 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unpaired Optical Coherence Tomography Angiography Image Super-Resolution via Frequency-Aware Inverse-Consistency GAN
Sep 29, 2023
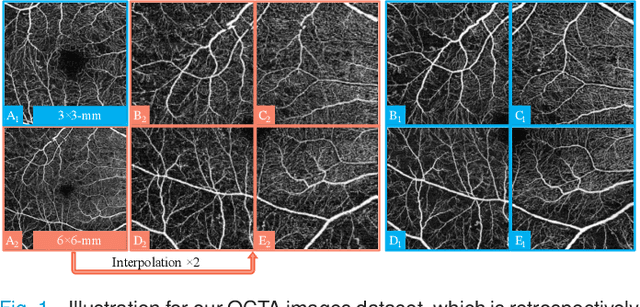
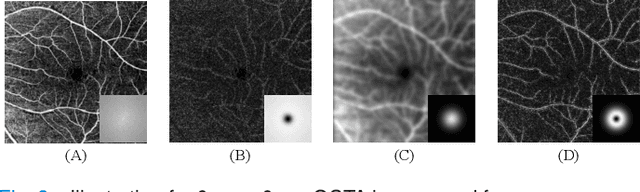
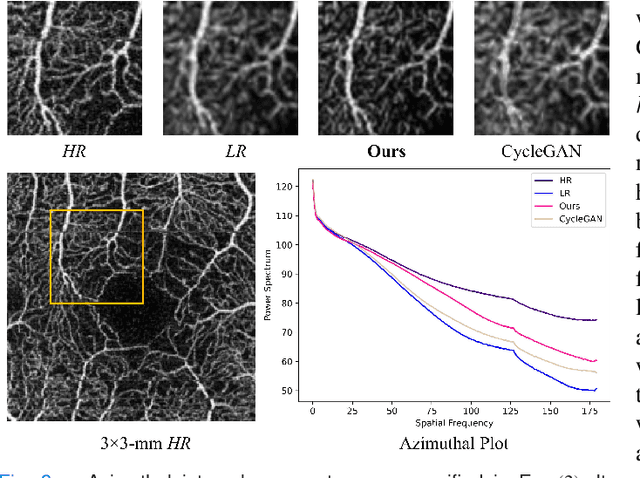
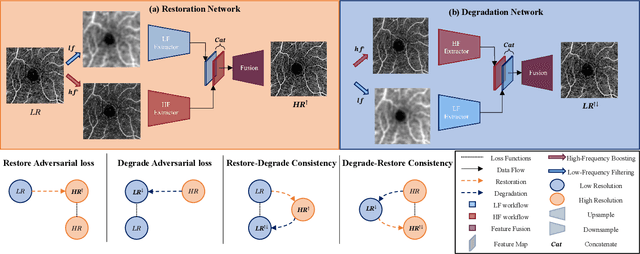
For optical coherence tomography angiography (OCTA) images, a limited scanning rate leads to a trade-off between field-of-view (FOV) and imaging resolution. Although larger FOV images may reveal more parafoveal vascular lesions, their application is greatly hampered due to lower resolution. To increase the resolution, previous works only achieved satisfactory performance by using paired data for training, but real-world applications are limited by the challenge of collecting large-scale paired images. Thus, an unpaired approach is highly demanded. Generative Adversarial Network (GAN) has been commonly used in the unpaired setting, but it may struggle to accurately preserve fine-grained capillary details, which are critical biomarkers for OCTA. In this paper, our approach aspires to preserve these details by leveraging the frequency information, which represents details as high-frequencies ($\textbf{hf}$) and coarse-grained backgrounds as low-frequencies ($\textbf{lf}$). In general, we propose a GAN-based unpaired super-resolution method for OCTA images and exceptionally emphasize $\textbf{hf}$ fine capillaries through a dual-path generator. To facilitate a precise spectrum of the reconstructed image, we also propose a frequency-aware adversarial loss for the discriminator and introduce a frequency-aware focal consistency loss for end-to-end optimization. Experiments show that our method outperforms other state-of-the-art unpaired methods both quantitatively and visually.
RLAdapter: Bridging Large Language Models to Reinforcement Learning in Open Worlds
Sep 29, 2023While reinforcement learning (RL) shows remarkable success in decision-making problems, it often requires a lot of interactions with the environment, and in sparse-reward environments, it is challenging to learn meaningful policies. Large Language Models (LLMs) can potentially provide valuable guidance to agents in learning policies, thereby enhancing the performance of RL algorithms in such environments. However, LLMs often encounter difficulties in understanding downstream tasks, which hinders their ability to optimally assist agents in these tasks. A common approach to mitigating this issue is to fine-tune the LLMs with task-related data, enabling them to offer useful guidance for RL agents. However, this approach encounters several difficulties, such as inaccessible model weights or the need for significant computational resources, making it impractical. In this work, we introduce RLAdapter, a framework that builds a better connection between RL algorithms and LLMs by incorporating an adapter model. Within the RLAdapter framework, fine-tuning a lightweight language model with information generated during the training process of RL agents significantly aids LLMs in adapting to downstream tasks, thereby providing better guidance for RL agents. We conducted experiments to evaluate RLAdapter in the Crafter environment, and the results show that RLAdapter surpasses the SOTA baselines. Furthermore, agents under our framework exhibit common-sense behaviors that are absent in baseline models.
Style Transfer for Non-differentiable Audio Effects
Sep 29, 2023Digital audio effects are widely used by audio engineers to alter the acoustic and temporal qualities of audio data. However, these effects can have a large number of parameters which can make them difficult to learn for beginners and hamper creativity for professionals. Recently, there have been a number of efforts to employ progress in deep learning to acquire the low-level parameter configurations of audio effects by minimising an objective function between an input and reference track, commonly referred to as style transfer. However, current approaches use inflexible black-box techniques or require that the effects under consideration are implemented in an auto-differentiation framework. In this work, we propose a deep learning approach to audio production style matching which can be used with effects implemented in some of the most widely used frameworks, requiring only that the parameters under consideration have a continuous domain. Further, our method includes style matching for various classes of effects, many of which are difficult or impossible to be approximated closely using differentiable functions. We show that our audio embedding approach creates logical encodings of timbral information, which can be used for a number of downstream tasks. Further, we perform a listening test which demonstrates that our approach is able to convincingly style match a multi-band compressor effect.
CrossLoco: Human Motion Driven Control of Legged Robots via Guided Unsupervised Reinforcement Learning
Sep 29, 2023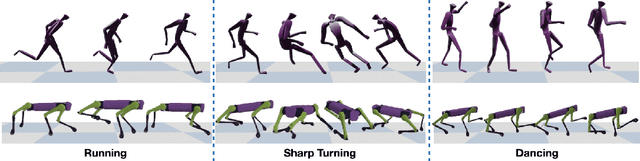
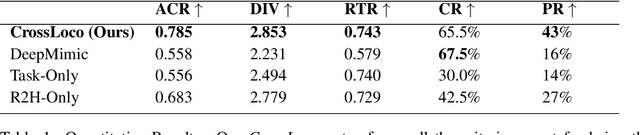
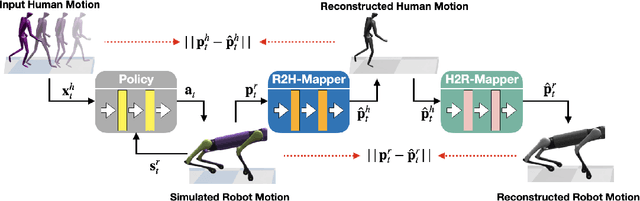
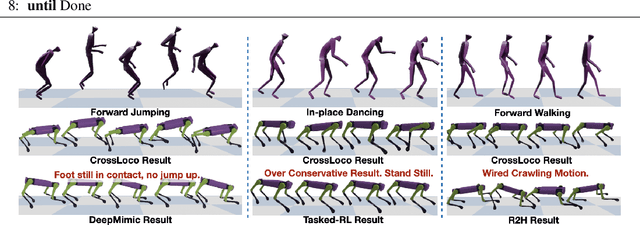
Human motion driven control (HMDC) is an effective approach for generating natural and compelling robot motions while preserving high-level semantics. However, establishing the correspondence between humans and robots with different body structures is not straightforward due to the mismatches in kinematics and dynamics properties, which causes intrinsic ambiguity to the problem. Many previous algorithms approach this motion retargeting problem with unsupervised learning, which requires the prerequisite skill sets. However, it will be extremely costly to learn all the skills without understanding the given human motions, particularly for high-dimensional robots. In this work, we introduce CrossLoco, a guided unsupervised reinforcement learning framework that simultaneously learns robot skills and their correspondence to human motions. Our key innovation is to introduce a cycle-consistency-based reward term designed to maximize the mutual information between human motions and robot states. We demonstrate that the proposed framework can generate compelling robot motions by translating diverse human motions, such as running, hopping, and dancing. We quantitatively compare our CrossLoco against the manually engineered and unsupervised baseline algorithms along with the ablated versions of our framework and demonstrate that our method translates human motions with better accuracy, diversity, and user preference. We also showcase its utility in other applications, such as synthesizing robot movements from language input and enabling interactive robot control.
Robust Asynchronous Collaborative 3D Detection via Bird's Eye View Flow
Sep 29, 2023By facilitating communication among multiple agents, collaborative perception can substantially boost each agent's perception ability. However, temporal asynchrony among agents is inevitable in real-world due to communication delays, interruptions, and clock misalignments. This issue causes information mismatch during multi-agent fusion, seriously shaking the foundation of collaboration. To address this issue, we propose CoBEVFlow, an asynchrony-robust collaborative 3D perception system based on bird's eye view (BEV) flow. The key intuition of CoBEVFlow is to compensate motions to align asynchronous collaboration messages sent by multiple agents. To model the motion in a scene, we propose BEV flow, which is a collection of the motion vector corresponding to each spatial location. Based on BEV flow, asynchronous perceptual features can be reassigned to appropriate positions, mitigating the impact of asynchrony. CoBEVFlow has two advantages: (i) CoBEVFlow can handle asynchronous collaboration messages sent at irregular, continuous time stamps without discretization; and (ii) with BEV flow, CoBEVFlow only transports the original perceptual features, instead of generating new perceptual features, avoiding additional noises. To validate CoBEVFlow's efficacy, we create IRregular V2V(IRV2V), the first synthetic collaborative perception dataset with various temporal asynchronies that simulate different real-world scenarios. Extensive experiments conducted on both IRV2V and the real-world dataset DAIR-V2X show that CoBEVFlow consistently outperforms other baselines and is robust in extremely asynchronous settings. The code will be released.
Improving Trajectory Prediction in Dynamic Multi-Agent Environment by Dropping Waypoints
Sep 29, 2023The inherently diverse and uncertain nature of trajectories presents a formidable challenge in accurately modeling them. Motion prediction systems must effectively learn spatial and temporal information from the past to forecast the future trajectories of the agent. Many existing methods learn temporal motion via separate components within stacked models to capture temporal features. This paper introduces a novel framework, called Temporal Waypoint Dropping (TWD), that promotes explicit temporal learning through the waypoint dropping technique. Learning through waypoint dropping can compel the model to improve its understanding of temporal correlations among agents, thus leading to a significant enhancement in trajectory prediction. Trajectory prediction methods often operate under the assumption that observed trajectory waypoint sequences are complete, disregarding real-world scenarios where missing values may occur, which can influence their performance. Moreover, these models frequently exhibit a bias towards particular waypoint sequences when making predictions. Our TWD is capable of effectively addressing these issues. It incorporates stochastic and fixed processes that regularize projected past trajectories by strategically dropping waypoints based on temporal sequences. Through extensive experiments, we demonstrate the effectiveness of TWD in forcing the model to learn complex temporal correlations among agents. Our approach can complement existing trajectory prediction methods to enhance prediction accuracy. We also evaluate our proposed method across three datasets: NBA Sports VU, ETH-UCY, and TrajNet++.
Enhancing Large Language Models in Coding Through Multi-Perspective Self-Consistency
Sep 29, 2023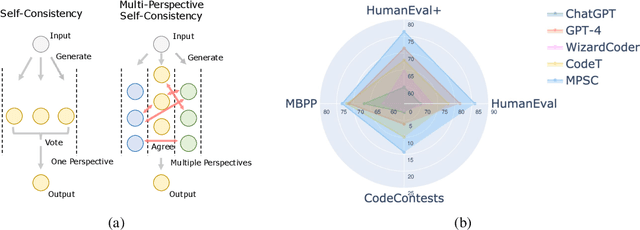


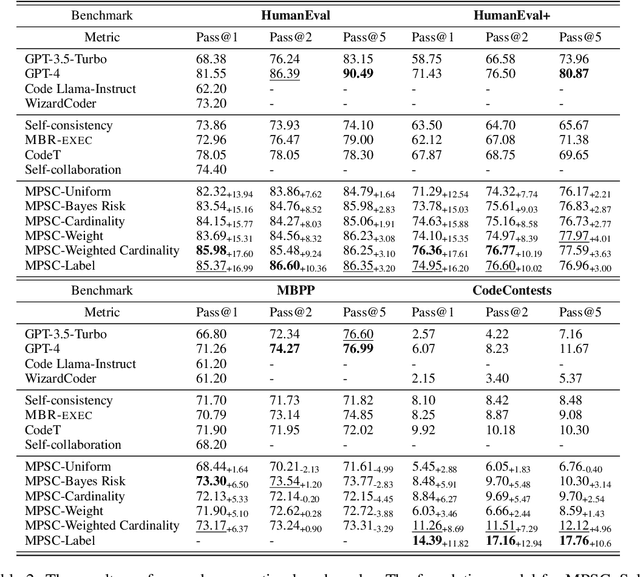
Large language models (LLMs) have exhibited remarkable ability in textual generation. However, in complex reasoning tasks such as code generation, generating the correct answer in a single attempt remains a formidable challenge for LLMs. Previous research has explored solutions by aggregating multiple outputs, leveraging the consistency among them. However, none of them have comprehensively captured this consistency from different perspectives. In this paper, we propose the Multi-Perspective Self-Consistency (MPSC) framework, a novel decoding strategy for LLM that incorporates both inter-consistency across outputs from multiple perspectives and intra-consistency within a single perspective. Specifically, we ask LLMs to sample multiple diverse outputs from various perspectives for a given query and then construct a multipartite graph based on them. With two predefined measures of consistency, we embed both inter- and intra-consistency information into the graph. The optimal choice is then determined based on consistency analysis in the graph. We conduct comprehensive evaluation on the code generation task by introducing solution, specification and test case as three perspectives. We leverage a code interpreter to quantitatively measure the inter-consistency and propose several intra-consistency measure functions. Our MPSC framework significantly boosts the performance on various popular benchmarks, including HumanEval (+17.60%), HumanEval Plus (+17.61%), MBPP (+6.50%) and CodeContests (+11.82%) in Pass@1, when compared to original outputs generated from ChatGPT, and even surpassing GPT-4.
Retail-786k: a Large-Scale Dataset for Visual Entity Matching
Sep 29, 2023
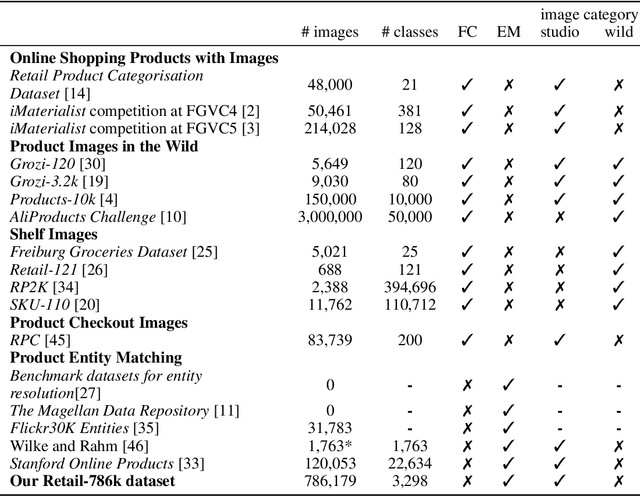


Entity Matching (EM) defines the task of learning to group objects by transferring semantic concepts from example groups (=entities) to unseen data. Despite the general availability of image data in the context of many EM-problems, most currently available EM-algorithms solely rely on (textual) meta data. In this paper, we introduce the first publicly available large-scale dataset for "visual entity matching", based on a production level use case in the retail domain. Using scanned advertisement leaflets, collected over several years from different European retailers, we provide a total of ~786k manually annotated, high resolution product images containing ~18k different individual retail products which are grouped into ~3k entities. The annotation of these product entities is based on a price comparison task, where each entity forms an equivalence class of comparable products. Following on a first baseline evaluation, we show that the proposed "visual entity matching" constitutes a novel learning problem which can not sufficiently be solved using standard image based classification and retrieval algorithms. Instead, novel approaches which allow to transfer example based visual equivalent classes to new data are needed to address the proposed problem. The aim of this paper is to provide a benchmark for such algorithms. Information about the dataset, evaluation code and download instructions are provided under https://www.retail-786k.org/.
DataDAM: Efficient Dataset Distillation with Attention Matching
Sep 29, 2023Researchers have long tried to minimize training costs in deep learning while maintaining strong generalization across diverse datasets. Emerging research on dataset distillation aims to reduce training costs by creating a small synthetic set that contains the information of a larger real dataset and ultimately achieves test accuracy equivalent to a model trained on the whole dataset. Unfortunately, the synthetic data generated by previous methods are not guaranteed to distribute and discriminate as well as the original training data, and they incur significant computational costs. Despite promising results, there still exists a significant performance gap between models trained on condensed synthetic sets and those trained on the whole dataset. In this paper, we address these challenges using efficient Dataset Distillation with Attention Matching (DataDAM), achieving state-of-the-art performance while reducing training costs. Specifically, we learn synthetic images by matching the spatial attention maps of real and synthetic data generated by different layers within a family of randomly initialized neural networks. Our method outperforms the prior methods on several datasets, including CIFAR10/100, TinyImageNet, ImageNet-1K, and subsets of ImageNet-1K across most of the settings, and achieves improvements of up to 6.5% and 4.1% on CIFAR100 and ImageNet-1K, respectively. We also show that our high-quality distilled images have practical benefits for downstream applications, such as continual learning and neural architecture search.
* Accepted in International Conference in Computer Vision (ICCV) 2023
Simultaneously Learning Speaker's Direction and Head Orientation from Binaural Recordings
Sep 26, 2023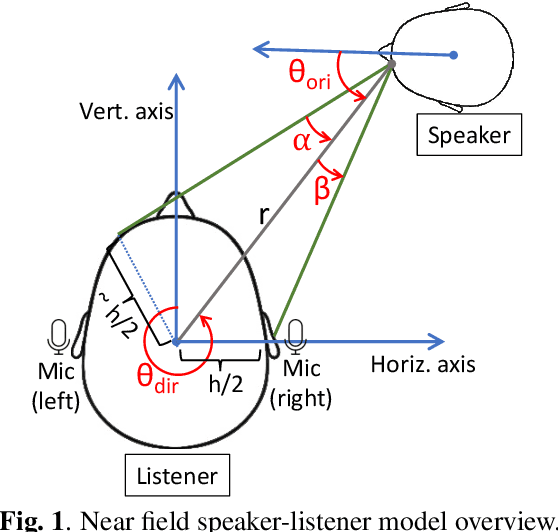
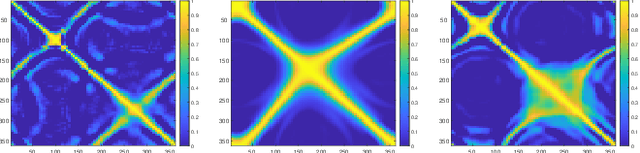
Estimation of a speaker's direction and head orientation with binaural recordings can be a critical piece of information in many real-world applications with emerging `earable' devices, including smart headphones and AR/VR headsets. However, it requires predicting the mutual head orientations of both the speaker and the listener, which is challenging in practice. This paper presents a system for jointly predicting speaker-listener head orientations by leveraging inherent human voice directivity and listener's head-related transfer function (HRTF) as perceived by the ear-mounted microphones on the listener. We propose a convolution neural network model that, given binaural speech recording, can predict the orientation of both speaker and listener with respect to the line joining the two. The system builds on the core observation that the recordings from the left and right ears are differentially affected by the voice directivity as well as the HRTF. We also incorporate the fact that voice is more directional at higher frequencies compared to lower frequencies.