 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Diverse Offline Imitation via Fenchel Duality
Jul 21, 2023
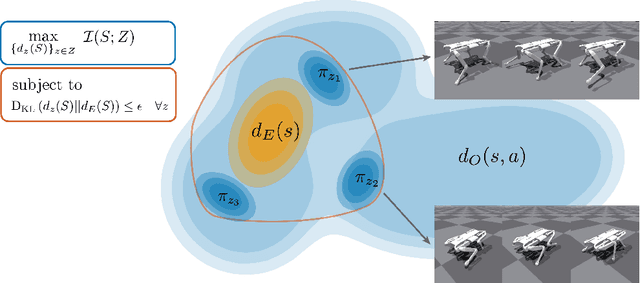

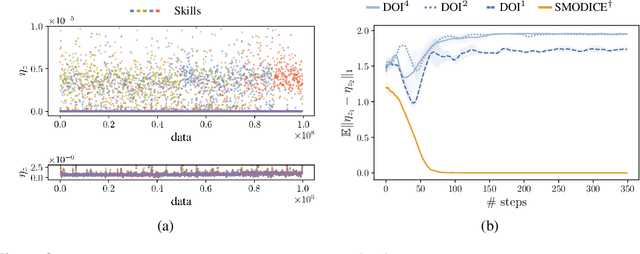
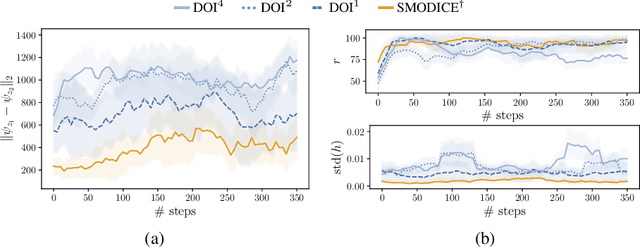
There has been significant recent progress in the area of unsupervised skill discovery, with various works proposing mutual information based objectives, as a source of intrinsic motivation. Prior works predominantly focused on designing algorithms that require online access to the environment. In contrast, we develop an \textit{offline} skill discovery algorithm. Our problem formulation considers the maximization of a mutual information objective constrained by a KL-divergence. More precisely, the constraints ensure that the state occupancy of each skill remains close to the state occupancy of an expert, within the support of an offline dataset with good state-action coverage. Our main contribution is to connect Fenchel duality, reinforcement learning and unsupervised skill discovery, and to give a simple offline algorithm for learning diverse skills that are aligned with an expert.
KITLM: Domain-Specific Knowledge InTegration into Language Models for Question Answering
Aug 07, 2023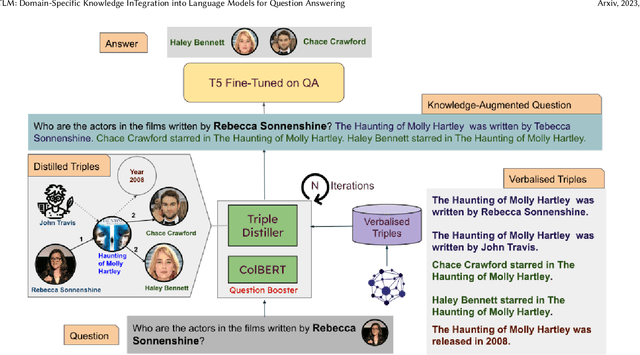



Large language models (LLMs) have demonstrated remarkable performance in a wide range of natural language tasks. However, as these models continue to grow in size, they face significant challenges in terms of computational costs. Additionally, LLMs often lack efficient domain-specific understanding, which is particularly crucial in specialized fields such as aviation and healthcare. To boost the domain-specific understanding, we propose, KITLM, a novel knowledge base integration approach into language model through relevant information infusion. By integrating pertinent knowledge, not only the performance of the language model is greatly enhanced, but the model size requirement is also significantly reduced while achieving comparable performance. Our proposed knowledge-infused model surpasses the performance of both GPT-3.5-turbo and the state-of-the-art knowledge infusion method, SKILL, achieving over 1.5 times improvement in exact match scores on the MetaQA. KITLM showed a similar performance boost in the aviation domain with AeroQA. The drastic performance improvement of KITLM over the existing methods can be attributed to the infusion of relevant knowledge while mitigating noise. In addition, we release two curated datasets to accelerate knowledge infusion research in specialized fields: a) AeroQA, a new benchmark dataset designed for multi-hop question-answering within the aviation domain, and b) Aviation Corpus, a dataset constructed from unstructured text extracted from the National Transportation Safety Board reports. Our research contributes to advancing the field of domain-specific language understanding and showcases the potential of knowledge infusion techniques in improving the performance of language models on question-answering.
UniversalNER: Targeted Distillation from Large Language Models for Open Named Entity Recognition
Aug 07, 2023


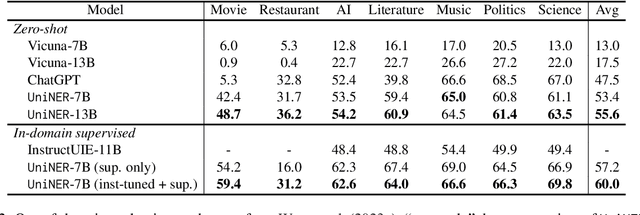
Large language models (LLMs) have demonstrated remarkable generalizability, such as understanding arbitrary entities and relations. Instruction tuning has proven effective for distilling LLMs into more cost-efficient models such as Alpaca and Vicuna. Yet such student models still trail the original LLMs by large margins in downstream applications. In this paper, we explore targeted distillation with mission-focused instruction tuning to train student models that can excel in a broad application class such as open information extraction. Using named entity recognition (NER) for case study, we show how ChatGPT can be distilled into much smaller UniversalNER models for open NER. For evaluation, we assemble the largest NER benchmark to date, comprising 43 datasets across 9 diverse domains such as biomedicine, programming, social media, law, finance. Without using any direct supervision, UniversalNER attains remarkable NER accuracy across tens of thousands of entity types, outperforming general instruction-tuned models such as Alpaca and Vicuna by over 30 absolute F1 points in average. With a tiny fraction of parameters, UniversalNER not only acquires ChatGPT's capability in recognizing arbitrary entity types, but also outperforms its NER accuracy by 7-9 absolute F1 points in average. Remarkably, UniversalNER even outperforms by a large margin state-of-the-art multi-task instruction-tuned systems such as InstructUIE, which uses supervised NER examples. We also conduct thorough ablation studies to assess the impact of various components in our distillation approach. We will release the distillation recipe, data, and UniversalNER models to facilitate future research on targeted distillation.
Local SGD Accelerates Convergence by Exploiting Second Order Information of the Loss Function
May 24, 2023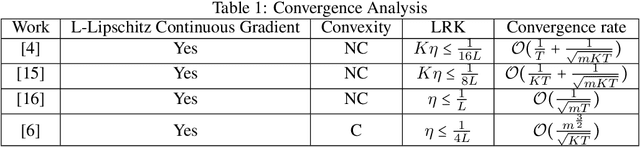
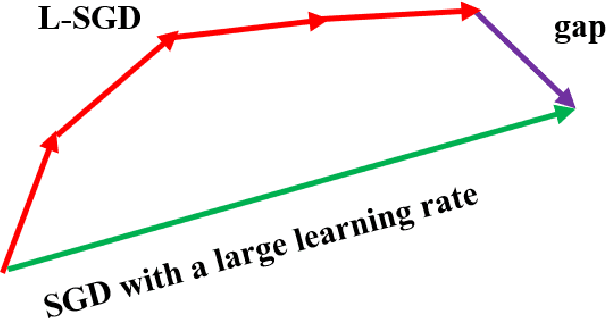
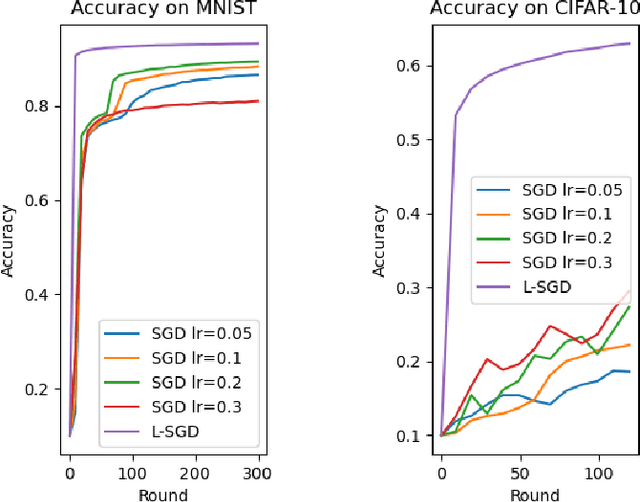
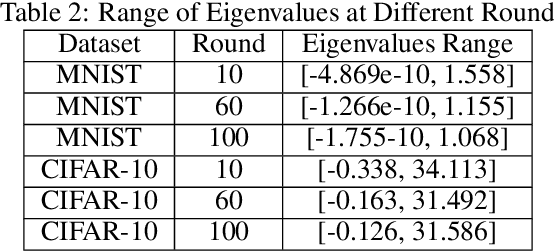
With multiple iterations of updates, local statistical gradient descent (L-SGD) has been proven to be very effective in distributed machine learning schemes such as federated learning. In fact, many innovative works have shown that L-SGD with independent and identically distributed (IID) data can even outperform SGD. As a result, extensive efforts have been made to unveil the power of L-SGD. However, existing analysis failed to explain why the multiple local updates with small mini-batches of data (L-SGD) can not be replaced by the update with one big batch of data and a larger learning rate (SGD). In this paper, we offer a new perspective to understand the strength of L-SGD. We theoretically prove that, with IID data, L-SGD can effectively explore the second order information of the loss function. In particular, compared with SGD, the updates of L-SGD have much larger projection on the eigenvectors of the Hessian matrix with small eigenvalues, which leads to faster convergence. Under certain conditions, L-SGD can even approach the Newton method. Experiment results over two popular datasets validate the theoretical results.
A Meta-learning based Generalizable Indoor Localization Model using Channel State Information
May 22, 2023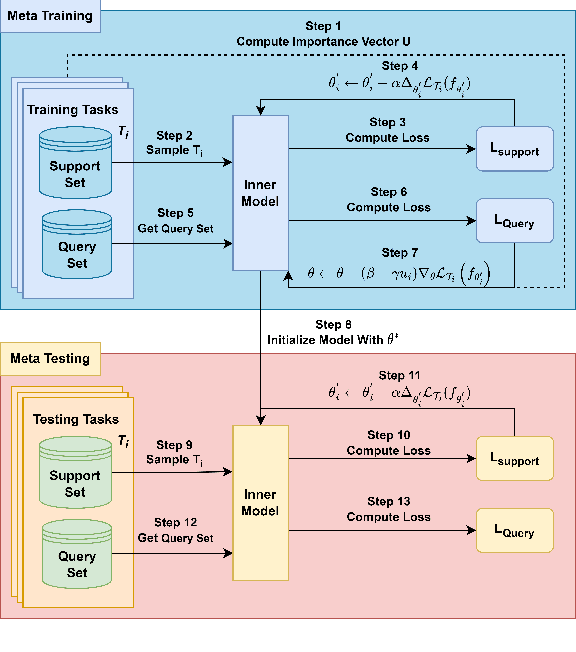
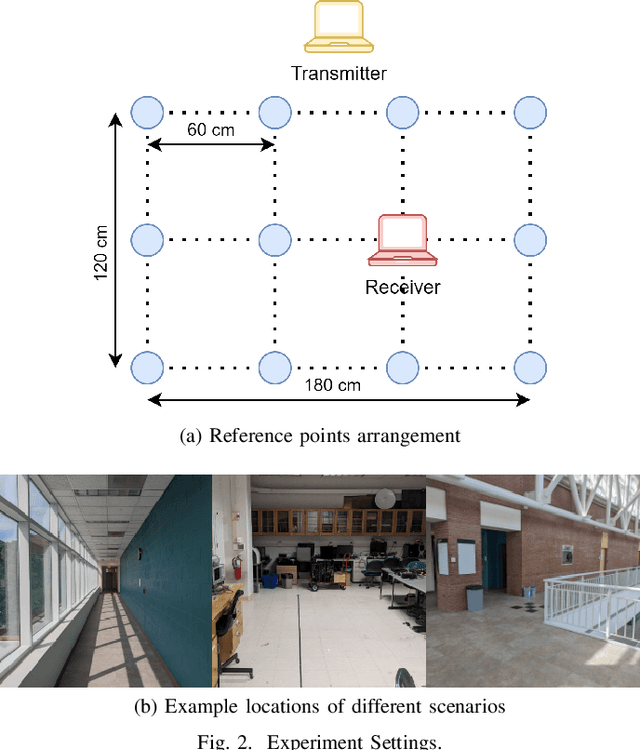
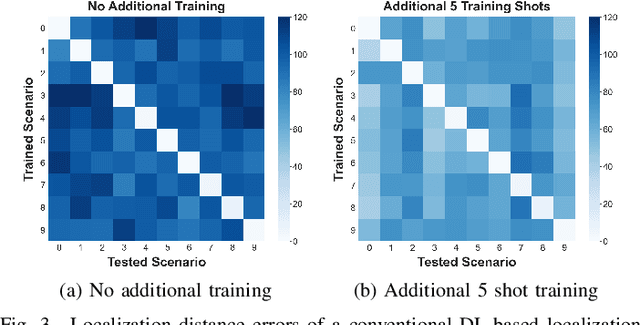
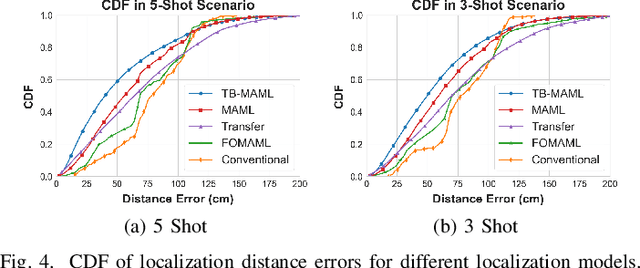
Indoor localization has gained significant attention in recent years due to its various applications in smart homes, industrial automation, and healthcare, especially since more people rely on their wireless devices for location-based services. Deep learning-based solutions have shown promising results in accurately estimating the position of wireless devices in indoor environments using wireless parameters such as Channel State Information (CSI) and Received Signal Strength Indicator (RSSI). However, despite the success of deep learning-based approaches in achieving high localization accuracy, these models suffer from a lack of generalizability and can not be readily-deployed to new environments or operate in dynamic environments without retraining. In this paper, we propose meta-learning-based localization models to address the lack of generalizability that persists in conventionally trained DL-based localization models. Furthermore, since meta-learning algorithms require diverse datasets from several different scenarios, which can be hard to collect in the context of localization, we design and propose a new meta-learning algorithm, TB-MAML (Task Biased Model Agnostic Meta Learning), intended to further improve generalizability when the dataset is limited. Lastly, we evaluate the performance of TB-MAML-based localization against conventionally trained localization models and localization done using other meta-learning algorithms.
Improving Text Semantic Similarity Modeling through a 3D Siamese Network
Jul 18, 2023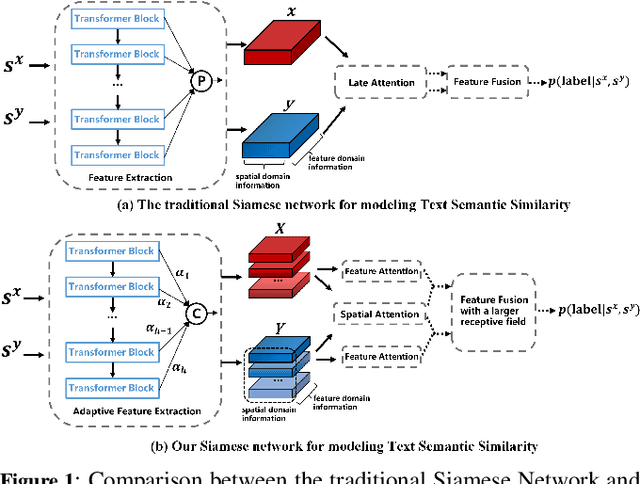
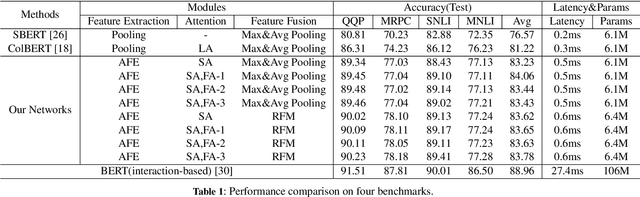
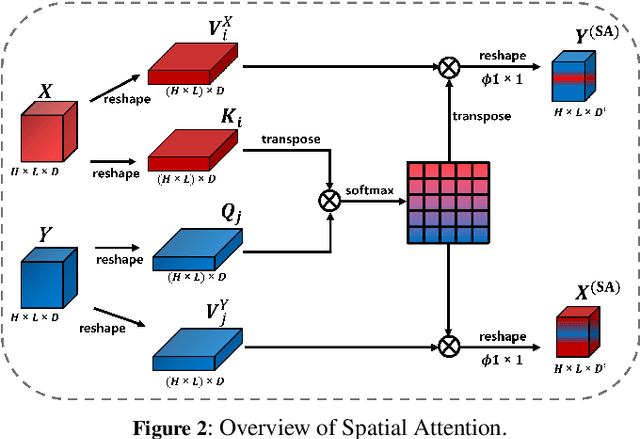
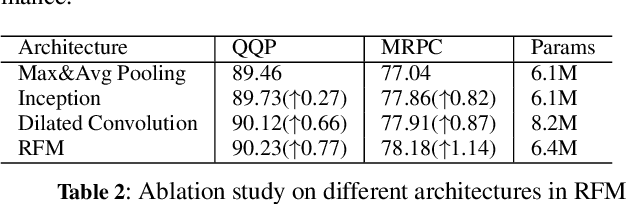
Siamese networks have gained popularity as a method for modeling text semantic similarity. Traditional methods rely on pooling operation to compress the semantic representations from Transformer blocks in encoding, resulting in two-dimensional semantic vectors and the loss of hierarchical semantic information from Transformer blocks. Moreover, this limited structure of semantic vectors is akin to a flattened landscape, which restricts the methods that can be applied in downstream modeling, as they can only navigate this flat terrain. To address this issue, we propose a novel 3D Siamese network for text semantic similarity modeling, which maps semantic information to a higher-dimensional space. The three-dimensional semantic tensors not only retains more precise spatial and feature domain information but also provides the necessary structural condition for comprehensive downstream modeling strategies to capture them. Leveraging this structural advantage, we introduce several modules to reinforce this 3D framework, focusing on three aspects: feature extraction, attention, and feature fusion. Our extensive experiments on four text semantic similarity benchmarks demonstrate the effectiveness and efficiency of our 3D Siamese Network.
JacobiNeRF: NeRF Shaping with Mutual Information Gradients
Apr 01, 2023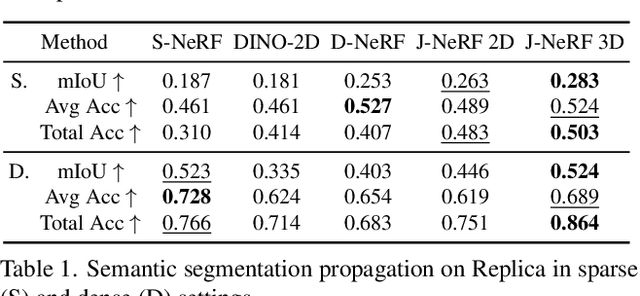
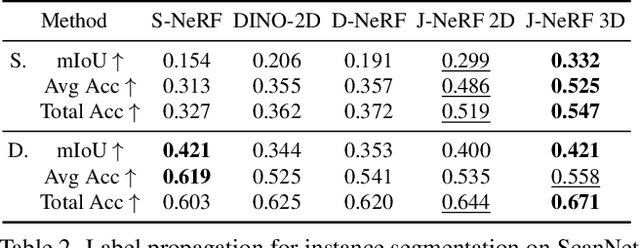

We propose a method that trains a neural radiance field (NeRF) to encode not only the appearance of the scene but also semantic correlations between scene points, regions, or entities -- aiming to capture their mutual co-variation patterns. In contrast to the traditional first-order photometric reconstruction objective, our method explicitly regularizes the learning dynamics to align the Jacobians of highly-correlated entities, which proves to maximize the mutual information between them under random scene perturbations. By paying attention to this second-order information, we can shape a NeRF to express semantically meaningful synergies when the network weights are changed by a delta along the gradient of a single entity, region, or even a point. To demonstrate the merit of this mutual information modeling, we leverage the coordinated behavior of scene entities that emerges from our shaping to perform label propagation for semantic and instance segmentation. Our experiments show that a JacobiNeRF is more efficient in propagating annotations among 2D pixels and 3D points compared to NeRFs without mutual information shaping, especially in extremely sparse label regimes -- thus reducing annotation burden. The same machinery can further be used for entity selection or scene modifications.
Brighten-and-Colorize: A Decoupled Network for Customized Low-Light Image Enhancement
Aug 06, 2023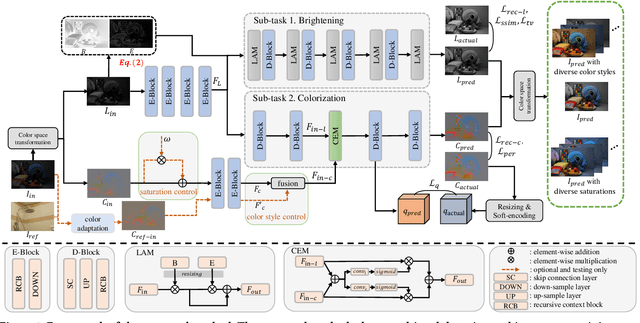

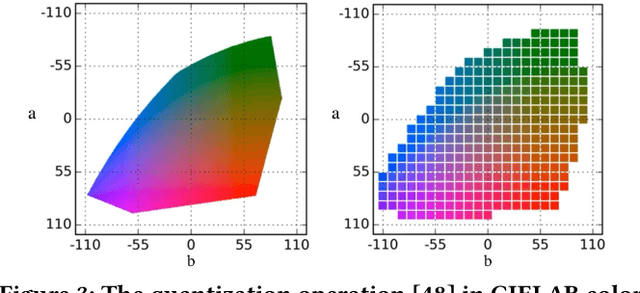
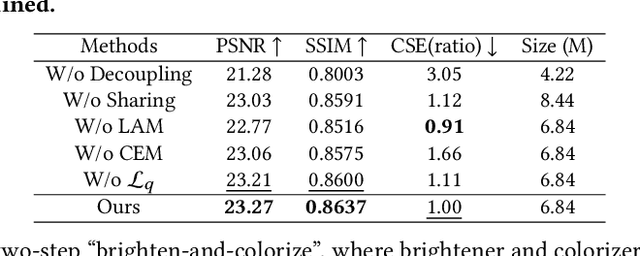
Low-Light Image Enhancement (LLIE) aims to improve the perceptual quality of an image captured in low-light conditions. Generally, a low-light image can be divided into lightness and chrominance components. Recent advances in this area mainly focus on the refinement of the lightness, while ignoring the role of chrominance. It easily leads to chromatic aberration and, to some extent, limits the diverse applications of chrominance in customized LLIE. In this work, a ``brighten-and-colorize'' network (called BCNet), which introduces image colorization to LLIE, is proposed to address the above issues. BCNet can accomplish LLIE with accurate color and simultaneously enables customized enhancement with varying saturations and color styles based on user preferences. Specifically, BCNet regards LLIE as a multi-task learning problem: brightening and colorization. The brightening sub-task aligns with other conventional LLIE methods to get a well-lit lightness. The colorization sub-task is accomplished by regarding the chrominance of the low-light image as color guidance like the user-guide image colorization. Upon completion of model training, the color guidance (i.e., input low-light chrominance) can be simply manipulated by users to acquire customized results. This customized process is optional and, due to its decoupled nature, does not compromise the structural and detailed information of lightness. Extensive experiments on the commonly used LLIE datasets show that the proposed method achieves both State-Of-The-Art (SOTA) performance and user-friendly customization.
Communication-Free Distributed GNN Training with Vertex Cut
Aug 06, 2023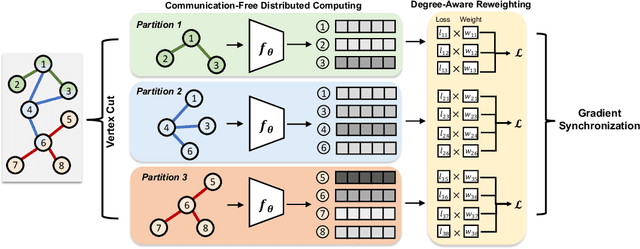
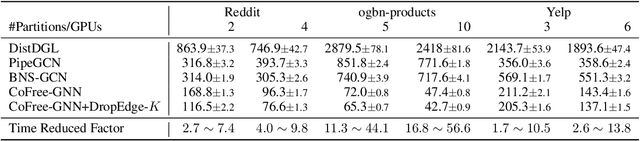
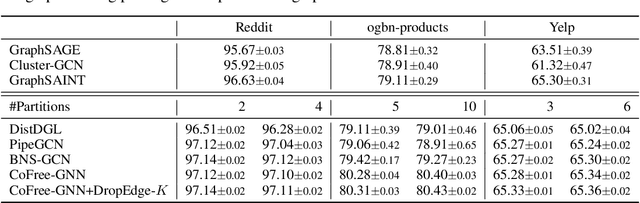

Training Graph Neural Networks (GNNs) on real-world graphs consisting of billions of nodes and edges is quite challenging, primarily due to the substantial memory needed to store the graph and its intermediate node and edge features, and there is a pressing need to speed up the training process. A common approach to achieve speed up is to divide the graph into many smaller subgraphs, which are then distributed across multiple GPUs in one or more machines and processed in parallel. However, existing distributed methods require frequent and substantial cross-GPU communication, leading to significant time overhead and progressively diminishing scalability. Here, we introduce CoFree-GNN, a novel distributed GNN training framework that significantly speeds up the training process by implementing communication-free training. The framework utilizes a Vertex Cut partitioning, i.e., rather than partitioning the graph by cutting the edges between partitions, the Vertex Cut partitions the edges and duplicates the node information to preserve the graph structure. Furthermore, the framework maintains high model accuracy by incorporating a reweighting mechanism to handle a distorted graph distribution that arises from the duplicated nodes. We also propose a modified DropEdge technique to further speed up the training process. Using an extensive set of experiments on real-world networks, we demonstrate that CoFree-GNN speeds up the GNN training process by up to 10 times over the existing state-of-the-art GNN training approaches.
Recurrent Spike-based Image Restoration under General Illumination
Aug 06, 2023Spike camera is a new type of bio-inspired vision sensor that records light intensity in the form of a spike array with high temporal resolution (20,000 Hz). This new paradigm of vision sensor offers significant advantages for many vision tasks such as high speed image reconstruction. However, existing spike-based approaches typically assume that the scenes are with sufficient light intensity, which is usually unavailable in many real-world scenarios such as rainy days or dusk scenes. To unlock more spike-based application scenarios, we propose a Recurrent Spike-based Image Restoration (RSIR) network, which is the first work towards restoring clear images from spike arrays under general illumination. Specifically, to accurately describe the noise distribution under different illuminations, we build a physical-based spike noise model according to the sampling process of the spike camera. Based on the noise model, we design our RSIR network which consists of an adaptive spike transformation module, a recurrent temporal feature fusion module, and a frequency-based spike denoising module. Our RSIR can process the spike array in a recursive manner to ensure that the spike temporal information is well utilized. In the training process, we generate the simulated spike data based on our noise model to train our network. Extensive experiments on real-world datasets with different illuminations demonstrate the effectiveness of the proposed network. The code and dataset are released at https://github.com/BIT-Vision/RSIR.