 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AV-SepFormer: Cross-Attention SepFormer for Audio-Visual Target Speaker Extraction
Jun 25, 2023
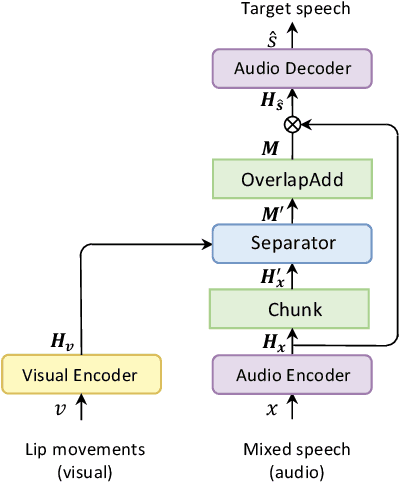

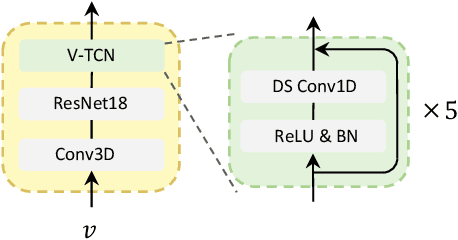

Visual information can serve as an effective cue for target speaker extraction (TSE) and is vital to improving extraction performance. In this paper, we propose AV-SepFormer, a SepFormer-based attention dual-scale model that utilizes cross- and self-attention to fuse and model features from audio and visual. AV-SepFormer splits the audio feature into a number of chunks, equivalent to the length of the visual feature. Then self- and cross-attention are employed to model and fuse the multi-modal features. Furthermore, we use a novel 2D positional encoding, that introduces the positional information between and within chunks and provides significant gains over the traditional positional encoding. Our model has two key advantages: the time granularity of audio chunked feature is synchronized to the visual feature, which alleviates the harm caused by the inconsistency of audio and video sampling rate; by combining self- and cross-attention, feature fusion and speech extraction processes are unified within an attention paradigm. The experimental results show that AV-SepFormer significantly outperforms other existing methods.
HonestBait: Forward References for Attractive but Faithful Headline Generation
Jun 26, 2023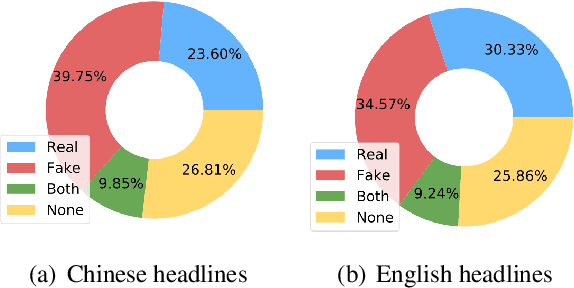

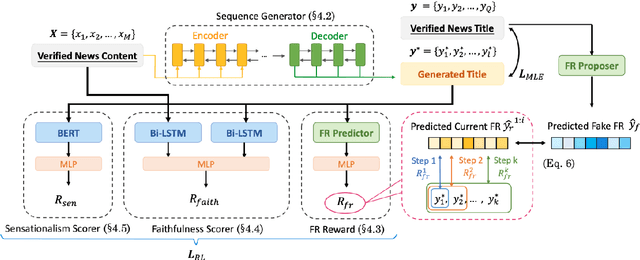
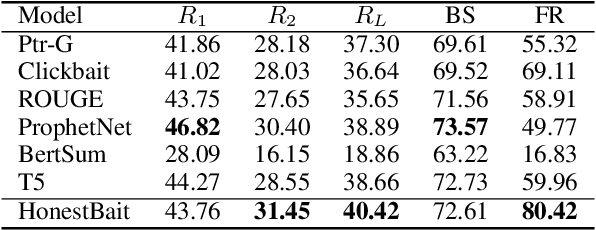
Current methods for generating attractive headlines often learn directly from data, which bases attractiveness on the number of user clicks and views. Although clicks or views do reflect user interest, they can fail to reveal how much interest is raised by the writing style and how much is due to the event or topic itself. Also, such approaches can lead to harmful inventions by over-exaggerating the content, aggravating the spread of false information. In this work, we propose HonestBait, a novel framework for solving these issues from another aspect: generating headlines using forward references (FRs), a writing technique often used for clickbait. A self-verification process is included during training to avoid spurious inventions. We begin with a preliminary user study to understand how FRs affect user interest, after which we present PANCO1, an innovative dataset containing pairs of fake news with verified news for attractive but faithful news headline generation. Automatic metrics and human evaluations show that our framework yields more attractive results (+11.25% compared to human-written verified news headlines) while maintaining high veracity, which helps promote real information to fight against fake news.
Transfer Learning across Several Centuries: Machine and Historian Integrated Method to Decipher Royal Secretary's Diary
Jun 26, 2023
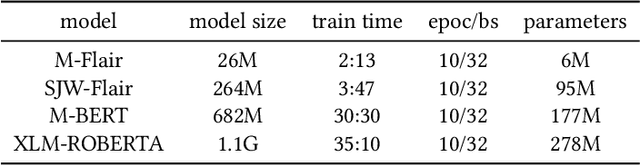
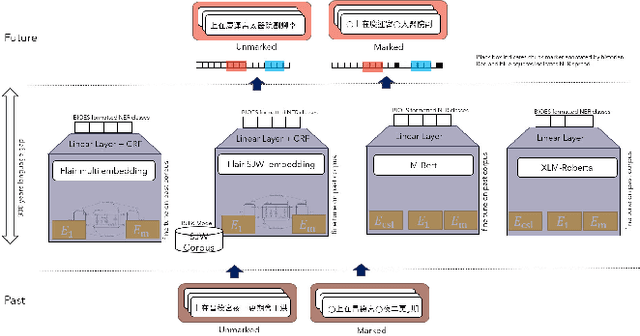
A named entity recognition and classification plays the first and foremost important role in capturing semantics in data and anchoring in translation as well as downstream study for history. However, NER in historical text has faced challenges such as scarcity of annotated corpus, multilanguage variety, various noise, and different convention far different from the contemporary language model. This paper introduces Korean historical corpus (Diary of Royal secretary which is named SeungJeongWon) recorded over several centuries and recently added with named entity information as well as phrase markers which historians carefully annotated. We fined-tuned the language model on history corpus, conducted extensive comparative experiments using our language model and pretrained muti-language models. We set up the hypothesis of combination of time and annotation information and tested it based on statistical t test. Our finding shows that phrase markers clearly improve the performance of NER model in predicting unseen entity in documents written far different time period. It also shows that each of phrase marker and corpus-specific trained model does not improve the performance. We discuss the future research directions and practical strategies to decipher the history document.
Fairness Scheduling in User-Centric Cell-Free Massive MIMO Wireless Networks
Jul 03, 2023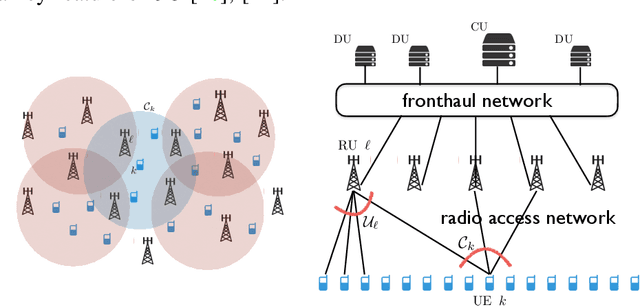
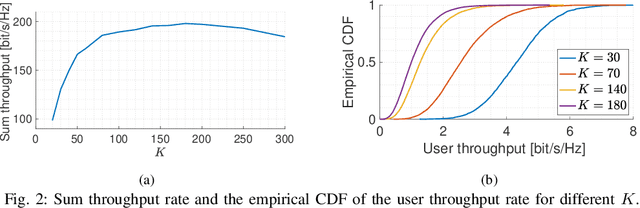
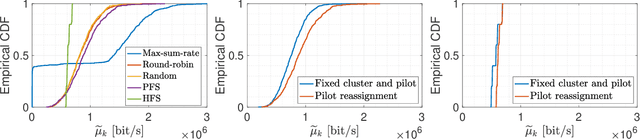
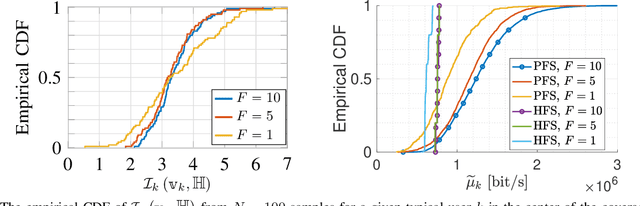
We consider a user-centric cell-free massive MIMO wireless network with $L$ remote radio units, each with $M$ antennas, serving $K_{\rm tot}$ user equipments (UEs). Most of the literature considers the regime $LM \gg K_{\rm tot}$, where the $K$ UEs are active on each time-frequency slot, and evaluates the system performance in terms of ergodic rates. In this paper, we take a quite different viewpoint. We observe that the regime of $LM \gg K_{\rm tot}$ corresponds to a lightly loaded system with low sum spectral efficiency (SE). In contrast, in most relevant scenarios, the number of UEs is much larger than the total number of antennas, but users are not all active at the same time. To achieve high sum SE and handle $K_{\rm tot} \gg ML$, users must be scheduled over the time-frequency resource. The number of active users $K_{\rm act} \leq K_{\rm tot}$ must be chosen such that: 1) the network operates close to its maximum SE; 2) the active user set must be chosen dynamically over time in order to enforce fairness in terms of per-user time-averaged throughput rates. The fairness scheduling problem is formulated as the maximization of a concave componentwise non-decreasing network utility function of the per-user rates. Intermittent user activity imposes slot-by-slot coding/decoding which prevents the achievability of ergodic rates. Hence, we model the per-slot service rates using information outage probability. To obtain a tractable problem, we make a decoupling assumption on the CDF of the instantaneous mutual information seen at each UE $k$ receiver. We approximately enforce this condition with a conflict graph that prevents the simultaneous scheduling of users with large pilot contamination and propose an adaptive scheme for instantaneous service rate scheduling. Overall, the proposed dynamic scheduling is robust to system model uncertainties and can be easily implemented in practice.
Reduction of Class Activation Uncertainty with Background Information
May 05, 2023Multitask learning is a popular approach to training high-performing neural networks with improved generalization. In this paper, we propose a background class to achieve improved generalization at a lower computation compared to multitask learning to help researchers and organizations with limited computation power. We also present a methodology for selecting background images and discuss potential future improvements. We apply our approach to several datasets and achieved improved generalization with much lower computation. We also investigate class activation mappings (CAMs) of the trained model and observed the tendency towards looking at a bigger picture in a few class classification problems with the proposed model training methodology. Example scripts are available in the `CAM' folder of the following GitHub Repository: github.com/dipuk0506/UQ
Spiking Neural Network for Ultra-low-latency and High-accurate Object Detection
Jun 27, 2023
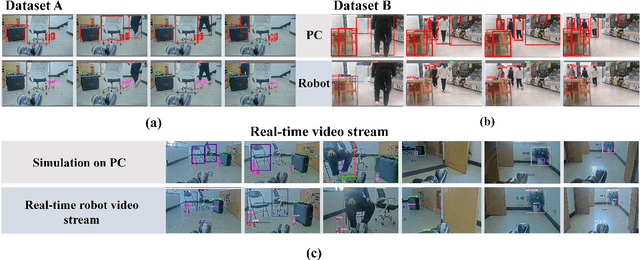
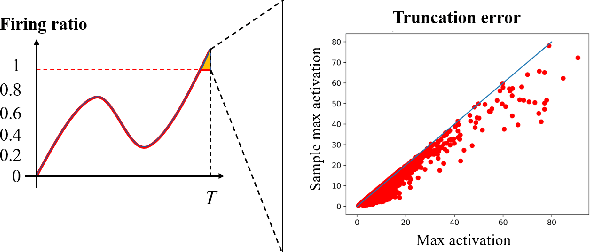
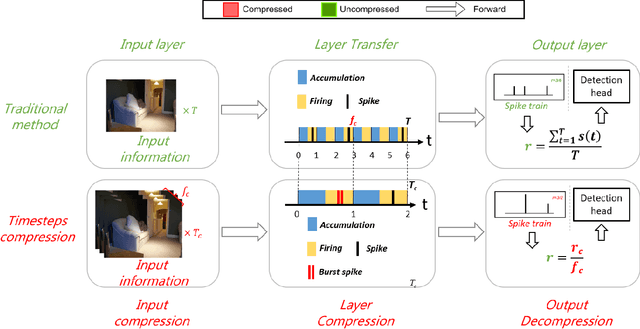
Spiking Neural Networks (SNNs) have garnered widespread interest for their energy efficiency and brain-inspired event-driven properties. While recent methods like Spiking-YOLO have expanded the SNNs to more challenging object detection tasks, they often suffer from high latency and low detection accuracy, making them difficult to deploy on latency sensitive mobile platforms. Furthermore, the conversion method from Artificial Neural Networks (ANNs) to SNNs is hard to maintain the complete structure of the ANNs, resulting in poor feature representation and high conversion errors. To address these challenges, we propose two methods: timesteps compression and spike-time-dependent integrated (STDI) coding. The former reduces the timesteps required in ANN-SNN conversion by compressing information, while the latter sets a time-varying threshold to expand the information holding capacity. We also present a SNN-based ultra-low latency and high accurate object detection model (SUHD) that achieves state-of-the-art performance on nontrivial datasets like PASCAL VOC and MS COCO, with about remarkable 750x fewer timesteps and 30% mean average precision (mAP) improvement, compared to the Spiking-YOLO on MS COCO datasets. To the best of our knowledge, SUHD is the deepest spike-based object detection model to date that achieves ultra low timesteps to complete the lossless conversion.
Optimal Execution Using Reinforcement Learning
Jun 19, 2023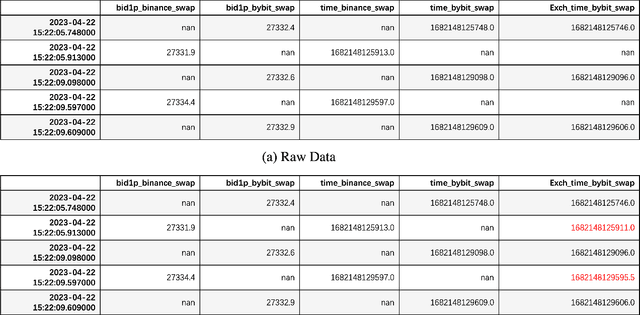
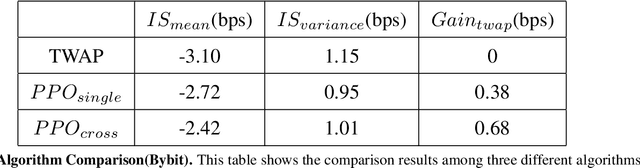
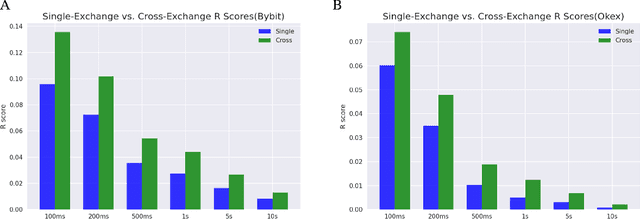
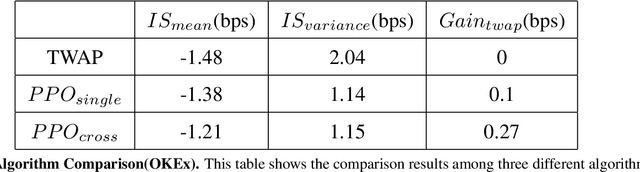
This work is about optimal order execution, where a large order is split into several small orders to maximize the implementation shortfall. Based on the diversity of cryptocurrency exchanges, we attempt to extract cross-exchange signals by aligning data from multiple exchanges for the first time. Unlike most previous studies that focused on using single-exchange information, we discuss the impact of cross-exchange signals on the agent's decision-making in the optimal execution problem. Experimental results show that cross-exchange signals can provide additional information for the optimal execution of cryptocurrency to facilitate the optimal execution process.
NOMA-Assisted Grant-Free Transmission: How to Design Pre-Configured SNR Levels?
Jul 03, 2023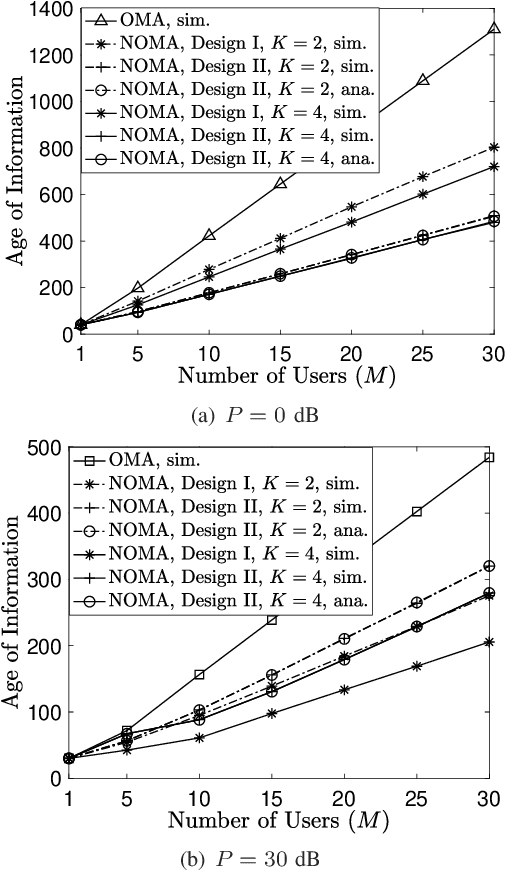
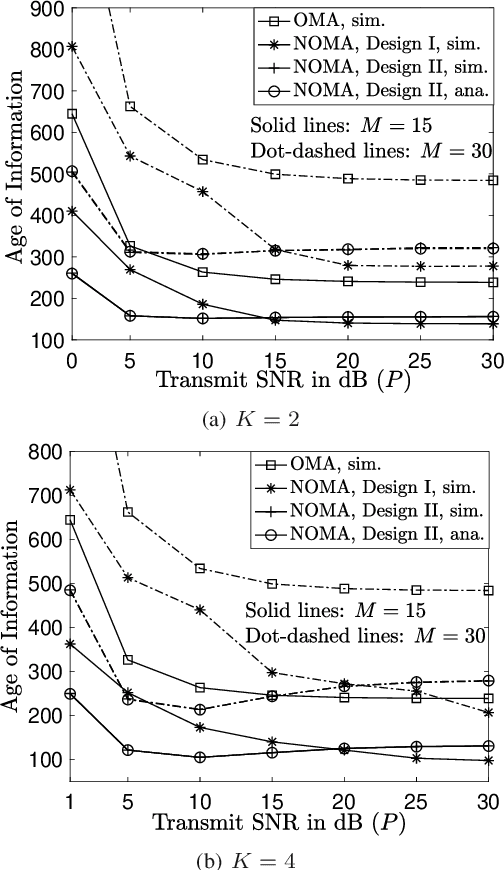
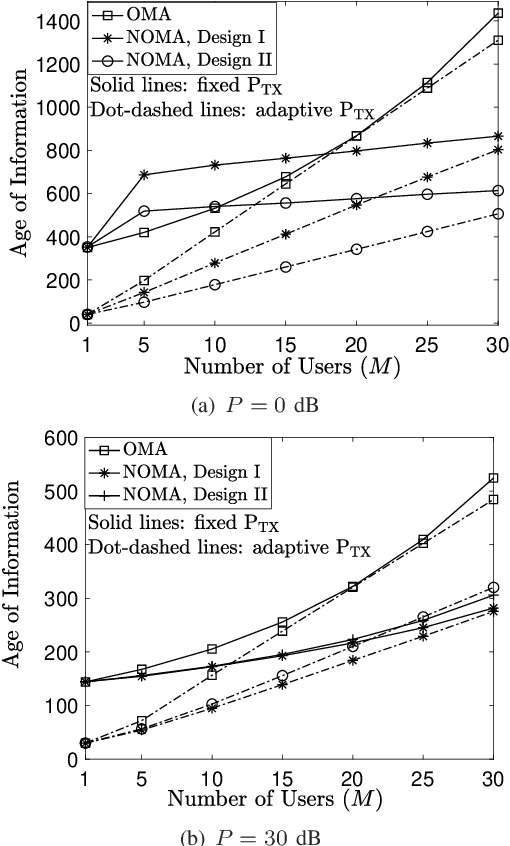

An effective way to realize non-orthogonal multiple access (NOMA) assisted grant-free transmission is to first create multiple receive signal-to-noise ratio (SNR) levels and then serve multiple grant-free users by employing these SNR levels as bandwidth resources. These SNR levels need to be pre-configured prior to the grant-free transmission and have great impact on the performance of grant-free networks. The aim of this letter is to illustrate different designs for configuring the SNR levels and investigate their impact on the performance of grant-free transmission, where age-of-information is used as the performance metric. The presented analytical and simulation results demonstrate the performance gain achieved by NOMA over orthogonal multiple access, and also reveal the relative merits of the considered designs for pre-configured SNR levels.
Scaling Distributed Multi-task Reinforcement Learning with Experience Sharing
Jul 11, 2023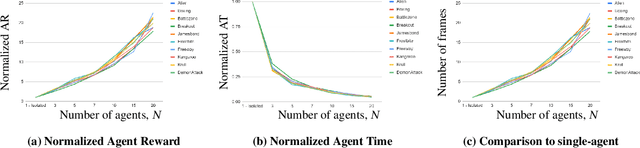
Recently, DARPA launched the ShELL program, which aims to explore how experience sharing can benefit distributed lifelong learning agents in adapting to new challenges. In this paper, we address this issue by conducting both theoretical and empirical research on distributed multi-task reinforcement learning (RL), where a group of $N$ agents collaboratively solves $M$ tasks without prior knowledge of their identities. We approach the problem by formulating it as linearly parameterized contextual Markov decision processes (MDPs), where each task is represented by a context that specifies the transition dynamics and rewards. To tackle this problem, we propose an algorithm called DistMT-LSVI. First, the agents identify the tasks, and then they exchange information through a central server to derive $\epsilon$-optimal policies for the tasks. Our research demonstrates that to achieve $\epsilon$-optimal policies for all $M$ tasks, a single agent using DistMT-LSVI needs to run a total number of episodes that is at most $\tilde{\mathcal{O}}({d^3H^6(\epsilon^{-2}+c_{\rm sep}^{-2})}\cdot M/N)$, where $c_{\rm sep}>0$ is a constant representing task separability, $H$ is the horizon of each episode, and $d$ is the feature dimension of the dynamics and rewards. Notably, DistMT-LSVI improves the sample complexity of non-distributed settings by a factor of $1/N$, as each agent independently learns $\epsilon$-optimal policies for all $M$ tasks using $\tilde{\mathcal{O}}(d^3H^6M\epsilon^{-2})$ episodes. Additionally, we provide numerical experiments conducted on OpenAI Gym Atari environments that validate our theoretical findings.
MinkSORT: A 3D deep feature extractor using sparse convolutions to improve 3D multi-object tracking in greenhouse tomato plants
Jul 11, 2023
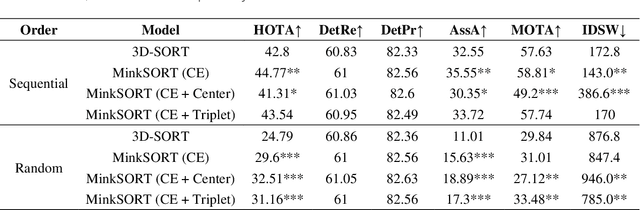

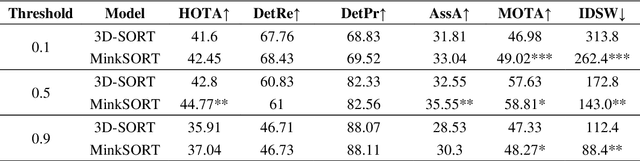
The agro-food industry is turning to robots to address the challenge of labour shortage. However, agro-food environments pose difficulties for robots due to high variation and occlusions. In the presence of these challenges, accurate world models, with information about object location, shape, and properties, are crucial for robots to perform tasks accurately. Building such models is challenging due to the complex and unique nature of agro-food environments, and errors in the model can lead to task execution issues. In this paper, we propose MinkSORT, a novel method for generating tracking features using a 3D sparse convolutional network in a deepSORT-like approach to improve the accuracy of world models in agro-food environments. We evaluated our feature extractor network using real-world data collected in a tomato greenhouse, which significantly improved the performance of our baseline model that tracks tomato positions in 3D using a Kalman filter and Mahalanobis distance. Our deep learning feature extractor improved the HOTA from 42.8% to 44.77%, the association accuracy from 32.55% to 35.55%, and the MOTA from 57.63% to 58.81%. We also evaluated different contrastive loss functions for training our deep learning feature extractor and demonstrated that our approach leads to improved performance in terms of three separate precision and recall detection outcomes. Our method improves world model accuracy, enabling robots to perform tasks such as harvesting and plant maintenance with greater efficiency and accuracy, which is essential for meeting the growing demand for food in a sustainable manner.