 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fine-grained Text and Image Guided Point Cloud Completion with CLIP Model
Aug 17, 2023
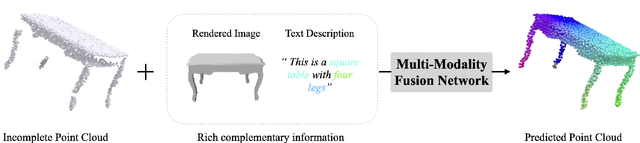
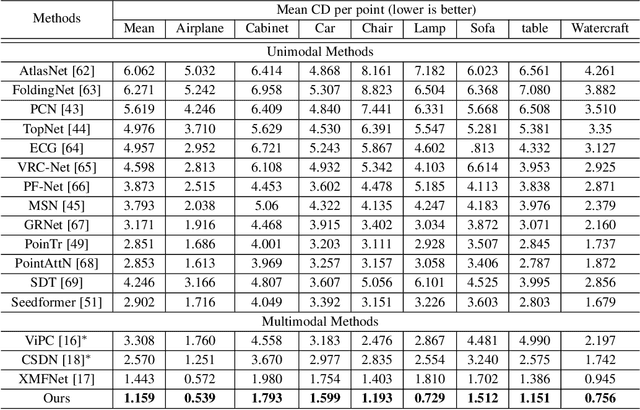
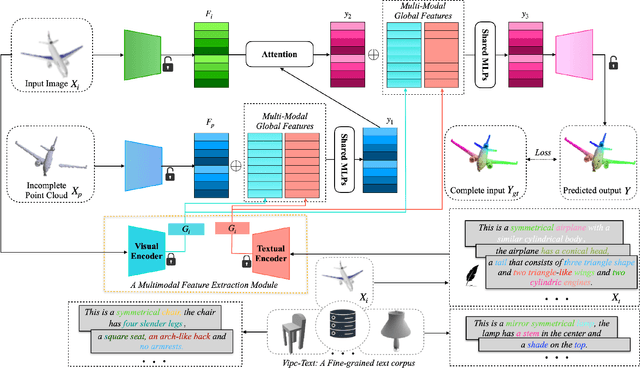
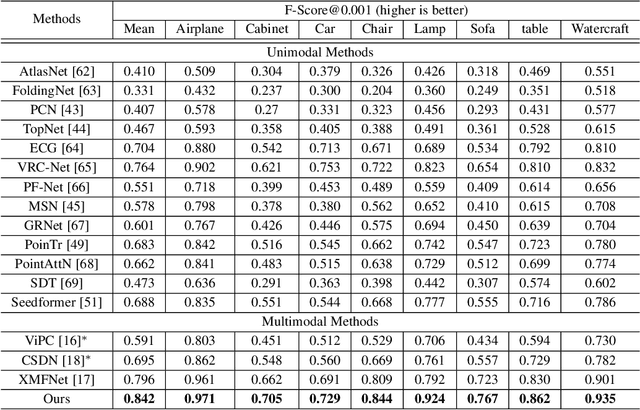
This paper focuses on the recently popular task of point cloud completion guided by multimodal information. Although existing methods have achieved excellent performance by fusing auxiliary images, there are still some deficiencies, including the poor generalization ability of the model and insufficient fine-grained semantic information for extracted features. In this work, we propose a novel multimodal fusion network for point cloud completion, which can simultaneously fuse visual and textual information to predict the semantic and geometric characteristics of incomplete shapes effectively. Specifically, to overcome the lack of prior information caused by the small-scale dataset, we employ a pre-trained vision-language model that is trained with a large amount of image-text pairs. Therefore, the textual and visual encoders of this large-scale model have stronger generalization ability. Then, we propose a multi-stage feature fusion strategy to fuse the textual and visual features into the backbone network progressively. Meanwhile, to further explore the effectiveness of fine-grained text descriptions for point cloud completion, we also build a text corpus with fine-grained descriptions, which can provide richer geometric details for 3D shapes. The rich text descriptions can be used for training and evaluating our network. Extensive quantitative and qualitative experiments demonstrate the superior performance of our method compared to state-of-the-art point cloud completion networks.
Edge-aware Hard Clustering Graph Pooling for Brain Imaging Data
Sep 03, 2023
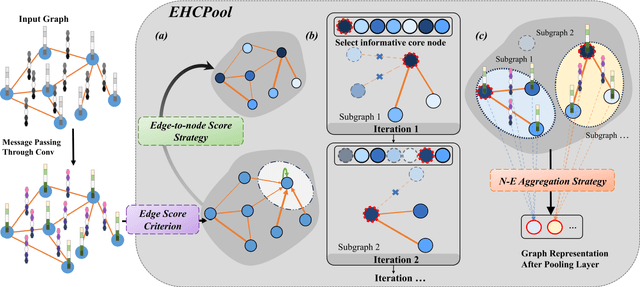
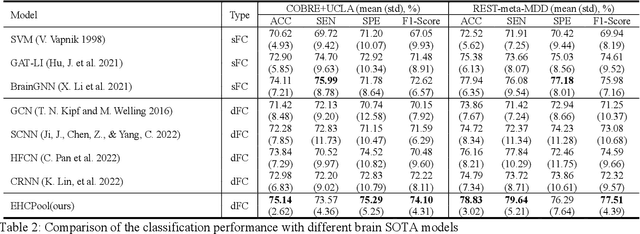

Graph Convolutional Networks (GCNs) can capture non-Euclidean spatial dependence between different brain regions, and the graph pooling operator in GCNs is key to enhancing the representation learning capability and acquiring abnormal brain maps. However, the majority of existing research designs graph pooling operators only from the perspective of nodes while disregarding the original edge features, in a way that not only confines graph pooling application scenarios, but also diminishes its ability to capture critical substructures. In this study, a clustering graph pooling method that first supports multidimensional edge features, called Edge-aware hard clustering graph pooling (EHCPool), is developed. EHCPool proposes the first 'Edge-to-node' score evaluation criterion based on edge features to assess node feature significance. To more effectively capture the critical subgraphs, a novel Iteration n-top strategy is further designed to adaptively learn sparse hard clustering assignments for graphs. Subsequently, an innovative N-E Aggregation strategy is presented to aggregate node and edge feature information in each independent subgraph. The proposed model was evaluated on multi-site brain imaging public datasets and yielded state-of-the-art performance. We believe this method is the first deep learning tool with the potential to probe different types of abnormal functional brain networks from data-driven perspective. Core code is at: https://github.com/swfen/EHCPool.
Spatial and Visual Perspective-Taking via View Rotation and Relation Reasoning for Embodied Reference Understanding
Sep 03, 2023Embodied Reference Understanding studies the reference understanding in an embodied fashion, where a receiver is required to locate a target object referred to by both language and gesture of the sender in a shared physical environment. Its main challenge lies in how to make the receiver with the egocentric view access spatial and visual information relative to the sender to judge how objects are oriented around and seen from the sender, i.e., spatial and visual perspective-taking. In this paper, we propose a REasoning from your Perspective (REP) method to tackle the challenge by modeling relations between the receiver and the sender and the sender and the objects via the proposed novel view rotation and relation reasoning. Specifically, view rotation first rotates the receiver to the position of the sender by constructing an embodied 3D coordinate system with the position of the sender as the origin. Then, it changes the orientation of the receiver to the orientation of the sender by encoding the body orientation and gesture of the sender. Relation reasoning models the nonverbal and verbal relations between the sender and the objects by multi-modal cooperative reasoning in gesture, language, visual content, and spatial position. Experiment results demonstrate the effectiveness of REP, which consistently surpasses all existing state-of-the-art algorithms by a large margin, i.e., +5.22% absolute accuracy in terms of Prec0.5 on YouRefIt.
Privacy Protectability: An Information-theoretical Approach
May 25, 2023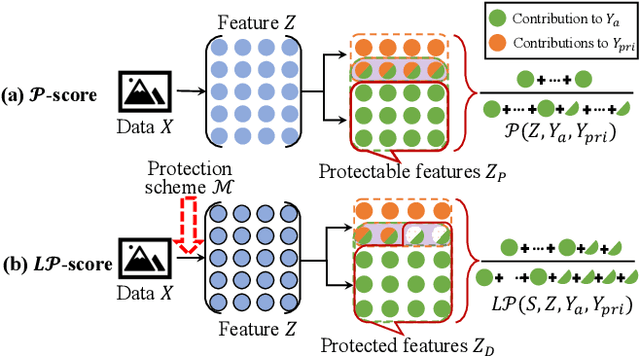


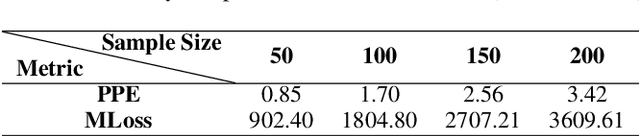
Recently, inference privacy has attracted increasing attention. The inference privacy concern arises most notably in the widely deployed edge-cloud video analytics systems, where the cloud needs the videos captured from the edge. The video data can contain sensitive information and subject to attack when they are transmitted to the cloud for inference. Many privacy protection schemes have been proposed. Yet, the performance of a scheme needs to be determined by experiments or inferred by analyzing the specific case. In this paper, we propose a new metric, \textit{privacy protectability}, to characterize to what degree a video stream can be protected given a certain video analytics task. Such a metric has strong operational meaning. For example, low protectability means that it may be necessary to set up an overall secure environment. We can also evaluate a privacy protection scheme, e.g., assume it obfuscates the video data, what level of protection this scheme has achieved after obfuscation. Our definition of privacy protectability is rooted in information theory and we develop efficient algorithms to estimate the metric. We use experiments on real data to validate that our metric is consistent with empirical measurements on how well a video stream can be protected for a video analytics task.
Four years of multi-modal odometry and mapping on the rail vehicles
Aug 22, 2023

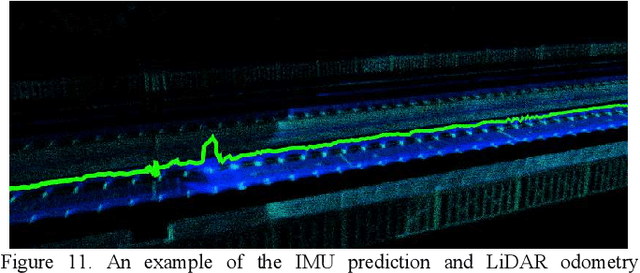
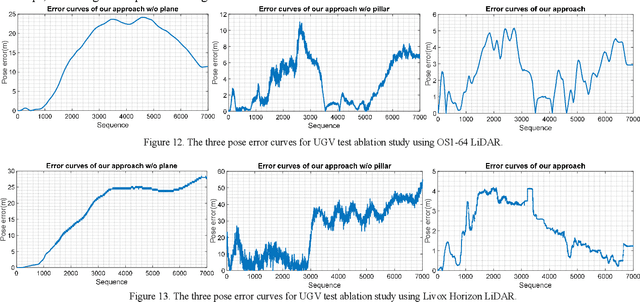
Precise, seamless, and efficient train localization as well as long-term railway environment monitoring is the essential property towards reliability, availability, maintainability, and safety (RAMS) engineering for railroad systems. Simultaneous localization and mapping (SLAM) is right at the core of solving the two problems concurrently. In this end, we propose a high-performance and versatile multi-modal framework in this paper, targeted for the odometry and mapping task for various rail vehicles. Our system is built atop an inertial-centric state estimator that tightly couples light detection and ranging (LiDAR), visual, optionally satellite navigation and map-based localization information with the convenience and extendibility of loosely coupled methods. The inertial sensors IMU and wheel encoder are treated as the primary sensor, which achieves the observations from subsystems to constrain the accelerometer and gyroscope biases. Compared to point-only LiDAR-inertial methods, our approach leverages more geometry information by introducing both track plane and electric power pillars into state estimation. The Visual-inertial subsystem also utilizes the environmental structure information by employing both lines and points. Besides, the method is capable of handling sensor failures by automatic reconfiguration bypassing failure modules. Our proposed method has been extensively tested in the long-during railway environments over four years, including general-speed, high-speed and metro, both passenger and freight traffic are investigated. Further, we aim to share, in an open way, the experience, problems, and successes of our group with the robotics community so that those that work in such environments can avoid these errors. In this view, we open source some of the datasets to benefit the research community.
Mutual Information Regularization for Weakly-supervised RGB-D Salient Object Detection
Jun 06, 2023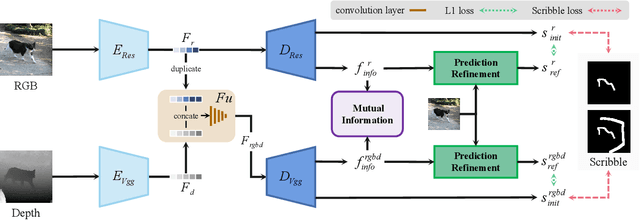

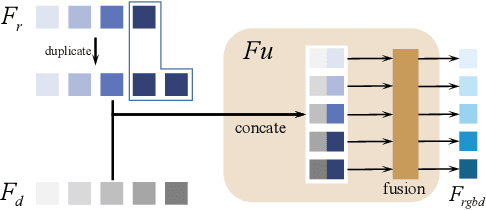

In this paper, we present a weakly-supervised RGB-D salient object detection model via scribble supervision. Specifically, as a multimodal learning task, we focus on effective multimodal representation learning via inter-modal mutual information regularization. In particular, following the principle of disentangled representation learning, we introduce a mutual information upper bound with a mutual information minimization regularizer to encourage the disentangled representation of each modality for salient object detection. Based on our multimodal representation learning framework, we introduce an asymmetric feature extractor for our multimodal data, which is proven more effective than the conventional symmetric backbone setting. We also introduce multimodal variational auto-encoder as stochastic prediction refinement techniques, which takes pseudo labels from the first training stage as supervision and generates refined prediction. Experimental results on benchmark RGB-D salient object detection datasets verify both effectiveness of our explicit multimodal disentangled representation learning method and the stochastic prediction refinement strategy, achieving comparable performance with the state-of-the-art fully supervised models. Our code and data are available at: https://github.com/baneitixiaomai/MIRV.
Dual-path Transformer Based Neural Beamformer for Target Speech Extraction
Aug 30, 2023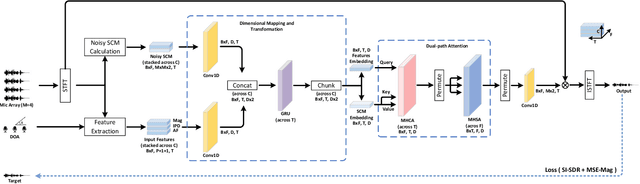
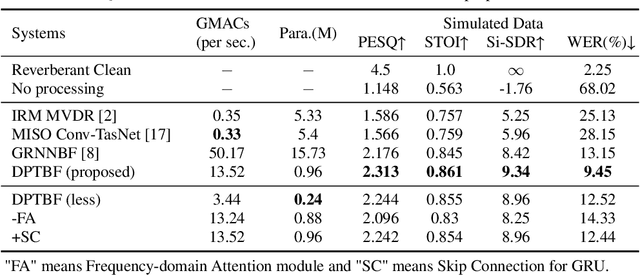
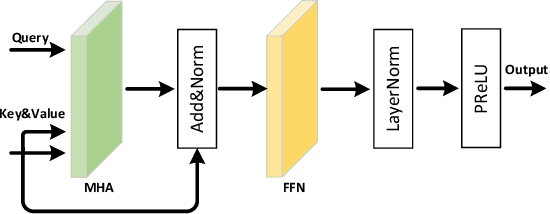
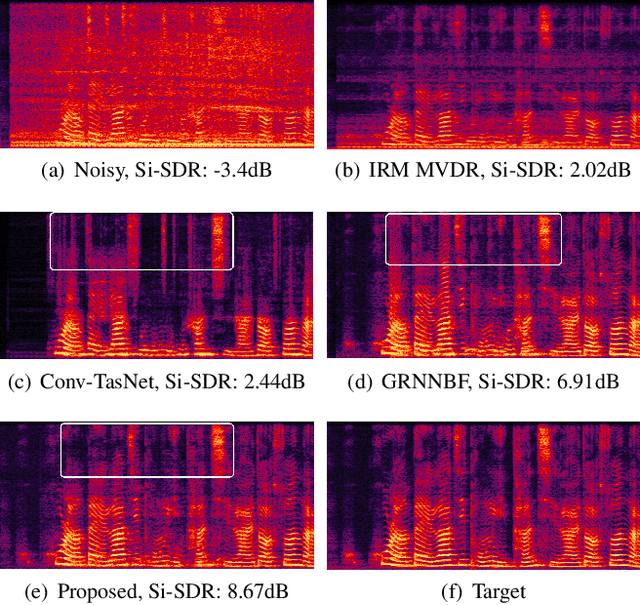
Neural beamformers, integrating both pre-separation and beamforming modules, have shown impressive efficacy in the target speech extraction task. Nevertheless, the performance of these beamformers is inherently constrained by the predictive accuracy of the pre-separation module. In this paper, we introduce a neural beamformer underpinned by a dual-path transformer. Initially, we harness the cross-attention mechanism in the time domain, extracting pivotal spatial information related to beamforming from the noisy covariance matrix. Subsequently, in the frequency domain, the self-attention mechanism is employed to bolster the model's capacity to process frequency-specific details. By design, our model circumvents the influence of pre-separation modules, delivering the performance in a more holistic end-to-end fashion. Experimental results reveal that our model not only surpasses contemporary leading neural beamforming algorithms in separation performance, but also achieves this with a notable reduction in parameter count.
Strengthening the EU AI Act: Defining Key Terms on AI Manipulation
Aug 30, 2023The European Union's Artificial Intelligence Act aims to regulate manipulative and harmful uses of AI, but lacks precise definitions for key concepts. This paper provides technical recommendations to improve the Act's conceptual clarity and enforceability. We review psychological models to define "personality traits," arguing the Act should protect full "psychometric profiles." We urge expanding "behavior" to include "preferences" since preferences causally influence and are influenced by behavior. Clear definitions are provided for "subliminal," "manipulative," and "deceptive" techniques, considering incentives, intent, and covertness. We distinguish "exploiting individuals" from "exploiting groups," emphasising different policy needs. An "informed decision" is defined by four facets: comprehension, accurate information, no manipulation, and understanding AI's influence. We caution the Act's therapeutic use exemption given the lack of regulation of digital therapeutics by the EMA. Overall, the recommendations strengthen definitions of vague concepts in the EU AI Act, enhancing precise applicability to regulate harmful AI manipulation.
WeaverBird: Empowering Financial Decision-Making with Large Language Model, Knowledge Base, and Search Engine
Aug 30, 2023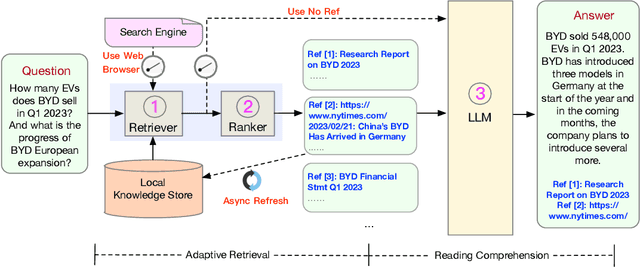
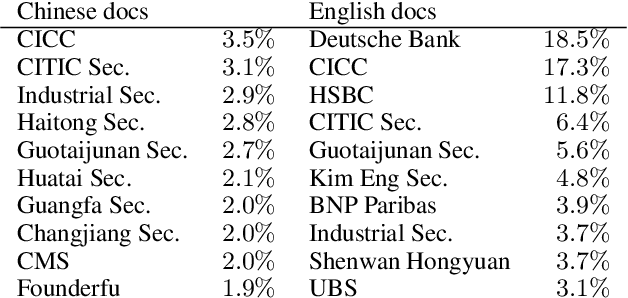
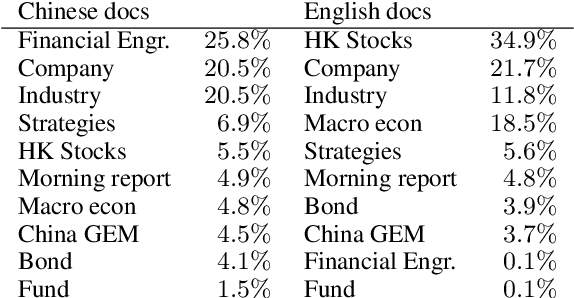
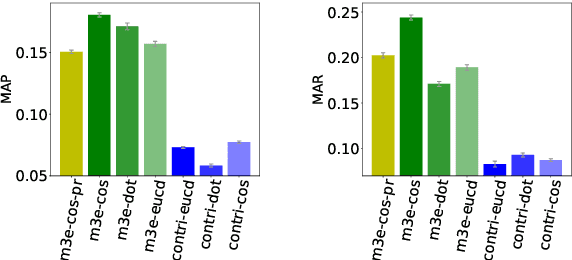
We present WeaverBird, an intelligent dialogue system designed specifically for the finance domain. Our system harnesses a large language model of GPT architecture that has been tuned using extensive corpora of finance-related text. As a result, our system possesses the capability to understand complex financial queries, such as "How should I manage my investments during inflation?", and provide informed responses. Furthermore, our system incorporates a local knowledge base and a search engine to retrieve relevant information. The final responses are conditioned on the search results and include proper citations to the sources, thus enjoying an enhanced credibility. Through a range of finance-related questions, we have demonstrated the superior performance of our system compared to other models. To experience our system firsthand, users can interact with our live demo at https://weaverbird.ttic.edu, as well as watch our 2-min video illustration at https://www.youtube.com/watch?v=fyV2qQkX6Tc.
Unlocking Fine-Grained Details with Wavelet-based High-Frequency Enhancement in Transformers
Aug 25, 2023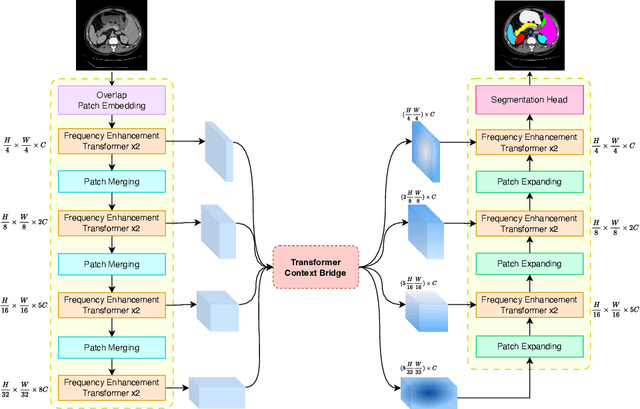
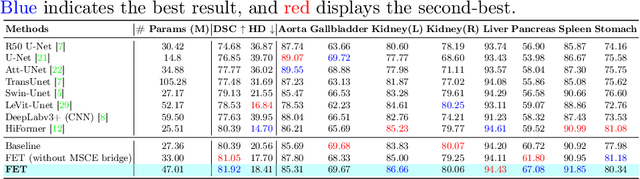
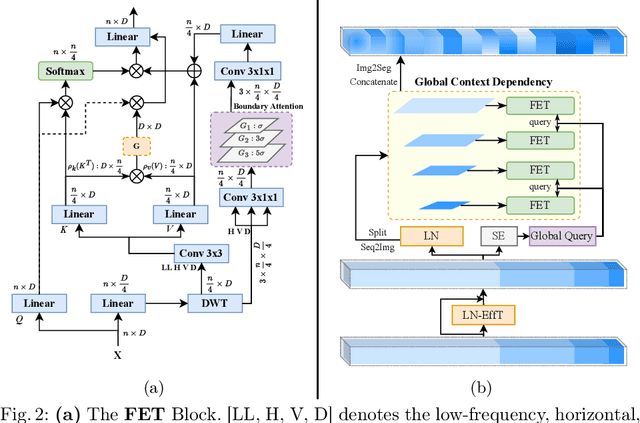
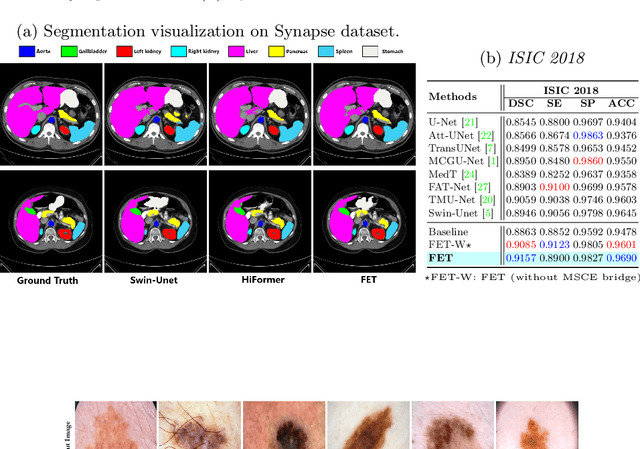
Medical image segmentation is a critical task that plays a vital role in diagnosis, treatment planning, and disease monitoring. Accurate segmentation of anatomical structures and abnormalities from medical images can aid in the early detection and treatment of various diseases. In this paper, we address the local feature deficiency of the Transformer model by carefully re-designing the self-attention map to produce accurate dense prediction in medical images. To this end, we first apply the wavelet transformation to decompose the input feature map into low-frequency (LF) and high-frequency (HF) subbands. The LF segment is associated with coarse-grained features while the HF components preserve fine-grained features such as texture and edge information. Next, we reformulate the self-attention operation using the efficient Transformer to perform both spatial and context attention on top of the frequency representation. Furthermore, to intensify the importance of the boundary information, we impose an additional attention map by creating a Gaussian pyramid on top of the HF components. Moreover, we propose a multi-scale context enhancement block within skip connections to adaptively model inter-scale dependencies to overcome the semantic gap among stages of the encoder and decoder modules. Throughout comprehensive experiments, we demonstrate the effectiveness of our strategy on multi-organ and skin lesion segmentation benchmarks. The implementation code will be available upon acceptance. \href{https://github.com/mindflow-institue/WaveFormer}{GitHub}.
* Accepted in MICCAI 2023 workshop MLMI