 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretical Analysis of Power-law Transformation on Images for Text Polarity Detection
Nov 11, 2025Several computer vision applications like vehicle license plate recognition, captcha recognition, printed or handwriting character recognition from images etc., text polarity detection and binarization are the important preprocessing tasks. To analyze any image, it has to be converted to a simple binary image. This binarization process requires the knowledge of polarity of text in the images. Text polarity is defined as the contrast of text with respect to background. That means, text is darker than the background (dark text on bright background) or vice-versa. The binarization process uses this polarity information to convert the original colour or gray scale image into a binary image. In the literature, there is an intuitive approach based on power-law transformation on the original images. In this approach, the authors have illustrated an interesting phenomenon from the histogram statistics of the transformed images. Considering text and background as two classes, they have observed that maximum between-class variance between two classes is increasing (decreasing) for dark (bright) text on bright (dark) background. The corresponding empirical results have been presented. In this paper, we present a theoretical analysis of the above phenomenon.
Application of data engineering approaches to address challenges in microbiome data for optimal medical decision-making
Jul 11, 2023



The human gut microbiota is known to contribute to numerous physiological functions of the body and also implicated in a myriad of pathological conditions. Prolific research work in the past few decades have yielded valuable information regarding the relative taxonomic distribution of gut microbiota. Unfortunately, the microbiome data suffers from class imbalance and high dimensionality issues that must be addressed. In this study, we have implemented data engineering algorithms to address the above-mentioned issues inherent to microbiome data. Four standard machine learning classifiers (logistic regression (LR), support vector machines (SVM), random forests (RF), and extreme gradient boosting (XGB) decision trees) were implemented on a previously published dataset. The issue of class imbalance and high dimensionality of the data was addressed through synthetic minority oversampling technique (SMOTE) and principal component analysis (PCA). Our results indicate that ensemble classifiers (RF and XGB decision trees) exhibit superior classification accuracy in predicting the host phenotype. The application of PCA significantly reduced testing time while maintaining high classification accuracy. The highest classification accuracy was obtained at the levels of species for most classifiers. The prototype employed in the study addresses the issues inherent to microbiome datasets and could be highly beneficial for providing personalized medicine.
Determination of the relative inclination and the viewing angle of an interacting pair of galaxies using convolutional neural networks
Feb 04, 2020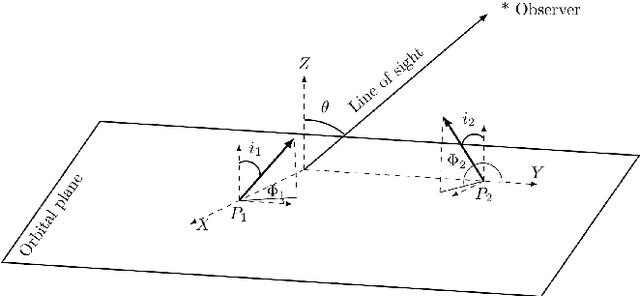
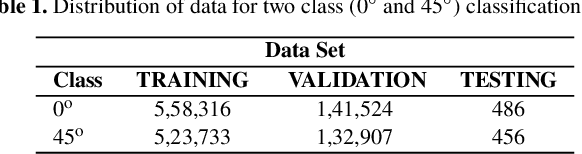
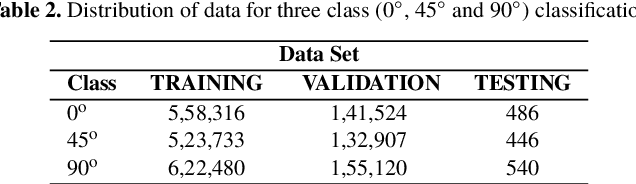
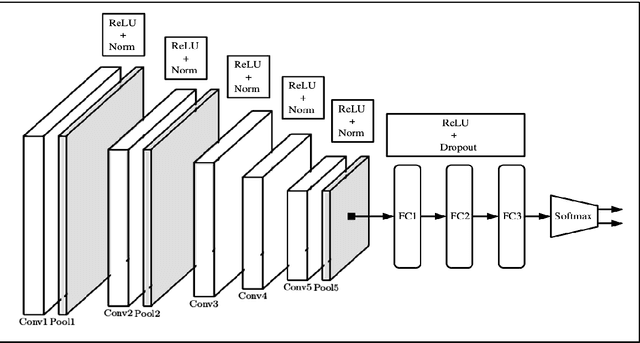
Constructing dynamical models for interacting pair of galaxies as constrained by their observed structure and kinematics crucially depends on the correct choice of the values of the relative inclination ($i$) between their galactic planes as well as the viewing angle ($\theta$), the angle between the line of sight and the normal to the plane of their orbital motion. We construct Deep Convolutional Neural Network (DCNN) models to determine the relative inclination ($i$) and the viewing angle ($\theta$) of interacting galaxy pairs, using N-body $+$ Smoothed Particle Hydrodynamics (SPH) simulation data from the GALMER database for training the same. In order to classify galaxy pairs based on their $i$ values only, we first construct DCNN models for a (a) 2-class ( $i$ = 0 $^{\circ}$, 45$^{\circ}$ ) and (b) 3-class ($i = 0^{\circ}, 45^{\circ} \text{ and } 90^{\circ}$) classification, obtaining $F_1$ scores of 99% and 98% respectively. Further, for a classification based on both $i$ and $\theta$ values, we develop a DCNN model for a 9-class classification ($(i,\theta) \sim (0^{\circ},15^{\circ}) ,(0^{\circ},45^{\circ}), (0^{\circ},90^{\circ}), (45^{\circ},15^{\circ}), (45^{\circ}, 45^{\circ}), (45^{\circ}, 90^{\circ}), (90^{\circ}, 15^{\circ}), (90^{\circ}, 45^{\circ}), (90^{\circ},90^{\circ})$), and the $F_1$ score was 97$\%$. Finally, we tested our 2-class model on real data of interacting galaxy pairs from the Sloan Digital Sky Survey (SDSS) DR15, and achieve an $F_1$ score of 78%. Our DCNN models could be further extended to determine additional parameters needed to model dynamics of interacting galaxy pairs, which is currently accomplished by trial and error method.