 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generative AI trial for nonviolent communication mediation
Aug 07, 2023
Aiming for a mixbiotic society that combines freedom and solidarity among people with diverse values, I focused on nonviolent communication (NVC) that enables compassionate giving in various situations of social division and conflict, and tried a generative AI for it. Specifically, ChatGPT was used in place of the traditional certified trainer to test the possibility of mediating (modifying) input sentences in four processes: observation, feelings, needs, and requests. The results indicate that there is potential for the application of generative AI, although not yet at a practical level. Suggested improvement guidelines included adding model responses, relearning revised responses, specifying appropriate terminology for each process, and re-asking for required information. The use of generative AI will be useful initially to assist certified trainers, to prepare for and review events and workshops, and in the future to support consensus building and cooperative behavior in digital democracy, platform cooperatives, and cyber-human social co-operating systems. It is hoped that the widespread use of NVC mediation using generative AI will lead to the early realization of a mixbiotic society.
Phase Matching for Out-of-Distribution Generalization
Aug 07, 2023
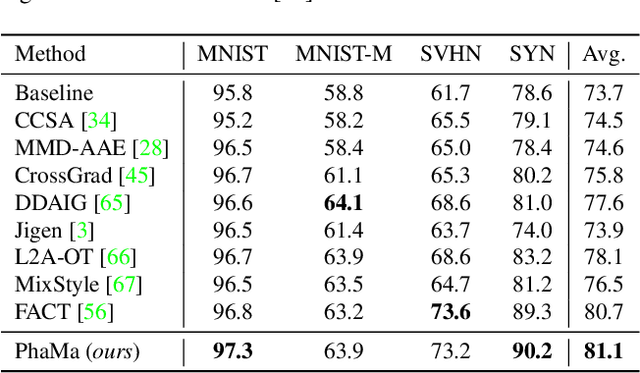
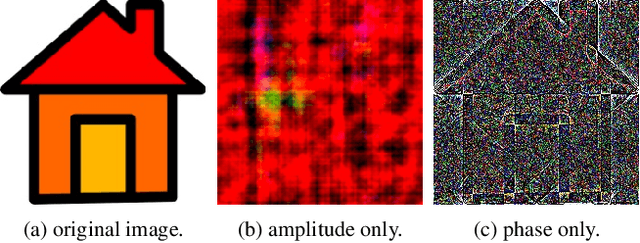
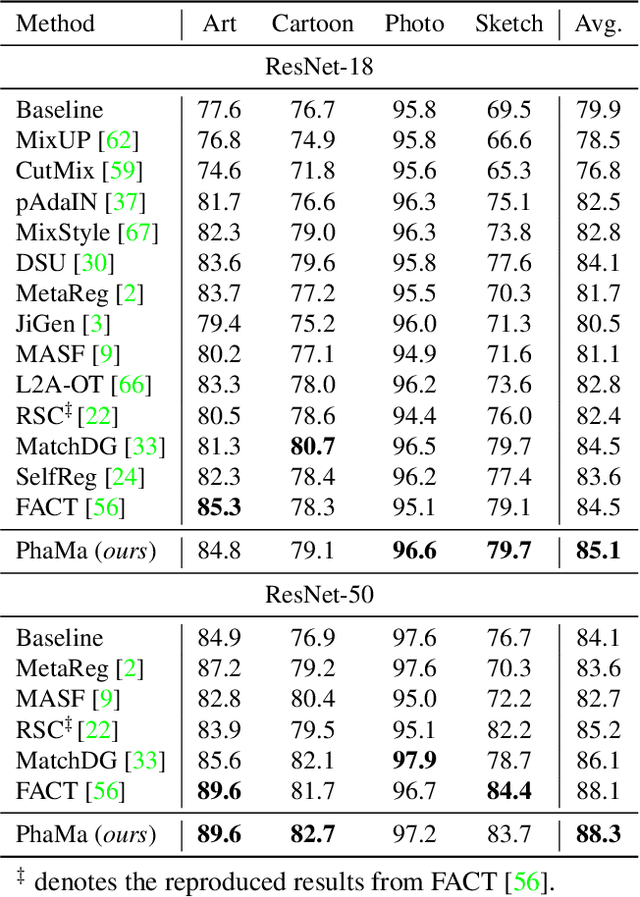
The Fourier transform, serving as an explicit decomposition method for visual signals, has been employed to explain the out-of-distribution generalization behaviors of Convolutional Neural Networks (CNNs). Previous studies have indicated that the amplitude spectrum is susceptible to the disturbance caused by distribution shifts. On the other hand, the phase spectrum preserves highly-structured spatial information, which is crucial for robust visual representation learning. However, the spatial relationships of phase spectrum remain unexplored in previous researches. In this paper, we aim to clarify the relationships between Domain Generalization (DG) and the frequency components, and explore the spatial relationships of the phase spectrum. Specifically, we first introduce a Fourier-based structural causal model which interprets the phase spectrum as semi-causal factors and the amplitude spectrum as non-causal factors. Then, we propose Phase Matching (PhaMa) to address DG problems. Our method introduces perturbations on the amplitude spectrum and establishes spatial relationships to match the phase components. Through experiments on multiple benchmarks, we demonstrate that our proposed method achieves state-of-the-art performance in domain generalization and out-of-distribution robustness tasks.
Freespace Optical Flow Modeling for Automated Driving
Jul 29, 2023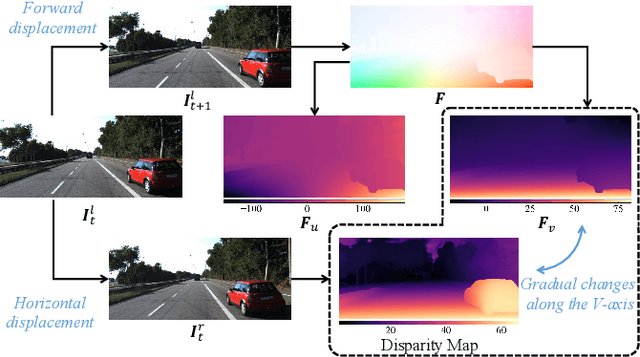
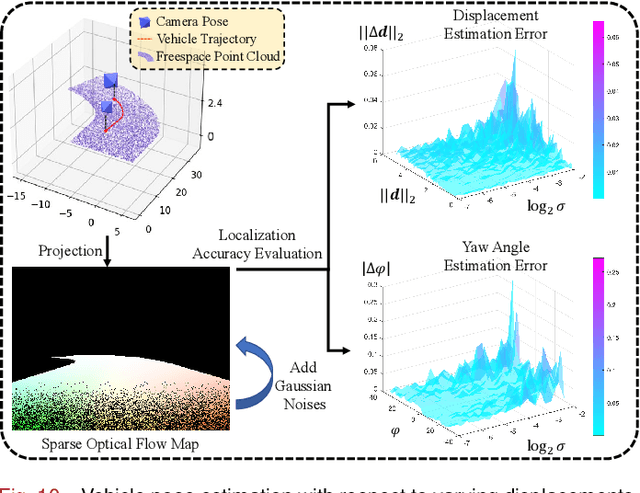

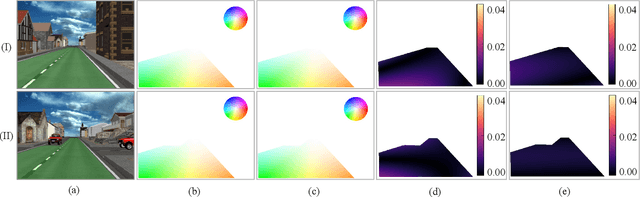
Optical flow and disparity are two informative visual features for autonomous driving perception. They have been used for a variety of applications, such as obstacle and lane detection. The concept of "U-V-Disparity" has been widely explored in the literature, while its counterpart in optical flow has received relatively little attention. Traditional motion analysis algorithms estimate optical flow by matching correspondences between two successive video frames, which limits the full utilization of environmental information and geometric constraints. Therefore, we propose a novel strategy to model optical flow in the collision-free space (also referred to as drivable area or simply freespace) for intelligent vehicles, with the full utilization of geometry information in a 3D driving environment. We provide explicit representations of optical flow and deduce the quadratic relationship between the optical flow component and the vertical coordinate. Through extensive experiments on several public datasets, we demonstrate the high accuracy and robustness of our model. Additionally, our proposed freespace optical flow model boasts a diverse array of applications within the realm of automated driving, providing a geometric constraint in freespace detection, vehicle localization, and more. We have made our source code publicly available at https://mias.group/FSOF.
JusticeBot: A Methodology for Building Augmented Intelligence Tools for Laypeople to Increase Access to Justice
Jul 27, 2023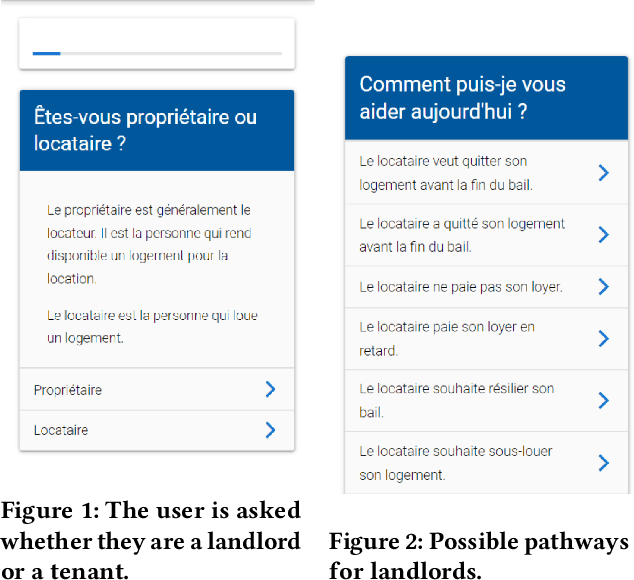
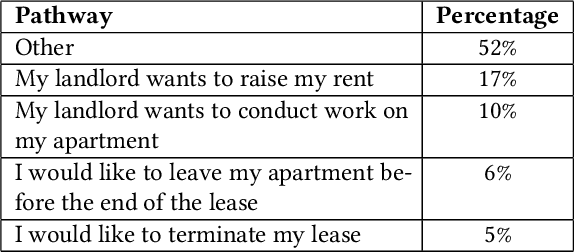
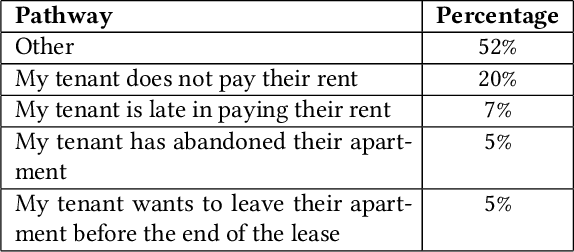
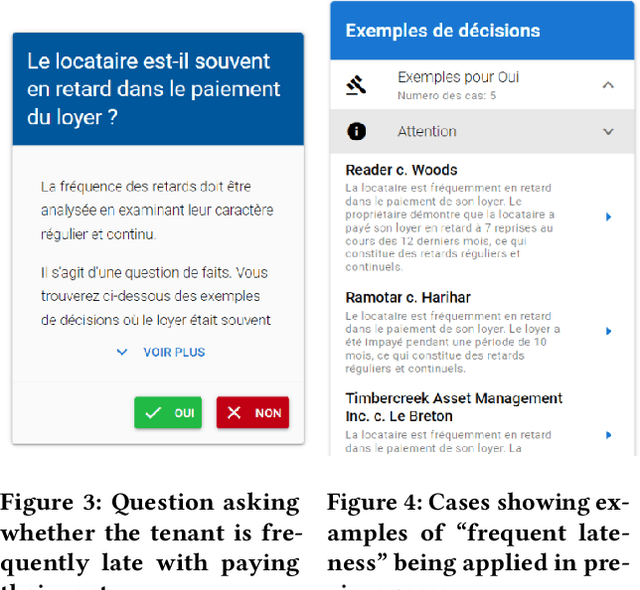
Laypeople (i.e. individuals without legal training) may often have trouble resolving their legal problems. In this work, we present the JusticeBot methodology. This methodology can be used to build legal decision support tools, that support laypeople in exploring their legal rights in certain situations, using a hybrid case-based and rule-based reasoning approach. The system ask the user questions regarding their situation and provides them with legal information, references to previous similar cases and possible next steps. This information could potentially help the user resolve their issue, e.g. by settling their case or enforcing their rights in court. We present the methodology for building such tools, which consists of discovering typically applied legal rules from legislation and case law, and encoding previous cases to support the user. We also present an interface to build tools using this methodology and a case study of the first deployed JusticeBot version, focused on landlord-tenant disputes, which has been used by thousands of individuals.
Towards Building More Robust Models with Frequency Bias
Jul 28, 2023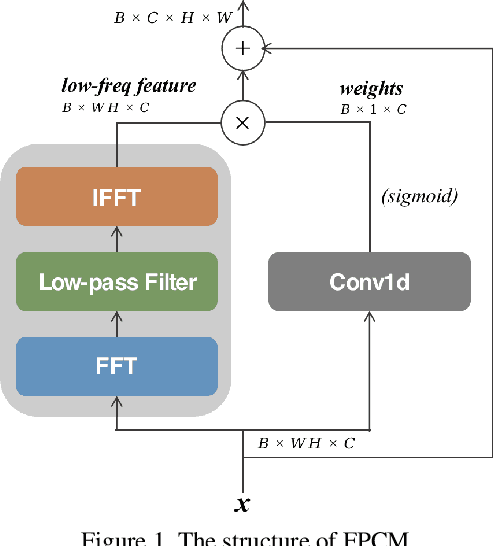
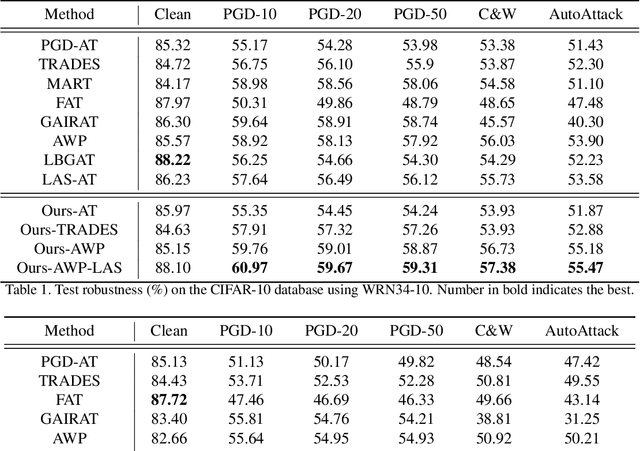
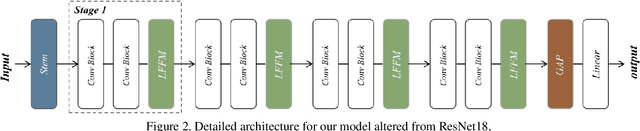
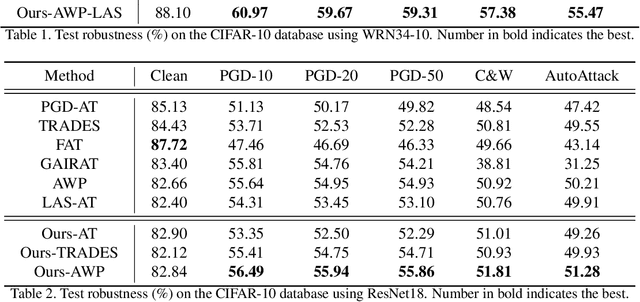
The vulnerability of deep neural networks to adversarial samples has been a major impediment to their broad applications, despite their success in various fields. Recently, some works suggested that adversarially-trained models emphasize the importance of low-frequency information to achieve higher robustness. While several attempts have been made to leverage this frequency characteristic, they have all faced the issue that applying low-pass filters directly to input images leads to irreversible loss of discriminative information and poor generalizability to datasets with distinct frequency features. This paper presents a plug-and-play module called the Frequency Preference Control Module that adaptively reconfigures the low- and high-frequency components of intermediate feature representations, providing better utilization of frequency in robust learning. Empirical studies show that our proposed module can be easily incorporated into any adversarial training framework, further improving model robustness across different architectures and datasets. Additionally, experiments were conducted to examine how the frequency bias of robust models impacts the adversarial training process and its final robustness, revealing interesting insights.
VOLTA: Diverse and Controllable Question-Answer Pair Generation with Variational Mutual Information Maximizing Autoencoder
Jul 03, 2023
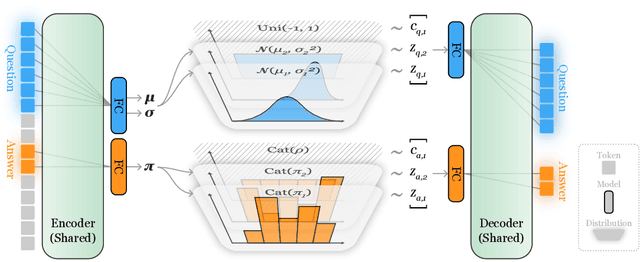
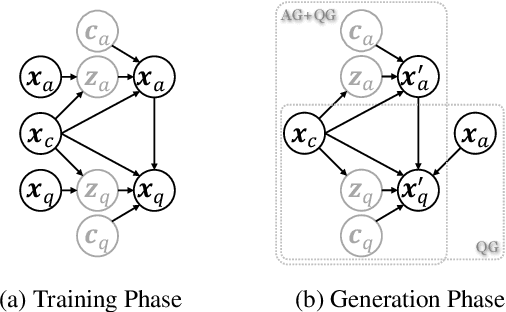
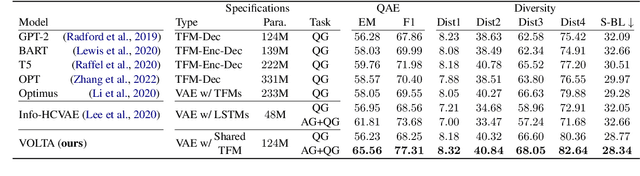
Previous question-answer pair generation methods aimed to produce fluent and meaningful question-answer pairs but tend to have poor diversity. Recent attempts addressing this issue suffer from either low model capacity or overcomplicated architecture. Furthermore, they overlooked the problem where the controllability of their models is highly dependent on the input. In this paper, we propose a model named VOLTA that enhances generative diversity by leveraging the Variational Autoencoder framework with a shared backbone network as its encoder and decoder. In addition, we propose adding InfoGAN-style latent codes to enable input-independent controllability over the generation process. We perform comprehensive experiments and the results show that our approach can significantly improve diversity and controllability over state-of-the-art models.
An Efficient Recommendation System in E-commerce using Passer learning optimization based on Bi-LSTM
Aug 02, 2023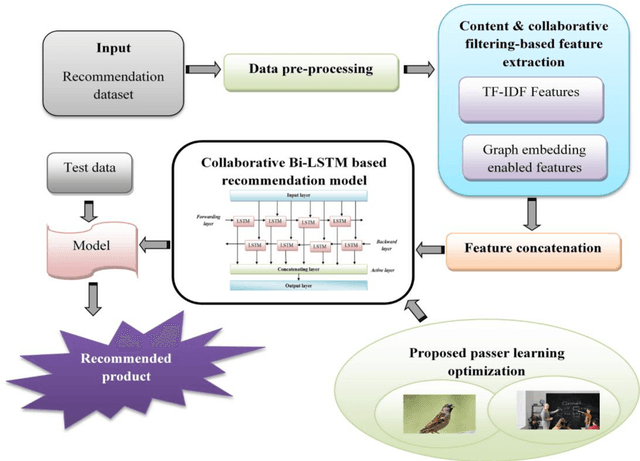

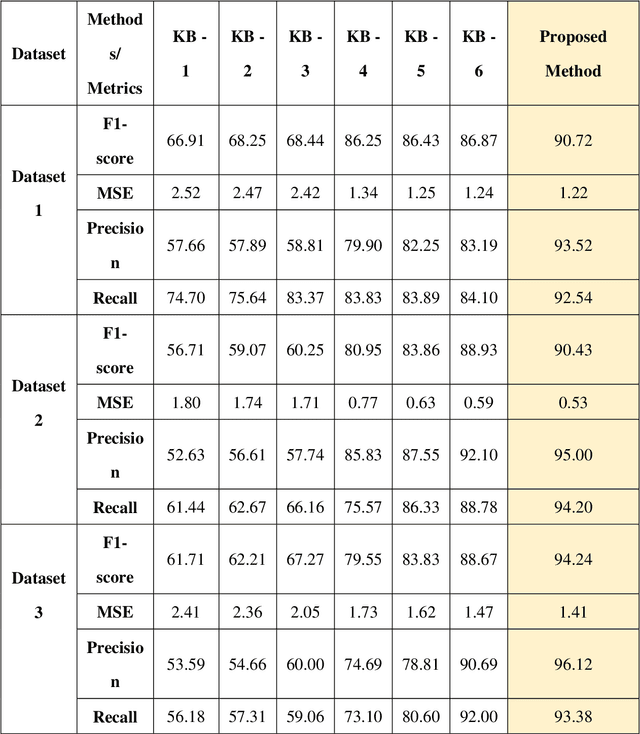
Recommendation system services have become crucial for users to access personalized goods or services as the global e-commerce market expands. They can increase business sales growth and lower the cost of user information exploration. Recent years have seen a signifi-cant increase in researchers actively using user reviews to solve standard recommender system research issues. Reviews may, however, contain information that does not help consumers de-cide what to buy, such as advertising or fictitious or fake reviews. Using such reviews to offer suggestion services may reduce the effectiveness of those recommendations. In this research, the recommendation in e-commerce is developed using passer learning optimization based on Bi-LSTM to solve that issue (PL optimized Bi-LSTM). Data is first obtained from the product recommendation dataset and pre-processed to remove any values that are missing or incon-sistent. Then, feature extraction is performed using TF-IDF features and features that support graph embedding. Before submitting numerous features with the same dimensions to the Bi-LSTM classifier for analysis, they are integrated using the feature concatenation approach. The Collaborative Bi-LSTM method employs these features to determine if the model is a recommended product. The PL optimization approach, which efficiently adjusts the classifier's parameters and produces an extract output that measures the f1-score, MSE, precision, and recall, is the basis of this research's contributions. As compared to earlier methods, the pro-posed PL-optimized Bi-LSTM achieved values of 88.58%, 1.24%, 92.69%, and 92.69% for dataset 1, 88.46%, 0.48%, 92.43%, and 93.47% for dataset 2, and 92.51%, 1.58%, 91.90%, and 90.76% for dataset 3.
A Large Language Model Enhanced Conversational Recommender System
Aug 11, 2023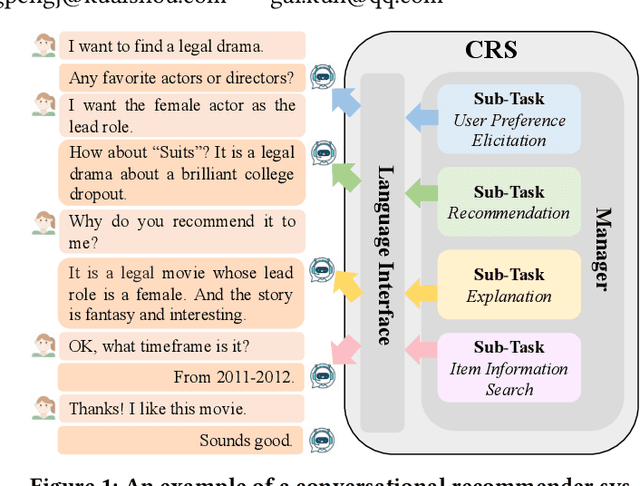
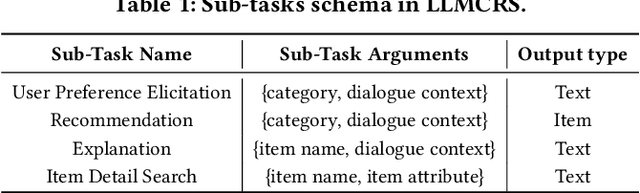
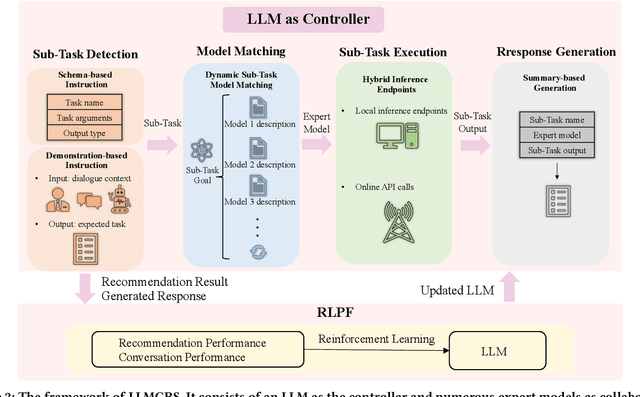

Conversational recommender systems (CRSs) aim to recommend high-quality items to users through a dialogue interface. It usually contains multiple sub-tasks, such as user preference elicitation, recommendation, explanation, and item information search. To develop effective CRSs, there are some challenges: 1) how to properly manage sub-tasks; 2) how to effectively solve different sub-tasks; and 3) how to correctly generate responses that interact with users. Recently, Large Language Models (LLMs) have exhibited an unprecedented ability to reason and generate, presenting a new opportunity to develop more powerful CRSs. In this work, we propose a new LLM-based CRS, referred to as LLMCRS, to address the above challenges. For sub-task management, we leverage the reasoning ability of LLM to effectively manage sub-task. For sub-task solving, we collaborate LLM with expert models of different sub-tasks to achieve the enhanced performance. For response generation, we utilize the generation ability of LLM as a language interface to better interact with users. Specifically, LLMCRS divides the workflow into four stages: sub-task detection, model matching, sub-task execution, and response generation. LLMCRS also designs schema-based instruction, demonstration-based instruction, dynamic sub-task and model matching, and summary-based generation to instruct LLM to generate desired results in the workflow. Finally, to adapt LLM to conversational recommendations, we also propose to fine-tune LLM with reinforcement learning from CRSs performance feedback, referred to as RLPF. Experimental results on benchmark datasets show that LLMCRS with RLPF outperforms the existing methods.
Node Embedding for Homophilous Graphs with ARGEW: Augmentation of Random walks by Graph Edge Weights
Aug 11, 2023
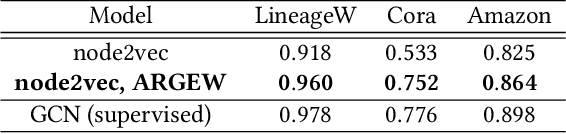
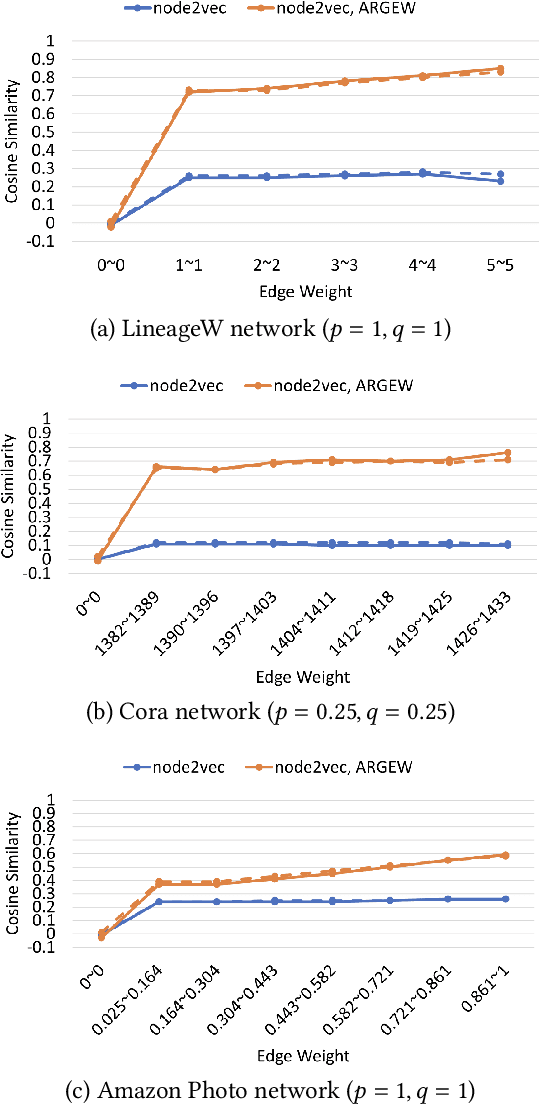
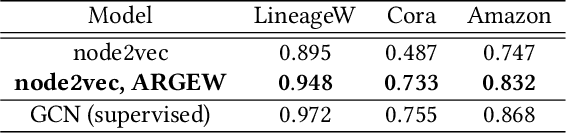
Representing nodes in a network as dense vectors node embeddings is important for understanding a given network and solving many downstream tasks. In particular, for weighted homophilous graphs where similar nodes are connected with larger edge weights, we desire node embeddings where node pairs with strong weights have closer embeddings. Although random walk based node embedding methods like node2vec and node2vec+ do work for weighted networks via including edge weights in the walk transition probabilities, our experiments show that the embedding result does not adequately reflect edge weights. In this paper, we propose ARGEW (Augmentation of Random walks by Graph Edge Weights), a novel augmentation method for random walks that expands the corpus in such a way that nodes with larger edge weights end up with closer embeddings. ARGEW can work with any random walk based node embedding method, because it is independent of the random sampling strategy itself and works on top of the already-performed walks. With several real-world networks, we demonstrate that with ARGEW, compared to not using it, the desired pattern that node pairs with larger edge weights have closer embeddings is much clearer. We also examine ARGEW's performance in node classification: node2vec with ARGEW outperforms pure node2vec and is not sensitive to hyperparameters (i.e. consistently good). In fact, it achieves similarly good results as supervised GCN, even without any node feature or label information during training. Finally, we explain why ARGEW works consistently well by exploring the coappearance distributions using a synthetic graph with clear structural roles.
Federated Learning: Organizational Opportunities, Challenges, and Adoption Strategies
Aug 04, 2023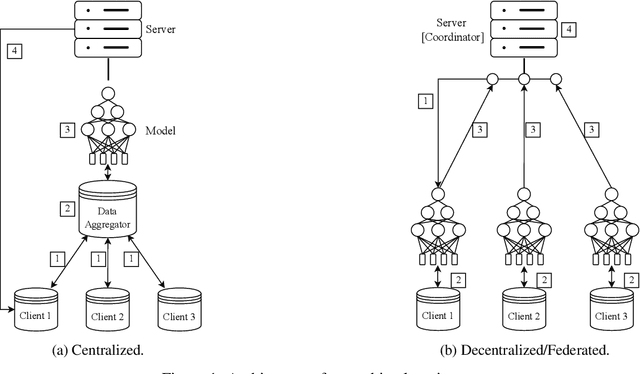
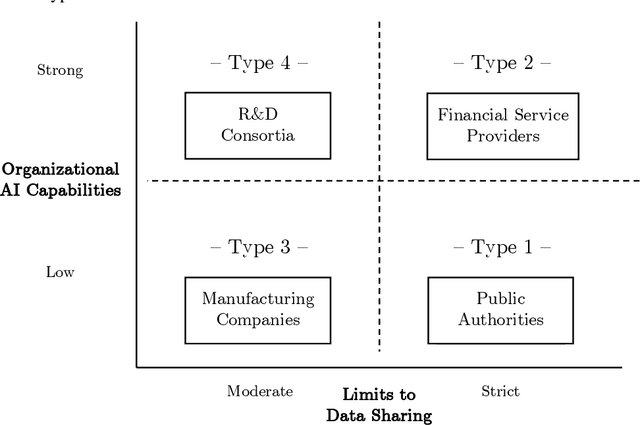
Restrictive rules for data sharing in many industries have led to the development of \ac{FL}. \ac{FL} is a \ac{ML} technique that allows distributed clients to train models collaboratively without the need to share their respective training data with others. In this article, we first explore the technical basics of FL and its potential applications. Second, we present a conceptual framework for the adoption of \ac{FL}, mapping organizations along the lines of their \ac{AI} capabilities and environment. We then discuss why exemplary organizations in different industries, including industry consortia, established banks, public authorities, and data-intensive SMEs might consider different approaches to \ac{FL}. To conclude, we argue that \ac{FL} presents an institutional shift with ample interdisciplinary research opportunities for the business and information systems engineering community.