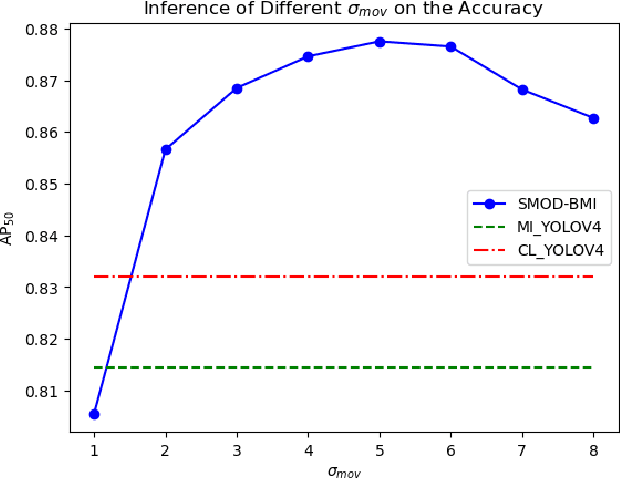
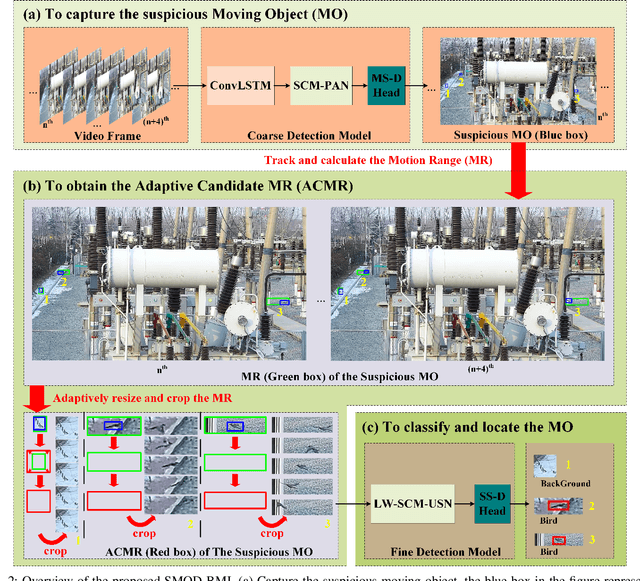
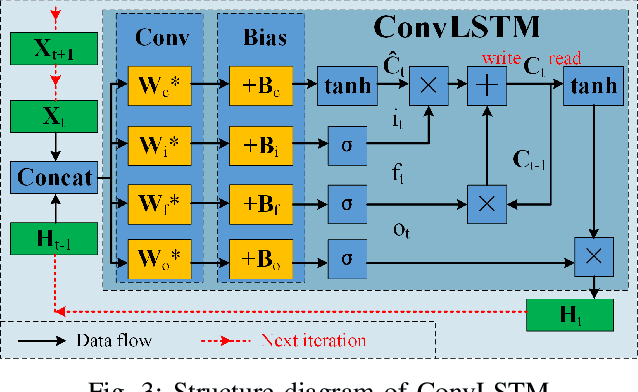
A Samll Moving Object Detection algorithm Based on Motion Information (SMOD-BMI) was proposed to detect small moving objects with low Signal-to-Noise Ratio (SNR). Firstly, To capture suspicious moving objects, a ConvLSTM-SCM-PAN model structure was designed, in which the Convolutional Long and Short Time Memory (ConvLSTM) network fused temporal and spatial information, the Selective Concatenate Module (SCM) was selected to solve the problem of channel unbalance during feature fusion, and the Path Aggregation Network (PAN) located the suspicious moving objects. Then, an object tracking algorithm is used to track suspicious moving objects and calculate their Motion Range (MR). At the same time, according to the moving speed of the suspicious moving objects, the size of their MR is adjusted adaptively (To be specific, if the objects move slowly, we expand their MR according their speed to ensure the contextual environment information) to obtain their Adaptive Candidate Motion Range (ACMR), so as to ensure that the SNR of the moving object is improved while the necessary context information is retained adaptively. Finally, a LightWeight SCM U-Shape Net (LW-SCM-USN) based on ACMR with a SCM module is designed to classify and locate small moving objects accurately and quickly. In this paper, the moving bird in surveillance video is used as the experimental dataset to verify the performance of the algorithm. The experimental results show that the proposed small moving object detection method based on motion information can effectively reduce the missing rate and false detection rate, and its performance is better than the existing moving small object detection method of SOTA.
Bayesian Renormalization
May 17, 2023In this note we present a fully information theoretic approach to renormalization inspired by Bayesian statistical inference, which we refer to as Bayesian Renormalization. The main insight of Bayesian Renormalization is that the Fisher metric defines a correlation length that plays the role of an emergent RG scale quantifying the distinguishability between nearby points in the space of probability distributions. This RG scale can be interpreted as a proxy for the maximum number of unique observations that can be made about a given system during a statistical inference experiment. The role of the Bayesian Renormalization scheme is subsequently to prepare an effective model for a given system up to a precision which is bounded by the aforementioned scale. In applications of Bayesian Renormalization to physical systems, the emergent information theoretic scale is naturally identified with the maximum energy that can be probed by current experimental apparatus, and thus Bayesian Renormalization coincides with ordinary renormalization. However, Bayesian Renormalization is sufficiently general to apply even in circumstances in which an immediate physical scale is absent, and thus provides an ideal approach to renormalization in data science contexts. To this end, we provide insight into how the Bayesian Renormalization scheme relates to existing methods for data compression and data generation such as the information bottleneck and the diffusion learning paradigm.
Edge Directionality Improves Learning on Heterophilic Graphs
May 17, 2023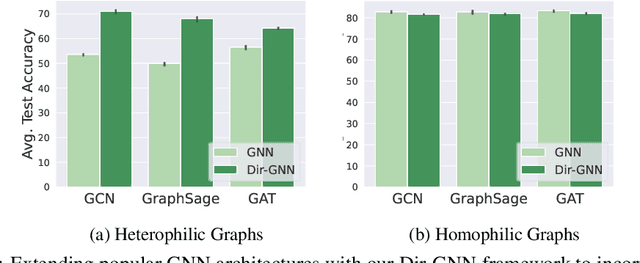

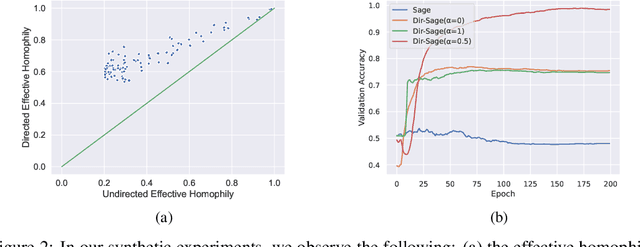
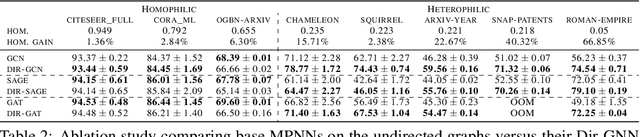
Graph Neural Networks (GNNs) have become the de-facto standard tool for modeling relational data. However, while many real-world graphs are directed, the majority of today's GNN models discard this information altogether by simply making the graph undirected. The reasons for this are historical: 1) many early variants of spectral GNNs explicitly required undirected graphs, and 2) the first benchmarks on homophilic graphs did not find significant gain from using direction. In this paper, we show that in heterophilic settings, treating the graph as directed increases the effective homophily of the graph, suggesting a potential gain from the correct use of directionality information. To this end, we introduce Directed Graph Neural Network (Dir-GNN), a novel general framework for deep learning on directed graphs. Dir-GNN can be used to extend any Message Passing Neural Network (MPNN) to account for edge directionality information by performing separate aggregations of the incoming and outgoing edges. We prove that Dir-GNN matches the expressivity of the Directed Weisfeiler-Lehman test, exceeding that of conventional MPNNs. In extensive experiments, we validate that while our framework leaves performance unchanged on homophilic datasets, it leads to large gains over base models such as GCN, GAT and GraphSage on heterophilic benchmarks, outperforming much more complex methods and achieving new state-of-the-art results.
Deep Metric Tensor Regularized Policy Gradient
May 18, 2023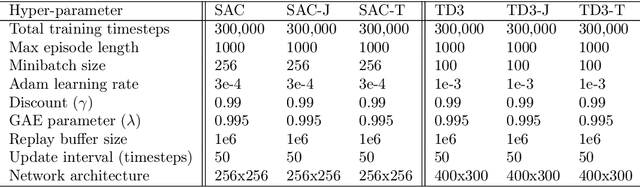
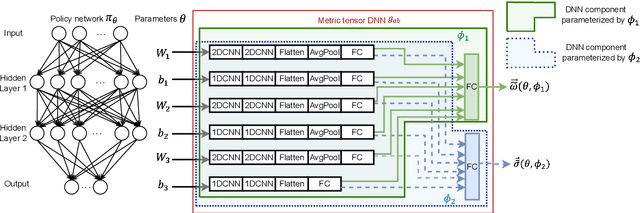

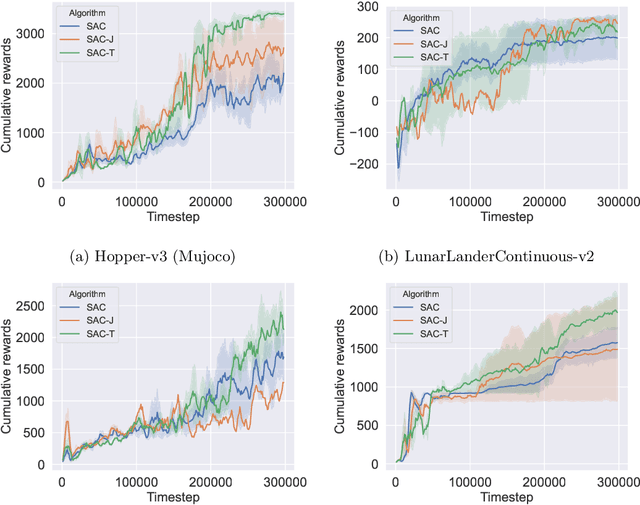
Policy gradient algorithms are an important family of deep reinforcement learning techniques. Many past research endeavors focused on using the first-order policy gradient information to train policy networks. Different from these works, we conduct research in this paper driven by the believe that properly utilizing and controlling Hessian information associated with the policy gradient can noticeably improve the performance of policy gradient algorithms. One key Hessian information that attracted our attention is the Hessian trace, which gives the divergence of the policy gradient vector field in the Euclidean policy parametric space. We set the goal to generalize this Euclidean policy parametric space into a general Riemmanian manifold by introducing a metric tensor field $g_ab$ in the parametric space. This is achieved through newly developed mathematical tools, deep learning algorithms, and metric tensor deep neural networks (DNNs). Armed with these technical developments, we propose a new policy gradient algorithm that learns to minimize the absolute divergence in the Riemannian manifold as an important regularization mechanism, allowing the Riemannian manifold to smoothen its policy gradient vector field. The newly developed algorithm is experimentally studied on several benchmark reinforcement learning problems. Our experiments clearly show that the new metric tensor regularized algorithm can significantly outperform its counterpart that does not use our regularization technique. Additional experimental analysis further suggests that the trained metric tensor DNN and the corresponding metric tensor $g_{ab}$ can effectively reduce the absolute divergence towards zero in the Riemannian manifold.
ConsistentNeRF: Enhancing Neural Radiance Fields with 3D Consistency for Sparse View Synthesis
May 18, 2023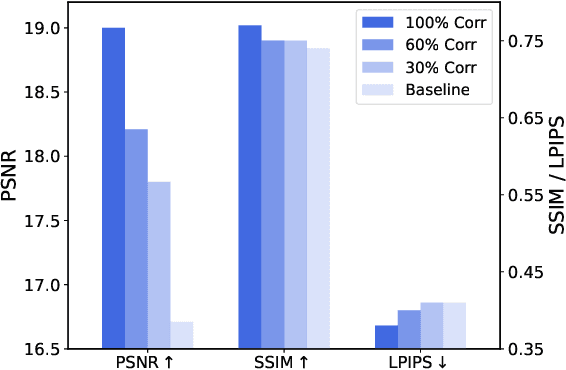
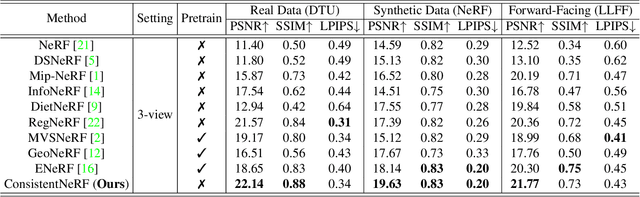
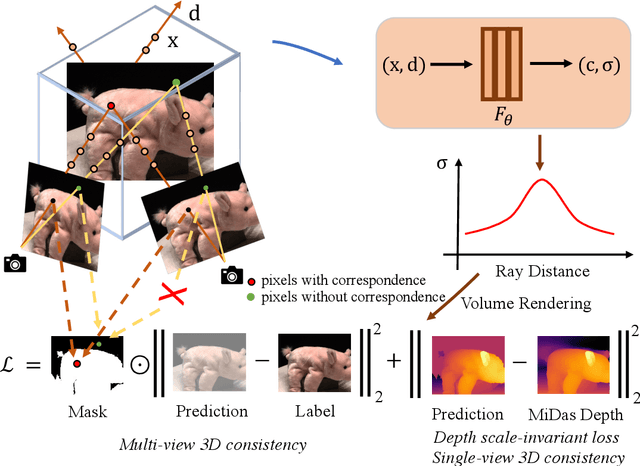

Neural Radiance Fields (NeRF) has demonstrated remarkable 3D reconstruction capabilities with dense view images. However, its performance significantly deteriorates under sparse view settings. We observe that learning the 3D consistency of pixels among different views is crucial for improving reconstruction quality in such cases. In this paper, we propose ConsistentNeRF, a method that leverages depth information to regularize both multi-view and single-view 3D consistency among pixels. Specifically, ConsistentNeRF employs depth-derived geometry information and a depth-invariant loss to concentrate on pixels that exhibit 3D correspondence and maintain consistent depth relationships. Extensive experiments on recent representative works reveal that our approach can considerably enhance model performance in sparse view conditions, achieving improvements of up to 94% in PSNR, 76% in SSIM, and 31% in LPIPS compared to the vanilla baselines across various benchmarks, including DTU, NeRF Synthetic, and LLFF.
Trading Syntax Trees for Wordpieces: Target-oriented Opinion Words Extraction with Wordpieces and Aspect Enhancement
May 18, 2023
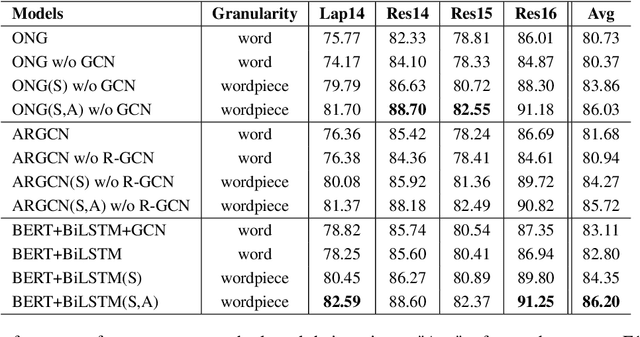
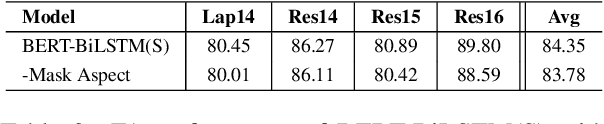

State-of-the-art target-oriented opinion word extraction (TOWE) models typically use BERT-based text encoders that operate on the word level, along with graph convolutional networks (GCNs) that incorporate syntactic information extracted from syntax trees. These methods achieve limited gains with GCNs and have difficulty using BERT wordpieces. Meanwhile, BERT wordpieces are known to be effective at representing rare words or words with insufficient context information. To address this issue, this work trades syntax trees for BERT wordpieces by entirely removing the GCN component from the methods' architectures. To enhance TOWE performance, we tackle the issue of aspect representation loss during encoding. Instead of solely utilizing a sentence as the input, we use a sentence-aspect pair. Our relatively simple approach achieves state-of-the-art results on benchmark datasets and should serve as a strong baseline for further research.