 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Accurate Eye Tracking from Dense 3D Surface Reconstructions using Single-Shot Deflectometry
Aug 14, 2023
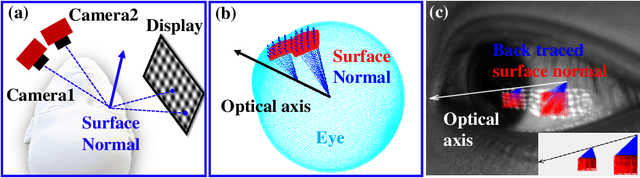

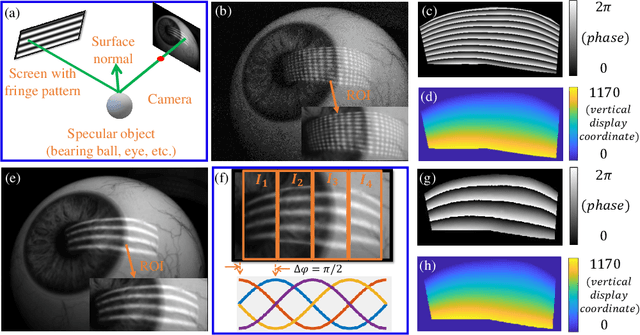
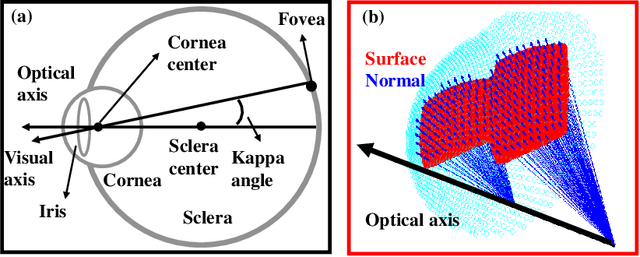
Eye-tracking plays a crucial role in the development of virtual reality devices, neuroscience research, and psychology. Despite its significance in numerous applications, achieving an accurate, robust, and fast eye-tracking solution remains a considerable challenge for current state-of-the-art methods. While existing reflection-based techniques (e.g., "glint tracking") are considered the most accurate, their performance is limited by their reliance on sparse 3D surface data acquired solely from the cornea surface. In this paper, we rethink the way how specular reflections can be used for eye tracking: We propose a novel method for accurate and fast evaluation of the gaze direction that exploits teachings from single-shot phase-measuring-deflectometry (PMD). In contrast to state-of-the-art reflection-based methods, our method acquires dense 3D surface information of both cornea and sclera within only one single camera frame (single-shot). Improvements in acquired reflection surface points("glints") of factors $>3300 \times$ are easily achievable. We show the feasibility of our approach with experimentally evaluated gaze errors of only $\leq 0.25^\circ$ demonstrating a significant improvement over the current state-of-the-art.
A Unified Masked Autoencoder with Patchified Skeletons for Motion Synthesis
Aug 14, 2023The synthesis of human motion has traditionally been addressed through task-dependent models that focus on specific challenges, such as predicting future motions or filling in intermediate poses conditioned on known key-poses. In this paper, we present a novel task-independent model called UNIMASK-M, which can effectively address these challenges using a unified architecture. Our model obtains comparable or better performance than the state-of-the-art in each field. Inspired by Vision Transformers (ViTs), our UNIMASK-M model decomposes a human pose into body parts to leverage the spatio-temporal relationships existing in human motion. Moreover, we reformulate various pose-conditioned motion synthesis tasks as a reconstruction problem with different masking patterns given as input. By explicitly informing our model about the masked joints, our UNIMASK-M becomes more robust to occlusions. Experimental results show that our model successfully forecasts human motion on the Human3.6M dataset. Moreover, it achieves state-of-the-art results in motion inbetweening on the LaFAN1 dataset, particularly in long transition periods. More information can be found on the project website https://sites.google.com/view/estevevallsmascaro/publications/unimask-m.
Masked Motion Predictors are Strong 3D Action Representation Learners
Aug 14, 2023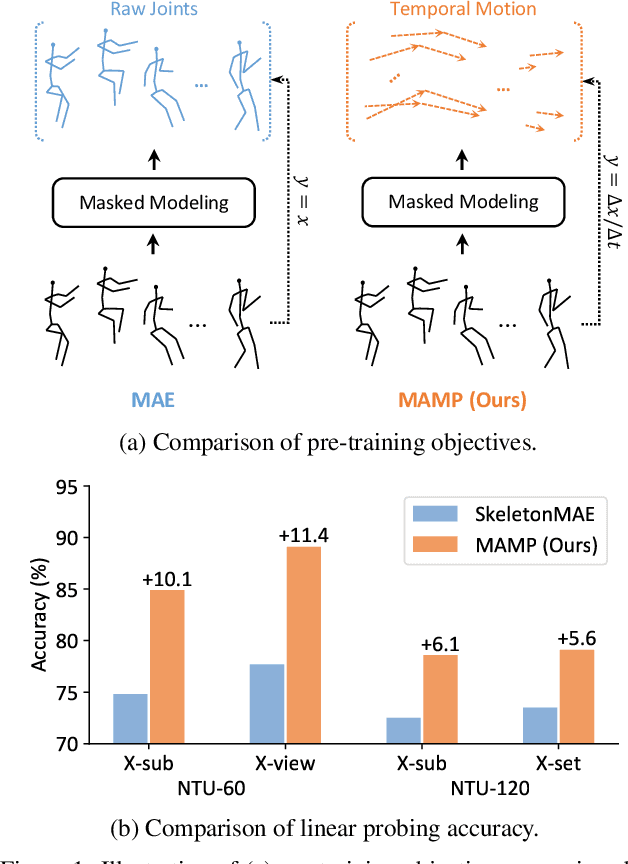
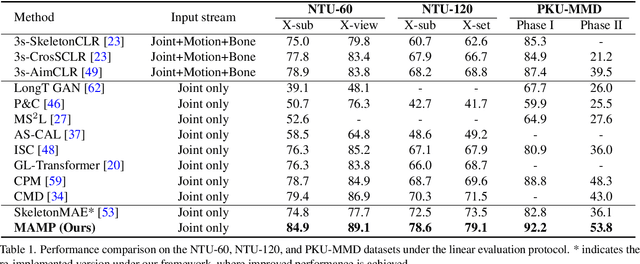
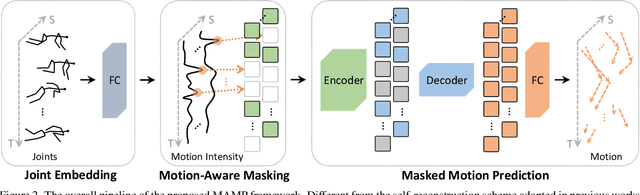
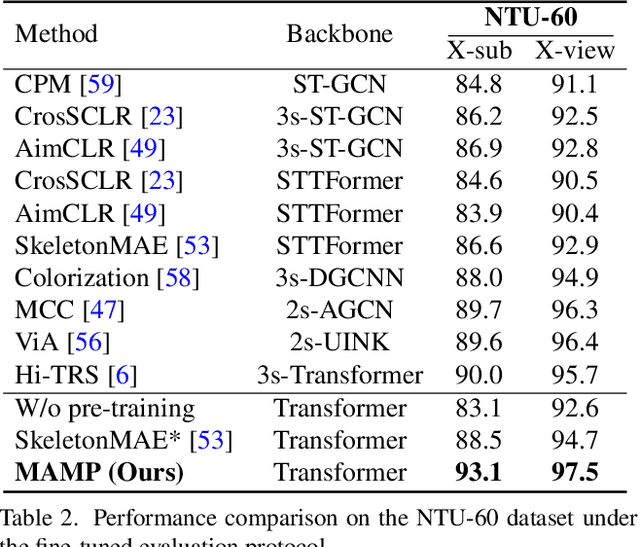
In 3D human action recognition, limited supervised data makes it challenging to fully tap into the modeling potential of powerful networks such as transformers. As a result, researchers have been actively investigating effective self-supervised pre-training strategies. In this work, we show that instead of following the prevalent pretext task to perform masked self-component reconstruction in human joints, explicit contextual motion modeling is key to the success of learning effective feature representation for 3D action recognition. Formally, we propose the Masked Motion Prediction (MAMP) framework. To be specific, the proposed MAMP takes as input the masked spatio-temporal skeleton sequence and predicts the corresponding temporal motion of the masked human joints. Considering the high temporal redundancy of the skeleton sequence, in our MAMP, the motion information also acts as an empirical semantic richness prior that guide the masking process, promoting better attention to semantically rich temporal regions. Extensive experiments on NTU-60, NTU-120, and PKU-MMD datasets show that the proposed MAMP pre-training substantially improves the performance of the adopted vanilla transformer, achieving state-of-the-art results without bells and whistles. The source code of our MAMP is available at https://github.com/maoyunyao/MAMP.
3D Localization and Tracking Methods for Multi-Platform Radar Networks
Aug 14, 2023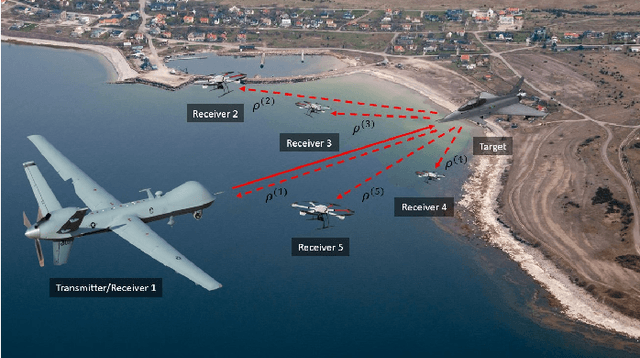
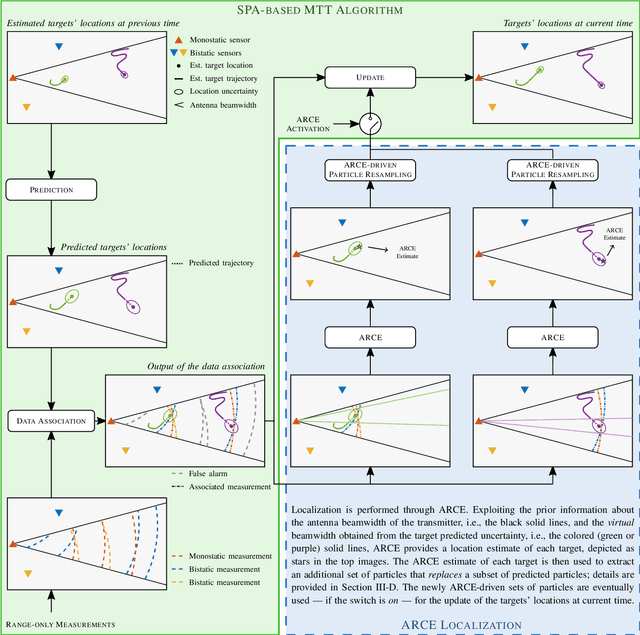
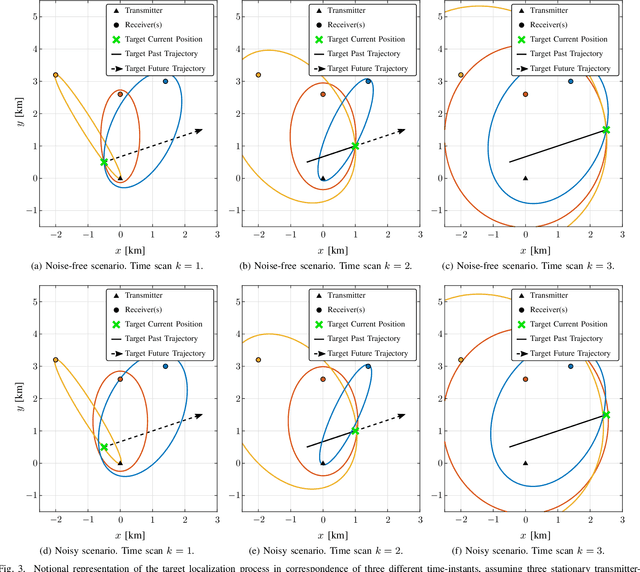
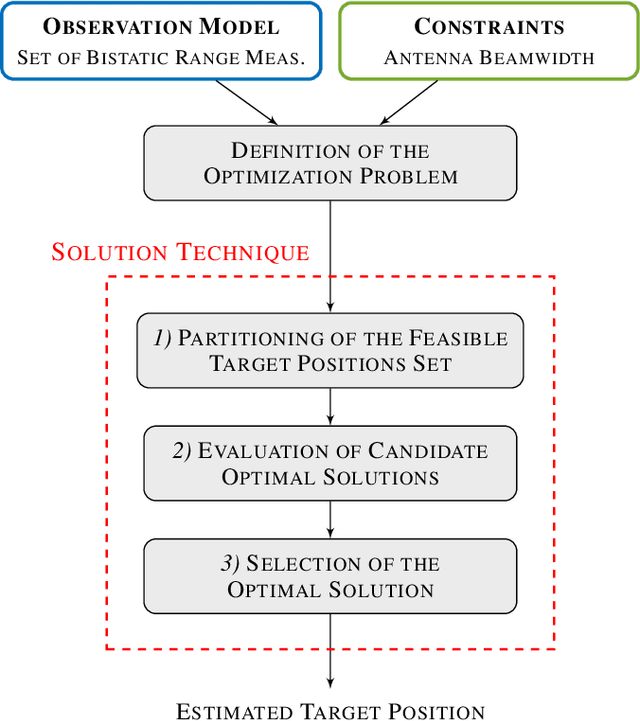
Multi-platform radar networks (MPRNs) are an emerging sensing technology due to their ability to provide improved surveillance capabilities over plain monostatic and bistatic systems. The design of advanced detection, localization, and tracking algorithms for efficient fusion of information obtained through multiple receivers has attracted much attention. However, considerable challenges remain. This article provides an overview on recent unconstrained and constrained localization techniques as well as multitarget tracking (MTT) algorithms tailored to MPRNs. In particular, two data-processing methods are illustrated and explored in detail, one aimed at accomplishing localization tasks the other tracking functions. As to the former, assuming a MPRN with one transmitter and multiple receivers, the angular and range constrained estimator (ARCE) algorithm capitalizes on the knowledge of the transmitter antenna beamwidth. As to the latter, the scalable sum-product algorithm (SPA) based MTT technique is presented. Additionally, a solution to combine ARCE and SPA-based MTT is investigated in order to boost the accuracy of the overall surveillance system. Simulated experiments show the benefit of the combined algorithm in comparison with the conventional baseline SPA-based MTT and the stand-alone ARCE localization, in a 3D sensing scenario.
Multi-Receiver Task-Oriented Communications via Multi-Task Deep Learning
Aug 14, 2023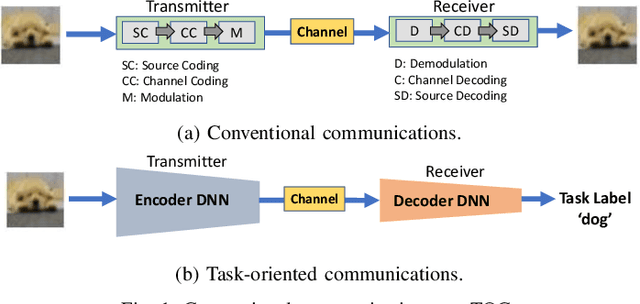
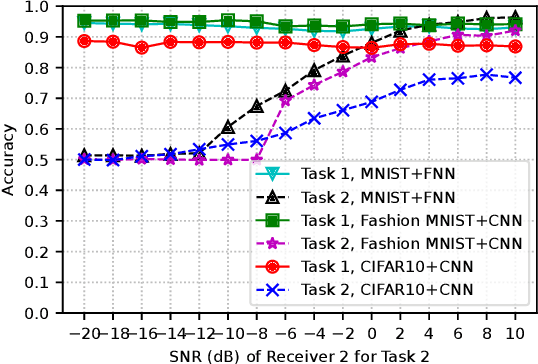
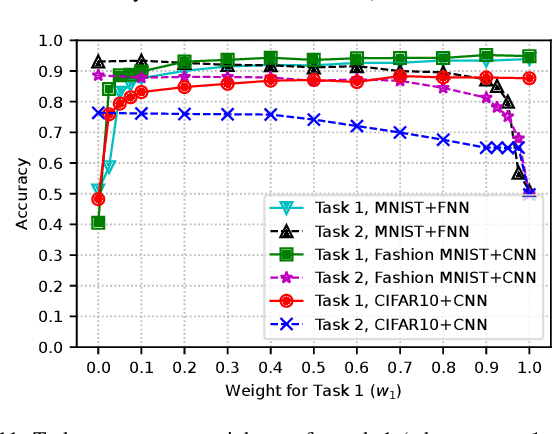
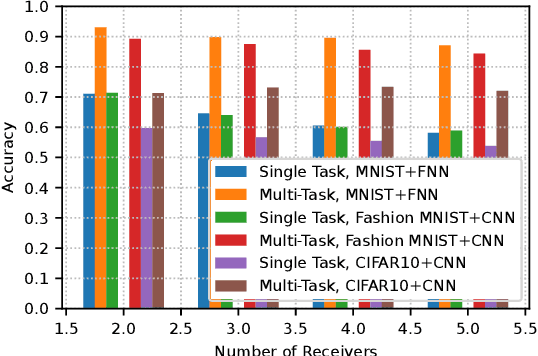
This paper studies task-oriented, otherwise known as goal-oriented, communications, in a setting where a transmitter communicates with multiple receivers, each with its own task to complete on a dataset, e.g., images, available at the transmitter. A multi-task deep learning approach that involves training a common encoder at the transmitter and individual decoders at the receivers is presented for joint optimization of completing multiple tasks and communicating with multiple receivers. By providing efficient resource allocation at the edge of 6G networks, the proposed approach allows the communications system to adapt to varying channel conditions and achieves task-specific objectives while minimizing transmission overhead. Joint training of the encoder and decoders using multi-task learning captures shared information across tasks and optimizes the communication process accordingly. By leveraging the broadcast nature of wireless communications, multi-receiver task-oriented communications (MTOC) reduces the number of transmissions required to complete tasks at different receivers. Performance evaluation conducted on the MNIST, Fashion MNIST, and CIFAR-10 datasets (with image classification considered for different tasks) demonstrates the effectiveness of MTOC in terms of classification accuracy and resource utilization compared to single-task-oriented communication systems.
AutoSeqRec: Autoencoder for Efficient Sequential Recommendation
Aug 14, 2023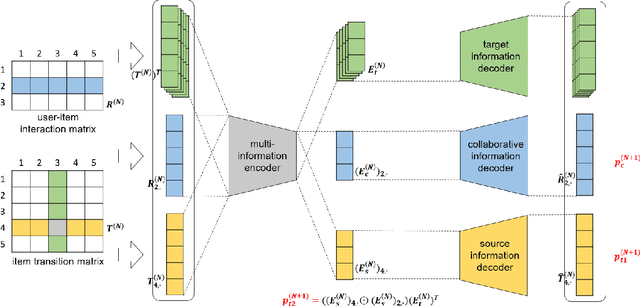
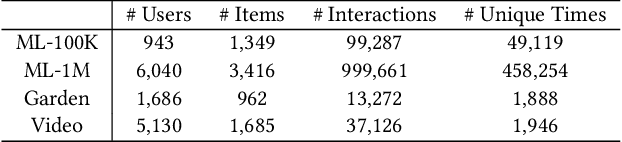
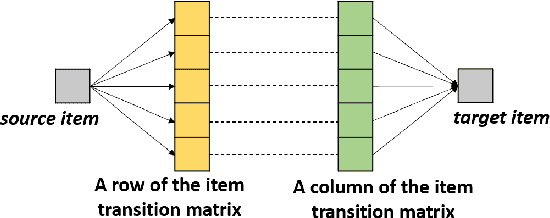
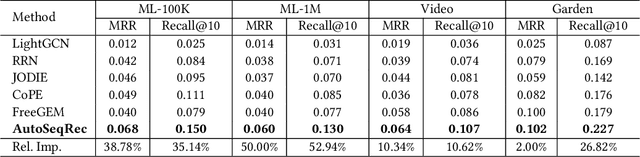
Sequential recommendation demonstrates the capability to recommend items by modeling the sequential behavior of users. Traditional methods typically treat users as sequences of items, overlooking the collaborative relationships among them. Graph-based methods incorporate collaborative information by utilizing the user-item interaction graph. However, these methods sometimes face challenges in terms of time complexity and computational efficiency. To address these limitations, this paper presents AutoSeqRec, an incremental recommendation model specifically designed for sequential recommendation tasks. AutoSeqRec is based on autoencoders and consists of an encoder and three decoders within the autoencoder architecture. These components consider both the user-item interaction matrix and the rows and columns of the item transition matrix. The reconstruction of the user-item interaction matrix captures user long-term preferences through collaborative filtering. In addition, the rows and columns of the item transition matrix represent the item out-degree and in-degree hopping behavior, which allows for modeling the user's short-term interests. When making incremental recommendations, only the input matrices need to be updated, without the need to update parameters, which makes AutoSeqRec very efficient. Comprehensive evaluations demonstrate that AutoSeqRec outperforms existing methods in terms of accuracy, while showcasing its robustness and efficiency.
UniBrain: Unify Image Reconstruction and Captioning All in One Diffusion Model from Human Brain Activity
Aug 14, 2023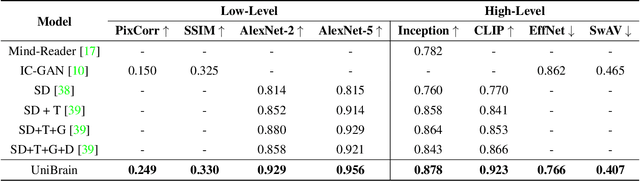
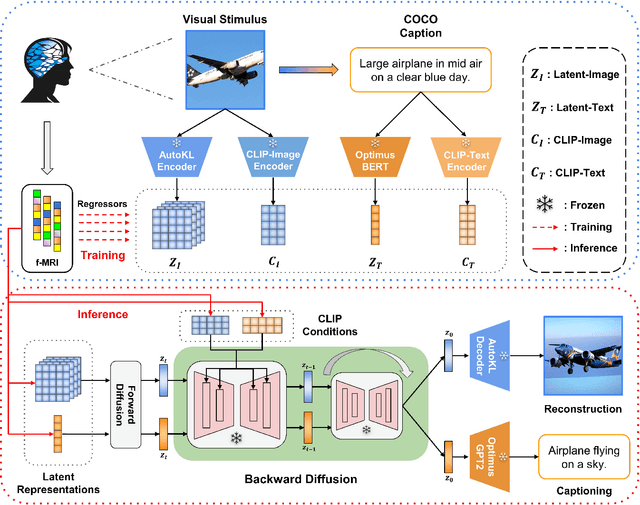
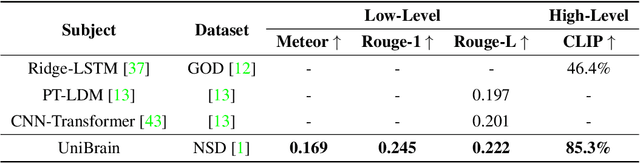

Image reconstruction and captioning from brain activity evoked by visual stimuli allow researchers to further understand the connection between the human brain and the visual perception system. While deep generative models have recently been employed in this field, reconstructing realistic captions and images with both low-level details and high semantic fidelity is still a challenging problem. In this work, we propose UniBrain: Unify Image Reconstruction and Captioning All in One Diffusion Model from Human Brain Activity. For the first time, we unify image reconstruction and captioning from visual-evoked functional magnetic resonance imaging (fMRI) through a latent diffusion model termed Versatile Diffusion. Specifically, we transform fMRI voxels into text and image latent for low-level information and guide the backward diffusion process through fMRI-based image and text conditions derived from CLIP to generate realistic captions and images. UniBrain outperforms current methods both qualitatively and quantitatively in terms of image reconstruction and reports image captioning results for the first time on the Natural Scenes Dataset (NSD) dataset. Moreover, the ablation experiments and functional region-of-interest (ROI) analysis further exhibit the superiority of UniBrain and provide comprehensive insight for visual-evoked brain decoding.
Probing self-supervised speech models for phonetic and phonemic information: a case study in aspiration
Jun 09, 2023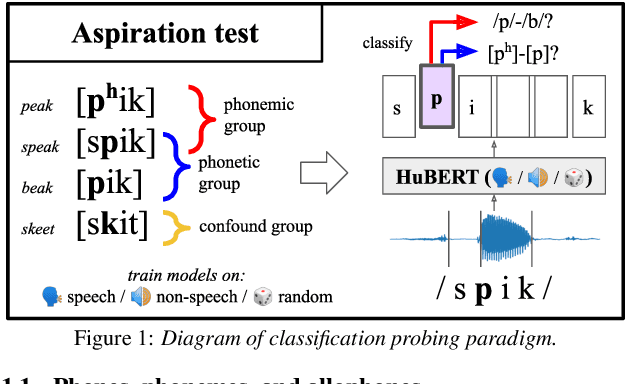
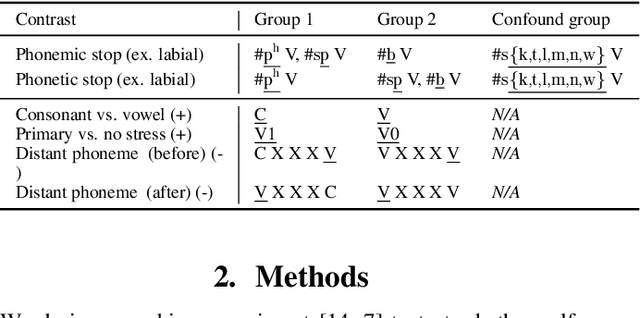
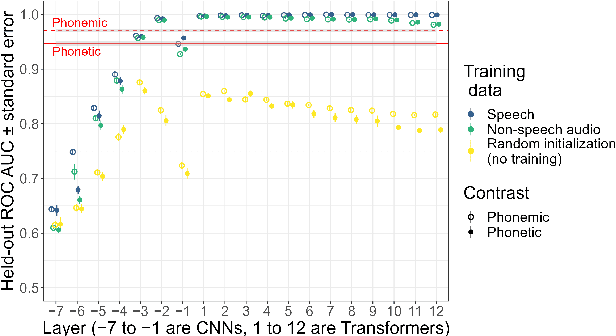
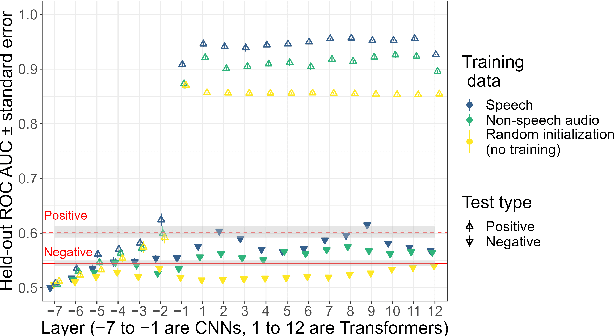
Textless self-supervised speech models have grown in capabilities in recent years, but the nature of the linguistic information they encode has not yet been thoroughly examined. We evaluate the extent to which these models' learned representations align with basic representational distinctions made by humans, focusing on a set of phonetic (low-level) and phonemic (more abstract) contrasts instantiated in word-initial stops. We find that robust representations of both phonetic and phonemic distinctions emerge in early layers of these models' architectures, and are preserved in the principal components of deeper layer representations. Our analyses suggest two sources for this success: some can only be explained by the optimization of the models on speech data, while some can be attributed to these models' high-dimensional architectures. Our findings show that speech-trained HuBERT derives a low-noise and low-dimensional subspace corresponding to abstract phonological distinctions.
Introducing Feature Attention Module on Convolutional Neural Network for Diabetic Retinopathy Detection
Aug 06, 2023Diabetic retinopathy (DR) is a leading cause of blindness among diabetic patients. Deep learning models have shown promising results in automating the detection of DR. In the present work, we propose a new methodology that integrates a feature attention module with a pretrained VGG19 convolutional neural network (CNN) for more accurate DR detection. Here, the pretrained net is fine-tuned with the proposed feature attention block. The proposed module aims to leverage the complementary information from various regions of fundus images to enhance the discriminative power of the CNN. The said feature attention module incorporates an attention mechanism which selectively highlights salient features from images and fuses them with the original input. The simultaneous learning of attention weights for the features and thereupon the combination of attention-modulated features within the feature attention block facilitates the network's ability to focus on relevant information while reducing the impact of noisy or irrelevant features. Performance of the proposed method has been evaluated on a widely used dataset for diabetic retinopathy classification e.g., the APTOS (Asia Pacific Tele-Ophthalmology Society) DR Dataset. Results are compared with/without attention module, as well as with other state-of-the-art approaches. Results confirm that the introduction of the fusion module (fusing of feature attention module with CNN) improves the accuracy of DR detection achieving an accuracy of 95.70%.
Effect of Choosing Loss Function when Using T-batching for Representation Learning on Dynamic Networks
Aug 13, 2023Representation learning methods have revolutionized machine learning on networks by converting discrete network structures into continuous domains. However, dynamic networks that evolve over time pose new challenges. To address this, dynamic representation learning methods have gained attention, offering benefits like reduced learning time and improved accuracy by utilizing temporal information. T-batching is a valuable technique for training dynamic network models that reduces training time while preserving vital conditions for accurate modeling. However, we have identified a limitation in the training loss function used with t-batching. Through mathematical analysis, we propose two alternative loss functions that overcome these issues, resulting in enhanced training performance. We extensively evaluate the proposed loss functions on synthetic and real-world dynamic networks. The results consistently demonstrate superior performance compared to the original loss function. Notably, in a real-world network characterized by diverse user interaction histories, the proposed loss functions achieved more than 26.9% enhancement in Mean Reciprocal Rank (MRR) and more than 11.8% improvement in Recall@10. These findings underscore the efficacy of the proposed loss functions in dynamic network modeling.