 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Machine Learning for Administrative Health Records: A Systematic Review of Techniques and Applications
Aug 27, 2023
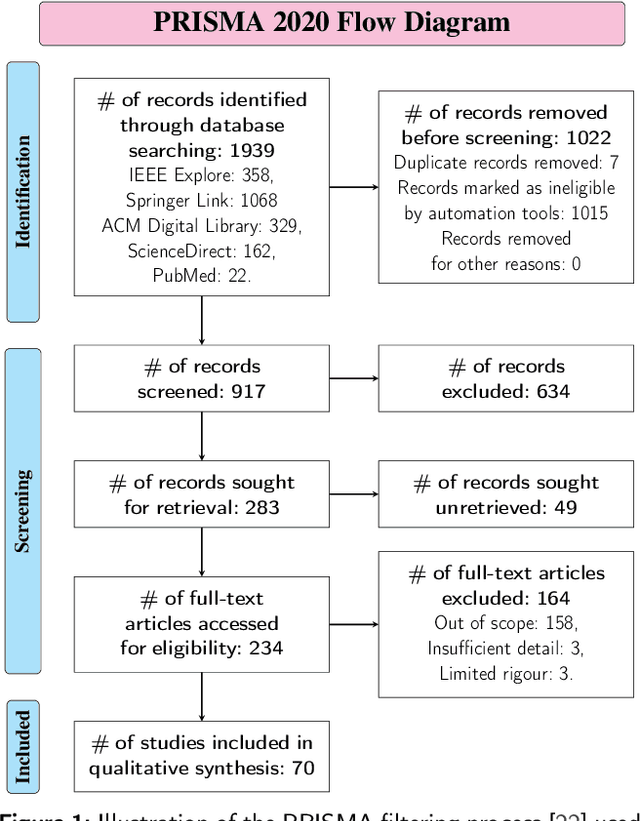
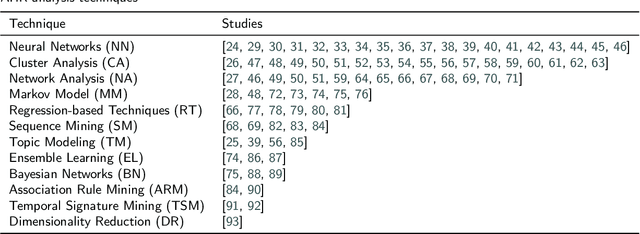
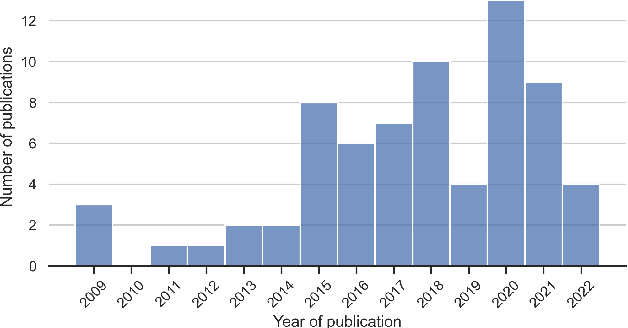
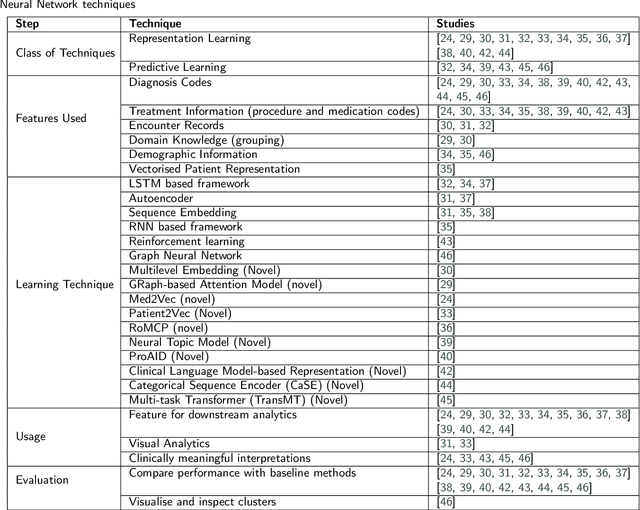
Machine learning provides many powerful and effective techniques for analysing heterogeneous electronic health records (EHR). Administrative Health Records (AHR) are a subset of EHR collected for administrative purposes, and the use of machine learning on AHRs is a growing subfield of EHR analytics. Existing reviews of EHR analytics emphasise that the data-modality of the EHR limits the breadth of suitable machine learning techniques, and pursuable healthcare applications. Despite emphasising the importance of data modality, the literature fails to analyse which techniques and applications are relevant to AHRs. AHRs contain uniquely well-structured, categorically encoded records which are distinct from other data-modalities captured by EHRs, and they can provide valuable information pertaining to how patients interact with the healthcare system. This paper systematically reviews AHR-based research, analysing 70 relevant studies and spanning multiple databases. We identify and analyse which machine learning techniques are applied to AHRs and which health informatics applications are pursued in AHR-based research. We also analyse how these techniques are applied in pursuit of each application, and identify the limitations of these approaches. We find that while AHR-based studies are disconnected from each other, the use of AHRs in health informatics research is substantial and accelerating. Our synthesis of these studies highlights the utility of AHRs for pursuing increasingly complex and diverse research objectives despite a number of pervading data- and technique-based limitations. Finally, through our findings, we propose a set of future research directions that can enhance the utility of AHR data and machine learning techniques for health informatics research.
Can Authorship Representation Learning Capture Stylistic Features?
Aug 24, 2023Automatically disentangling an author's style from the content of their writing is a longstanding and possibly insurmountable problem in computational linguistics. At the same time, the availability of large text corpora furnished with author labels has recently enabled learning authorship representations in a purely data-driven manner for authorship attribution, a task that ostensibly depends to a greater extent on encoding writing style than encoding content. However, success on this surrogate task does not ensure that such representations capture writing style since authorship could also be correlated with other latent variables, such as topic. In an effort to better understand the nature of the information these representations convey, and specifically to validate the hypothesis that they chiefly encode writing style, we systematically probe these representations through a series of targeted experiments. The results of these experiments suggest that representations learned for the surrogate authorship prediction task are indeed sensitive to writing style. As a consequence, authorship representations may be expected to be robust to certain kinds of data shift, such as topic drift over time. Additionally, our findings may open the door to downstream applications that require stylistic representations, such as style transfer.
ZeroLeak: Using LLMs for Scalable and Cost Effective Side-Channel Patching
Aug 24, 2023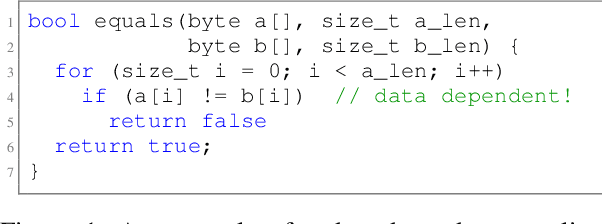

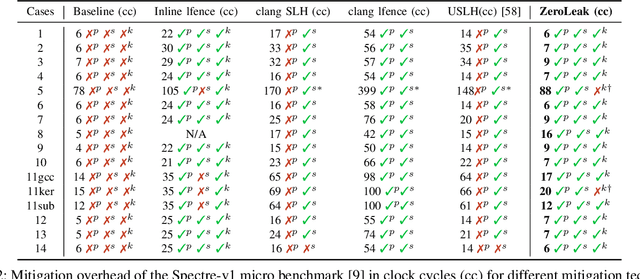
Security critical software, e.g., OpenSSL, comes with numerous side-channel leakages left unpatched due to a lack of resources or experts. The situation will only worsen as the pace of code development accelerates, with developers relying on Large Language Models (LLMs) to automatically generate code. In this work, we explore the use of LLMs in generating patches for vulnerable code with microarchitectural side-channel leakages. For this, we investigate the generative abilities of powerful LLMs by carefully crafting prompts following a zero-shot learning approach. All generated code is dynamically analyzed by leakage detection tools, which are capable of pinpointing information leakage at the instruction level leaked either from secret dependent accesses or branches or vulnerable Spectre gadgets, respectively. Carefully crafted prompts are used to generate candidate replacements for vulnerable code, which are then analyzed for correctness and for leakage resilience. From a cost/performance perspective, the GPT4-based configuration costs in API calls a mere few cents per vulnerability fixed. Our results show that LLM-based patching is far more cost-effective and thus provides a scalable solution. Finally, the framework we propose will improve in time, especially as vulnerability detection tools and LLMs mature.
Hybrid noise shaping for audio coding using perfectly overlapped window
Aug 24, 2023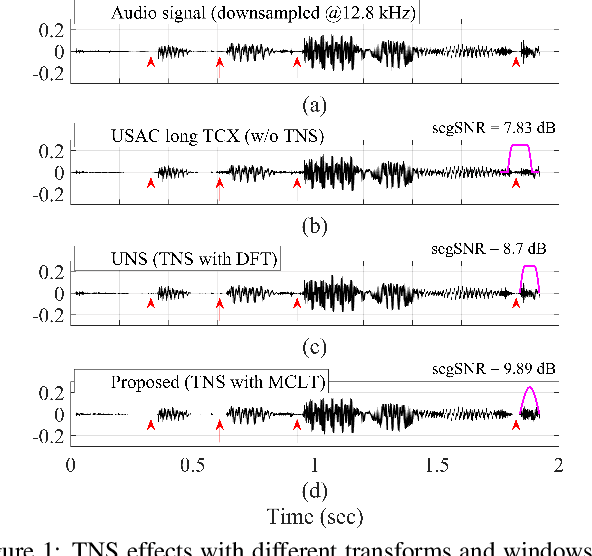
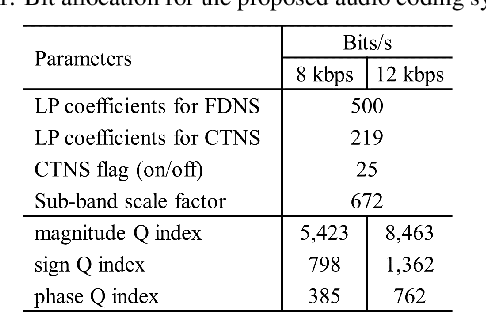
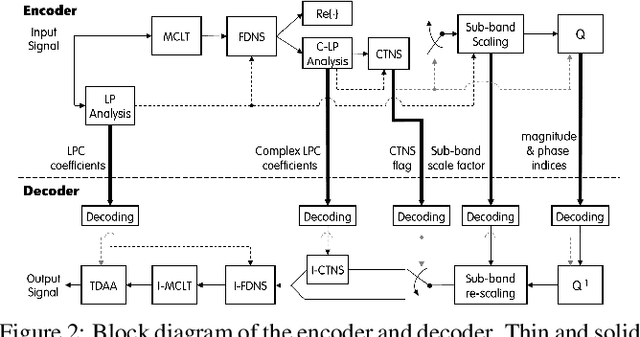
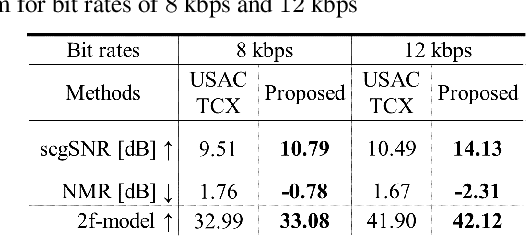
In recent years, audio coding technology has been standardized based on several frameworks that incorporate linear predictive coding (LPC). However, coding the transient signal using frequency-domain LP residual signals remains a challenge. To address this, temporal noise shaping (TNS) can be adapted, although it cannot be effectively operated since the estimated temporal envelope in the modified discrete cosine transform (MDCT) domain is accompanied by the time-domain aliasing (TDA) terms. In this study, we propose the modulated complex lapped transform-based coding framework integrated with transform coded excitation (TCX) and complex LPC-based TNS (CTNS). Our approach uses a 50\% overlap window and switching scheme for the CTNS to improve the coding efficiency. Additionally, an adaptive calculation of the target bits for the sub-bands using the frequency envelope information based on the quantized LPC coefficients is proposed. To minimize the quantization mismatch between both modes, an integrated quantization for real and complex values and a TDA augmentation method that compensates for the artificially generated TDA components during switching operations are proposed. The proposed coding framework shows a superior performance in both objective metrics and subjective listening tests, thereby demonstrating its low bit-rate audio coding.
Asymmetric Co-Training with Explainable Cell Graph Ensembling for Histopathological Image Classification
Aug 24, 2023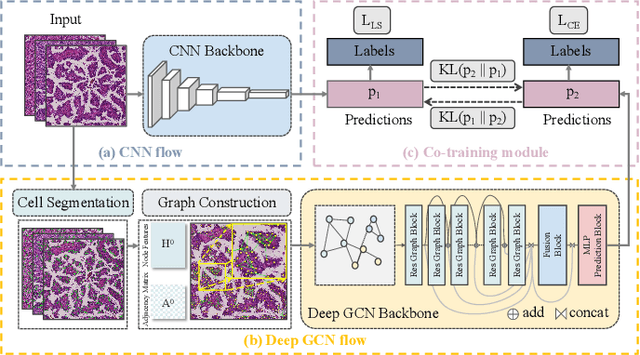
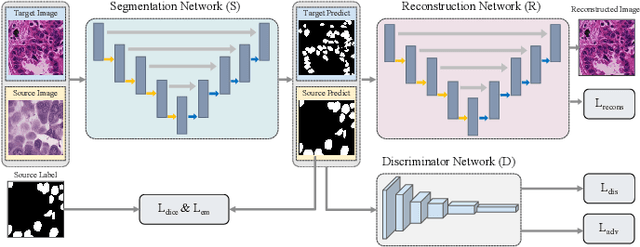
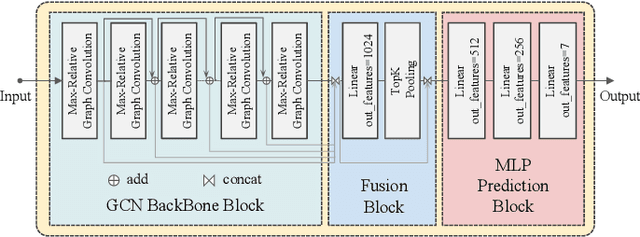
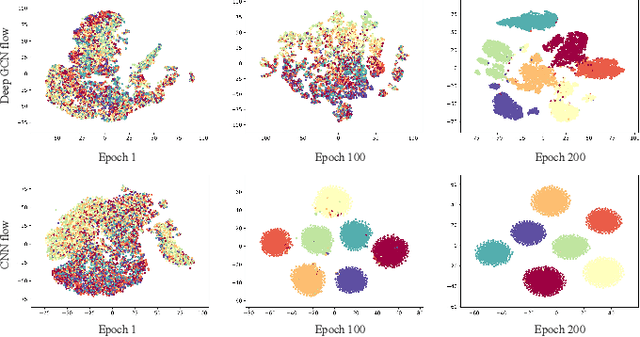
Convolutional neural networks excel in histopathological image classification, yet their pixel-level focus hampers explainability. Conversely, emerging graph convolutional networks spotlight cell-level features and medical implications. However, limited by their shallowness and suboptimal use of high-dimensional pixel data, GCNs underperform in multi-class histopathological image classification. To make full use of pixel-level and cell-level features dynamically, we propose an asymmetric co-training framework combining a deep graph convolutional network and a convolutional neural network for multi-class histopathological image classification. To improve the explainability of the entire framework by embedding morphological and topological distribution of cells, we build a 14-layer deep graph convolutional network to handle cell graph data. For the further utilization and dynamic interactions between pixel-level and cell-level information, we also design a co-training strategy to integrate the two asymmetric branches. Notably, we collect a private clinically acquired dataset termed LUAD7C, including seven subtypes of lung adenocarcinoma, which is rare and more challenging. We evaluated our approach on the private LUAD7C and public colorectal cancer datasets, showcasing its superior performance, explainability, and generalizability in multi-class histopathological image classification.
Inducing Causal Structure for Abstractive Text Summarization
Aug 24, 2023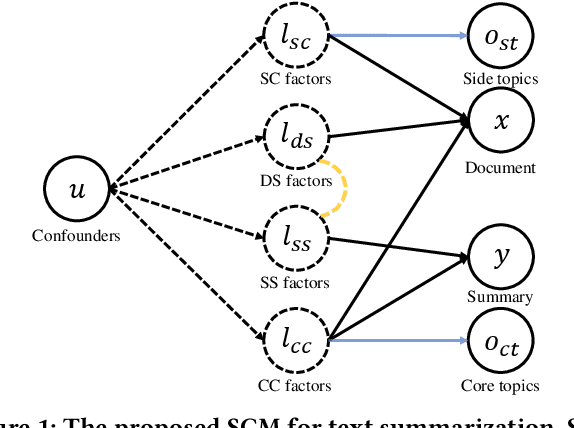
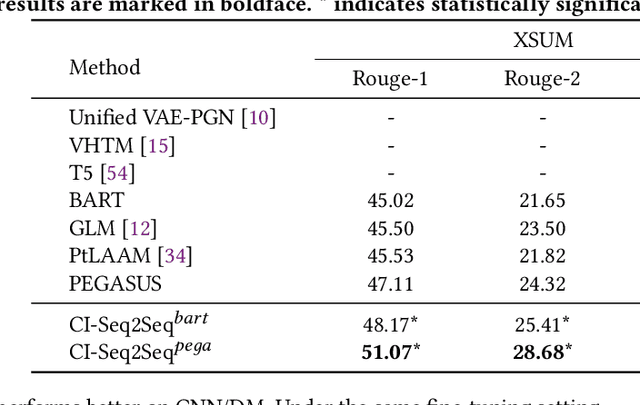
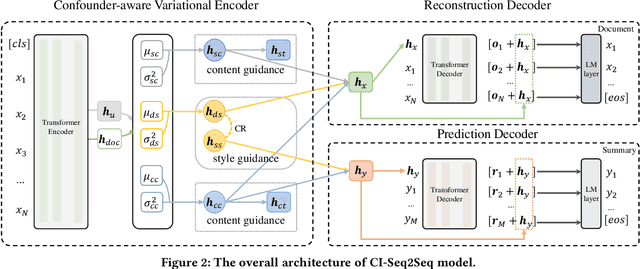
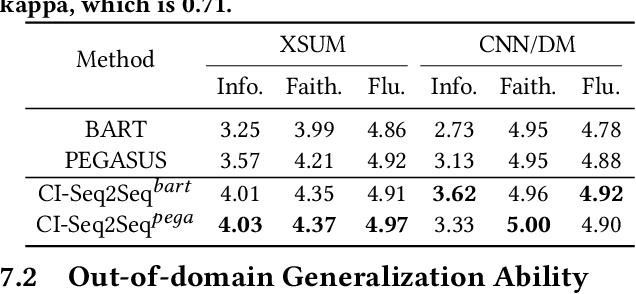
The mainstream of data-driven abstractive summarization models tends to explore the correlations rather than the causal relationships. Among such correlations, there can be spurious ones which suffer from the language prior learned from the training corpus and therefore undermine the overall effectiveness of the learned model. To tackle this issue, we introduce a Structural Causal Model (SCM) to induce the underlying causal structure of the summarization data. We assume several latent causal factors and non-causal factors, representing the content and style of the document and summary. Theoretically, we prove that the latent factors in our SCM can be identified by fitting the observed training data under certain conditions. On the basis of this, we propose a Causality Inspired Sequence-to-Sequence model (CI-Seq2Seq) to learn the causal representations that can mimic the causal factors, guiding us to pursue causal information for summary generation. The key idea is to reformulate the Variational Auto-encoder (VAE) to fit the joint distribution of the document and summary variables from the training corpus. Experimental results on two widely used text summarization datasets demonstrate the advantages of our approach.
Don't Look into the Sun: Adversarial Solarization Attacks on Image Classifiers
Aug 24, 2023Assessing the robustness of deep neural networks against out-of-distribution inputs is crucial, especially in safety-critical domains like autonomous driving, but also in safety systems where malicious actors can digitally alter inputs to circumvent safety guards. However, designing effective out-of-distribution tests that encompass all possible scenarios while preserving accurate label information is a challenging task. Existing methodologies often entail a compromise between variety and constraint levels for attacks and sometimes even both. In a first step towards a more holistic robustness evaluation of image classification models, we introduce an attack method based on image solarization that is conceptually straightforward yet avoids jeopardizing the global structure of natural images independent of the intensity. Through comprehensive evaluations of multiple ImageNet models, we demonstrate the attack's capacity to degrade accuracy significantly, provided it is not integrated into the training augmentations. Interestingly, even then, no full immunity to accuracy deterioration is achieved. In other settings, the attack can often be simplified into a black-box attack with model-independent parameters. Defenses against other corruptions do not consistently extend to be effective against our specific attack. Project website: https://github.com/paulgavrikov/adversarial_solarization
Boosting Semantic Segmentation from the Perspective of Explicit Class Embeddings
Aug 24, 2023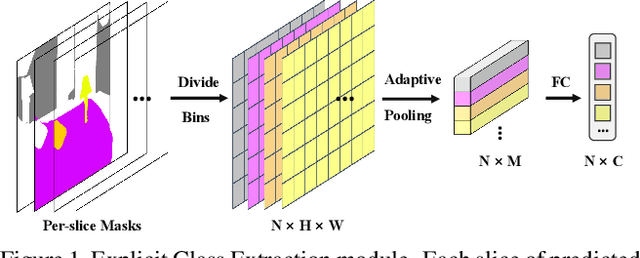
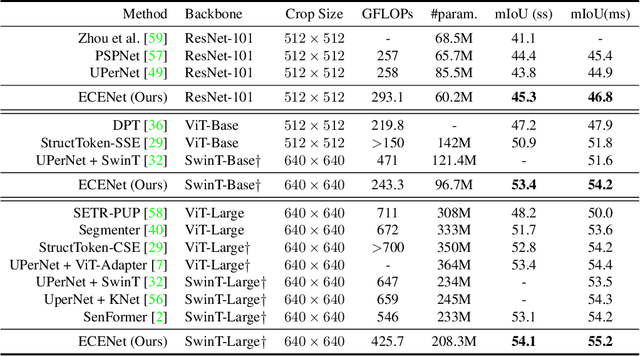
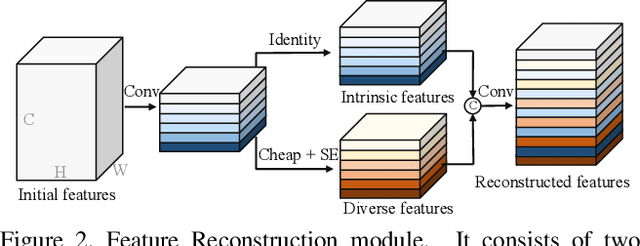
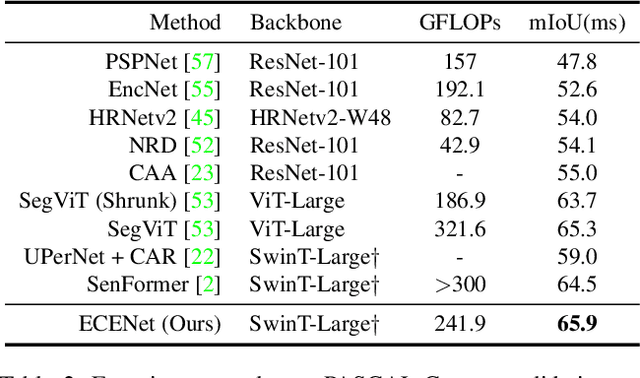
Semantic segmentation is a computer vision task that associates a label with each pixel in an image. Modern approaches tend to introduce class embeddings into semantic segmentation for deeply utilizing category semantics, and regard supervised class masks as final predictions. In this paper, we explore the mechanism of class embeddings and have an insight that more explicit and meaningful class embeddings can be generated based on class masks purposely. Following this observation, we propose ECENet, a new segmentation paradigm, in which class embeddings are obtained and enhanced explicitly during interacting with multi-stage image features. Based on this, we revisit the traditional decoding process and explore inverted information flow between segmentation masks and class embeddings. Furthermore, to ensure the discriminability and informativity of features from backbone, we propose a Feature Reconstruction module, which combines intrinsic and diverse branches together to ensure the concurrence of diversity and redundancy in features. Experiments show that our ECENet outperforms its counterparts on the ADE20K dataset with much less computational cost and achieves new state-of-the-art results on PASCAL-Context dataset. The code will be released at https://gitee.com/mindspore/models and https://github.com/Carol-lyh/ECENet.
Eigenvector prediction-based precoding for massive MIMO with mobility
Aug 24, 2023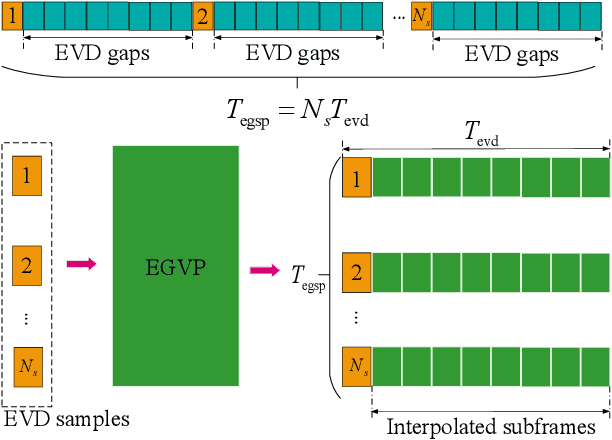
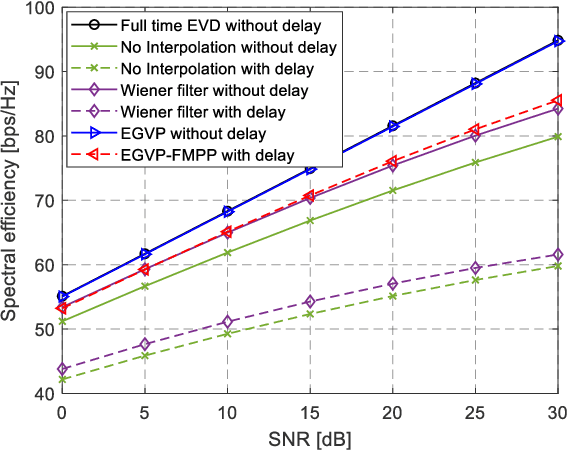
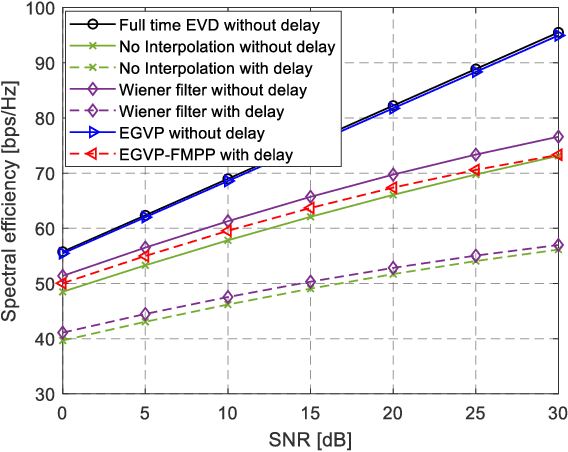
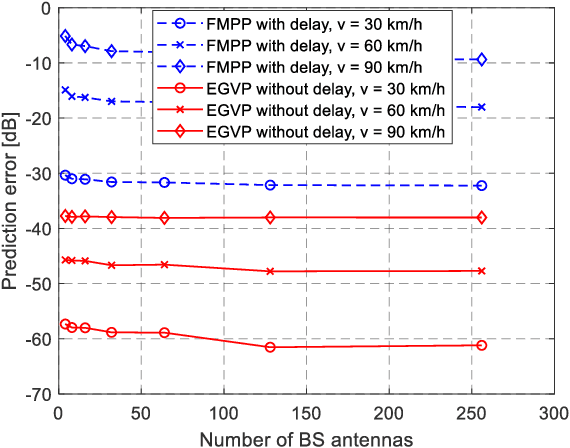
Eigenvector decomposition (EVD) is an inevitable operation to obtain the precoders in practical massive multiple-input multiple-output (MIMO) systems. Due to the large antenna size and at finite computation resources at the base station (BS), the overwhelming computation complexity of EVD is one of the key limiting factors of the system performance. To address this problem, we propose an eigenvector prediction (EGVP) method by interpolating the precoding matrix with predicted eigenvectors. The basic idea is to exploit a few historical precoders to interpolate the rest of them without EVD of the channel state information (CSI). We transform the nonlinear EVD into a linear prediction problem and prove that the prediction of the eigenvectors can be achieved with a complex exponential model. Furthermore, a channel prediction method called fast matrix pencil prediction (FMPP) is proposed to cope with the CSI delay when applying the EGVP method in mobility environments. The asymptotic analysis demonstrates how many samples are needed to achieve asymptotically error-free eigenvector predictions and channel predictions. Finally, the simulation results demonstrate the spectral efficiency improvement of our scheme over the benchmarks and the robustness to different mobility scenarios.
Feature Extraction Using Deep Generative Models for Bangla Text Classification on a New Comprehensive Dataset
Aug 21, 2023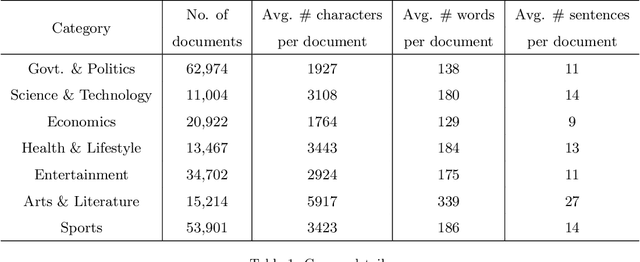
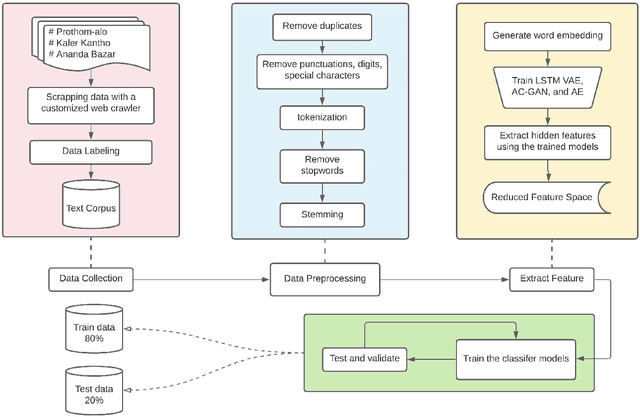
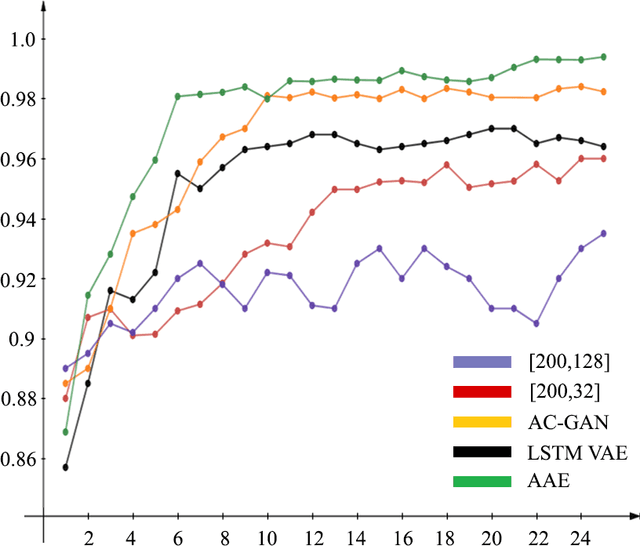
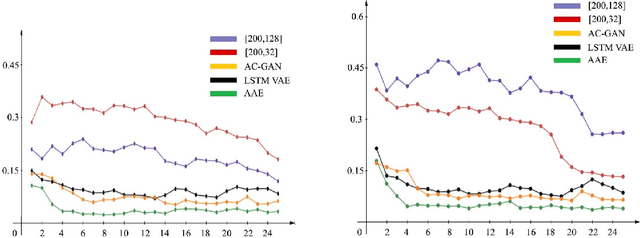
The selection of features for text classification is a fundamental task in text mining and information retrieval. Despite being the sixth most widely spoken language in the world, Bangla has received little attention due to the scarcity of text datasets. In this research, we collected, annotated, and prepared a comprehensive dataset of 212,184 Bangla documents in seven different categories and made it publicly accessible. We implemented three deep learning generative models: LSTM variational autoencoder (LSTM VAE), auxiliary classifier generative adversarial network (AC-GAN), and adversarial autoencoder (AAE) to extract text features, although their applications are initially found in the field of computer vision. We utilized our dataset to train these three models and used the feature space obtained in the document classification task. We evaluated the performance of the classifiers and found that the adversarial autoencoder model produced the best feature space.