 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Collaborative Transfer Learning Framework for Cross-domain Recommendation
Jun 26, 2023
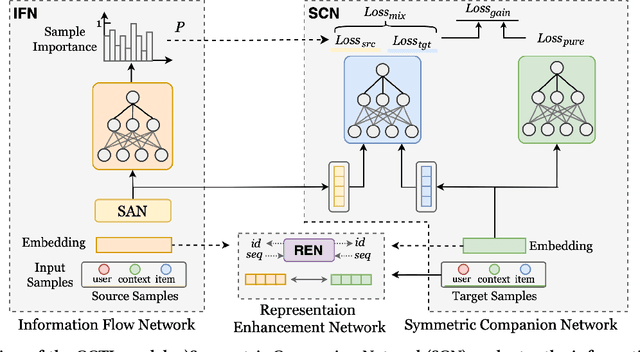
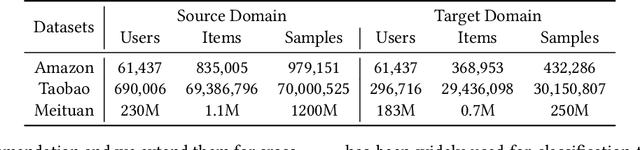
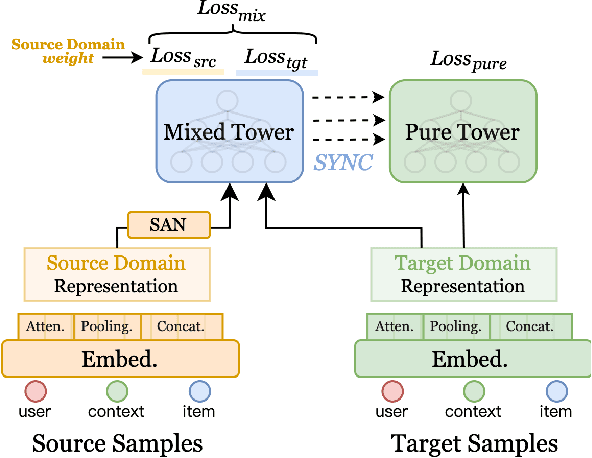
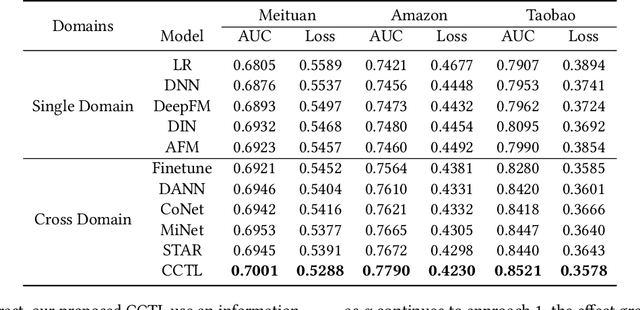
In the recommendation systems, there are multiple business domains to meet the diverse interests and needs of users, and the click-through rate(CTR) of each domain can be quite different, which leads to the demand for CTR prediction modeling for different business domains. The industry solution is to use domain-specific models or transfer learning techniques for each domain. The disadvantage of the former is that the data from other domains is not utilized by a single domain model, while the latter leverage all the data from different domains, but the fine-tuned model of transfer learning may trap the model in a local optimum of the source domain, making it difficult to fit the target domain. Meanwhile, significant differences in data quantity and feature schemas between different domains, known as domain shift, may lead to negative transfer in the process of transferring. To overcome these challenges, we propose the Collaborative Cross-Domain Transfer Learning Framework (CCTL). CCTL evaluates the information gain of the source domain on the target domain using a symmetric companion network and adjusts the information transfer weight of each source domain sample using the information flow network. This approach enables full utilization of other domain data while avoiding negative migration. Additionally, a representation enhancement network is used as an auxiliary task to preserve domain-specific features. Comprehensive experiments on both public and real-world industrial datasets, CCTL achieved SOTA score on offline metrics. At the same time, the CCTL algorithm has been deployed in Meituan, bringing 4.37% CTR and 5.43% GMV lift, which is significant to the business.
Neural Fields for Interactive Visualization of Statistical Dependencies in 3D Simulation Ensembles
Jul 05, 2023
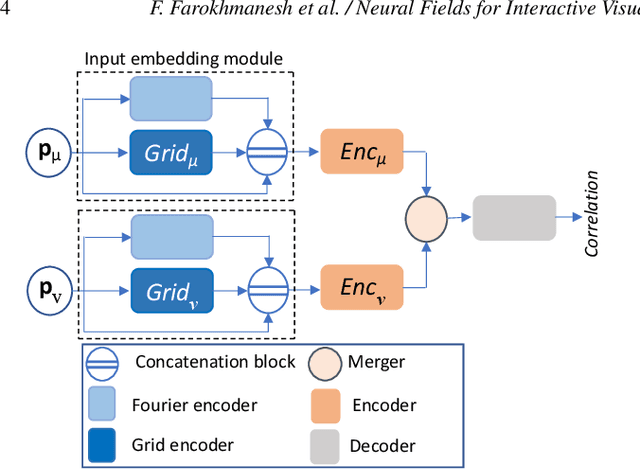
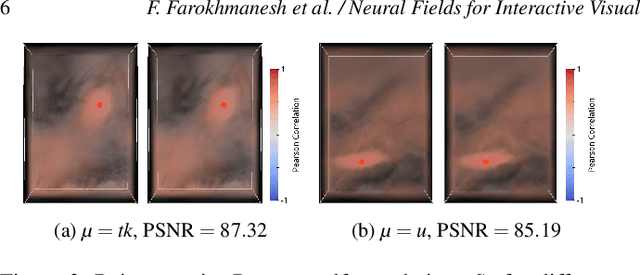
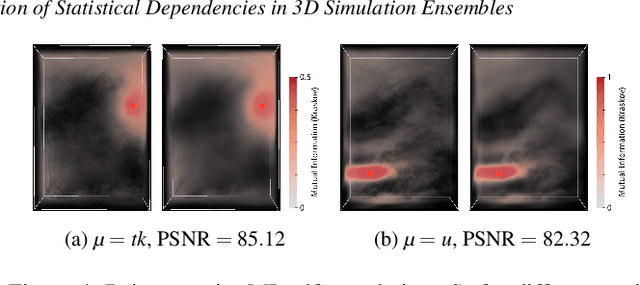
We present the first neural network that has learned to compactly represent and can efficiently reconstruct the statistical dependencies between the values of physical variables at different spatial locations in large 3D simulation ensembles. Going beyond linear dependencies, we consider mutual information as a measure of non-linear dependence. We demonstrate learning and reconstruction with a large weather forecast ensemble comprising 1000 members, each storing multiple physical variables at a 250 x 352 x 20 simulation grid. By circumventing compute-intensive statistical estimators at runtime, we demonstrate significantly reduced memory and computation requirements for reconstructing the major dependence structures. This enables embedding the estimator into a GPU-accelerated direct volume renderer and interactively visualizing all mutual dependencies for a selected domain point.
Quantifying the Echo Chamber Effect: An Embedding Distance-based Approach
Jul 10, 2023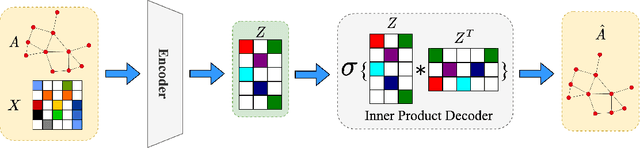
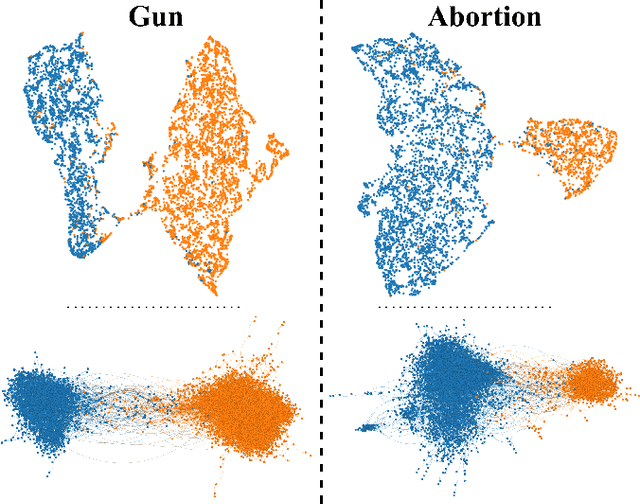
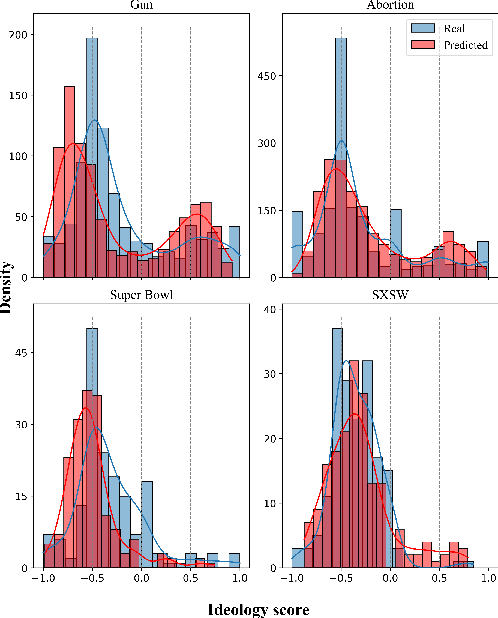
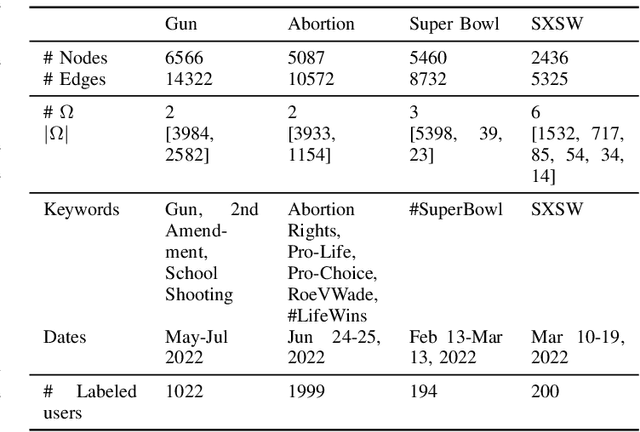
The rise of social media platforms has facilitated the formation of echo chambers, which are online spaces where users predominantly encounter viewpoints that reinforce their existing beliefs while excluding dissenting perspectives. This phenomenon significantly hinders information dissemination across communities and fuels societal polarization. Therefore, it is crucial to develop methods for quantifying echo chambers. In this paper, we present the Echo Chamber Score (ECS), a novel metric that assesses the cohesion and separation of user communities by measuring distances between users in the embedding space. In contrast to existing approaches, ECS is able to function without labels for user ideologies and makes no assumptions about the structure of the interaction graph. To facilitate measuring distances between users, we propose EchoGAE, a self-supervised graph autoencoder-based user embedding model that leverages users' posts and the interaction graph to embed them in a manner that reflects their ideological similarity. To assess the effectiveness of ECS, we use a Twitter dataset consisting of four topics - two polarizing and two non-polarizing. Our results showcase ECS's effectiveness as a tool for quantifying echo chambers and shedding light on the dynamics of online discourse.
Testing the Predictions of Surprisal Theory in 11 Languages
Jul 10, 2023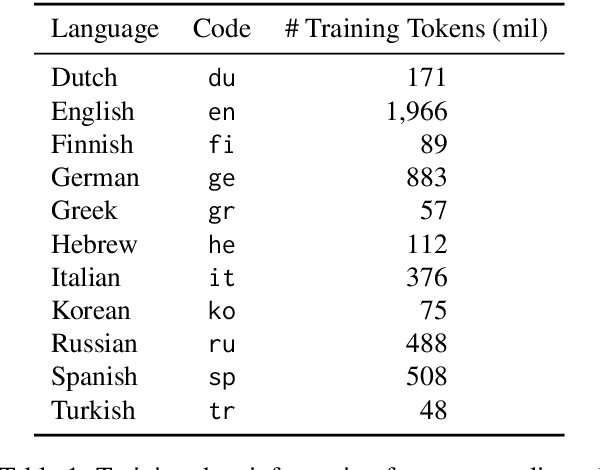
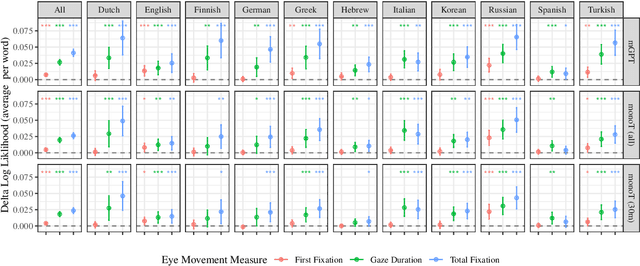
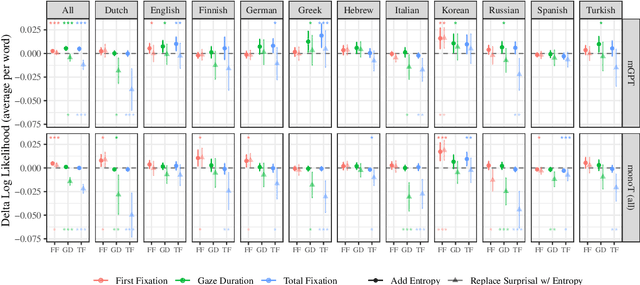

A fundamental result in psycholinguistics is that less predictable words take a longer time to process. One theoretical explanation for this finding is Surprisal Theory (Hale, 2001; Levy, 2008), which quantifies a word's predictability as its surprisal, i.e. its negative log-probability given a context. While evidence supporting the predictions of Surprisal Theory have been replicated widely, most have focused on a very narrow slice of data: native English speakers reading English texts. Indeed, no comprehensive multilingual analysis exists. We address this gap in the current literature by investigating the relationship between surprisal and reading times in eleven different languages, distributed across five language families. Deriving estimates from language models trained on monolingual and multilingual corpora, we test three predictions associated with surprisal theory: (i) whether surprisal is predictive of reading times; (ii) whether expected surprisal, i.e. contextual entropy, is predictive of reading times; (iii) and whether the linking function between surprisal and reading times is linear. We find that all three predictions are borne out crosslinguistically. By focusing on a more diverse set of languages, we argue that these results offer the most robust link to-date between information theory and incremental language processing across languages.
A unifying framework for differentially private quantum algorithms
Jul 10, 2023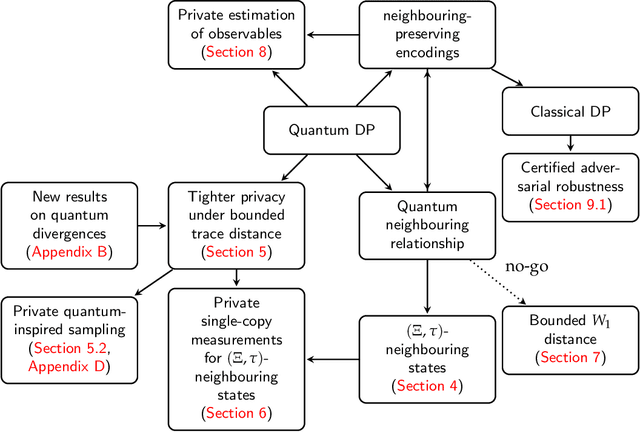

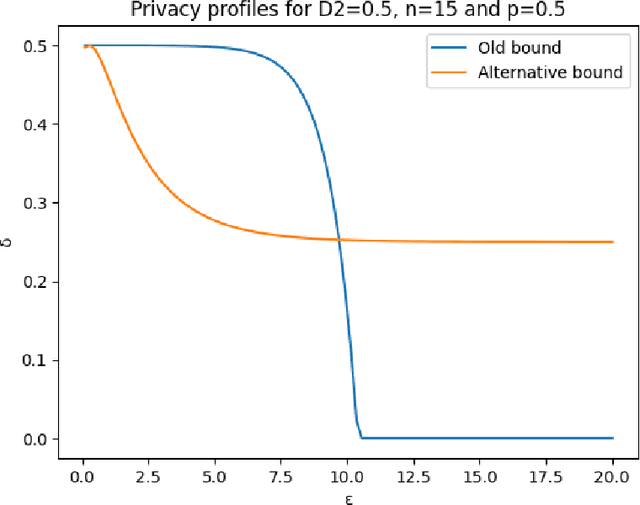

Differential privacy is a widely used notion of security that enables the processing of sensitive information. In short, differentially private algorithms map "neighbouring" inputs to close output distributions. Prior work proposed several quantum extensions of differential privacy, each of them built on substantially different notions of neighbouring quantum states. In this paper, we propose a novel and general definition of neighbouring quantum states. We demonstrate that this definition captures the underlying structure of quantum encodings and can be used to provide exponentially tighter privacy guarantees for quantum measurements. Our approach combines the addition of classical and quantum noise and is motivated by the noisy nature of near-term quantum devices. Moreover, we also investigate an alternative setting where we are provided with multiple copies of the input state. In this case, differential privacy can be ensured with little loss in accuracy combining concentration of measure and noise-adding mechanisms. En route, we prove the advanced joint convexity of the quantum hockey-stick divergence and we demonstrate how this result can be applied to quantum differential privacy. Finally, we complement our theoretical findings with an empirical estimation of the certified adversarial robustness ensured by differentially private measurements.
Temporal Conditioning Spiking Latent Variable Models of the Neural Response to Natural Visual Scenes
Jul 11, 2023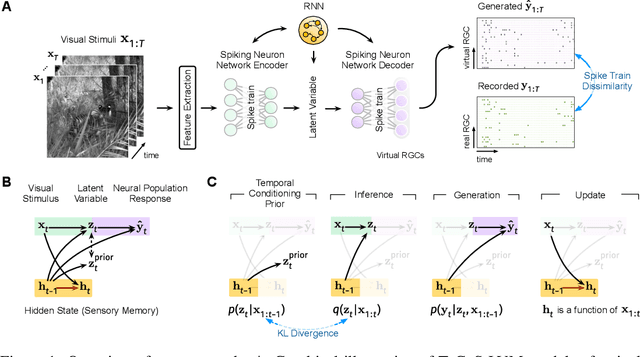


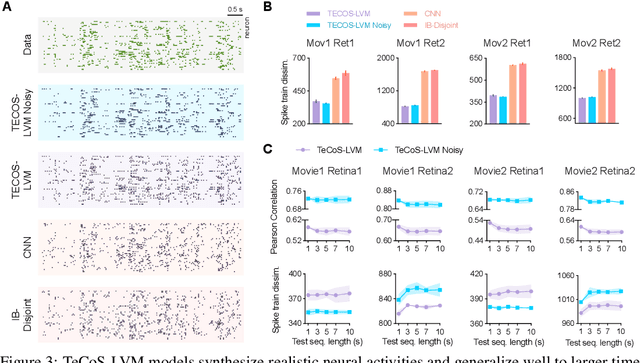
Developing computational models of neural response is crucial for understanding sensory processing and neural computations. Current state-of-the-art neural network methods use temporal filters to handle temporal dependencies, resulting in an unrealistic and inflexible processing flow. Meanwhile, these methods target trial-averaged firing rates and fail to capture important features in spike trains. This work presents the temporal conditioning spiking latent variable models (TeCoS-LVM) to simulate the neural response to natural visual stimuli. We use spiking neurons to produce spike outputs that directly match the recorded trains. This approach helps to avoid losing information embedded in the original spike trains. We exclude the temporal dimension from the model parameter space and introduce a temporal conditioning operation to allow the model to adaptively explore and exploit temporal dependencies in stimuli sequences in a natural paradigm. We show that TeCoS-LVM models can produce more realistic spike activities and accurately fit spike statistics than powerful alternatives. Additionally, learned TeCoS-LVM models can generalize well to longer time scales. Overall, while remaining computationally tractable, our model effectively captures key features of neural coding systems. It thus provides a useful tool for building accurate predictive computational accounts for various sensory perception circuits.
Application of data engineering approaches to address challenges in microbiome data for optimal medical decision-making
Jul 11, 2023The human gut microbiota is known to contribute to numerous physiological functions of the body and also implicated in a myriad of pathological conditions. Prolific research work in the past few decades have yielded valuable information regarding the relative taxonomic distribution of gut microbiota. Unfortunately, the microbiome data suffers from class imbalance and high dimensionality issues that must be addressed. In this study, we have implemented data engineering algorithms to address the above-mentioned issues inherent to microbiome data. Four standard machine learning classifiers (logistic regression (LR), support vector machines (SVM), random forests (RF), and extreme gradient boosting (XGB) decision trees) were implemented on a previously published dataset. The issue of class imbalance and high dimensionality of the data was addressed through synthetic minority oversampling technique (SMOTE) and principal component analysis (PCA). Our results indicate that ensemble classifiers (RF and XGB decision trees) exhibit superior classification accuracy in predicting the host phenotype. The application of PCA significantly reduced testing time while maintaining high classification accuracy. The highest classification accuracy was obtained at the levels of species for most classifiers. The prototype employed in the study addresses the issues inherent to microbiome datasets and could be highly beneficial for providing personalized medicine.
Mitigating the Accuracy-Robustness Trade-off via Multi-Teacher Adversarial Distillation
Jul 11, 2023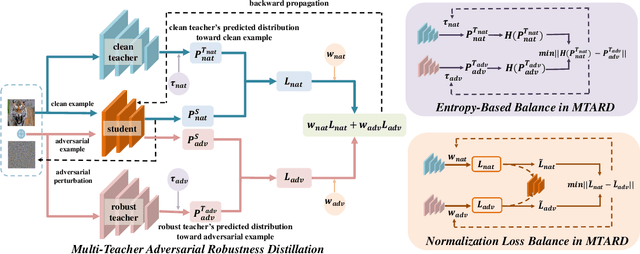

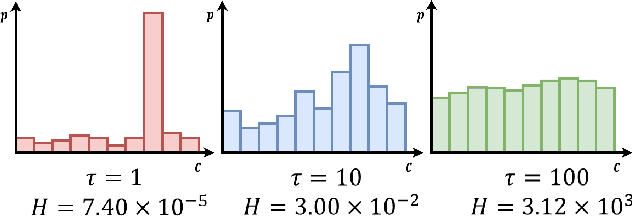
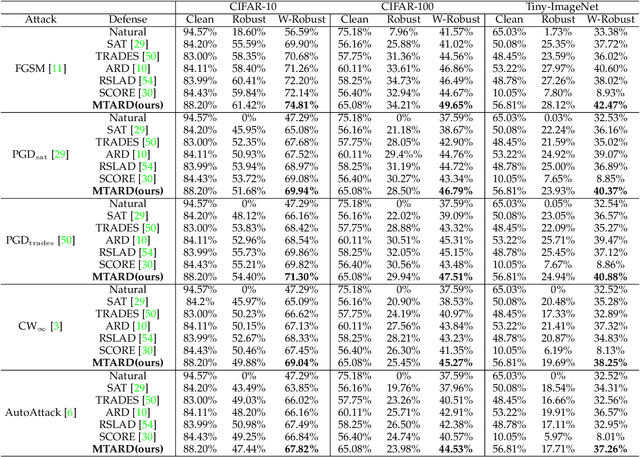
Adversarial training is a practical approach for improving the robustness of deep neural networks against adversarial attacks. Although bringing reliable robustness, the performance toward clean examples is negatively affected after adversarial training, which means a trade-off exists between accuracy and robustness. Recently, some studies have tried to use knowledge distillation methods in adversarial training, achieving competitive performance in improving the robustness but the accuracy for clean samples is still limited. In this paper, to mitigate the accuracy-robustness trade-off, we introduce the Multi-Teacher Adversarial Robustness Distillation (MTARD) to guide the model's adversarial training process by applying a strong clean teacher and a strong robust teacher to handle the clean examples and adversarial examples, respectively. During the optimization process, to ensure that different teachers show similar knowledge scales, we design the Entropy-Based Balance algorithm to adjust the teacher's temperature and keep the teachers' information entropy consistent. Besides, to ensure that the student has a relatively consistent learning speed from multiple teachers, we propose the Normalization Loss Balance algorithm to adjust the learning weights of different types of knowledge. A series of experiments conducted on public datasets demonstrate that MTARD outperforms the state-of-the-art adversarial training and distillation methods against various adversarial attacks.
Bag of Views: An Appearance-based Approach to Next-Best-View Planning for 3D Reconstruction
Jul 11, 2023UAV-based intelligent data acquisition for 3D reconstruction and monitoring of infrastructure has been experiencing an increasing surge of interest due to the recent advancements in image processing and deep learning-based techniques. View planning is an essential part of this task that dictates the information capture strategy and heavily impacts the quality of the 3D model generated from the captured data. Recent methods have used prior knowledge or partial reconstruction of the target to accomplish view planning for active reconstruction; the former approach poses a challenge for complex or newly identified targets while the latter is computationally expensive. In this work, we present Bag-of-Views (BoV), a fully appearance-based model used to assign utility to the captured views for both offline dataset refinement and online next-best-view (NBV) planning applications targeting the task of 3D reconstruction. With this contribution, we also developed the View Planning Toolbox (VPT), a lightweight package for training and testing machine learning-based view planning frameworks, custom view dataset generation of arbitrary 3D scenes, and 3D reconstruction. Through experiments which pair a BoV-based reinforcement learning model with VPT, we demonstrate the efficacy of our model in reducing the number of required views for high-quality reconstructions in dataset refinement and NBV planning.
Towards Robust and Efficient Continual Language Learning
Jul 11, 2023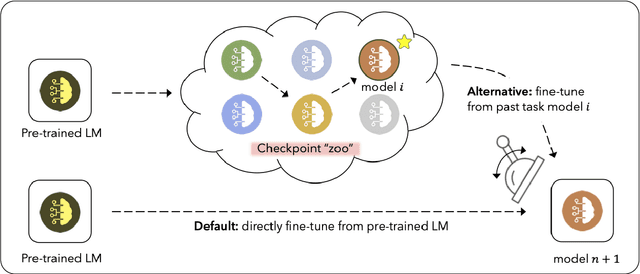

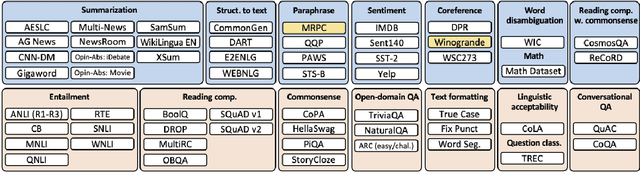
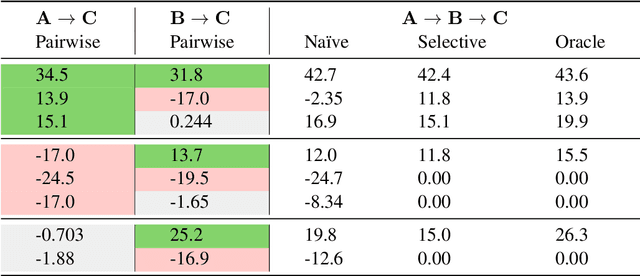
As the application space of language models continues to evolve, a natural question to ask is how we can quickly adapt models to new tasks. We approach this classic question from a continual learning perspective, in which we aim to continue fine-tuning models trained on past tasks on new tasks, with the goal of "transferring" relevant knowledge. However, this strategy also runs the risk of doing more harm than good, i.e., negative transfer. In this paper, we construct a new benchmark of task sequences that target different possible transfer scenarios one might face, such as a sequence of tasks with high potential of positive transfer, high potential for negative transfer, no expected effect, or a mixture of each. An ideal learner should be able to maximally exploit information from all tasks that have any potential for positive transfer, while also avoiding the negative effects of any distracting tasks that may confuse it. We then propose a simple, yet effective, learner that satisfies many of our desiderata simply by leveraging a selective strategy for initializing new models from past task checkpoints. Still, limitations remain, and we hope this benchmark can help the community to further build and analyze such learners.