 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spain on Fire: A novel wildfire risk assessment model based on image satellite processing and atmospheric information
Jun 08, 2023
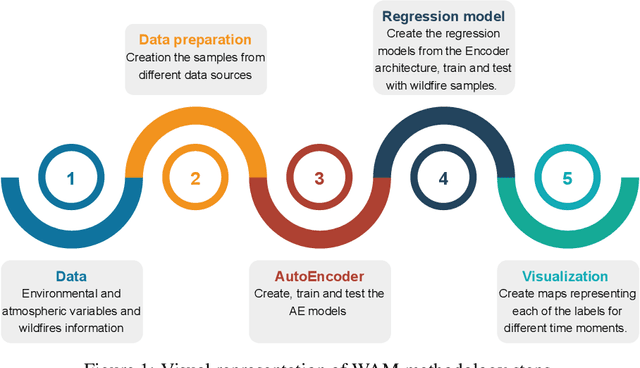
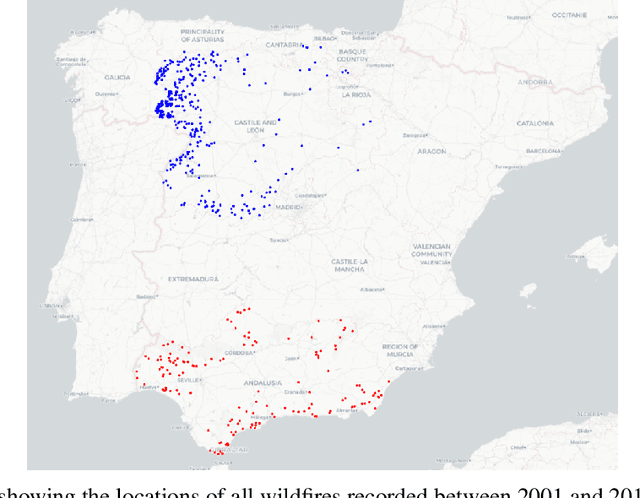
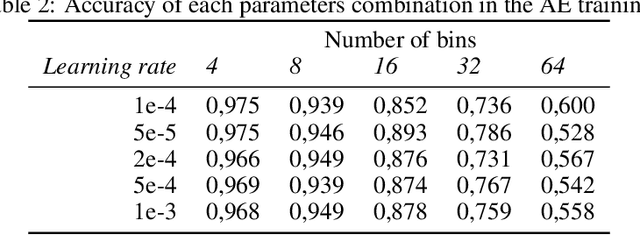
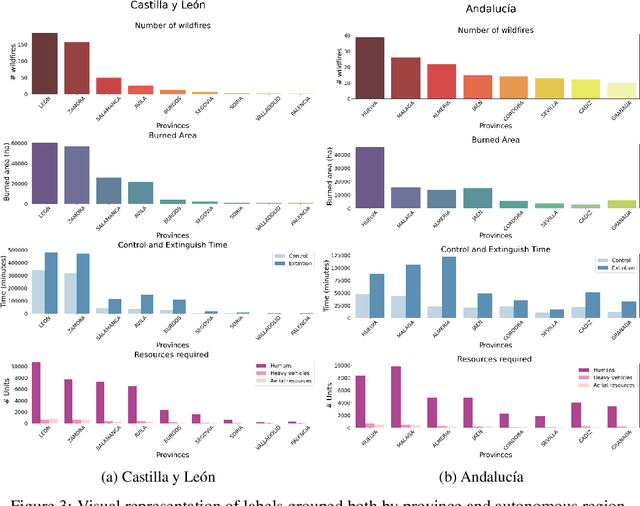
Each year, wildfires destroy larger areas of Spain, threatening numerous ecosystems. Humans cause 90% of them (negligence or provoked) and the behaviour of individuals is unpredictable. However, atmospheric and environmental variables affect the spread of wildfires, and they can be analysed by using deep learning. In order to mitigate the damage of these events we proposed the novel Wildfire Assessment Model (WAM). Our aim is to anticipate the economic and ecological impact of a wildfire, assisting managers resource allocation and decision making for dangerous regions in Spain, Castilla y Le\'on and Andaluc\'ia. The WAM uses a residual-style convolutional network architecture to perform regression over atmospheric variables and the greenness index, computing necessary resources, the control and extinction time, and the expected burnt surface area. It is first pre-trained with self-supervision over 100,000 examples of unlabelled data with a masked patch prediction objective and fine-tuned using 311 samples of wildfires. The pretraining allows the model to understand situations, outclassing baselines with a 1,4%, 3,7% and 9% improvement estimating human, heavy and aerial resources; 21% and 10,2% in expected extinction and control time; and 18,8% in expected burnt area. Using the WAM we provide an example assessment map of Castilla y Le\'on, visualizing the expected resources over an entire region.
Computationally Efficient Labeling of Cancer Related Forum Posts by Non-Clinical Text Information Retrieval
Mar 24, 2023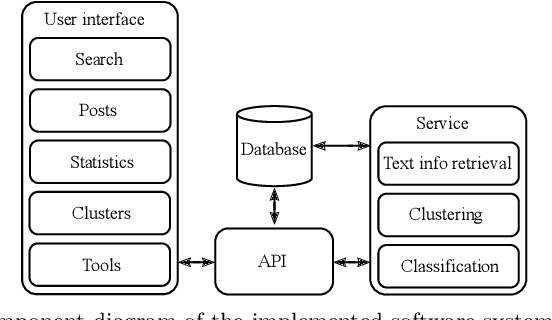
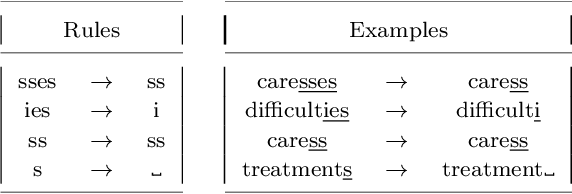
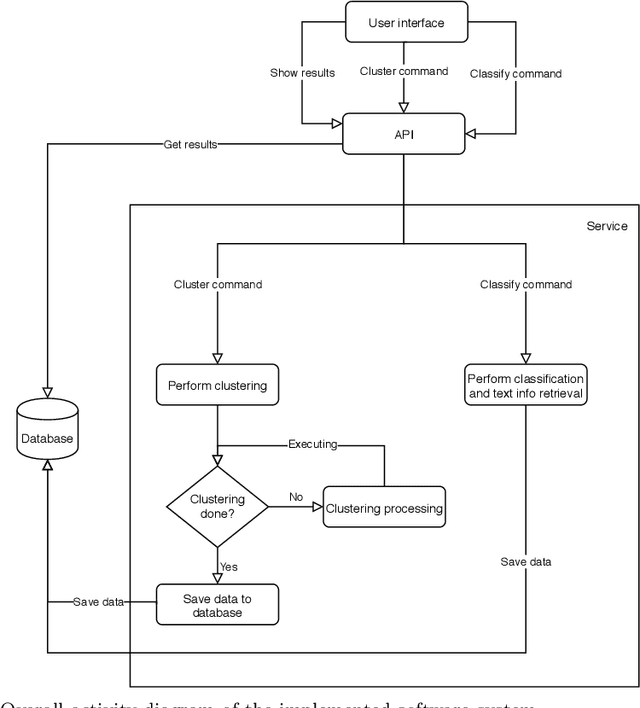

An abundance of information about cancer exists online, but categorizing and extracting useful information from it is difficult. Almost all research within healthcare data processing is concerned with formal clinical data, but there is valuable information in non-clinical data too. The present study combines methods within distributed computing, text retrieval, clustering, and classification into a coherent and computationally efficient system, that can clarify cancer patient trajectories based on non-clinical and freely available information. We produce a fully-functional prototype that can retrieve, cluster and present information about cancer trajectories from non-clinical forum posts. We evaluate three clustering algorithms (MR-DBSCAN, DBSCAN, and HDBSCAN) and compare them in terms of Adjusted Rand Index and total run time as a function of the number of posts retrieved and the neighborhood radius. Clustering results show that neighborhood radius has the most significant impact on clustering performance. For small values, the data set is split accordingly, but high values produce a large number of possible partitions and searching for the best partition is hereby time-consuming. With a proper estimated radius, MR-DBSCAN can cluster 50000 forum posts in 46.1 seconds, compared to DBSCAN (143.4) and HDBSCAN (282.3). We conduct an interview with the Danish Cancer Society and present our software prototype. The organization sees a potential in software that can democratize online information about cancer and foresee that such systems will be required in the future.
milliFlow: Scene Flow Estimation on mmWave Radar Point Cloud for Human Motion Sensing
Jun 29, 2023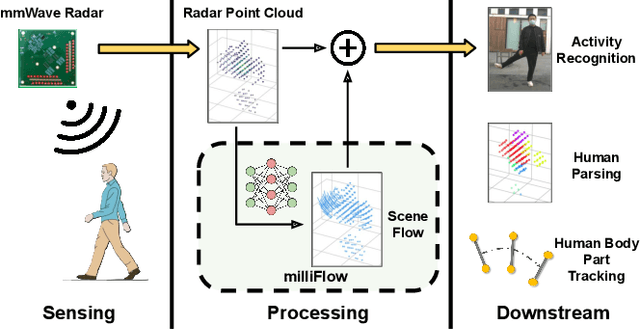
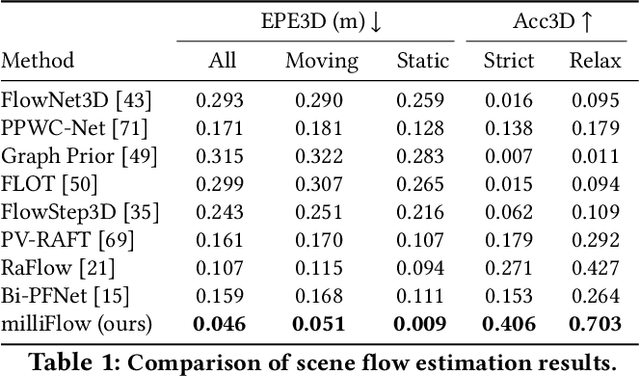
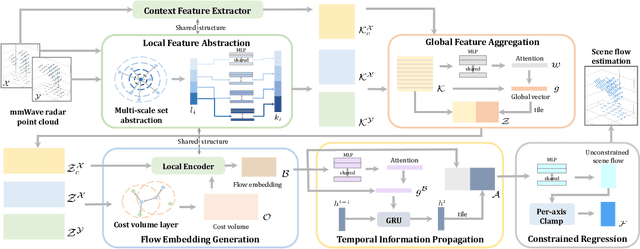
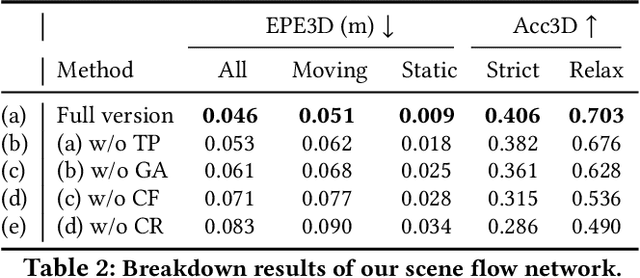
Approaching the era of ubiquitous computing, human motion sensing plays a crucial role in smart systems for decision making, user interaction, and personalized services. Extensive research has been conducted on human tracking, pose estimation, gesture recognition, and activity recognition, which are predominantly based on cameras in traditional methods. However, the intrusive nature of cameras limits their use in smart home applications. To address this, mmWave radars have gained popularity due to their privacy-friendly features. In this work, we propose \textit{milliFlow}, a novel deep learning method for scene flow estimation as a complementary motion information for mmWave point cloud, serving as an intermediate level of features and directly benefiting downstream human motion sensing tasks. Experimental results demonstrate the superior performance of our method with an average 3D endpoint error of 4.6cm, significantly surpassing the competing approaches. Furthermore, by incorporating scene flow information, we achieve remarkable improvements in human activity recognition, human parsing, and human body part tracking. To foster further research in this area, we provide our codebase and dataset for open access.
Unveiling the Potential of Spike Streams for Foreground Occlusion Removal from Densely Continuous Views
Jul 03, 2023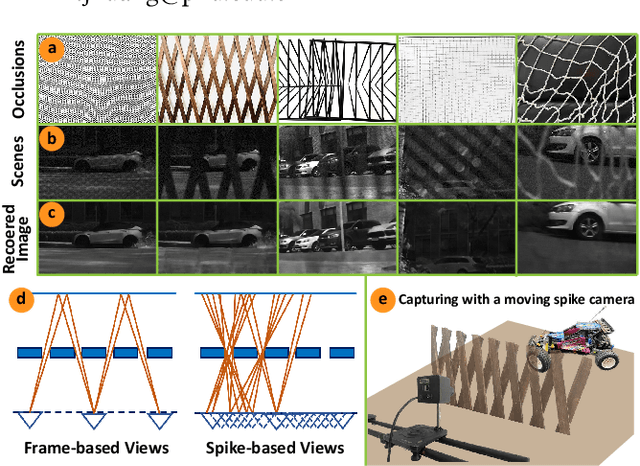
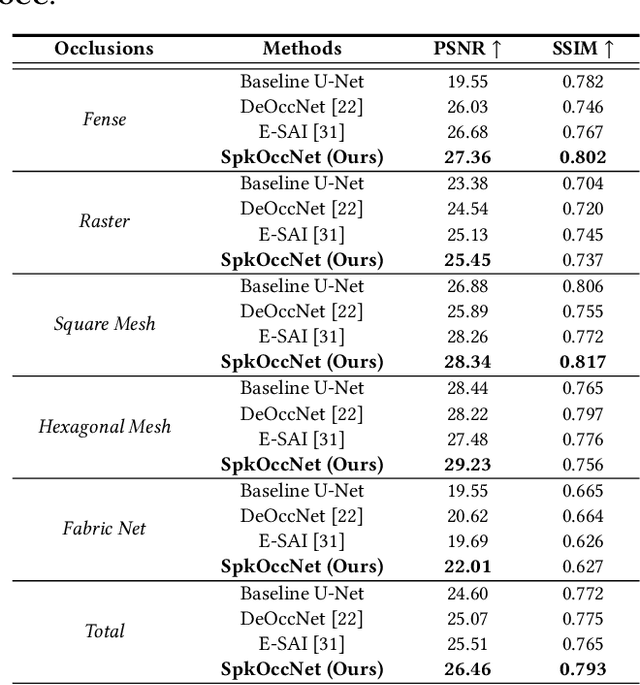
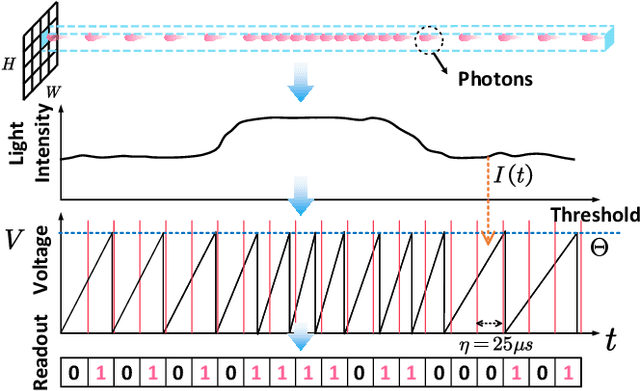
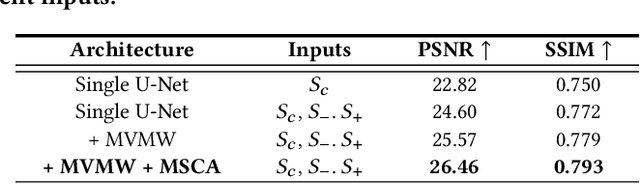
The extraction of a clean background image by removing foreground occlusion holds immense practical significance, but it also presents several challenges. Presently, the majority of de-occlusion research focuses on addressing this issue through the extraction and synthesis of discrete images from calibrated camera arrays. Nonetheless, the restoration quality tends to suffer when faced with dense occlusions or high-speed motions due to limited perspectives and motion blur. To successfully remove dense foreground occlusion, an effective multi-view visual information integration approach is required. Introducing the spike camera as a novel type of neuromorphic sensor offers promising capabilities with its ultra-high temporal resolution and high dynamic range. In this paper, we propose an innovative solution for tackling the de-occlusion problem through continuous multi-view imaging using only one spike camera without any prior knowledge of camera intrinsic parameters and camera poses. By rapidly moving the spike camera, we continually capture the dense stream of spikes from the occluded scene. To process the spikes, we build a novel model \textbf{SpkOccNet}, in which we integrate information of spikes from continuous viewpoints within multi-windows, and propose a novel cross-view mutual attention mechanism for effective fusion and refinement. In addition, we contribute the first real-world spike-based dataset \textbf{S-OCC} for occlusion removal. The experimental results demonstrate that our proposed model efficiently removes dense occlusions in diverse scenes while exhibiting strong generalization.
Valid Information Guidance Network for Compressed Video Quality Enhancement
Feb 28, 2023

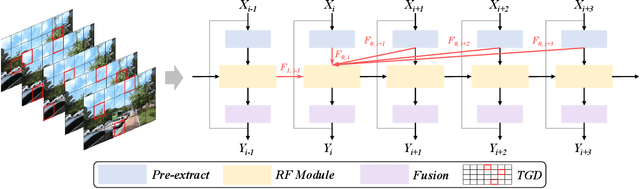
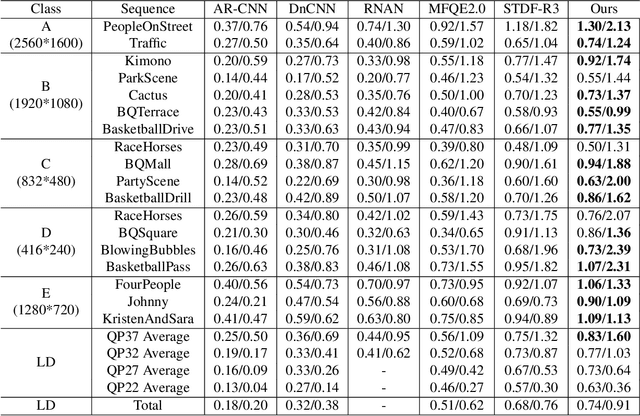
In recent years deep learning methods have shown great superiority in compressed video quality enhancement tasks. Existing methods generally take the raw video as the ground truth and extract practical information from consecutive frames containing various artifacts. However, they do not fully exploit the valid information of compressed and raw videos to guide the quality enhancement for compressed videos. In this paper, we propose a unique Valid Information Guidance scheme (VIG) to enhance the quality of compressed videos by mining valid information from both compressed videos and raw videos. Specifically, we propose an efficient framework, Compressed Redundancy Filtering (CRF) network, to balance speed and enhancement. After removing the redundancy by filtering the information, CRF can use the valid information of the compressed video to reconstruct the texture. Furthermore, we propose a progressive Truth Guidance Distillation (TGD) strategy, which does not need to design additional teacher models and distillation loss functions. By only using the ground truth as input to guide the model to aggregate the correct spatio-temporal correspondence across the raw frames, TGD can significantly improve the enhancement effect without increasing the extra training cost. Extensive experiments show that our method achieves the state-of-the-art performance of compressed video quality enhancement in terms of accuracy and efficiency.
Restricted Generative Projection for One-Class Classification and Anomaly Detection
Jul 09, 2023
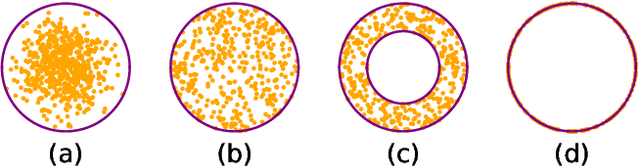
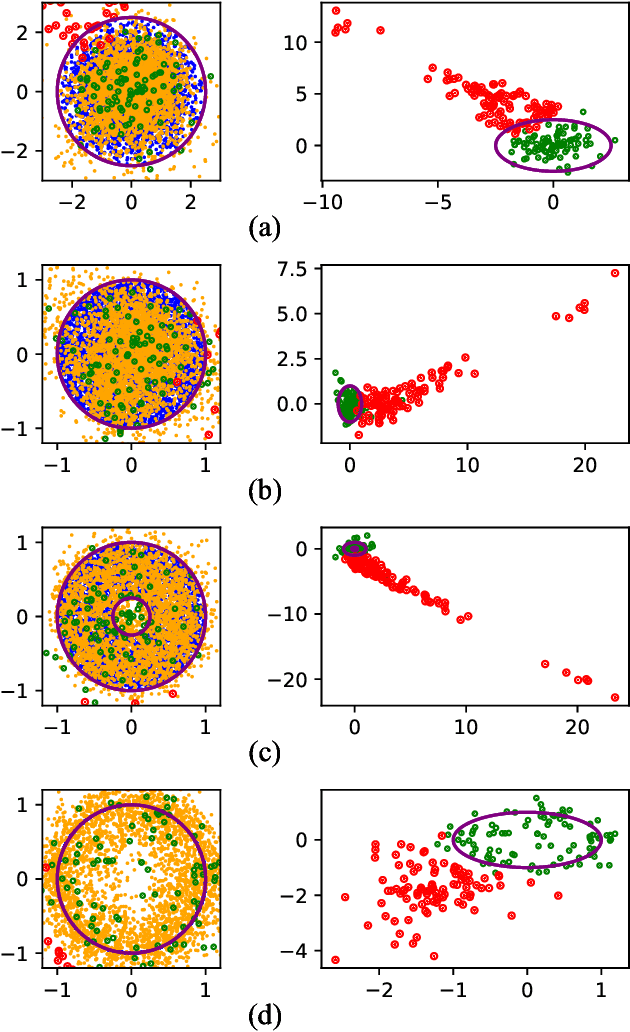
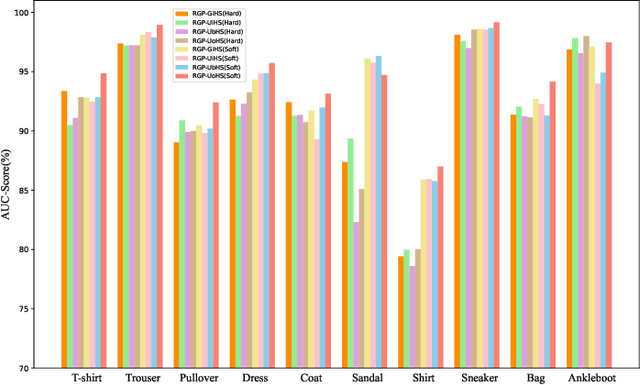
We present a simple framework for one-class classification and anomaly detection. The core idea is to learn a mapping to transform the unknown distribution of training (normal) data to a known target distribution. Crucially, the target distribution should be sufficiently simple, compact, and informative. The simplicity is to ensure that we can sample from the distribution easily, the compactness is to ensure that the decision boundary between normal data and abnormal data is clear and reliable, and the informativeness is to ensure that the transformed data preserve the important information of the original data. Therefore, we propose to use truncated Gaussian, uniform in hypersphere, uniform on hypersphere, or uniform between hyperspheres, as the target distribution. We then minimize the distance between the transformed data distribution and the target distribution while keeping the reconstruction error for the original data small enough. Comparative studies on multiple benchmark datasets verify the effectiveness of our methods in comparison to baselines.
Action-State Dependent Dynamic Model Selection
Jul 07, 2023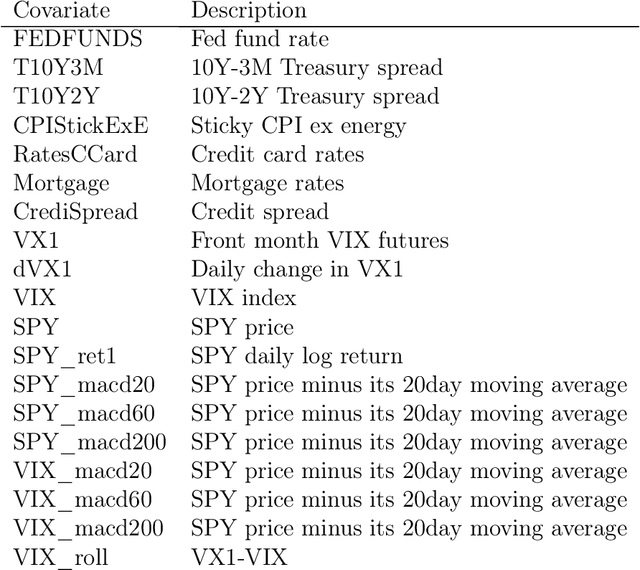
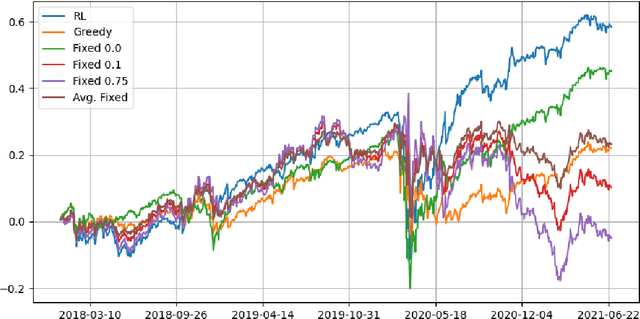
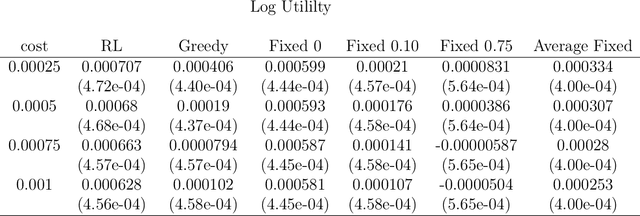
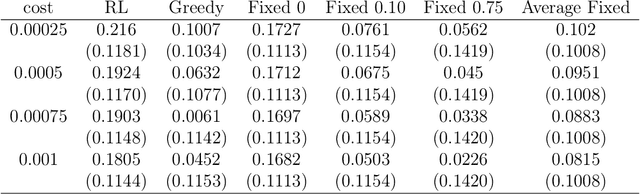
A model among many may only be best under certain states of the world. Switching from a model to another can also be costly. Finding a procedure to dynamically choose a model in these circumstances requires to solve a complex estimation procedure and a dynamic programming problem. A Reinforcement learning algorithm is used to approximate and estimate from the data the optimal solution to this dynamic programming problem. The algorithm is shown to consistently estimate the optimal policy that may choose different models based on a set of covariates. A typical example is the one of switching between different portfolio models under rebalancing costs, using macroeconomic information. Using a set of macroeconomic variables and price data, an empirical application to the aforementioned portfolio problem shows superior performance to choosing the best portfolio model with hindsight.
Channel Adaptive DL based Joint Source-Channel Coding without A Prior Knowledge
Jul 02, 2023
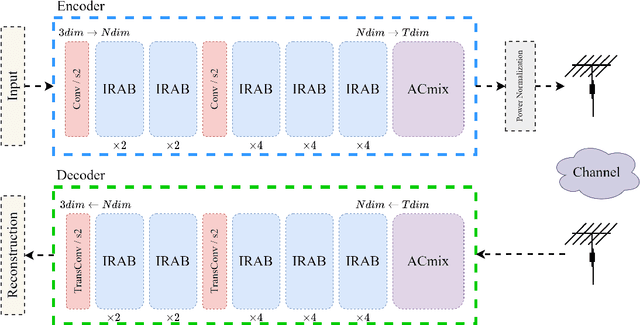
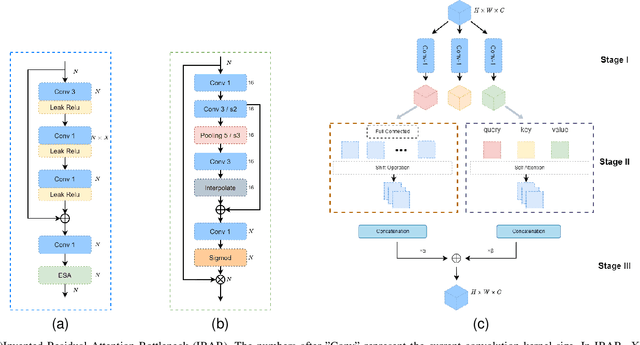
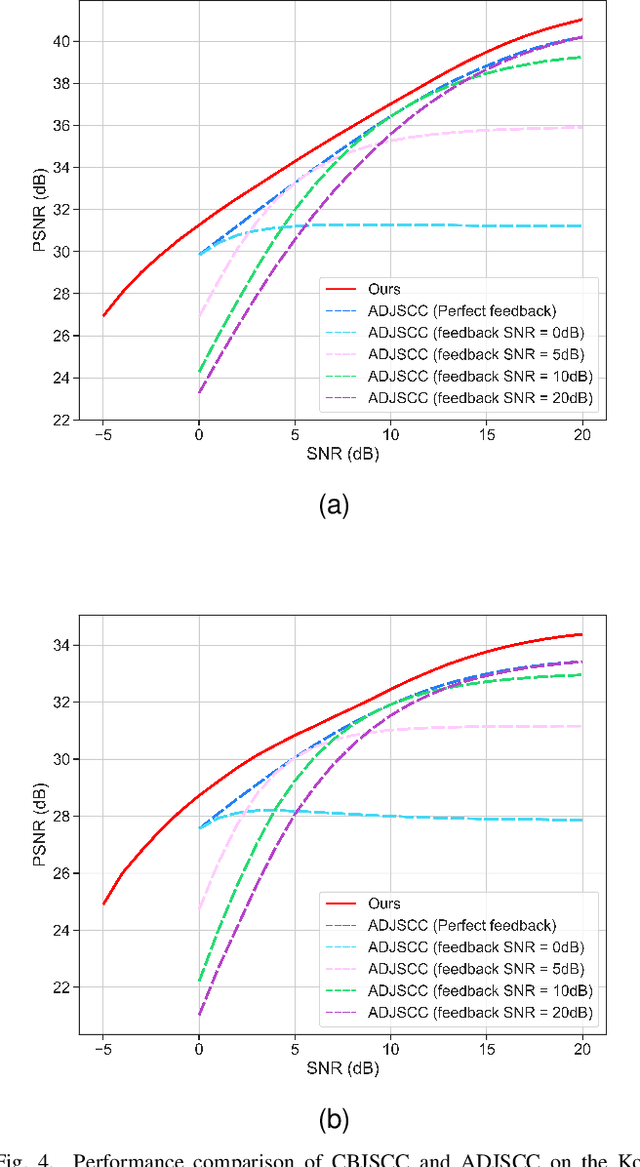
Significant progress has been made in wireless Joint Source-Channel Coding (JSCC) using deep learning techniques. The latest DL-based image JSCC methods have demonstrated exceptional performance across various signal-to-noise ratio (SNR) levels during transmission, while also avoiding cliff effects. However, current channel adaptive JSCC methods rely heavily on channel prior knowledge, which can lead to performance degradation in practical applications due to channel mismatch effects. This paper proposes a novel approach for image transmission, called Channel Blind Joint Source-Channel Coding (CBJSCC). CBJSCC utilizes Deep Learning techniques to achieve exceptional performance across various signal-to-noise ratio (SNR) levels during transmission, without relying on channel prior information. We have designed an Inverted Residual Attention Bottleneck (IRAB) module for the model, which can effectively reduce the number of parameters while expanding the receptive field. In addition, we have incorporated a convolution and self-attention mixed encoding module to establish long-range dependency relationships between channel symbols. Our experiments have shown that CBJSCC outperforms existing channel adaptive DL-based JSCC methods that rely on feedback information. Furthermore, we found that channel estimation does not significantly benefit CBJSCC, which provides insights for the future design of DL-based JSCC methods. The reliability of the proposed method is further demonstrated through an analysis of the model bottleneck and its adaptability to different domains, as shown by our experiments.
Look, Remember and Reason: Visual Reasoning with Grounded Rationales
Jun 30, 2023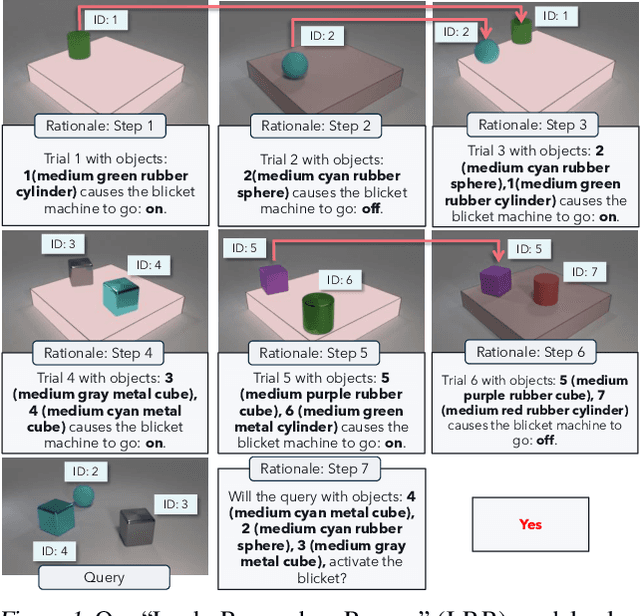
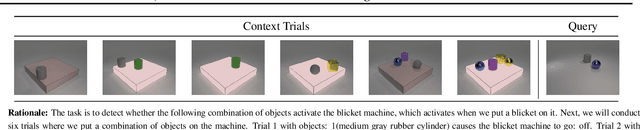
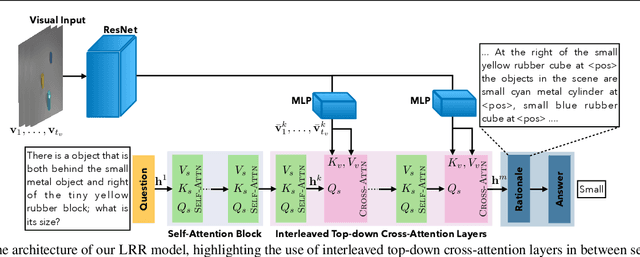

Large language models have recently shown human level performance on a variety of reasoning tasks. However, the ability of these models to perform complex visual reasoning has not been studied in detail yet. A key challenge in many visual reasoning tasks is that the visual information needs to be tightly integrated in the reasoning process. We propose to address this challenge by drawing inspiration from human visual problem solving which depends on a variety of low-level visual capabilities. It can often be cast as the three step-process of ``Look, Remember, Reason'': visual information is incrementally extracted using low-level visual routines in a step-by-step fashion until a final answer is reached. We follow the same paradigm to enable existing large language models, with minimal changes to the architecture, to solve visual reasoning problems. To this end, we introduce rationales over the visual input that allow us to integrate low-level visual capabilities, such as object recognition and tracking, as surrogate tasks. We show competitive performance on diverse visual reasoning tasks from the CLEVR, CATER, and ACRE datasets over state-of-the-art models designed specifically for these tasks.
Hierarchical Pretraining for Biomedical Term Embeddings
Jul 01, 2023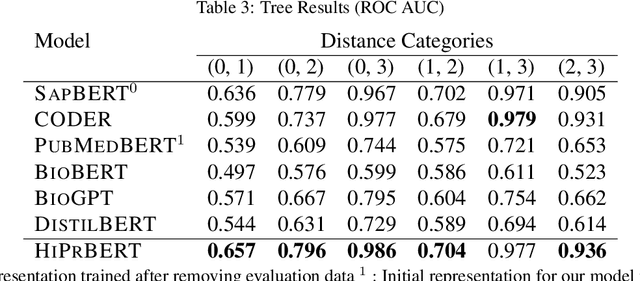
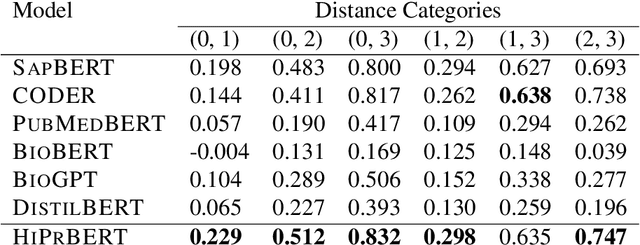
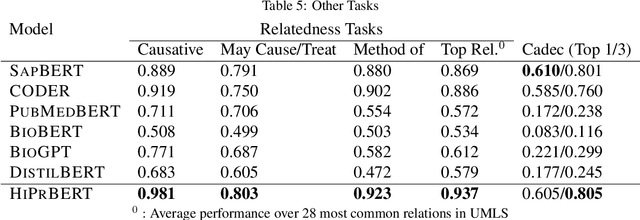
Electronic health records (EHR) contain narrative notes that provide extensive details on the medical condition and management of patients. Natural language processing (NLP) of clinical notes can use observed frequencies of clinical terms as predictive features for downstream applications such as clinical decision making and patient trajectory prediction. However, due to the vast number of highly similar and related clinical concepts, a more effective modeling strategy is to represent clinical terms as semantic embeddings via representation learning and use the low dimensional embeddings as feature vectors for predictive modeling. To achieve efficient representation, fine-tuning pretrained language models with biomedical knowledge graphs may generate better embeddings for biomedical terms than those from standard language models alone. These embeddings can effectively discriminate synonymous pairs of from those that are unrelated. However, they often fail to capture different degrees of similarity or relatedness for concepts that are hierarchical in nature. To overcome this limitation, we propose HiPrBERT, a novel biomedical term representation model trained on additionally complied data that contains hierarchical structures for various biomedical terms. We modify an existing contrastive loss function to extract information from these hierarchies. Our numerical experiments demonstrate that HiPrBERT effectively learns the pair-wise distance from hierarchical information, resulting in a substantially more informative embeddings for further biomedical applications